
解析Transformer模型
?GiantPandaCV導(dǎo)語(yǔ):這篇文章為大家介紹了一下Transformer模型,Transformer模型原本是NLP中的一個(gè)Idea,后來(lái)也被引入到計(jì)算機(jī)視覺(jué)中,例如前面介紹過(guò)的DETR就是將目標(biāo)檢測(cè)算法和Transformer進(jìn)行結(jié)合,另外基于Transformer的魔改工作最近也層出不窮,感興趣的同學(xué)可以了解一下。
?
要讀DETR論文視頻解讀的同學(xué)可以點(diǎn)下方鏈接:
CV和NLP的統(tǒng)一,DETR 目標(biāo)檢測(cè)框架論文解讀
前言
Google于2017年提出了《Attention is all you need》,拋棄了傳統(tǒng)的RNN結(jié)構(gòu),「設(shè)計(jì)了一種Attention機(jī)制,通過(guò)堆疊Encoder-Decoder結(jié)構(gòu)」,得到了一個(gè)Transformer模型,在機(jī)器翻譯任務(wù)中「取得了BLEU值的新高」。在后續(xù)很多模型也基于Transformer進(jìn)行改進(jìn),也得到了很多表現(xiàn)不錯(cuò)的NLP模型,前段時(shí)間,相關(guān)工作也引申到了CV中的目標(biāo)檢測(cè),可參考FAIR的DETR模型
引入問(wèn)題
常見(jiàn)的時(shí)間序列任務(wù)采用的模型通常都是RNN系列,然而RNN系列模型的順序計(jì)算方式帶來(lái)了兩個(gè)問(wèn)題
某個(gè)時(shí)間狀態(tài),依賴于上一時(shí)間步狀態(tài),導(dǎo)致模型「不能通過(guò)并行計(jì)算來(lái)加速」 RNN系列的魔改模型比如GRU, LSTM,雖然「引入了門機(jī)制」(gate),但是對(duì)「長(zhǎng)時(shí)間依賴的問(wèn)題緩解能力有限」,不能徹底解決
因此我們?cè)O(shè)計(jì)了一個(gè)全新的結(jié)構(gòu)Transformer,通過(guò)Attention注意力機(jī)制,來(lái)對(duì)時(shí)間序列更好的建模。同時(shí)我們不需要像RNN那樣順序計(jì)算,從而能讓模型更能充分發(fā)揮并行計(jì)算性能。
模型架構(gòu)

上圖展示的就是Transformer的結(jié)構(gòu),左邊是編碼器Encoder,右邊是解碼器Decoder。通過(guò)多次堆疊,形成了Transformer。下面我們分別看下Encoder和Decoder的具體結(jié)構(gòu)
Encoder
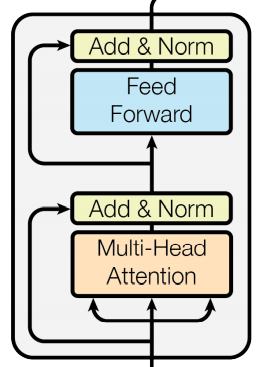
Encoder結(jié)構(gòu)如上,它由以下sublayer構(gòu)成
Multi-Head Attention 多頭注意力 Feed Forward 層
Self Attention
Multi-Head Attention多頭注意力層是由多個(gè)self attention來(lái)組成的,因此我們先講解下模型的自注意力機(jī)制。
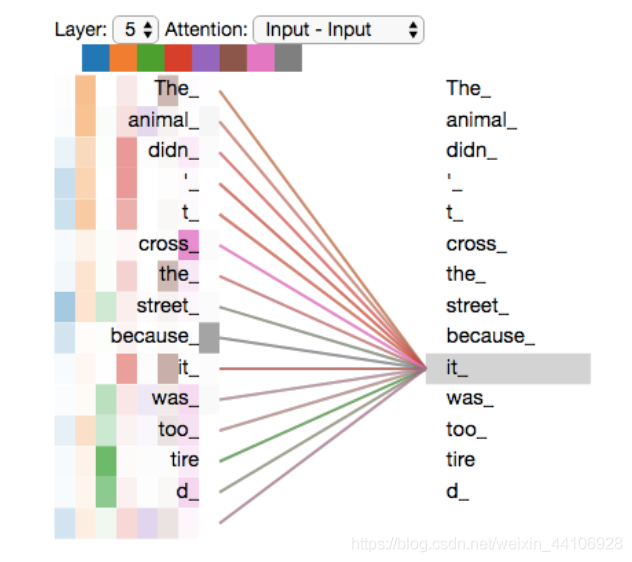
在一句話中,如果給每個(gè)詞都分配相同的權(quán)重,那么會(huì)很難讓模型去學(xué)習(xí)詞與詞對(duì)應(yīng)的關(guān)系。舉個(gè)例子
The?animal?didn't?cross?the?street?because?it?was?too?tired
我們需要讓模型去推斷 it 所指代的東西,當(dāng)我們給模型加了注意力機(jī)制,它的表現(xiàn)如下

我們通過(guò)注意力機(jī)制,讓模型能看到輸入的各個(gè)單詞,然后它會(huì)更加關(guān)注于 The animal,從而更好的進(jìn)行編碼。
論文里將attention模塊記為「Scaled Dot-Product Attention」,計(jì)算如下
