
2020年大廠面試題-數(shù)據(jù)倉庫篇

以下面試題均為身邊朋友面試大廠所提供;
且后期將不定期進(jìn)行更新并會附上最終答案;
其中涉及到的題目沒有標(biāo)準(zhǔn)答案
該答案均為筆者手動整理,如有錯誤
請及時指出改正~
最后強(qiáng)烈建議進(jìn)行收藏閱讀!!!

手寫"連續(xù)活躍登陸"等類似場景的sql
# 該題目有不同的解法,可以使用row_number窗口函數(shù)或者使用lag函數(shù)# 第一種解決方案,使用lag(向前)或者lead(向后)select*from(selectuser_id,date_id,lead(date_id) over(partition by user_id order by date_id) as last_date_idfrom(selectuser_id,date_idfrom wedw_dw.tmp_logwhere date_id>='2020-08-10'and user_id is not nulland length(user_id)>0group by user_id,date_idorder by user_id,date_id)t)t1where datediff(last_date_id,date_id)=1
-- 第二種解決方案,使用row_numberselectuser_id,min(date_id),max(date_id),count(1)from(selectt1.user_id,t1.date_id,date_sub(t1.date_id,rn) as disfrom(selectuser_id,date_id,row_number() over(partition by user_id order by date_id asc) rnfrom(selectuser_id,date_idfrom wedw_dw.tmp_logwhere date_id>='2020-08-10'and user_id is not nulland length(user_id)>0group by user_id,date_idorder by user_id,date_id)t)t1)t2group by user_id,hishaving count(1)>2
left semi join和left join區(qū)別
-
left semi join 左半連接
in(keySet),相當(dāng)于在右表中查詢左表的key, left semi join 是 in(keySet) 的關(guān)系,遇到右表重復(fù)記錄,左表會跳過;當(dāng)右表不存在的時候,左表數(shù)據(jù)不會顯示; 相當(dāng)于SQL的in語句.比如測試的語句相當(dāng)于
select * from table1 where table1.student_no in (table2.student_no)注意,結(jié)果中是沒有B表的字段的.LEFT SEMI JOIN 是 IN/EXISTS 子查詢的一種更高效的實(shí)現(xiàn);Hive 當(dāng)前沒有實(shí)現(xiàn) IN/EXISTS 子查詢,所以你可以用 LEFT SEMI JOIN 重寫你的子查詢語句。LEFT SEMI JOIN 的限制是, JOIN 子句中右邊的表只能在 ON 子句中設(shè)置過濾條件,在 WHERE 子句、SELECT 子句或其他地方過濾都不行
-
left join
當(dāng)右表不存在的時候,則會顯示NULL
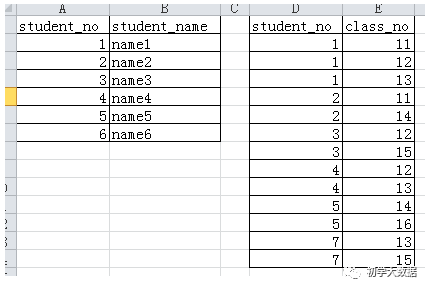
select * from table1 left semi join table2 on(table1.student_no=table2.student_no);結(jié)果:1 name12 name23 name34 name45 name5select * from table1 left outer join table2 on(table1.student_no=table2.student_no);結(jié)果:1 name1 1 111 name1 1 121 name1 1 132 name2 2 112 name2 2 143 name3 3 153 name3 3 124 name4 4 134 name4 4 125 name5 5 145 name5 5 166 name6 NULL NULL
維度建模和范式建模的區(qū)別
通常數(shù)據(jù)建模有以下幾個流程:
-
概念建模:即通常先將業(yè)務(wù)劃分多個主題
-
邏輯建模:即定義各種實(shí)體、屬性和關(guān)系
-
物理建模:設(shè)計數(shù)據(jù)對象的物理實(shí)現(xiàn),比如表字段類型、命名等。
那么范式建模,即3NF模型具有以下特點(diǎn):
-
原子性,即數(shù)據(jù)不可分割
-
基于第一個條件,實(shí)體屬性完全依賴于主鍵,不能存在僅依賴主關(guān)鍵字一部分屬性。即不能存在部分依賴
-
基于第二個條件,任何非主屬性不依賴于其他非主屬性。即消除傳遞依賴.
