
目標(biāo)檢測算法YOLO-V2詳解
?上期我們一起學(xué)習(xí)了
?YOLO-V1算法的框架原來和損失函數(shù)等知識,如下:
目標(biāo)檢測算法YOLO-V1算法詳解
目標(biāo)檢測模型YOLO-V1損失函數(shù)詳解
【文末領(lǐng)福利】
今天,我們一起學(xué)習(xí)下YOLO-V2跟YOLO-V1比起來都做了哪些改進?從速度優(yōu)化和精確度優(yōu)化的角度來看,主要有以下內(nèi)容:
Darknet-19結(jié)構(gòu)YOLO-v2結(jié)構(gòu)高精度分類器 Anchor卷積維度聚類 直接位置預(yù)測 細(xì)粒度特征 多尺度訓(xùn)練 YOLO-v2性能
針對YOLO-V1準(zhǔn)確率不高,容易漏檢,對長寬比不常見物體效果差等問題,結(jié)合SSD的特點,提出了YOLO-V2算法。改算法從速度和精度上做了一些改進措施,我們一起看下都有哪些優(yōu)化?微信公眾號[智能算法]回復(fù)關(guān)鍵字“1002”,即可下載YOLOV2論文。
YOLO-V2速度優(yōu)化
大多數(shù)檢測網(wǎng)絡(luò)依賴于VGG-16作為特征提取網(wǎng)絡(luò),VGG-16是一個強大而準(zhǔn)確的分類網(wǎng)絡(luò),但是過于復(fù)雜。比如一張224x224的圖片進行一次前向傳播,其卷積層就需要多達306.9億次浮點數(shù)運算。YOLO-V1使用使用的是基于GoogLeNet的自定制的網(wǎng)絡(luò),比VGG-16更快,一次前向傳播需要85.2億次運算,不過它的精度要略低于VGG-16。
在YOLO-V2中,使用的是Darknet-19的網(wǎng)絡(luò),該網(wǎng)絡(luò)一次前向傳播僅需要55.8億次運算,我們先來看下Darknet-19模型的網(wǎng)絡(luò)框架:
Darknet-19結(jié)構(gòu)
Darknet-19顧名思義,有19個卷積層,如下圖:
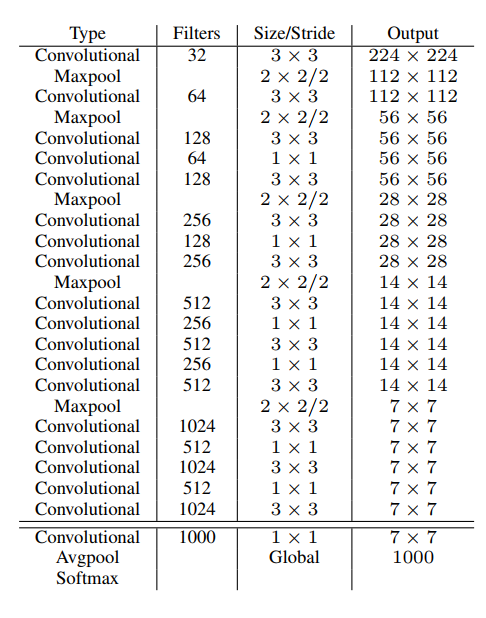
網(wǎng)絡(luò)很簡單,大致連接如下:
首先輸入圖像大小為 224x224x3,經(jīng)過3x3x32的卷積層以及池化后得到112x112x32的特征圖;接著經(jīng)過 3x3x64的卷積層以及池化后得到56x56x64的特征圖;接著依次經(jīng)過 3x3x128,1x1x64,3x3x128的卷積層以及池化后得到28x28x128的特征圖;接著依次 3x3x256,1x1x128,3x3x256的卷積層和最大化池化后得到14x14x256的特征圖;接著依次經(jīng)過 3x3x512,1x1x256,3x3x512,1x1x256,3x3x512和最大化池化后得到7x7x512的特征圖;接著再一次通過 3x3x1024,1x1x512,3x3x1024,1x1x512,3x3x1024的卷積層后得到7x7x1024的特征圖;最后經(jīng)過一個 1x1x1000的卷積層,均值池化層得到1000個結(jié)果再經(jīng)過softmax輸出。
YOLO-v2結(jié)構(gòu)
既然YOLO-V2的主框架是基于Darknet-19搭建的,我們來看下YOLO-V2的結(jié)構(gòu),如下圖:
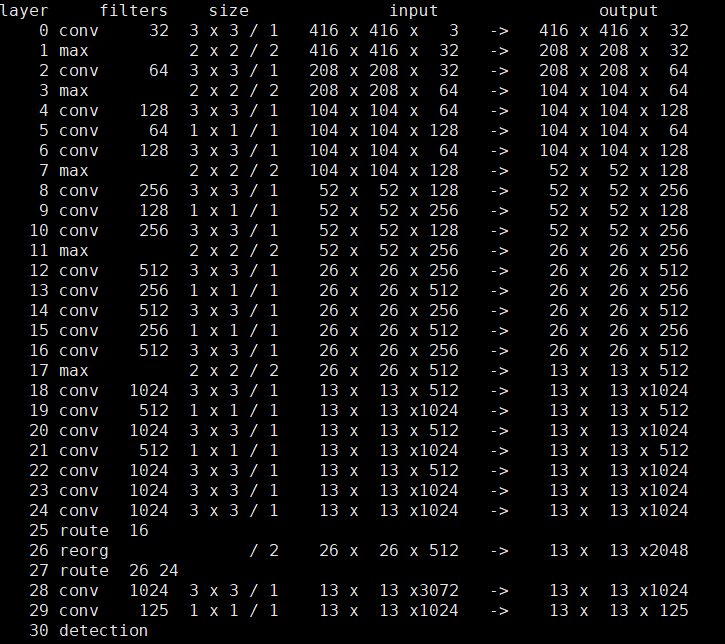
