
詳解java集合框架

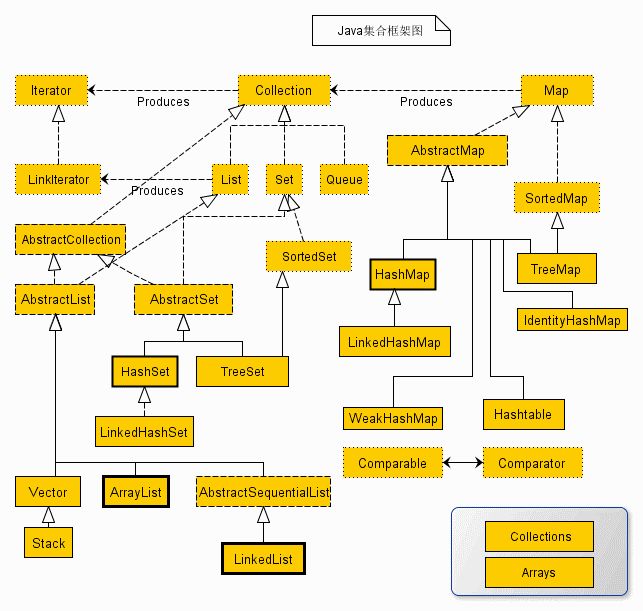
一、集合框架圖
簡(jiǎn)化圖:
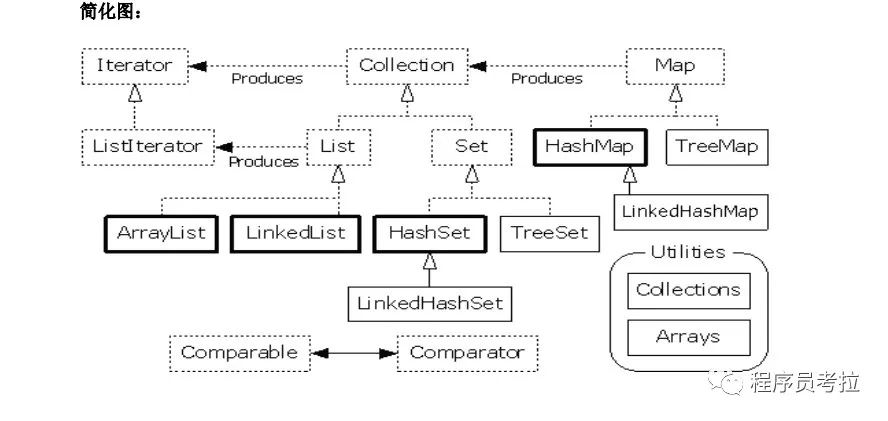
說明:對(duì)于以上的框架圖有如下幾點(diǎn)說明
1.所有集合類都位于java.util包下。Java的集合類主要由兩個(gè)接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口,這兩個(gè)接口又包含了一些子接口或?qū)崿F(xiàn)類。
2. 集合接口:6個(gè)接口(短虛線表示),表示不同集合類型,是集合框架的基礎(chǔ)。
3. 抽象類:5個(gè)抽象類(長(zhǎng)虛線表示),對(duì)集合接口的部分實(shí)現(xiàn)。可擴(kuò)展為自定義集合類。
4. 實(shí)現(xiàn)類:8個(gè)實(shí)現(xiàn)類(實(shí)線表示),對(duì)接口的具體實(shí)現(xiàn)。
5. Collection 接口是一組允許重復(fù)的對(duì)象。
6. Set 接口繼承 Collection,集合元素不重復(fù)。
7. List 接口繼承 Collection,允許重復(fù),維護(hù)元素插入順序。
8. Map接口是鍵-值對(duì)象,與Collection接口沒有什么關(guān)系。
9.Set、List和Map可以看做集合的三大類:
List集合是有序集合,集合中的元素可以重復(fù),訪問集合中的元素可以根據(jù)元素的索引來訪問。
Set集合是無序集合,集合中的元素不可以重復(fù),訪問集合中的元素只能根據(jù)元素本身來訪問(也是集合里元素不允許重復(fù)的原因)。
Map集合中保存Key-value對(duì)形式的元素,訪問時(shí)只能根據(jù)每項(xiàng)元素的key來訪問其value。
二、總體分析
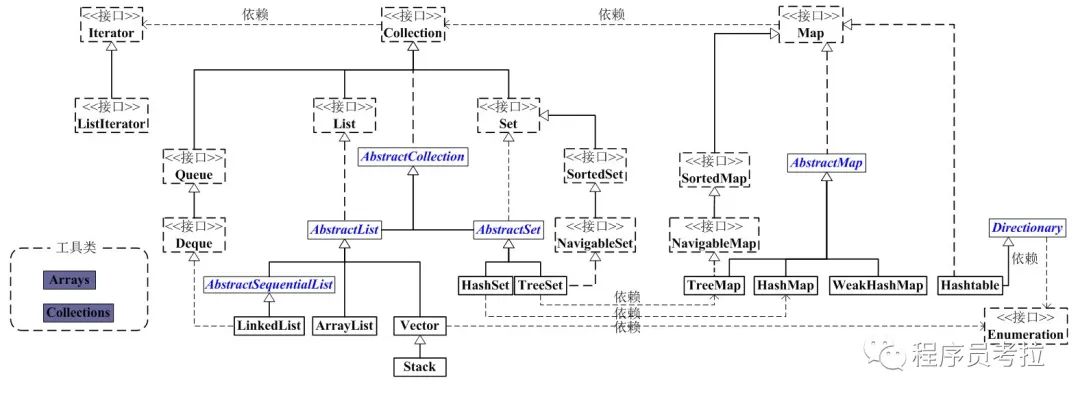
大致說明:
看上面的框架圖,先抓住它的主干,即Collection和Map。
1、Collection是一個(gè)接口,是高度抽象出來的集合,它包含了集合的基本操作和屬性。Collection包含了List和Set兩大分支。
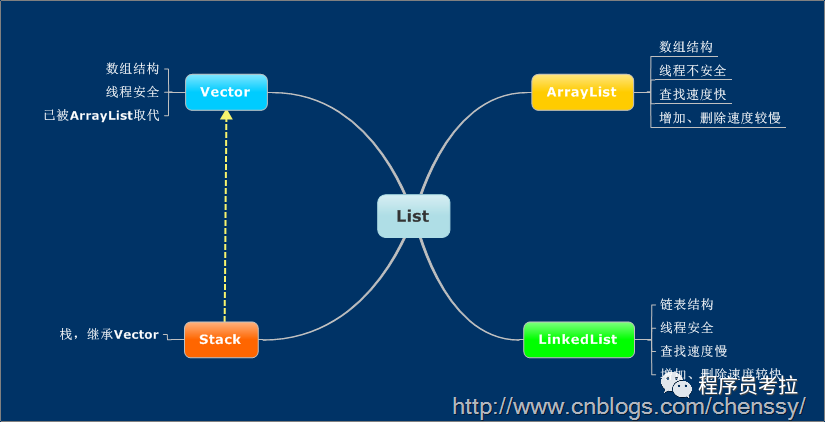
(1)List是一個(gè)有序的隊(duì)列,每一個(gè)元素都有它的索引。第一個(gè)元素的索引值是0。List的實(shí)現(xiàn)類有LinkedList, ArrayList, Vector, Stack。
(2)Set是一個(gè)不允許有重復(fù)元素的集合。Set的實(shí)現(xiàn)類有HastSet和TreeSet。HashSet依賴于HashMap,它實(shí)際上是通過HashMap實(shí)現(xiàn)的;TreeSet依賴于TreeMap,它實(shí)際上是通過TreeMap實(shí)現(xiàn)的。
2、Map是一個(gè)映射接口,即key-value鍵值對(duì)。Map中的每一個(gè)元素包含“一個(gè)key”和“key對(duì)應(yīng)的value”。AbstractMap是個(gè)抽象類,它實(shí)現(xiàn)了Map接口中的大部分API。而HashMap,TreeMap,WeakHashMap都是繼承于AbstractMap。Hashtable雖然繼承于Dictionary,但它實(shí)現(xiàn)了Map接口。
3、接下來,再看Iterator。它是遍歷集合的工具,即我們通常通過Iterator迭代器來遍歷集合。我們說Collection依賴于Iterator,是因?yàn)镃ollection的實(shí)現(xiàn)類都要實(shí)現(xiàn)iterator()函數(shù),返回一個(gè)Iterator對(duì)象。ListIterator是專門為遍歷List而存在的。
