
Yolov3&Yolov4核心基礎(chǔ)知識(shí)完整講解
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

1. 論文匯總
2. Yolov3核心基礎(chǔ)內(nèi)容
2.1 網(wǎng)絡(luò)結(jié)構(gòu)可視化
2.2 網(wǎng)絡(luò)結(jié)構(gòu)圖
2.3 核心基礎(chǔ)內(nèi)容
3. Yolov3相關(guān)代碼
3.1 python代碼
3.2 C++代碼內(nèi)容
3.3 python版本的Tensorrt代碼
3.4 C++版本的Tensorrt代碼
4. Yolov4核心基礎(chǔ)內(nèi)容
4.1 網(wǎng)絡(luò)結(jié)構(gòu)可視化
4.2 網(wǎng)絡(luò)結(jié)構(gòu)圖
4.3 核心基礎(chǔ)內(nèi)容
4.3.1 輸入端創(chuàng)新
4.3.2 Backbone創(chuàng)新
4.3.3 Neck創(chuàng)新
4.4.4 Prediction創(chuàng)新
5. Yolov4相關(guān)代碼
5.1 python代碼
5.2 C++代碼
1.論文匯總
Yolov3論文名:《Yolov3: An Incremental Improvement》
Yolov3論文地址:https://arxiv.org/pdf/1804.02767.pdf
Yolov4論文名:《Yolov4: Optimal Speed and Accuracy of Object Detection》
Yolov4論文地址:https://arxiv.org/pdf/2004.10934.pdf
2.YoloV3核心基礎(chǔ)內(nèi)容
2.1 網(wǎng)絡(luò)結(jié)構(gòu)可視化
Yolov3是目標(biāo)檢測(cè)Yolo系列非常非常經(jīng)典的算法,不過(guò)很多同學(xué)拿到Yolov3或者Yolov4的cfg文件時(shí),并不知道如何直觀的可視化查看網(wǎng)絡(luò)結(jié)構(gòu)。如果純粹看cfg里面的內(nèi)容,肯定會(huì)一臉懵逼。
其實(shí)可以很方便的用netron查看Yolov3的網(wǎng)絡(luò)結(jié)構(gòu)圖,一目了然。
2.2 網(wǎng)絡(luò)結(jié)構(gòu)圖
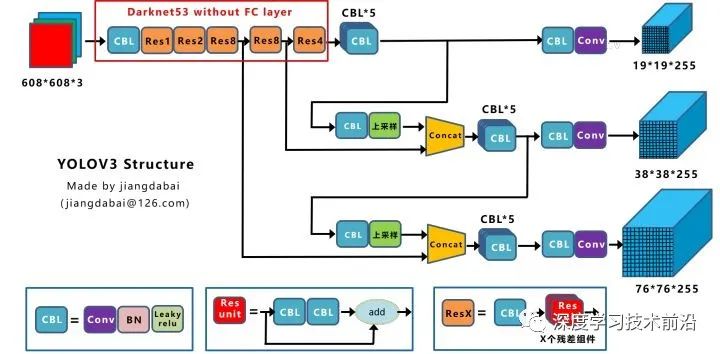
上圖三個(gè)藍(lán)色方框內(nèi)表示Yolov3的三個(gè)基本組件:
CBL:Yolov3網(wǎng)絡(luò)結(jié)構(gòu)中的最小組件,由Conv+Bn+Leaky_relu激活函數(shù)三者組成。
Res unit:借鑒Resnet網(wǎng)絡(luò)中的殘差結(jié)構(gòu),讓網(wǎng)絡(luò)可以構(gòu)建的更深。
ResX:由一個(gè)CBL和X個(gè)殘差組件構(gòu)成,是Yolov3中的大組件。每個(gè)Res模塊前面的CBL都起到下采樣的作用,因此經(jīng)過(guò)5次Res模塊后,得到的特征圖是608->304->152->76->38->19大小。
其他基礎(chǔ)操作:
Concat:張量拼接,會(huì)擴(kuò)充兩個(gè)張量的維度,例如26*26*256和26*26*512兩個(gè)張量拼接,結(jié)果是26*26*768。Concat和cfg文件中的route功能一樣。
add:張量相加,張量直接相加,不會(huì)擴(kuò)充維度,例如104*104*128和104*104*128相加,結(jié)果還是104*104*128。add和cfg文件中的shortcut功能一樣。
Backbone中卷積層的數(shù)量:
每個(gè)ResX中包含1+2*X個(gè)卷積層,因此整個(gè)主干網(wǎng)絡(luò)Backbone中一共包含1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)=52,再加上一個(gè)FC全連接層,即可以組成一個(gè)Darknet53分類網(wǎng)絡(luò)。不過(guò)在目標(biāo)檢測(cè)Yolov3中,去掉FC層,不過(guò)為了方便稱呼,仍然把Yolov3的主干網(wǎng)絡(luò)叫做Darknet53結(jié)構(gòu)。
2.3 核心基礎(chǔ)內(nèi)容
Yolov3是2018年發(fā)明提出的,這成為了目標(biāo)檢測(cè)one-stage中非常經(jīng)典的算法,包含Darknet-53網(wǎng)絡(luò)結(jié)構(gòu)、anchor錨框、FPN等非常優(yōu)秀的結(jié)構(gòu)。
本文主要目的在于描述Yolov4和Yolov3算法的不同及創(chuàng)新之處,對(duì)Yolov3的基礎(chǔ)不過(guò)多描述。
不過(guò)大白也正在準(zhǔn)備Yolov3算法非常淺顯易懂的基礎(chǔ)視頻課程,讓小白也能簡(jiǎn)單清楚的了解Yolov3的整個(gè)過(guò)程及各個(gè)算法細(xì)節(jié),制作好后會(huì)更新到此處,便于大家查看。
在準(zhǔn)備課程過(guò)程中,大白搜集查看了網(wǎng)絡(luò)上幾乎所有的Yolov3資料,在此整理幾個(gè)非常不錯(cuò)的文章及視頻,大家也可以點(diǎn)擊查看,學(xué)習(xí)相關(guān)知識(shí)。