基于以上三個特點(diǎn),3NF的最終目的就是為了降低數(shù)據(jù)冗余,保障數(shù)據(jù)一致性;同時也有了數(shù)據(jù)關(guān)聯(lián)邏輯復(fù)雜的缺點(diǎn)。
而維度建模是面向分析場景的,主要關(guān)注點(diǎn)在于快速、靈活,能夠提供大規(guī)模的數(shù)據(jù)響應(yīng)。
常用的維度模型類型主要有:
-
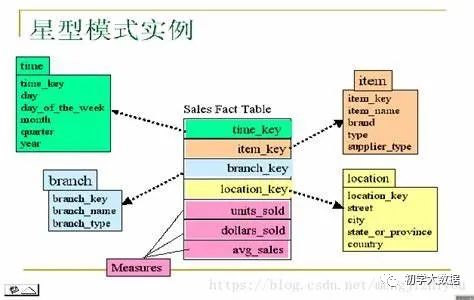
星型模型:即由一個事實(shí)表和一組維度表組成,每個維表都有一個維度作為主鍵。事實(shí)表居中,多個維表呈輻射狀分布在四周,并與事實(shí)表關(guān)聯(lián),形成一個星型結(jié)構(gòu)
-
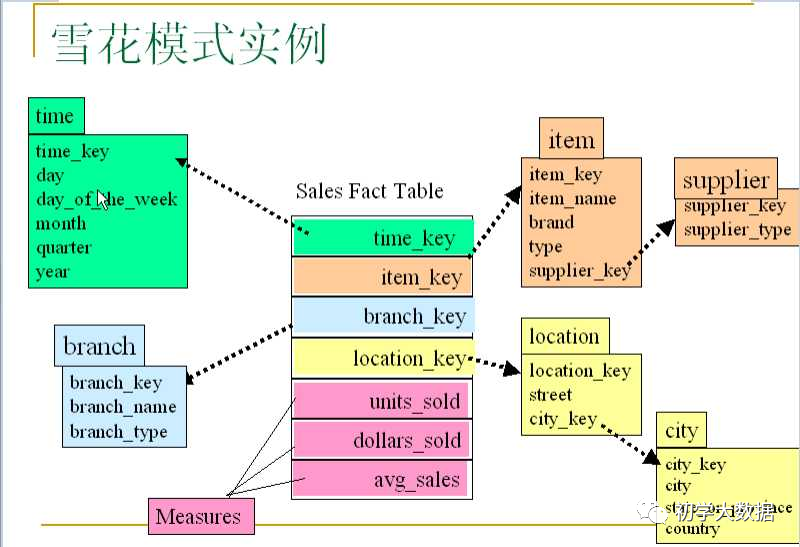
雪花模型:在星型模型的基礎(chǔ)上,基于范式理論進(jìn)一步層次化,將某些維表擴(kuò)展成事實(shí)表,最終形成雪花狀結(jié)構(gòu)
-
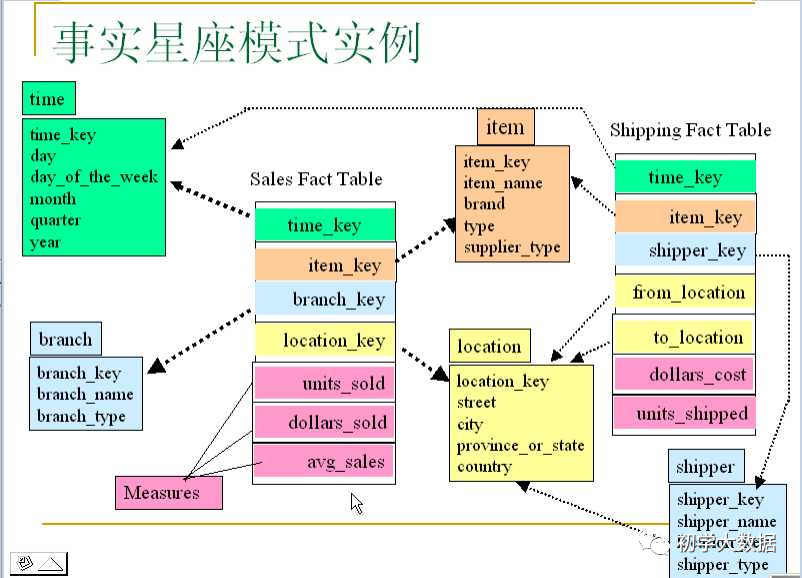
星系模型:基于多個事實(shí)表,共享一些維度表
數(shù)據(jù)漂移如何解決
什么是數(shù)據(jù)漂移?