4、再看Enumeration,它是JDK 1.0引入的抽象類。作用和Iterator一樣,也是遍歷集合;但是Enumeration的功能要比Iterator少。在上面的框圖中,Enumeration只能在Hashtable, Vector, Stack中使用。
5、最后,看Arrays和Collections。它們是操作數(shù)組、集合的兩個(gè)工具類。
有了上面的整體框架之后,我們接下來對(duì)每個(gè)類分別進(jìn)行分析。?
三、Collection接口
Collection接口是處理對(duì)象集合的根接口,其中定義了很多對(duì)元素進(jìn)行操作的方法。Collection接口有兩個(gè)主要的子接口List和Set,注意Map不是Collection的子接口,這個(gè)要牢記。
Collection接口中的方法如下:?
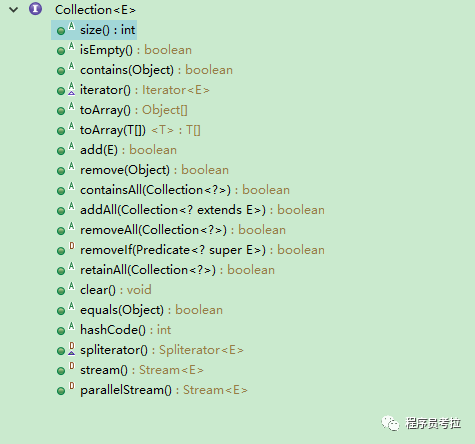
其中,有幾個(gè)比較常用的方法,比如方法add()添加一個(gè)元素到集合中,addAll()將指定集合中的所有元素添加到集合中,contains()方法檢測(cè)集合中是否包含指定的元素,toArray()方法返回一個(gè)表示集合的數(shù)組。
另外,Collection中有一個(gè)iterator()函數(shù),它的作用是返回一個(gè)Iterator接口。通常,我們通過Iterator迭代器來遍歷集合。ListIterator是List接口所特有的,在List接口中,通過ListIterator()返回一個(gè)ListIterator對(duì)象。
Collection接口有兩個(gè)常用的子接口,下面詳細(xì)介紹。
1.List接口
List集合代表一個(gè)有序集合,集合中每個(gè)元素都有其對(duì)應(yīng)的順序索引。List集合允許使用重復(fù)元素,可以通過索引來訪問指定位置的集合元素。
List接口繼承于Collection接口,它可以定義一個(gè)允許重復(fù)的有序集合。因?yàn)長(zhǎng)ist中的元素是有序的,所以我們可以通過使用索引(元素在List中的位置,類似于數(shù)組下標(biāo))來訪問List中的元素,這類似于Java的數(shù)組。
List接口為Collection直接接口。List所代表的是有序的Collection,即它用某種特定的插入順序來維護(hù)元素順序。用戶可以對(duì)列表中每個(gè)元素的插入位置進(jìn)行精確地控制,同時(shí)可以根據(jù)元素的整數(shù)索引(在列表中的位置)訪問元素,并搜索列表中的元素。實(shí)現(xiàn)List接口的集合主要有:ArrayList、LinkedList、Vector、Stack。
(1)ArrayList
ArrayList是一個(gè)動(dòng)態(tài)數(shù)組,也是我們最常用的集合。它允許任何符合規(guī)則的元素插入甚至包括null。每一個(gè)ArrayList都有一個(gè)初始容量(10),該容量代表了數(shù)組的大小。隨著容器中的元素不斷增加,容器的大小也會(huì)隨著增加。在每次向容器中增加元素的同時(shí)都會(huì)進(jìn)行容量檢查,當(dāng)快溢出時(shí),就會(huì)進(jìn)行擴(kuò)容操作。所以如果我們明確所插入元素的多少,最好指定一個(gè)初始容量值,避免過多的進(jìn)行擴(kuò)容操作而浪費(fèi)時(shí)間、效率。
??????
size、isEmpty、get、set、iterator 和 listIterator 操作都以固定時(shí)間運(yùn)行。add 操作以分?jǐn)偟墓潭〞r(shí)間運(yùn)行,也就是說,添加 n 個(gè)元素需要 O(n) 時(shí)間(由于要考慮到擴(kuò)容,所以這不只是添加元素會(huì)帶來分?jǐn)偣潭〞r(shí)間開銷那樣簡(jiǎn)單)。
ArrayList擅長(zhǎng)于隨機(jī)訪問。同時(shí)ArrayList是非同步的。
(2)LinkedList
??????
