
Kafka 和 DistributedLog 技術(shù)對(duì)比
因?yàn)閮烧叨际翘幚砣罩荆瑪?shù)據(jù)模型也類(lèi)似,所以這篇文章主要從技術(shù)角度討論 Apache Kafka 與 DistributedLog 的不同點(diǎn)。我們會(huì)盡量做到客觀,但由于我們不是 Apache Kafka 的專(zhuān)家,因此我們可能會(huì)對(duì) Apache Kafka 存在誤解。如果發(fā)現(xiàn)有錯(cuò),也請(qǐng)大家直接指出。
首先,讓我們簡(jiǎn)單地介紹一下 Kafka 和 DistributedLog 的概況。
Kafka 是什么?
Kafka 是最初由 Linkedin 開(kāi)源出來(lái)的一套分布式消息系統(tǒng),現(xiàn)在由 Apache 軟件基金會(huì)管理。這是一套基于分區(qū)的發(fā)布 / 訂閱系統(tǒng)。Kafka 中的關(guān)鍵概念就是 Topic。一個(gè) Topic 下面會(huì)有多個(gè)分區(qū),每個(gè)分區(qū)都有備份,分布在不同的代理服務(wù)器上。生產(chǎn)者會(huì)把數(shù)據(jù)記錄發(fā)布到一個(gè) Topic 下面的分區(qū)中,具體方式是輪詢(xún)或者基于主鍵做分區(qū),而消費(fèi)者會(huì)處理 Topic 中發(fā)布出來(lái)的數(shù)據(jù)記錄。所有數(shù)據(jù)都是發(fā)布給相應(yīng)分區(qū)的主代理進(jìn)程,再?gòu)?fù)制到從代理進(jìn)程,所有的讀數(shù)據(jù)請(qǐng)求也都是依次由主代理處理的。從代理僅僅用于數(shù)據(jù)的冗余備份,并在主代理無(wú)法繼續(xù)提供服務(wù)時(shí)頂上。圖一的左邊部分顯示了 Kafka 中的數(shù)據(jù)流。
DistributedLog 是什么?
與 Kafka 不同,DistributedLog 并不是一個(gè)基于分區(qū)的發(fā)布 / 訂閱系統(tǒng),它是一個(gè)復(fù)制日志流倉(cāng)庫(kù)。DistributedLog 中的關(guān)鍵概念是持續(xù)的復(fù)制日志流。一個(gè)日志流會(huì)被分段成多個(gè)日志片段。每個(gè)日志片段都在 Apache BookKeeper 中存儲(chǔ)成 Apache BooKeeper 中的一個(gè)賬目,其中的數(shù)據(jù)會(huì)在多個(gè)Bookie(Bookie 就是Apache BookKeeper 的存儲(chǔ)節(jié)點(diǎn))之間復(fù)制和均衡分布。一個(gè)日志流的所有數(shù)據(jù)記錄都由日志流的屬主排序,由許多個(gè)寫(xiě)入代理來(lái)管理日志流的屬主關(guān)系。應(yīng)用程序也可以使用核心庫(kù)來(lái)直接追加日志記錄。