
思考 | 怎樣的視覺識別算法才是完整的?
如果有不同見解,或者發(fā)現(xiàn)我這個想法已經(jīng)被前人提出過,請以任何一種方式告訴我,非常感謝!
初稿的鏈接:arxiv.org/abs/2105.1397

0. 鋪墊部分
視覺識別,是計算機視覺領域最重要的任務。雖然深度學習技術給這個領域帶來了深遠的影響,許多任務的SOTA相比于十年前也已經(jīng)是突飛猛進,但就目前來看,還沒有任何一套方法能夠在一般意義上解決識別問題。當前算法的不足之處有很多,而學界較為公認的未來發(fā)展方向主要分為數(shù)據(jù)、模型、知識三大方面。其中,知識是一個相對模糊的概念,迄今學界還沒有準確清晰的定義。而數(shù)據(jù)和模型,則構成了當前大部分視覺算法的主要困難。
回顧過去一年,在視覺識別領域,有兩類方法得到了廣泛的重視。一個是自監(jiān)督學習,嘗試從數(shù)據(jù)的角度來提升算法的泛化性能;一個是Transformer,嘗試引入新型模型設計,提升神經(jīng)網(wǎng)絡的擬合能力和泛化能力。這兩類方法確實為視覺識別提供了種種新線索,但是它們也很快展現(xiàn)出了各自的局限性。
在拼命內(nèi)卷、忙于刷新各種指標的間隙,我時常會問自己一個問題:計算機視覺領域,有沒有一些被忽視,卻十分重要的問題?在一段時間的思考以后,我在數(shù)據(jù)和模型層面都有了一些不成熟的idea。今天寫寫數(shù)據(jù)方面的想法,未來有機會,再寫寫模型方面(更不成熟)的想法。
下面進入正題。
1. 研究動機
開門見山,我研究的主要動機是在標題中提出的問題:怎樣的視覺識別算法才是完整的?這里我對“完整”的定義是:識別出所有人類無需專門記憶就能夠識別的內(nèi)容。
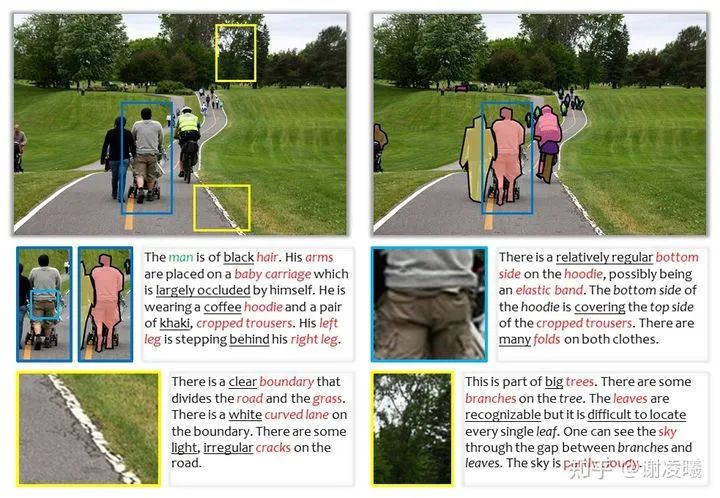
我們以上述圖片為例。這是一張來自MS-COCO數(shù)據(jù)集的圖片,主要包含“人”這一類別。雖然MS-COCO已經(jīng)提供了像素級標注——幾乎是當前能夠獲取的最精細級別,然而還是有大量的語義信息無法被標注出來。更加重要的事實是:即使提供足夠的人力成本,我們也很難定義出一套規(guī)范的標準,完成“所有語義信息”的標注。舉個例子:當我們標注出“人”以后,還可以進一步標注“手臂”,進而標注“手”、“手指”、“指節(jié)”、“指紋”,甚至是“指紋上的缺口”。即使某些語義信息已經(jīng)到達“子像素級”,只要人類愿意,就可以通過語言、刻畫等某種方式,將它從圖像中識別出來。
通過上述例子,我們可以得出以下兩個結(jié)論:
我們難以定義人類識別能力的極限——雖然對大多數(shù)人而言,這個極限應當是差不太多的
當前計算機視覺能夠通過標注獲取的監(jiān)督信號,遠遠低于這個極限——即使投入大量人力,也很難逼近這個極限
于是我認為:要想得到完整的識別結(jié)果,就不能依靠人工標注來學習。那靠什么呢?我認為應該靠數(shù)據(jù)壓縮。認知科學的實驗提供了一條重要的線索:人類在識別圖像時,往往傾向于最省事的做法:也就是說,人類會尋找一種最容易記憶的形式,而識別只是為了方便壓縮而做的一種量化。
沿著這條思路,我設計出了下面的預訓練任務。
2. 通過壓縮來學習(learning-by-compression)
這個概念是相對于“通過標注來學習”(learning-by-compression)而言的。當然實現(xiàn)要說明的是,這個概念并不新:早年的autoencoder就是建立在類似的思想上的。如果想看related work,可以參考原文。這里想要強調(diào)的是,我們重新提出這個概念,是基于“標簽學習”無法解決上述gap的判斷。而我們的提議和autoencoder類方法最大的不同,恰恰在于我們把重心從網(wǎng)絡結(jié)構的設計轉(zhuǎn)到對圖像恢復質(zhì)量的評估上。
