
「Clickhouse系列」分布式表&本地表詳解

Hi,我是王知無(wú),一個(gè)大數(shù)據(jù)領(lǐng)域的原創(chuàng)作者。? 放心關(guān)注我,獲取更多行業(yè)的一手消息。
課前必讀整個(gè)ClickHouse系列:
4萬(wàn)字長(zhǎng)文 | ClickHouse基礎(chǔ)&實(shí)踐&調(diào)優(yōu)全視角解析 來(lái)自俄羅斯的兇猛彪悍的分析數(shù)據(jù)庫(kù)-ClickHouse 你需要懂一點(diǎn)ClickHouse的基礎(chǔ)知識(shí) 基于ClickHouse的用戶行為分析實(shí)踐 趣頭條實(shí)戰(zhàn) | 基于Flink+ClickHouse構(gòu)建實(shí)時(shí)數(shù)據(jù)平臺(tái) ClickHouse萬(wàn)億數(shù)據(jù)雙中心的設(shè)計(jì)與實(shí)踐 利用 Flink CDC實(shí)現(xiàn)數(shù)據(jù)增量備份到 ClickHouse
ClickHouse分布式表和本地表
ClickHouse的表分為兩種
分布式表
一個(gè)邏輯上的表, 可以理解為數(shù)據(jù)庫(kù)中的視圖, 一般查詢都查詢分布式表. 分布式表引擎會(huì)將我們的查詢請(qǐng)求路由本地表進(jìn)行查詢, 然后進(jìn)行匯總最終返回給用戶.
本地表
實(shí)際存儲(chǔ)數(shù)據(jù)的表
1. 不寫分布式表的原因
分布式表接收到數(shù)據(jù)后會(huì)將數(shù)據(jù)拆分成多個(gè)parts, 并轉(zhuǎn)發(fā)數(shù)據(jù)到其它服務(wù)器, 會(huì)引起服務(wù)器間網(wǎng)絡(luò)流量增加、服務(wù)器merge的工作量增加, 導(dǎo)致寫入速度變慢, 并且增加了Too many parts的可能性. 數(shù)據(jù)的一致性問(wèn)題, 先在分布式表所在的機(jī)器進(jìn)行落盤, 然后異步的發(fā)送到本地表所在機(jī)器進(jìn)行存儲(chǔ),中間沒(méi)有一致性的校驗(yàn), 而且在分布式表所在機(jī)器時(shí)如果機(jī)器出現(xiàn)down機(jī), 會(huì)存在數(shù)據(jù)丟失風(fēng)險(xiǎn). 數(shù)據(jù)寫入默認(rèn)是異步的,短時(shí)間內(nèi)可能造成不一致. 對(duì)zookeeper的壓力比較大
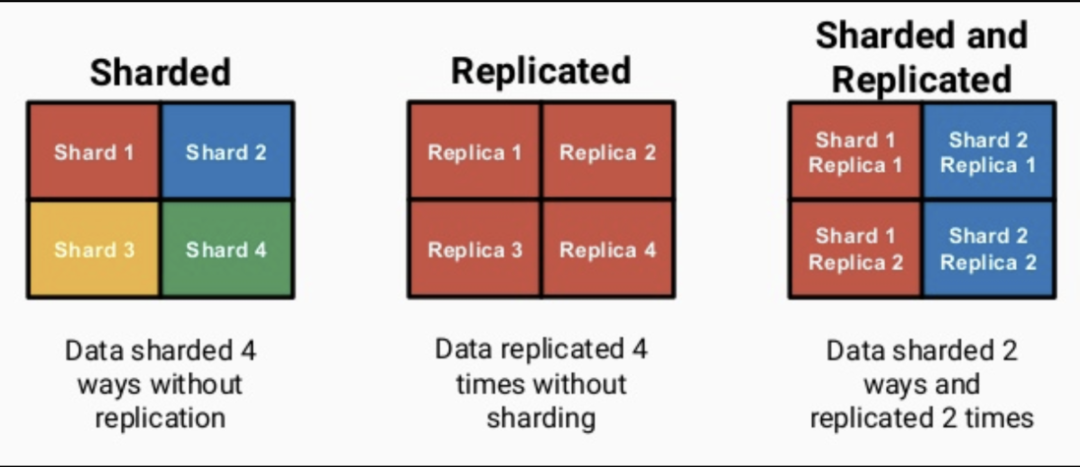
2. Replication & Sharding
ClickHouse依靠ReplicatedMergeTree引擎族與ZooKeeper實(shí)現(xiàn)了復(fù)制表機(jī)制, 成為其高可用的基礎(chǔ).
