
深入剖析 Redis 高可用解決方案:哨兵、集群
前言
哨兵和集群的兩種高可用解決方案,但是兩者在保證高可用上的實現(xiàn)基本是一致的,因為集群模式的高可用解決方案基本就是“照搬”哨兵模式的。
集群可以認(rèn)為就是用來代替哨兵的,解決哨兵存在的一些問題,同時提供更優(yōu)秀的特性。
因為現(xiàn)在基本不會使用到哨兵模式,哨兵模式可以說基本只存在于面試中,同時由于哨兵的內(nèi)容在集群中都有類似的,所以本文對哨兵的介紹會比較簡單。
正文
哨兵是什么
哨兵(Sentinel)?是 Redis 的高可用性解決方案:由一個或多個 Sentinel 實例組成的 Sentinel 系統(tǒng)可以監(jiān)視任意多個主服務(wù)器,以及這些主服務(wù)器屬下的所有從服務(wù)器。
Sentinel 可以在被監(jiān)視的主服務(wù)器進(jìn)入下線狀態(tài)時,自動將下線主服務(wù)器的某個從服務(wù)器升級為新的主服務(wù)器,然后由新的主服務(wù)器代替已下線的主服務(wù)器繼續(xù)處理命令請求。
哨兵故障檢測
檢查主觀下線狀態(tài)
在默認(rèn)情況下,Sentinel 會以每秒一次的頻率向所有與它創(chuàng)建了命令連接的實例(包括主服務(wù)器、從服務(wù)器、其他 Sentinel 在內(nèi))發(fā)送 PING 命令,并通過實例返回的 PING 命令回復(fù)來判斷實例是否在線。
如果一個實例在 down-after-miliseconds 毫秒內(nèi),連續(xù)向 Sentinel 返回?zé)o效回復(fù),那么 Sentinel 會修改這個實例所對應(yīng)的實例結(jié)構(gòu),在結(jié)構(gòu)的 flags 屬性中設(shè)置 SRI_S_DOWN 標(biāo)識,以此來表示這個實例已經(jīng)進(jìn)入主觀下線狀態(tài)。
檢查客觀下線狀態(tài)
當(dāng) Sentinel 將一個主服務(wù)器判斷為主觀下線之后,為了確定這個主服務(wù)器是否真的下線了,它會向同樣監(jiān)視這一服務(wù)器的其他 Sentinel 進(jìn)行詢問,看它們是否也認(rèn)為主服務(wù)器已經(jīng)進(jìn)入了下線狀態(tài)(可以是主觀下線或者客觀下線)。
當(dāng) Sentinel 從其他 Sentinel 那里接收到足夠數(shù)量(quorum,可配置)的已下線判斷之后,Sentinel 就會將服務(wù)器置為客觀下線,在 flags 上打上 SRI_O_DOWN 標(biāo)識,并對主服務(wù)器執(zhí)行故障轉(zhuǎn)移操作。
哨兵故障轉(zhuǎn)移流程
當(dāng)哨兵監(jiān)測到某個主節(jié)點(diǎn)客觀下線之后,就會開始故障轉(zhuǎn)移流程。核心流程如下:
1、發(fā)起一次選舉,選舉出領(lǐng)頭 Sentinel
2、領(lǐng)頭 Sentinel 在已下線主服務(wù)器的所有從服務(wù)器里面,挑選出一個從服務(wù)器,并將其升級為新的主服務(wù)器。
3、領(lǐng)頭 Sentinel 將剩余的所有從服務(wù)器改為復(fù)制新的主服務(wù)器。
4、領(lǐng)頭 Sentinel 更新相關(guān)配置信息,當(dāng)這個舊的主服務(wù)器重新上線時,將其設(shè)置為新的主服務(wù)器的從服務(wù)器。
選舉領(lǐng)頭哨兵
當(dāng)一個主服務(wù)器被判斷為客觀下線時,監(jiān)視這個下線主服務(wù)器的各個 Sentinel 會進(jìn)行協(xié)商,選舉出一個領(lǐng)頭 Sentinel,并由領(lǐng)頭 Sentinel 對下線主服務(wù)器執(zhí)行故障轉(zhuǎn)移操作。Redis 選舉領(lǐng)頭 Sentinei 的流程如下:
1、當(dāng) Sentinel 發(fā)現(xiàn)自己監(jiān)視的主服務(wù)器進(jìn)入客觀下線時,會發(fā)起一次選舉:將 current_epoch(集群紀(jì)元)加1,向其他監(jiān)視該 master 的 Sentinel 發(fā)送拉票命令:SENTINEL is-master-down-by-addr,要求目標(biāo) Sentinel 將選票投給自己。