其中上圖中的輸入大小為416x416x3,其他的0-24層跟上面學(xué)的Darknet-19是一樣的。我們來從第25層看一下后面的那幾層啥意思:
第 25層的route 16的意思是將第16層中的數(shù)據(jù)取過來做第26層的處理。第 26層對第16層的數(shù)據(jù)做了一個reorganization的處理,將26x26x512的數(shù)據(jù)轉(zhuǎn)化為13x13x2048的特征圖;第 27層將第26層和24層的數(shù)據(jù)拿過來堆放到一起,給第28層處理;第 28層做了一個3x3x1024的卷積,將特征圖大小變?yōu)?code style="overflow-wrap: break-word;margin-right: 2px;margin-left: 2px;font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(53, 148, 247);background: rgba(59, 170, 250, 0.1);padding-right: 2px;padding-left: 2px;border-radius: 2px;height: 21px;line-height: 22px;">13x13x1024;第 29層最終經(jīng)過一個1x1x125的卷積層,將特征圖變?yōu)?code style="overflow-wrap: break-word;margin-right: 2px;margin-left: 2px;font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(53, 148, 247);background: rgba(59, 170, 250, 0.1);padding-right: 2px;padding-left: 2px;border-radius: 2px;height: 21px;line-height: 22px;">13x13x125,最后得到檢測結(jié)果。
到這里應(yīng)該有一些疑問,什么是reorganization處理?以及為什么最后是13x13x125的尺寸?這里簡單的說下reorganization處理,reorganization處理就是硬性的對數(shù)據(jù)進行重組,比如將一個2x2的矩陣重組成1x4,重組前后元素總個數(shù)不變,但是尺寸變化。上面的就是對26x26x512的數(shù)據(jù)進行了重組為13x13x2048大小。那么最后的尺寸為什么是13x13x125,這個下面再講好理解些。框架上大致優(yōu)化就這些,我們接著看以下精確度上如何優(yōu)化。
YOLO-V2精確度優(yōu)化
為了得到更好的精確度,YOLO-V2主要做從這幾方面做了優(yōu)化:高精度分類器,Anchor卷積,維度聚類,直接位置預(yù)測,細(xì)粒度特征,多尺度訓(xùn)練。我們一個一個看:
高精度分類器
在YOLO-V1中,網(wǎng)絡(luò)訓(xùn)練的分辨率是224x224,檢測的時候?qū)⒎直媛侍嵘?code style="overflow-wrap: break-word;margin-right: 2px;margin-left: 2px;font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(53, 148, 247);background: rgba(59, 170, 250, 0.1);padding-right: 2px;padding-left: 2px;border-radius: 2px;height: 21px;line-height: 22px;">448x448。