
Presto高性能引擎在美圖的實(shí)踐
01
技術(shù)選型
Presto是一個(gè)Ad-Hoc的ROLAP解決方案。ROLAP的優(yōu)缺點(diǎn)簡單介紹如下:

ROLAP優(yōu)點(diǎn):
ROLAP適合非常靈活的查詢。
ROLAP查詢性能相對(duì)比較高。
ROLAP針對(duì)MPP架構(gòu)支持實(shí)時(shí)數(shù)據(jù)的寫入與實(shí)時(shí)分析。
Presto內(nèi)置支持各種聚合的算子,如sum、count,擅長計(jì)算一些指標(biāo)如PV、UV,適合多維度聚合查詢。
ROLAP缺點(diǎn):
所有計(jì)算和分析都是基于內(nèi)存去完成的,對(duì)內(nèi)存的需求比較大。
線上實(shí)際使用過程中發(fā)現(xiàn),查詢周期相對(duì)比較長時(shí)(如查一年、兩年的數(shù)據(jù)),經(jīng)常會(huì)遇到數(shù)據(jù)量會(huì)過大的問題,會(huì)線性影響查詢性能。
對(duì)比MOLAP由于需要提前做一次預(yù)計(jì)算,Presto則存在一定的性能差距。
MOLAP的典型技術(shù)實(shí)現(xiàn)是Druid和Kylin。兩者均通過做預(yù)計(jì)算,創(chuàng)建對(duì)應(yīng)的cube,來實(shí)現(xiàn)一個(gè)性能上比較快的OLAP方案。但是,這是以犧牲業(yè)務(wù)靈活性為代價(jià)的。相比來說,Presto有更好的靈活性。
我們內(nèi)部調(diào)研了三個(gè)Ad-Hoc的ROLAP技術(shù)組件選型,包括Hive on Spark,Impala和Presto。
1. Hive on Spark

Hive on Spark的優(yōu)點(diǎn),首先是在美圖內(nèi)部廣泛使用,經(jīng)受住了時(shí)間的考驗(yàn)。其次是使用上的靈活性,因?yàn)橐呀?jīng)使用了很多年,相對(duì)比較熟悉,做過較多二次改造,包括源碼增強(qiáng)和一些重點(diǎn)模塊重構(gòu)。