ClickHouse像ElasticSearch一樣具有數(shù)據(jù)分片(shard)的概念, 這也是分布式存儲(chǔ)的特點(diǎn)之一, 即通過(guò)并行讀寫提高效率. ClickHouse依靠Distributed引擎實(shí)現(xiàn)了分布式表機(jī)制, 在所有分片(本地表)上建立視圖進(jìn)行分布式查詢.
3. Replicated Table & ReplicatedMergeTree Engines
不同于HDFS的副本機(jī)制(基于集群實(shí)現(xiàn)), Clickhouse的副本機(jī)制是基于表實(shí)現(xiàn)的. 用戶在創(chuàng)建每張表的時(shí)候, 可以決定該表是否高可用.
Local_table
CREATE?TABLE?IF?NOT?EXISTS?{local_table}?({columns})?
ENGINE?=?ReplicatedMergeTree('/clickhouse/tables/#_tenant_id_#/#__appname__#/#_at_date_#/{shard}/hits',?'{replica}')
partition?by?toString(_at_date_)?sample?by?intHash64(toInt64(toDateTime(_at_timestamp_)))
order?by?(_at_date_,?_at_timestamp_,?intHash64(toInt64(toDateTime(_at_timestamp_))))
支持復(fù)制表的引擎都是ReplicatedMergeTree引擎族, 具體可以查看官網(wǎng):
Data Replication
ReplicatedMergeTree引擎族接收兩個(gè)參數(shù):
ZK中該表相關(guān)數(shù)據(jù)的存儲(chǔ)路徑, ClickHouse官方建議規(guī)范化, 例如: /clickhouse/tables/{shard}/[database_name]/[table_name].副本名稱, 一般用 {replica}即可.
ReplicatedMergeTree引擎族非常依賴于zookeeper, 它在zookeeper中存儲(chǔ)了大量的數(shù)據(jù):
表結(jié)構(gòu)信息、元數(shù)據(jù)、操作日志、副本狀態(tài)、數(shù)據(jù)塊校驗(yàn)值、數(shù)據(jù)part merge過(guò)程中的選主信息.
同時(shí), zookeeper又在復(fù)制表急之下扮演了三種角色:
元數(shù)據(jù)存儲(chǔ)、日志框架、分布式協(xié)調(diào)服務(wù)
可以說(shuō)當(dāng)使用了ReplicatedMergeTree時(shí), zookeeper壓力特別重, 一定要保證zookeeper集群的高可用和資源.
3.1 數(shù)據(jù)同步的流程
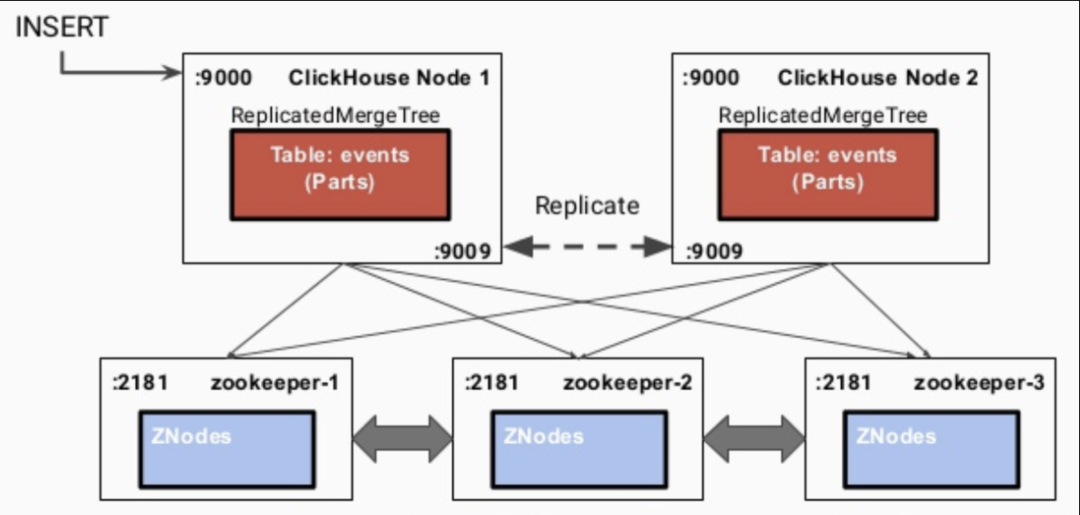
寫入到一個(gè)節(jié)點(diǎn) 通過(guò)interserver HTTP port端口同步到其他實(shí)例上 更新zookeeper集群記錄的信息
3.2. 重度依賴Zookeeper導(dǎo)致的問(wèn)題
ck的replicatedMergeTree引擎方案有太多的信息存儲(chǔ)在zk上, 當(dāng)數(shù)據(jù)量增大, ck節(jié)點(diǎn)數(shù)增多, 會(huì)導(dǎo)致服務(wù)非常不穩(wěn)定, 目前我們的ck集群規(guī)模還小, 這個(gè)問(wèn)題還不嚴(yán)重, 但依舊會(huì)出現(xiàn)很多和zk有關(guān)的問(wèn)題(詳見(jiàn)遇到的問(wèn)題).
