
從源碼分析如何優(yōu)雅的使用 Kafka 生產者
本文公眾號來源:crossoverJie作者:crossoverJie本文已收錄至我的GitHub前言
其中有朋友咨詢在大量消息的情況下 Kakfa 是如何保證消息的高效及一致性呢?
正好以這個問題結合 Kakfa 的源碼討論下如何正確、高效的發(fā)送消息。
簡單的消息發(fā)送內容較多,對源碼感興趣的朋友請系好安全帶?(源碼基于
v0.10.0.0版本分析)。同時最好是有一定的 Kafka 使用經驗,知曉基本的用法。
在分析之前先看一個簡單的消息發(fā)送是怎么樣的。
以下代碼基于 SpringBoot 構建。
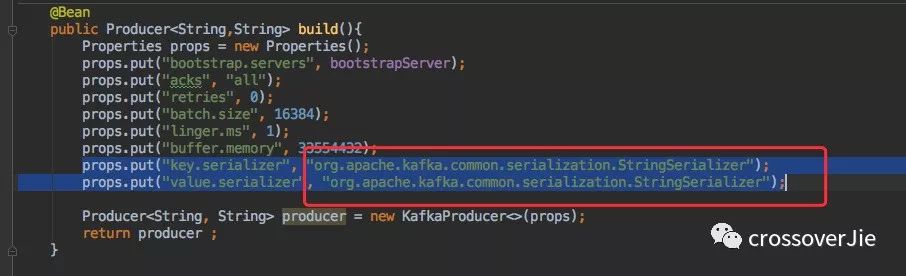
首先創(chuàng)建一個 org.apache.kafka.clients.producer.Producer 的 bean。
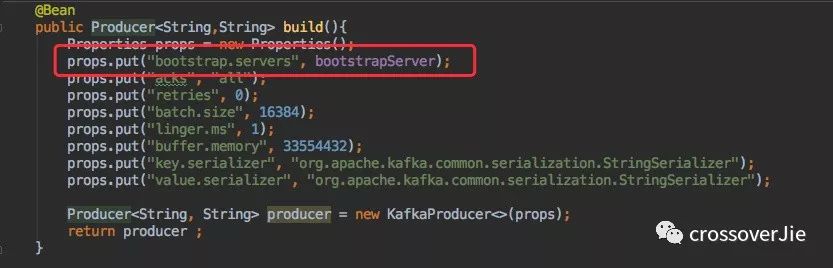
主要關注 bootstrap.servers,它是必填參數。指的是 Kafka 集群中的 broker 地址,例如 127.0.0.1:9094。
其余幾個參數暫時不做討論,后文會有詳細介紹。
接著注入這個 bean 即可調用它的發(fā)送函數發(fā)送消息。
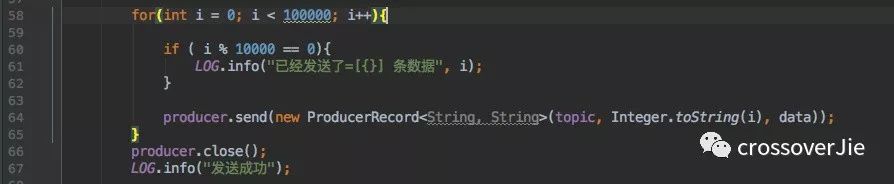
這里我給某一個 Topic 發(fā)送了 10W 條數據,運行程序消息正常發(fā)送。
但這僅僅只是做到了消息發(fā)送,對消息是否成功送達完全沒管,等于是純 異步的方式。
同步
那么我想知道消息到底發(fā)送成功沒有該怎么辦呢?