缺點(diǎn)也是顯而易見的,Hive on Spark在查詢一些相對(duì)比較大的任務(wù),容易發(fā)生shuffle、OOM和數(shù)據(jù)傾斜等問題。其次,Hive on Spark和其他競品如Impala和 Presto相比,查詢速度很慢,明顯無法滿足在線查詢的需求。
2. Impala
Impala的優(yōu)點(diǎn),首先是輕量快速,支持近實(shí)時(shí)的查詢。其次,所有計(jì)算均在內(nèi)存中完成,減少了計(jì)算延遲和磁盤IO開銷。
但缺點(diǎn)也比較多,首先是主節(jié)點(diǎn)缺乏高可用的機(jī)制(HA機(jī)制)。其次是零容忍問題,即一個(gè)查詢發(fā)送過來的話,如果其中一個(gè)節(jié)點(diǎn)查詢失敗,會(huì)導(dǎo)致整個(gè)查詢都失敗。再次,我們在使用過程中發(fā)現(xiàn)它對(duì)自定義函數(shù)支持的不是很好。另外,Impala強(qiáng)依賴于CDH的生態(tài),跟我們現(xiàn)有架構(gòu)不能很好的融合。我們現(xiàn)有架構(gòu)使用了一些開源社區(qū)的組件。如果強(qiáng)依賴于CDH, 當(dāng)我們要做版本升級(jí)、補(bǔ)丁升級(jí)或者代碼重構(gòu)后的升級(jí)時(shí),存在過度依賴CDH而操作不友好的問題。最后,就是查詢數(shù)據(jù)量過大的話,會(huì)發(fā)生比較嚴(yán)重的性能下降。此外,還有對(duì)于并發(fā)的支持,不是特別好。
3. Presto
最后來看今天的主角Presto。Presto優(yōu)點(diǎn)首先是輕量快速,支持近乎實(shí)時(shí)查詢。其次,它的社區(qū)活躍度也比較高,文檔也比較完善,基本可以兼容業(yè)務(wù)上所有的SQL,也能扛住比較大的并發(fā)。
