
Meta新開源模型AudioCraft炸場!文本自動(dòng)生成音樂
專注AIGC領(lǐng)域的專業(yè)社區(qū),關(guān)注OpenAI、百度文心一言等大語言模型(LLM)的發(fā)展和應(yīng)用落地,關(guān)注LLM的基準(zhǔn)評(píng)測(cè)和市場研究,歡迎關(guān)注!
8月3日,全球社交、科技巨頭Meta(Facebook、Instagram等母公司)宣布開源文本生成音樂模型Audiocraft(開源地址:https://github.com/facebookresearch/audiocraft)。
據(jù)悉,Audiocraft是一個(gè)混合模型,由MusicGen、AudioGen和EnCodec組合而成。僅用文本就能生成鳥叫、汽車?yán)嚷暋⒛_步等背景音頻,或更復(fù)雜的音樂,適用于游戲開發(fā)、社交、視頻配音等業(yè)務(wù)場景。
MusicGen論文:https://arxiv.org/abs/2306.05284
AudioGen論文:https://arxiv.org/abs/2209.15352
高保真解碼器論文:https://arxiv.org/abs/2210.13438

Meta表示,ChatGPT掀起的大語言模型熱潮受到了全球各行業(yè)的熱烈追捧,相繼開發(fā)出了很多自動(dòng)生成文本、圖片、視頻的大模型。但關(guān)于音頻領(lǐng)域的不是很多,開源模型更是少的可憐,而音頻模型又是一個(gè)復(fù)雜的領(lǐng)域。
因此,Meta結(jié)合自身多年AI技術(shù)和訓(xùn)練數(shù)據(jù)積累推出了Audiocraft,這也是目前功能最強(qiáng)大的開源音樂模型之一。
Audiocraft簡單介紹
Audiocraft由MusicGen、AudioGen和EnCodec三個(gè)模型組合而成:
MusicGen是一個(gè)文本生成音樂的自回歸語言模型,大約使用了40萬份文本描述和元數(shù)據(jù)的錄音,總計(jì)2萬小時(shí)的授權(quán)音樂進(jìn)行訓(xùn)練。可通過文本自動(dòng)生成搖滾、流行、重金屬、RPA等類型音樂。
AudioGen是一個(gè)文本生成音頻的自回歸語言模型,具備分離音頻功能,例如,可識(shí)別背景聲、說話聲和物體發(fā)出的聲音等。這有助于僅使用文本生成音頻時(shí),更準(zhǔn)確貼近用戶的目標(biāo)音樂。
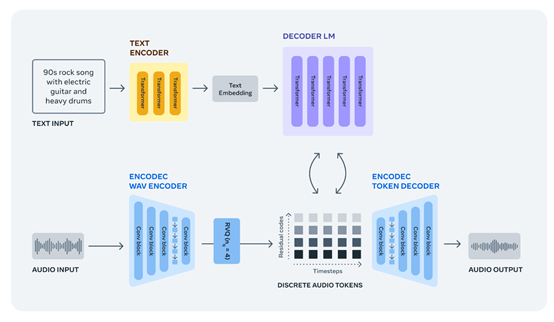
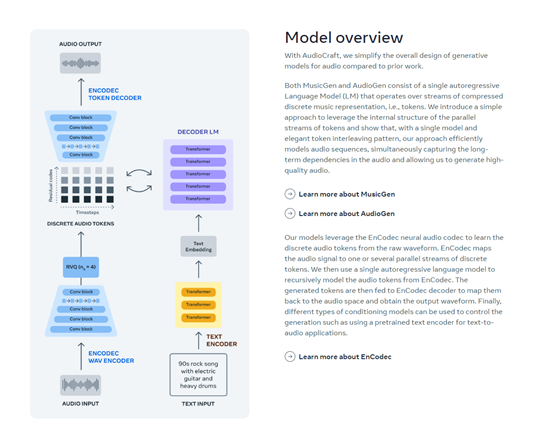
EnCodec是一個(gè)高保真音頻、音樂的壓縮和解壓器,可以用最小的體積盡可能還原原始音樂,這對(duì)于打造高質(zhì)量音頻模型來說至關(guān)重要。EnCodec由編碼器、量化器和解碼器三大塊組成。
1)編碼器,通過獲取未壓縮的數(shù)據(jù),并將其轉(zhuǎn)換為更高維度和更低幀速率的表示。2)量化器,將編碼器生成的“表示”壓縮到目標(biāo)大小,同時(shí)保留最重要的信息來重建原始信號(hào)。
3)解碼器,將壓縮信號(hào)轉(zhuǎn)換回,與原始信號(hào)盡可能相似的波形。因?yàn)樵诘捅忍芈氏虏豢赡苓M(jìn)行完美的重建,所以,使用了鑒別器來提高音頻生成樣本的質(zhì)量。
Audiocraft案例展示
Meta展示了Audiocraft通過文本自動(dòng)生成各種音頻、音樂的能力,并且質(zhì)量與原始音樂幾乎沒有差別,以下是案例展示。
警笛聲和嗡嗡作響的引擎接近并迅速通過
本文素材來源Meta,如有侵權(quán)請(qǐng)聯(lián)系刪除
END