
一文搞懂工程化協(xié)同推薦算法(三)

? ? ?作者:livan
? ? ?來(lái)源:數(shù)據(jù)EDTA
前言

經(jīng)過(guò)前面兩篇的文章:
一文搞懂工程化協(xié)同推薦算法(一)一文搞懂工程化協(xié)同推薦算法(二)
不知大家對(duì)推薦算法有沒(méi)有一個(gè)系統(tǒng)的了解,推薦本身的邏輯很簡(jiǎn)單,就是需要找到用戶(hù)喜歡的物品,然后呈現(xiàn)到用戶(hù)的面前,這其實(shí)像是一個(gè)算法與用戶(hù)的博弈,當(dāng)用戶(hù)到APP上的時(shí)候,留下一串足印,算法根據(jù)用戶(hù)的足印和基本信息推斷用戶(hù)來(lái)這里想要做什么?或者說(shuō)想要去什么地方?然后給他推薦他需要的東西。
推薦的基本結(jié)構(gòu)基本上可以分成兩類(lèi):
1) 基于協(xié)同理論的推薦算法:
????如上文,協(xié)同理論就是找到相似的用戶(hù)/物品或者相似的標(biāo)簽,然后根據(jù)交易歷史中用戶(hù)和物品的交互情況進(jìn)行推薦。算法在進(jìn)行過(guò)程中遇到各種問(wèn)題,程序員用各種方法來(lái)解決這些問(wèn)題,久而久之,延伸出了現(xiàn)在各種復(fù)雜的協(xié)同推薦模式。
常見(jiàn)的問(wèn)題有:
1.1)人工進(jìn)行特征工程的問(wèn)題:1.2)運(yùn)算量龐大的問(wèn)題:1.3)特征挖掘?qū)哟尾蛔愕膯?wèn)題:1.4)如何使用社交鏈的問(wèn)題:
2) 基于模型分類(lèi)的推薦算法:
????推薦從模型的角度理解可以看作是對(duì)用戶(hù)喜好的預(yù)測(cè),即為一個(gè)二分類(lèi)的預(yù)測(cè)模型,根據(jù)用戶(hù)的行為預(yù)測(cè)用戶(hù)對(duì)某個(gè)商品喜歡不喜歡,進(jìn)而根據(jù)喜好進(jìn)行推薦。
????基于模型的推薦比較多的應(yīng)用于點(diǎn)擊率預(yù)測(cè),用戶(hù)是否會(huì)購(gòu)買(mǎi)某個(gè)商品的預(yù)測(cè),在主流思路中依然是以協(xié)同為主。
????下面我們延續(xù)上文的討論,在上面常見(jiàn)問(wèn)題的基礎(chǔ)上深化我們對(duì)協(xié)同推薦的理解:
運(yùn)算量龐大的問(wèn)題
協(xié)同推薦的一個(gè)常見(jiàn)問(wèn)題就是運(yùn)算量的問(wèn)題,每一次的迭代需要對(duì)全部的用戶(hù)行為和商品信息進(jìn)行復(fù)盤(pán),計(jì)算出最新的相似系數(shù)。用戶(hù)和商品量少的情況下還好說(shuō),可如果用戶(hù)超過(guò)一億,商品有上百萬(wàn)個(gè)呢?這一情況下UV矩陣就會(huì)非常大,每運(yùn)算一次都需要耗費(fèi)很大的資源,而且數(shù)據(jù)存在較多的稀疏的問(wèn)題,幾百萬(wàn)的商品,大部分用戶(hù)點(diǎn)擊的只有十幾個(gè),剩下的部分全都是零,極大的浪費(fèi)運(yùn)算資源。
????所以,需要找尋一些方法來(lái)降低數(shù)據(jù)的運(yùn)算,即常說(shuō)的——降維。
????一提到降維這個(gè)詞,有沒(méi)有很熟悉,對(duì):很多人想到PCA、SVD等等常規(guī)的降維方法,在推薦算法中也有對(duì)應(yīng)的基于降維的推薦方式:
——基于矩陣分解的系統(tǒng)推薦:
基于矩陣的推薦算法是以SVD奇異值分解為基礎(chǔ)進(jìn)行的。
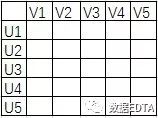
假設(shè)上圖為用戶(hù)的評(píng)分矩陣,經(jīng)過(guò)上文的講解,這個(gè)矩陣已經(jīng)非常熟悉了吧,我們假設(shè)他現(xiàn)在有一億行一億列,那該如何降維呢?
