
一文搞懂戴克斯特拉算法-dijkstra
大學(xué)學(xué)習(xí)數(shù)據(jù)結(jié)構(gòu)那會(huì),當(dāng)時(shí)記得終于把 dijkstra 算法搞明白了,但是今天碰到的時(shí)候,大腦又是一片空白,于是我就又學(xué)習(xí)了下,把自己的理解寫(xiě)下來(lái),希望你也可以通過(guò)本文搞懂 dijkstra 算法。
dijkstra 的起源
dijkstra 已經(jīng) 62 歲了,是由荷蘭計(jì)算機(jī)科學(xué)家艾茲赫爾·戴克斯特拉在 1956 年制造,并于 3 年后在期刊上發(fā)表,在 2001 年的采訪(fǎng)中[1]他說(shuō)到:從鹿特丹到格羅寧根的最短路徑是什么?實(shí)際上,這就是對(duì)于任意兩座城市之間的最短路問(wèn)題。解決這個(gè)問(wèn)題實(shí)際上大概只花了我 20 分鐘:一天早上,我和我的未婚妻在阿姆斯特丹購(gòu)物,累了,我們便坐在咖啡館的露臺(tái)上喝咖啡,然后我就試了一下能否用一個(gè)算法解決最短路問(wèn)題。正如我所說(shuō),這是一個(gè) 20 分鐘的發(fā)現(xiàn)。不過(guò)實(shí)際上,我在 3 年后的 1959 年才把這個(gè)算法發(fā)表在論文上。即使現(xiàn)在來(lái)看這篇論文的可讀性也非常高,這個(gè)算法之所以如此優(yōu)雅,其中一個(gè)原因就是我沒(méi)用筆紙就設(shè)計(jì)了它。后來(lái)我才知道,沒(méi)用筆紙?jiān)O(shè)計(jì)的優(yōu)點(diǎn)之一是你不得不避免所有可避免的復(fù)雜問(wèn)題。令我驚訝的是,這個(gè)算法最終成為我成名的基石之一。"
dijkstra 解決什么問(wèn)題
主要解決帶權(quán)圖的最短路徑問(wèn)題,如果圖中的頂點(diǎn)表示城市,而邊上的權(quán)重表示城市間開(kāi)車(chē)行經(jīng)的距離,該算法可以用來(lái)找到兩個(gè)城市之間的最短路徑。dijkstra 算法使用類(lèi)似廣度優(yōu)先搜索的方法解決賦權(quán)圖的單源最短路徑問(wèn)題。
廣度優(yōu)先搜索,這個(gè)應(yīng)該很形象,記得在算法實(shí)現(xiàn)的時(shí)候使用隊(duì)列就可以了。賦權(quán)圖也好理解,就是邊上有權(quán)重值,可以理解為兩點(diǎn)之間的距離,單源最短路徑,就是一個(gè)已知的點(diǎn)到其他所有點(diǎn)的最短路徑。
當(dāng)然了,單源最短路徑算法也不是只有 dijkstra,還有 Bellman-ford 算法或者 SPFA 算法,在邊權(quán)非負(fù)時(shí)適合使用 Dijkstra 算法,若邊權(quán)為負(fù)時(shí)則適合使用 Bellman-ford 算法或者 SPFA 算法。今天只聊 dijkstra。
dijkstra 算法思路
咱直接說(shuō)優(yōu)化后的思路,其實(shí)就是用到了小頂堆(優(yōu)先級(jí)隊(duì)列)來(lái)比較哪一個(gè)點(diǎn)的距離最近,關(guān)于堆排序,可以參考堆的實(shí)現(xiàn)及工程應(yīng)用。
從起點(diǎn) s 開(kāi)始,將與起點(diǎn) s 直接相連的點(diǎn),根據(jù)它與起點(diǎn) s 的距離,加入到小頂堆中,堆頂那個(gè)點(diǎn) s1 與起點(diǎn) s 的距離 d1 一定是最近的,取出堆頂?shù)狞c(diǎn) s1 ,然后把與 s1 直接相連的點(diǎn),根據(jù)它與 s 的距離(d1 + s1到這個(gè)點(diǎn)的距離),加入到小頂堆中,堆頂那個(gè)點(diǎn) s2 與起點(diǎn)的距離就是最小的。
每次取出堆頂元素的時(shí)候,這個(gè)堆頂就是已確認(rèn)的最近距離的點(diǎn),把它加入已訪(fǎng)問(wèn)的集合中,防止無(wú)向圖的重復(fù)計(jì)算,這樣直到遍歷完所有頂點(diǎn),就找出了起點(diǎn)到所有點(diǎn)的最小距離。
是不是很簡(jiǎn)單,就是廣度搜索,加上貪心的思想,先找出起點(diǎn) s 開(kāi)始直接相連的點(diǎn)(廣度搜索),然后找出與 s 第一個(gè)最近的點(diǎn)(貪心),從最近的點(diǎn)出發(fā),再次廣度,再次貪心,就可以找出距離起點(diǎn) s 第二個(gè)最近的點(diǎn),直到全部搜索完畢。
算法時(shí)間復(fù)雜度 O(E+Vlog(v)) ,E 是邊的數(shù)量,V 是定點(diǎn)的數(shù)量,Vlog(v) 其實(shí)就是堆排序的時(shí)間復(fù)雜度。
算法時(shí)間復(fù)雜度 O(E+V) 鄰接矩陣的空間復(fù)雜度。
如果還不理解的話(huà),多看幾遍下這個(gè)動(dòng)圖:
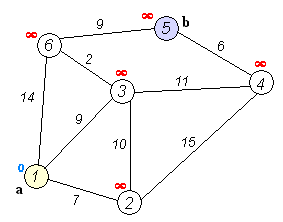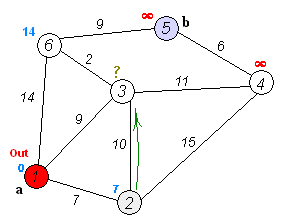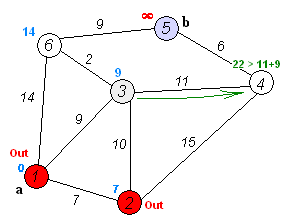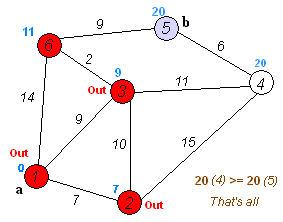
dijkstra 代碼實(shí)現(xiàn)(Python)
為了簡(jiǎn)化說(shuō)明,我們使用鄰接矩陣來(lái)表示一個(gè)圖,圖中有 n 個(gè)頂點(diǎn),標(biāo)記為 1,2,...n,現(xiàn)在要求解起點(diǎn) 1 到所有其他點(diǎn)的最小距離。