2、目標(biāo) Sentinel ?在接收到 SENTINEL is-master-down-by-addr 命令之后,會判斷自己是否已經(jīng)在本屆選舉投過票,如果沒有則會將選票投給源 Sentinel,最后回復(fù) leader 和 leader_epoch,代表自己所投的局部領(lǐng)頭 Sentinel 的運(yùn)行ID和配置紀(jì)元。
3、源 Sentinel 收到回復(fù)后,會將目標(biāo) Sentinel 的投票信息記錄下來,用于后續(xù)統(tǒng)計。
4、Sentinel 中同樣有自己的時間事件會被定期觸發(fā),當(dāng) Sentinel 狀態(tài)為:SENTINEL_FAILOVER_STATE_WAIT_START,會觸發(fā)選舉的投票結(jié)果統(tǒng)計。如果某個 Sentinel 獲得超過半數(shù)以上的選票(>=voters/2+1),而且票數(shù)要大于等于 quorum,那么這個 Sentinel 將成為領(lǐng)頭 Sentinel 。
因為領(lǐng)頭 Sentinel 的產(chǎn)生需要半數(shù)以上 Sentinel 的支持,并且每個 Sentinel 在每個配置紀(jì)元里面只能投一次票 ,所以在一個配置紀(jì)元里面,只會出現(xiàn)一個領(lǐng)頭 Sentinel 。
5、如果在一個配置紀(jì)元里沒有一個 Sentinel 被選舉為領(lǐng)頭 Sentinel ,那么各個 Sentinel 將在一段時間之后再次進(jìn)行選舉,直到選出領(lǐng)頭 Sentinel 為止。
哨兵選舉主服務(wù)器
1、領(lǐng)頭 Sentinel 會遍歷已下線主節(jié)點(diǎn)的所有從節(jié)點(diǎn),留下狀態(tài)好的節(jié)點(diǎn),過濾掉狀態(tài)不好的節(jié)點(diǎn),過濾規(guī)則主要有以下幾個:
從節(jié)點(diǎn)狀態(tài)為主觀下線或客觀下線
從節(jié)點(diǎn)鏈接斷開
上次收到該從節(jié)點(diǎn)的正常 PING 回復(fù)超過5秒(5 * SENTINEL_PING_PERIOD)
從節(jié)點(diǎn)的優(yōu)先級為0
上一次收到該從節(jié)點(diǎn)對于 INFO 的回復(fù)時間超過允許的時間,master 為主觀下線則為5秒,否則為30秒。這是因為在 master 為主觀下線后,Sentinel 會更頻繁的向從節(jié)點(diǎn)發(fā)送 INFO 命令,因為需要更實時的獲取從節(jié)點(diǎn)的狀態(tài)。
從節(jié)點(diǎn)與已下線的主節(jié)點(diǎn)鏈接斷開時間超過 down-after-miliseconds 配置的 10 倍
2、對剩下的狀態(tài)好的節(jié)點(diǎn)進(jìn)行排序,狀態(tài)越好的排在越前面,排序規(guī)則如下:
比較優(yōu)先級,優(yōu)先級值(slave-priority)較小的排在前面,跟 Spring 里的 Order 有點(diǎn)類似,也是小的排前面。
如果優(yōu)先級相同,比較復(fù)制偏移量,復(fù)制偏移量較大的排前面。
如果優(yōu)先級和復(fù)制偏移量相同,比較運(yùn)行ID,運(yùn)行ID小的排前面。
3、最終,排序后的第一個從節(jié)點(diǎn)會當(dāng)選為新的主節(jié)點(diǎn)
集群模式
哨兵模式最大的缺點(diǎn)就是所有的數(shù)據(jù)都放在一臺服務(wù)器上,無法較好的進(jìn)行水平擴(kuò)展。
為了解決哨兵模式存在的問題,集群模式應(yīng)運(yùn)而生。在高可用上,集群基本是直接復(fù)用的哨兵模式的邏輯,并且針對水平擴(kuò)展進(jìn)行了優(yōu)化。
集群模式具備的特點(diǎn)如下:
1、采取去中心化的集群模式,將數(shù)據(jù)按槽存儲分布在多個 Redis 節(jié)點(diǎn)上。集群共有 16384 個槽,每個節(jié)點(diǎn)負(fù)責(zé)處理部分槽。
2、使用 CRC16 算法來計算 key 所屬的槽:crc16(key,keylen)?& 16383。