其實 Producer 的 API 已經幫我們考慮到了,發(fā)送之后只需要調用它的 get() 方法即可同步獲取發(fā)送結果。

發(fā)送結果:

這樣的發(fā)送效率其實是比較低下的,因為每次都需要同步等待消息發(fā)送的結果。
異步
為此我們應當采取異步的方式發(fā)送,其實 send() 方法默認則是異步的,只要不手動調用 get() 方法。
但這樣就沒法獲知發(fā)送結果。
所以查看 send() 的 API 可以發(fā)現還有一個參數。
Future<RecordMetadata> send(ProducerRecord<K, V> producer,Callback callback);
Callback 是一個回調接口,在消息發(fā)送完成之后可以回調我們自定義的實現。
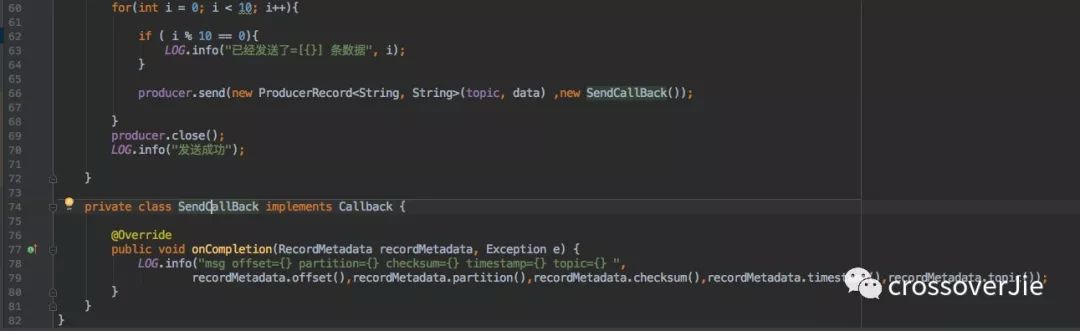
執(zhí)行之后的結果:

同樣的也能獲取結果,同時發(fā)現回調的線程并不是上文同步時的 主線程,這樣也能證明是異步回調的。
同時回調的時候會傳遞兩個參數:
RecordMetadata?和上文一致的消息發(fā)送成功后的元數據。Exception?消息發(fā)送過程中的異常信息。
但是這兩個參數并不會同時都有數據,只有發(fā)送失敗才會有異常信息,同時發(fā)送元數據為空。
所以正確的寫法應當是:
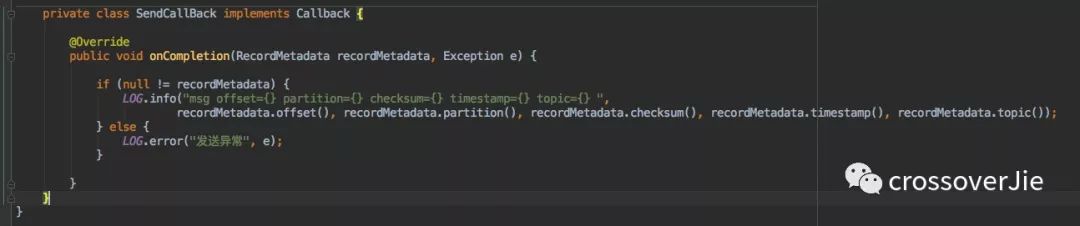
源碼分析至于為什么會只有參數一個有值,在下文的源碼分析中會一一解釋。
現在只掌握了基本的消息發(fā)送,想要深刻的理解發(fā)送中的一些參數配置還是得源碼說了算。
首先還是來談談消息發(fā)送時的整個流程是怎么樣的, Kafka 并不是簡單的把消息通過網絡發(fā)送到了 broker中,在 Java 內部還是經過了許多優(yōu)化和設計。
發(fā)送流程
為了直觀的了解發(fā)送的流程,簡單的畫了幾個在發(fā)送過程中關鍵的步驟。
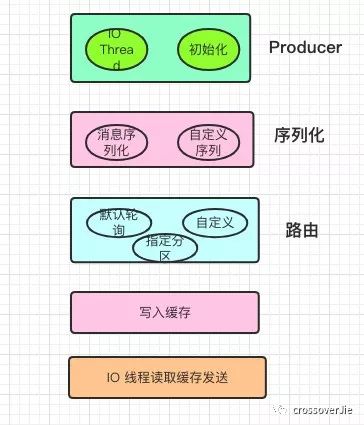
從上至下依次是:
初始化以及真正發(fā)送消息的?
