
如何優(yōu)雅地學(xué)習(xí)Pandas
Pandas是數(shù)據(jù)挖掘常見的工具,掌握使用過程中的函數(shù)是非常重要的。
本文將借助可視化的過程,講解Pandas中常用函數(shù)的操作。
一、sort_values
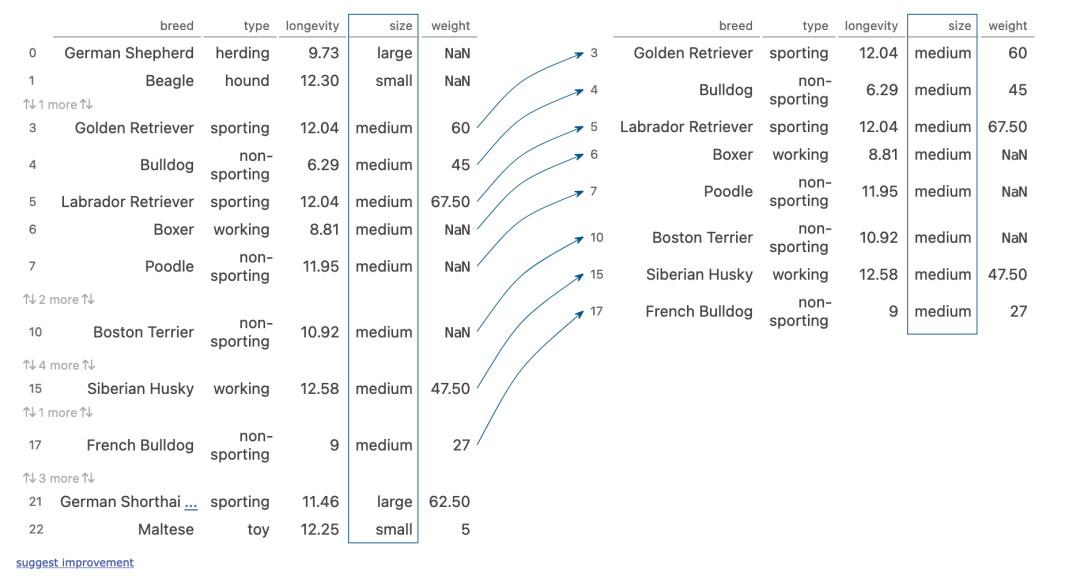
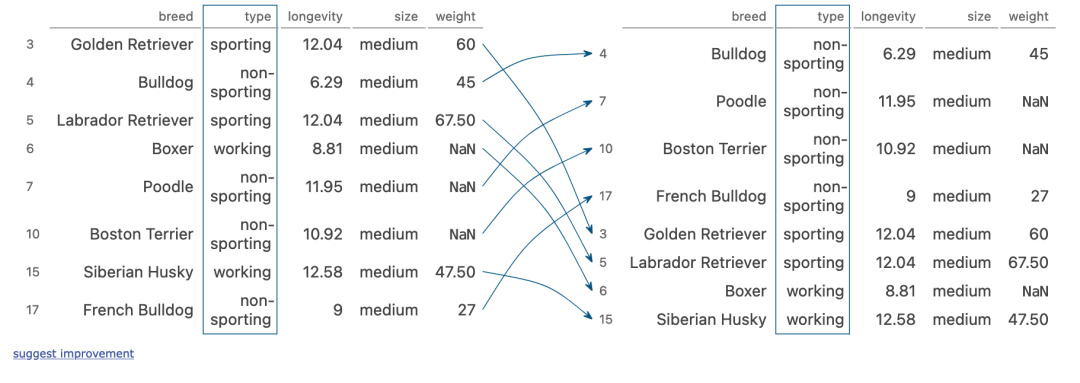
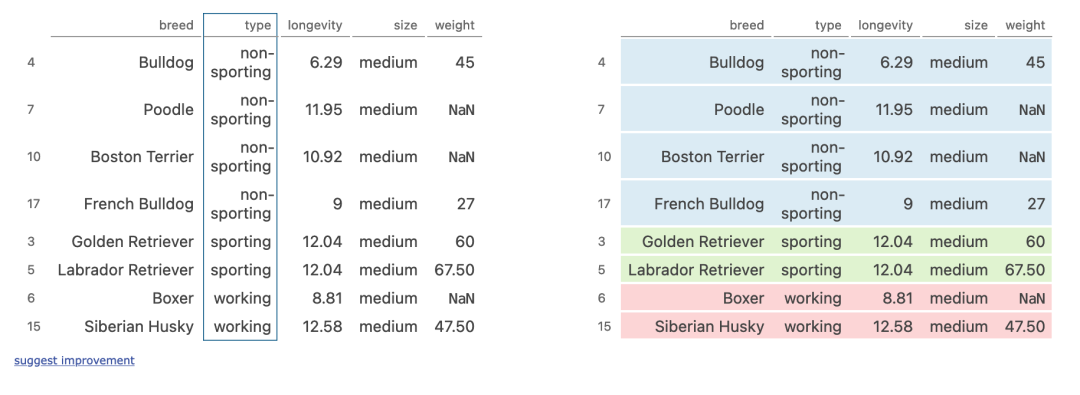