3、所有的 Redis 節(jié)點(diǎn)彼此互聯(lián),通過 PING-PONG 機(jī)制來進(jìn)行節(jié)點(diǎn)間的心跳檢測。
4、分片內(nèi)采用一主多從保證高可用,并提供復(fù)制和故障恢復(fù)功能。在實際使用中,通常會將主從分布在不同機(jī)房,避免機(jī)房出現(xiàn)故障導(dǎo)致整個分片出問題,下面的架構(gòu)圖就是這樣設(shè)計的。
5、客戶端與 Redis 節(jié)點(diǎn)直連,不需要中間代理層(proxy)。客戶端不需要連接集群所有節(jié)點(diǎn),連接集群中任何一個可用節(jié)點(diǎn)即可。
集群的架構(gòu)圖如下所示:
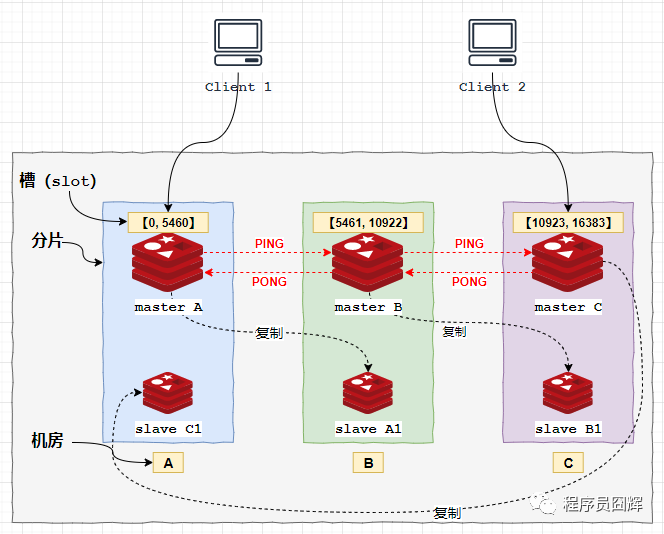
Redis 集群目標(biāo)
1、高性能:沒有代理層(proxy),采用異步復(fù)制,不對值進(jìn)行合并操作。
2、水平擴(kuò)展:集群共有 16384 個槽,每個節(jié)點(diǎn)負(fù)責(zé)處理部分槽,可以支持線性擴(kuò)展至 1000 個節(jié)點(diǎn)。
3、寫安全性:系統(tǒng)嘗試(盡最大努力)保留來自與大多數(shù)主節(jié)點(diǎn)連接的客戶機(jī)的所有寫操作。但是由于使用異步復(fù)制,所以可能會丟失一些寫命令。
4、可用性:集群模式下,Redis 能夠自動進(jìn)行故障檢測、master 選舉、故障轉(zhuǎn)移。
MOVED錯誤
通過上面的介紹和架構(gòu)圖,我們知道客戶端只會連接到某個節(jié)點(diǎn)上,但是該節(jié)點(diǎn)只負(fù)責(zé)部分槽,萬一客戶端請求的是其他槽怎么辦?
Redis 引入 MOVED 錯誤來解決這個問題。
當(dāng)客戶端向節(jié)點(diǎn)發(fā)送與數(shù)據(jù)庫鍵有關(guān)的命令時,接收命令的節(jié)點(diǎn)會計算出要處理的數(shù)據(jù)庫鍵屬于哪個槽,并檢查這個槽是否是自己負(fù)責(zé)的。
如果鍵所在的槽正好是自己負(fù)責(zé),那么節(jié)點(diǎn)直接執(zhí)行這個命令。
否則,節(jié)點(diǎn)會向客戶端返回一個 MOVED 錯誤,該命令可以指引客戶端轉(zhuǎn)向(redirect)正確的節(jié)點(diǎn),并再次發(fā)送之前想要執(zhí)行的命令,得到正確的結(jié)果。
集群的主從復(fù)制
集群的每個分片中使用了主從復(fù)制來保證高可用,這邊的主從復(fù)制邏輯也是直接復(fù)用的之前的主從復(fù)制模式的邏輯。
紀(jì)元(epoch)
Redis 集群中使用了類似于 Raft 算法 term(任期)的概念稱為 epoch(紀(jì)元),用來給事件增加版本號。
Redis 集群中的紀(jì)元主要是兩種:currentEpoch 和 configEpoch。
currentEpoch
集群當(dāng)前的配置紀(jì)元,這是一個集群狀態(tài)相關(guān)的概念,可以當(dāng)做記錄集群狀態(tài)變更的遞增版本號。
currentEpoch 作用在于,當(dāng)集群的狀態(tài)發(fā)生改變,某個節(jié)點(diǎn)為了執(zhí)行一些動作需要尋求其他節(jié)點(diǎn)的同意時,就會增加 currentEpoch 的值,例如故障轉(zhuǎn)移流程。
當(dāng)從節(jié)點(diǎn) A 發(fā)現(xiàn)其所屬的主節(jié)點(diǎn)下線時,就會試圖發(fā)起故障轉(zhuǎn)移流程。首先就是增加 currentEpoch 的值,這個增加后的 currentEpoch 是所有集群節(jié)點(diǎn)中最大的。然后從節(jié)點(diǎn)A向所有節(jié)點(diǎn)發(fā)包用于拉票,請求其他主節(jié)點(diǎn)投票給自己,使自己能成為新的主節(jié)點(diǎn)。
其他節(jié)點(diǎn)收到包后,發(fā)現(xiàn)發(fā)送者的 currentEpoch 比自己的 currentEpoch 大,就會更新自己的 currentEpoch,并在尚未投票的情況下,投票給從節(jié)點(diǎn) A,表示同意使其成為新的主節(jié)點(diǎn)。
configEpoch
