
Apache Flink是流式計算處理領(lǐng)域的領(lǐng)跑者。它憑借易用、高吞吐、低延遲、豐富的算子和原生狀態(tài)支持等優(yōu)勢,多方位領(lǐng)先同領(lǐng)域的開源競品。同樣地,ClickHouse是OLAP在線分析領(lǐng)域的一顆冉冉新星,它擁有極其出眾的查詢性能,以及豐富的分析函數(shù),可以助力分析師靈活而迅速地挖掘海量數(shù)據(jù)的價值。然而金無足赤,人無完人,每個組件都有自己擅長和不擅長的方面。為了實現(xiàn)構(gòu)造高性能實時數(shù)倉的目標,接下來的文章會介紹如何將它們巧妙地結(jié)合起來,取長補短,最終實現(xiàn)“效率翻倍,快樂加倍”的夢想。
面對海量的業(yè)務(wù)數(shù)據(jù),有很多因素會顯著降低我們的端對端查詢效率(即數(shù)據(jù)從產(chǎn)生到最終消費的全流程效率)。第一個因素是業(yè)務(wù)需求多樣,分析的鏈路繁雜。例如我們有一個電商相關(guān)的數(shù)據(jù)庫,做增長分析的同學需要用它的數(shù)據(jù)來進行用戶畫像,以便實施精準營銷,例如對新用戶、流失用戶制定不同的營銷策略;而做風控的同學則需要把數(shù)據(jù)接入機器學習模型,打擊“羊毛黨”和黑產(chǎn)用戶。
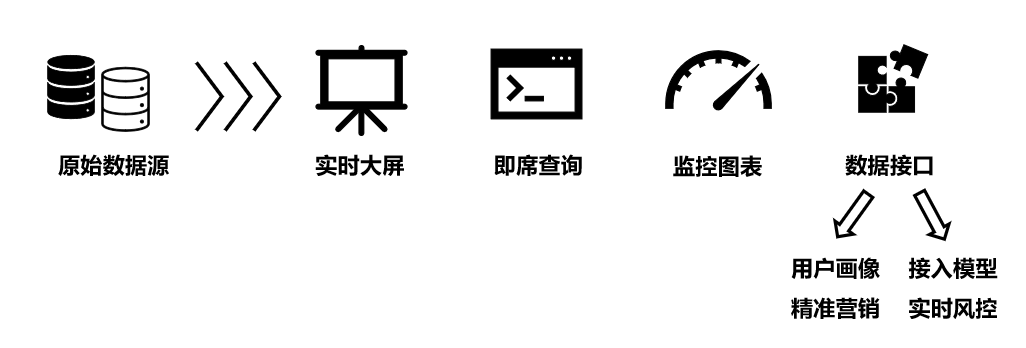
如果不加約束,大家都從原始數(shù)據(jù)源來讀取數(shù)據(jù)并分析,一方面對原始數(shù)據(jù)源的壓力非常大(同時承擔著各類業(yè)務(wù)的寫請求、讀請求),另一方面分析鏈路難以復用,最終會形成重復開發(fā)、各自為政的“煙囪模式”,開發(fā)慢,運維難。第二個因素是數(shù)據(jù)量龐大且多樣化,傳統(tǒng)的分析工具難以應(yīng)對:
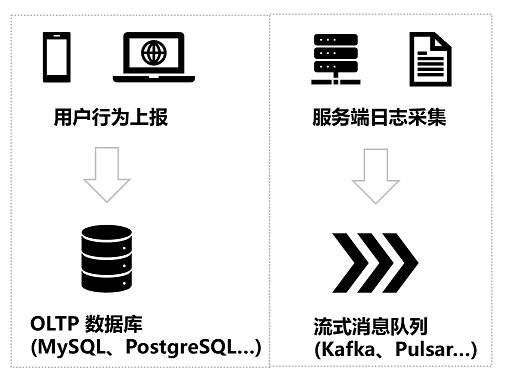
例如我們通常用MySQL、PostgreSQL、Oracle等OLTP(Online Transation Processing)數(shù)據(jù)庫來存放各類的交易流水等數(shù)據(jù),它們的優(yōu)點是支持高并發(fā)、低延遲讀寫,且對事務(wù)提供了完整的支持。但是缺點是復雜查詢(聚合、窗口、分組等)性能差,且缺少數(shù)據(jù)分析常用的各類函數(shù),用作數(shù)據(jù)分析場景既低效,又不方便,還可能影響線上業(yè)務(wù)的穩(wěn)定性。因此,我們需要OLAP(Online Analytical Processing)引擎構(gòu)造的數(shù)據(jù)倉庫(例如我們的ClickHouse 就可以被用作OLAP引擎),來滿足海量數(shù)據(jù)的復雜查詢能力。