
關(guān)于memcache內(nèi)核,全網(wǎng)最通俗的講解!(由淺入深,值得收藏)
memcache曾經(jīng)是互聯(lián)網(wǎng)分層架構(gòu)中,使用最多的的KV緩存,如今卻幾乎被 redis 替代。
畫(huà)外音:你還在用mc嗎,還是redis?
但memcache的內(nèi)核設(shè)計(jì),卻值得每一個(gè)技術(shù)人學(xué)習(xí)和借鑒。
第一部分:知其然
關(guān)于memcache一些基礎(chǔ)特性,使用過(guò)的小伙伴必須知道:
(1)mc的核心職能是KV內(nèi)存管理,value存儲(chǔ)最大為1M,它不支持復(fù)雜數(shù)據(jù)結(jié)構(gòu)(哈希、列表、集合、有序集合等);
(2)mc不支持持久化;
(3)mc支持key過(guò)期;
(4)mc持續(xù)運(yùn)行很少會(huì)出現(xiàn)內(nèi)存碎片,速度不會(huì)隨著服務(wù)運(yùn)行時(shí)間降低;
(5)mc使用非阻塞IO復(fù)用網(wǎng)絡(luò)模型,使用監(jiān)聽(tīng)線程/工作線程的多線程模型;
memcache的這些特性,成竹在胸了嗎?
第二部分:知其原理(why, what)
第一部分,只停留在使用層面,除此之外,還必須了解原理。
memcache為什么不支持復(fù)雜數(shù)據(jù)結(jié)構(gòu)?為什么不支持持久化?
業(yè)務(wù)決定技術(shù)方案,mc的誕生,以“以服務(wù)的方式,而不是庫(kù)的方式管理KV內(nèi)存”為設(shè)計(jì)目標(biāo),它顛覆的是,KV內(nèi)存管理組件庫(kù),復(fù)雜數(shù)據(jù)結(jié)構(gòu)與持久化并不是它的初衷。
當(dāng)然,用“顛覆”這個(gè)詞未必不合適,庫(kù)和服務(wù)各有使用場(chǎng)景,只是在分布式的環(huán)境下,服務(wù)的使用范圍更廣。設(shè)計(jì)目標(biāo),誕生背景很重要,這一定程度上決定了實(shí)現(xiàn)方案,就如redis的出現(xiàn),是為了有一個(gè)更好用,更多功能的緩存服務(wù)。
memcache是用什么技術(shù)實(shí)現(xiàn)key過(guò)期的?
懶淘汰(lazy expiration)。
memcache為什么能保證運(yùn)行性能,且很少會(huì)出現(xiàn)內(nèi)存碎片?
提前分配內(nèi)存。
memcache為什么要使用非阻塞IO復(fù)用網(wǎng)絡(luò)模型,使用監(jiān)聽(tīng)線程/工作線程的多線程模型,有什么優(yōu)缺點(diǎn)?
目的是提高吞吐量。多線程能夠充分的利用多核,但會(huì)帶來(lái)一些鎖沖突。
第三部分:知其所以然,知其內(nèi)核(how)
一個(gè)對(duì)技術(shù)內(nèi)核充滿“好奇心”的工程師,必須了解細(xì)節(jié),掌握內(nèi)核。
畫(huà)外音:本文剛剛開(kāi)始。
memcache是什么實(shí)現(xiàn)內(nèi)存管理,以減小內(nèi)存碎片,是怎么實(shí)現(xiàn)分配內(nèi)存的?
開(kāi)講之前,先解釋幾個(gè)非常重要的概念:
chunk:它是將內(nèi)存分配給用戶使用的最小單元。
item:用戶要存儲(chǔ)的數(shù)據(jù),包含key和value,最終都存儲(chǔ)在chunk里。
slab:它會(huì)管理一個(gè)固定chunk size的若干個(gè)chunk,而mc的內(nèi)存管理,由若干個(gè)slab組成。
畫(huà)外音:為了避免復(fù)雜性,本文先不引入page的概念了。

如上圖所示,一系列slab,分別管理128B,256B,512B…的chunk內(nèi)存單元。
將上圖中管理128B的slab0放大:
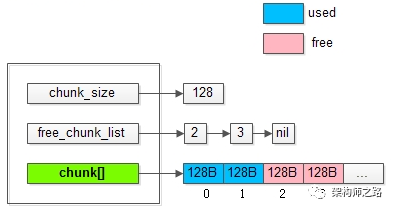
能夠發(fā)現(xiàn)slab中的一些核心數(shù)據(jù)結(jié)構(gòu)是:
(1)chunk_size:該slab管理的是128B的chunk;
(2)free_chunk_list:用于快速找到空閑的chunk;
(3)chunk[]:已經(jīng)預(yù)分配好,用于存放用戶item數(shù)據(jù)的實(shí)際chunk空間;
畫(huà)外音:其實(shí)還有l(wèi)ru_list。
假如用戶要存儲(chǔ)一個(gè)100B的item,是如何找到對(duì)應(yīng)的可用chunk的呢?