(dogs[dogs['size']?==?'medium']
?.sort_values('type')
?.groupby('type').median()
)
執(zhí)行步驟:
size列篩選出部分行 然后將行的類型進(jìn)行轉(zhuǎn)換 按照type列進(jìn)行分組,計(jì)算中位數(shù)

二、selecting a column
dogs['longevity']

三、groupby + mean
dogs.groupby('size').mean()
執(zhí)行步驟:
將數(shù)據(jù)按照size進(jìn)行分組 在分組內(nèi)進(jìn)行聚合操作
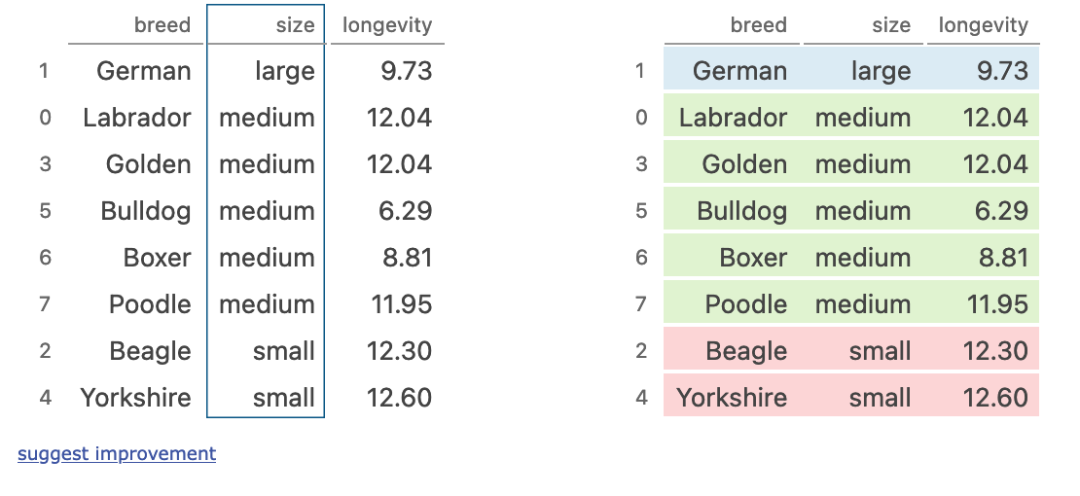

四、grouping multiple columns
dogs.groupby(['type',?'size'])

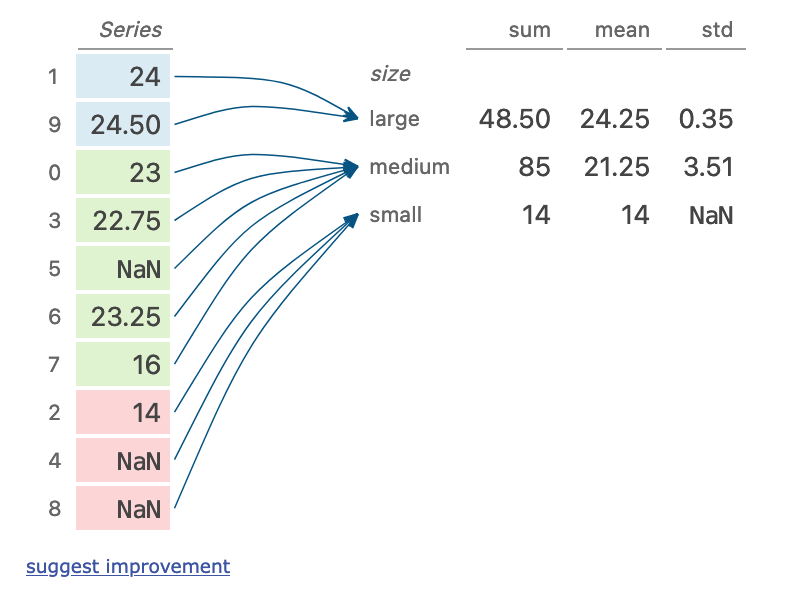
五、groupby + multi aggregation
(dogs
??.sort_values('size')