而YOLO-V2直接修改了預(yù)訓(xùn)練分類網(wǎng)絡(luò)的分辨率為448x448,在ImageNet數(shù)據(jù)集上訓(xùn)練10個周期(10 epochs)。這個過程讓網(wǎng)絡(luò)有足夠的時間去適應(yīng)高分辨率的輸入,然后再fine tune檢測網(wǎng)絡(luò),mAP獲得了4%的提升。
Anchor卷積
在YOLO-V1中使用全連接層進行bounding box預(yù)測,這會丟失較多的空間信息,導(dǎo)致定位不準(zhǔn)。YOLO-V2借鑒了Faster RCNN中anchor的思想,我們知道Faster RCNN中的anchor就是在卷積特征圖上進行滑窗采樣,每個中心預(yù)測9個不同大小和比例的anchor。
總的來說YOLO-V2移除了全連接層(以獲得更多的空間信息)使用anchor boxes去預(yù)測bounding boxes。并且YOLO-V2中的anchor box可以同時預(yù)測類別和坐標(biāo)。具體做法如下:
跟 YOLO-V1比起來,去掉最后的池化層,確保輸出的卷積特征圖有更高的分辨率。縮減網(wǎng)絡(luò),讓圖片的輸入分辨率為 416x416,目的是讓后面產(chǎn)生的卷積特征圖寬高都為奇數(shù),這樣就可以產(chǎn)生一個center cell。因為大物體通常占據(jù)了圖像的中間位置,可以只用一個中心的cell來預(yù)測這些物體的位置,否則就要用中間的4個cell來進行預(yù)測,這個技巧可稍稍提升效率。使用卷積層降采樣( factor=32),使得輸入卷積網(wǎng)絡(luò)的416x416的圖片最終得到13x13的卷積特征圖(416/32=13)。由 anchor box同時預(yù)測類別和坐標(biāo)。因為YOLO-V1是由每個cell來負(fù)責(zé)預(yù)測類別的,每個cell對應(yīng)的兩個bounding box負(fù)責(zé)預(yù)測坐標(biāo)。YOLO-V2中不再讓類別的預(yù)測與每個cell綁定一起,而是全部都放到anchor box中去預(yù)測。
加入了anchor之后,我們來計算下,假設(shè)每個cell預(yù)測9個anchor,那么總計會有13x13x9=1521個boxes,而之前的網(wǎng)絡(luò)僅僅預(yù)測了7x7x2=98個boxes。具體每個網(wǎng)格對應(yīng)的輸出維度如下圖:
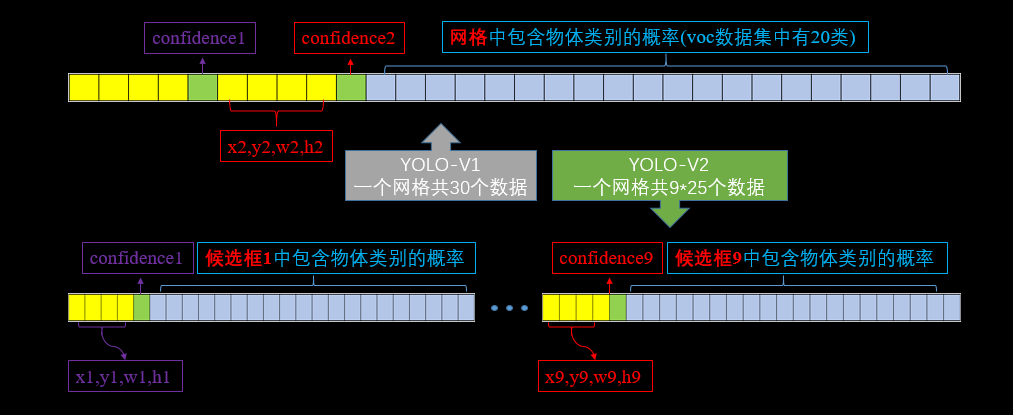
我們知道YOLO-V1輸出7x7x30的檢測結(jié)果,如上圖,其中每個網(wǎng)格輸出的30個數(shù)據(jù)包括兩個候選框的位置,有無包含物體的置信度,以及網(wǎng)格中包含物體類別的20個概率值。YOLO-V2對此做了些改進,將物體類別的預(yù)測任務(wù)交給了候選框,而不再是網(wǎng)格擔(dān)任了,那么假如是9個候選框,那么就會有9x25=225個數(shù)據(jù)的輸出維度,其中25為每個候選框的位置,有無物體的置信度以及20個物體類別的概率值。這樣的話,最后網(wǎng)絡(luò)輸出的檢測結(jié)果就應(yīng)該是13x13x225,但是上面網(wǎng)絡(luò)框架中是125,是怎么回事兒呢?我們接著看。
維度聚類