實(shí)際上 ClickHouse 把 ZK 當(dāng)成了三種服務(wù)的結(jié)合, 而不僅把它當(dāng)作一個(gè) Coordinate service(協(xié)調(diào)服務(wù)), 可能這也是大家使用 ZK 的常用用法。ClickHouse 還會(huì)把它當(dāng)作 Log Service(日志服務(wù)),很多行為日志等數(shù)字的信息也會(huì)存在 ZK 上;還會(huì)作為表的 catalog service(元數(shù)據(jù)存儲(chǔ)),像表的一些 schema 信息也會(huì)在 ZK 上做校驗(yàn),這就會(huì)導(dǎo)致 ZK 上接入的數(shù)量與數(shù)據(jù)總量會(huì)成線性關(guān)系。
目前針對(duì)這個(gè)問(wèn)題, clickhouse社區(qū)提出了一個(gè)mini checksum方案, 但是這并沒(méi)有徹底解決 znode 與數(shù)據(jù)量成線性關(guān)系的問(wèn)題. 目前看到比較好的方案是字節(jié)的:
我們就基于 MergeTree 存儲(chǔ)引擎開(kāi)發(fā)了一套自己的高可用方案。我們的想法很簡(jiǎn)單,就是把更多 ZK 上的信息卸載下來(lái),ZK 只作為 coordinate Service。只讓它做三件簡(jiǎn)單的事情:行為日志的 Sequence Number 分配、Block ID 的分配和數(shù)據(jù)的元信息,這樣就能保證數(shù)據(jù)和行為在全局內(nèi)是唯一的。
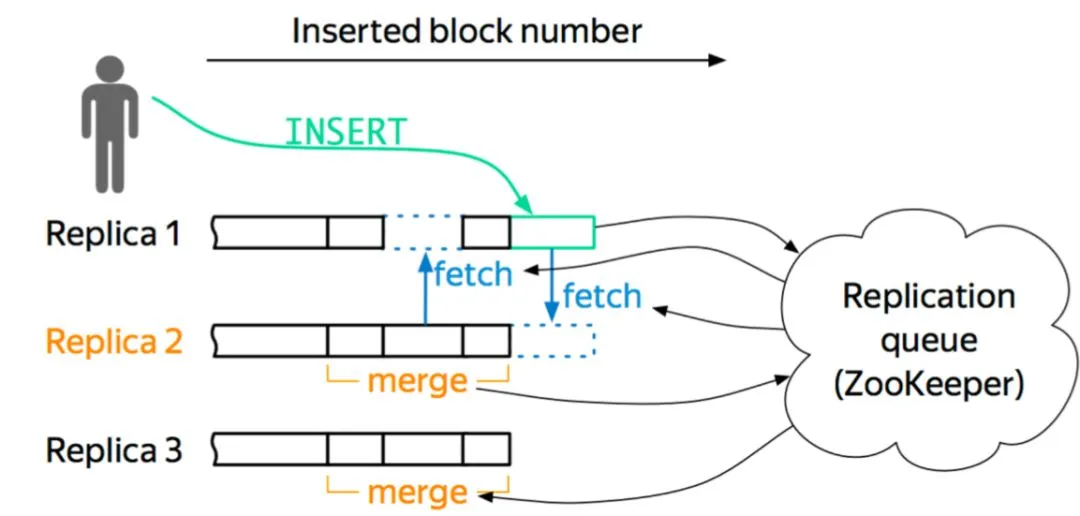
關(guān)于節(jié)點(diǎn),它維護(hù)自身的數(shù)據(jù)信息和行為日志信息,Log 和數(shù)據(jù)的信息在一個(gè) shard 內(nèi)部的副本之間,通過(guò) Gossip 協(xié)議進(jìn)行交互。我們保留了原生的 multi-master 寫入特性,這樣多個(gè)副本都是可以寫的,好處就是能夠簡(jiǎn)化數(shù)據(jù)導(dǎo)入。圖 6 是一個(gè)簡(jiǎn)單的框架圖。