節(jié)點(diǎn)當(dāng)前的配置紀(jì)元,這是一個集群節(jié)點(diǎn)配置相關(guān)的概念,每個集群節(jié)點(diǎn)都有自己獨(dú)一無二的 configepoch。所謂的節(jié)點(diǎn)配置,實際上是指節(jié)點(diǎn)所負(fù)責(zé)的槽位信息。
每一個 master 在向其他節(jié)點(diǎn)發(fā)送消息時,都會附帶其 configEpoch 信息,以及一份表示它所負(fù)責(zé)的 slots 信息。
節(jié)點(diǎn)收到消息之后,就會根據(jù)消息中的 configEpoch 和負(fù)責(zé)的 slots 信息,記錄到相應(yīng)節(jié)點(diǎn)屬性中。這邊有兩種情況:
1)如果該消息中的 slots 在當(dāng)前節(jié)點(diǎn)中被記錄為還未有節(jié)點(diǎn)負(fù)責(zé),那可以直接指定為發(fā)送消息的節(jié)點(diǎn)。
2)如果消息中的 slots 在當(dāng)前節(jié)點(diǎn)已經(jīng)被記錄為有節(jié)點(diǎn)負(fù)責(zé),這種情況相當(dāng)于有多個節(jié)點(diǎn)都宣稱他負(fù)責(zé)了某個 slot,那怎么處理了?
這時候就要用到 configEpoch,configEpoch 更大的說明是更新的配置,當(dāng)前節(jié)點(diǎn)會使用 configEpoch 更大的配置。
?
多個節(jié)點(diǎn)宣稱負(fù)責(zé)同一個 slot 最常見的場景就是故障轉(zhuǎn)移之后。當(dāng)故障的主節(jié)點(diǎn)重新連接時,他會向集群其他節(jié)點(diǎn)發(fā)送消息,會帶上自己故障前負(fù)責(zé)的 slots 信息,當(dāng)其他節(jié)點(diǎn)收到后判斷該節(jié)點(diǎn)的?configEpoch?更小,知道是舊的配置信息,則不會進(jìn)行更新。
節(jié)點(diǎn)的 configEpoch 會在自己當(dāng)選為新的主節(jié)點(diǎn)的時候,更新為集群當(dāng)前選舉的紀(jì)元,其實也就是 currentEpoch 的值。
因為每一次選舉只會有一個從節(jié)點(diǎn)當(dāng)選為新的主節(jié)點(diǎn),所以該從節(jié)點(diǎn)的 configEpoch 會是當(dāng)前所有集群節(jié)點(diǎn) configEpoch 中的最大值。這樣,該從節(jié)點(diǎn)成為主節(jié)點(diǎn)后,就會向所有節(jié)點(diǎn)發(fā)送廣播包,強(qiáng)制其他節(jié)點(diǎn)更新相關(guān)槽位的負(fù)責(zé)節(jié)點(diǎn)為自己。
集群故障檢測
本節(jié)與哨兵的故障核心思想是相同的。
集群中的每個節(jié)點(diǎn)都會定期地向集群中的其他節(jié)點(diǎn)發(fā)送 PING 消息,以此來檢測對方是否在線。
集群節(jié)點(diǎn)間互相發(fā)送 PING 檢測的時機(jī),目前看主要有以下兩個:
1、每秒執(zhí)行1次:隨機(jī)檢查5個節(jié)點(diǎn),選出最早收到 PONG 回復(fù)的節(jié)點(diǎn),也就是最久沒有通信過的節(jié)點(diǎn),發(fā)送 PING 消息。
2、每100毫秒執(zhí)行1次:輪詢集群的節(jié)點(diǎn),對于那些鏈接正常的節(jié)點(diǎn),如果上一次收到該節(jié)點(diǎn)的 PONG 回復(fù)時間距離現(xiàn)在已經(jīng)超過集群超時時間的一半(server.cluster_node_timeout/2),則直接向該節(jié)點(diǎn)發(fā)送 PING。
如果接收 PING 消息的節(jié)點(diǎn)在規(guī)定的時間內(nèi)(cluster_node_timeout,默認(rèn)15秒),沒有向發(fā)送 PING 消息的節(jié)點(diǎn)返回 PONG 回復(fù)或者發(fā)送其他任何消息,那么發(fā)送 PING 消息的節(jié)點(diǎn)就會將接收 PING 消息的節(jié)點(diǎn)標(biāo)記為疑似下線(probable failure,PFAIL)。
