
理解Meta Learning 元學(xué)習(xí),這篇文章就夠了!
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

AI編輯:我是小將
本文作者:謝楊易
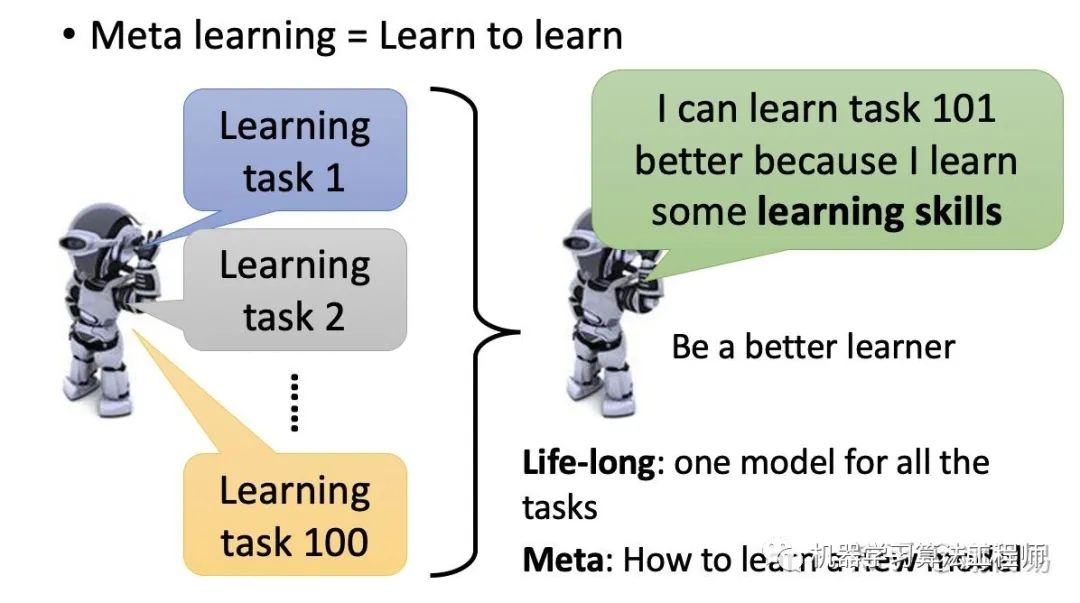
優(yōu)化目標(biāo)和loss 一般的機(jī)器學(xué)習(xí)任務(wù)是,通過訓(xùn)練數(shù)據(jù)得到一個(gè)模型,然后在測(cè)試數(shù)據(jù)上進(jìn)行驗(yàn)證。一般來說我們僅關(guān)注模型在該任務(wù)上的表現(xiàn)。而meta learning則探討解決另一個(gè)問題,就是我們能否通過學(xué)習(xí)不同的任務(wù),從而讓機(jī)器學(xué)會(huì)如何去學(xué)習(xí)呢?也就是learn to learn。我們關(guān)注的不再是模型在某個(gè)任務(wù)上的表現(xiàn),而是模型在多個(gè)任務(wù)上學(xué)習(xí)的能力。
試想一下機(jī)器學(xué)習(xí)了100個(gè)任務(wù),他在第101個(gè)任務(wù)上一般就可以學(xué)的更好。比如機(jī)器學(xué)習(xí)了圖像分類、語(yǔ)音識(shí)別、推薦排序等任務(wù)后,在文本分類上,它就可以因?yàn)橹皩W(xué)到的東西,而學(xué)的更好。meta learning就是解決這個(gè)問題,如何讓機(jī)器去學(xué)習(xí)。
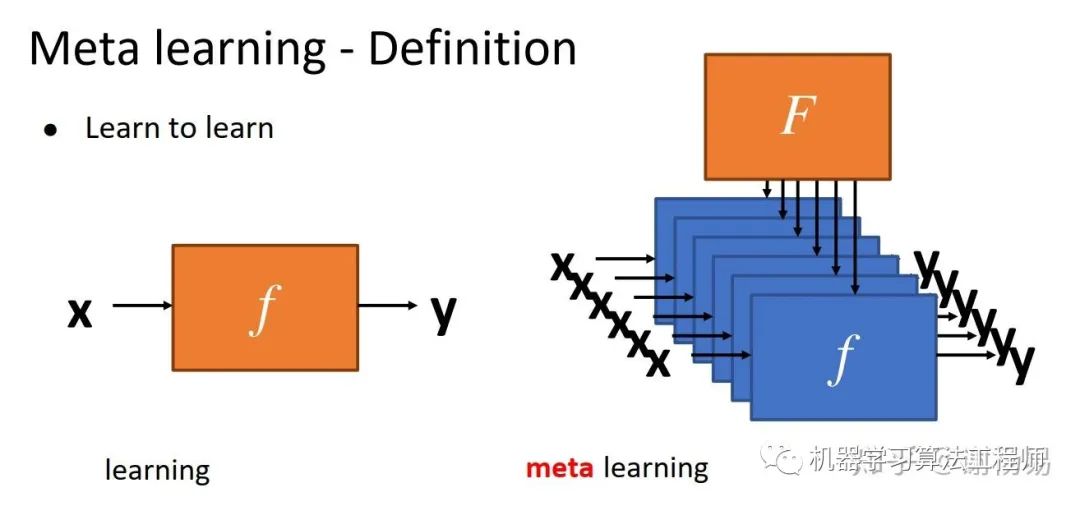
一般的機(jī)器學(xué)習(xí)任務(wù),我們是需要學(xué)習(xí)一個(gè)模型f,由輸入x得到輸出y。而meta learning,則是要學(xué)習(xí)一個(gè)F,用它來學(xué)習(xí)各種任務(wù)的f。如下圖
