
容易被輕視的主角,神奇的 SQL 之 HAVING

作者 | 青石路
關(guān)于 SQL 中的 HAVING,相信大家都不陌生,它往往與 GROUP BY 配合使用,為聚合操作指定條件
說到指定條件,我們最先想到的往往是 WHERE 子句,但 WHERE 子句只能指定行的條件,而不能指定組的條件,因此就有了 HAVING 子句,它用來指定組的條件。我們來看個(gè)具體示例就清楚了。
我們有 學(xué)生班級表(tbl_student_class) 以及 數(shù)據(jù)如下 :
DROP TABLE IF EXISTS tbl_student_class; CREATE TABLE tbl_student_class (
id int(8) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主鍵',
sno varchar(12) NOT NULL COMMENT '學(xué)號',
cno varchar(5) NOT NULL COMMENT '班級號',
cname varchar(50) NOT NULL COMMENT '班級名', PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='學(xué)生班級表'; -- ---------------------------- -- Records of tbl_student_class -- ----------------------------
INSERT INTO tbl_student_class(sno, cno, cname) VALUES ('20190607001', '0607', '影視7班'); INSERT INTO tbl_student_class(sno, cno, cname) VALUES ('20190607002', '0607', '影視7班'); INSERT INTO tbl_student_class(sno, cno, cname) VALUES ('20190608003', '0608', '影視8班'); INSERT INTO tbl_student_class(sno, cno, cname) VALUES ('20190608004', '0608', '影視8班'); INSERT INTO tbl_student_class(sno, cno, cname) VALUES ('20190609005', '0609', '影視9班'); INSERT INTO tbl_student_class(sno, cno, cname) VALUES ('20190609006', '0609', '影視9班'); INSERT INTO tbl_student_class(sno, cno, cname) VALUES ('20190609007', '0609', '影視9班');
我們要查詢 學(xué)生人數(shù)為 3 的班級 ,這就需要用到 HAVING 了,相信大家都會寫
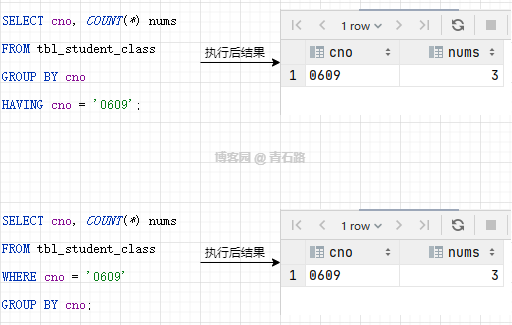
SELECT cno, COUNT(*) nums FROM tbl_student_class GROUP BY cno HAVING COUNT(*) = 3;
 Java API版權(quán)第一大案,索賠百億美元,打了10年終于有結(jié)果了!
Java API版權(quán)第一大案,索賠百億美元,打了10年終于有結(jié)果了!
如果我們不使用 HAVING,會是什么樣呢

可以看到,除了數(shù)量等于 3 的班級之前,其他的班級也被查出來了
我們可以簡單總結(jié)下:WHERE 先過濾出行,然后 GROUP BY 對行進(jìn)行分組,HAVING 再對組進(jìn)行過濾,篩選出我們需要的組

HAVING 子句的構(gòu)成要素
既然 HAVING 操作的對象是組,那么其使用的要素是有一定限制的,能夠使用的要素有 3 種:常數(shù) 、 聚合函數(shù) 和 聚合鍵 ,聚合鍵也就是 GROUP BY 子句中指定的列名
示例中的 HAVING COUNT(*) = 3 , COUNT(*) 是聚合函數(shù),3 是常數(shù),都在 3 要素之中;如果有 3 要素之外的條件,會是怎么樣呢
SELECT cno, COUNT(*) nums FROM tbl_student_class GROUP BY cno HAVING cname = '影視9班';
執(zhí)行如上 SQL 會失敗,并提示:
[Err] 1054 - Unknown column 'cname' in 'having clause'
在使用 HAVING 子句時(shí),把 GROUP BY 聚合后的結(jié)果作為 HAVING 子句的起點(diǎn),會更容易理解;示例中通過 cno 進(jìn)行聚合后的結(jié)果如下:

聚合后的這個(gè)結(jié)果并沒有 cname 這個(gè)列,那么通過這個(gè)列來進(jìn)行條件處理,當(dāng)然就報(bào)錯(cuò)了啦
細(xì)心的小伙伴應(yīng)該已經(jīng)發(fā)現(xiàn),HAVING 子句的構(gòu)成要素和包含 GROUP BY 子句時(shí)的 SELECT 子句的構(gòu)成要素是一樣的,都是只能包含 常數(shù) 、 聚合函數(shù) 和 聚合鍵
HAVING 的魅力
HAVING 子句是 SQL 里一個(gè)非常重要的功能,是理解 SQL 面向集合這一本質(zhì)的關(guān)鍵。下面結(jié)合具體的案例,來感受下 HAVING 的魅力
是否存在缺失的編號
tbl_student_class 表中記錄的 id 是連續(xù)的(id 的起始值不一定是 1),我們?nèi)サ羝渲?3 條
DELETE FROM tbl_student_class WHERE id IN(2,5,6); SELECT * FROM tbl_student_class;

如何判斷是否有編號缺失?
數(shù)據(jù)量少,我們一眼就能看出來,但是如果數(shù)據(jù)量上百萬行了,用眼就看不出來了吧
不繞圈子了,我就直接寫了,相信大家都能看懂(記得和自己想的對比一下)
SELECT '存在缺失的編號' AS gap FROM tbl_student_class HAVING COUNT(*) <> MAX(id) - MIN(id) + 1;
上面的 SQL 語句里沒有 GROUP BY 子句,此時(shí)整張表會被聚合為一組,這種情況下 HAVING 子句也是可以使用的(HAVING 不是一定要和 GROUP BY 一起使用)
寫的更嚴(yán)謹(jǐn)點(diǎn),如下(沒有 HAVING,不是主角,看一眼就好)
-- 無論如何都有結(jié)果返回
SELECT CASE WHEN COUNT(*) = 0 THEN '表為空'
WHEN COUNT(*) <> MAX(id) - MIN(id) + 1 THEN '存在缺失的編號'
ELSE '連續(xù)' END AS gap FROM tbl_student_class;
那如何找出缺失的編號了,歡迎評論區(qū)留言
求眾數(shù)
假設(shè)我們有一張表:tbl_student_salary ,記錄著畢業(yè)生首份工作的年薪
DROP TABLE IF EXISTS tbl_student_salary; CREATE TABLE tbl_student_salary (
id int(8) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主鍵',
name varchar(5) NOT NULL COMMENT '姓名',
salary DECIMAL(15,2) NOT NULL COMMENT '年薪, 單位元', PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='畢業(yè)生年薪標(biāo)'; insert into tbl_student_salary values (1,'李小龍', 1000000); insert into tbl_student_salary values (2,'李四', 50000); insert into tbl_student_salary values (3,'王五', 50000); insert into tbl_student_salary values (4,'趙六', 50000); insert into tbl_student_salary values (5,'張三', 70000); insert into tbl_student_salary values (6,'張一三', 70000); insert into tbl_student_salary values (7,'張二三', 70000); insert into tbl_student_salary values (8,'張三三', 60000); insert into tbl_student_salary values (9,'張三四', 40000); insert into tbl_student_salary values (10,'張三豐', 30000);
平均工資達(dá)到了 149000 元,乍一看好像畢業(yè)生大多都能拿到很高的工資。然而這個(gè)數(shù)字背后卻有一些玄機(jī),因?yàn)楣Ψ虼髱熇钚↓堅(jiān)谶@一屆畢業(yè)生中,由于他出眾的薪資,將大家的平均薪資拉升了一大截
簡單地求平均值有一個(gè)缺點(diǎn),那就是很容易受到離群值(outlier)的影響。這種時(shí)候就必須使用更能準(zhǔn)確反映出群體趨勢的指標(biāo)——眾數(shù)(mode)就是其中之一
那么如何用 SQL 語句來求眾數(shù)了,我們往下看
-- 使用謂詞 ALL 求眾數(shù)
SELECT salary, COUNT(*) AS cnt FROM tbl_student_salary GROUP BY salary HAVING COUNT(*) >= ALL ( SELECT COUNT(*) FROM tbl_student_salary GROUP BY salary);
結(jié)果如下
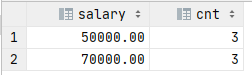
ALL 謂詞用于 NULL 或空集時(shí)會出現(xiàn)問題,我們可以用極值函數(shù)來代替;這里要求的是元素?cái)?shù)最多的集合,因此可以用 MAX 函數(shù)
-- 使用極值函數(shù)求眾數(shù)
SELECT salary, COUNT(*) AS cnt FROM tbl_student_salary GROUP BY salary HAVING COUNT(*) >= ( SELECT MAX(cnt) FROM ( SELECT COUNT(*) AS cnt FROM tbl_student_salary GROUP BY salary
) TMP
) ;
求中位數(shù)
當(dāng)平均值不可信時(shí),與眾數(shù)一樣經(jīng)常被用到的另一個(gè)指標(biāo)是中位數(shù)(median)。它指的是將集合中的元素按升序排列后恰好位于正中間的元素。如果集合的元素個(gè)數(shù)為偶數(shù),則取中間兩個(gè)元素的平均值作為中位數(shù)
表 tbl_student_salary 有 10 條記錄,那么 張三三, 60000 和 李四, 50000 的平均值 55000 就是中位數(shù)
那么用 SQL,該如何求中位數(shù)呢?做法是,將集合里的元素按照大小分為上半部分和下半部分兩個(gè)子集,同時(shí)讓這 2 個(gè)子集共同擁有集合正中間的元素。這樣,共同部分的元素的平均值就是中位數(shù),思路如下圖所示