我們?cè)趯W(xué)習(xí)奇異值的時(shí)候,經(jīng)常會(huì)聽(tīng)到一句話(huà):前10%的奇異值之和占了全部奇異值之和的80%以上的比例。所以,我們只需要通過(guò)奇異值計(jì)算的方式找到前10%的奇異值k個(gè),計(jì)算他對(duì)應(yīng)的k個(gè)特征向量,即可大規(guī)模的降低上面UV矩陣的計(jì)算資源。
經(jīng)過(guò)SVD的運(yùn)算得到m*k的新的矩陣,我們就可以用這一矩陣替代UV矩陣進(jìn)行相似度計(jì)算了。
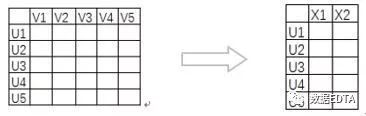
基于新的低階矩陣我們計(jì)算出用戶(hù)的相似度/物品相似度,然后再對(duì)相似用戶(hù)進(jìn)行推薦,計(jì)算效率大大的提升。
這樣運(yùn)算有兩個(gè)好處:其一:減輕了線(xiàn)上存儲(chǔ)和計(jì)算的壓力;其二:解決了矩陣稀疏的問(wèn)題;
也有一個(gè)壞處:
SVD是減輕了UV矩陣的運(yùn)算量,但是SVD自身的運(yùn)算呢?
????從一個(gè)矩陣拆分成三個(gè)矩陣,這本身就意味著巨大的運(yùn)算量,所以,在平時(shí)工作中很少使用SVD,而是使用隱語(yǔ)義模型,隱語(yǔ)義模型與SVD不同,他把矩陣拆分成了兩個(gè)矩陣。
——ALS模式下隱語(yǔ)義推薦算法:
ALS是交替最小二乘法,主要是用來(lái)優(yōu)化最小損失函數(shù)的。
即根據(jù)用戶(hù)評(píng)分矩陣A,用求最小損失函數(shù)的方法求解出兩個(gè)分解的參數(shù)矩陣:
K即為隱含的因子個(gè)數(shù)。對(duì)應(yīng)的損失函數(shù)為:
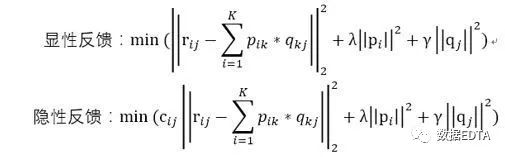
Cij即為用戶(hù)偏愛(ài)某個(gè)商品的置信程度,交互次數(shù)多的權(quán)重就會(huì)增加。
這里,協(xié)同過(guò)濾就成功轉(zhuǎn)化成了一個(gè)優(yōu)化問(wèn)題。通過(guò)ALS計(jì)算出用戶(hù)因子矩陣P和物品因子矩陣Q。雖然降低了運(yùn)算量,但是對(duì)于大數(shù)據(jù)集,還是推薦使用spark進(jìn)行計(jì)算。
ALS模式的優(yōu)點(diǎn)在于能夠有效的解決過(guò)擬合的問(wèn)題,同時(shí)對(duì)算法的可擴(kuò)展性也有所提高。
特征挖掘?qū)哟尾蛔愕膯?wèn)題
雖然說(shuō)矩陣分解的方法進(jìn)行相似性計(jì)算已經(jīng)非常成熟,但是,聰明的讀者也已經(jīng)發(fā)現(xiàn),矩陣分解只是針對(duì)矩陣進(jìn)行的一次運(yùn)算,對(duì)特征的挖掘?qū)哟蚊黠@不足,而且,矩陣也沒(méi)有用到用戶(hù)和物品本身的特性。