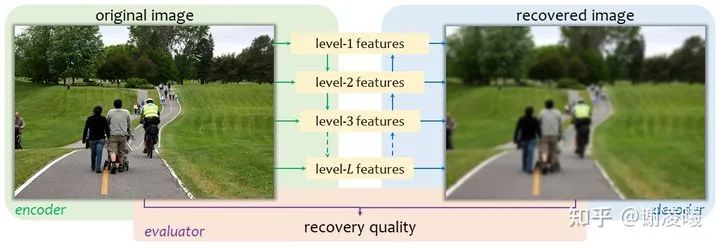
如上圖所示,我們的設想很簡單:一張圖像通過編碼器壓縮成維度盡可能低的向量,再通過解碼器恢復成與原圖差距盡可能小的圖像。其中編碼器和解碼器都可以是標準的神經(jīng)網(wǎng)絡(不限定于CNN或者Transformer),而評估器既可以是自主學習的神經(jīng)網(wǎng)絡,也可以是預先定義的函數(shù),甚至可以通過human-in-the-loop的方式來設計。后面我們會說到,評估器是整個框架中最難設計的模塊,也是當前阻止我們把這個idea變成現(xiàn)實的最大障礙。
用幾個小點,來解釋這樣做的目的:
我們的假設是:如果能夠設計出一對編碼器和解碼器,使得輸入圖像能夠被壓縮成盡可能短的向量,同時這個低維向量能夠用于生成高質(zhì)量的輸出,那么我們就認為編碼器和解碼器只有一條路可走——學習高效的語義特征,并以此對圖像進行編解碼。
如果壓縮率足夠高,那么算法一定無法準確地恢復原圖的所有細節(jié)。這看似與“完整的視覺識別結(jié)果”相矛盾,但我們可以通過調(diào)節(jié)壓縮率(比如在編碼器和解碼器之間插入一些線性映射層,詳見原文)來控制恢復的質(zhì)量。于是,只要有一個合理的評估器,我們就可以在任何一對編碼器和解碼器上,得到一組壓縮率和恢復質(zhì)量的tradeoff,如下圖所示。
順便要指出:天下沒有免費的午餐。追求更高的壓縮率和恢復質(zhì)量的tradeoff,就意味著編碼器和解碼器存儲了更多視覺特征(可以理解為更大的視覺詞典),以供算法調(diào)取。這也就為當前盛行的視覺預訓練大模型提供了另一種視角。
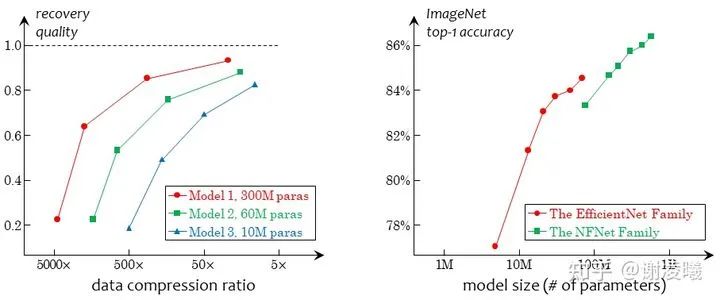
最后,如果我的設想成真,那么業(yè)界的注意力會更多地轉(zhuǎn)向追求上圖左邊的tradeoff而不是右邊。雖然右邊也很重要,但我認為左邊或許更接近本質(zhì)一些。
3. 評估算法的困難
上述自監(jiān)督學習算法,都建立在一個合理的評估函數(shù)上。然而我們不難想象,這個評估函數(shù)是很難設計的。我們知道,人類的對圖像的理解是層次化的。在能夠存儲的信息很少(即壓縮率很高)的情況下,人類往往傾向于關注圖像的全局信息,而忽略圖像的細節(jié)。僅就滿足這一特性而言,要設計出合理的評估函數(shù),就十分困難。我大膽地猜測:設計這個評估函數(shù)的難度,甚至不亞于視覺識別問題本身。也就是說,某種意義上看,設計評估函數(shù)能夠提供視覺識別問題的另一種視角,或者啟發(fā)些新的思路。

這里順帶說明,以autoencoder為代表的算法,大多建立在無差別地恢復圖像像素的基礎上,而這并不是我們想要達到的效果。換句話說,既然已經(jīng)決定壓縮數(shù)據(jù),就不應指望能夠恢復出所有細節(jié)來。于是,我設想了幾種評估算法的可能性:
語義弱監(jiān)督:如果在龐大的預訓練數(shù)據(jù)集中,部分圖像被賦予了語義標簽,那么這些圖像就可以用語義層面的監(jiān)督來度量相似度。舉例說,如果恢復前后的圖像在某個檢測算法上的結(jié)果一致,那么就可以粗略地認為,恢復算法保留了一定的語義信息。原文中,我還根據(jù)這個思路設想了一個迭代算法,此處不再展開。