通常是指ods表的同一個業(yè)務(wù)日期數(shù)據(jù)中包含了前一天或后一天凌晨附近的數(shù)據(jù)或者丟失當(dāng)天變更的數(shù)據(jù),這種現(xiàn)象就叫做漂移,且在大部分公司中都會遇到的場景。
如何解決數(shù)據(jù)漂移問題?
通常有兩種解決方案:
-
多獲取后一天的數(shù)據(jù),保障數(shù)據(jù)只多不少
-
通過多個時間戳字段來限制時間獲取相對準(zhǔn)確的數(shù)據(jù)
第一種方案比較暴力,這里不做過多解釋,主要來講解一下第二種解決方案。(首先這種解決方案在大數(shù)據(jù)之路這本書有體現(xiàn))
以下內(nèi)容為該書的描述:
通常,時間戳字段分為四類:
數(shù)據(jù)庫表中用來標(biāo)識數(shù)據(jù)記錄更新時間的時間戳字段(假設(shè)這類字段叫 modified time )
數(shù)據(jù)庫日志中用來標(biāo)識數(shù)據(jù)記錄更新時間的時間戳字段·(假設(shè)這類宇段叫 log_time)
數(shù)據(jù)庫表中用來記錄具體業(yè)務(wù)過程發(fā)生時間的時間戳字段 (假設(shè)這類字段叫 proc_time)
標(biāo)識數(shù)據(jù)記錄被抽取到時間的時間戳字段(假設(shè)這類字段extract time)
理論上這幾個時間應(yīng)該是一致的,但往往會出現(xiàn)差異,造成的原因可能為:
數(shù)據(jù)抽取需要一定的時間,extract_time往往晚于前三個時間
業(yè)務(wù)系統(tǒng)手動改動數(shù)據(jù)并未更新modfied_time
網(wǎng)絡(luò)或系統(tǒng)壓力問題,log_time或modified_time晚于proc_time
通常都是根據(jù)以上的某幾個字段來切分ODS表,這就產(chǎn)生了數(shù)據(jù)漂移。具體場景如下:
根據(jù)extract_time進(jìn)行同步
根據(jù)modified_time進(jìn)行限制同步, 在實(shí)際生產(chǎn)中這種情況最常見,但是往往會發(fā)生不更新 modified time 而導(dǎo)致的數(shù)據(jù)遺漏,或者凌晨時間產(chǎn)生的數(shù)據(jù)記錄漂移到后天 。由于網(wǎng)絡(luò)或者系統(tǒng)壓力問題, log_time 會晚proc_time ,從而導(dǎo)致凌晨時間產(chǎn)生的數(shù)據(jù)記錄漂移到后一天。
根據(jù)proc_time來限制,會違背ods和業(yè)務(wù)庫保持一致的原則,因?yàn)閮H僅根據(jù)proc_time來限制,會遺漏很多其他過程的變化
那么該書籍中提到的第二種解決方案:
-
首先通過log_time多同步前一天最后15分鐘和后一天凌晨開始15分鐘的數(shù)據(jù),然后用modified_time過濾非當(dāng)天的數(shù)據(jù),這樣確保數(shù)據(jù)不會因?yàn)橄到y(tǒng)問題被遺漏
-
然后根據(jù)log_time獲取后一天15分鐘的數(shù)據(jù),基于這部分?jǐn)?shù)據(jù),按照主鍵根據(jù)log_time做升序排序,那么第一條數(shù)據(jù)也就是最接近當(dāng)天記錄變化的
-
最后將前兩步的數(shù)據(jù)做全外連接,通過限制業(yè)務(wù)時間proc_time來獲取想要的數(shù)據(jù)
拉鏈表如何設(shè)計,拉鏈表出現(xiàn)數(shù)據(jù)回滾的需求怎么解決
拉鏈表使用的場景:
數(shù)據(jù)量大,且表中部分字段會更新,比如用戶地址、產(chǎn)品描述信息、訂單狀態(tài)等等
需要查看某一個時間段的歷史快照信息
變化比例和頻率不是很大
