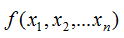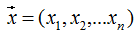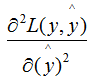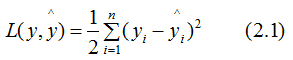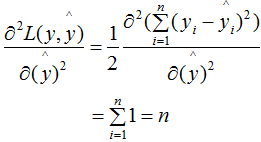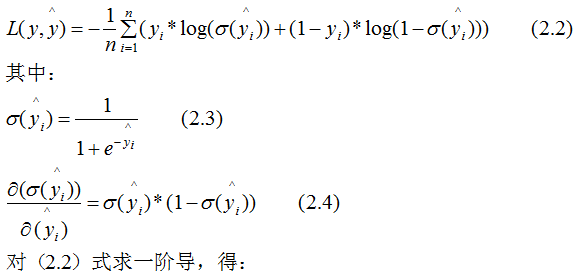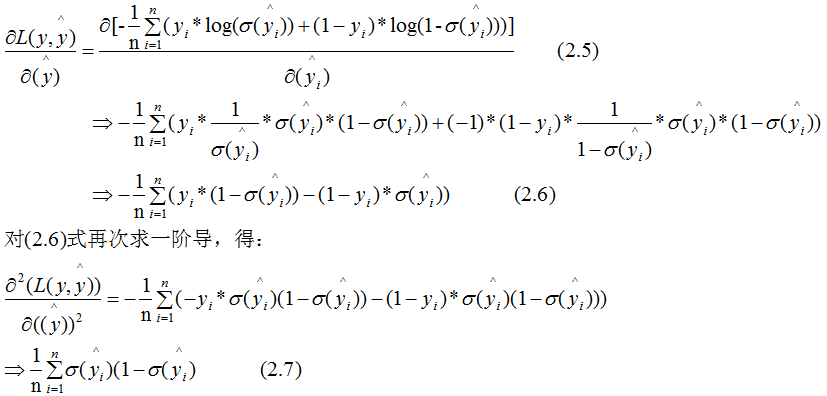來源:機(jī)器學(xué)習(xí)算法那些事本文深入淺出的總結(jié)了Hessian矩陣在XGboost算法中的兩種應(yīng)用,即權(quán)重分位點(diǎn)算法和樣本權(quán)重和算法 。
Hessian矩陣最常見的應(yīng)用是牛頓法最優(yōu)化算法,其主要思想是搜尋一階導(dǎo)數(shù)為0的函數(shù)極值點(diǎn),本文深入淺出的總結(jié)了Hessian矩陣在XGboost算法中的兩種應(yīng)用,即權(quán)重分位點(diǎn)算法和樣本權(quán)重和算法 。
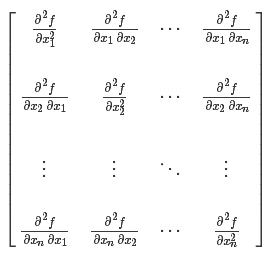
Hessian矩陣(Hessian matrix或Hessian)是一個(gè)自變量為向量的實(shí)值函數(shù)的二階導(dǎo)偏導(dǎo)數(shù)組成的方塊矩陣,此實(shí)值函數(shù)如下:2. 最小葉子節(jié)點(diǎn)樣本權(quán)重和算法官方文檔對(duì)XGBoost算法參數(shù)最小葉子節(jié)點(diǎn)樣本權(quán)重和 (min_child_weitht) 的定義:minimum sum of instance weight (hessian) needed in a child. If the tree partition step results in a leaf node with the sum of instance weight less than min_child_weight, then the building process will give up further partitioning. In linear regression mode, this simply corresponds to minimum number of instances needed to be in each node. The larger, the more conservative the algorithm will be.
