
掌握pandas中的時(shí)序數(shù)據(jù)分組運(yùn)算

點(diǎn)擊上方"藍(lán)字"關(guān)注我們
記錄? ?分享? ?成長
?本文示例代碼及文件已上傳至我的
?Github倉庫https://github.com/CNFeffery/DataScienceStudyNotes
1 簡介
我們在使用pandas分析處理時(shí)間序列數(shù)據(jù)時(shí),經(jīng)常需要對原始時(shí)間粒度下的數(shù)據(jù),按照不同的時(shí)間粒度進(jìn)行分組聚合運(yùn)算,譬如基于每個(gè)交易日的股票收盤價(jià),計(jì)算每個(gè)月的最低和最高收盤價(jià)。
而在pandas中,針對不同的應(yīng)用場景,我們可以使用resample()、groupby()以及Grouper()來非常高效快捷地完成此類任務(wù)。

2 在pandas中進(jìn)行時(shí)間分組聚合
在pandas中根據(jù)具體任務(wù)場景的不同,對時(shí)間序列進(jìn)行分組聚合可通過以下兩類方式實(shí)現(xiàn):
2.1 利用resample()對時(shí)序數(shù)據(jù)進(jìn)行分組聚合
resample原始的意思是「重采樣」,可分為「上采樣」與「下采樣」,而我們通常情況下使用的都是「下采樣」,也就是從高頻的數(shù)據(jù)中按照一定規(guī)則計(jì)算出更低頻的數(shù)據(jù),就像我們一開始說的對每日數(shù)據(jù)按月匯總那樣。
如果你熟悉pandas中的groupby()分組運(yùn)算,那么你就可以很快地理解resample()的使用方式,它本質(zhì)上就是在對時(shí)間序列數(shù)據(jù)進(jìn)行“分組”,最基礎(chǔ)的參數(shù)為rule,用于設(shè)置按照何種方式進(jìn)行重采樣,就像下面的例子那樣:
import?pandas?as?pd
#?記錄了2013-02-08到2018-02-07之間每個(gè)交易日蘋果公司的股價(jià)
AAPL?=?pd.read_csv('AAPL.csv',?parse_dates=['date'])
#?以月為統(tǒng)計(jì)窗口計(jì)算每月股票最高收盤價(jià)
(
????AAPL
????.set_index('date')?#?設(shè)置date為index
????.resample('M')?#?以月為單位
????.agg({
????????'close':?['max',?'min']
????})
)