同樣實(shí)現(xiàn)List接口的LinkedList與ArrayList不同,ArrayList是一個(gè)動(dòng)態(tài)數(shù)組,而LinkedList是一個(gè)雙向鏈表。所以它除了有ArrayList的基本操作方法外還額外提供了get,remove,insert方法在LinkedList的首部或尾部。
??????
由于實(shí)現(xiàn)的方式不同,LinkedList不能隨機(jī)訪問,它所有的操作都是要按照雙重鏈表的需要執(zhí)行。在列表中索引的操作將從開頭或結(jié)尾遍歷列表(從靠近指定索引的一端)。這樣做的好處就是可以通過較低的代價(jià)在List中進(jìn)行插入和刪除操作。
??????
與ArrayList一樣,LinkedList也是非同步的。如果多個(gè)線程同時(shí)訪問一個(gè)List,則必須自己實(shí)現(xiàn)訪問同步。一種解決方法是在創(chuàng)建List時(shí)構(gòu)造一個(gè)同步的List:
List list = Collections.synchronizedList(new LinkedList(...));
(3)Vector
??????
與ArrayList相似,但是Vector是同步的。所以說Vector是線程安全的動(dòng)態(tài)數(shù)組。它的操作與ArrayList幾乎一樣。
(4)Stack
?????
Stack繼承自Vector,實(shí)現(xiàn)一個(gè)后進(jìn)先出的堆棧。Stack提供5個(gè)額外的方法使得Vector得以被當(dāng)作堆棧使用。基本的push和pop 方法,還有peek方法得到棧頂?shù)脑兀琫mpty方法測(cè)試堆棧是否為空,search方法檢測(cè)一個(gè)元素在堆棧中的位置。Stack剛創(chuàng)建后是空棧。
2.Set接口
Set是一種不包括重復(fù)元素的Collection。它維持它自己的內(nèi)部排序,所以隨機(jī)訪問沒有任何意義。與List一樣,它同樣允許null的存在但是僅有一個(gè)。由于Set接口的特殊性,所有傳入Set集合中的元素都必須不同,同時(shí)要注意任何可變對(duì)象,如果在對(duì)集合中元素進(jìn)行操作時(shí),導(dǎo)致e1.equals(e2)==true,則必定會(huì)產(chǎn)生某些問題。Set接口有三個(gè)具體實(shí)現(xiàn)類,分別是散列集HashSet、鏈?zhǔn)缴⒘屑疞inkedHashSet和樹形集TreeSet。
?????
Set是一種不包含重復(fù)的元素的Collection,無序,即任意的兩個(gè)元素e1和e2都有e1.equals(e2)=false,Set最多有一個(gè)null元素。需要注意的是:雖然Set中元素沒有順序,但是元素在set中的位置是由該元素的HashCode決定的,其具體位置其實(shí)是固定的。
?????
此外需要說明一點(diǎn),在set接口中的不重復(fù)是有特殊要求的。
?????
舉一個(gè)例子:對(duì)象A和對(duì)象B,本來是不同的兩個(gè)對(duì)象,正常情況下它們是能夠放入到Set里面的,但是如果對(duì)象A和B的都重寫了hashcode和equals方法,并且重寫后的hashcode和equals方法是相同的話。那么A和B是不能同時(shí)放入到Set集合中去的,也就是Set集合中的去重和hashcode與equals方法直接相關(guān)。?
為了更好地理解,請(qǐng)看下面的例子:
public?class?Test{
public?static?void?main(String[] args) {
?????Set set=new?HashSet();
?????set.add("Hello");
?????set.add("world");
?????set.add("Hello");
?????System.out.println("集合的尺寸為:"+set.size());
?????System.out.println("集合中的元素為:"+set.toString());
??}
} 運(yùn)行結(jié)果:
集合的尺寸為:2
集合中的元素為:[world, Hello]
分析:由于String類中重寫了hashcode和equals方法,用來比較指向的字符串對(duì)象所存儲(chǔ)的字符串是否相等。所以這里的第二個(gè)Hello是加不進(jìn)去的。
再看一個(gè)例子:
public?class?TestSet?{
????
????public?static?void?main(String[] args){
????????
????????Set books = new?HashSet();
????????//添加一個(gè)字符串對(duì)象
????????books.add(new?String("Struts2權(quán)威指南"));
????????
????????//再次添加一個(gè)字符串對(duì)象,
????????//因?yàn)閮蓚€(gè)字符串對(duì)象通過equals方法比較相等,所以添加失敗,返回false
????????boolean result = books.add(new?String("Struts2權(quán)威指南"));
????????
????????System.out.println(result);
????????
????????//下面輸出看到集合只有一個(gè)元素
????????System.out.println(books);
????}
} 運(yùn)行結(jié)果:
false
[Struts2權(quán)威指南]
說明:程序中,book集合兩次添加的字符串對(duì)象明顯不是一個(gè)對(duì)象(程序通過new關(guān)鍵字來創(chuàng)建字符串對(duì)象),當(dāng)使用==運(yùn)算符判斷返回false,使用equals方法比較返回true,所以不能添加到Set集合中,最后只能輸出一個(gè)元素。
(1)HashSet
? ? ?