m5 優(yōu)化目標(biāo)和loss5 優(yōu)化目標(biāo)和losseta learning的優(yōu)勢(shì)主要有
讓學(xué)習(xí)更加有效率。我們通過多個(gè)task的學(xué)習(xí),使得模型學(xué)習(xí)其他task時(shí)更加容易。
樣本數(shù)量比較少的任務(wù)上,更加需要有效率的學(xué)習(xí),從而提升準(zhǔn)確率和收斂速度。meta learning是few shot learning的一個(gè)比較好的解決方案
通過meta learning,我們可以學(xué)到
模型參數(shù) model parameters。包括模型的初始化參數(shù),embedding,特征表達(dá)等
模型架構(gòu)。可以通過network architecture search(NAS)得到模型的架構(gòu),比如幾層網(wǎng)絡(luò),每層內(nèi)部如何設(shè)計(jì)等
模型超參數(shù)。比如learning rate,drop out rate,optimizer等。這個(gè)是AutoML的范疇
算法本身,因?yàn)椴灰欢ㄊ且粋€(gè)網(wǎng)絡(luò)模型。
meta learning需要訓(xùn)練多個(gè)task,故一般每個(gè)task樣本不會(huì)很多,其數(shù)據(jù)集本身也是few shot。常用的數(shù)據(jù)集datasets如下。
Omniglot
它由很多種不同語(yǔ)言構(gòu)成,包括1623種字符,每個(gè)字符20個(gè)樣本。所以也算是few shot learning了。

miniImageNet
ImageNet的few shot版本
CUB