像這樣需要根據(jù)大小關(guān)系生成子集時(shí),就輪到非等值自連接出場了
-- 求中位數(shù)的SQL 語句:在HAVING 子句中使用非等值自連接
SELECT AVG(DISTINCT salary) FROM ( SELECT T1.salary FROM tbl_student_salary T1, tbl_student_salary T2 GROUP BY T1.salary -- S1 的條件
HAVING SUM(CASE WHEN T2.salary >= T1.salary THEN 1 ELSE 0 END) >= COUNT(*) / 2
-- S2 的條件
AND SUM(CASE WHEN T2.salary <= T1.salary THEN 1 ELSE 0 END) >= COUNT(*) / 2 ) TMP;
這條 SQL 語句的要點(diǎn)在于比較條件 >= COUNT(*)/2 里的等號,加上等號并不是為了清晰地分開子集 S1 和 S2,而是為了讓這 2 個(gè)子集擁有共同部分
如果去掉等號,將條件改成 > COUNT(*)/2 ,那么當(dāng)元素個(gè)數(shù)為偶數(shù)時(shí),S1 和 S2 就沒有共同的元素了,也就無法求出中位數(shù)了;加上等號是為了寫出通用性更高的 SQL
查詢不包含 NULL 的集合
假設(shè)我們有一張學(xué)生報(bào)告提交記錄表:tbl_student_submit_log
DROP TABLE IF EXISTS tbl_student_submit_log; CREATE TABLE tbl_student_submit_log (
id int(8) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主鍵',
sno varchar(12) NOT NULL COMMENT '學(xué)號',
dept varchar(50) NOT NULL COMMENT '學(xué)院',
submit_date DATE COMMENT '提交日期', PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='學(xué)生報(bào)告提交記錄表'; insert into tbl_student_submit_log values (1,'20200607001', '理學(xué)院', '2020-12-12'),
(2,'20200607002', '理學(xué)院', '2020-12-13'),
(3,'20200608001', '文學(xué)院', null),
(4,'20200608002', '文學(xué)院', '2020-12-22'),
(5,'20200608003', '文學(xué)院', '2020-12-22'),
(6,'20200612001', '工學(xué)院', null),
(7,'20200617001', '經(jīng)濟(jì)學(xué)院', '2020-12-23');
學(xué)生提交報(bào)告后, submit_date 列會被寫入日期,而提交之前是 NULL
現(xiàn)在我們需要從這張表里找出哪些學(xué)院的學(xué)生全部都提交了報(bào)告,這個(gè) SQL 該怎么寫?
如果只是用 WHERE submit_date IS NOT NULL 條件進(jìn)行查詢,那文學(xué)院也會被包含進(jìn)來,結(jié)果就不正確了
正確的做法應(yīng)該先以 dept 進(jìn)行分組(GROUP BY),然后對組進(jìn)行條件的過濾,SQL 如下
SELECT dept FROM tbl_student_submit_log GROUP BY dept HAVING COUNT(*) = COUNT(submit_date);
這里其實(shí)用到了 COUNT 函數(shù),COUNT(*) 可以用于 NULL ,而 COUNT(列名) 與其他聚合函數(shù)一樣,要先排除掉 NULL 的行再進(jìn)行統(tǒng)計(jì)
當(dāng)然,使用 CASE 表達(dá)式也可以實(shí)現(xiàn)同樣的功能,而且更加通用
SELECT dept FROM tbl_student_submit_log GROUP BY dept HAVING COUNT(*) = SUM( CASE WHEN submit_date IS NOT NULL THEN 1
ELSE 0 END );
其他
不僅僅只是如上的那些場景適用于 HAVING,還有很多其他的場景也是需要用到 HAVING 的,有興趣的可以去翻閱《SQL進(jìn)階教程》
聚合鍵條件的歸屬
我們來看個(gè)有趣的東西,還是用表:tbl_student_class
 4 個(gè)使用率非常高的 Linux 監(jiān)控工具
4 個(gè)使用率非常高的 Linux 監(jiān)控工具
我們發(fā)現(xiàn),聚合鍵所對應(yīng)的條件既可以寫在 HAVING 子句當(dāng)中,也可以寫在 WHERE 子句當(dāng)中
雖然條件分別寫在 HAVING 子句和 WHERE 子句當(dāng)中,但是條件的內(nèi)容,以及返回的結(jié)果都完全相同,因此,很多小伙伴就會覺得兩種書寫方式都沒問題
單從結(jié)果來看,確實(shí)沒問題,但其中有一種屬于偏離了 SQL 規(guī)范的非正規(guī)用法,推薦做法是:聚合鍵所對應(yīng)的條件應(yīng)該書寫在 WHERE 子句中 ,理由有二
語義更清晰
WHERE 子句和 HAVING 子句的作用是不同的;前面已經(jīng)說過,HAVING 子句是用來指定“組”的條件的,而“行”所對應(yīng)的條件應(yīng)該寫在 WHERE 子句中,這樣一來,寫出來的 SQL 語句不但可以分清兩者各自的功能,而且理解起來也更容易