??.groupby('size')['height']
??.agg(['sum',?'mean',?'std'])
)
執(zhí)行步驟
按照size列對(duì)數(shù)據(jù)進(jìn)行排序 按照size進(jìn)行分組 對(duì)分組內(nèi)的height進(jìn)行計(jì)算
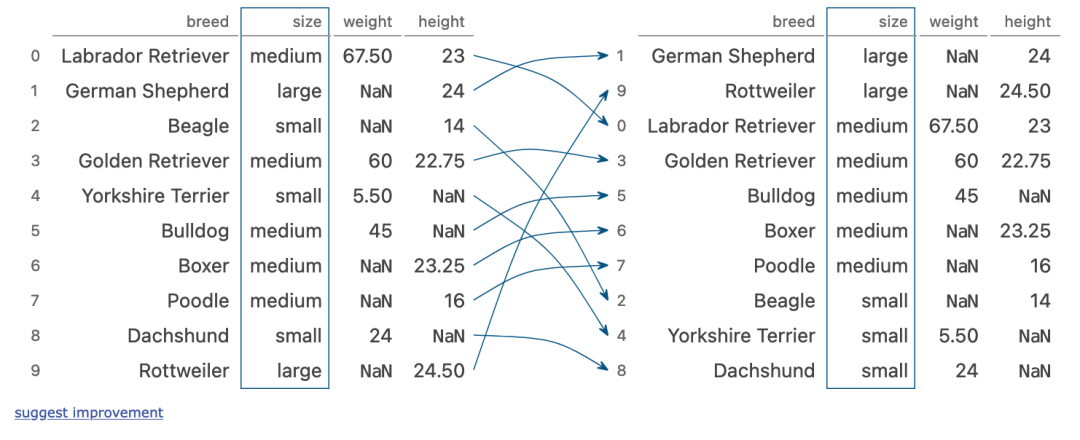
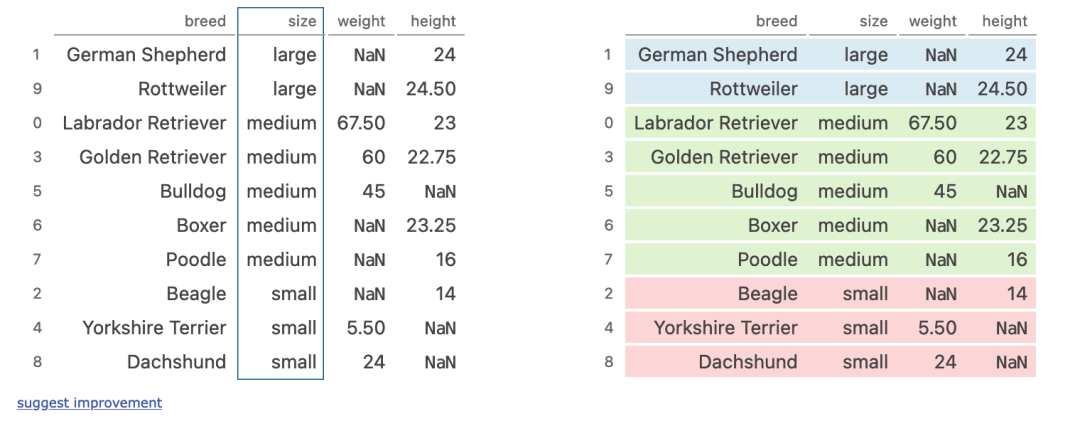