但它們通常并發(fā)讀寫的能力差,且事務(wù)支持不完備,因此也不建議直接用作線上的唯一數(shù)據(jù)存取系統(tǒng)。通常我們會使用CDC(Change Data Capture,變更數(shù)據(jù)捕獲)工具,例如Debezium、Canal等,將OLTP數(shù)據(jù)庫的流水實時同步到OLAP系統(tǒng)以供分析,這樣可以充分發(fā)揮兩套系統(tǒng)各自的優(yōu)勢。有些系統(tǒng)宣稱自己同時滿足OLAP和OLTP的特性,通常被稱為HTAP(Hybrid Transactional/Analytical Processing)。但實際上對于很多HTAP系統(tǒng)而言,往往只是在內(nèi)部將兩套系統(tǒng)的CDC數(shù)據(jù)同步的過程對用戶隱藏了,本質(zhì)上還是異構(gòu)的。此外,我們還會有一些流式數(shù)據(jù),例如日志采集流、用戶點擊流等,它們以流的形式源源不斷輸入,且有很強的時效性,且順序在傳輸過程中很容易錯亂,導致分析起來異常困難。第三個因素是數(shù)據(jù)源繁雜,組件和格式眾多,接入起來耗時長:
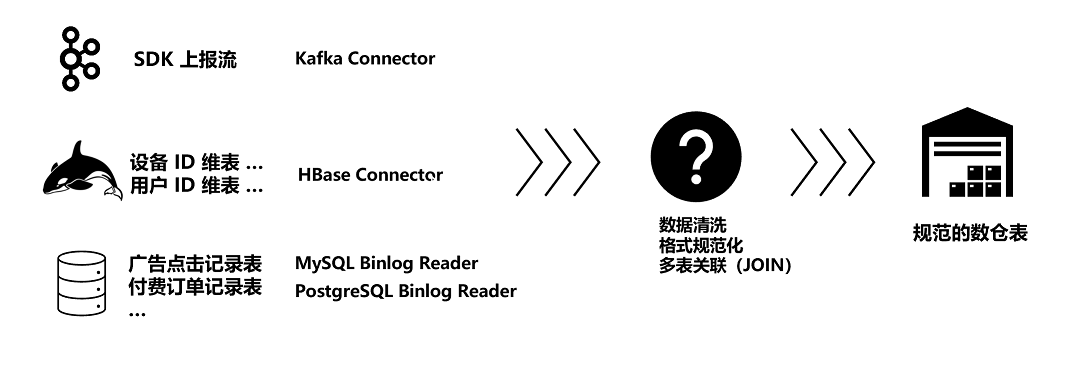
例如一個業(yè)務(wù)可能用Kafka來承接從SDK中上報的各類點擊流數(shù)據(jù),又使用HBase等KV系統(tǒng)來存儲維表信息,還使用傳統(tǒng)的MySQL、PostgreSQL數(shù)據(jù)庫來保存精確的廣告點擊記錄和付費訂單記錄等等。這些數(shù)據(jù)來自不同數(shù)據(jù)源,如何將它們規(guī)范化,并合理地關(guān)聯(lián)在一起,最終寫入到數(shù)倉中,也是一個難點和重點。上述痛點和難點如果不加解決,會嚴重拖慢分析師的效率:輕則影響拓客和營銷的效果,巨額的投入得不到轉(zhuǎn)化;重則會因為風控系統(tǒng)失靈,對業(yè)務(wù)造成毀滅性打擊。因此我們必須通過系統(tǒng)化的體系構(gòu)建,選擇合適的工具組件,逐一解決上述提到的效率困境。
我們知道,數(shù)據(jù)倉庫(Data Warehouse)是面向主題的、集成的一套系統(tǒng)。它遵循一系列的建模規(guī)范,每層致力于解決不同的問題。下圖是一個典型的實時數(shù)倉架構(gòu),它分為外部應(yīng)用、應(yīng)用層(ADS或APP)、匯總層(DWS)、明細層(DWD)和維度層(DIM),以及原始數(shù)據(jù)層(ODS)。我們以電商行業(yè)的互聯(lián)網(wǎng)精準營銷為例子,講解一下典型的實時數(shù)倉結(jié)構(gòu)。
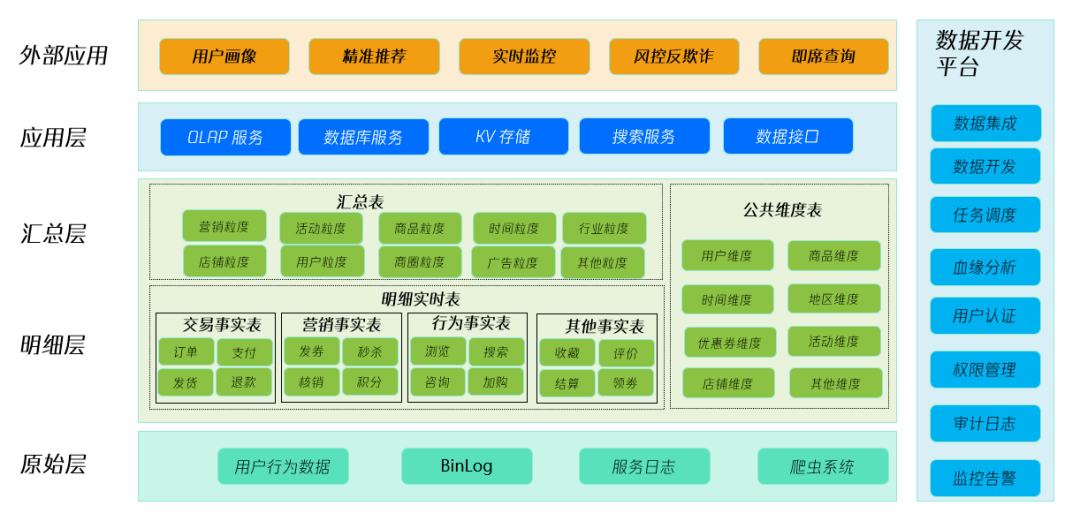
