
詳解目標檢測之Neck選擇

極市導讀
?Neck是目標檢測框架中承上啟下的關鍵環(huán)節(jié)。它對Backbone提取到的重要特征,進行再加工及合理利用,有利于下一步head的具體任務學習。本文按照Neck的六種分類順序對主流Neck進行階段性總結。>>加入極市CV技術交流群,走在計算機視覺的最前沿
Neck是目標檢測框架中承上啟下的關鍵環(huán)節(jié)。它對Backbone提取到的重要特征,進行再加工及合理利用,有利于下一步head的具體任務學習,如分類、回歸、keypoint、instance mask等常見的任務。本文將對主流Neck進行階段性總結。
總體概要:
根據(jù)它們各自的論文創(chuàng)新點,大體上分為六種,這些方法當然可以同時屬于多個類別。
上下采樣:SSD (https://arxiv.org/abs/1512.02325) (ECCV 2016) STDN(https://openaccess.thecvf.com/content_cvpr_2018/html/Zhou_Scale-Transferrable_Object_Detection_CVPR_2018_paper.html) (CVPR 2018) 路徑聚合:DSSD(https://arxiv.org/abs/1701.06659) (Arxiv 2017), FPN(https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.html) (CVPR 2017), PANet(https://openaccess.thecvf.com/content_cvpr_2018/html/Liu_Path_Aggregation_Network_CVPR_2018_paper.html) (CVPR 2018), Bi-FPN(https://openaccess.thecvf.com/content_CVPR_2020/html/Tan_EfficientDet_Scalable_and_Efficient_Object_Detection_CVPR_2020_paper.html) (CVPR 2020), NETNet(https://openaccess.thecvf.com/content_CVPR_2020/html/Li_NETNet_Neighbor_Erasing_and_Transferring_Network_for_Better_Single_Shot_CVPR_2020_paper.html) (CVPR 