以這個(gè)圖為例,如果往 Replica 1 上寫,它會(huì)從 ZK 上獲得一個(gè) ID,就是 Log ID,然后把這些行為和 Log Push 到集群內(nèi)部 shard 內(nèi)部活著的副本上去,然后當(dāng)其他副本收到這些信息之后,它會(huì)主動(dòng)去 Pull 數(shù)據(jù),實(shí)現(xiàn)數(shù)據(jù)的最終一致性。我們現(xiàn)在所有集群加起來(lái) znode 數(shù)不超過(guò)三百萬(wàn),服務(wù)的高可用基本上得到了保障,壓力也不會(huì)隨著數(shù)據(jù)增加而增加。
4. Distributed Table & Distributed Engine
ClickHouse分布式表的本質(zhì)并不是一張表, 而是一些本地物理表(分片)的分布式視圖,本身并不存儲(chǔ)數(shù)據(jù). 分布式表建表的引擎為Distributed.
Distrbuted_table
CREATE?TABLE?IF?NOT?EXISTS?{distributed_table}?as?{local_table}?
ENGINE?=?Distributed({cluster},?'{local_database}',?'{local_table}',?rand())
Distributed引擎需要以下幾個(gè)參數(shù):
集群標(biāo)識(shí)符 本地表所在的數(shù)據(jù)庫(kù)名稱 本地表名稱 分片鍵(sharding key) - 可選 該鍵與config.xml中配置的分片權(quán)重(weight)一同決定寫入分布式表時(shí)的路由, 即數(shù)據(jù)最終落到哪個(gè)物理表上. 它可以是表中一列的原始數(shù)據(jù)(如site_id), 也可以是函數(shù)調(diào)用的結(jié)果, 如上面的SQL語(yǔ)句采用了隨機(jī)值rand(). 注意該鍵要盡量保證數(shù)據(jù)均勻分布, 另外一個(gè)常用的操作是采用區(qū)分度較高的列的哈希值, 如intHash64(user_id).
4.1. 數(shù)據(jù)查詢的流程
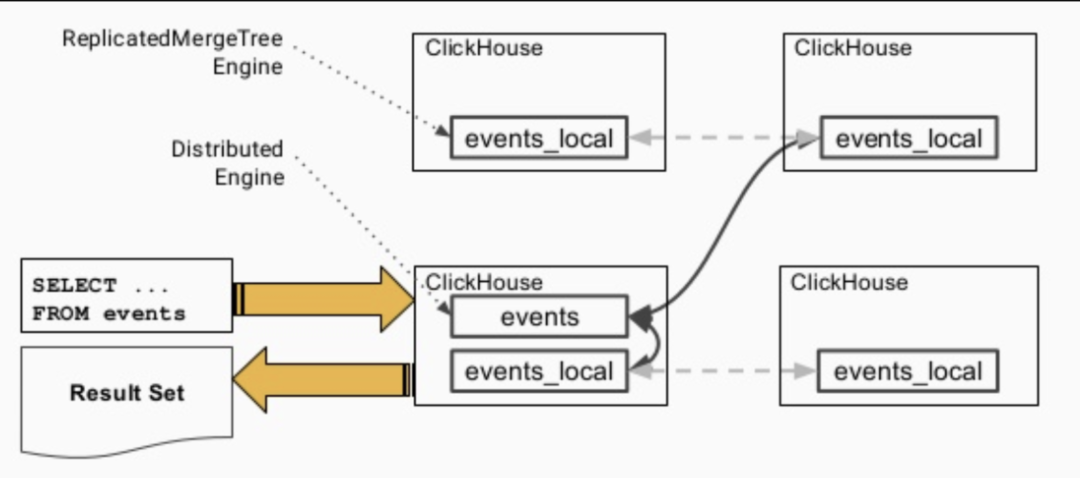
各個(gè)實(shí)例之間會(huì)交換自己持有的分片的表數(shù)據(jù) 匯總到同一個(gè)實(shí)例上返回給用戶