實時數(shù)倉可以對接很多外部應(yīng)用,例如用戶畫像、精準推薦系統(tǒng)可以針對性地推送營銷活動,做到“千人千面”,如下圖;BI實時大屏可以將雙11大促的總體交易數(shù)據(jù)圖表化;實時監(jiān)控則能讓運維及時感知服務(wù)和主機運行的風險;風控反欺詐則可以對業(yè)務(wù)運行數(shù)據(jù)做展示,配合告警閾值系統(tǒng),可以實時監(jiān)控用戶行為和訂單量異常等風險因子等;即席查詢可以應(yīng)對分析師靈光一現(xiàn)的突發(fā)查詢需求。
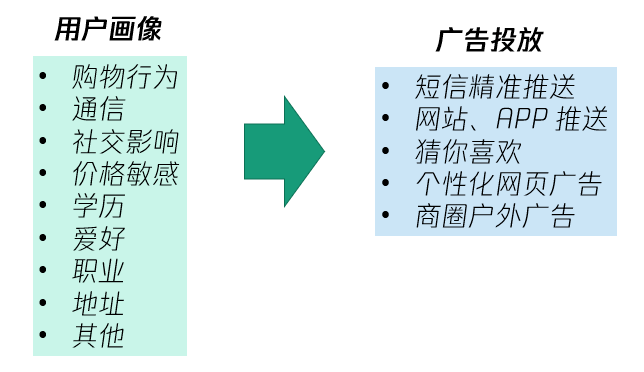
應(yīng)用層承擔了各類數(shù)據(jù)應(yīng)用的基礎(chǔ)設(shè)施,例如KV存儲(HBase等)、數(shù)據(jù)庫服務(wù)(PostgreSQL等)、OLAP服務(wù)(ClickHouse等)、搜索服務(wù)(Elasticsearch等),為上層的外部應(yīng)用提供支持。實時數(shù)倉的應(yīng)用層的數(shù)據(jù)來源于匯總層的各類多維主題寬表和匯總表,例如營銷匯總表、活動匯總表、商品匯總表等等。這樣,業(yè)務(wù)方只需要從不同的主題匯總表中讀取數(shù)據(jù),無需再單獨對各類數(shù)據(jù)源做一整套分析鏈路。如果寬表字段設(shè)計合理,內(nèi)容足夠豐富的話,可以大大緩解開發(fā)慢的問題。此外,還可以導出數(shù)據(jù)接口,以供其他業(yè)務(wù)部門對接。匯總層的數(shù)據(jù)是從明細層和維度層關(guān)聯(lián)而來的。由于ClickHouse等OLAP 工具對關(guān)聯(lián)(JOIN)的性能較弱,因此我們可以采用Flink來實現(xiàn)流式數(shù)據(jù)的高效動態(tài)JOIN,并將實時的關(guān)聯(lián)數(shù)據(jù)定義為寬表并寫入ClickHouse以供應(yīng)用層后續(xù)分析查詢。由于ClickHouse等OLAP引擎的強勁性能,海量數(shù)據(jù)的分析慢等問題也可以得到一定程度的解決。明細層通常是經(jīng)過清洗過濾等規(guī)范化操作后的各類主題的事實表,例如訂單交易數(shù)據(jù)、瀏覽數(shù)據(jù)等,而維度表則保存了數(shù)據(jù)中ID與實際字段的映射關(guān)系,以及其他變化緩慢但可以用來補充寬表的數(shù)據(jù)。原始層是對各類數(shù)據(jù)源的接入映射,例如業(yè)務(wù)方寫入Kafka的各類Topics,以及MySQL等數(shù)據(jù)庫的Binlog等原始數(shù)據(jù)等等。主要側(cè)重于數(shù)據(jù)攝取和簡單存儲,是上面各層的數(shù)據(jù)來源。由于Flink等流計算平臺具有豐富的Connector以對接各種外部系統(tǒng),且提供了豐富的自定義接口,我們接入各類異構(gòu)的數(shù)據(jù)源也不成問題了。