2020) NAS搜索:NAS-FPN(https://openaccess.thecvf.com/content_CVPR_2019/html/Ghiasi_NAS-FPN_Learning_Scalable_Feature_Pyramid_Architecture_for_Object_Detection_CVPR_2019_paper.html) (CVPR 2019) 加權聚合:ASFF(https://arxiv.org/abs/1911.09516) (Arxiv 2019), Bi-FPN 非線性聚合:Feature Reconfiguration(https://openaccess.thecvf.com/content_ECCV_2018/html/Tao_Kong_Deep_Feature_Pyramid_ECCV_2018_paper.html) (ECCV2018, TIP 2019) 無限堆疊:i-FPN(https://arxiv.org/abs/2012.13563) (Arxiv 2020)
上下采樣
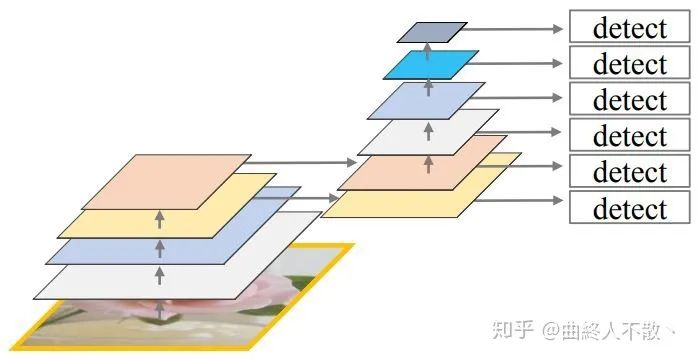
該方法的特點是不具有特征層聚合性的操作,如SSD,直接在多級特征圖后接head。
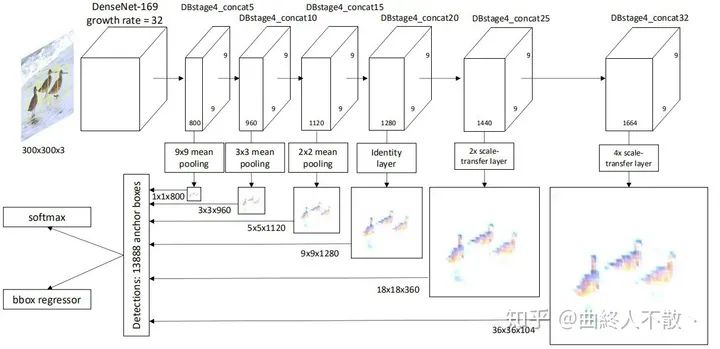
STDN是基于SSD的模型,其思想是構造法。由于STDN使用了DenseNet作為主干,因此后面的特征圖在尺寸上是相同的,所以需要構造出各種大小的特征圖來檢測不同大小的物體。中間尺寸特征圖直接使用,大尺寸特征圖以尺寸變換層上采樣獲得,小尺寸特征圖以池化獲得。
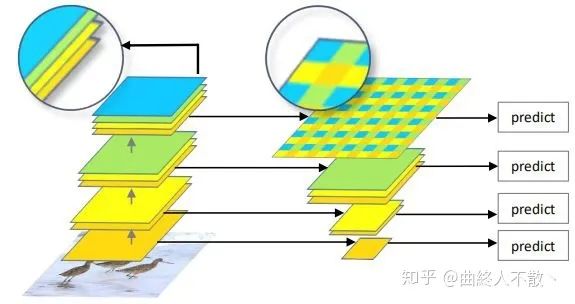
路徑聚合
該方法基于一個最基本的觀察:深層特征圖尺寸小,經過層層卷積下采樣使得小物體的信息嚴重丟失,所以深層不利于小物體檢測,就將小物體檢測交給淺層來做。這也是為什么SSD需要多級head的原因。
然而光是這樣還不夠,由于深層特征圖具有非常豐富的語義信息,那么最好把深層特征再往淺層傳,以增加淺層語義信息。于是乎就誕生了最為人所熟知的FPN。在如何上采樣方面,F(xiàn)PN使用最鄰近上采樣,當然還有使用反卷積的DSSD。
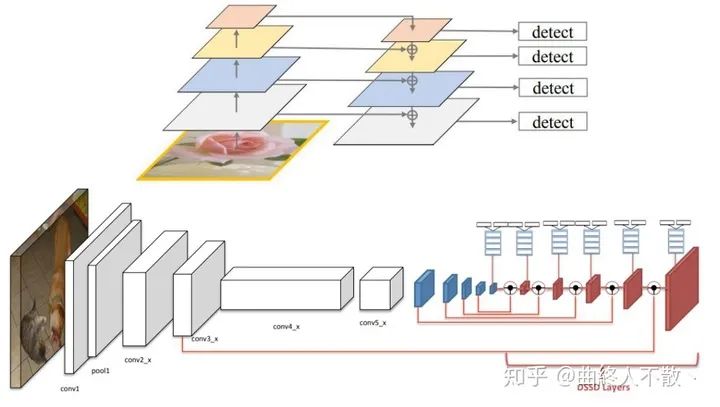