kafka-producer-network-thread?IO 線程。將消息序列化。
得到需要發(fā)送的分區(qū)。
寫入內部的一個緩存區(qū)中。
初始化的 IO 線程不斷的消費這個緩存來發(fā)送消息。
步驟解析
接下來詳解每個步驟。
初始化

調用該構造方法進行初始化時,不止是簡單的將基本參數寫入 KafkaProducer。比較麻煩的是初始化 Sender 線程進行緩沖區(qū)消費。
初始化 IO 線程處:

可以看到 Sender 線程有需要成員變量,比如:
acks,retries,requestTimeout
等,這些參數會在后文分析。
序列化消息
在調用 send() 函數后其實第一步就是序列化,畢竟我們的消息需要通過網絡才能發(fā)送到 Kafka。

其中的 valueSerializer.serialize(record.topic(),record.value()); 是一個接口,我們需要在初始化時候指定序列化實現類。
我們也可以自己實現序列化,只需要實現 org.apache.kafka.common.serialization.Serializer 接口即可。
路由分區(qū)
接下來就是路由分區(qū),通常我們使用的 Topic 為了實現擴展性以及高性能都會創(chuàng)建多個分區(qū)。
如果是一個分區(qū)好說,所有消息都往里面寫入即可。
但多個分區(qū)就不可避免需要知道寫入哪個分區(qū)。
通常有三種方式。
指定分區(qū)
可以在構建 ProducerRecord 為每條消息指定分區(qū)。