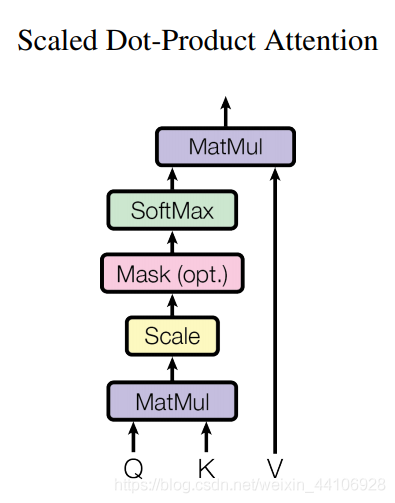
Q 代表 Query 矩陣 K 代表 Key 矩陣 V 代表 Value 矩陣 dk 是一個(gè)縮放因子
其中 Q, K, V(向量長(zhǎng)度為64)是由輸入X經(jīng)過(guò)三個(gè)不同的權(quán)重矩陣(shape=512x64)計(jì)算得來(lái),

下面我們看一個(gè)具體例子

以Thinking這個(gè)單詞為例,我們需要計(jì)算整個(gè)句子所有詞與它的score。
X1是 Thinking對(duì)應(yīng)的Embedding向量。然后我們計(jì)算得到了X1對(duì)應(yīng)的查詢向量q1 然后我們與Key向量進(jìn)行相乘,來(lái)計(jì)算相關(guān)性,這里記作Score。「這個(gè)過(guò)程可以看作是當(dāng)前詞的搜索q1,與其他詞的key去匹配」。當(dāng)相關(guān)性越高,說(shuō)明我們需要放更多注意力在上面。 然后除以縮放因子,做一個(gè)Softmax運(yùn)算 Softmax后的結(jié)果與Value向量相乘,得到最終結(jié)果
MultiHead-Attention
理解了自注意力機(jī)制后,我們可以很好的理解多頭注意力機(jī)制。簡(jiǎn)單來(lái)說(shuō),多頭注意力其實(shí)就是合并了多個(gè)自注意力機(jī)制的結(jié)果

我們以原文的8個(gè)注意力頭為例子,多頭注意力的操作如下
將輸入數(shù)據(jù)X分別輸入進(jìn)8個(gè)自注意力模塊
分別計(jì)算出每個(gè)自注意力模塊的結(jié)果Z0, Z1, Z2.....Z7
將各個(gè)自注意力模塊結(jié)果Zi拼成一個(gè)大矩陣Z
經(jīng)過(guò)一層全連接層,得到最終的輸出 最后多頭注意力的表現(xiàn)類似如下
多頭注意力機(jī)制效果
Feed Forward Neural Network
這個(gè)FFN模塊比較簡(jiǎn)單,本質(zhì)上全是兩層全連接層加一個(gè)Relu激活
Positional Encoding
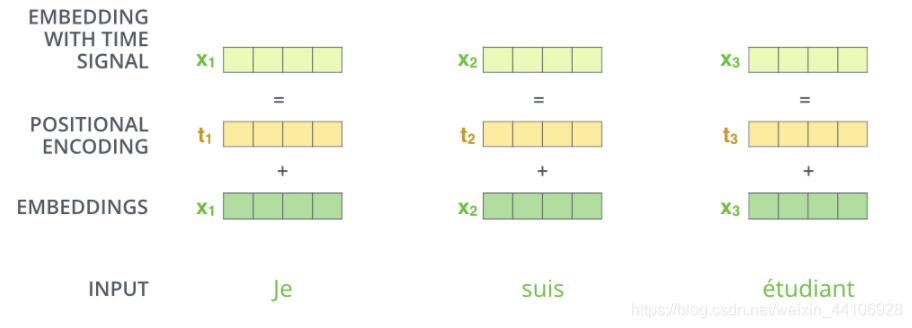
摒棄了CNN和RNN結(jié)構(gòu),我們無(wú)法很好的利用序列的順序信息,因此我們采用了額外的一個(gè)位置編碼來(lái)進(jìn)行緩解
然后與輸入相加,通過(guò)引入位置編碼,給詞向量中賦予了單詞的位置信息
下圖是總Encoder的架構(gòu)

Decoder
Decoder的結(jié)構(gòu)與Encoder的結(jié)構(gòu)很相似
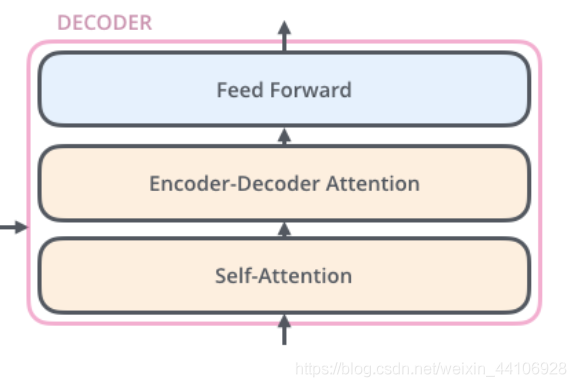
「只不過(guò)額外引入了當(dāng)前翻譯和編碼特征向量的注意力」,這里就不展開(kāi)了。
代碼
這里參考的是TensorFlow的官方實(shí)現(xiàn)notebook transformer.ipynb
位置編碼
def?get_angles(pos,?i,?d_model):
??angle_rates?=?1?/?np.power(10000,?(2?*?(i//2))?/?np.float32(d_model))
??return?pos?*?angle_rates
def?positional_encoding(position,?d_model):
??angle_rads?=?get_angles(np.arange(position)[:,?np.newaxis],
??????????????????????????np.arange(d_model)[np.newaxis,?:],
??????????????????????????d_model)
??
??#?apply?sin?to?even?indices?in?the?array;?2i
??angle_rads[:,?0::2]?=?np.sin(angle_rads[:,?0::2])
??