這對(duì)于復(fù)制狀態(tài)機(jī)一類(lèi)對(duì)于順序和排他寫(xiě)有著非常高要求的場(chǎng)景非常有用。每個(gè)追加到日志流末尾的日志記錄都會(huì)被賦予一個(gè)序列號(hào)。讀者可以從任何指定的序列號(hào)開(kāi)始讀日志流的數(shù)據(jù)。讀請(qǐng)求也會(huì)在那個(gè)流的所有存儲(chǔ)副本上做負(fù)載均衡。圖一的右半部分顯示了DistributedLog 中的數(shù)據(jù)流。
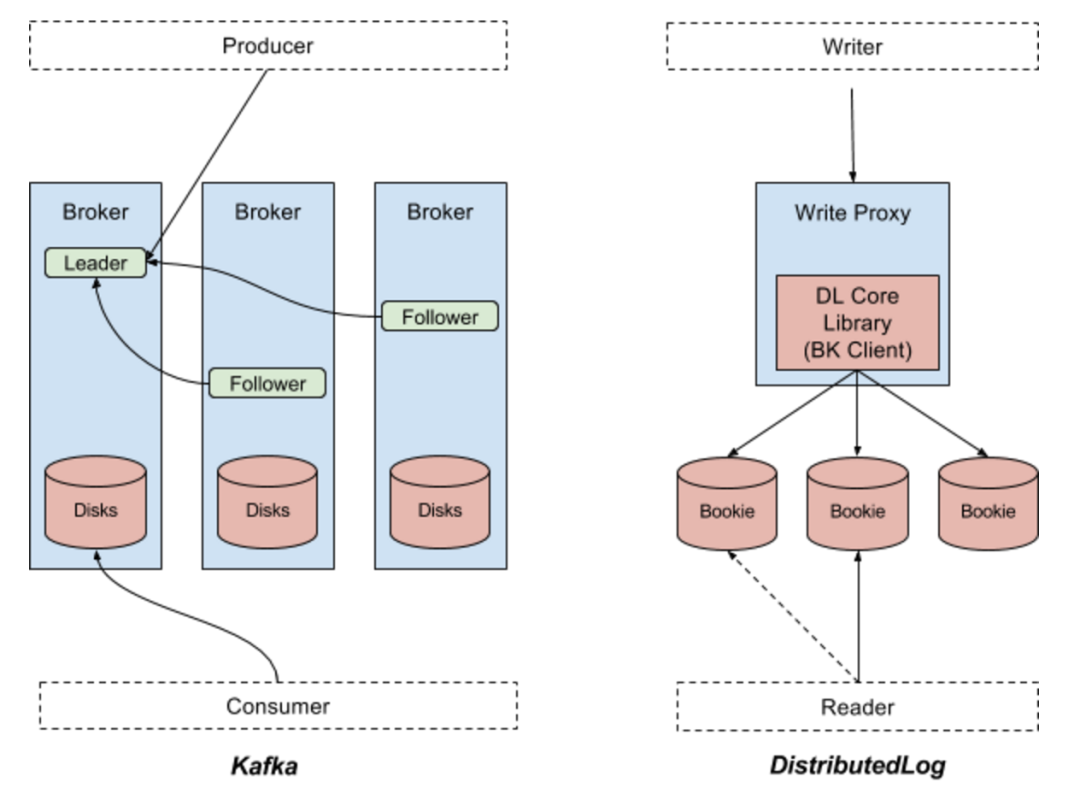
圖一:Apache Kafka 與Apache DistributedLog
Kafka 與 DistributedLog 有什么不同?
因?yàn)橥?lèi)事物才有可比較的基礎(chǔ),所以我們只在本文中把 Kafka 分區(qū)和 DistributedLog 流相對(duì)比。下表列出了兩套系統(tǒng)之間最顯著的不同點(diǎn)。

數(shù)據(jù)模型
Kafka 分區(qū)是存儲(chǔ)在代理服務(wù)器磁盤(pán)上的以若干個(gè)文件形式存在的日志。每條記錄都是一個(gè)鍵 - 值對(duì),但對(duì)于輪詢(xún)式的數(shù)據(jù)發(fā)布可以省略數(shù)據(jù)的主鍵。主鍵用于決定該條記錄會(huì)被存儲(chǔ)到哪個(gè)分區(qū)上以及用于日志壓縮功能。一個(gè)分區(qū)的所有數(shù)據(jù)只存儲(chǔ)在若干個(gè)代理服務(wù)器上,并從主代理服務(wù)器復(fù)制到從代理服務(wù)器。
DistributedLog 流是以一系列日志分片的形式存在的虛擬流。每個(gè)日志分片都以一條 BookKeeper 賬目的形式存在,并被復(fù)制到多個(gè) Bookie 上。在任意時(shí)刻都只有一個(gè)活躍的日志分片接受寫(xiě)入請(qǐng)求。在特定的時(shí)間段過(guò)后,或者舊日志分片達(dá)到配置大小(由配置的日志分片策略決定)之后,或者日志的屬主出故障之后,舊的日志分片會(huì)被封存,一個(gè)新的日志分片會(huì)被開(kāi)啟。
Kafka 分區(qū)和 DistributedLog 流在數(shù)據(jù)分片和分布的不同點(diǎn)決定了它們?cè)跀?shù)據(jù)持久化策略和集群操作(比如集群擴(kuò)展)上的不同。
圖二顯示了 DistributedLog 和 Kafka 數(shù)據(jù)模型的不同點(diǎn)
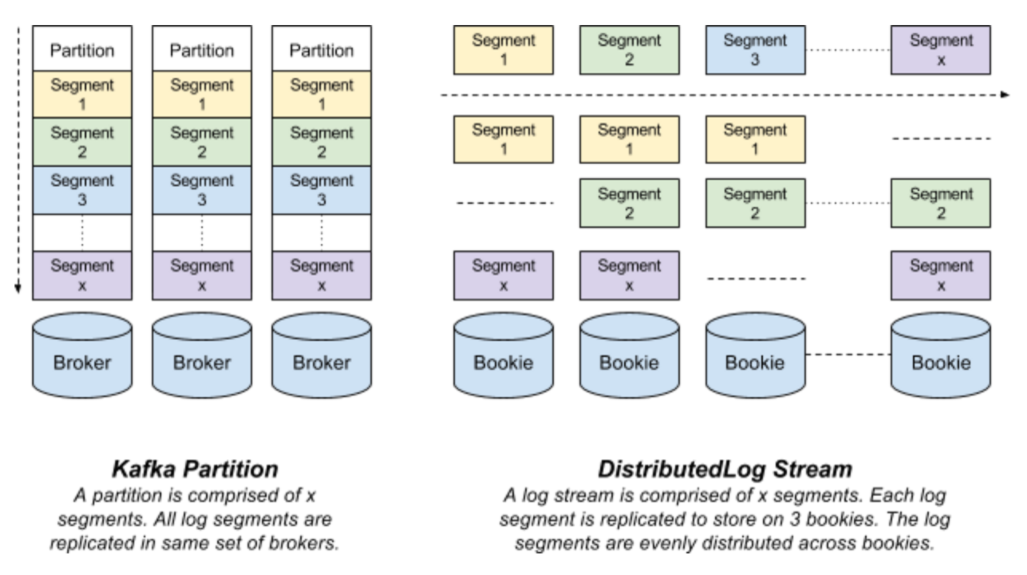
圖二:Kafka 分區(qū)與DistributedLog 流
數(shù)據(jù)持久化