HashSet 是一個(gè)沒有重復(fù)元素的集合。它是由HashMap實(shí)現(xiàn)的,不保證元素的順序(這里所說的沒有順序是指:元素插入的順序與輸出的順序不一致),而且HashSet允許使用null 元素。HashSet是非同步的,如果多個(gè)線程同時(shí)訪問一個(gè)哈希set,而其中至少一個(gè)線程修改了該set,那么它必須保持外部同步。HashSet按Hash算法來存儲(chǔ)集合的元素,因此具有很好的存取和查找性能。
HashSet的實(shí)現(xiàn)方式大致如下,通過一個(gè)HashMap存儲(chǔ)元素,元素是存放在HashMap的Key中,而Value統(tǒng)一使用一個(gè)Object對(duì)象。
HashSet使用和理解中容易出現(xiàn)的誤區(qū):
a.HashSet中存放null值
HashSet中是允許存入null值的,但是在HashSet中僅僅能夠存入一個(gè)null值。
b.HashSet中存儲(chǔ)元素的位置是固定的
??
HashSet中存儲(chǔ)的元素的是無序的,這個(gè)沒什么好說的,但是由于HashSet底層是基于Hash算法實(shí)現(xiàn)的,使用了hashcode,所以HashSet中相應(yīng)的元素的位置是固定的。
c.必須小心操作可變對(duì)象(Mutable Object)。如果一個(gè)Set中的可變?cè)馗淖兞俗陨頎顟B(tài)導(dǎo)致Object.equals(Object)=true將導(dǎo)致一些問題。
(2)LinkedHashSet
??????
LinkedHashSet繼承自HashSet,其底層是基于LinkedHashMap來實(shí)現(xiàn)的,有序,非同步。LinkedHashSet集合同樣是根據(jù)元素的hashCode值來決定元素的存儲(chǔ)位置,但是它同時(shí)使用鏈表維護(hù)元素的次序。這樣使得元素看起來像是以插入順序保存的,也就是說,當(dāng)遍歷該集合時(shí)候,LinkedHashSet將會(huì)以元素的添加順序訪問集合的元素。
(3)TreeSet
?????
TreeSet是一個(gè)有序集合,其底層是基于TreeMap實(shí)現(xiàn)的,非線程安全。TreeSet可以確保集合元素處于排序狀態(tài)。TreeSet支持兩種排序方式,自然排序和定制排序,其中自然排序?yàn)槟J(rèn)的排序方式。當(dāng)我們構(gòu)造TreeSet時(shí),若使用不帶參數(shù)的構(gòu)造函數(shù),則TreeSet的使用自然比較器;若用戶需要使用自定義的比較器,則需要使用帶比較器的參數(shù)。
注意:TreeSet集合不是通過hashcode和equals函數(shù)來比較元素的.它是通過compare或者comparaeTo函數(shù)來判斷元素是否相等.compare函數(shù)通過判斷兩個(gè)對(duì)象的id,相同的id判斷為重復(fù)元素,不會(huì)被加入到集合中。
四、Map接口
?????
Map與List、Set接口不同,它是由一系列鍵值對(duì)組成的集合,提供了key到Value的映射。同時(shí)它也沒有繼承Collection。在Map中它保證了key與value之間的一一對(duì)應(yīng)關(guān)系。也就是說一個(gè)key對(duì)應(yīng)一個(gè)value,所以它不能存在相同的key值,當(dāng)然value值可以相同。
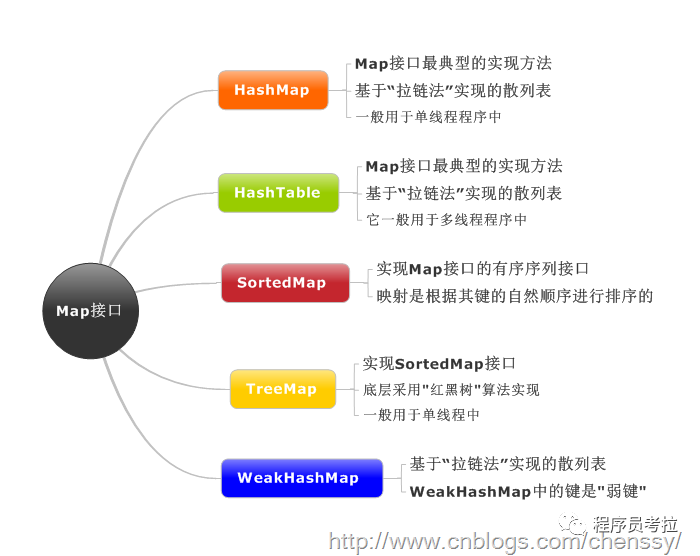
1.HashMap
??????
以哈希表數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn),查找對(duì)象時(shí)通過哈希函數(shù)計(jì)算其位置,它是為快速查詢而設(shè)計(jì)的,其內(nèi)部定義了一個(gè)hash表數(shù)組(Entry[] table),元素會(huì)通過哈希轉(zhuǎn)換函數(shù)將元素的哈希地址轉(zhuǎn)換成數(shù)組中存放的索引,如果有沖突,則使用散列鏈表的形式將所有相同哈希地址的元素串起來,可能通過查看HashMap.Entry的源碼它是一個(gè)單鏈表結(jié)構(gòu)。
2.LinkedHashMap
?????
LinkedHashMap是HashMap的一個(gè)子類,它保留插入的順序,如果需要輸出的順序和輸入時(shí)的相同,那么就選用LinkedHashMap。
????
LinkedHashMap是Map接口的哈希表和鏈接列表實(shí)現(xiàn),具有可預(yù)知的迭代順序。此實(shí)現(xiàn)提供所有可選的映射操作,并允許使用null值和null鍵。此類不保證映射的順序,特別是它不保證該順序恒久不變。
????
LinkedHashMap實(shí)現(xiàn)與HashMap的不同之處在于,后者維護(hù)著一個(gè)運(yùn)行于所有條目的雙重鏈接列表。此鏈接列表定義了迭代順序,該迭代順序可以是插入順序或者是訪問順序。
???