--拉鏈表實(shí)現(xiàn)--原始數(shù)據(jù)CREATE TABLE wedw_tmp.tmp_orders (orderid INT,createtime STRING,modifiedtime STRING,status STRING) stored AS textfile;--拉鏈表CREATE TABLE wedw_tmp.tmp_orders_dz(orderid int,createtime STRING,modifiedtime STRING,status STRING,link_start_date string,link_end_date string) stored AS textfile;--更新表CREATE TABLE wedw_tmp.tmp_orders_update(orderid INT,createtime STRING,modifiedtime STRING,status STRING) stored AS textfile;--插入原始數(shù)據(jù)insert overwrite table wedw_tmp.tmp_ordersselect 1,"2015-08-18","2015-08-18","創(chuàng)建"union allselect 2,"2015-08-18","2015-08-18","創(chuàng)建"union allselect 3,"2015-08-19","2015-08-21","支付"union allselect 4,"2015-08-19","2015-08-21","完成"union allselect 5,"2015-08-19","2015-08-20","支付"union allselect 6,"2015-08-20","2015-08-20","創(chuàng)建"union allselect 7,"2015-08-20","2015-08-21","支付"--拉鏈表初始化insert into wedw_tmp.tmp_orders_dzselect *,createtime,'9999-12-31'from wedw_tmp.tmp_orders--增量數(shù)據(jù)insert into wedw_tmp.tmp_orders_updateselect 3,"2015-08-19","2015-08-21","支付"union allselect 4,"2015-08-19","2015-08-21","完成"union allselect 7,"2015-08-20","2015-08-21","支付"union allselect 8,"2015-08-21","2015-08-21","創(chuàng)建"--更新拉鏈表insert overwrite table wedw_tmp.tmp_orders_dzselectt1.orderid,t1.createtime,t1.modifiedtime,t1.status,t1.link_start_date,case when t1.link_end_date='9999-12-31' and t2.orderid is not null then '2015-08-20'else t1.link_end_dateend as link_end_datefrom wedw_tmp.tmp_orders_dz t1left join wedw_tmp.tmp_orders_update t2on t1.orderid = t2.orderidunion allselectorderid,createtime,modifiedtime,status,'2015-08-21' as link_start_date,'9999-12-31' as link_end_datefrom wedw_tmp.tmp_orders_update--拉鏈表回滾,比如在插入2015-08-22的數(shù)據(jù)后,-- 回滾2015-08-21的數(shù)據(jù),使拉鏈表與2015-08-20的一致-- 具體操作過程如下selectorderid,createtime,modifiedtime,status,link_start_date,link_end_datefrom wedw_tmp.tmp_orders_dzwhere link_end_date<'2015-08-20'union allselectorderid,createtime,modifiedtime,status,link_start_date,'9999-12-31'from wedw_tmp.tmp_orders_dzwhere link_end_date='2015-08-20'union allselectorderid,createtime,modifiedtime,status,link_start_date,'9999-12-31'from wedw_tmp.tmp_orders_dzwhere link_start_date<'2020-08-21' and link_end_date>='2015-08-21'