ClickHouse是一個用于聯(lián)機分析 (OLAP) 的列式數(shù)據(jù)庫管理系統(tǒng)(DBMS),它采用了列式存儲、數(shù)據(jù)壓縮、多核并行、向量引擎、分布式處理等技術(shù),性能遙遙領(lǐng)先競品。例如我們給定一條數(shù)據(jù)分析時常見的分組和排序查詢語句:
SELECT Phone, Model, uniq(UID) AS uFROM hitsWHERE Model != ''GROUP BY Phone, ModelORDER BY u DESCLIMIT 10;
下圖是1億條數(shù)據(jù)量級下,ClickHouse與多種常見數(shù)據(jù)處理系統(tǒng)的查詢速度對比圖(數(shù)字越小代表耗時越短,性能越好),可以看到ClickHouse的性能數(shù)據(jù)遙遙領(lǐng)先:

ClickHouse與其他產(chǎn)品的性能對比盡管ClickHouse的數(shù)據(jù)分析能力如此高效,它還是有自己不擅長的地方:
而這些ClickHouse不擅長做的事情,剛好是Flink最適合的領(lǐng)域:
由于開源版Flink的應(yīng)用開發(fā)、調(diào)優(yōu)、監(jiān)控、運維較為繁瑣,騰訊云為了解決這些痛點,推出了流計算Oceanus產(chǎn)品。它是基于Apache Flink的實時化分析利器,具備一站開發(fā)、無縫連接、亞秒延時、低廉成本、安全穩(wěn)定等特點,致力于打造企業(yè)級實時大數(shù)據(jù)分析平臺。它提供了豐富的運維開發(fā)、監(jiān)控告警、異常檢測能力,融合了技術(shù)團隊多年的Flink開發(fā)和運維經(jīng)驗,并持續(xù)為Flink內(nèi)核與生態(tài)貢獻力量。
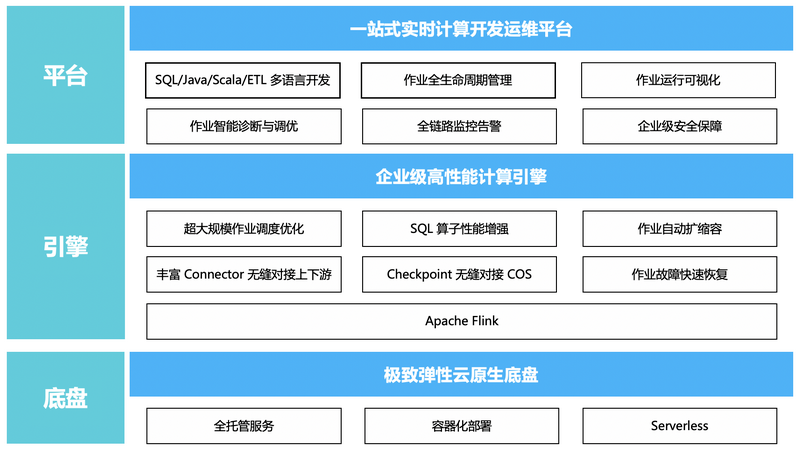
騰訊云Oceanus
五、打造穩(wěn)定可靠的實時數(shù)倉v1.0
對于實時數(shù)倉的構(gòu)造方法,業(yè)界和學界有很多的探索和實踐。Lambda架構(gòu)是一個成熟且廣為采用的方案。它分為離線批處理和實時流處理兩個子系統(tǒng)。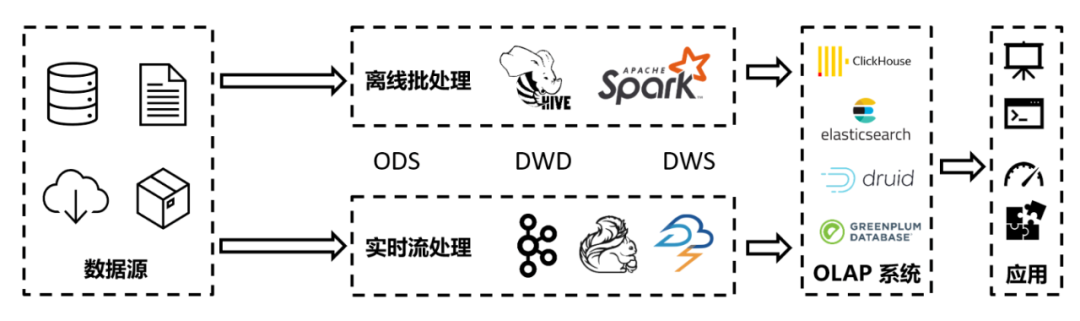
Lambda架構(gòu)的優(yōu)點是離線和在線的數(shù)據(jù)源統(tǒng)一的前提下,準確性和容錯性相對較好。例如實時流處理遇到了故障導致輸出的結(jié)果不夠精確時,離線批處理系統(tǒng)可以把數(shù)據(jù)重跑一次,用更精確的數(shù)據(jù)來覆蓋它。但Lambda的缺點也很明顯:離線和實時采用獨立的平臺,每個分析語句都需要重復寫兩套,而且運維人員也需要維護兩套以上的系統(tǒng),成本高昂。而且如果兩套系統(tǒng)的數(shù)據(jù)口徑不一致,那么離線重算的結(jié)果,很可能和實時部分產(chǎn)生較大偏差,造成數(shù)據(jù)的“跳變”等異常,反而失去了準確性的優(yōu)勢。問題解決