一個(gè)Kafka 分區(qū)中的所有數(shù)據(jù)都保存在一個(gè)代理服務(wù)器上(并被復(fù)制到別的代理服務(wù)器上)。在配置的有效期過(guò)后數(shù)據(jù)會(huì)失效并被刪除。另外,也可以配置策略讓Kafka 的分區(qū)保留每個(gè)主鍵的最新值。
與Kafka 相似,DistributedLog 也可以為每個(gè)流配置有效期,并在超時(shí)之后將相應(yīng)的日志分片失效或刪除。除此之外,DistributedLog 還提供了顯示的截?cái)鄼C(jī)制。應(yīng)用程序可以顯式地將一個(gè)日志流截?cái)嗟搅鞯哪硞€(gè)指定位置。這對(duì)于構(gòu)建可復(fù)制的狀態(tài)機(jī)非常有用,因?yàn)榭蓮?fù)制的狀態(tài)機(jī)需要在刪除日志記錄之前先將狀態(tài)持久化。Manhattan 就是一個(gè)用到了這個(gè)功能的典型系統(tǒng)。
操作
數(shù)據(jù)分片和分布機(jī)制的不同也導(dǎo)致了維護(hù)集群操作上的不同,擴(kuò)展集群操作就是一個(gè)例子。
擴(kuò)展 Kafka 集群時(shí),通常現(xiàn)有分區(qū)都要做重新分布。重新分布操作會(huì)將 Kafka 分區(qū)挪動(dòng)到不同的副本上,以此達(dá)到均衡分布。這就要把整個(gè)流的數(shù)據(jù)從一個(gè)副本拷到另一個(gè)副本上。我們也說(shuō)過(guò)很多次了,執(zhí)行重新分布操作時(shí)必須非常小心,避免耗盡磁盤(pán)和網(wǎng)絡(luò)資源。
而擴(kuò)展 DistributedLog 集群的工作方式則截然不同。DistributedLog 包含兩層:存儲(chǔ)層(Apache BooKeeper)和服務(wù)層(寫(xiě)入和讀出代理)。在擴(kuò)展存儲(chǔ)層時(shí),我們只需要添加更多的 Bookie 就好了。新的 Bookie 馬上會(huì)被寫(xiě)入代理發(fā)現(xiàn),并立刻用于寫(xiě)入新的日志分片。在擴(kuò)展數(shù)據(jù)存儲(chǔ)層時(shí)不會(huì)有任何的重新分布操作。只在增加服務(wù)層時(shí)會(huì)有重新分布操作,但這個(gè)重新分布也只是移動(dòng)日志流的屬主權(quán),以使網(wǎng)絡(luò)代寬可以在各個(gè)代理之間均衡分布。這個(gè)重新分布的過(guò)程只與屬主權(quán)相關(guān),沒(méi)有數(shù)據(jù)遷移操作。這種存儲(chǔ)層和服務(wù)層的隔離不僅僅是讓系統(tǒng)具備了自動(dòng)擴(kuò)展的機(jī)制,更讓各種不同類(lèi)型的資源可以獨(dú)立擴(kuò)展。
寫(xiě)與生產(chǎn)者