而深度學(xué)習(xí)中的稀疏自編碼模式可以有效的解決這兩個(gè)問(wèn)題:
——稀疏自編碼模式下的推薦算法:
稀疏自編碼是用神經(jīng)網(wǎng)絡(luò)的方式來(lái)壓縮原始物品的特征向量,使物品的相似度運(yùn)算能在較低緯度下進(jìn)行。
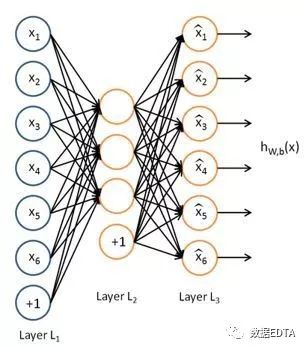
如圖所示即為稀疏自編碼的網(wǎng)絡(luò)結(jié)構(gòu),簡(jiǎn)單來(lái)講,稀疏自編碼就是一個(gè)hw,b(x) = x的函數(shù),設(shè)定神經(jīng)網(wǎng)絡(luò)的輸入值和輸出值都是x,中間多個(gè)隱含層的節(jié)點(diǎn)數(shù)量小于輸入和輸出層的節(jié)點(diǎn)數(shù)量(輸入和輸出層的節(jié)點(diǎn)數(shù)量一樣多),對(duì)網(wǎng)絡(luò)進(jìn)行訓(xùn)練,輸出層使用softmax進(jìn)行訓(xùn)練,得到最后的隱含層為輸出矩陣V,這一矩陣V即為經(jīng)過(guò)稀疏自編碼之后得到的物品的低維矩陣。
通常情況下,隱含層會(huì)有多層,以保證輸入層的數(shù)據(jù)得到充分的運(yùn)算,也就解決了上面講的特征挖掘?qū)哟尾蛔愕那闆r,同時(shí)網(wǎng)絡(luò)輸入的是物品的屬性信息,所以,第二個(gè)問(wèn)題也得以解決。
假設(shè)一個(gè)物品的特性為v1=(x1,x2,x3,x4,x5,x6),經(jīng)過(guò)上面的模型運(yùn)算之后,向量就會(huì)變成v1=(k1, k2, k3)。
?????? 在使用稀疏自編碼進(jìn)行運(yùn)算時(shí)有兩個(gè)比較常用的延伸思路,是在使用稀疏自編碼進(jìn)行數(shù)據(jù)降維時(shí)頻繁使用的方法,如下:
1) 添加隨機(jī)因子:
如果直接將輸入值看做輸出層,有可能使輸入層的數(shù)據(jù)直接穿透隱含層到達(dá)輸出層,起不到準(zhǔn)確訓(xùn)練的效果,此時(shí)可以在輸入層中加入一些混淆因子,使輸入和輸出層不完全一致,即避免了數(shù)據(jù)穿透的問(wèn)題。
????隨機(jī)因子應(yīng)該是遠(yuǎn)遠(yuǎn)小于x的值,以保證攪亂一致性的同時(shí)不會(huì)引發(fā)x值變化。
2) 用已知的X、Y值:
????在多層隱含層的自編碼模式中有一種典型的方法是:棧式自編碼。
即已知X和Y的值,通過(guò)輸入X,輸出Y訓(xùn)練多層隱含層,然后得到最后一個(gè)隱含層,作為X的壓縮向量。
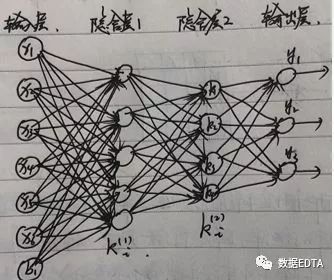