(1)視頻:吳恩達(dá)目標(biāo)檢測(cè)Yolo入門講解
https://www.bilibili.com/video/BV1N4411J7Y6?from=search&seid=18074481568368507115
(2)文章:Yolo系列之Yolov3【深度解析】
https://blog.csdn.net/leviopku/article/details/82660381
(3)文章:一文看懂Yolov3
https://blog.csdn.net/litt1e/article/details/88907542
相信大家看完,對(duì)于Yolov3的基礎(chǔ)知識(shí)點(diǎn)會(huì)有一定的了解。
3.YoloV3相關(guān)代碼
3.1 python代碼
代碼地址:https://github.com/ultralytics/Yolov3
3.2 C++代碼
這里推薦Yolov4作者的darknetAB代碼,代碼和原始作者代碼相比,進(jìn)行了很多的優(yōu)化,如需要運(yùn)行Yolov3網(wǎng)絡(luò),加載cfg時(shí),使用Yolov3.cfg即可
代碼地址:https://github.com/AlexeyAB/darknet
3.3 python版本的Tensorrt代碼
除了算法研究外,實(shí)際項(xiàng)目中還需要將算法落地部署到工程上使用,比如GPU服務(wù)器使用時(shí)還需要對(duì)模型進(jìn)行tensorrt加速。
(1)Tensort中的加速案例
強(qiáng)烈推薦tensort軟件中,自帶的Yolov3加速案例,路徑位于tensorrt解壓文件夾的TensortX/samples/python/Yolov3_onnx中
針對(duì)案例中的代碼,如果有不明白的,也可參照下方文章上的詳細(xì)說(shuō)明:
代碼地址:https://www.cnblogs.com/shouhuxianjian/p/10550262.html
(2)Github上的tensorrt加速
除了tensorrt軟件中的代碼, github上也有其他作者的開(kāi)源代碼
代碼地址:https://github.com/lewes6369/TensorRT-Yolov3
3.4 C++版本的Tensorrt代碼
項(xiàng)目的工程部署上,如果使用C++版本進(jìn)行Tensorrt加速,一方面可以參照Alexey的github代碼,另一方面也可以參照下面其他作者的開(kāi)源代碼
代碼地址:https://github.com/wang-xinyu/tensorrtx/tree/master/Yolov3
4.YoloV4核心基礎(chǔ)內(nèi)容
4.1 網(wǎng)絡(luò)結(jié)構(gòu)可視化
Yolov4的網(wǎng)絡(luò)結(jié)構(gòu)也可以使用netron工具查看。
4.2 網(wǎng)絡(luò)結(jié)構(gòu)圖
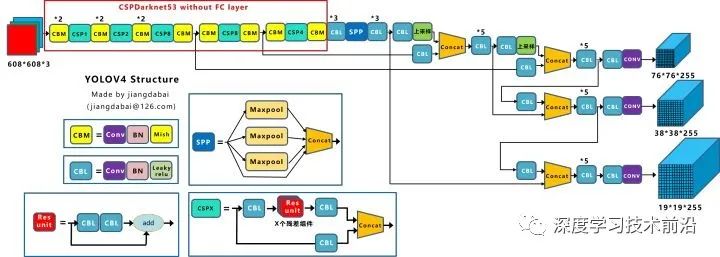
Yolov4的結(jié)構(gòu)圖和Yolov3相比,因?yàn)槎嗔?span style="font-weight: 600;color: rgb(122, 79, 214);">CSP結(jié)構(gòu),PAN結(jié)構(gòu),如果單純看可視化流程圖,會(huì)覺(jué)得很繞,不過(guò)在繪制出上面的圖形后,會(huì)覺(jué)得豁然開(kāi)朗,其實(shí)整體架構(gòu)和Yolov3是相同的,不過(guò)使用各種新的算法思想對(duì)各個(gè)子結(jié)構(gòu)都進(jìn)行了改進(jìn)。
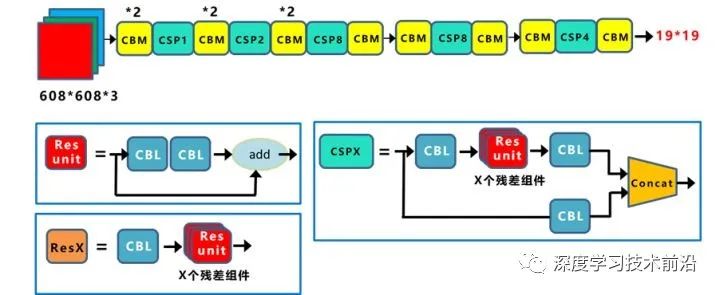
先整理下Yolov4的五個(gè)基本組件:
CBM:Yolov4網(wǎng)絡(luò)結(jié)構(gòu)中的最小組件,由Conv+Bn+Mish激活函數(shù)三者組成。
CBL:由Conv+Bn+Leaky_relu激活函數(shù)三者組成。
Res unit:借鑒Resnet網(wǎng)絡(luò)中的殘差結(jié)構(gòu),讓網(wǎng)絡(luò)可以構(gòu)建的更深。
CSPX:借鑒CSPNet網(wǎng)絡(luò)結(jié)構(gòu),由三個(gè)卷積層和X個(gè)Res unint模塊Concate組成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,進(jìn)行多尺度融合。
其他基礎(chǔ)操作:
Concat:張量拼接,維度會(huì)擴(kuò)充,和Yolov3中的解釋一樣,對(duì)應(yīng)于cfg文件中的route操作。
add:張量相加,不會(huì)擴(kuò)充維度,對(duì)應(yīng)于cfg文件中的shortcut操作。
Backbone中卷積層的數(shù)量:
和Yolov3一樣,再來(lái)數(shù)一下Backbone里面的卷積層數(shù)量。
每個(gè)CSPX中包含3+2*X個(gè)卷積層,因此整個(gè)主干網(wǎng)絡(luò)Backbone中一共包含2+(3+2*1)+2+(3+2*2)+2+(3+2*8)+2+(3+2*8)+2+(3+2*4)+1=72。
這里大白有些疑惑,按照Yolov3設(shè)計(jì)的傳統(tǒng),這么多卷積層,主干網(wǎng)絡(luò)不應(yīng)該叫CSPDaeknet73嗎????