??#?apply?cos?to?odd?indices?in?the?array;?2i+1
??angle_rads[:,?1::2]?=?np.cos(angle_rads[:,?1::2])
????
??pos_encoding?=?angle_rads[np.newaxis,?...]
????
??return?tf.cast(pos_encoding,?dtype=tf.float32)
這里就是根據(jù)公式,生成位置編碼
Scaled-Dot Attention
def?scaled_dot_product_attention(q,?k,?v,?mask):
??"""Calculate?the?attention?weights.
??q,?k,?v?must?have?matching?leading?dimensions.
??k,?v?must?have?matching?penultimate?dimension,?i.e.:?seq_len_k?=?seq_len_v.
??The?mask?has?different?shapes?depending?on?its?type(padding?or?look?ahead)?
??but?it?must?be?broadcastable?for?addition.
??
??Args:
????q:?query?shape?==?(...,?seq_len_q,?depth)
????k:?key?shape?==?(...,?seq_len_k,?depth)
????v:?value?shape?==?(...,?seq_len_v,?depth_v)
????mask:?Float?tensor?with?shape?broadcastable?
??????????to?(...,?seq_len_q,?seq_len_k).?Defaults?to?None.
????
??Returns:
????output,?attention_weights
??"""
??matmul_qk?=?tf.matmul(q,?k,?transpose_b=True)??#?(...,?seq_len_q,?seq_len_k)
??
??#?scale?matmul_qk
??dk?=?tf.cast(tf.shape(k)[-1],?tf.float32)
??scaled_attention_logits?=?matmul_qk?/?tf.math.sqrt(dk)
??#?add?the?mask?to?the?scaled?tensor.
??if?mask?is?not?None:
????scaled_attention_logits?+=?(mask?*?-1e9)??
??#?softmax?is?normalized?on?the?last?axis?(seq_len_k)?so?that?the?scores
??#?add?up?to?1.
??attention_weights?=?tf.nn.softmax(scaled_attention_logits,?axis=-1)??#?(...,?seq_len_q,?seq_len_k)
??output?=?tf.matmul(attention_weights,?v)??#?(...,?seq_len_q,?depth_v)
??return?output,?attention_weights
輸入的是Q, K, V矩陣和一個(gè)mask掩碼向量 根據(jù)公式進(jìn)行矩陣相乘,得到最終的輸出,以及注意力權(quán)重
MultiheadAttention
這里的代碼就是將多個(gè)注意力結(jié)果組合在一起
class?MultiHeadAttention(tf.keras.layers.Layer):
??def?__init__(self,?d_model,?num_heads):
????super(MultiHeadAttention,?self).__init__()
????self.num_heads?=?num_heads
????self.d_model?=?d_model
????