Caltech-UCSD Birds。各種鳥類的圖片,也是few shot。

如何評(píng)價(jià)meta learning的好壞呢,也就是我們的優(yōu)化目標(biāo)是什么呢。一般來說,meta learning需要多個(gè)機(jī)器學(xué)習(xí)task作為數(shù)據(jù)集,其中一部分task作為training task,另一部分作為testing task。training task和testing task中都包括訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)。
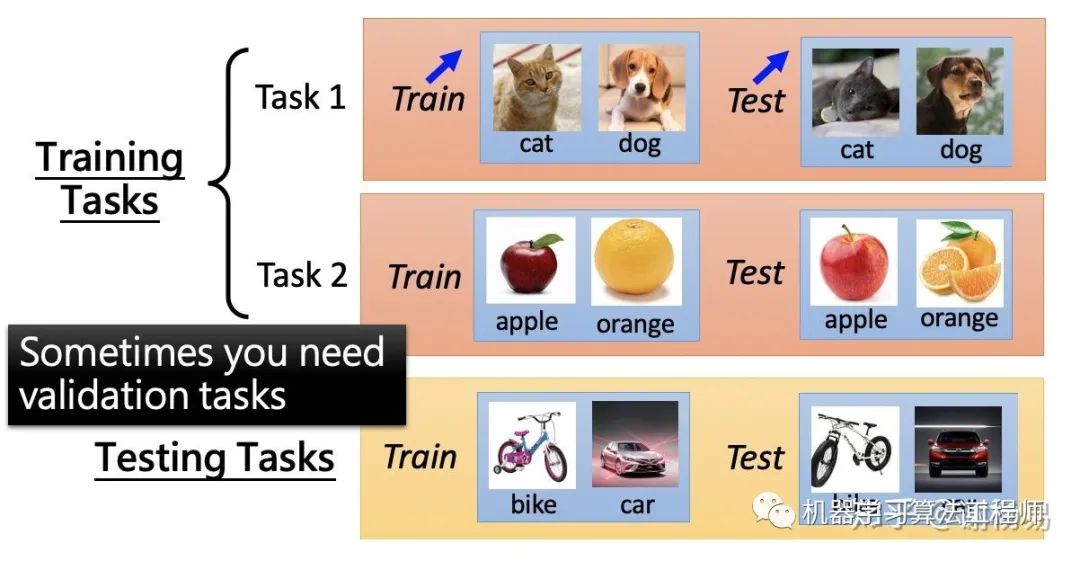
我們先通過task1學(xué)習(xí)到模型f1,并得到損失函數(shù)l1。然后再task2上學(xué)習(xí)模型f2,并得到l2。以此類推,得到所有task上的損失函數(shù)之和,即為meta learning的損失函數(shù)。如下
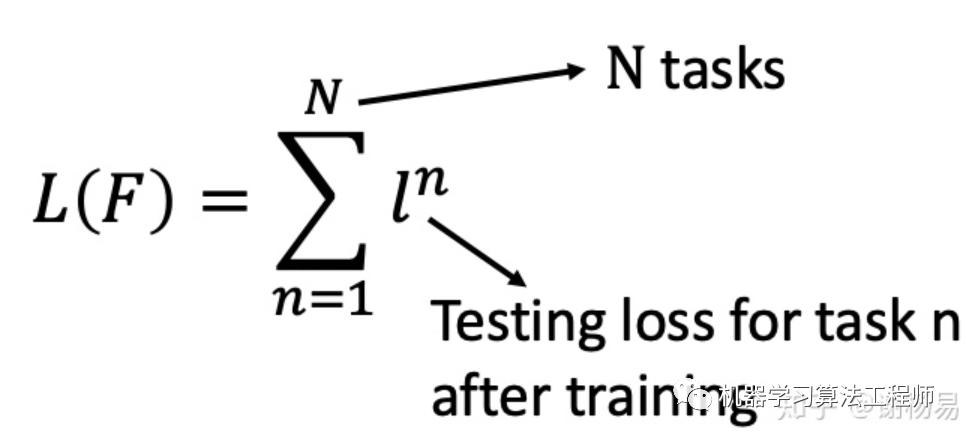
我們的目標(biāo)就是降低這個(gè)損失函數(shù) L(F)。
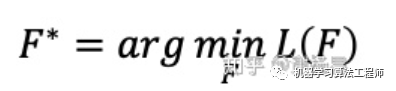

ICML 2017
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks。
MAML focus在學(xué)習(xí)模型初始化參數(shù)上,這和pretrain models的目標(biāo)是相同的。pretrain models通過有監(jiān)督或自監(jiān)督方式,先在數(shù)據(jù)集充足的任務(wù)A上訓(xùn)練模型,然后利用該模型的參數(shù)來初始化數(shù)據(jù)量比較少的任務(wù)B。通過遷移學(xué)習(xí)的方式,讓數(shù)據(jù)量比較少的任務(wù),也能夠train起來。meta learning和pretrain models雖然都可以幫助模型參數(shù)初始化,但二者差別還是很大的