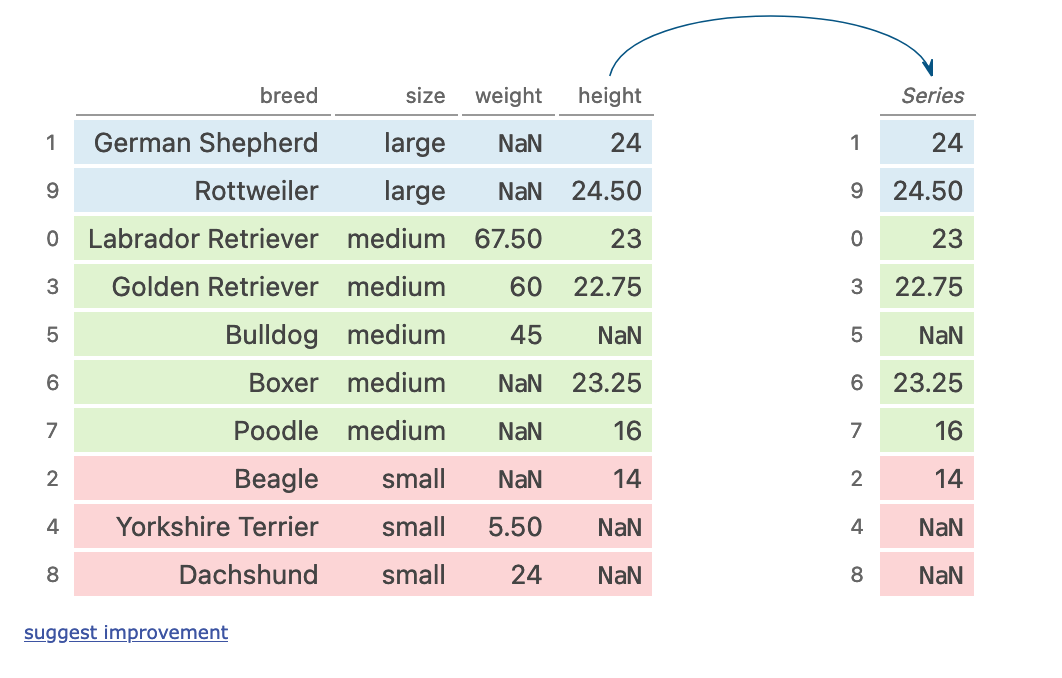
六、filtering for columns
df.loc[:,?df.loc['two']?<=?20]

七、filtering for rows
dogs.loc[(dogs['size']?==?'medium')?&?(dogs['longevity']?>?12),?'breed']

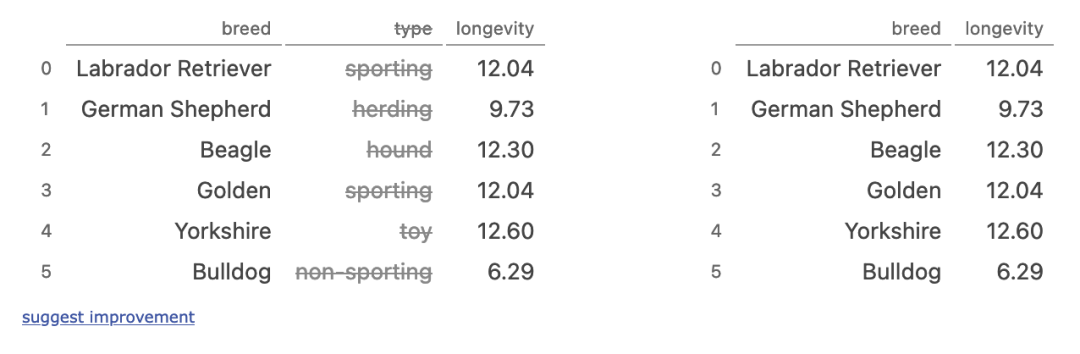
八、dropping columns