4.3 核心基礎(chǔ)內(nèi)容
Yolov4本質(zhì)上和Yolov3相差不大,可能有些人會(huì)覺(jué)得失望。
但我覺(jué)得算法創(chuàng)新分為三種方式:
第一種:面目一新的創(chuàng)新,比如Yolov1、Faster-RCNN、Centernet等,開(kāi)創(chuàng)出新的算法領(lǐng)域,不過(guò)這種也是最難的
第二種:守正出奇的創(chuàng)新,比如將圖像金字塔改進(jìn)為特征金字塔
第三種:各種先進(jìn)算法集成的創(chuàng)新,比如不同領(lǐng)域發(fā)表的最新論文的tricks,集成到自己的算法中,卻發(fā)現(xiàn)有出乎意料的改進(jìn)
Yolov4既有第二種也有第三種創(chuàng)新,組合嘗試了大量深度學(xué)習(xí)領(lǐng)域最新論文的20多項(xiàng)研究成果,而且不得不佩服的是作者Alexey在github代碼庫(kù)維護(hù)的頻繁程度。
目前Yolov4代碼的star數(shù)量已經(jīng)1萬(wàn)多,據(jù)我所了解,目前超過(guò)這個(gè)數(shù)量的,目標(biāo)檢測(cè)領(lǐng)域只有Facebook的Detectron(v1-v2)、和Yolo(v1-v3)官方代碼庫(kù)(已停止更新)。
所以Yolov4中的各種創(chuàng)新方式,大白覺(jué)得還是很值得仔細(xì)研究的。
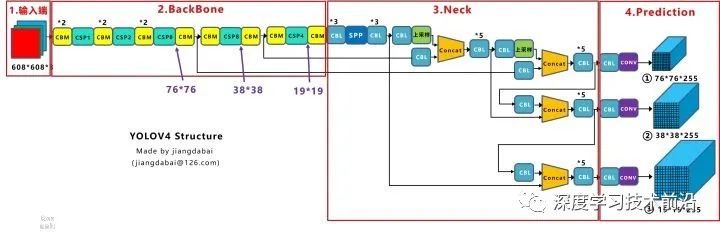
為了便于分析,將Yolov4的整體結(jié)構(gòu)拆分成四大板塊:
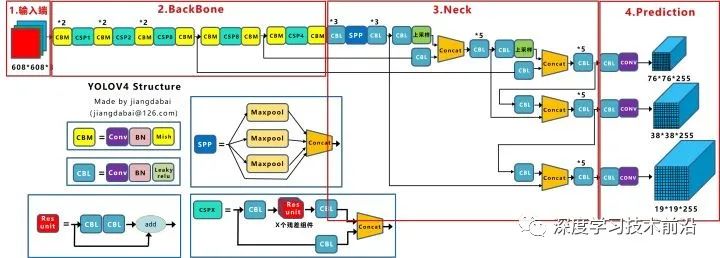
大白主要從以上4個(gè)部分對(duì)YoloV4的創(chuàng)新之處進(jìn)行講解,讓大家一目了然。
輸入端:這里指的創(chuàng)新主要是訓(xùn)練時(shí)對(duì)輸入端的改進(jìn),主要包括Mosaic數(shù)據(jù)增強(qiáng)、cmBN、SAT自對(duì)抗訓(xùn)練
BackBone主干網(wǎng)絡(luò):將各種新的方式結(jié)合起來(lái),包括:CSPDarknet53、Mish激活函數(shù)、Dropblock
Neck:目標(biāo)檢測(cè)網(wǎng)絡(luò)在BackBone和最后的輸出層之間往往會(huì)插入一些層,比如Yolov4中的SPP模塊、FPN+PAN結(jié)構(gòu)
Prediction:輸出層的錨框機(jī)制和Yolov3相同,主要改進(jìn)的是訓(xùn)練時(shí)的損失函數(shù)CIOU_Loss,以及預(yù)測(cè)框篩選的nms變?yōu)?span style="font-weight: 600;color: rgb(122, 79, 214);">DIOU_nms
總體來(lái)說(shuō),Yolov4對(duì)Yolov3的各個(gè)部分都進(jìn)行了改進(jìn)優(yōu)化,下面丟上作者的算法對(duì)比圖。
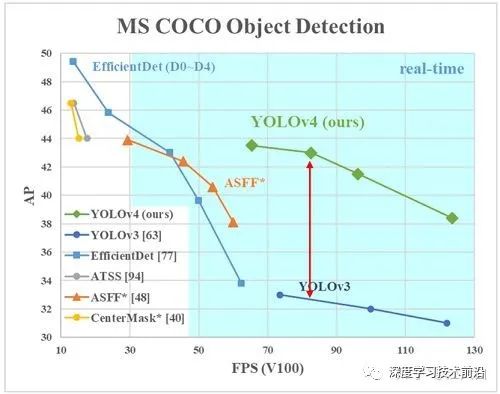
僅對(duì)比Yolov3和Yolov4,在COCO數(shù)據(jù)集上,同樣的FPS等于83左右時(shí),Yolov4的AP是43,而Yolov3是33,直接上漲了10個(gè)百分點(diǎn)。
不得不服,當(dāng)然可能針對(duì)具體不同的數(shù)據(jù)集效果也不一樣,但總體來(lái)說(shuō),改進(jìn)效果是很優(yōu)秀的,下面大白對(duì)Yolov4的各個(gè)創(chuàng)新點(diǎn)繼續(xù)進(jìn)行深挖。
4.3.1 輸入端創(chuàng)新
考慮到很多同學(xué)GPU顯卡數(shù)量并不是很多,Yolov4對(duì)訓(xùn)練時(shí)的輸入端進(jìn)行改進(jìn),使得訓(xùn)練在單張GPU上也能有不錯(cuò)的成績(jī)。比如數(shù)據(jù)增強(qiáng)Mosaic、cmBN、SAT自對(duì)抗訓(xùn)練。
但感覺(jué)cmBN和SAT影響并不是很大,所以這里主要講解Mosaic數(shù)據(jù)增強(qiáng)。
(1)Mosaic數(shù)據(jù)增強(qiáng)
Yolov4中使用的Mosaic是參考2019年底提出的CutMix數(shù)據(jù)增強(qiáng)的方式,但CutMix只使用了兩張圖片進(jìn)行拼接,而Mosaic數(shù)據(jù)增強(qiáng)則采用了4張圖片,隨機(jī)縮放、隨機(jī)裁剪、隨機(jī)排布的方式進(jìn)行拼接。
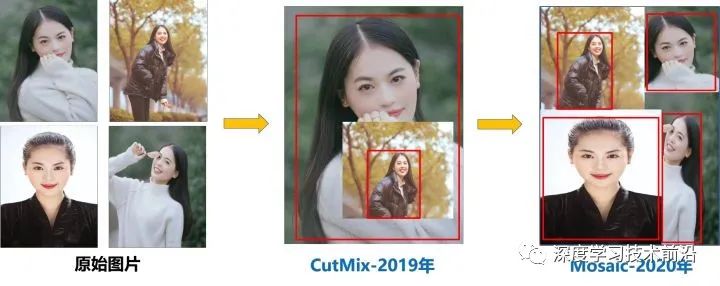
這里首先要了解為什么要進(jìn)行Mosaic數(shù)據(jù)增強(qiáng)呢?