當我們推動這套實時數(shù)倉系統(tǒng)落地時,會遇到一些實踐的問題:(一)如何將大量的流數(shù)據(jù),從Flink高效地寫入到ClickHouse
我們知道,寫入ClickHouse時,既可以寫分布式表,也可以直接寫本地表。寫分布式表的優(yōu)點在于不需要關(guān)注太多底層節(jié)點的細節(jié),但是缺點也很明顯:由于數(shù)據(jù)需要被集中緩存和轉(zhuǎn)發(fā),會增加一定的延時,且會加重短期的數(shù)據(jù)不一致現(xiàn)象;此外,網(wǎng)絡(luò)方面壓力也較大,連接數(shù)和網(wǎng)絡(luò)流量都會有較大的上升。因此,如果我們要寫入的數(shù)據(jù)量很大的話,可以事先獲取各節(jié)點的連接地址,通過寫本地表的方式直接寫入各個節(jié)點。寫入本地表的方式可以有很多,例如為了防止節(jié)點之間出現(xiàn)較為嚴重的數(shù)據(jù)傾斜,可在每次寫入式隨機選擇一個節(jié)點;也可以采用輪詢的方式,每次寫入下一個不同節(jié)點。如果數(shù)據(jù)后續(xù)要按Key進行聚合,那么還可以使用散列的方式,將相同Key的數(shù)據(jù)寫到同一個節(jié)點,如下圖所示:
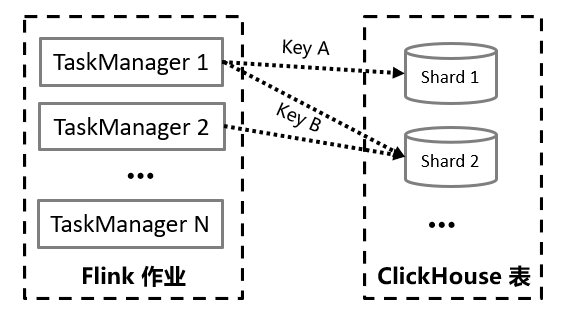
另外我們注意到,流式數(shù)據(jù)通常會包含大量的更新和刪除操作。為了支持頻繁變更的數(shù)據(jù),可以將Flink的Retract Stream(回撤流)、Upsert Stream(更新-插入流)等含有狀態(tài)標記的數(shù)據(jù)流,寫入到ClickHouse的 CollapsingMergeTree引擎表中。例如下圖(來自Flink官方文檔[https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/concepts/dynamic_tables/])中的GROUP BY查詢會隨著新數(shù)據(jù)的寫入,對user這個Key的統(tǒng)計值cnt進行持續(xù)的更新。當Mary第二次出現(xiàn)時,cnt統(tǒng)計值由1變成了2,那么可以對舊記錄發(fā)一條sign為-1的消息,和之前那條sign為1的記錄相互抵消。然后再寫入新的cnt為2的記錄。后續(xù)Mary第三次出現(xiàn)時,執(zhí)行同樣的操作,即可保證寫入ClickHouse的最終統(tǒng)計數(shù)據(jù)是準確的。