dogs.drop(columns=['type'])
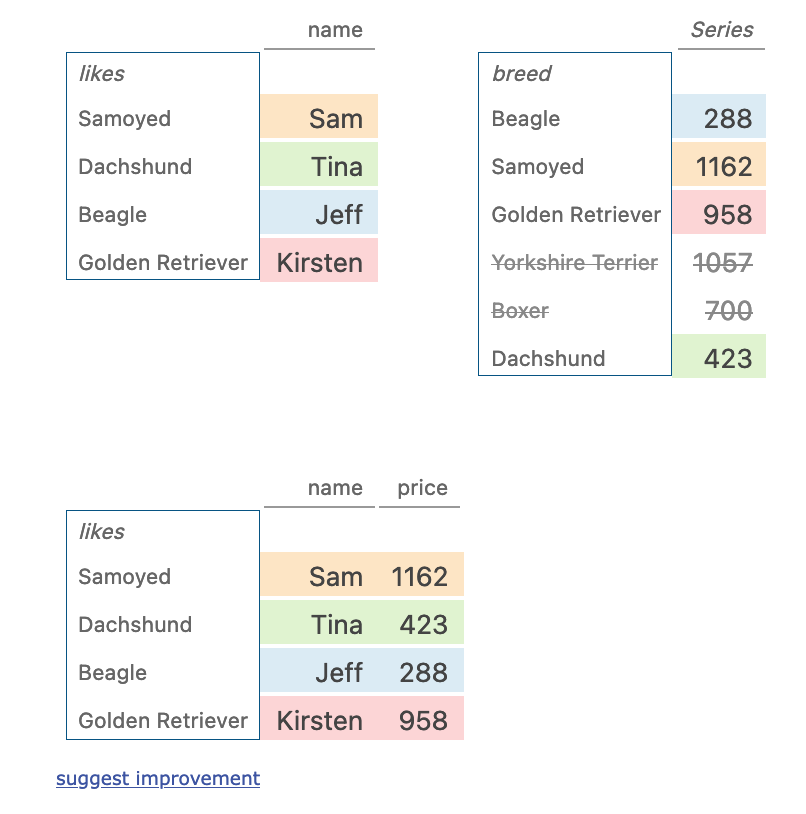
九、join
ppl.join(dogs)
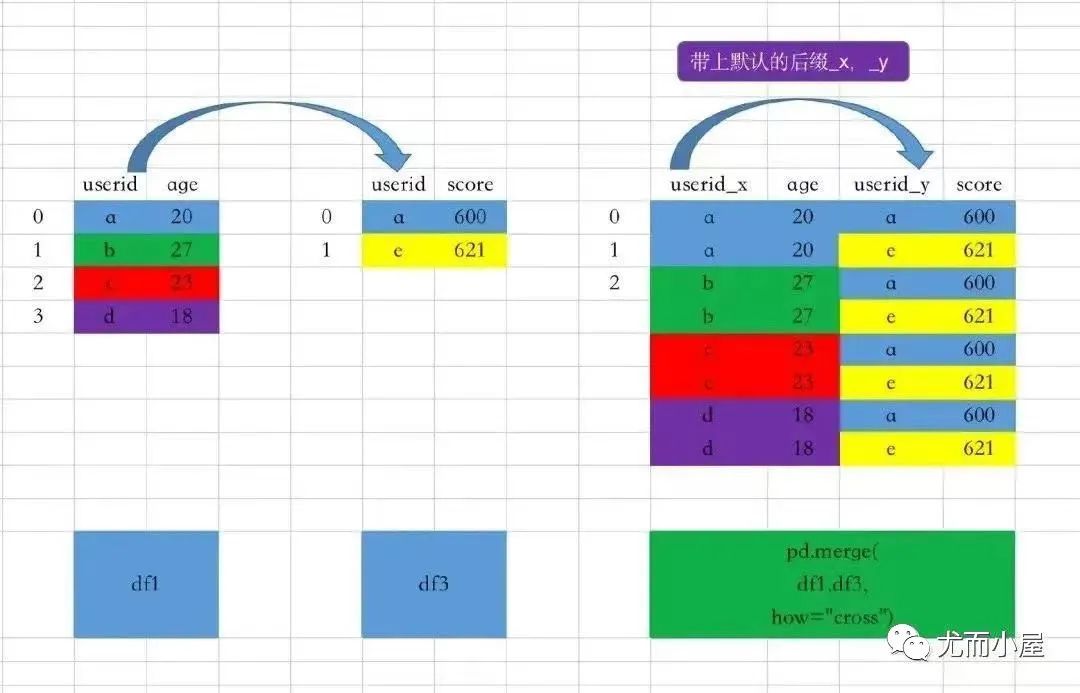
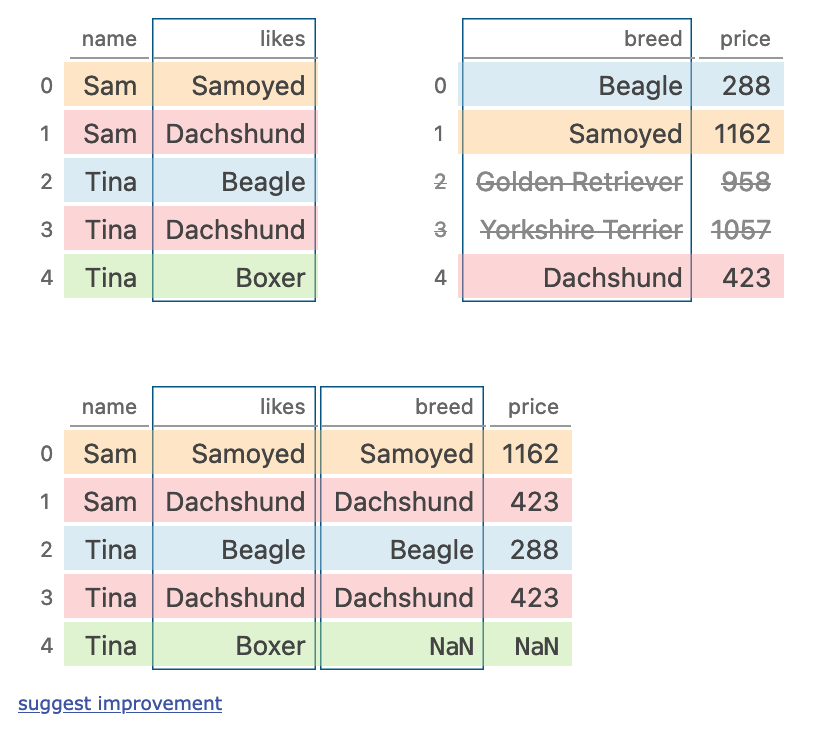
十、merge
ppl.merge(dogs,?left_on='likes',?right_on='breed',?how='left')