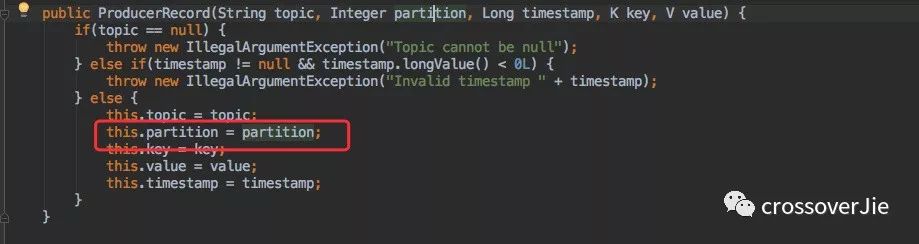
這樣在路由時會判斷是否有指定,有就直接使用該分區(qū)。
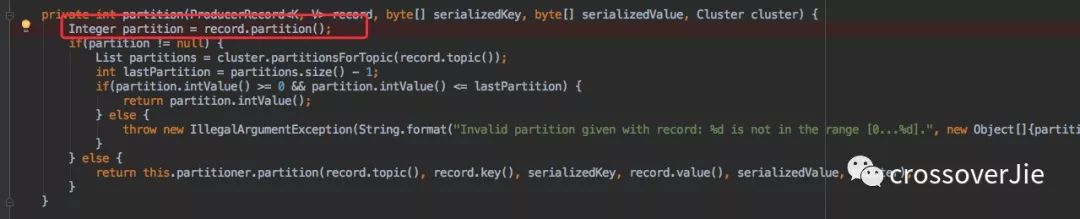
這種一般在特殊場景下會使用。
自定義路由策略
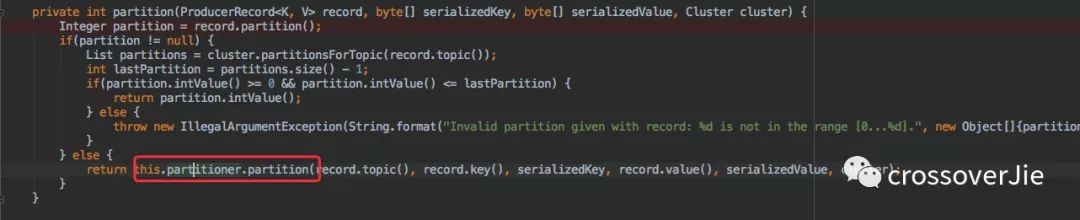
如果沒有指定分區(qū),則會調用 partitioner.partition 接口執(zhí)行自定義分區(qū)策略。
而我們也只需要自定義一個類實現 org.apache.kafka.clients.producer.Partitioner 接口,同時在創(chuàng)建 KafkaProducer 實例時配置 partitioner.class 參數。

通常需要自定義分區(qū)一般是在想盡量的保證消息的順序性。
或者是寫入某些特有的分區(qū),由特別的消費者來進行處理等。
默認策略
最后一種則是默認的路由策略,如果我們啥都沒做就會執(zhí)行該策略。
該策略也會使得消息分配的比較均勻。
來看看它的實現:
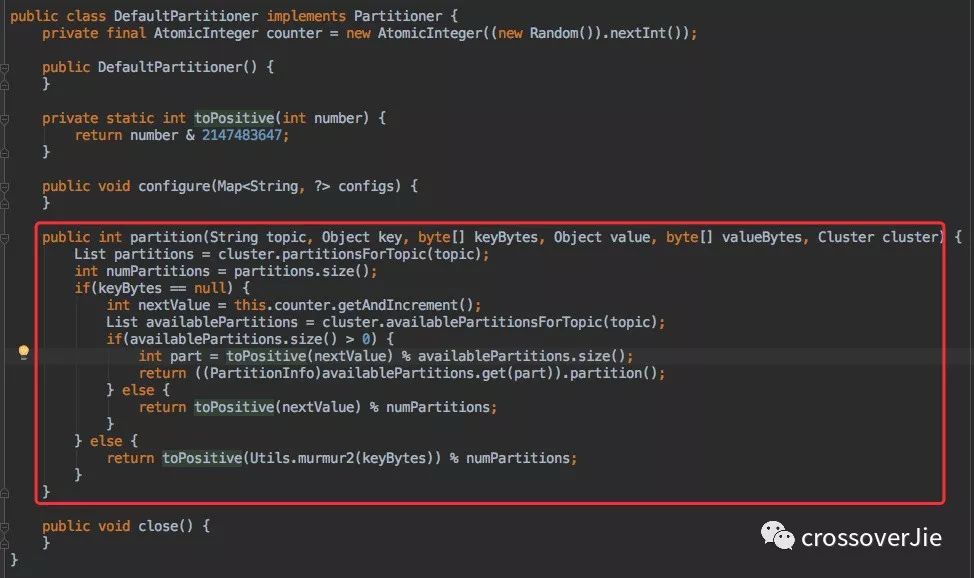
簡單的來說分為以下幾步:
獲取 Topic 分區(qū)數。
將內部維護的一個線程安全計數器 +1。
與分區(qū)數取模得到分區(qū)編號。
其實這就是很典型的輪詢算法,所以只要分區(qū)數不頻繁變動這種方式也會比較均勻。
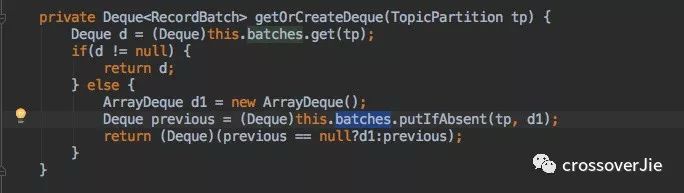