在使用anchor時,Faster RCNN中anchor boxes的個數(shù)和寬高維度往往是手動精選的先驗框(hand-picked priors),如果能夠一開始就選擇了更好的,更有代表性的先驗boxes維度,那么網(wǎng)絡(luò)就應(yīng)該更容易學(xué)到精準(zhǔn)的預(yù)測位置。YOLO-V2中利用K-means聚類方法,通過對數(shù)據(jù)集中的ground truth box做聚類,找到ground truth box的統(tǒng)計規(guī)律。以聚類個數(shù)k為anchor boxes個數(shù),以k個聚類中心box的寬高為anchor box的寬高。
關(guān)于K-means,我們之前也有講過如下:
基礎(chǔ)聚類算法:K-means算法
但是,如果按照標(biāo)準(zhǔn)的k-means使用歐式距離函數(shù),計算距離的時候,大boxes比小boxes產(chǎn)生更多的error。但是,我們真正想要的是產(chǎn)生好的IoU得分的boxes(與box大小無關(guān)),因此采用了如下距離度量方式:
假設(shè)有兩個框,一個是3x5,一個框是5x5,那么歐式距離計算為:
IoU的計算如下,為了統(tǒng)計寬高聚類,這里默認(rèn)中心點是重疊的:
這里,為了得到較好的聚類個數(shù),算法里做了組測試,如下圖,隨著k的增大IoU也在增大,但是復(fù)雜度也在增加。

所以平衡復(fù)雜度和IoU之后,最終得到k值為5.可以從右邊的聚類結(jié)果上看到5個聚類中心的寬高與手動精選的boxes是完全不同的,扁長的框較少,瘦高的框較多(黑絲框?qū)?yīng)VOC2007數(shù)據(jù)集,紫色框?qū)?yīng)COCO數(shù)據(jù)集)。?這樣就能明白為什么上面網(wǎng)絡(luò)框架中的輸出為什么是13x13x125了,因為通過聚類選用了5個anchor。
直接位置預(yù)測
上面學(xué)習(xí),我們知道這里用到了類似Faster RCNN中的anchor,但是使用anchor boxes有一個問題,就是會使得模型不穩(wěn)定,尤其是早期迭代的時候。大部分的不穩(wěn)定現(xiàn)象出現(xiàn)在預(yù)測box的中心坐標(biāo)時,所以YOLO-V2沒有用Faster RCNN的預(yù)測方式。
YOLO-V2位置預(yù)測,就是預(yù)測邊界框中心點相對于對應(yīng)cell左上角位置的相對偏移值,為了將邊界框中心點約束在當(dāng)前cell中,使用了sigmoid函數(shù)處理偏移值,這樣預(yù)測的偏移值就在(0,1)范圍內(nèi)了(每個cell的尺度看作1)。
我們具體來看以下這個預(yù)測框是怎么產(chǎn)生的?
在網(wǎng)格特征圖(13x13)的每個cell上預(yù)測5個anchor,每一個anchor預(yù)測5個值:,,,,。如果這個cell距離圖像左上角的邊距為(,),cell對應(yīng)的先驗框(anchor)的長和寬分別為(,),那么網(wǎng)格預(yù)測框為下圖藍(lán)框。如下圖:

總的來說,虛線框為anchor box就是通過先驗聚類方法產(chǎn)生的框,而藍(lán)色的為調(diào)整后的預(yù)測框。算法通過使用維度聚類和直接位置預(yù)測這亮相anchor boxes的改進方法,將mAP提高了5%。接下來,我們繼續(xù)看下還有哪些優(yōu)化?