在平時(shí)項(xiàng)目訓(xùn)練時(shí),小目標(biāo)的AP一般比中目標(biāo)和大目標(biāo)低很多。而Coco數(shù)據(jù)集中也包含大量的小目標(biāo),但比較麻煩的是小目標(biāo)的分布并不均勻。
首先看下小、中、大目標(biāo)的定義:
2019年發(fā)布的論文《Augmentation for small object detection》對(duì)此進(jìn)行了區(qū)分:

可以看到小目標(biāo)的定義是目標(biāo)框的長(zhǎng)寬0×0~32×32之間的物體。

但在整體的數(shù)據(jù)集中,小、中、大目標(biāo)的占比并不均衡。
如上表所示,Coco數(shù)據(jù)集中小目標(biāo)占比達(dá)到41.4%,數(shù)量比中目標(biāo)和大目標(biāo)都要多。
但在所有的訓(xùn)練集圖片中,只有52.3%的圖片有小目標(biāo),而中目標(biāo)和大目標(biāo)的分布相對(duì)來(lái)說(shuō)更加均勻一些。
針對(duì)這種狀況,Yolov4的作者采用了Mosaic數(shù)據(jù)增強(qiáng)的方式。
主要有幾個(gè)優(yōu)點(diǎn):
豐富數(shù)據(jù)集:隨機(jī)使用4張圖片,隨機(jī)縮放,再隨機(jī)分布進(jìn)行拼接,大大豐富了檢測(cè)數(shù)據(jù)集,特別是隨機(jī)縮放增加了很多小目標(biāo),讓網(wǎng)絡(luò)的魯棒性更好。
減少GPU:可能會(huì)有人說(shuō),隨機(jī)縮放,普通的數(shù)據(jù)增強(qiáng)也可以做,但作者考慮到很多人可能只有一個(gè)GPU,因此Mosaic增強(qiáng)訓(xùn)練時(shí),可以直接計(jì)算4張圖片的數(shù)據(jù),使得Mini-batch大小并不需要很大,一個(gè)GPU就可以達(dá)到比較好的效果。
此外,發(fā)現(xiàn)另一研究者的訓(xùn)練方式也值得借鑒,采用的數(shù)據(jù)增強(qiáng)和Mosaic比較類似,也是使用4張圖片(不是隨機(jī)分布),但訓(xùn)練計(jì)算loss時(shí),采用“缺啥補(bǔ)啥”的思路:
如果上一個(gè)iteration中,小物體產(chǎn)生的loss不足(比如小于某一個(gè)閾值),則下一個(gè)iteration就用拼接圖;否則就用正常圖片訓(xùn)練,也很有意思。
參考鏈接:https://www.zhihu.com/question/390191723?rf=390194081
4.3.2 BackBone創(chuàng)新
(1)CSPDarknet53
CSPDarknet53是在Yolov3主干網(wǎng)絡(luò)Darknet53的基礎(chǔ)上,借鑒2019年CSPNet的經(jīng)驗(yàn),產(chǎn)生的Backbone結(jié)構(gòu),其中包含了5個(gè)CSP模塊。
這里因?yàn)?span style="font-weight: 600;">CSP模塊比較長(zhǎng),不放到本處,大家也可以點(diǎn)擊Yolov4的netron網(wǎng)絡(luò)結(jié)構(gòu)圖,對(duì)比查看,一目了然。
每個(gè)CSP模塊前面的卷積核的大小都是3*3,stride=2,因此可以起到下采樣的作用。
因?yàn)锽ackbone有5個(gè)CSP模塊,輸入圖像是608*608,所以特征圖變化的規(guī)律是:608->304->152->76->38->19
經(jīng)過(guò)5次CSP模塊后得到19*19大小的特征圖。
而且作者只在Backbone中采用了Mish激活函數(shù),網(wǎng)絡(luò)后面仍然采用Leaky_relu激活函數(shù)。
我們?cè)倏纯聪伦髡邽樯兑獏⒖?019年的CSPNet,采用CSP模塊?