根據(jù)鏈表中元素的順序可以分為:按插入順序的鏈表,和按訪問順序(調(diào)用get方法)的鏈表。默認(rèn)是按插入順序排序,如果指定按訪問順序排序,那么調(diào)用get方法后,會(huì)將這次訪問的元素移至鏈表尾部,不斷訪問可以形成按訪問順序排序的鏈表。
?????
注意,此實(shí)現(xiàn)不是同步的。如果多個(gè)線程同時(shí)訪問鏈接的哈希映射,而其中至少一個(gè)線程從結(jié)構(gòu)上修改了該映射,則它必須保持外部同步。
?????
由于LinkedHashMap需要維護(hù)元素的插入順序,因此性能略低于HashMap的性能,但在迭代訪問Map里的全部元素時(shí)將有很好的性能,因?yàn)樗枣湵韥砭S護(hù)內(nèi)部順序。
3.TreeMap
?????
TreeMap 是一個(gè)有序的key-value集合,非同步,基于紅黑樹(Red-Black tree)實(shí)現(xiàn),每一個(gè)key-value節(jié)點(diǎn)作為紅黑樹的一個(gè)節(jié)點(diǎn)。TreeMap存儲(chǔ)時(shí)會(huì)進(jìn)行排序的,會(huì)根據(jù)key來對(duì)key-value鍵值對(duì)進(jìn)行排序,其中排序方式也是分為兩種,一種是自然排序,一種是定制排序,具體取決于使用的構(gòu)造方法。
自然排序:TreeMap中所有的key必須實(shí)現(xiàn)Comparable接口,并且所有的key都應(yīng)該是同一個(gè)類的對(duì)象,否則會(huì)報(bào)ClassCastException異常。
定制排序:定義TreeMap時(shí),創(chuàng)建一個(gè)comparator對(duì)象,該對(duì)象對(duì)所有的treeMap中所有的key值進(jìn)行排序,采用定制排序的時(shí)候不需要TreeMap中所有的key必須實(shí)現(xiàn)Comparable接口。
TreeMap判斷兩個(gè)元素相等的標(biāo)準(zhǔn):兩個(gè)key通過compareTo()方法返回0,則認(rèn)為這兩個(gè)key相等。
如果使用自定義的類來作為TreeMap中的key值,且想讓TreeMap能夠良好的工作,則必須重寫自定義類中的equals()方法,TreeMap中判斷相等的標(biāo)準(zhǔn)是:兩個(gè)key通過equals()方法返回為true,并且通過compareTo()方法比較應(yīng)該返回為0。
五、Iterator 與 ListIterator詳解
1.Iterator
Iterator的定義如下:
public?interface?Iterator{}Iterator是一個(gè)接口,它是集合的迭代器。集合可以通過Iterator去遍歷集合中的元素。Iterator提供的API接口如下:
boolean hasNext():判斷集合里是否存在下一個(gè)元素。如果有,hasNext()方法返回 true。
Object next():返回集合里下一個(gè)元素。
void remove():刪除集合里上一次next方法返回的元素。
使用示例:
public?class?IteratorExample?{
????public?static?void?main(String[] args) {
????????ArrayList a = new?ArrayList();
????????a.add("aaa");
????????a.add("bbb");
????????a.add("ccc");
????????System.out.println("Before iterate : "?+ a);
????????Iterator it = a.iterator();
????????while?(it.hasNext()) {
????????????String t = it.next();
????????????if?("bbb".equals(t)) {
????????????????it.remove();
????????????}
????????}
????????System.out.println("After iterate : "?+ a);
????}
} 輸出結(jié)果如下:
Before iterate : [aaa, bbb, ccc]
After iterate : [aaa, ccc]
注意:
(1)Iterator只能單向移動(dòng)。
(2)Iterator.remove()是唯一安全的方式來在迭代過程中修改集合;如果在迭代過程中以任何其它的方式修改了基本集合將會(huì)產(chǎn)生未知的行為。而且每調(diào)用一次next()方法,remove()方法只能被調(diào)用一次,如果違反這個(gè)規(guī)則將拋出一個(gè)異常。
2.ListIterator
ListIterator是一個(gè)功能更加強(qiáng)大的迭代器, 它繼承于Iterator接口,只能用于各種List類型的訪問。可以通過調(diào)用listIterator()方法產(chǎn)生一個(gè)指向List開始處的ListIterator, 還可以調(diào)用listIterator(n)方法創(chuàng)建一個(gè)一開始就指向列表索引為n的元素處的ListIterator.
ListIterator接口定義如下:
public?interface?ListIterator<E> extends?Iterator<E> {
????boolean?hasNext();
?
????E next();
?
????boolean?hasPrevious();
?
????E previous();
?
????int?nextIndex();
?
????int?previousIndex();
?
????void?remove();
?
????void?set(E e);
?
????void?add(E e);
?????
}由以上定義我們可以推出ListIterator可以:
(1)雙向移動(dòng)(向前/向后遍歷).
(2)產(chǎn)生相對(duì)于迭代器在列表中指向的當(dāng)前位置的前一個(gè)和后一個(gè)元素的索引.
(3)可以使用set()方法替換它訪問過的最后一個(gè)元素.
(4)可以使用add()方法在next()方法返回的元素之前或previous()方法返回的元素之后插入一個(gè)元素.
使用示例:
public?class?ListIteratorExample?{
?
????public?static?void?main(String[] args) {
????????ArrayList a = new?ArrayList();
????????a.add("aaa");
????????a.add("bbb");
????????a.add("ccc");
????????System.out.println("Before iterate : "?+ a);
????????ListIterator it = a.listIterator();
????????while?(it.hasNext()) {
????????????System.out.println(it.next() + ", "?+ it.previousIndex() + ", "?+ it.nextIndex());
????????}
????????while?(it.hasPrevious()) {
????????????System.out.print(it.previous() + " ");
????????}
????????System.out.println();
????????it = a.listIterator(1);
????????while?(it.hasNext()) {
????????????String t = it.next();
????????????System.out.println(t);
????????????if?("ccc".equals(t)) {
????????????????it.set("nnn");
????????????} else?{
????????????????it.add("kkk");
????????????}
????????}
????????System.out.println("After iterate : "?+ a);
????}
} 輸出結(jié)果如下:
Before?iterate?: [aaa, bbb, ccc]
aaa, 0, 1
bbb, 1, 2
ccc, 2, 3
ccc?bbb?aaa?
bbb
ccc
After?iterate?: [aaa, bbb, kkk, nnn]六、異同點(diǎn)
1.ArrayList和LinkedList
(1)ArrayList是實(shí)現(xiàn)了基于動(dòng)態(tài)數(shù)組的數(shù)據(jù)結(jié)構(gòu),LinkedList基于鏈表的數(shù)據(jù)結(jié)構(gòu)。
(2)對(duì)于隨機(jī)訪問get和set,ArrayList絕對(duì)優(yōu)于LinkedList,因?yàn)長(zhǎng)inkedList要移動(dòng)指針。?