這邊 Redis 沒有將 PONG 回復(fù)作為目標(biāo)節(jié)點(diǎn)存活的唯一證明,而是將目標(biāo)節(jié)點(diǎn)的任何消息都作為存活的證明。這是因為在集群負(fù)載較高的時候,收到 PONG 回復(fù)可能會出現(xiàn)延遲。
集群中的各個節(jié)點(diǎn)在向其他節(jié)點(diǎn)發(fā)送 PING(PONG、MEET)消息的時候,會附加上 Gossip(八卦)消息,Gossip 消息記錄了集群中其他節(jié)點(diǎn)的狀態(tài)信息,例如某個節(jié)點(diǎn)是處于在線狀態(tài)、疑似下線狀態(tài)(PFAIL),還是已下線狀態(tài)(FAIL)。
Gossip 消息包含兩部分:
1)正常節(jié)點(diǎn)的狀態(tài)信息:隨機(jī)選擇集群節(jié)點(diǎn)數(shù)的 1/10,但是不能小于3,除非目標(biāo)集群節(jié)點(diǎn)中正常的數(shù)量已經(jīng)小于3。
2)被標(biāo)記為 PFAIL 的節(jié)點(diǎn)信息會被全部添加到 Gossip 消息中。
當(dāng)主節(jié)點(diǎn) A 通過 Gossip?消息得知主節(jié)點(diǎn) B 認(rèn)為主節(jié)點(diǎn) C 進(jìn)入了 PFAIL 或 FAIL 狀態(tài)時,主節(jié)點(diǎn) A 會在自己的 clusterState.nodes 字典中找到主節(jié)點(diǎn) C 對應(yīng)的 clusterNode 結(jié)構(gòu),并將主節(jié)點(diǎn) C 的故障報告(failure report)添加到 clusterNode 結(jié)構(gòu)的 fail_reports 鏈表中。
這樣,主節(jié)點(diǎn) A 就可以通過主節(jié)點(diǎn) C 的 clusterNode->fail_reports 鏈表快速計算出有多少個節(jié)點(diǎn)將主節(jié)點(diǎn) C 標(biāo)記為 PFAIL 狀態(tài)。
當(dāng)主節(jié)點(diǎn) A 為主節(jié)點(diǎn) C 新增故障報告的時候,會順帶檢查是否需要將主節(jié)點(diǎn) C 標(biāo)記為 FAIL,如果通過 fail_reports 鏈表發(fā)現(xiàn)主節(jié)點(diǎn) C 被半數(shù)以上負(fù)責(zé)處理槽的主節(jié)點(diǎn)標(biāo)記為疑似下線(PFAIL),則會進(jìn)一步將主節(jié)點(diǎn) C 標(biāo)記為已下線(FAIL),同時向集群廣播 “主節(jié)點(diǎn) C 已經(jīng) FAIL 的消息”,所有收到消息的節(jié)點(diǎn)都會立即將主節(jié)點(diǎn) C 標(biāo)記為已下線。
集群故障轉(zhuǎn)移
當(dāng) slave 發(fā)現(xiàn)自己正在復(fù)制的 master 進(jìn)入了已下線(FAIL)狀態(tài),slave 會對下線的 master 進(jìn)行故障轉(zhuǎn)移,以下是故障轉(zhuǎn)移的執(zhí)行步驟:
1、發(fā)起一次選舉,該下線的 master 的所有 slave 里面,會有一個 slave 被選中。
2、被選中的 slave 會升級為新的 master,清除 slave 相關(guān)的信息:slave 標(biāo)記位等。
3、新的 master 會撤銷所有對已下線 master 的槽指派,并將這些槽全部指派給自己。
4、新的 master 向集群廣播一條 PONG 消息,這條 PONG 消息可以讓集群中的其他節(jié)點(diǎn)立即知道這個節(jié)點(diǎn)已經(jīng)由 slave 變成了 master ,并且這個新的 master 已經(jīng)接管了原本由已下線節(jié)點(diǎn)負(fù)責(zé)處理的槽。集群中的其他節(jié)點(diǎn)收到消息后會更新自己保存的相關(guān)配置信息。
5、新的 master 開始接收和自己負(fù)責(zé)處理的槽有關(guān)的命令請求,故障轉(zhuǎn)移完成。
集群選舉