細(xì)粒度特征
我們前面學(xué)過SSD通過不同Scale的Feature Map來預(yù)測Box,實現(xiàn)多尺度,如下:
目標(biāo)檢測算法SSD結(jié)構(gòu)詳解
而YOLO-V2則采用了另一種思路:通過添加一個passthrough layer,來獲取之前的26x26x512的特征圖特征,也就是前面框架圖中的第25步。對于26x26x512的特征圖,經(jīng)過重組之后變成了13x13x2048個新的特征圖(特征圖大小降低4倍,而channels增加4倍),這樣就可以與后面的13x13x1024特征圖連接在一起形成13x13x3072大小的特征圖,然后再在此特征圖的基礎(chǔ)上卷積做預(yù)測。如下圖:
YOLO-V2算法使用經(jīng)過擴展后的特征圖,利用了之前層的特征,使得模型的性能獲得了1%的提升。
多尺度訓(xùn)練
原始的YOLO網(wǎng)絡(luò)使用固定的448x448的圖片作為輸入,加入anchor boxes后輸入變成了416x416,由于網(wǎng)絡(luò)只用到了卷積層和池化層,就可以進行動態(tài)調(diào)整,檢測任意大小的圖片。為了讓YOLO-V2對不同尺寸圖片具有魯棒性,在訓(xùn)練的時候也考慮到了這一點。
不同于固定網(wǎng)絡(luò)輸入圖片尺寸的方法,沒經(jīng)過10批訓(xùn)練(10 batches)就會隨機選擇新的圖片尺寸。網(wǎng)絡(luò)使用的降采樣參數(shù)為32,于是使用32的倍數(shù){320,352,...,608},最小尺寸為320x320,最大尺寸為608x608。調(diào)整網(wǎng)絡(luò)到相應(yīng)維度然后繼續(xù)訓(xùn)練。這樣只需要調(diào)整最后一個卷積層的大小即可,如下圖:
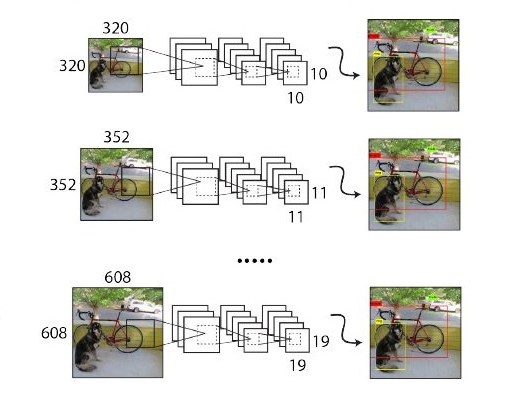
這種機制使得網(wǎng)絡(luò)可以更好地預(yù)測不同尺寸的圖片,同一個網(wǎng)格可以進行不同分辨率的檢測任務(wù),在小尺寸圖片上YOLO-V2運行更快,在速度和精度上達到了平衡。
YOLOV2性能
對于YOLO-V2的性能,直接看下YOLOV2和其他常見的框架在pascal voc2007數(shù)據(jù)集上測試結(jié)果性能比對表,如下表:
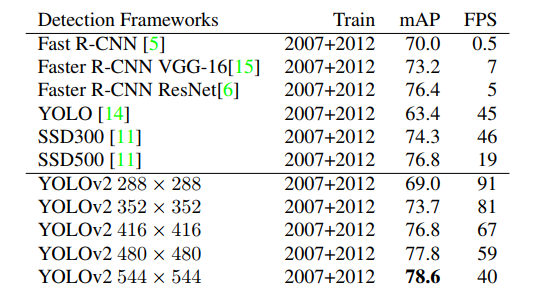
首先可以看到隨著訓(xùn)練尺寸的尺寸變大,YOLOv2算法的mAP是逐漸上升的,FPS相應(yīng)的逐漸下降。在554x554尺寸上的訓(xùn)練mAP達到78.6,從下面的性能分布圖圖中也可以看到YOLOV2算法的性能相對來說是挺不錯的。
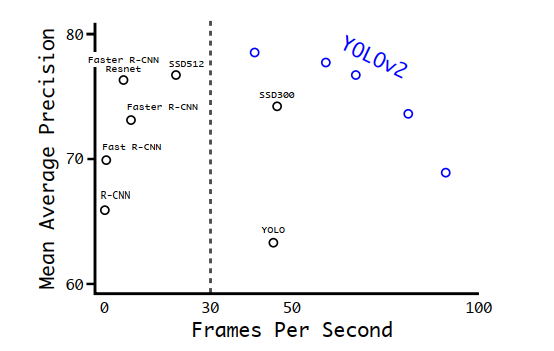
其中YOLOv2的五個藍(lán)色圈圈代表上面表中的五個不同尺寸的結(jié)果。
好了,至此,我們從Darknet-19結(jié)構(gòu),YOLO-v2結(jié)構(gòu),高精度分類器,Anchor卷積,維度聚類,直接位置預(yù)測,細(xì)粒度特征,多尺度訓(xùn)練以及性能方面一起學(xué)習(xí)了YOLO-V2相比與YOLO-V1做了哪些改進。下一期,我們將一起學(xué)習(xí)YOLO-V3的算法框架。
添加作者微信,備注“2020nn”領(lǐng)取:2020最新版《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》中文版及課件。
?轉(zhuǎn)發(fā)在看也是一種支持?