CSPNet論文地址:https://arxiv.org/pdf/1911.11929.pdf
CSPNet全稱是Cross Stage Paritial Network,主要從網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)的角度解決推理中從計(jì)算量很大的問(wèn)題。
CSPNet的作者認(rèn)為推理計(jì)算過(guò)高的問(wèn)題是由于網(wǎng)絡(luò)優(yōu)化中的梯度信息重復(fù)導(dǎo)致的。
因此采用CSP模塊先將基礎(chǔ)層的特征映射劃分為兩部分,然后通過(guò)跨階段層次結(jié)構(gòu)將它們合并,在減少了計(jì)算量的同時(shí)可以保證準(zhǔn)確率。
因此Yolov4在主干網(wǎng)絡(luò)Backbone采用CSPDarknet53網(wǎng)絡(luò)結(jié)構(gòu),主要有三個(gè)方面的優(yōu)點(diǎn):
優(yōu)點(diǎn)一:增強(qiáng)CNN的學(xué)習(xí)能力,使得在輕量化的同時(shí)保持準(zhǔn)確性。
優(yōu)點(diǎn)二:降低計(jì)算瓶頸
優(yōu)點(diǎn)三:降低內(nèi)存成本
(2)Mish激活函數(shù)
Mish激活函數(shù)是2019年下半年提出的激活函數(shù)
論文地址:https://arxiv.org/abs/1908.08681
和Leaky_relu激活函數(shù)的圖形對(duì)比如下:
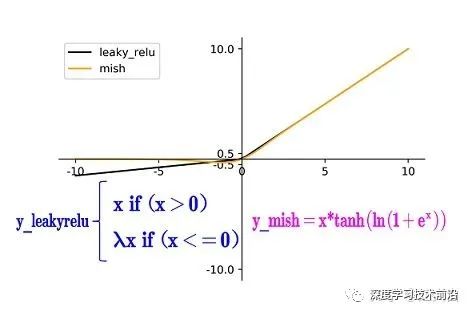
Yolov4的Backbone中都使用了Mish激活函數(shù),而后面的網(wǎng)絡(luò)則還是使用leaky_relu函數(shù)。

Yolov4作者實(shí)驗(yàn)測(cè)試時(shí),使用CSPDarknet53網(wǎng)絡(luò)在ImageNet數(shù)據(jù)集上做圖像分類任務(wù),發(fā)現(xiàn)使用了Mish激活函數(shù)的TOP-1和TOP-5的精度比沒(méi)有使用時(shí)都略高一些。
因此在設(shè)計(jì)Yolov4目標(biāo)檢測(cè)任務(wù)時(shí),主干網(wǎng)絡(luò)Backbone還是使用Mish激活函數(shù)。
(3)Dropblock
Yolov4中使用的Dropblock,其實(shí)和常見(jiàn)網(wǎng)絡(luò)中的Dropout功能類似,也是緩解過(guò)擬合的一種正則化方式。
Dropblock在2018年提出,論文地址:https://arxiv.org/pdf/1810.12890.pdf
傳統(tǒng)的Dropout很簡(jiǎn)單,一句話就可以說(shuō)的清:隨機(jī)刪除減少神經(jīng)元的數(shù)量,使網(wǎng)絡(luò)變得更簡(jiǎn)單。
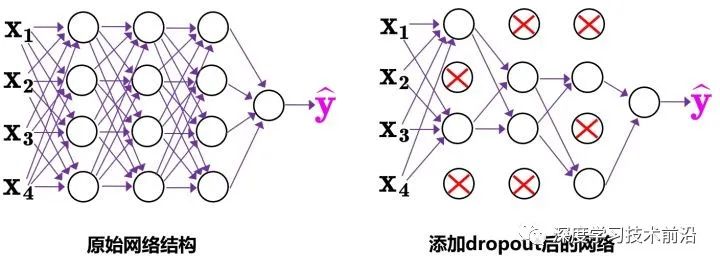
而Dropblock和Dropout相似,比如下圖:

中間Dropout的方式會(huì)隨機(jī)的刪減丟棄一些信息,但Dropblock的研究者認(rèn)為,卷積層對(duì)于這種隨機(jī)丟棄并不敏感,因?yàn)榫矸e層通常是三層連用:卷積+激活+池化層,池化層本身就是對(duì)相鄰單元起作用。而且即使隨機(jī)丟棄,卷積層仍然可以從相鄰的激活單元學(xué)習(xí)到相同的信息。
因此,在全連接層上效果很好的Dropout在卷積層上效果并不好。
所以右圖Dropblock的研究者則干脆整個(gè)局部區(qū)域進(jìn)行刪減丟棄。
這種方式其實(shí)是借鑒2017年的cutout數(shù)據(jù)增強(qiáng)的方式,cutout是將輸入圖像的部分區(qū)域清零,而Dropblock則是將Cutout應(yīng)用到每一個(gè)特征圖。而且并不是用固定的歸零比率,而是在訓(xùn)練時(shí)以一個(gè)小的比率開(kāi)始,隨著訓(xùn)練過(guò)程線性的增加這個(gè)比率。

Dropblock的研究者與Cutout進(jìn)行對(duì)比驗(yàn)證時(shí),發(fā)現(xiàn)有幾個(gè)特點(diǎn):
優(yōu)點(diǎn)一:Dropblock的效果優(yōu)于Cutout
優(yōu)點(diǎn)二:Cutout只能作用于輸入層,而Dropblock則是將Cutout應(yīng)用到網(wǎng)絡(luò)中的每一個(gè)特征圖上
優(yōu)點(diǎn)三:Dropblock可以定制各種組合,在訓(xùn)練的不同階段可以修改刪減的概率,從空間層面和時(shí)間層面,和Cutout相比都有更精細(xì)的改進(jìn)。