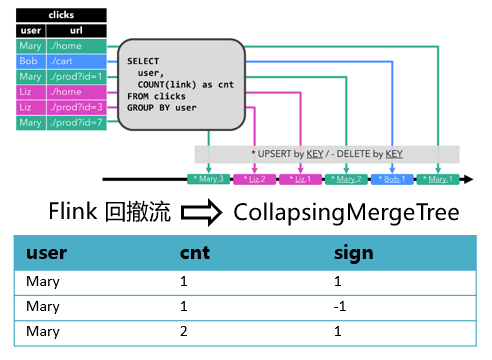
Flink回撤流與CollapsingMergeTree的映射考慮到ClickHouse擅長大批量寫入的特點,還需要對Flink ClickHouse Sink增加攢批寫入的支持,避免頻繁寫入造成的性能下降問題;此外還有故障重試策略、Flink與ClickHouse之間的SQL類型映射等需要關(guān)注的點。做好了這些,我們才可以得到一個性能、穩(wěn)定性俱佳的Flink ClickHouse Connector。(二)如何評價數(shù)倉的質(zhì)量
當我們完成了對數(shù)倉的初步建模和構(gòu)建后,數(shù)據(jù)質(zhì)量驗證是決定數(shù)倉是否真正可用的關(guān)鍵環(huán)節(jié),需要關(guān)注的有:一致性、準確性、容錯能力、鏈路延遲等。對于業(yè)務(wù)方和平臺方而言,各自需要關(guān)注和保證不同的方面,如下圖所示:

業(yè)務(wù)方需要盡早制定并嚴格遵守數(shù)據(jù)格式(Schema)的規(guī)范,因為Flink SQL和很多Connector是不支持運行時動態(tài)修改表結(jié)構(gòu)的。如果需要修改,則作業(yè)的狀態(tài)準確度可能受到影響,甚至需要重新跑一遍所有數(shù)據(jù),代價很大。此外,對于離線和實時鏈路,一定要保證數(shù)據(jù)源的口徑是一致的,不然會出現(xiàn)數(shù)據(jù)“跳變”的問題。對于多分區(qū)的數(shù)據(jù)源(例如Kafka等),還要保證應(yīng)當將數(shù)據(jù)有序?qū)懭雴蝹€分區(qū),否則亂序的數(shù)據(jù)會影響流處理的精度,造成結(jié)果錯亂。對于平臺提供方,例如我們騰訊云流計算Oceanus而言,需要提供元數(shù)據(jù)管理等基本能力,避免實際需要修改表結(jié)構(gòu)時,難以追蹤多個不同作業(yè)之間的依賴關(guān)系,造成錯漏。同時平臺方需要集成Flink自帶的狀態(tài)快照功能,精確保存作業(yè)的運行時狀態(tài),并在作業(yè)發(fā)生異常時使用最近的狀態(tài)來恢復作業(yè),以最大程度地保證計算精度,減少誤差的存在。Flink提供的Watermark機制也可以做到一定程度的亂序數(shù)據(jù)重整,對避免結(jié)果錯亂也很有幫助。如果從離線數(shù)倉或其他版本的數(shù)倉系統(tǒng)遷移到實時數(shù)倉時,一定要做雙寫驗證,確保新系統(tǒng)的計算結(jié)果與原系統(tǒng)保持一致。另外可以使用例如Apache Griffin(https://griffin.apache.org/) 等數(shù)據(jù)質(zhì)量監(jiān)控工具,實現(xiàn)數(shù)據(jù)異常的發(fā)現(xiàn)和告警。