(3)對(duì)于新增和刪除操作add和remove,LinedList比較占優(yōu)勢(shì),因?yàn)锳rrayList要移動(dòng)數(shù)據(jù)。?
這一點(diǎn)要看實(shí)際情況的。若只對(duì)單條數(shù)據(jù)插入或刪除,ArrayList的速度反而優(yōu)于LinkedList。但若是批量隨機(jī)的插入刪除數(shù)據(jù),LinkedList的速度大大優(yōu)于ArrayList. 因?yàn)锳rrayList每插入一條數(shù)據(jù),要移動(dòng)插入點(diǎn)及之后的所有數(shù)據(jù)。
2.HashTable與HashMap
相同點(diǎn):
(1)都實(shí)現(xiàn)了Map、Cloneable、java.io.Serializable接口。
(2)都是存儲(chǔ)"鍵值對(duì)(key-value)"的散列表,而且都是采用拉鏈法實(shí)現(xiàn)的。
不同點(diǎn):
(1)歷史原因:HashTable是基于陳舊的Dictionary類的,HashMap是Java 1.2引進(jìn)的Map接口的一個(gè)實(shí)現(xiàn) 。
(2)同步性:HashTable是線程安全的,也就是說是同步的,而HashMap是線程序不安全的,不是同步的 。
(3)對(duì)null值的處理:HashMap的key、value都可為null,HashTable的key、value都不可為null 。
(4)基類不同:HashMap繼承于AbstractMap,而Hashtable繼承于Dictionary。
??????
Dictionary是一個(gè)抽象類,它直接繼承于Object類,沒有實(shí)現(xiàn)任何接口。Dictionary類是JDK
1.0的引入的。雖然Dictionary也支持“添加key-value鍵值對(duì)”、“獲取value”、“獲取大小”等基本操作,但它的API函數(shù)比Map少;而且Dictionary一般是通過Enumeration(枚舉類)去遍歷,Map則是通過Iterator(迭代M器)去遍歷。然而由于Hashtable也實(shí)現(xiàn)了Map接口,所以,它即支持Enumeration遍歷,也支持Iterator遍歷。
?????
AbstractMap是一個(gè)抽象類,它實(shí)現(xiàn)了Map接口的絕大部分API函數(shù);為Map的具體實(shí)現(xiàn)類提供了極大的便利。它是JDK 1.2新增的類。
(5)支持的遍歷種類不同:HashMap只支持Iterator(迭代器)遍歷。而Hashtable支持Iterator(迭代器)和Enumeration(枚舉器)兩種方式遍歷。
3.HashMap、Hashtable、LinkedHashMap和TreeMap比較
?????
Hashmap 是一個(gè)最常用的Map,它根據(jù)鍵的HashCode 值存儲(chǔ)數(shù)據(jù),根據(jù)鍵可以直接獲取它的值,具有很快的訪問速度。遍歷時(shí),取得數(shù)據(jù)的順序是完全隨機(jī)的。HashMap最多只允許一條記錄的鍵為Null;允許多條記錄的值為Null;HashMap不支持線程的同步,即任一時(shí)刻可以有多個(gè)線程同時(shí)寫HashMap;可能會(huì)導(dǎo)致數(shù)據(jù)的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力。
?????
Hashtable 與 HashMap類似,不同的是:它不允許記錄的鍵或者值為空;它支持線程的同步,即任一時(shí)刻只有一個(gè)線程能寫Hashtable,因此也導(dǎo)致了Hashtale在寫入時(shí)會(huì)比較慢。
?????
LinkedHashMap保存了記錄的插入順序,在用Iterator遍歷LinkedHashMap時(shí),先得到的記錄肯定是先插入的,也可以在構(gòu)造時(shí)用帶參數(shù),按照應(yīng)用次數(shù)排序。在遍歷的時(shí)候會(huì)比HashMap慢,不過有種情況例外,當(dāng)HashMap容量很大,實(shí)際數(shù)據(jù)較少時(shí),遍歷起來可能會(huì)比LinkedHashMap慢,因?yàn)長(zhǎng)inkedHashMap的遍歷速度只和實(shí)際數(shù)據(jù)有關(guān),和容量無關(guān),而HashMap的遍歷速度和他的容量有關(guān)。如果需要輸出的順序和輸入的相同,那么用LinkedHashMap可以實(shí)現(xiàn),它還可以按讀取順序來排列,像連接池中可以應(yīng)用。LinkedHashMap實(shí)現(xiàn)與HashMap的不同之處在于,后者維護(hù)著一個(gè)運(yùn)行于所有條目的雙重鏈表。此鏈接列表定義了迭代順序,該迭代順序可以是插入順序或者是訪問順序。對(duì)于LinkedHashMap而言,它繼承與HashMap、底層使用哈希表與雙向鏈表來保存所有元素。其基本操作與父類HashMap相似,它通過重寫父類相關(guān)的方法,來實(shí)現(xiàn)自己的鏈接列表特性。
?????
TreeMap實(shí)現(xiàn)SortMap接口,內(nèi)部實(shí)現(xiàn)是紅黑樹。能夠把它保存的記錄根據(jù)鍵排序,默認(rèn)是按鍵值的升序排序,也可以指定排序的比較器,當(dāng)用Iterator 遍歷TreeMap時(shí),得到的記錄是排過序的。TreeMap不允許key的值為null。非同步的。?