Yolov4中直接采用了更優(yōu)的Dropblock,對(duì)網(wǎng)絡(luò)的正則化過(guò)程進(jìn)行了全面的升級(jí)改進(jìn)。
4.3.3 Neck創(chuàng)新
在目標(biāo)檢測(cè)領(lǐng)域,為了更好的提取融合特征,通常在Backbone和輸出層,會(huì)插入一些層,這個(gè)部分稱為Neck。相當(dāng)于目標(biāo)檢測(cè)網(wǎng)絡(luò)的頸部,也是非常關(guān)鍵的。
Yolov4的Neck結(jié)構(gòu)主要采用了SPP模塊、FPN+PAN的方式。
(1)SPP模塊
SPP模塊,其實(shí)在Yolov3中已經(jīng)存在了,在Yolov4的C++代碼文件夾中有一個(gè)Yolov3_spp版本,但有的同學(xué)估計(jì)從來(lái)沒(méi)有使用過(guò),在Yolov4中,SPP模塊仍然是在Backbone主干網(wǎng)絡(luò)之后:
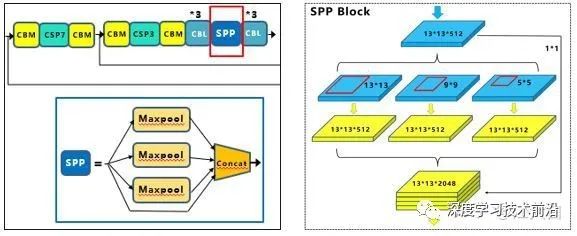
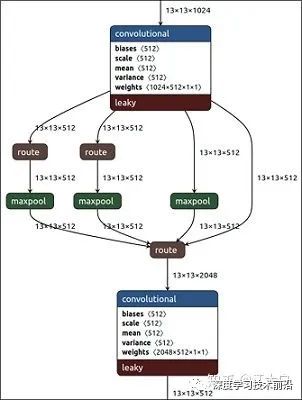
作者在SPP模塊中,使用k={1*1,5*5,9*9,13*13}的最大池化的方式,再將不同尺度的特征圖進(jìn)行Concat操作。
在2019提出的《DC-SPP-Yolo》文章:https://arxiv.org/ftp/arxiv/papers/1903/1903.08589.pdf
也對(duì)Yolo目標(biāo)檢測(cè)的SPP模塊進(jìn)行了對(duì)比測(cè)試。
和Yolov4作者的研究相同,采用SPP模塊的方式,比單純的使用k*k最大池化的方式,更有效的增加主干特征的接收范圍,顯著的分離了最重要的上下文特征。
Yolov4的作者在使用608*608大小的圖像進(jìn)行測(cè)試時(shí)發(fā)現(xiàn),在COCO目標(biāo)檢測(cè)任務(wù)中,以0.5%的額外計(jì)算代價(jià)將AP50增加了2.7%,因此Yolov4中也采用了SPP模塊。
(2)FPN+PAN
PAN結(jié)構(gòu)比較有意思,看了網(wǎng)上Yolov4關(guān)于這個(gè)部分的講解,大多都是講的比較籠統(tǒng)的,而PAN是借鑒圖像分割領(lǐng)域PANet的創(chuàng)新點(diǎn),有些同學(xué)可能不是很清楚。
下面大白將這個(gè)部分拆解開(kāi)來(lái),看下Yolov4中是如何設(shè)計(jì)的。
Yolov3結(jié)構(gòu):
我們先來(lái)看下Yolov3中Neck的FPN結(jié)構(gòu)

可以看到經(jīng)過(guò)幾次下采樣,三個(gè)紫色箭頭指向的地方,輸出分別是76*76、38*38、19*19。
以及最后的Prediction中用于預(yù)測(cè)的三個(gè)特征圖①19*19*255、②38*38*255、③76*76*255。[注:255表示80類別(1+4+80)×3=255]
我們將Neck部分用立體圖畫(huà)出來(lái),更直觀的看下兩部分之間是如何通過(guò)FPN結(jié)構(gòu)融合的。
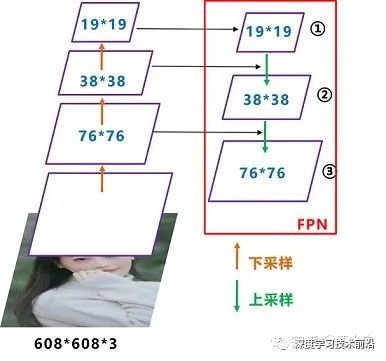
如圖所示,F(xiàn)PN是自頂向下的,將高層的特征信息通過(guò)上采樣的方式進(jìn)行傳遞融合,得到進(jìn)行預(yù)測(cè)的特征圖。
Yolov4結(jié)構(gòu):
而Yolov4中Neck這部分除了使用FPN外,還在此基礎(chǔ)上使用了PAN結(jié)構(gòu):
前面CSPDarknet53中講到,每個(gè)CSP模塊前面的卷積核都是3*3大小,相當(dāng)于下采樣操作。
因此可以看到三個(gè)紫色箭頭處的特征圖是76*76、38*38、19*19。
以及最后Prediction中用于預(yù)測(cè)的三個(gè)特征圖:①76*76*255,②38*38*255,③19*19*255。
我們也看下Neck部分的立體圖像,看下兩部分是如何通過(guò)FPN+PAN結(jié)構(gòu)進(jìn)行融合的。
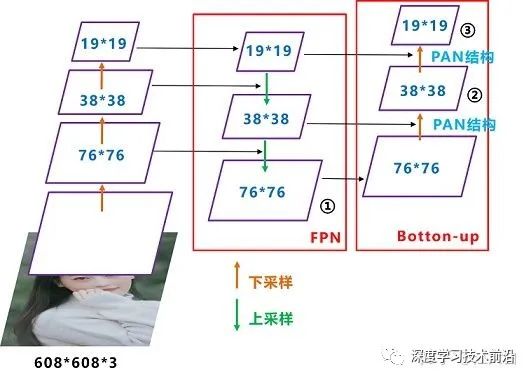
和Yolov3的FPN層不同,Yolov4在FPN層的后面還添加了一個(gè)自底向上的特征金字塔。
其中包含兩個(gè)PAN結(jié)構(gòu)。
這樣結(jié)合操作,FPN層自頂向下傳達(dá)強(qiáng)語(yǔ)義特征,而特征金字塔則自底向上傳達(dá)強(qiáng)定位特征,兩兩聯(lián)手,從不同的主干層對(duì)不同的檢測(cè)層進(jìn)行參數(shù)聚合,這樣的操作確實(shí)很皮。
FPN+PAN借鑒的是18年CVPR的PANet,當(dāng)時(shí)主要應(yīng)用于圖像分割領(lǐng)域,但Alexey將其拆分應(yīng)用到Y(jié)olov4中,進(jìn)一步提高特征提取的能力。