寫入內部緩存
在 send() 方法拿到分區(qū)后會調用一個 append() 函數:

該函數中會調用一個 getOrCreateDeque() 寫入到一個內部緩存中 batches。
消費緩存
在最開始初始化的 IO 線程其實是一個守護線程,它會一直消費這些數據。
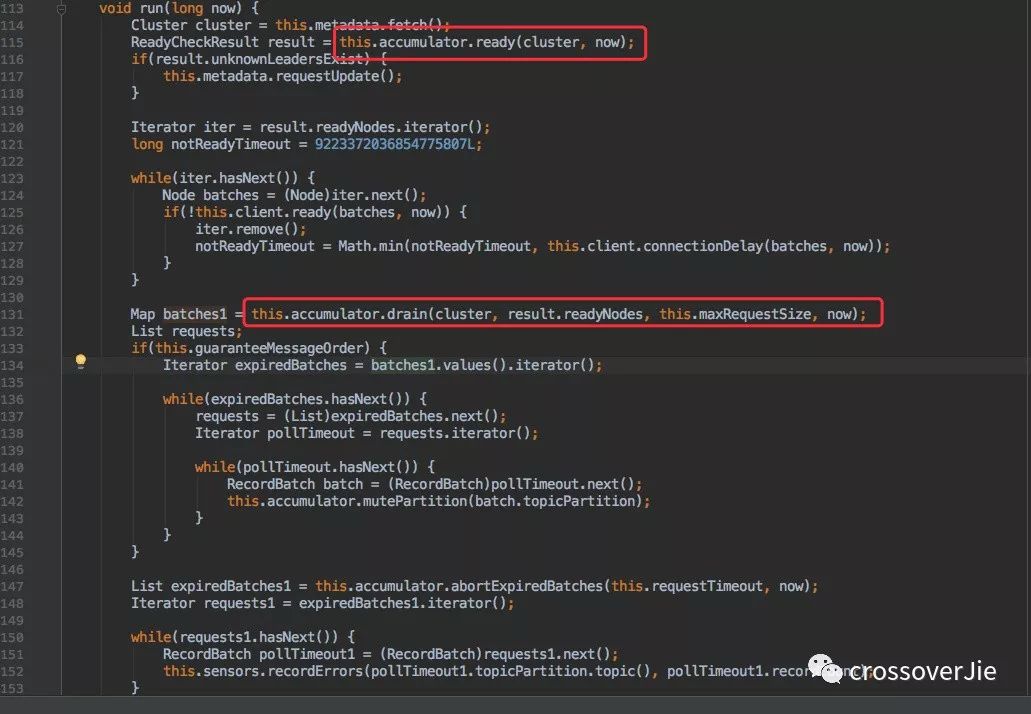
通過圖中的幾個函數會獲取到之前寫入的數據。這塊內容可以不必深究,但其中有個 completeBatch 方法卻非常關鍵。
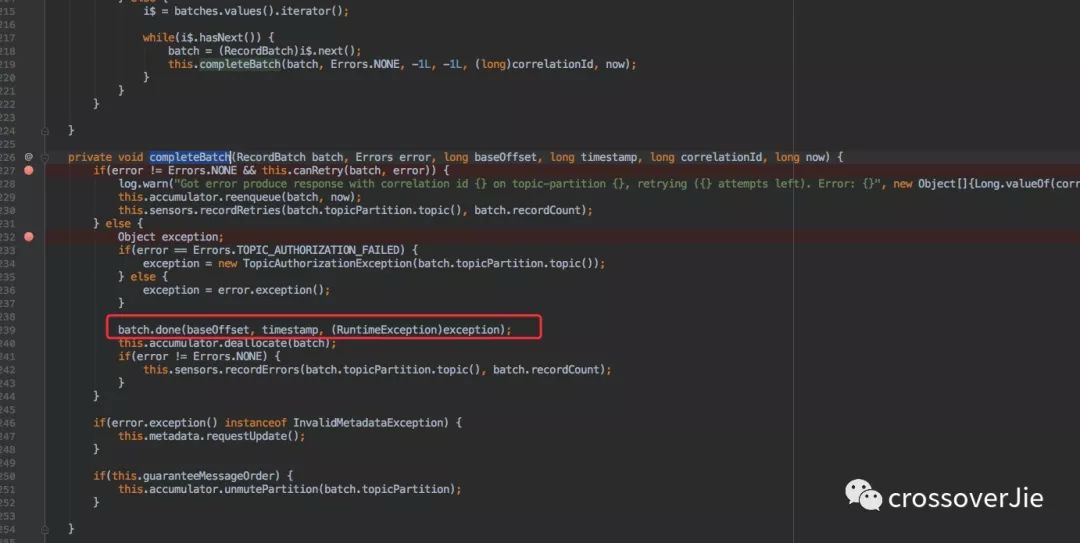
調用該方法時候肯定已經是消息發(fā)送完畢了,所以會調用 batch.done() 來完成之前我們在 send() 方法中定義的回調接口。
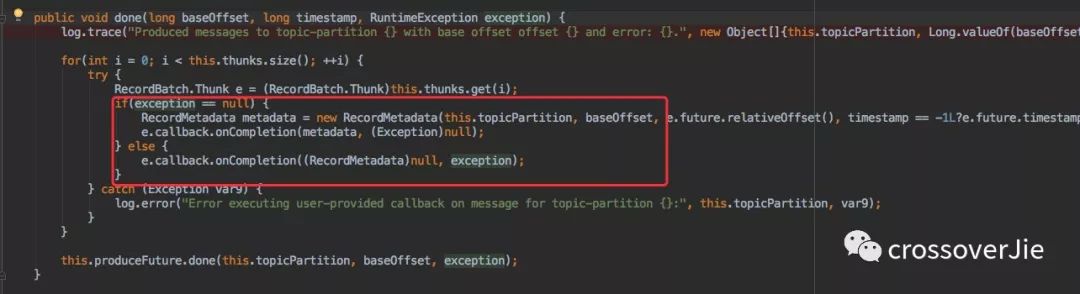
Producer 參數解析從這里也可以看出為什么之前說發(fā)送完成后元數據和異常信息只會出現一個。
發(fā)送流程講完了再來看看 Producer 中比較重要的幾個參數。
acks
acks 是一個影響消息吞吐量的一個關鍵參數。

主要有 [all、-1,0,1] 這幾個選項,默認為 1。
由于 Kafka 不是采取的主備模式,而是采用類似于 Zookeeper 的主備模式。
前提是
Topic配置副本數量replica>1。
當 acks=all/-1 時:
意味著會確保所有的 follower 副本都完成數據的寫入才會返回。
這樣可以保證消息不會丟失!