執(zhí)行速度更快
使用 COUNT 等函數(shù)對表中數(shù)據(jù)進(jìn)行聚合操作時(shí),DBMS 內(nèi)部進(jìn)行排序處理,而排序處理會大大增加機(jī)器的負(fù)擔(dān),從而降低處理速度;因此,盡可能減少排序的行數(shù),可以提高處理速度
通過 WHERE 子句指定條件時(shí),由于排序之前就對數(shù)據(jù)進(jìn)行了過濾,那么就減少了聚合操作時(shí)的需要排序的記錄數(shù)量;而 HAVING 子句是在排序之后才對數(shù)據(jù)進(jìn)行分組的,與在 WHERE 子句中指定條件比起來,需要排序的數(shù)量就會多得多
另外,索引是 WHERE 根據(jù)速度優(yōu)勢的另一個(gè)有利支持,在 WHERE 子句指定條件所對應(yīng)的列上創(chuàng)建索引,可以大大提高 WHERE 子句的處理速度
總結(jié)
1、集合論
集合論是 SQL 語言的根基,只有從集合的角度來思考,才能明白 SQL 的強(qiáng)大威力
學(xué)習(xí) HAVING 子句的用法是幫助我們順利地忘掉面向過程語言的思考方式并理解 SQL 面向集合特性的最為有效的方法
2、HAVING 子句的要素
3 個(gè)要素:常數(shù)、聚合函數(shù) 和 聚合鍵
HAVING 大多數(shù)情況下和結(jié)合 GROUP BY 來使用,但不是一定要結(jié)合 GROUP BY 來使用
3、SQL 的執(zhí)行順序
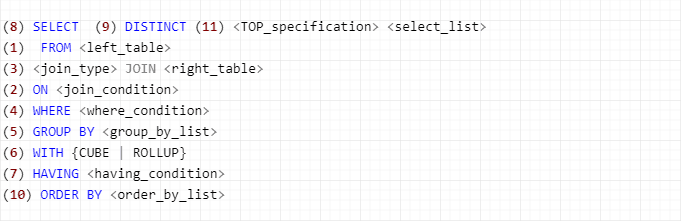
WHERE 子句是指定行所對應(yīng)的條件,而 HAVING 子句是指定組所對應(yīng)的條件
往期推薦
免費(fèi)領(lǐng)取:字節(jié)跳動資料-圖解網(wǎng)絡(luò)
喜歡的這里報(bào)道
↘↘↘