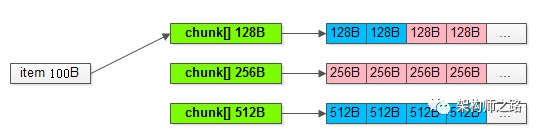
會(huì)從最接近item大小的slab的chunk[]中,通過(guò)free_chunk_list快速找到對(duì)應(yīng)的chunk,如上圖所示,與item大小最接近的chunk是128B。
為什么不會(huì)出現(xiàn)內(nèi)存碎片呢?

拿到一個(gè)128B的chunk,去存儲(chǔ)一個(gè)100B的item,余下的28B不會(huì)再被其他的item所使用,即:實(shí)際上浪費(fèi)了存儲(chǔ)空間,來(lái)減少內(nèi)存碎片,保證訪問(wèn)的速度。
畫(huà)外音:理論上,內(nèi)存碎片幾乎不存在。
memcache通過(guò)slab,chunk,free_chunk_list來(lái)快速分配內(nèi)存,存儲(chǔ)用戶的item,那它又是如何快速實(shí)現(xiàn)key的查找的呢?
沒(méi)有什么特別算法:
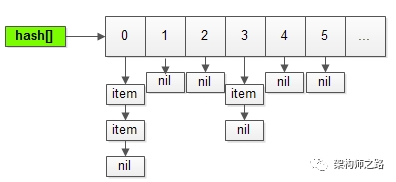
(1)通過(guò)hash表實(shí)現(xiàn)快速查找;
(2)通過(guò)鏈表來(lái)解決沖突;
用最樸素的方式,實(shí)現(xiàn)key的快速查找。
隨著item的個(gè)數(shù)不斷增多,hash沖突越來(lái)越大,hash表如何保證查詢效率呢?
當(dāng)item總數(shù)達(dá)到hash表長(zhǎng)度的1.5倍時(shí),hash表會(huì)動(dòng)態(tài)擴(kuò)容,rehash將數(shù)據(jù)重新分布,以保證查找效率不會(huì)不斷降低。
擴(kuò)展hash表之后,同一個(gè)key在新舊hash表內(nèi)的位置會(huì)發(fā)生變化,如何保證數(shù)據(jù)的一致性,以及如何保證遷移過(guò)程服務(wù)的可用性呢(肯定不能加一把大鎖,遷移完成數(shù)據(jù),再重新服務(wù)吧)?
哈希表擴(kuò)展,數(shù)據(jù)遷移是一個(gè)耗時(shí)的操作,會(huì)有一個(gè)專(zhuān)門(mén)的線程來(lái)實(shí)施,為了避免大鎖,采用的是“分段遷移”的策略。
當(dāng)item數(shù)量達(dá)到閾值時(shí),遷移線程會(huì)分段遷移,對(duì)hash表中的一部分桶進(jìn)行加鎖,遷移數(shù)據(jù),解鎖:
(1)一來(lái),保證不會(huì)有長(zhǎng)時(shí)間的阻塞,影響服務(wù)的可用性;
(2)二來(lái),保證item不會(huì)在新舊hash表里不一致;
新的問(wèn)題來(lái)了,對(duì)于已經(jīng)存在于舊hash表中的item,可以通過(guò)上述方式遷移,那么在item遷移的過(guò)程中,如果有新的item插入,是應(yīng)該插入舊hash表還是新hash表呢?