故障轉(zhuǎn)移的第一步就是選舉出新的主節(jié)點(diǎn),以下是集群選舉新的主節(jié)點(diǎn)的方法:
1、當(dāng)從節(jié)點(diǎn)發(fā)現(xiàn)自己正在復(fù)制的主節(jié)點(diǎn)進(jìn)入已下線狀態(tài)時,會發(fā)起一次選舉:將 currentEpoch 加1,然后向集群廣播一條 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 消息,要求所有收到這條消息、并且具有投票權(quán)的主節(jié)點(diǎn)向這個從節(jié)點(diǎn)投票。
2、其他節(jié)點(diǎn)收到消息后,會判斷是否要給發(fā)送消息的節(jié)點(diǎn)投票,判斷流程如下:
當(dāng)前節(jié)點(diǎn)是 slave,或者當(dāng)前節(jié)點(diǎn)是 master,但是不負(fù)責(zé)處理槽,則當(dāng)前節(jié)點(diǎn)沒有投票權(quán),直接返回。
請求節(jié)點(diǎn)的 currentEpoch 小于當(dāng)前節(jié)點(diǎn)的 currentEpoch,校驗失敗返回。因為發(fā)送者的狀態(tài)與當(dāng)前集群狀態(tài)不一致,可能是長時間下線的節(jié)點(diǎn)剛剛上線,這種情況下,直接返回即可。
當(dāng)前節(jié)點(diǎn)在該 currentEpoch 已經(jīng)投過票,校驗失敗返回。
請求節(jié)點(diǎn)是 master,校驗失敗返回。
請求節(jié)點(diǎn)的 master 為空,校驗失敗返回。
請求節(jié)點(diǎn)的 master 沒有故障,并且不是手動故障轉(zhuǎn)移,校驗失敗返回。因為手動故障轉(zhuǎn)移是可以在 master 正常的情況下直接發(fā)起的。
上一次為該master的投票時間,在cluster_node_timeout的2倍范圍內(nèi),校驗失敗返回。這個用于使獲勝從節(jié)點(diǎn)有時間將其成為新主節(jié)點(diǎn)的消息通知給其他從節(jié)點(diǎn),從而避免另一個從節(jié)點(diǎn)發(fā)起新一輪選舉又進(jìn)行一次沒必要的故障轉(zhuǎn)移
請求節(jié)點(diǎn)宣稱要負(fù)責(zé)的槽位,是否比之前負(fù)責(zé)這些槽位的節(jié)點(diǎn),具有相等或更大的 configEpoch,如果不是,校驗失敗返回。
如果通過以上所有校驗,那么主節(jié)點(diǎn)將向要求投票的從節(jié)點(diǎn)返回一條 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 消息,表示這個主節(jié)點(diǎn)支持從節(jié)點(diǎn)成為新的主節(jié)點(diǎn)。
3、每個參與選舉的從節(jié)點(diǎn)都會接收 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 消息,并根據(jù)自己收到了多少條這種消息來統(tǒng)計自己獲得了多少個主節(jié)點(diǎn)的支持。
4、如果集群里有N個具有投票權(quán)的主節(jié)點(diǎn),那么當(dāng)一個從節(jié)點(diǎn)收集到大于等于N/2+1 張支持票時,這個從節(jié)點(diǎn)就會當(dāng)選為新的主節(jié)點(diǎn)。因為在每一個配置紀(jì)元里面,每個具有投票權(quán)的主節(jié)點(diǎn)只能投一次票,所以如果有 N個主節(jié)點(diǎn)進(jìn)行投票,那么具有大于等于 N/2+1 張支持票的從節(jié)點(diǎn)只會有一個,這確保了新的主節(jié)點(diǎn)只會有一個。
5、如果在一個配置紀(jì)元里面沒有從節(jié)點(diǎn)能收集到足夠多的支持票,那么集群進(jìn)入一個新的配置紀(jì)元,并再次進(jìn)行選舉,直到選出新的主節(jié)點(diǎn)為止。
這個選舉新主節(jié)點(diǎn)的方法和選舉領(lǐng)頭 Sentinel 的方法非常相似,因為兩者都是基于 Raft 算法的領(lǐng)頭選舉(leader election)方法來實現(xiàn)的。
如何保證集群在線擴(kuò)容的安全性?