如圖一所示,Kafka 生產(chǎn)者把數(shù)據(jù)一批批地寫(xiě)到 Kafka 分區(qū)的主代理服務(wù)器上。而 ISR (同步復(fù)制)集合中的從代理服務(wù)器會(huì)從主代理上把記錄復(fù)制走。只有在主代理從所有的 ISR 集合中的副本上都收到了成功的響應(yīng)之后,一條記錄才會(huì)被認(rèn)為是成功寫(xiě)入的。可以配置讓生產(chǎn)者只等待主代理的響應(yīng),還是等待 ISR 集合中的所有代理的響應(yīng)。
DistributedLog 中則有兩種方式把數(shù)據(jù)寫(xiě)入 DistributedLog 流,一是用一個(gè) Thrift 的瘦客戶(hù)端通過(guò)寫(xiě)代理(眾所周知的多寫(xiě)入)寫(xiě)入,二是通過(guò) DistributedLog 的核心庫(kù)來(lái)直接與存儲(chǔ)節(jié)點(diǎn)交互(眾所周知的單獨(dú)寫(xiě)入)。第一種方式很適合于構(gòu)建消息系統(tǒng),第二種則適用于構(gòu)建復(fù)制狀態(tài)機(jī)。你可以查閱 DistributedLog 文檔的相關(guān)章節(jié)來(lái)獲取更多的信息和參考,以找到你需要的方式。
日志流的屬主會(huì)并發(fā)地以BookKeeper 條目的形式向Bookie 中寫(xiě)入一批記錄,并等待多個(gè)Bookie 的Quorum 結(jié)果。Quorum 的大小取決于BookKeeper 賬目的_ack_quorum_size_ 參數(shù),并且可以配置到DistributedLog 流的級(jí)別。它提供了和Kafka 生產(chǎn)者相似的在持久性上的靈活性。在接下來(lái)的“復(fù)制”一節(jié)我們會(huì)對(duì)比兩者在復(fù)制算法上的更多不同之處。
Kafka 和 DistributedLog 都支持端到端的批量操作和壓縮機(jī)制。但兩者之間的一點(diǎn)微妙區(qū)別是對(duì) DistributedLog 的寫(xiě)入操作都是在收到響應(yīng)之前都先通過(guò) fsync 刷到硬盤(pán)上的,而我們并沒(méi)發(fā)現(xiàn) Kafka 也提供了類(lèi)似的可靠性保證。
讀與消費(fèi)者
Kafka 消費(fèi)者從主代理服務(wù)器上讀出數(shù)據(jù)記錄。這個(gè)設(shè)計(jì)的前提就是主代理上在大多數(shù)情況下最新的數(shù)據(jù)都還在文件系統(tǒng)頁(yè)緩存中。從充分利用文件系統(tǒng)頁(yè)緩存和獲得高性能的角度來(lái)說(shuō)這是一個(gè)好辦法。
DistributedLog 則采用了完全不同的方法。因?yàn)楦鱾€(gè)存儲(chǔ)節(jié)點(diǎn)之間沒(méi)有明確的主從關(guān)系,DistributedLog 可以從任意存儲(chǔ)著相關(guān)數(shù)據(jù)的存儲(chǔ)節(jié)點(diǎn)上讀出數(shù)據(jù)。