一般情況下,我們用的最多的是HashMap,HashMap里面存入的鍵值對(duì)在取出的時(shí)候是隨機(jī)的,它根據(jù)鍵的HashCode值存儲(chǔ)數(shù)據(jù),根據(jù)鍵可以直接獲取它的值,具有很快的訪問速度。在Map 中插入、刪除和定位元素,HashMap 是最好的選擇。
????
TreeMap取出來的是排序后的鍵值對(duì)。但如果您要按自然順序或自定義順序遍歷鍵,那么TreeMap會(huì)更好。
?????
LinkedHashMap 是HashMap的一個(gè)子類,如果需要輸出的順序和輸入的相同,那么用LinkedHashMap可以實(shí)現(xiàn),它還可以按讀取順序來排列,像連接池中可以應(yīng)用。?
import?java.util.HashMap;
import?java.util.Iterator;
import?java.util.LinkedHashMap;
import?java.util.TreeMap;
public?class?MapTest {
????public?static?void?main(String[] args) {
????????//HashMap
????????HashMap<String,String> hashMap = new?HashMap();
????????hashMap.put("4", "d");
????????hashMap.put("3", "c");
????????hashMap.put("2", "b");
????????hashMap.put("1", "a");
????????Iterator<String> iteratorHashMap = hashMap.keySet().iterator();
????????System.out.println("HashMap-->");
????????while?(iteratorHashMap.hasNext()){
????????????Object?key1 = iteratorHashMap.next();
????????????System.out.println(key1 + "--"?+ hashMap.get(key1));
????????}
????????//LinkedHashMap
????????LinkedHashMap<String,String> linkedHashMap = new?LinkedHashMap();
????????linkedHashMap.put("4", "d");
????????linkedHashMap.put("3", "c");
????????linkedHashMap.put("2", "b");
????????linkedHashMap.put("1", "a");
????????Iterator<String> iteratorLinkedHashMap = linkedHashMap.keySet().iterator();
????????System.out.println("LinkedHashMap-->");
????????while?(iteratorLinkedHashMap.hasNext()){
????????????Object?key2 = iteratorLinkedHashMap.next();
????????????System.out.println(key2 + "--"?+ linkedHashMap.get(key2));
????????}
????????//TreeMap
????????TreeMap<String,String> treeMap = new?TreeMap();
????????treeMap.put("4", "d");
????????treeMap.put("3", "c");
????????treeMap.put("2", "b");
????????treeMap.put("1", "a");
????????Iterator<String> iteratorTreeMap = treeMap.keySet().iterator();
????????System.out.println("TreeMap-->");
????????while?(iteratorTreeMap.hasNext()){
????????????Object?key3 = iteratorTreeMap.next();
????????????System.out.println(key3 + "--"?+ treeMap.get(key3));
????????}
????}
}輸出結(jié)果:
HashMap-->
3--c
2--b
1--a
4--d
LinkedHashMap-->
4--d
3--c
2--b
1--a
TreeMap-->
1--a
2--b
3--c
4--d4.HashSet、LinkedHashSet、TreeSet比較
Set接口
Set不允許包含相同的元素,如果試圖把兩個(gè)相同元素加入同一個(gè)集合中,add方法返回false。
Set判斷兩個(gè)對(duì)象相同不是使用==運(yùn)算符,而是根據(jù)equals方法。也就是說,只要兩個(gè)對(duì)象用equals方法比較返回true,Set就不會(huì)接受這兩個(gè)對(duì)象。
HashSet
HashSet有以下特點(diǎn):
->? 不能保證元素的排列順序,順序有可能發(fā)生變化。
->? 不是同步的。
->? 集合元素可以是null,但只能放入一個(gè)null。
????
當(dāng)向HashSet結(jié)合中存入一個(gè)元素時(shí),HashSet會(huì)調(diào)用該對(duì)象的hashCode()方法來得到該對(duì)象的hashCode值,然后根據(jù) hashCode值來決定該對(duì)象在HashSet中存儲(chǔ)位置。簡(jiǎn)單的說,HashSet集合判斷兩個(gè)元素相等的標(biāo)準(zhǔn)是兩個(gè)對(duì)象通過equals方法比較相等,并且兩個(gè)對(duì)象的hashCode()方法返回值也相等。
????
注意,如果要把一個(gè)對(duì)象放入HashSet中,重寫該對(duì)象對(duì)應(yīng)類的equals方法,也應(yīng)該重寫其hashCode()方法。其規(guī)則是如果兩個(gè)對(duì)象通過equals方法比較返回true時(shí),其hashCode也應(yīng)該相同。另外,對(duì)象中用作equals比較標(biāo)準(zhǔn)的屬性,都應(yīng)該用來計(jì)算 hashCode的值。
LinkedHashSet
????
LinkedHashSet集合同樣是根據(jù)元素的hashCode值來決定元素的存儲(chǔ)位置,但是它同時(shí)使用鏈表維護(hù)元素的次序。這樣使得元素看起來像是以插入順序保存的,也就是說,當(dāng)遍歷該集合時(shí)候,LinkedHashSet將會(huì)以元素的添加順序訪問集合的元素。
????
LinkedHashSet在迭代訪問Set中的全部元素時(shí),性能比HashSet好,但是插入時(shí)性能稍微遜色于HashSet。
TreeSet類
????
TreeSet是SortedSet接口的唯一實(shí)現(xiàn)類,TreeSet可以確保集合元素處于排序狀態(tài)。TreeSet支持兩種排序方式,自然排序和定制排序,其中自然排序?yàn)槟J(rèn)的排序方式。向TreeSet中加入的應(yīng)該是同一個(gè)類的對(duì)象。
????
TreeSet判斷兩個(gè)對(duì)象不相等的方式是兩個(gè)對(duì)象通過equals方法返回false,或者通過CompareTo方法比較沒有返回0。
自然排序
????
自然排序使用要排序元素的CompareTo(Object obj)方法來比較元素之間大小關(guān)系,然后將元素按照升序排列。
????