當(dāng)然Presto也有一些缺點(diǎn),一是零容忍問題,如果一個(gè)失敗,一個(gè)節(jié)點(diǎn)上的查詢失敗,會(huì)導(dǎo)致整個(gè)查詢的失敗。再就是主節(jié)點(diǎn)缺乏HA的機(jī)制。HA這個(gè)缺點(diǎn),業(yè)界也有方案可以去完善。在下一個(gè)章節(jié),會(huì)分享美圖是如何完善HA機(jī)制的。
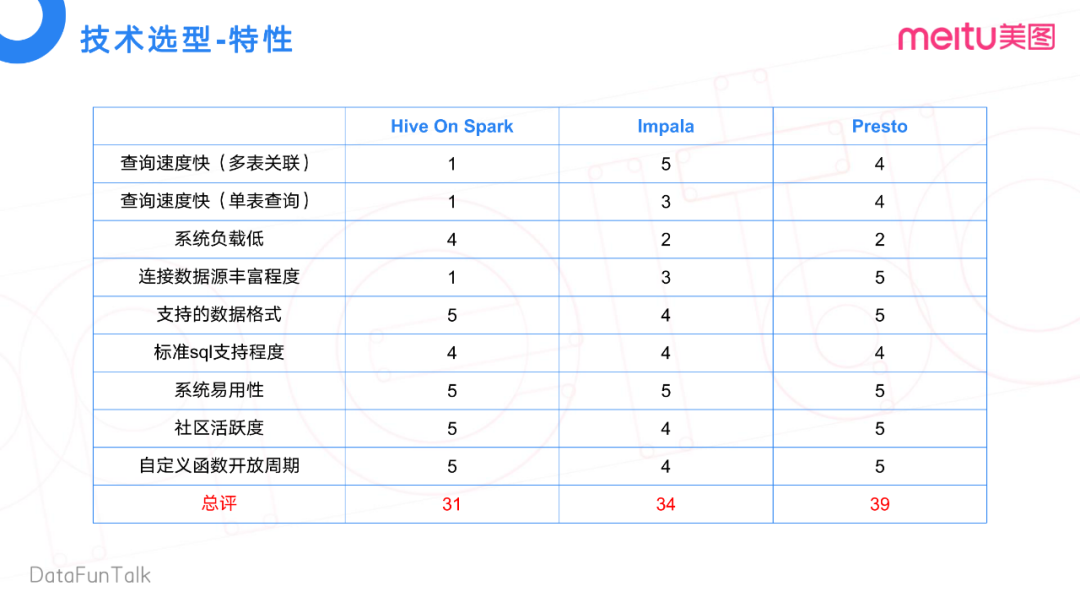
我們通過對(duì)比三個(gè)組件的一些特性,包括多表關(guān)聯(lián)、單表查詢和系統(tǒng)負(fù)載等,得到了一個(gè)打分。分?jǐn)?shù)越高越適合我們的業(yè)務(wù)場景,優(yōu)勢越明顯。表格中可以看到,Presto總計(jì)39分是最高的,最符合我們的業(yè)務(wù)場景。
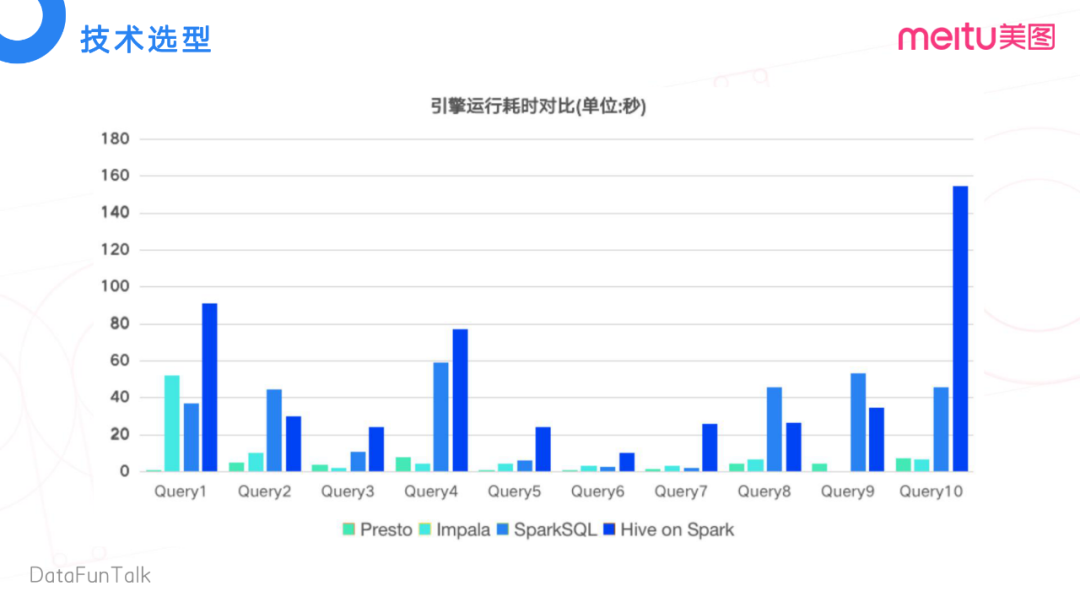
同時(shí)我們也做了計(jì)算性能上的對(duì)比。Presto的性能最好,Impala略微差一些。可能比較細(xì)心的同學(xué)會(huì)發(fā)現(xiàn),在Query 9里面,Impala的結(jié)果是空白的,這是因?yàn)?/span>Impala不兼容Query 9中的語法。這里面我們也對(duì)比了在美圖內(nèi)部用的比較多的Spark SQL,由于上篇文章沒講到Spark SQL,所以這里只做了一個(gè)性能的比較。基于這些維度考慮,我們最終選擇了Presto。
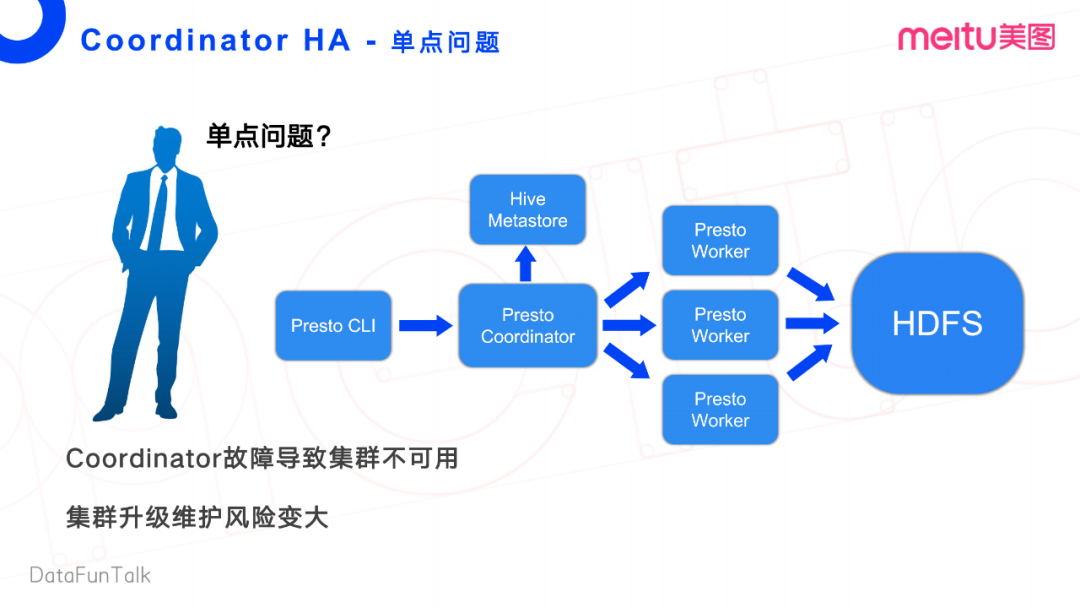
前面提到,Presto有一個(gè)比較致命的缺陷,就是缺乏主節(jié)點(diǎn)的HA高可用性。在這一章節(jié)中,看看我們?nèi)绾稳タ朔屯晟七@個(gè)組件。
首先,我們看一看Presto的整體流程。Presto Client端發(fā)送一個(gè)查詢請(qǐng)求給Presto的Coordinator, Coordinator先去Hive Metastore獲取這個(gè)任務(wù)執(zhí)行過程中所需的一些源數(shù)據(jù)信息,再將任務(wù)轉(zhuǎn)發(fā)給它對(duì)應(yīng)的Worker節(jié)點(diǎn),然后Worker節(jié)點(diǎn)從文件系統(tǒng)里面去拉數(shù)據(jù)做計(jì)算。