為了獲得可預(yù)期的低延遲,DistributedLog 引入了一個(gè)推理式讀機(jī)制,即在超出了配置的讀操作時(shí)限之后,它會(huì)在不同的副本上再次嘗試獲取數(shù)據(jù)。這就可能會(huì)對(duì)存儲(chǔ)節(jié)點(diǎn)導(dǎo)致比 Kafka 更高的讀壓力。不過(guò),如果將讀超時(shí)時(shí)間配成可以讓 99% 的存儲(chǔ)節(jié)點(diǎn)的讀操作都不會(huì)超時(shí),那就可以極大程度地解決延遲問(wèn)題,只帶來(lái) 1% 的額外讀壓力。
對(duì)于讀的考慮和機(jī)制上的不同主要源于復(fù)制機(jī)制和存儲(chǔ)節(jié)點(diǎn)的 I/O 系統(tǒng)的不同,在下文會(huì)繼續(xù)討論。
復(fù)制
Kafka 用的是 ISR 復(fù)制算法:將一個(gè)代理服務(wù)器選為主。所有寫(xiě)操作都被發(fā)送到主代理上,所有處于 ISR 集合中的從代理都從主代理上讀取和復(fù)制數(shù)據(jù)。主代理會(huì)維護(hù)一個(gè)高水位線(xiàn)(HW,High Watermark),即每個(gè)分區(qū)最新提交的數(shù)據(jù)記錄的偏移量。高水位線(xiàn)會(huì)不斷同步到從代理上,并周期性地在所有代理上記錄檢查點(diǎn),以備恢復(fù)之用。在所有 ISR 集合中的副本都把數(shù)據(jù)寫(xiě)入了文件系統(tǒng)(并不必須是磁盤(pán))并向主代理發(fā)回了響應(yīng)之后,主代理才會(huì)更新高水位線(xiàn)。
ISR 機(jī)制讓我們可以增加或減少副本的數(shù)量,在可用性和性能之間做出權(quán)衡。可是擴(kuò)大或縮小副本的集合的副作用是增大了丟失數(shù)據(jù)的可能性。
DistributedLog 使用的是 Quorum 投票復(fù)制算法,這在 Zab、Raft 以及 Viewstamped Replication 等一致性算法中都很常見(jiàn)。日志流的屬主會(huì)并發(fā)地把數(shù)據(jù)記錄寫(xiě)入所有存儲(chǔ)節(jié)點(diǎn),并在得到超過(guò)配置數(shù)量的存儲(chǔ)節(jié)點(diǎn)投票確認(rèn)之后,才認(rèn)為數(shù)據(jù)已成功提交。存儲(chǔ)節(jié)點(diǎn)也只在數(shù)據(jù)被顯式地調(diào)用 flush 操作刷入磁盤(pán)之后才會(huì)響應(yīng)寫(xiě)入請(qǐng)求。日志流的屬主也會(huì)維護(hù)一個(gè)日志流的最新提交的數(shù)據(jù)記錄的偏移量,就是大家知道的 Apache BookKeeper 中的 LAC(LastAddConfirmed)。LAC 也會(huì)保存在數(shù)據(jù)記錄中(來(lái)節(jié)省額外的 RPC 調(diào)用開(kāi)銷(xiāo)),并不斷復(fù)制到別的存儲(chǔ)節(jié)點(diǎn)上。DistributedLog 中復(fù)本集合的大小是在每個(gè)流的每個(gè)日志分片級(jí)別可配置的。改變復(fù)制參數(shù)只會(huì)影響新的日志分片,不會(huì)影響已有的。