不過(guò)這里需要注意幾點(diǎn):
注意一:
Yolov3的FPN層輸出的三個(gè)大小不一的特征圖①②③直接進(jìn)行預(yù)測(cè)
但Yolov4的FPN層,只使用最后的一個(gè)76*76特征圖①,而經(jīng)過(guò)兩次PAN結(jié)構(gòu),輸出預(yù)測(cè)的特征圖②和③。
這里的不同也體現(xiàn)在cfg文件中,這一點(diǎn)有很多同學(xué)之前不太明白,
比如Yolov3.cfg最后的三個(gè)Yolo層,
第一個(gè)Yolo層是最小的特征圖19*19,mask=6,7,8,對(duì)應(yīng)最大的anchor box。
第二個(gè)Yolo層是中等的特征圖38*38,mask=3,4,5,對(duì)應(yīng)中等的anchor box。
第三個(gè)Yolo層是最大的特征圖76*76,mask=0,1,2,對(duì)應(yīng)最小的anchor box。
而Yolov4.cfg則恰恰相反
第一個(gè)Yolo層是最大的特征圖76*76,mask=0,1,2,對(duì)應(yīng)最小的anchor box。
第二個(gè)Yolo層是中等的特征圖38*38,mask=3,4,5,對(duì)應(yīng)中等的anchor box。
第三個(gè)Yolo層是最小的特征圖19*19,mask=6,7,8,對(duì)應(yīng)最大的anchor box。
注意點(diǎn)二:
原本的PANet網(wǎng)絡(luò)的PAN結(jié)構(gòu)中,兩個(gè)特征圖結(jié)合是采用shortcut操作,而Yolov4中則采用concat(route)操作,特征圖融合后的尺寸發(fā)生了變化。
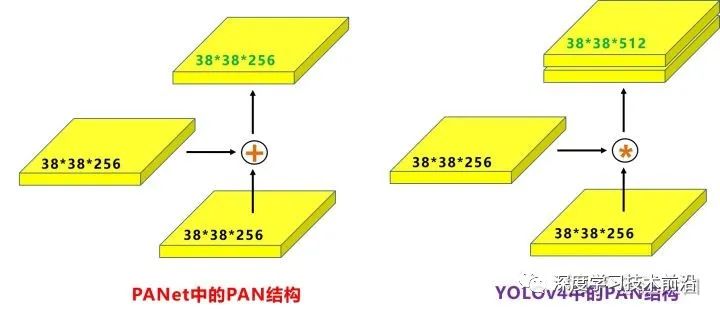
這里也可以對(duì)應(yīng)Yolov4的netron網(wǎng)絡(luò)圖查看,很有意思。
4.3.4 Prediction創(chuàng)新
(1)CIOU_loss
目標(biāo)檢測(cè)任務(wù)的損失函數(shù)一般由Classificition Loss(分類損失函數(shù))和Bounding Box Regeression Loss(回歸損失函數(shù))兩部分構(gòu)成。
Bounding Box Regeression的Loss近些年的發(fā)展過(guò)程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
我們從最常用的IOU_Loss開(kāi)始,進(jìn)行對(duì)比拆解分析,看下Yolov4為啥要選擇CIOU_Loss。
a.IOU_Loss
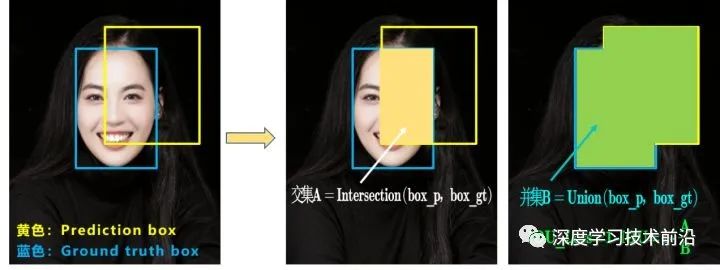
可以看到IOU的loss其實(shí)很簡(jiǎn)單,主要是交集/并集,但其實(shí)也存在兩個(gè)問(wèn)題。

問(wèn)題1:即狀態(tài)1的情況,當(dāng)預(yù)測(cè)框和目標(biāo)框不相交時(shí),IOU=0,無(wú)法反應(yīng)兩個(gè)框距離的遠(yuǎn)近,此時(shí)損失函數(shù)不可導(dǎo),IOU_Loss無(wú)法優(yōu)化兩個(gè)框不相交的情況。
問(wèn)題2:即狀態(tài)2和狀態(tài)3的情況,當(dāng)兩個(gè)預(yù)測(cè)框大小相同,兩個(gè)IOU也相同,IOU_Loss無(wú)法區(qū)分兩者相交情況的不同。
因此2019年出現(xiàn)了GIOU_Loss來(lái)進(jìn)行改進(jìn)。
b.GIOU_Loss

可以看到右圖GIOU_Loss中,增加了相交尺度的衡量方式,緩解了單純IOU_Loss時(shí)的尷尬。
但為什么僅僅說(shuō)緩解呢?
因?yàn)檫€存在一種不足:

問(wèn)題:狀態(tài)1、2、3都是預(yù)測(cè)框在目標(biāo)框內(nèi)部且預(yù)測(cè)框大小一致的情況,這時(shí)預(yù)測(cè)框和目標(biāo)框的差集都是相同的,因此這三種狀態(tài)的GIOU值也都是相同的,這時(shí)GIOU退化成了IOU,無(wú)法區(qū)分相對(duì)位置關(guān)系。
基于這個(gè)問(wèn)題,2020年的AAAI又提出了DIOU_Loss。
c.DIOU_Loss
好的目標(biāo)框回歸函數(shù)應(yīng)該考慮三個(gè)重要幾何因素:重疊面積、中心點(diǎn)距離,長(zhǎng)寬比。
針對(duì)IOU和GIOU存在的問(wèn)題,作者從兩個(gè)方面進(jìn)行考慮
一:如何最小化預(yù)測(cè)框和目標(biāo)框之間的歸一化距離?
二:如何在預(yù)測(cè)框和目標(biāo)框重疊時(shí),回歸的更準(zhǔn)確?