sql里面on和where有區(qū)別嗎
數(shù)據(jù)庫在通過連接兩張或多張表來返回記錄時,都會生成一張中間的臨時表
以 LEFT JOIN 為例:在使用 LEFT JOIN 時,ON 和 WHERE 過濾條件的區(qū)別如下:
on 條件是在生成臨時表時使用的條件,它不管 on 中的條件是否為真,都會返回左邊表中的記錄
where 條件是在臨時表生成好后,再對臨時表進(jìn)行過濾的條件。這時已經(jīng)沒有 left join 的含義(必須返回左邊表的記錄)了,條件不為真的就全部過濾掉。
公共層和數(shù)據(jù)集市層的區(qū)別和特點(diǎn)
公共維度模型層(CDM):
又細(xì)分為dwd層和dws層,主要存放明細(xì)事實(shí)數(shù)據(jù)、維表數(shù)據(jù)以及公共指標(biāo)匯總數(shù)據(jù),其中明細(xì)事實(shí)數(shù)據(jù)、維表數(shù)據(jù)一般是根據(jù)ods層數(shù)據(jù)加工生成的,公共指標(biāo)匯總數(shù)據(jù)一般是基于維表和明細(xì)事實(shí)數(shù)據(jù)加工生成的。
采用維度模型方法作為理論基礎(chǔ),更多采用一些維度退化的手段,將維度退化到事實(shí)表中,減少事實(shí)表和維度表之間的關(guān)聯(lián)。同時在匯總層,加強(qiáng)指標(biāo)的維度退化,采用更多的寬表化手段構(gòu)建公共指標(biāo)數(shù)據(jù)層,提升公共指標(biāo)的復(fù)用性,減少重復(fù)加工。
其主要功能:
-
組合相關(guān)和相似數(shù)據(jù):采用明細(xì)寬表,復(fù)用關(guān)聯(lián)計算,減少數(shù)據(jù) 掃描。
公共指標(biāo)統(tǒng)一加工:基于 OneData 體系構(gòu)建命名規(guī)范、口徑一致 和算法統(tǒng)一的統(tǒng)計指標(biāo),為上層數(shù)據(jù)產(chǎn)品、應(yīng)用和服務(wù)提供公共 指標(biāo) 建立邏輯匯總寬表
建立一致性維度:建立一致的數(shù)據(jù)分析維表,降低數(shù)據(jù)計算口徑、 算法不統(tǒng)一的風(fēng)險。應(yīng)用數(shù)據(jù)層( ADS):存放數(shù)據(jù)產(chǎn)品個性化的統(tǒng)計指標(biāo)數(shù)據(jù),根據(jù) CDM 層與 ODS 層加工生成。
數(shù)據(jù)集市(Data Mart):
就是滿足特定部門或者用戶的需求,按照多維方式存儲。面向決策分析的數(shù)據(jù)立方體
從原理上說一下mpp和mr的區(qū)別
MPP 為并行數(shù)據(jù)庫 :
它的思路簡單粗暴,把數(shù)據(jù)分塊,交給不同節(jié)點(diǎn)儲存, 查詢的時候各塊的節(jié)點(diǎn)有獨(dú)立的計算資源分別處理,然后匯總到一個leader node(又叫control node),具體的優(yōu)化和傳統(tǒng)的關(guān)系型數(shù)據(jù)庫很相似,涉及到了索引,統(tǒng)計信息等概念. MPP有shared everything /Disk / Nothing之別.
MapReduce其實(shí)就是二分查找的一個逆過程,不過因?yàn)橛嬎愎?jié)點(diǎn)有限,所以map和reduce前都預(yù)先有一個分區(qū)的步驟.二分查找要求數(shù)據(jù)是排序好的,所以Map Reduce之間會有一個shuffle的過程對Map的結(jié)果排序. Reduce的輸入是排好序的 .