memcache的做法是,判斷舊hash表中,item應(yīng)該插入的桶,是否已經(jīng)遷移至新表中:
(1)如果已經(jīng)遷移,則item直接插入新hash表;
(2)如果還沒(méi)有被遷移,則直接插入舊hash表,未來(lái)等待遷移線程來(lái)遷移至新hash表;
為什么要這么做呢,不能直接插入新hash表嗎?
memcache沒(méi)有給出官方的解釋?zhuān)瑯侵鞔y(cè),這種方法能夠保證一個(gè)桶內(nèi)的數(shù)據(jù),只在一個(gè)hash表中(要么新表,要么舊表),任何場(chǎng)景下都不會(huì)出現(xiàn),舊表新表查詢兩次,以提升查詢速度。
memcache是怎么實(shí)現(xiàn)key過(guò)期的,懶淘汰(lazy expiration)具體是怎么玩的?
實(shí)現(xiàn)“超時(shí)”和“過(guò)期”,最常見(jiàn)的兩種方法是:
(1)啟動(dòng)一個(gè)超時(shí)線程,對(duì)所有item進(jìn)行掃描,如果發(fā)現(xiàn)超時(shí),則進(jìn)行超時(shí)回調(diào)處理;
(2)每個(gè)item設(shè)定一個(gè)超時(shí)信號(hào)通知,通知觸發(fā)超時(shí)回調(diào)處理;
這兩種方法,都需要有額外的資源消耗。
mc的查詢業(yè)務(wù)非常簡(jiǎn)單,只會(huì)返回cache hit與cache miss兩種結(jié)果,這種場(chǎng)景下,非常適合使用懶淘汰的方式。
懶淘汰的核心是:
(1)item不會(huì)被主動(dòng)淘汰,即沒(méi)有超時(shí)線程,也沒(méi)有信號(hào)通知來(lái)主動(dòng)檢查;
(2)item每次會(huì)查詢(get)時(shí),檢查一下時(shí)間戳,如果已經(jīng)過(guò)期,被動(dòng)淘汰,并返回cache miss;
舉個(gè)例子,假如set了一個(gè)key,有效期100s:
(1)在第50s的時(shí)候,有用戶查詢(get)了這個(gè)key,判斷未過(guò)期,返回對(duì)應(yīng)的value值;
(2)在第200s的時(shí)候,又有用戶查詢(get)了這個(gè)key,判斷已過(guò)期,將item所在的chunk釋放,返回cache miss;
這種方式的實(shí)現(xiàn)代價(jià)很小,消耗資源非常低:
(1)在item里,加入一個(gè)過(guò)期時(shí)間屬性;
(2)在get時(shí),加入一個(gè)時(shí)間判斷;
內(nèi)存總是有限的,chunk數(shù)量有限的情況下,能夠存儲(chǔ)的item個(gè)數(shù)是有限的,假如chunk被用完了,該怎么辦?
仍然是上面的例子,假如128B的chunk都用完了,用戶又set了一個(gè)100B的item,要不要擠掉已有的item?
要。
這里的啟示是:
(1)即使item的有效期設(shè)置為“永久”,也可能被淘汰;
(2)如果要做全量數(shù)據(jù)緩存,一定要仔細(xì)評(píng)估,cache的內(nèi)存大小,必須大于,全量數(shù)據(jù)的總大小,否則很容易踩坑;
擠掉哪一個(gè)item?怎么擠?
這里涉及LRU淘汰機(jī)制。
如果操作系統(tǒng)的內(nèi)存管理,最常見(jiàn)的淘汰算法是FIFO和LRU:
(1)FIFO(first in first out):最先被set的item,最先被淘汰;
(2)LRU(least recently used):最近最少被使用(get/set)的item,最先被淘汰;
使用LRU算法擠掉item,需要增加兩個(gè)屬性:
(1)最近item訪問(wèn)計(jì)數(shù);
(2)最近item訪問(wèn)時(shí)間;
并增加一個(gè)LRU鏈表,就能夠快速實(shí)現(xiàn)。
畫(huà)外音:所以,管理chunk的每個(gè)slab,除了free_chunk_list,還有l(wèi)ru_list。
memcache,你學(xué)會(huì)了嗎?
思路比結(jié)論重要。
架構(gòu)師之路-分享技術(shù)思路
文章較長(zhǎng),幫忙轉(zhuǎn)發(fā)+在看。