對于重點任務(wù),還可以通過熱備等方式,避免單個任務(wù)由于外部不可控原因而發(fā)生崩潰時,引發(fā)輸出中斷等事故。實時數(shù)倉相比離線數(shù)倉平臺,對質(zhì)量的評價標準還多了一項:鏈路延遲。如果不能及時得到數(shù)據(jù)輸出的話,這個數(shù)倉也是不合格的。而影響鏈路時延有很多不同因素,例如:

流計算Oceanus平臺為了確保及時發(fā)現(xiàn)上述問題,也做了很多優(yōu)化工作。例如,我們支持70+項Flink核心指標的訂閱,用戶可在界面上查看數(shù)據(jù)源(Source)的實時數(shù)據(jù)攝入量、鏈路處理時延、JobManager和TaskManager內(nèi)存各分區(qū)的用量、GC次數(shù)等指標;也可以通過自定義 Reporter,將Flink監(jiān)控數(shù)據(jù)導出到自己的Prometheus等外部系統(tǒng)來自助分析。在異常感知方面,流計算Oceanus平臺還可以自動診斷作業(yè)運行期間的常見異常事件,例如TaskManager CPU占用率過高、Full GC事件過久、嚴重背壓、Pod異常退出等,事件可以秒級送達,幫助用戶及時獲知并處理作業(yè)的異常情況。六、持續(xù)演進批流融合數(shù)倉v2.0
在實時數(shù)倉領(lǐng)域,除了上述介紹的Lambda架構(gòu)外,還有一個比較流行的Kappa架構(gòu),如圖所示:
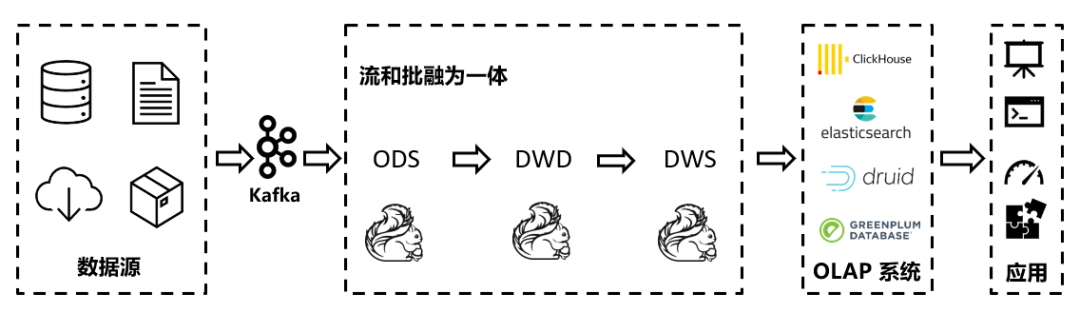
相比Lambda架構(gòu)而言,Kappa架構(gòu)將流和批融為一體,不再分為兩條數(shù)據(jù)處理鏈路,數(shù)據(jù)統(tǒng)一經(jīng)過流式數(shù)據(jù)管道傳遞,清晰簡明,可以大幅降低開發(fā)和運維成本。但是它的缺點也很明顯:由于數(shù)據(jù)傳輸都需要經(jīng)過消息隊列等數(shù)據(jù)管道,為了保證作業(yè)崩潰或邏輯修改后可以隨時追溯歷史數(shù)據(jù),消息需要有很長的保存期。此外,由于各層之間沒有可落盤的文件存儲,難以直接分析中間層的數(shù)據(jù),通常需要啟動一個單獨的作業(yè)來導出數(shù)據(jù)才能分析,靈活度欠佳。為了解決Kappa架構(gòu)的缺點,我們引入新一代的表結(jié)構(gòu):Apache Iceberg(https://iceberg.apache.org/),它的優(yōu)點如下:

Iceberg同時支持流式讀寫和批量讀寫。對于實時鏈路而言,它可以在一定程度上代替Kafka等傳統(tǒng)流式數(shù)據(jù)管道;對于需要讀取中間層的數(shù)據(jù)等特殊需求,又可以使用常見的批處理分析工具來直接分析Iceberg數(shù)據(jù)文件,非常便捷。如果流作業(yè)發(fā)生了崩潰等情形,還可以借助它高效的歷史數(shù)據(jù)回溯能力,快速從特定的時間點開始重新消費數(shù)據(jù),如下圖:
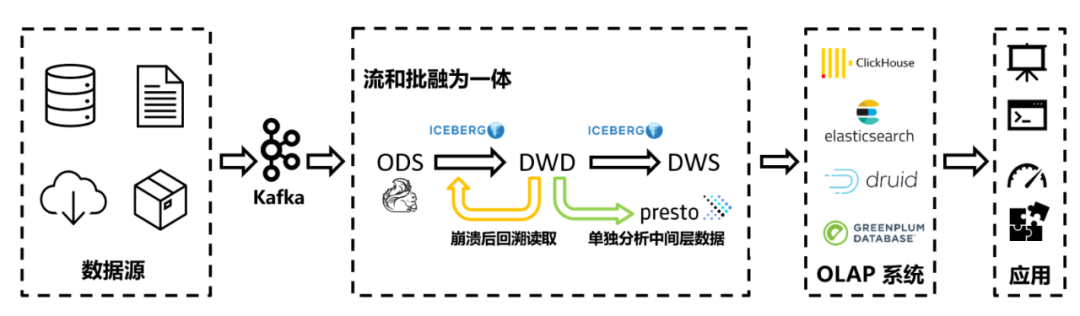
使用Flink和Iceberg構(gòu)造實時數(shù)倉此外,它還支持超長的數(shù)據(jù)保存期,不必擔心數(shù)據(jù)保存期過短,歷史數(shù)據(jù)被清理而難以回溯等傳統(tǒng)數(shù)據(jù)管道會遇到的難題,因此Iceberg的引入,彌補了傳統(tǒng)Kappa架構(gòu)的各類缺點。雖然Iceberg等組件的成熟度相對而言沒有那么高,但是已經(jīng)有不少大客戶在使用了。相信在不久的未來,我們可以看到更多的類似的組件在生產(chǎn)環(huán)境的持續(xù)落地。
當數(shù)據(jù)量總體較小時,傳統(tǒng)的OLTP數(shù)據(jù)庫已經(jīng)可以初步滿足分析需求。但是隨著數(shù)據(jù)量的劇增,以及分析邏輯的復雜化,OLTP數(shù)據(jù)庫已經(jīng)無法滿足需求時,業(yè)界逐步發(fā)展出了離線OLAP引擎和離線數(shù)倉等應(yīng)用技術(shù)。后來隨著大家對實時性的關(guān)注,在離線數(shù)倉的基礎(chǔ)上又演進出了Lambda實時數(shù)倉。為了解決Lambda數(shù)倉重復開發(fā)和運維的繁雜等缺陷,Kappa數(shù)倉也漸漸得到了采納。為了彌補Kappa數(shù)倉的缺點,很多公司又設(shè)計了批流融合的數(shù)據(jù)格式,打造了融合的一體化數(shù)倉結(jié)構(gòu)。例如Iceberg(https://iceberg.apache.org/)、Hudi(https://hudi.apache.org/) 為批處理的文件格式增加了流式讀寫支持;而Pulsar(https://pulsar.apache.org/)、Pravega(http://pravega.io/)則為數(shù)據(jù)流增加了批處理所需的長期持久化存儲特性。

流計算Oceanus產(chǎn)品在實時數(shù)倉領(lǐng)域長期深耕,也將批流融合數(shù)倉也作為重點發(fā)展方向。在不久的將來,我們會提供一整套的全面數(shù)倉構(gòu)造的解決方案,助力企業(yè)數(shù)據(jù)價值最大化,加速企業(yè)實時化數(shù)字化的建設(shè)進程,實現(xiàn)效率騰飛的夢想。(作者:董偉柯——騰訊云大數(shù)據(jù)產(chǎn)品中心高級工程師)流計算Oceanus&ClickHouse服務(wù)組合套餐限時放價售賣中↓↓

??戳「閱讀原文」立即預約直播,了解更多信息~