但同時性能和吞吐量卻是最低的。
當 acks=0 時:
producer 不會等待副本的任何響應,這樣最容易丟失消息但同時性能卻是最好的!
當 acks=1 時:
這是一種折中的方案,它會等待副本 Leader 響應,但不會等到 follower 的響應。
一旦 Leader 掛掉消息就會丟失。但性能和消息安全性都得到了一定的保證。
batch.size
這個參數看名稱就知道是內部緩存區(qū)的大小限制,對他適當的調大可以提高吞吐量。
但也不能極端,調太大會浪費內存。小了也發(fā)揮不了作用,也是一個典型的時間和空間的權衡。
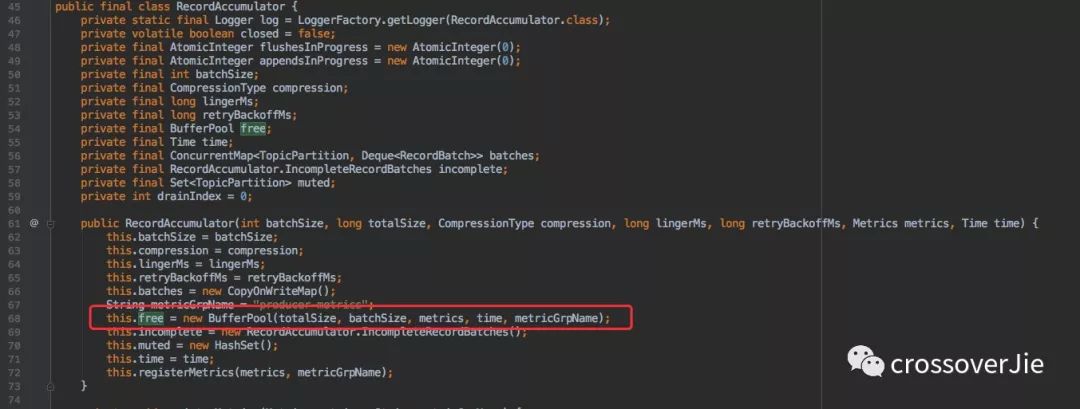
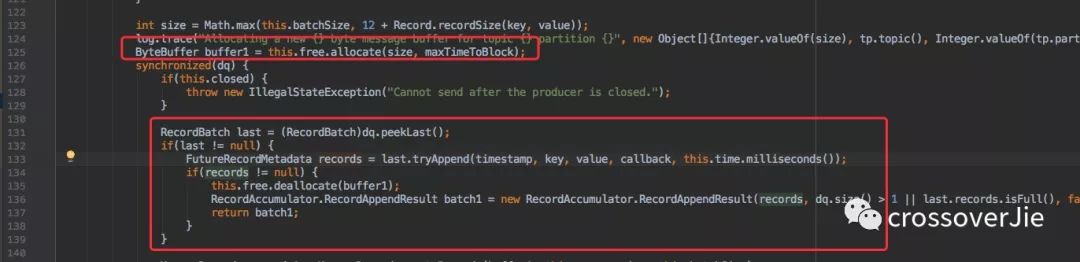
上圖是幾個使用的體現。
retries
retries 該參數主要是來做重試使用,當發(fā)生一些網絡抖動都會造成重試。
這個參數也就是限制重試次數。
但也有一些其他問題。
因為是重發(fā)所以消息順序可能不會一致,這也是上文提到就算是一個分區(qū)消息也不會是完全順序的情況。
還是由于網絡問題,本來消息已經成功寫入了但是沒有成功響應給 producer,進行重試時就可能會出現?