????assert?d_model?%?self.num_heads?==?0
????
????self.depth?=?d_model?//?self.num_heads
????
????self.wq?=?tf.keras.layers.Dense(d_model)
????self.wk?=?tf.keras.layers.Dense(d_model)
????self.wv?=?tf.keras.layers.Dense(d_model)
????
????self.dense?=?tf.keras.layers.Dense(d_model)
????????
??def?split_heads(self,?x,?batch_size):
????"""Split?the?last?dimension?into?(num_heads,?depth).
????Transpose?the?result?such?that?the?shape?is?(batch_size,?num_heads,?seq_len,?depth)
????"""
????x?=?tf.reshape(x,?(batch_size,?-1,?self.num_heads,?self.depth))
????return?tf.transpose(x,?perm=[0,?2,?1,?3])
????
??def?call(self,?v,?k,?q,?mask):
????batch_size?=?tf.shape(q)[0]
????
????q?=?self.wq(q)??#?(batch_size,?seq_len,?d_model)
????k?=?self.wk(k)??#?(batch_size,?seq_len,?d_model)
????v?=?self.wv(v)??#?(batch_size,?seq_len,?d_model)
????
????q?=?self.split_heads(q,?batch_size)??#?(batch_size,?num_heads,?seq_len_q,?depth)
????k?=?self.split_heads(k,?batch_size)??#?(batch_size,?num_heads,?seq_len_k,?depth)
????v?=?self.split_heads(v,?batch_size)??#?(batch_size,?num_heads,?seq_len_v,?depth)
????
????#?scaled_attention.shape?==?(batch_size,?num_heads,?seq_len_q,?depth)
????#?attention_weights.shape?==?(batch_size,?num_heads,?seq_len_q,?seq_len_k)
????scaled_attention,?attention_weights?=?scaled_dot_product_attention(
????????q,?k,?v,?mask)
????
????scaled_attention?=?tf.transpose(scaled_attention,?perm=[0,?2,?1,?3])??#?(batch_size,?seq_len_q,?num_heads,?depth)
????concat_attention?=?tf.reshape(scaled_attention,?
??????????????????????????????????(batch_size,?-1,?self.d_model))??#?(batch_size,?seq_len_q,?d_model)
????output?=?self.dense(concat_attention)??#?(batch_size,?seq_len_q,?d_model)
????????
????return?output,?attention_weights
FFN
def?point_wise_feed_forward_network(d_model,?dff):
??return?tf.keras.Sequential([
??????tf.keras.layers.Dense(dff,?activation='relu'),??#?(batch_size,?seq_len,?dff)
??????tf.keras.layers.Dense(d_model)??#?(batch_size,?seq_len,?d_model)
??])
有了這三個(gè)模塊,就可以組合成Encoder和Decoder了,這里限于篇幅就不展開(kāi),有興趣的可以看下官方notebook
總結(jié)
Transformer這個(gè)模型設(shè)計(jì)還是很有特點(diǎn)的,雖然本質(zhì)上還是全連接層的各個(gè)組合,但是通過(guò)不同的權(quán)重矩陣,對(duì)序列進(jìn)行注意力機(jī)制建模。并且根據(jù)模型無(wú)法利用序列順序信息的缺陷,設(shè)計(jì)了一套位置編碼機(jī)制,賦予詞向量位置信息。近年來(lái)對(duì)Transformer的魔改也有很多,相信這個(gè)模型還有很大的潛力去挖掘。
相關(guān)資料參考
Tensorflow官方notebook transformer.ipynb: ('https://github.com/tensorflow/docs/blob/master/site/en/tutorials/text/transformer.ipynb') illustrated-transformer: (http://jalammar.github.io/illustrated-transformer/) 該作者的圖示很明晰,相對(duì)容易理解
歡迎關(guān)注GiantPandaCV, 在這里你將看到獨(dú)家的深度學(xué)習(xí)分享,堅(jiān)持原創(chuàng),每天分享我們學(xué)習(xí)到的新鮮知識(shí)。( ? ?ω?? )?
有對(duì)文章相關(guān)的問(wèn)題,或者想要加入交流群,歡迎添加BBuf微信:
為了方便讀者獲取資料以及我們公眾號(hào)的作者發(fā)布一些Github工程的更新,我們成立了一個(gè)QQ群,二維碼如下,感興趣可以加入。