還是剛才的假設(shè):v1=(x1,x2,x3,x4,x5,x6),輸出層的標(biāo)簽為Y=(y1、y2、y3),經(jīng)過(guò)兩層隱含層的計(jì)算得到v1 = (k1, k2, k3, k4),這一特征向量涵蓋了輸入端的物品的用戶(hù)評(píng)分屬性和輸出端的物品分類(lèi)標(biāo)簽屬性,是一個(gè)綜合性的向量。基于這樣的數(shù)據(jù)進(jìn)行物品相似度計(jì)算能獲得較好的效果。
????寫(xiě)到這里,大家有沒(méi)有發(fā)現(xiàn),稀疏自編碼并沒(méi)有用上面的評(píng)分表,而是使用了基于內(nèi)容的一些思路,推薦的協(xié)同邏輯發(fā)生了變化。所以,推薦本身不是基于一個(gè)固定不變的思路進(jìn)行優(yōu)化的,有時(shí)會(huì)不停的跳躍,直到找到較好的方法。
如何使用社交鏈的問(wèn)題
不管什么樣的APP都希望能夠使用到社交網(wǎng)絡(luò)的信息,因?yàn)樯缃痪W(wǎng)絡(luò)本身就是一個(gè)計(jì)算良好的U-U矩陣,能夠更準(zhǔn)確的表示出用戶(hù)的相似度。
社交網(wǎng)絡(luò)主要有兩種模式:興趣圖譜和社交圖譜。
導(dǎo)致網(wǎng)絡(luò)中會(huì)有三種常見(jiàn)的社交數(shù)據(jù):1) 雙向確認(rèn)的社交數(shù)據(jù),比如微信,A<——>B;2) 單向關(guān)注的社交數(shù)據(jù),比如微博,A——>B;3) 基于社區(qū)的社交數(shù)據(jù),比如知乎,A——>社區(qū)<——B;
在推薦算法中,社交網(wǎng)絡(luò)最常用的用法還是與協(xié)同推薦結(jié)合使用,我們先看一個(gè)社交網(wǎng)絡(luò)的圖片:
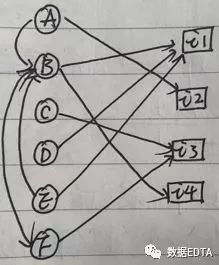
從圖中可以看出,B有兩人關(guān)注(A,E),有一人是好友(F),B購(gòu)買(mǎi)了兩個(gè)物品(i1,i4)。上圖為社交網(wǎng)絡(luò)的一個(gè)完整的圖形,我們的推薦也是基于這一圖形進(jìn)行的。
限于篇幅,本文就寫(xiě)到這里~
下一篇文章我們來(lái)詳細(xì)的講解:基于社交網(wǎng)絡(luò)的推薦方式和基于深度學(xué)習(xí)融合模型的推薦算法。
◆?◆?◆ ?◆?◆
長(zhǎng)按二維碼關(guān)注我們
數(shù)據(jù)森麟公眾號(hào)的交流群已經(jīng)建立,許多小伙伴已經(jīng)加入其中,感謝大家的支持。大家可以在群里交流關(guān)于數(shù)據(jù)分析&數(shù)據(jù)挖掘的相關(guān)內(nèi)容,還沒(méi)有加入的小伙伴可以?huà)呙柘路焦芾韱T二維碼,進(jìn)群前一定要關(guān)注公眾號(hào)奧,關(guān)注后讓管理員幫忙拉進(jìn)群,期待大家的加入。
管理員二維碼:
●?互聯(lián)網(wǎng)大佬學(xué)歷&背景大揭秘,看看是你的老鄉(xiāng)還是校友
評(píng)論
圖片
表情