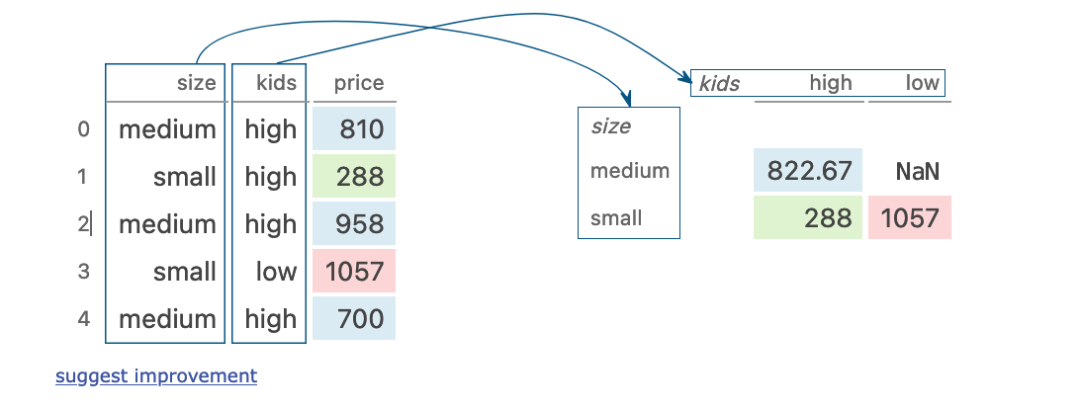
十一、pivot table
dogs.pivot_table(index='size',?columns='kids',?values='price')
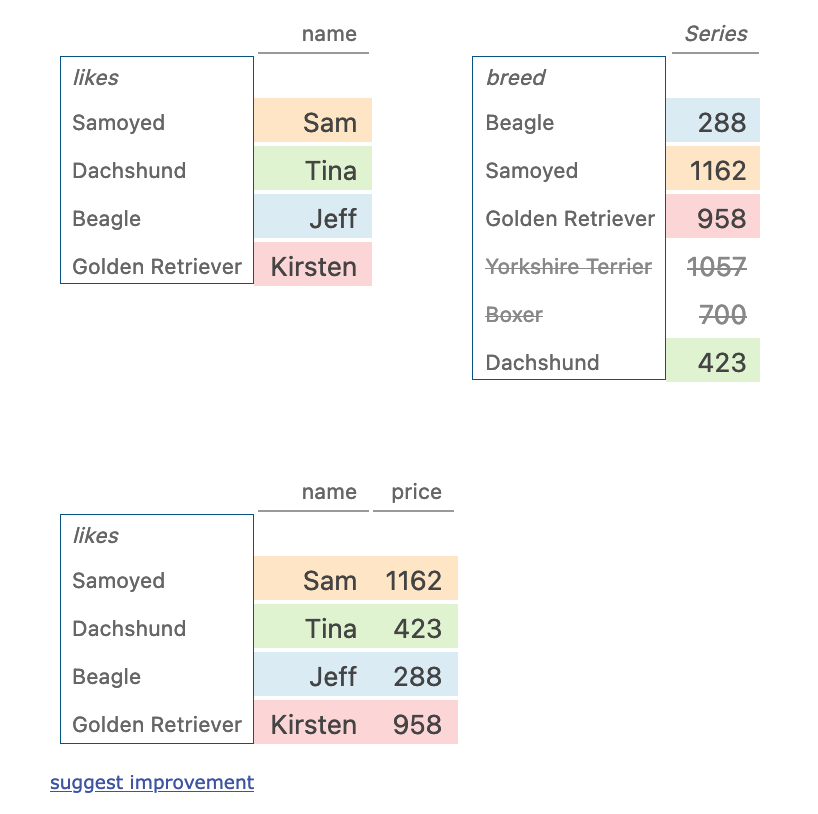
十二、melt
dogs.melt()

十三、pivot
dogs.pivot(index='size',?columns='kids')
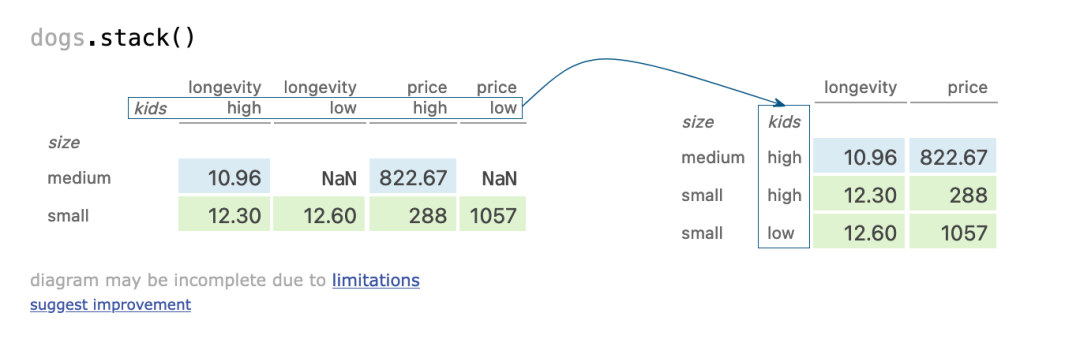