存儲(chǔ)
每個(gè) Kafka 分區(qū)都以若干個(gè)文件的形式保存在代理的磁盤(pán)上。它利用文件系統(tǒng)的頁(yè)緩存和 I/O 調(diào)度機(jī)制來(lái)得到高性能。Kafka 也是因此利用 Java 的 sendfile API 來(lái)高效地從代理中寫(xiě)入讀出數(shù)據(jù)的。不過(guò),在某些情況下(比如消費(fèi)者處理不及時(shí)、隨機(jī)讀寫(xiě)等),頁(yè)緩存中的數(shù)據(jù)淘汰很頻繁,它的性能也有很大的不確性性。
DistributedLog 用的則是不同的 I/O 模型。圖三表示了 Bookie(BookKeeper 的存儲(chǔ)節(jié)點(diǎn))的 I/O 機(jī)制。寫(xiě)入(藍(lán)線(xiàn))、末尾讀(紅線(xiàn))和中間讀(紫線(xiàn))這三種常見(jiàn)的 I/O 操作都被隔離到了三種物理上不同的 I/O 子系統(tǒng)中。所有寫(xiě)入都被順序地追加到磁盤(pán)上的日志文件,再批量提交到硬盤(pán)上。在寫(xiě)操作持久化到磁盤(pán)上之后,它們就會(huì)放到一個(gè) Memtable 中,再向客戶(hù)端發(fā)回響應(yīng)。Memtable 中的數(shù)據(jù)會(huì)被異步刷新到交叉存取的索引數(shù)據(jù)結(jié)構(gòu)中:記錄被追加到日志文件中,偏移量則在分類(lèi)賬目的索引文件中根據(jù)記錄 ID 索引起來(lái)。最新的數(shù)據(jù)肯定在 Memtable 中,供末尾讀操作使用。中間讀會(huì)從記錄日志文件中獲取數(shù)據(jù)。由于物理隔離的存在,Bookie 節(jié)點(diǎn)可以充分利用網(wǎng)絡(luò)流入帶寬和磁盤(pán)的順序?qū)懭胩匦詠?lái)滿(mǎn)足寫(xiě)請(qǐng)求,以及利用網(wǎng)絡(luò)流出代寬和多個(gè)磁盤(pán)共同提供的 IOPS 處理能力來(lái)滿(mǎn)足讀請(qǐng)求,彼此之間不會(huì)相互干擾。
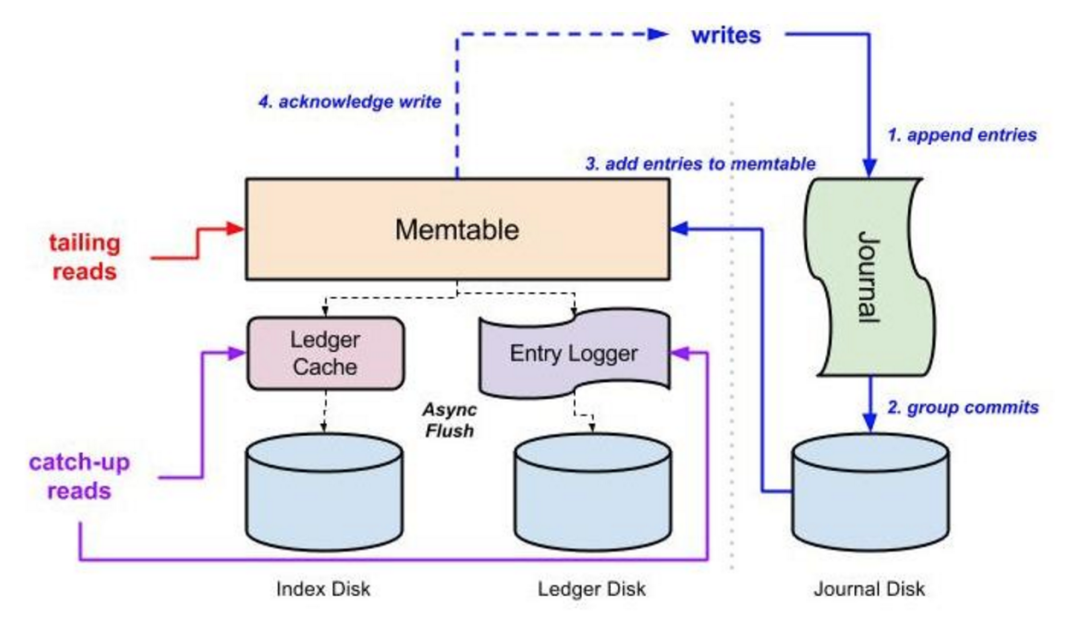
圖三:BookKeeper 的 I/O 隔離
小結(jié)
Kafka 和 DistributedLog 都是設(shè)計(jì)來(lái)處理日志流相關(guān)問(wèn)題的。它們有相似性,但在存儲(chǔ)和復(fù)制機(jī)制上有著不同的設(shè)計(jì)理念,因此有了不同的實(shí)現(xiàn)方式。希望這篇文章能從技術(shù)角度解釋清楚它們的區(qū)別,回答一些問(wèn)題。