區(qū)別:
底層數(shù)據(jù)庫:MPP跑的是SQL,而Hadoop底層處理是MapReduce程序
擴(kuò)展程度:MPP雖然是宣稱可以橫向擴(kuò)展Scale OUT,但是這種擴(kuò)展一般是擴(kuò)展到100左右,而Hadoop一般可以擴(kuò)展1000+ ;因?yàn)镸PP始終還是DB,一定要考慮到C(Consistency),其次考慮A(Availability),最后才在可能的情況下盡量做好P(Partition-tolerance)。而Hadoop就是為了并行處理和存儲設(shè)計的,所以數(shù)據(jù)都是以文件存儲,所以有限考慮的是P,然后是A,最后再考慮C.所以后者的可靠型當(dāng)然好于前者
本質(zhì)mpp還是數(shù)據(jù)庫,需要優(yōu)先考慮C(數(shù)據(jù)一致性),而mr首先考慮的是P(分區(qū)容錯性);關(guān)于CAP理論可見十分鐘搞定分布式一致性算法
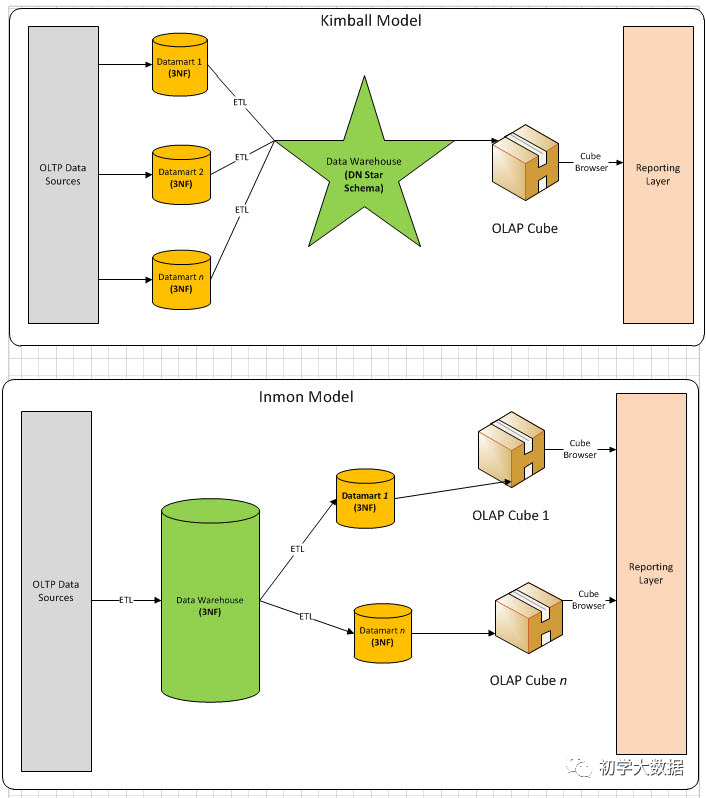
Kimball和Inmon的相同和不同
Inmon模型:
流程:自頂向下,即從分散異構(gòu)的數(shù)據(jù)源-->數(shù)據(jù)倉庫---->數(shù)據(jù)集市。是一種瀑布流開發(fā)方法。模型偏向于3NF
數(shù)據(jù)源往往是異構(gòu)的,比如爬蟲;數(shù)據(jù)源是根據(jù)最終目標(biāo)自行定制的。
這里主要的處理工作集中在對異構(gòu)數(shù)據(jù)進(jìn)行清洗,否則無法從stage層直接輸出到dm層,必須先通過etl將數(shù)據(jù)進(jìn)行清洗后放入dw層。
Inmon模式下,不強(qiáng)調(diào)事實(shí)表和維度表的概念,因?yàn)閿?shù)據(jù)源變化可能性較大,更加強(qiáng)調(diào)的是數(shù)據(jù)的清洗工作,從中抽取實(shí)體-關(guān)系
Inmon是以數(shù)據(jù)源頭為導(dǎo)向,具體流程如下:
首先探索獲取盡量符合預(yù)期的數(shù)據(jù),嘗試將數(shù)據(jù)按照預(yù)期劃分不同的表需求
明確數(shù)據(jù)清洗規(guī)則后將各個任務(wù)通過etl由stage層轉(zhuǎn)化到dm層,這里dm層通常涉及到較多的UDF開發(fā),將數(shù)據(jù)抽象為實(shí)體-關(guān)系模型