針對(duì)第一個(gè)問(wèn)題,提出了DIOU_Loss(Distance_IOU_Loss)

DIOU_Loss考慮了重疊面積和中心點(diǎn)距離,當(dāng)目標(biāo)框包裹預(yù)測(cè)框的時(shí)候,直接度量2個(gè)框的距離,因此DIOU_Loss收斂的更快。
但就像前面好的目標(biāo)框回歸函數(shù)所說(shuō)的,沒(méi)有考慮到長(zhǎng)寬比。
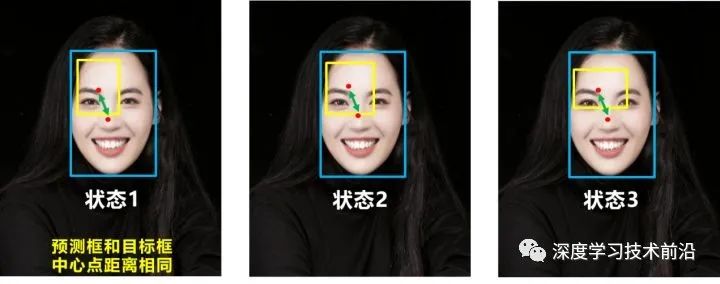
比如上面三種情況,目標(biāo)框包裹預(yù)測(cè)框,本來(lái)DIOU_Loss可以起作用。
但預(yù)測(cè)框的中心點(diǎn)的位置都是一樣的,因此按照DIOU_Loss的計(jì)算公式,三者的值都是相同的。
針對(duì)這個(gè)問(wèn)題,又提出了CIOU_Loss,不對(duì)不說(shuō),科學(xué)總是在解決問(wèn)題中,不斷進(jìn)步!!
d.CIOU_Loss
CIOU_Loss和DIOU_Loss前面的公式都是一樣的,不過(guò)在此基礎(chǔ)上還增加了一個(gè)影響因子,將預(yù)測(cè)框和目標(biāo)框的長(zhǎng)寬比都考慮了進(jìn)去。
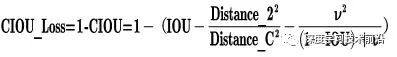
其中v是衡量長(zhǎng)寬比一致性的參數(shù),我們也可以定義為:

這樣CIOU_Loss就將目標(biāo)框回歸函數(shù)應(yīng)該考慮三個(gè)重要幾何因素:重疊面積、中心點(diǎn)距離,長(zhǎng)寬比全都考慮進(jìn)去了。
再來(lái)綜合的看下各個(gè)Loss函數(shù)的不同點(diǎn):
IOU_Loss:主要考慮檢測(cè)框和目標(biāo)框重疊面積。
GIOU_Loss:在IOU的基礎(chǔ)上,解決邊界框不重合時(shí)的問(wèn)題。
DIOU_Loss:在IOU和GIOU的基礎(chǔ)上,考慮邊界框中心點(diǎn)距離的信息。
CIOU_Loss:在DIOU的基礎(chǔ)上,考慮邊界框?qū)捀弑鹊某叨刃畔ⅰ?/p>
Yolov4中采用了CIOU_Loss的回歸方式,使得預(yù)測(cè)框回歸的速度和精度更高一些。
(2)DIOU_nms
Nms主要用于預(yù)測(cè)框的篩選,常用的目標(biāo)檢測(cè)算法中,一般采用普通的nms的方式,Yolov4則借鑒上面D/CIOU loss的論文:arxiv.org/pdf/1911.0828
將其中計(jì)算IOU的部分替換成DIOU的方式:
再來(lái)看下實(shí)際的案例

在上圖重疊的摩托車檢測(cè)中,中間的摩托車因?yàn)榭紤]邊界框中心點(diǎn)的位置信息,也可以回歸出來(lái)。
因此在重疊目標(biāo)的檢測(cè)中,DIOU_nms的效果優(yōu)于傳統(tǒng)的nms。
注意:有讀者會(huì)有疑問(wèn),這里為什么不用CIOU_nms,而用DIOU_nms?
答:因?yàn)榍懊嬷v到的CIOU_loss,是在DIOU_loss的基礎(chǔ)上,添加的影響因子,包含groundtruth標(biāo)注框的信息,在訓(xùn)練時(shí)用于回歸。
但在測(cè)試過(guò)程中,并沒(méi)有g(shù)roundtruth的信息,不用考慮影響因子,因此直接用DIOU_nms即可。
總體來(lái)說(shuō),YOLOv4的論文稱的上良心之作,將近幾年關(guān)于深度學(xué)習(xí)領(lǐng)域最新研究的tricks移植到Y(jié)olov4中做驗(yàn)證測(cè)試,將Yolov3的精度提高了不少。
雖然沒(méi)有全新的創(chuàng)新,但很多改進(jìn)之處都值得借鑒,借用Yolov4作者的總結(jié)。
Yolov4 主要帶來(lái)了 3 點(diǎn)新貢獻(xiàn):
(1)提出了一種高效而強(qiáng)大的目標(biāo)檢測(cè)模型,使用 1080Ti 或 2080Ti 就能訓(xùn)練出超快、準(zhǔn)確的目標(biāo)檢測(cè)器。
(2)在檢測(cè)器訓(xùn)練過(guò)程中,驗(yàn)證了最先進(jìn)的一些研究成果對(duì)目標(biāo)檢測(cè)器的影響。
(3)改進(jìn)了 SOTA 方法,使其更有效、更適合單 GPU 訓(xùn)練。
5.YoloV4相關(guān)代碼
5.1 python代碼
代碼地址:https://github.com/Tianxiaomo/pytorch-Yolov4
作者的訓(xùn)練和測(cè)試推理代碼都已經(jīng)完成
5.2 C++代碼
Yolov4作者Alexey的代碼,俄羅斯的大神,應(yīng)該是個(gè)獨(dú)立研究員,更新算法的頻繁程度令人佩服。
在Yolov3作者Joseph Redmon宣布停止更新Yolo算法之后,Alexey憑借對(duì)于Yolov3算法的不斷探索研究,贏得了Yolov3作者的認(rèn)可,發(fā)布了Yolov4。
代碼地址:https://github.com/AlexeyAB/darknet
好消息!
小白學(xué)視覺(jué)知識(shí)星球
開(kāi)始面向外開(kāi)放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺(jué)、目標(biāo)跟蹤、生物視覺(jué)、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車道線檢測(cè)、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺(jué)實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺(jué)。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~