利用human-in-the-loop的思路:即將人類的反饋機制引入訓練過程,在需要評估恢復圖像的時候,讓受試者指出幾張圖像中恢復較好的或者恢復較差的圖,或者指出一張圖像上恢復較好的或者恢復較差的區(qū)域。這些反饋可以作為弱監(jiān)督信息,讓算法不斷迭代。
當然我們要強調(diào),上述兩個方案都不是完美的。語義監(jiān)督方面,從我們的研究動機就知道,所有語義信息都只能提供有偏的弱監(jiān)督,因而不可能從頭到尾訓練一個高效模型;而利用人類反饋,則需要大量的人力勞動,同時隨著訓練的進行,受試者將越來越難以客觀地區(qū)分恢復效果的好壞,因而導致預訓練過程出現(xiàn)瓶頸。
4. 下游任務的應用
如果上述算法得以實現(xiàn),那么我們將得到一個通用的視覺預訓練模型。由于這一模型不偏向任何特定的識別算法,且它同時包含編碼器和解碼器,我們就可以用它來完成各種下游任務。
如果要做分類或者檢測,直接繼承編碼器,加上輕量級的head做微調(diào)即可
如果要做分割,同時繼承編碼器和解碼器,并且對解碼器做微調(diào)即可——在高壓縮率的驅(qū)動下,編碼器和解碼器將更擅長將不同物體區(qū)分開來,否則難以生成出高質(zhì)量的圖片
如果要做底層視覺任務(如圖像超分),同時繼承編碼器和解碼器,并且在合理的位置插入一些shortcut連接,微調(diào)解碼器即可
如果要做圖像生成任務,直接繼承解碼器的分布和解碼器的權重,采樣生成即可;如果是有條件的生成任務,可以事先將編碼器進行微調(diào),以適應給定的分布
最有趣的應用是視頻識別:視頻數(shù)據(jù)比圖像數(shù)據(jù)的維度更高,也更難學習;為此可以設計兩階段的特征學習方法:利用上述的編碼器逐幀抽取特征,再將序列特征送入時序模型(如seq2seq或Transformer)進行進一步壓縮,以期得到適合視頻識別的預訓練模型
……
當然,在現(xiàn)階段,這些還都無法成為現(xiàn)實。
5. 總結(jié)和展望
我們首先指出,當前所有視覺識別任務,距離完整識別還有相當大的距離,而且這一鴻溝難以通過增加標注量和標注粒度來跨越。基于這一判斷,我們提出了一個新的視覺預訓練任務,即通過壓縮來學習(learning by compression)。這個任務的難度主要體現(xiàn)在評估函數(shù)上,而我們甚至認為,這也許是視覺本質(zhì)問題的另一種表現(xiàn)形式,或許能夠提供新穎的思路。
面向未來,我們認為大規(guī)模預訓練模型是計算機視覺乃至整個人工智能領域的大勢所趨。然而當前的預訓練模型還比較笨重,除了用于抽取強有力特征外,并沒有一個完整的pipeline去釋放它們的能力。更重要的是,大模型預訓練和小樣本微調(diào),似乎有著天然的沖突:大模型希望看到更general的數(shù)據(jù)分布,在均攤意義上追求最優(yōu)解;而小樣本則往往針對一個特定的領域,在單點上追求最優(yōu)解。于是,模型規(guī)模越大,微調(diào)的難度就越大——現(xiàn)在的大模型更多地是說服下游應用無需微調(diào),而對于下游domain相差較大的場景,往往就難以取得良好的效果。這一點,也是AI部署算法需要著力解決的問題。
聲明:部分內(nèi)容來源于網(wǎng)絡,僅供讀者學術交流之目的。文章版權歸原作者所有。如有不妥,請聯(lián)系刪除。
---END---
雙一流大學研究生團隊創(chuàng)建,一個專注于目標檢測與深度學習的組織,希望可以將分享變成一種習慣。
由于微信公眾號試行亂序推送,您可能不再能第一時間收到「目標檢測與深度學習」的消息。可以的話,將公眾號設為星標★,并點擊右下角“在看“,可第一時間收到我們的最新分享。
整理不易,點贊三連↓