完成dm數(shù)據(jù)治理后,可以將數(shù)據(jù)輸出到數(shù)據(jù)集市中做基本數(shù)據(jù)組合,最后輸出到BI系統(tǒng)輔助具體業(yè)務(wù)
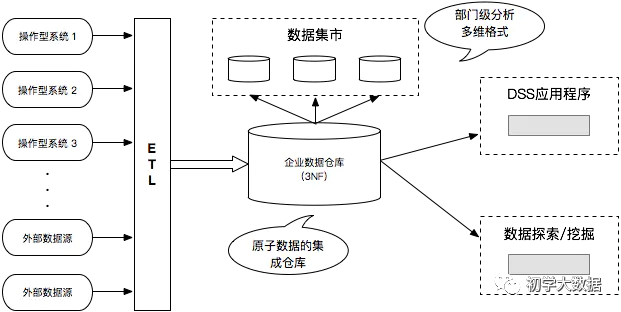
一般這種模型構(gòu)建屬于細(xì)水長流型的,而且技能/數(shù)據(jù)要求比較高,有可能有一天公司倒閉了,數(shù)倉還沒有建設(shè)好
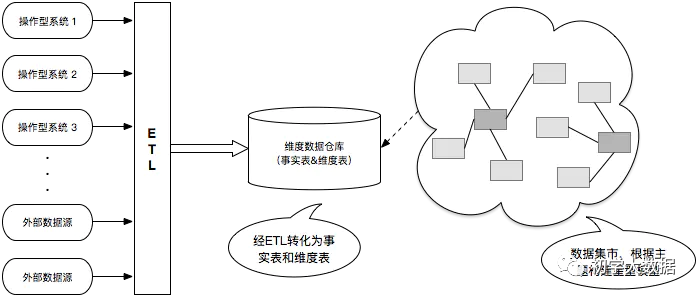
Kimball模型是以需求為導(dǎo)向
流程:自下向上, 即從數(shù)據(jù)集市-> 數(shù)據(jù)倉庫 -> 分散異構(gòu)的數(shù)據(jù)源 ,相當(dāng)于是以最終任務(wù)為導(dǎo)向的;模型使用星型、雪花
-
首先得到數(shù)據(jù)后需要先做數(shù)據(jù)的探索,嘗試將數(shù)據(jù)按照目標(biāo)拆分出不同的表需求
明確數(shù)據(jù)依賴后將各個任務(wù)再通過etl由stage層轉(zhuǎn)化到DM層。DM層由若干事實(shí)表和維度表組成
完成DM層的事實(shí)表和維度表拆分后,數(shù)據(jù)集市一側(cè)可以直接向BI環(huán)節(jié)輸出數(shù)據(jù)
Kimball往往意味著快速交付,敏捷交付,不會對數(shù)倉架構(gòu)做過多復(fù)雜的設(shè)計
特征對比:
MOLAP ROLAP HOLAP的區(qū)別和聯(lián)系
MOLAP:多維聯(lián)機(jī)分析處理,預(yù)計算
ROLAP:關(guān)系型聯(lián)機(jī)分析處理, 依賴于操作存儲在關(guān)系型數(shù)據(jù)庫中的數(shù)據(jù).本質(zhì)上,每個slicing或dicing功能和SQL語句中"WHERE"子句的功能是一樣的。
HOLAP:混合型聯(lián)機(jī)分析處理(指的是MOLAP和ROLAP的結(jié)合)
埋點(diǎn)的碼表如何設(shè)計
數(shù)據(jù)傾斜
group by為什么要排序
緩慢變化維的處理方式
hive常見的優(yōu)化思路
數(shù)據(jù)質(zhì)量/元數(shù)據(jù)管理/指標(biāo)體系建設(shè)/數(shù)據(jù)驅(qū)動
如何保證數(shù)據(jù)質(zhì)量
如何保證指標(biāo)一致性
--end--
掃描下方二維碼
添加好友,備注【交流】 可私聊交流,也可進(jìn)資源豐富學(xué)習(xí)群