可以看到,在上面的例子中,我們對index為日期時(shí)間類型的DataFrame應(yīng)用resample()方法,傳入的參數(shù)'M'是resample第一個(gè)位置上的參數(shù)rule,用于確定時(shí)間窗口的規(guī)則,譬如這里的字符串'M'就代表「月且聚合結(jié)果中顯示對應(yīng)月的最后一天」,常用的固化的時(shí)間窗口規(guī)則如下表所示:
| 規(guī)則 | 說明 |
|---|---|
| W | 星期 |
| M | 月,顯示為當(dāng)月最后一天 |
| MS | 月,顯示為當(dāng)月第一天 |
| Q | 季度,顯示為當(dāng)季最后一天 |
| QS | 季度,顯示為當(dāng)季第一天 |
| A | 年,顯示為當(dāng)年最后一天 |
| AS | 年,顯示為當(dāng)年第一天 |
| D | 日 |
| H | 小時(shí)T |
| T或min | 分鐘 |
| S | 秒 |
| L或 ms | 毫秒 |
且這些規(guī)則都可以在前面添加數(shù)字實(shí)現(xiàn)倍數(shù)效果:
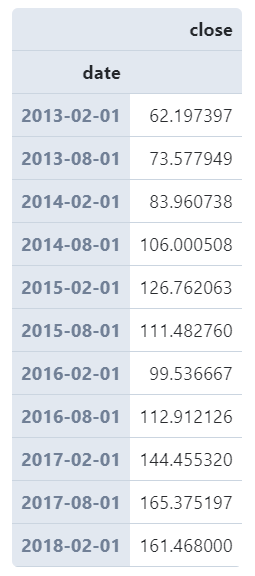
#?以6個(gè)月為統(tǒng)計(jì)窗口計(jì)算每月股票平均收盤價(jià)且顯示為當(dāng)月第一天
(
????AAPL
????.set_index('date')?#?設(shè)置date為index
????.resample('6MS')?#?以6個(gè)月為單位
????.agg({
????????'close':?'mean'
????})
)
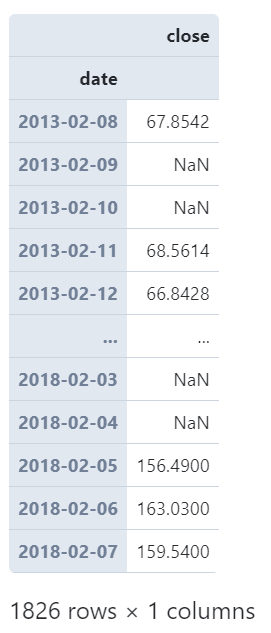
且resample()非常貼心之處在于它會自動幫你對齊到規(guī)整的時(shí)間單位上,譬如我們這里只有交易日才會有記錄,如果我們設(shè)置的時(shí)間單位下無對應(yīng)記錄,也會為你保留帶有缺失值記錄的時(shí)間點(diǎn):
(
????AAPL
????.set_index('date')?#?設(shè)置date為index
????.resample('1D')?#?以1日為單位
????.agg({
????????'close':?'mean'
????})
)
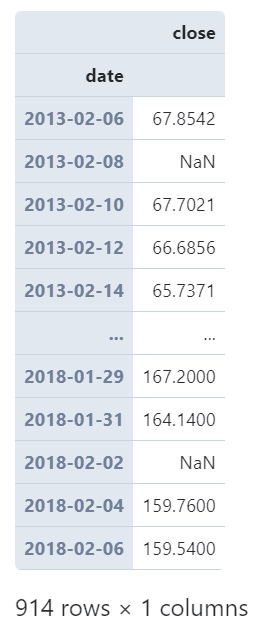
而通過參數(shù)closed我們可以為細(xì)粒度的時(shí)間單位設(shè)置區(qū)間閉合方式,譬如我們以2日為單位,將closed設(shè)置為'right'時(shí),從第一行記錄開始計(jì)算所落入的時(shí)間窗口時(shí),其對應(yīng)為時(shí)間窗口的右邊界,從而影響后續(xù)所有時(shí)間單元的劃分方式:
(
????AAPL
????.set_index('date')?#?設(shè)置date為index
????.resample('2D',?closed='right')
????.agg({
????????'close':?'mean'
????})
)
而即使你的數(shù)據(jù)框index不是日期時(shí)間類型,也可以使用參數(shù)on來傳入日期時(shí)間列名實(shí)現(xiàn)同樣的效果。
2.2 利用groupby()+Grouper()實(shí)現(xiàn)混合分組
有些情況下,我們不僅僅需要利用時(shí)間類型列來分組,也可能需要包含時(shí)間類型在內(nèi)的多個(gè)列共同進(jìn)行分組,這種情況下我們就可以使用到Grouper()。
它通過參數(shù)freq傳入等價(jià)于resample()中rule的參數(shù),并利用參數(shù)key指定對應(yīng)的時(shí)間類型列名稱,但是可以幫助我們創(chuàng)建分組規(guī)則后傳入groupby()中:
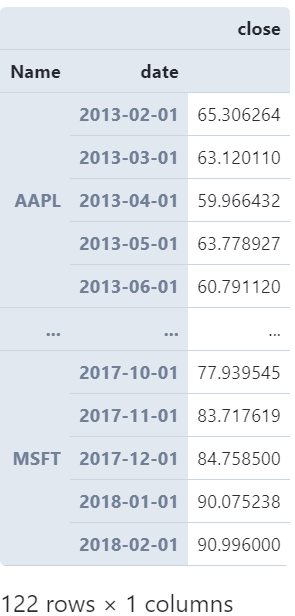
#?分別對蘋果與微軟每月平均收盤價(jià)進(jìn)行統(tǒng)計(jì)
(
????pd
????.read_csv('AAPL&MSFT.csv',?parse_dates=['date'])
????.groupby(['Name',?pd.Grouper(freq='MS',?key='date')])
????.agg({
????????'close':?'mean'
????})
)
且在此種混合分組模式下,我們可以非常方便的配合apply、transform等操作,這里就不再贅述。
以上就是本文的全部內(nèi)容,歡迎在評論區(qū)與我進(jìn)行討論~
加入我們的知識星球【Python大數(shù)據(jù)分析】
愛上數(shù)據(jù)分析!

最詳細(xì)的PyCharm 安裝+破解詳細(xì)使用指南
Python大數(shù)據(jù)分析
data creates?value
掃碼關(guān)注我們