翻譯:min_child_weight定義為最小葉子節(jié)點(diǎn)樣本權(quán)重(hessian)和,如果樹分裂步驟產(chǎn)生的葉子節(jié)點(diǎn)上所有樣本權(quán)重和小于min_child_weight,就停止分裂 。在線性回歸的模型中,最小樣本個(gè)數(shù)反映了最小葉子節(jié)點(diǎn)樣本權(quán)重和 。min_child_weight越大,模型越保守,即降低了模型的復(fù)雜度 ,避免過擬合 。
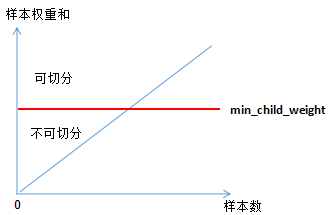
下面討論樹模型和線性模型用hessian表示節(jié)點(diǎn)樣本權(quán)重的含義 。還記得hessian矩陣的定義嗎? hessian是函數(shù)值對(duì)變量的二階導(dǎo),xgboost算法中用損失函數(shù)對(duì)預(yù)測(cè)值的二階導(dǎo)表示hessian,如下:其中,L 表示損失函數(shù),y和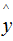 分別表示真實(shí)值和預(yù)測(cè)值 。若某一節(jié)點(diǎn)的樣本數(shù)為n,其損失函數(shù):因此,線性回歸模型中,節(jié)點(diǎn)的樣本數(shù)表示了樣本權(quán)重和 。樹模型中用Hessian表示樣本權(quán)重,決定某一節(jié)點(diǎn)是否切分的條件是比較該節(jié)點(diǎn)的樣本權(quán)重和與min_child_weight的大小,若大于,則切分;反之則不切分(假設(shè)其他條件滿足切分)。為了加深理解,本節(jié)用二分類邏輯回歸舉例:(2.7)式表示節(jié)點(diǎn)所有樣本的權(quán)重和,可以定性的畫出(2.7)式與min_child_weight的關(guān)系:由上圖可知,樣本數(shù)與樣本權(quán)重成正相關(guān)的關(guān)系,因此樹模型的樣本權(quán)重和在一定程度上反映了樣本數(shù) 。(1)、當(dāng)yi為1時(shí),
分別表示真實(shí)值和預(yù)測(cè)值 。若某一節(jié)點(diǎn)的樣本數(shù)為n,其損失函數(shù):因此,線性回歸模型中,節(jié)點(diǎn)的樣本數(shù)表示了樣本權(quán)重和 。樹模型中用Hessian表示樣本權(quán)重,決定某一節(jié)點(diǎn)是否切分的條件是比較該節(jié)點(diǎn)的樣本權(quán)重和與min_child_weight的大小,若大于,則切分;反之則不切分(假設(shè)其他條件滿足切分)。為了加深理解,本節(jié)用二分類邏輯回歸舉例:(2.7)式表示節(jié)點(diǎn)所有樣本的權(quán)重和,可以定性的畫出(2.7)式與min_child_weight的關(guān)系:由上圖可知,樣本數(shù)與樣本權(quán)重成正相關(guān)的關(guān)系,因此樹模型的樣本權(quán)重和在一定程度上反映了樣本數(shù) 。(1)、當(dāng)yi為1時(shí),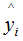 越大,損失函數(shù)越小,(2.7)式越接近于0 。(2)、當(dāng)yi為0時(shí),越小,損失函數(shù)越小,(2.7)式越接近于0 。
越大,損失函數(shù)越小,(2.7)式越接近于0 。(2)、當(dāng)yi為0時(shí),越小,損失函數(shù)越小,(2.7)式越接近于0 。
因此,(2.7)式也可以表示某一節(jié)點(diǎn)的純度(purity),若純度大于 min_child_weight,那么可繼續(xù)對(duì)該節(jié)點(diǎn)切分;純度小于 min_child_weight,則不切分 。
對(duì)損失函數(shù)的二階導(dǎo)值進(jìn)行排序,然后根據(jù)分位點(diǎn)進(jìn)行切分,選擇最佳切分點(diǎn) 。這里不展開了,具體算法請(qǐng)參考XGBoost切分點(diǎn)算法 。XGBoost算法用損失函數(shù)的二階導(dǎo)(Hessian)表示樣本權(quán)重,這一思想在線性回歸模型中反映了節(jié)點(diǎn)的樣本個(gè)數(shù),在樹模型中反映了該節(jié)點(diǎn)的純度 。參考:
https://stats.stackexchange.com/questions/317073/explanation-of-min-child-weight-in-xgboost-algorithm#
編輯:于騰凱