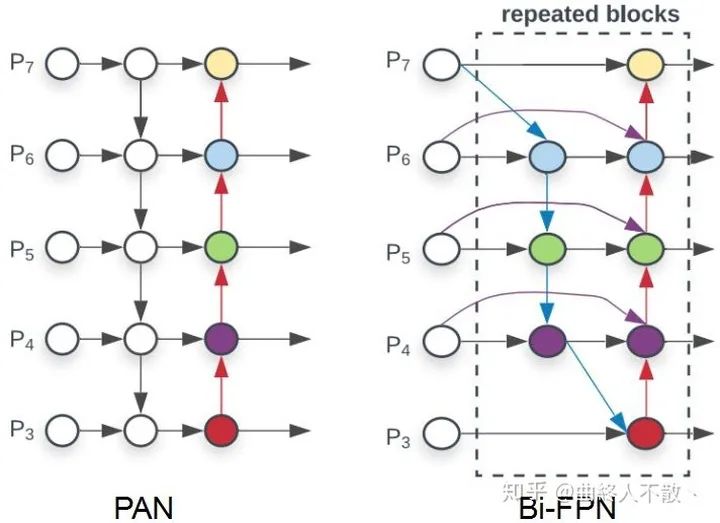
這類方法的共性就是反復利用各種上下采樣、拼接、點和或點積,來設計聚合策略。可改進的點還包括加上Deformable Conv、Attention、門控機制、跨FPN level的label assignment等,都已有文章。
比較特殊的還有一種名為NETNet (CVPR 2020)的方法,其認為上述路徑聚合方案無論怎么設計,對于預測小物體而言,大物體的特征一直存在,因為高層語義信息被傳了下來,再加上其本身淺層自帶的大物體特征,這對小物體來說會是一種干擾,如下圖所示。

因此需要人為地進行干預,為淺層消除大物體特征。
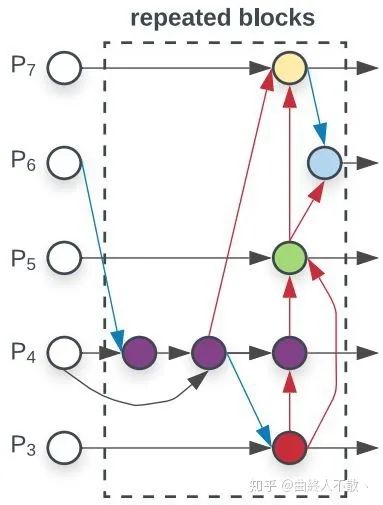
思路也很簡單,隨著下采樣的進行,小物體特征會丟失,那么深層必然已經都是大物體的特征。此時對深層上采樣,得到的還是大物體特征,再把原來的淺層減去經過上采樣的深層,于是淺層就不再有了大物體的特征。那么小物體的特征將被突出化。

同樣的,被消除的大物體特征也可以進一步被傳輸?shù)胶线m的層,以增強大物體的檢測。
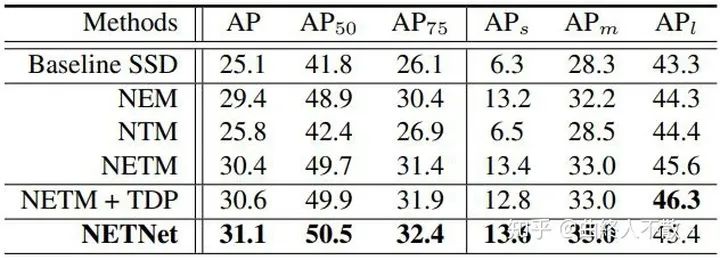
對小物體確實改進比較顯著,值得一試。
NAS搜索
即利用神經網(wǎng)絡搜索方法來搜索合適的聚合路徑,但是搜索的時間成本極高,且數(shù)學可解釋性低。最新的研究已表明,人工設計的路徑聚合在精度上亦可超過NAS搜索出來的結構 (大力出奇跡)。
加權聚合
顧名思義,簡單的聚合對所有參與的特征層都是一視同仁的,而實際上,這些來自不同層級的特征圖對于單個物體而言,必然只有某一個是最適合檢測它的。因此對聚合進行加權就顯得尤為重要。
ASFF引入了可參與訓練的加權因子來體現(xiàn)不同層級特征圖的重要性。
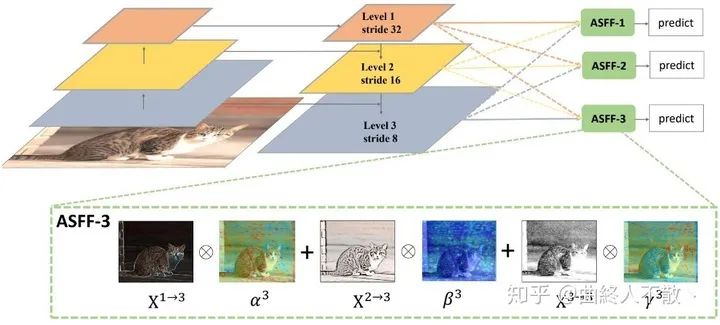
加權公式為? ,其中加權因子? 求和為1,即對所參與的特征圖先調整到同樣尺寸,然后對每個像素點進行加權。
Bi-FPN也有類似的操作,區(qū)別在于其簡單地使用標量進行加權,? ,并且在限制加權因子求和為1方面,使用快速歸一化,而非費時的Softmax操作。
非線性聚合
以上這些方法,都可以視為線性聚合操作。首先,讓我們用一些簡單符號來描述一下聚合過程。
給定特征金字塔的不同層特征圖? ,SSD會從某個層開始,選擇? 層后接head.