pretrain model的任務(wù)A,一般來說數(shù)據(jù)量比較充足,否則自己都沒法train起來,也就無法得到一個(gè)不錯(cuò)的初始化參數(shù)
pretrain model的初始化參數(shù),重在當(dāng)前任務(wù)A上表現(xiàn)好,可能在任務(wù)B上不一定好。meta learning則利用初始化參數(shù),在各任務(wù)上繼續(xù)訓(xùn)練后,效果都不錯(cuò)。它重在模型的潛力

MAML loss function如下
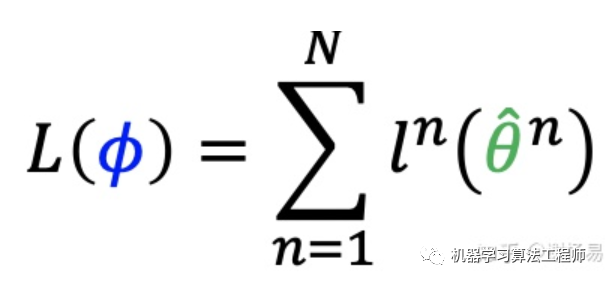
所有task的testing set上的loss之和,即為MAML的Loss,我們需要最小化這個(gè)loss。通過gradient descent的方法就可以實(shí)現(xiàn)。
MAML的創(chuàng)新點(diǎn)在于,訓(xùn)練模型時(shí),在單個(gè)任務(wù)task中,模型參數(shù)只更新一次。李宏毅老師認(rèn)為主要原因是
MAML希望模型具有單個(gè)task上,參數(shù)只更新一次,就可以得到不錯(cuò)初始化參數(shù)的能力
meta learning的數(shù)據(jù)集一般都是few shot的,否則很多task,訓(xùn)練耗時(shí)會(huì)很高。而few shot場(chǎng)景下,一般模型參數(shù)也更新不了幾次
雖然在訓(xùn)練模型時(shí)只更新一次初始化參數(shù),但在task test時(shí),是可以更新多次參數(shù),讓模型充分訓(xùn)練的