這個(gè)流程中,顯而易見致命的缺點(diǎn)是Coordinator的單節(jié)點(diǎn)。Coordinator故障會(huì)導(dǎo)致整個(gè)集群的不可用,會(huì)嚴(yán)重影響線上業(yè)務(wù)。此外,Coordinator對(duì)集群升級(jí)也帶來比較大的風(fēng)險(xiǎn)。
2. 方案
這里面整理了業(yè)界廣泛使用的兩個(gè)方案。
方案一:
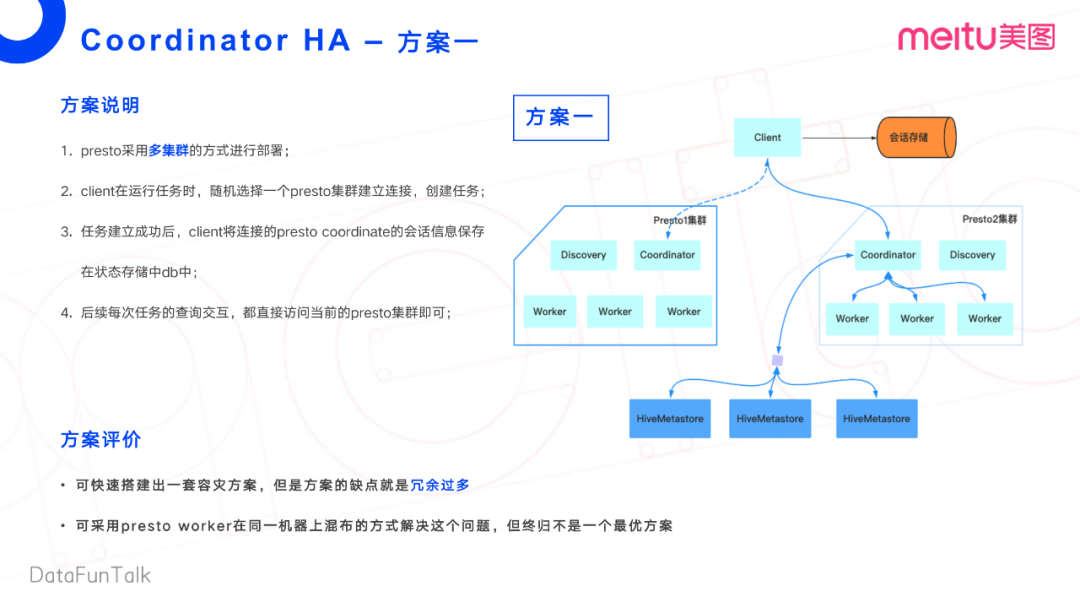
方案一是多集群部署的方式,分為兩個(gè)集群,分別為Presto集群一和Presto集群二。Client端在運(yùn)行任務(wù)時(shí),會(huì)按照一定的規(guī)則去選擇某一個(gè)Presto集群,建立連接,創(chuàng)建任務(wù)。任務(wù)建立完成后,Client端將連接的Presto Coordinator會(huì)話信息保存起來,存儲(chǔ)在DB里面。這樣當(dāng)Presto集群掛掉之后,當(dāng)前會(huì)話會(huì)有一些任務(wù)失敗,在連接到新的集群之后,可以做任務(wù)恢復(fù)。最后,每一次任務(wù)進(jìn)行交互的時(shí)候,都直接訪問當(dāng)前獲取連接的Presto集群即可。
這個(gè)方案本身沒有問題,可以快速的搭建出一套容災(zāi)方案。但是其缺點(diǎn)也是顯而易見的。其實(shí)只需要一套集群,但是做了過多的冗余,用了兩套集群來完成在線查詢的業(yè)務(wù),在成本方面不能接受。當(dāng)然基于這個(gè)方案,也可以在同一個(gè)機(jī)器上做混部,相當(dāng)于一個(gè)機(jī)器多個(gè)Worker實(shí)例。但會(huì)存在管理難度比較大的問題,可能會(huì)涉及到Worker與Worker之間的資源搶占,終歸不是最優(yōu)的方案。