以終為始,先定義一個(gè)保存結(jié)果的最小距離的數(shù)組,cost[n] cost[i] 就是表示起點(diǎn) 1 到點(diǎn) i+1 的最小距離,cost[0] = 0,起點(diǎn) 1 到它本身的距離是 0。這里 i+1 是因?yàn)閿?shù)組下標(biāo)從 0 開(kāi)始。
假如有 6 個(gè)頂點(diǎn),使用鄰接矩陣來(lái)表示:
adjacency_matrix = [
[0, 7, 9, -1, -1, 14],
[7, 0, 10, 15, -1, -1],
[9, 10, 0, 11, -1, 2],
[-1, 15, 11, 0, 6, -1],
[-1, -1, -1, 6, 0, 9],
[14, -1, 2, -1, 9, 0]
]
adjacency_matrix[i][j] = c 意思就是點(diǎn) i+1 到 j+1 的成本是 c,加一的原因是數(shù)組的下標(biāo)從 0 開(kāi)始。
下面是我根據(jù)上述思路,實(shí)現(xiàn)的 dijkstra 算法,里面有注釋?zhuān)浑y看懂:
import sys
import heapq
max = sys.maxsize
vertices_number = 6
adjacency_matrix = [
[0, 7, 9, -1, -1, 14],
[7, 0, 10, 15, -1, -1],
[9, 10, 0, 11, -1, 2],
[-1, 15, 11, 0, 6, -1],
[-1, -1, -1, 6, 0, 9],
[14, -1, 2, -1, 9, 0],
]
cost = [max] * vertices_number
pq = [] # 優(yōu)先級(jí)隊(duì)列,最小堆
class Node(object):
def __init__(self, vertex, distance):
self.vertex = vertex
self.distance = distance
def __lt__(self, other):
"""
為了進(jìn)堆時(shí)比較大小,重寫(xiě) __lt__ 方法
"""
return self.distance < other.distance
def printpq(pq):
## debug 用,查看堆里面的數(shù)據(jù)
for item in pq:
print(item.vertex, item.distance, end="|")
print("")
def dijkstra(from_vertex, dest_vertex):
from_vertex = from_vertex - 1 # 轉(zhuǎn)換為列表的下標(biāo),因此減 1
dest_vertex = dest_vertex - 1
visited = set() # 定義已經(jīng)確定最小距離的點(diǎn),防止重復(fù)計(jì)算。
# 起點(diǎn)入隊(duì)
heapq.heappush(pq, Node(from_vertex, 0)) # 按照距離比較大小進(jìn)堆
while pq and len(visited) < vertices_number:
# printpq(pq)
# 出隊(duì)
node = heapq.heappop(pq)
from_vertex1 = node.vertex
distance1 = node.distance
if from_vertex1 in visited:
# 如果改點(diǎn)已經(jīng)確認(rèn)了最小距離,直接拋棄。
continue
# 更新距離,已經(jīng)確定時(shí)最小距離的點(diǎn)加入已訪(fǎng)問(wèn)集合。
print(from_vertex1)
cost[from_vertex1] = distance1
visited.add(from_vertex1)
# 取出 from_vertex1 的鄰居節(jié)點(diǎn),
for index, distance in enumerate(adjacency_matrix[from_vertex1]):
# 只選擇與 from_vertex1 連通的點(diǎn),也就是鄰居,排除已經(jīng)確定了最小值的點(diǎn)。
if distance > 0 and index not in visited:
heapq.heappush(pq, Node(index, distance + distance1))
return -1 if cost[dest_vertex] == max else cost[dest_vertex]
if __name__ == "__main__":
print(dijkstra(1, 5))
#其他點(diǎn)的最小距離均已經(jīng)計(jì)算得出:
print(cost)
# assert 20 == dijkstra(1, 5)
最后的話(huà)
純粹的記憶算法的實(shí)現(xiàn)其實(shí)沒(méi)有太大用處,算法最重要的是理解它的思路,以及學(xué)會(huì)靈活的運(yùn)用,比如說(shuō)從 A 到 B 中間最多經(jīng)過(guò) k 個(gè)節(jié)點(diǎn)的最小距離,你可以試著用 dijkstra 算法的思路來(lái)求解么?假如有負(fù)數(shù)的權(quán)值,怎么用 dijkstra 算法求解?
如果有問(wèn)題,請(qǐng)留言賜教。
都看到這里了,你不確定不關(guān)注一下嗎???
參考資料
在 2001 年的采訪(fǎng)中: https://zh.wikipedia.org/wiki/%E6%88%B4%E5%85%8B%E6%96%AF%E7%89%B9%E6%8B%89%E7%AE%97%E6%B3%95