接下來以FPN為例,最高層? 聚合后仍然是它本身,所以? . 接下來是第二高層? ,它等于原來的? 與新的? 按照一定的方式進行聚合。最后完整的聚合可以表達為如下的過程:
這里的? 以及? 都是特定的線性操作,比如不帶有激活函數(shù)的卷積,? 卷積,雙線性插值上采樣,最鄰近上采樣,反卷積等。
因此FPN以及其他的路徑聚合法,都可視為是線性聚合。于是在《Deep Feature Pyramid Reconfiguration for Object Detection》一文中,作者建立了一種非線性聚合法。
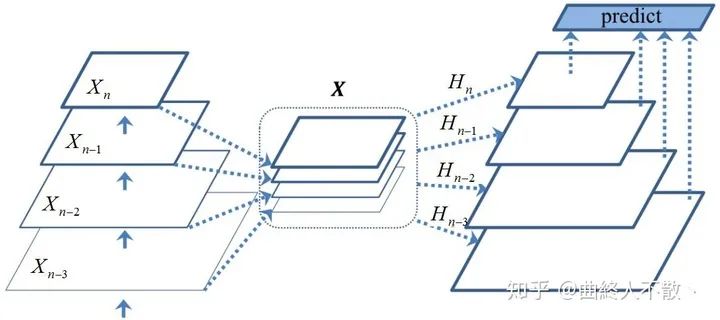
先把所有的層級特征圖放在一起,然后學習多個非線性映射? .
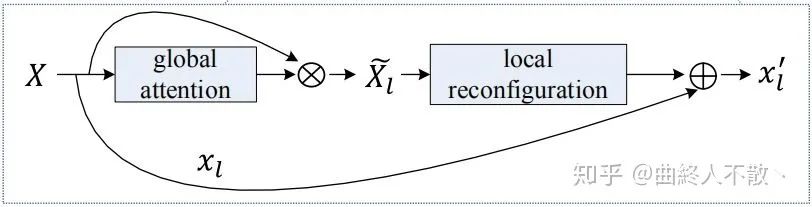
非線性映射的學習模仿SENet的方法,帶有注意力的味道。
無限堆疊
EfficientDet通過重復堆疊多個Bi-FPN block來獲得性能的提升。
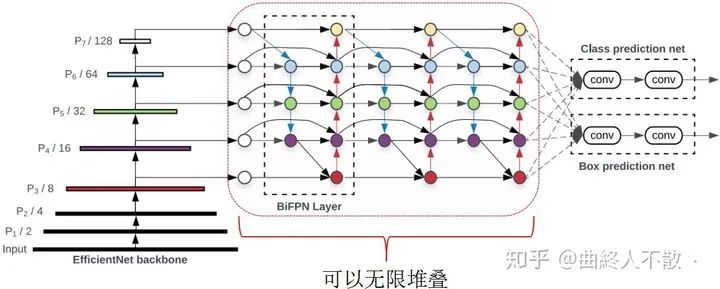
顯然這樣的操作會造成大量的計算開銷與顯存占用。
那么有沒有更好的方法呢?當然有,比如權重共享,即只使用一個FPN block,backbone提取到的特征圖會反復經過這個block,由于權重共享,顯存占用很少,參數(shù)量也少,但是計算量仍然隨著重復的次數(shù)而增加,因為每迭代一次,對該block的更新最終都需要增加一次反向傳播。
但是上述過程有一個有趣的現(xiàn)象,就是當重復計算的次數(shù)趨于無窮多次時,這個FPN block的參數(shù)會收斂到一個固定點,即特征平衡態(tài)。那么如何利用有限次前向傳播即可求解這樣的網(wǎng)絡參數(shù)固定點呢?就是《Deep Equilibrium Models》(曲終人不散丶)(NeurIPS 2019) 的厲害之處了。只要我們求得了該固定點,我們就直接得到了單個block重復前后向傳播無數(shù)次的結果。