meta learning一般會(huì)包括很多個(gè)task,單個(gè)task上只更新一次,可以保證學(xué)習(xí)效率。
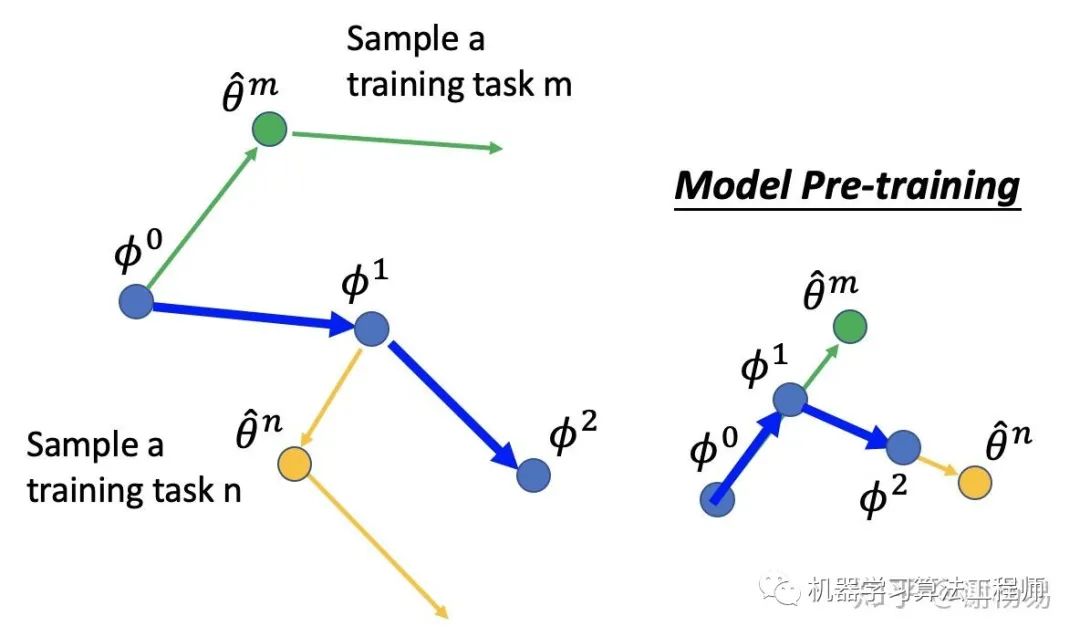
MAML更新參數(shù)的過程如下所示
初始化meta learning參數(shù)φ0
由φ0梯度下降一次,更新得到θm
在task m上更新一次參數(shù)
通過第二次θ的方向,確定φ的更新方向,得到φ1。
而對(duì)于model pretrain,其φ和θ的更新始終保持一致。

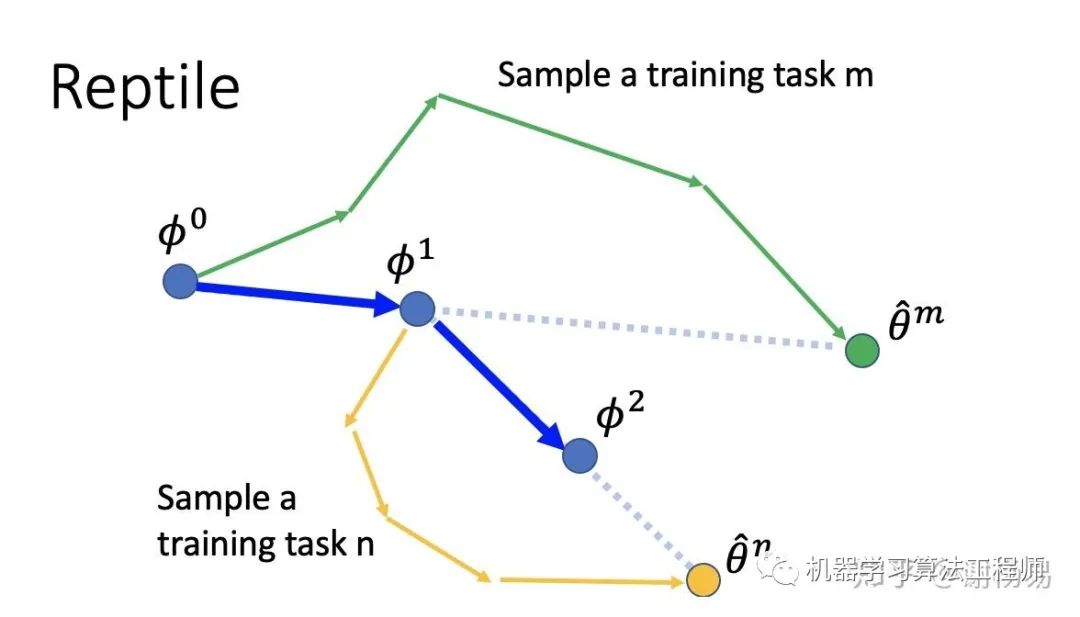
openAI,2018,On First-Order Meta-Learning Algorithms
Reptile和MAML一樣,也是focus在模型參數(shù)初始化上。故loss function也基本相同。不同之處是,它結(jié)合了pretrain model和MAML的特點(diǎn),在模型參數(shù)更新上有所不同。Reptile也是先初始化參數(shù)φ0,然后采樣出任務(wù)m,更新多次(而不是MAML的單次),得到一個(gè)不錯(cuò)的參數(shù)θm。利用θm的方向來更新φ0到φ1。同樣的方法更新到φ2
好消息,小白學(xué)視覺團(tuán)隊(duì)的知識(shí)星球開通啦,為了感謝大家的支持與厚愛,團(tuán)隊(duì)決定將價(jià)值149元的知識(shí)星球現(xiàn)時(shí)免費(fèi)加入。各位小伙伴們要抓住機(jī)會(huì)哦!

交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請(qǐng)按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~