例如:集群已經(jīng)對外提供服務(wù),原來有3分片,準(zhǔn)備新增2個分片,怎么在不下線的情況下,無損的從原有的3個分片指派若干個槽給這2個分片?
Redis 使用了 ASK 錯誤來保證在線擴(kuò)容的安全性。
在槽的遷移過程中若有客戶端訪問,依舊先訪問源節(jié)點(diǎn),源節(jié)點(diǎn)會先在自己的數(shù)據(jù)庫里面査找指定的鍵,如果找到的話,就直接執(zhí)行客戶端發(fā)送的命令。
如果沒找到,說明該鍵可能已經(jīng)被遷移到目標(biāo)節(jié)點(diǎn)了,源節(jié)點(diǎn)將向客戶端返回一個 ASK 錯誤,該錯誤會指引客戶端轉(zhuǎn)向正在導(dǎo)入槽的目標(biāo)節(jié)點(diǎn),并再次發(fā)送之前想要執(zhí)行的命令,從而獲取到結(jié)果。
ASK錯誤
在進(jìn)行重新分片期間,源節(jié)點(diǎn)向目標(biāo)節(jié)點(diǎn)遷移一個槽的過程中,可能會出現(xiàn)這樣一種情況:屬于被遷移槽的一部分鍵值對保存在源節(jié)點(diǎn)里面,而另一部分鍵值對則保存在目標(biāo)節(jié)點(diǎn)里面。
當(dāng)客戶端向源節(jié)點(diǎn)發(fā)送一個與數(shù)據(jù)庫鍵有關(guān)的命令,并且命令要處理的數(shù)據(jù)庫鍵恰好就屬于正在被遷移的槽時。源節(jié)點(diǎn)會先在自己的數(shù)據(jù)庫里面査找指定的鍵,如果找到的話,就直接執(zhí)行客戶端發(fā)送的命令。
否則,這個鍵有可能已經(jīng)被遷移到了目標(biāo)節(jié)點(diǎn),源節(jié)點(diǎn)將向客戶端返回一個 ASK 錯誤,指引客戶端轉(zhuǎn)向正在導(dǎo)入槽的目標(biāo)節(jié)點(diǎn),并再次發(fā)送之前想要執(zhí)行的命令,從而獲取到結(jié)果。
MOVED和ASK的區(qū)別
從上面的介紹來看 MOVED 錯誤和 ASK 錯誤非常類似,都起到重定向客戶端的效果,他們有什么區(qū)別?能否合并成一個?