下面把最精華的部分提取出來描述:
給定一個FPN block的網(wǎng)絡? ,? 是它的網(wǎng)絡參數(shù)點,backbone提取到的多級特征? , 以及一系列初始化的特征金字塔? ,上標為0表示還沒開始迭代。
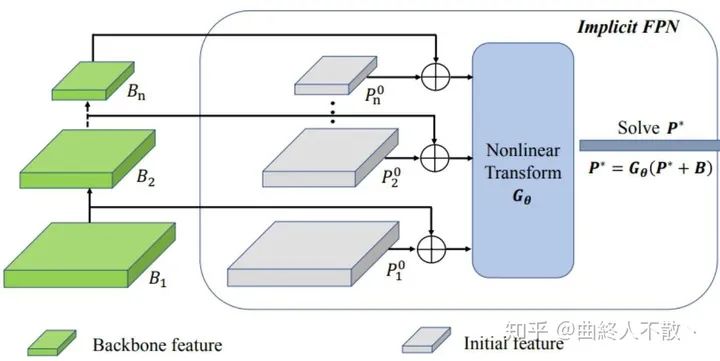
這個? 的選擇有多種,如FPN,PANet,Bi-FPN,Dense-FPN等,最終輸出的也是多級特征金字塔,每一級后面接head. 由于權重共享,上述過程重復多次,那么第? 次的輸出就是
于是當重復無窮多次時,多級特征圖收斂到固定值?
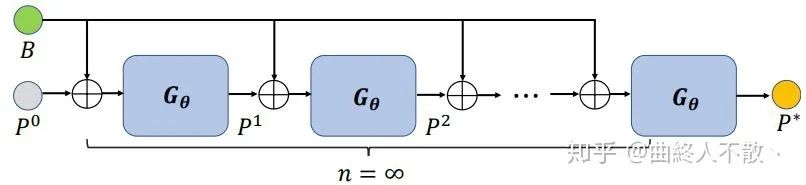
假如你選擇迭代10次,就會得到10次多級特征圖,依據(jù)鏈式求導法則,你就得更新10次這個block的網(wǎng)絡參數(shù)? ,這是極為耗時的,且增加了內存開銷,因為你需要存儲中間的每一次輸出。
現(xiàn)在事后諸葛亮一波,假如我已經迭代了1000次,可以認為此時的多級特征圖已經是收斂到固定點了,誤差很小。DEQ提出反向傳播一次就夠,即直接使用有關于這個固定點的雅克比的逆來反向傳播。即利用它可以直接對一個還沒開始迭代的block進行更新。
現(xiàn)在改寫一下,把優(yōu)化? 改為優(yōu)化? ,顯然這個固定點就是這個方程的根,即 .
那么如何求這個固定點? ?你可以采用擬牛頓法,或者任何其他的求根法,通過多次迭代,得到滿足給定誤差以內的近似的? .
然后再使用? 來反向傳播,一次解決所有梯度回傳。
i-FPN的思想就源于此,《Implicit Feature Pyramid Network for Object Detection》一文將其應用至目標檢測的Neck中。作者以Dense-FPN為基礎。
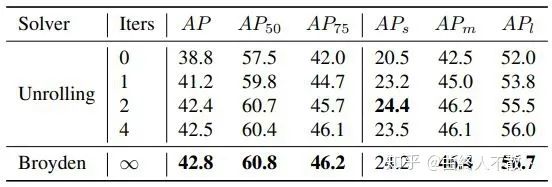
可以看到i-FPN相比較于迭代4次權重共享的block的方法來說,可以獲得更好的性能。
就總結到這,如有錯誤,歡迎指正。
推薦閱讀