Java提供了一個(gè)Comparable接口,該接口里定義了一個(gè)compareTo(Object
obj)方法,該方法返回一個(gè)整數(shù)值,實(shí)現(xiàn)了該接口的對(duì)象就可以比較大小。obj1.compareTo(obj2)方法如果返回0,則說明被比較的兩個(gè)對(duì)象相等,如果返回一個(gè)正數(shù),則表明obj1大于obj2,如果是負(fù)數(shù),則表明obj1小于obj2。如果我們將兩個(gè)對(duì)象的equals方法總是返回true,則這兩個(gè)對(duì)象的compareTo方法返回應(yīng)該返回0。
定制排序
????
自然排序是根據(jù)集合元素的大小,以升序排列,如果要定制排序,應(yīng)該使用Comparator接口,實(shí)現(xiàn) int compare(T o1,T o2)方法。
package com.test;
??
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.TreeSet;
??
/**
?* @description 幾個(gè)set的比較
?* HashSet:哈希表是通過使用稱為散列法的機(jī)制來存儲(chǔ)信息的,元素并沒有以某種特定順序來存放;
?* LinkedHashSet:以元素插入的順序來維護(hù)集合的鏈接表,允許以插入的順序在集合中迭代;
?* TreeSet:提供一個(gè)使用樹結(jié)構(gòu)存儲(chǔ)Set接口的實(shí)現(xiàn),對(duì)象以升序順序存儲(chǔ),訪問和遍歷的時(shí)間很快。
?* @author Zhou-Jingxian
?*
?*/??
public?class?SetDemo?{
??
????public?static?void?main(String[] args) {
??
????????HashSet hs = new?HashSet();
????????hs.add("B");
????????hs.add("A");
????????hs.add("D");
????????hs.add("E");
????????hs.add("C");
????????hs.add("F");
????????System.out.println("HashSet 順序:\n"+hs);
??????????
????????LinkedHashSet lhs = new?LinkedHashSet();
????????lhs.add("B");
????????lhs.add("A");
????????lhs.add("D");
????????lhs.add("E");
????????lhs.add("C");
????????lhs.add("F");
????????System.out.println("LinkedHashSet 順序:\n"+lhs);
??????????
????????TreeSet ts = new?TreeSet();
????????ts.add("B");
????????ts.add("A");
????????ts.add("D");
????????ts.add("E");
????????ts.add("C");
????????ts.add("F");
????????System.out.println("TreeSet 順序:\n"+ts);
????}
} 輸出結(jié)果:
HashSet 順序:[D, E, F, A, B, C]
LinkedHashSet 順序:[B, A, D, E, C, F]
TreeSet 順序:[A, B, C, D, E, F]
?
5、Iterator和ListIterator區(qū)別
?????
我們?cè)谑褂肔ist,Set的時(shí)候,為了實(shí)現(xiàn)對(duì)其數(shù)據(jù)的遍歷,我們經(jīng)常使用到了Iterator(迭代器)。使用迭代器,你不需要干涉其遍歷的過程,只需要每次取出一個(gè)你想要的數(shù)據(jù)進(jìn)行處理就可以了。但是在使用的時(shí)候也是有不同的。List和Set都有iterator()來取得其迭代器。對(duì)List來說,你也可以通過listIterator()取得其迭代器,兩種迭代器在有些時(shí)候是不能通用的,Iterator和ListIterator主要區(qū)別在以下方面:
(1)ListIterator有add()方法,可以向List中添加對(duì)象,而Iterator不能
(2)ListIterator和Iterator都有hasNext()和next()方法,可以實(shí)現(xiàn)順序向后遍歷,但是ListIterator有hasPrevious()和previous()方法,可以實(shí)現(xiàn)逆向(順序向前)遍歷。Iterator就不可以。
(3)ListIterator可以定位當(dāng)前的索引位置,nextIndex()和previousIndex()可以實(shí)現(xiàn)。Iterator沒有此功能。
(4)都可實(shí)現(xiàn)刪除對(duì)象,但是ListIterator可以實(shí)現(xiàn)對(duì)象的修改,set()方法可以實(shí)現(xiàn)。Iierator僅能遍歷,不能修改。
因?yàn)長(zhǎng)istIterator的這些功能,可以實(shí)現(xiàn)對(duì)LinkedList等List數(shù)據(jù)結(jié)構(gòu)的操作。其實(shí),數(shù)組對(duì)象也可以用迭代器來實(shí)現(xiàn)。
6、Collection 和 Collections區(qū)別
(1)java.util.Collection 是一個(gè)集合接口(集合類的一個(gè)頂級(jí)接口)。它提供了對(duì)集合對(duì)象進(jìn)行基本操作的通用接口方法。Collection接口在Java 類庫中有很多具體的實(shí)現(xiàn)。Collection接口的意義是為各種具體的集合提供了最大化的統(tǒng)一操作方式,其直接繼承接口有List與Set。
?Collection???
├List???
│├LinkedList???
│├ArrayList???
│└Vector???
│ └Stack???
└Set?
(2)java.util.Collections 是一個(gè)包裝類(工具類/幫助類)。它包含有各種有關(guān)集合操作的靜態(tài)多態(tài)方法。此類不能實(shí)例化,就像一個(gè)工具類,用于對(duì)集合中元素進(jìn)行排序、搜索以及線程安全等各種操作,服務(wù)于Java的Collection框架。
代碼示例:
import?java.util.ArrayList;
import?java.util.Collections;
import?java.util.List;
??
public?class?TestCollections?{?
??????
????public?static?void?main(String args[])?{
????????//注意List是實(shí)現(xiàn)Collection接口的
????????List list?= new?ArrayList();
????????double?array[] = { 112, 111, 23, 456, 231?};
????????for?(int?i = 0; i < array.length; i++) {
????????????list.add(new?Double(array[i]));
????????}
????????Collections.sort(list);
????????for?(int?i = 0; i < array.length; i++) {
????????????System.out.println(list.get(i));
????????}
????????// 結(jié)果:23.0 111.0 112.0 231.0 456.0
????}
}原文鏈接:cnblogs.com/xiaoxi/p/6089984.html