十四、stack?column index
dogs.stack()
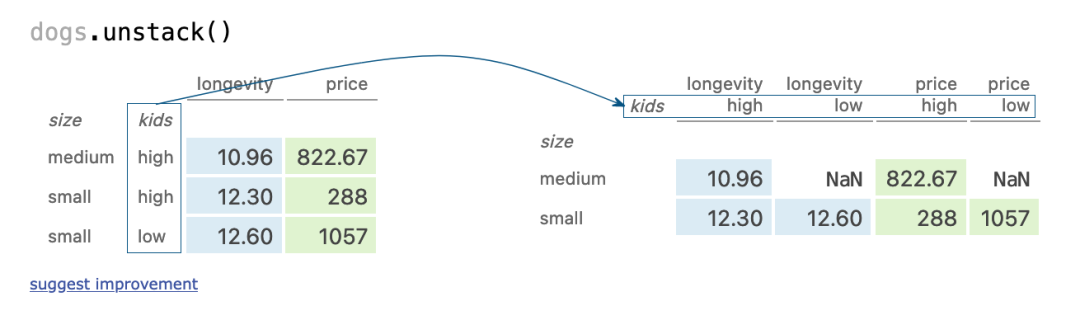
十五、unstack?row index
dogs.unstack()
十六、reset?index
dogs.reset_index()

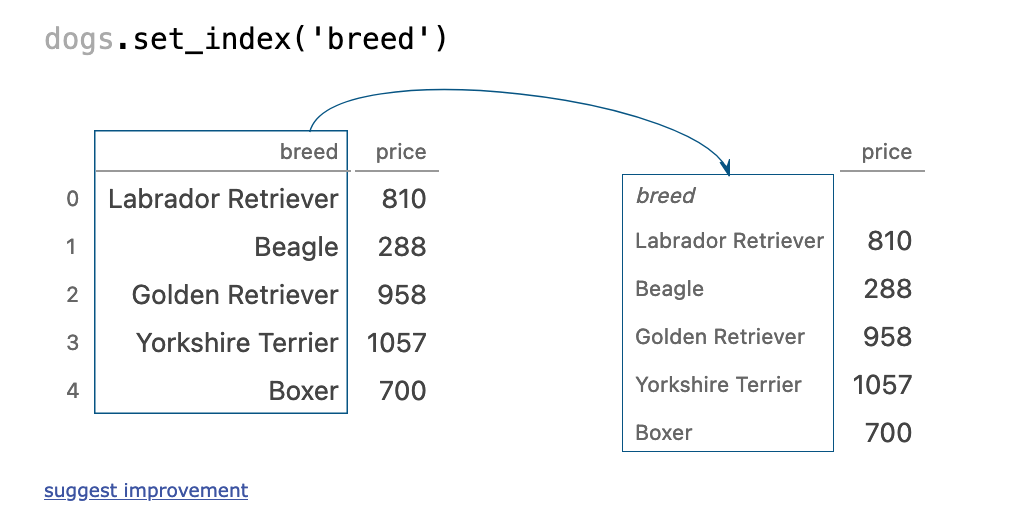
十七、set_index
dogs.set_index('breed')
評(píng)論
圖片
表情