消息重復。這種只能是消費者進行冪等處理。
如果消息量真的非常大,同時又需要盡快的將消息發(fā)送到 Kafka。一個 producer 始終會收到緩存大小等影響。
那是否可以創(chuàng)建多個 producer 來進行發(fā)送呢?
配置一個最大 producer 個數。
發(fā)送消息時首先獲取一個?
producer,獲取的同時判斷是否達到最大上限,沒有就新建一個同時保存到內部的?List中,保存時做好同步處理防止并發(fā)問題。獲取發(fā)送者時可以按照默認的分區(qū)策略使用輪詢的方式獲取(保證使用均勻)。
這樣在大量、頻繁的消息發(fā)送場景中可以提高發(fā)送效率減輕單個 producer 的壓力。
最后則是 Producer 的關閉,Producer 在使用過程中消耗了不少資源(線程、內存、網絡等)因此需要顯式的關閉從而回收這些資源。
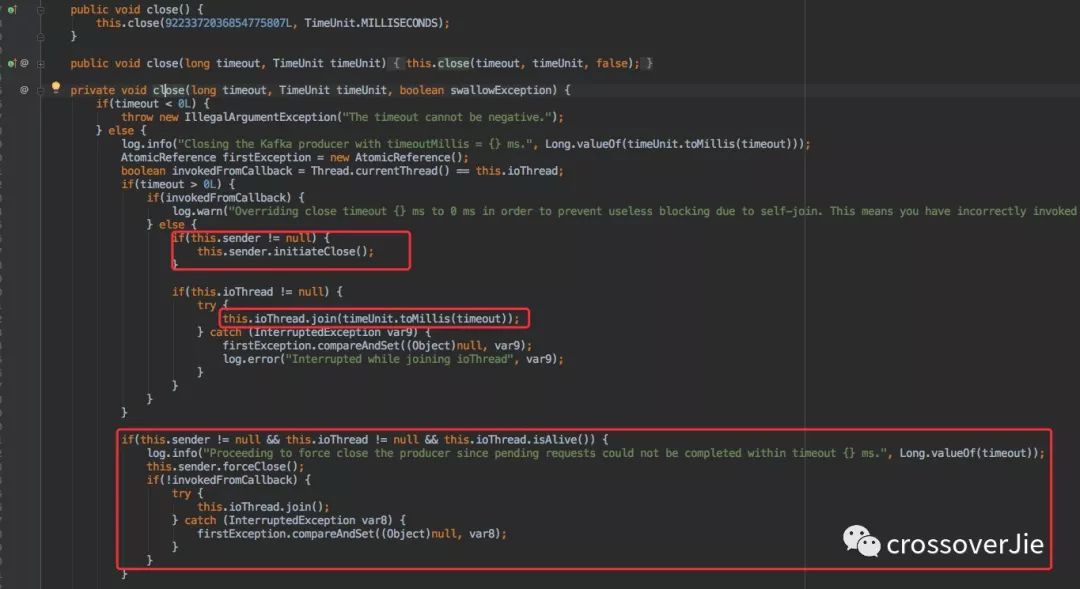
默認的 close() 方法和帶有超時時間的方法都是在一定的時間后強制關閉。
但在過期之前都會處理完剩余的任務。
所以使用哪一個得視情況而定。
總結本文內容較多,從實例和源碼的角度分析了 Kafka 生產者。
希望看完的朋友能有收獲,同時也歡迎留言討論。
不出意外下期會討論 Kafka 消費者。
如果對你有幫助還請分享讓更多的人看到。
如果大家想要實時關注我更新的文章以及分享的干貨的話,可以關注我的公眾號Java3y。
?獲取海量視頻資源

獲取Java精美腦圖
?獲取Java學習路線
獲取開發(fā)常用工具
?精美整理好的PDF電子書
在公眾號下回復「888」即可獲取!!
點個在看 ,分享到朋友圈
,分享到朋友圈 ,對我真的很重要!!
,對我真的很重要!!