MOVED 錯誤代表槽位的負(fù)責(zé)權(quán)已經(jīng)從一個節(jié)點(diǎn)轉(zhuǎn)移到了另一個節(jié)點(diǎn):在客戶端收到關(guān)于槽位 k 的MOVED 錯誤之后,會更新槽位 k 及其負(fù)責(zé)節(jié)點(diǎn)的對應(yīng)關(guān)系,這樣下次遇到關(guān)于槽位 k 的命令請求時,就可以直接將命令請求發(fā)送新的負(fù)責(zé)節(jié)點(diǎn)。
ASK 錯誤只是兩個節(jié)點(diǎn)在遷移槽的過程中使用的一種臨時措施:客戶端收到關(guān)于槽位 k 的 ASK 錯誤之后,客戶端只會在接下來的一次命令請求中將關(guān)于槽位 k 的命令請求發(fā)送至 ASK 錯誤所指示的節(jié)點(diǎn),但這種重定向不會對客戶端今后發(fā)送關(guān)于槽位 k 的命令請求產(chǎn)生任何影響,客戶端之后仍然會將關(guān)于槽位 k 的命令請求發(fā)送至目前負(fù)責(zé)處理 k 槽位的節(jié)點(diǎn),除非 ASK 錯誤再次出現(xiàn)。
總結(jié)就是:
1)ASK 是一種遷移槽臨時措施,只是會產(chǎn)生一次重定向
2)MOVED 代表該槽已經(jīng)完全由另一個節(jié)點(diǎn)負(fù)責(zé)了,會觸發(fā)客戶端刷新本地路由表,之后對于該槽的請求都會請求新的節(jié)點(diǎn)。
這邊提到的本地路由表是該集群的插槽和負(fù)責(zé)處理該槽的節(jié)點(diǎn)地址的映射,通過該路由表客戶端可以在大部分情況下都直接請求到正確的節(jié)點(diǎn),而無需重定向,從而提升性能。
數(shù)據(jù)丟失場景:腦裂(split-brain)
腦裂是導(dǎo)致 Redis 產(chǎn)生數(shù)據(jù)丟失比較常見的場景。如下例子:
集群有3個節(jié)點(diǎn),每個節(jié)點(diǎn)采用1主2從,如下圖所示,紅色圈代表出現(xiàn)了網(wǎng)絡(luò)分區(qū)故障。
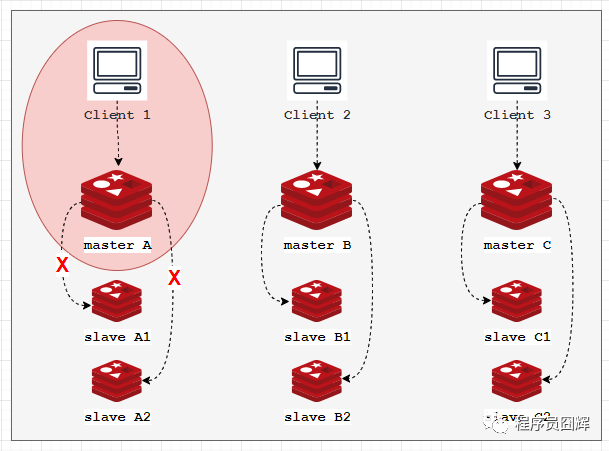
當(dāng)主節(jié)點(diǎn) A 與集群中其他節(jié)點(diǎn)出現(xiàn)網(wǎng)絡(luò)分區(qū)故障時,此時集群會分為2個分區(qū),“少數(shù)派”:節(jié)點(diǎn) A;多數(shù)派:節(jié)點(diǎn) A1、A2、B、B1、B2、C、C1、C2。
由于集群節(jié)點(diǎn)之間的故障檢測需要一定時間,通常是 cluster_node_timeout,因此在 cluster_node_timeout 期間內(nèi) Client1 仍然可以向節(jié)點(diǎn) A 發(fā)出寫命令,但此時由于網(wǎng)絡(luò)分區(qū)節(jié)點(diǎn) A 已經(jīng)無法通過異步復(fù)制將命令傳播到節(jié)點(diǎn) A1 和 A2。
如果節(jié)點(diǎn) A 在 cluster_node_timeout 內(nèi)仍然無法恢復(fù),則集群 “多數(shù)派” 這邊會發(fā)起故障轉(zhuǎn)移,選擇 A1 和 A2 中的一個升級為新的 master,對外提供服務(wù)。
與此同時,節(jié)點(diǎn) A 所在的 “少數(shù)派” 由于在 cluster_node_timeout 內(nèi)無法檢測到與其他節(jié)點(diǎn)的心跳,此時也會開始拒絕對外提供服務(wù)。
當(dāng)網(wǎng)絡(luò)分區(qū)故障恢復(fù)后,由于新 master 擁有更高的配置紀(jì)元,此時節(jié)點(diǎn) A 會被降級為 slave,清空自身數(shù)據(jù),然后復(fù)制新的 master。此時,節(jié)點(diǎn) A 在網(wǎng)絡(luò)分區(qū)故障期間處理的寫命令就全部丟失了。
最后
當(dāng)你的才華還撐不起你的野心的時候,你就應(yīng)該靜下心來學(xué)習(xí),愿你在我這里能有所收獲。
原創(chuàng)不易,如果你覺得本文寫的還不錯,對你有幫助,請通過【點(diǎn)贊】讓我知道,支持我寫出更好的文章。
推薦閱讀
面試必問的 Redis:數(shù)據(jù)結(jié)構(gòu)和基礎(chǔ)概念
兩年Java開發(fā)工作經(jīng)驗面試總結(jié)
4 年 Java 經(jīng)驗面試總結(jié)、心得體會