這里稍微點(diǎn)一下,這邊Meta Store有三臺(tái)機(jī)器,是為了實(shí)現(xiàn)高可用。Coordinator接收到任務(wù),會(huì)去獲取任務(wù)的一些源數(shù)據(jù)信息。此時(shí)通過三個(gè)Meta Store進(jìn)行輪詢選擇。當(dāng)一臺(tái)Meta Store掛掉之后,還有兩個(gè)實(shí)例可以用。這個(gè)方案一被pass掉了,因?yàn)椴荒芙邮芩娜哂唷?/span>
方案二:
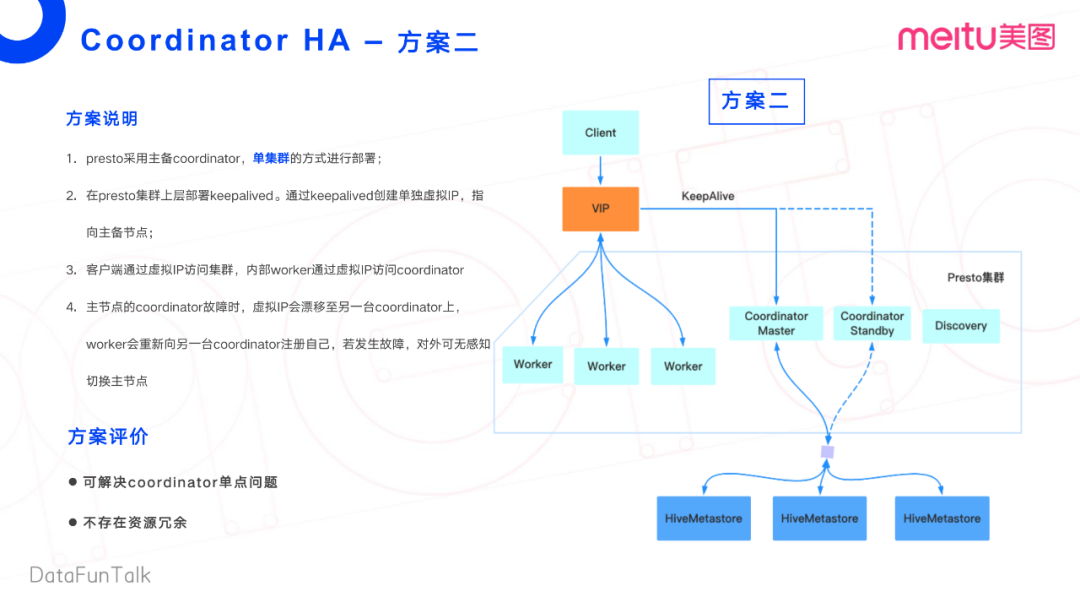
接下來看方案二,Presto采取了一個(gè)主備的Coordinator單集群部署方式。這個(gè)是大規(guī)模集群比較常見的部署方式。
首先,在Presto集群上層部署一個(gè)KeepAlived的第三方服務(wù)。然后通過KeepAlived創(chuàng)建單獨(dú)的虛擬IP(Virtual IP),指向?qū)?yīng)的主備節(jié)點(diǎn)。這樣,客戶端通過虛擬IP訪問集群,內(nèi)部Worker也通過虛擬IP訪問Coordinator節(jié)點(diǎn)。主節(jié)點(diǎn)故障時(shí),KeepAlived通過內(nèi)部的服務(wù)注冊Discovery機(jī)制,注冊到一臺(tái)新的Coordinator上,這樣對(duì)虛擬IP的訪問會(huì)飄移至另外一臺(tái)Coordinator,同樣Worker節(jié)點(diǎn)也會(huì)訪問另外一臺(tái)Coordinator。
總結(jié)來說:如果Coordinator master發(fā)生了故障,可以業(yè)務(wù)無感知的切換到備用Coordinator上。這個(gè)方案可以解決我們Coordinator單點(diǎn)的問題,也不存在任何的資源浪費(fèi)的問題。
3. 實(shí)施步驟
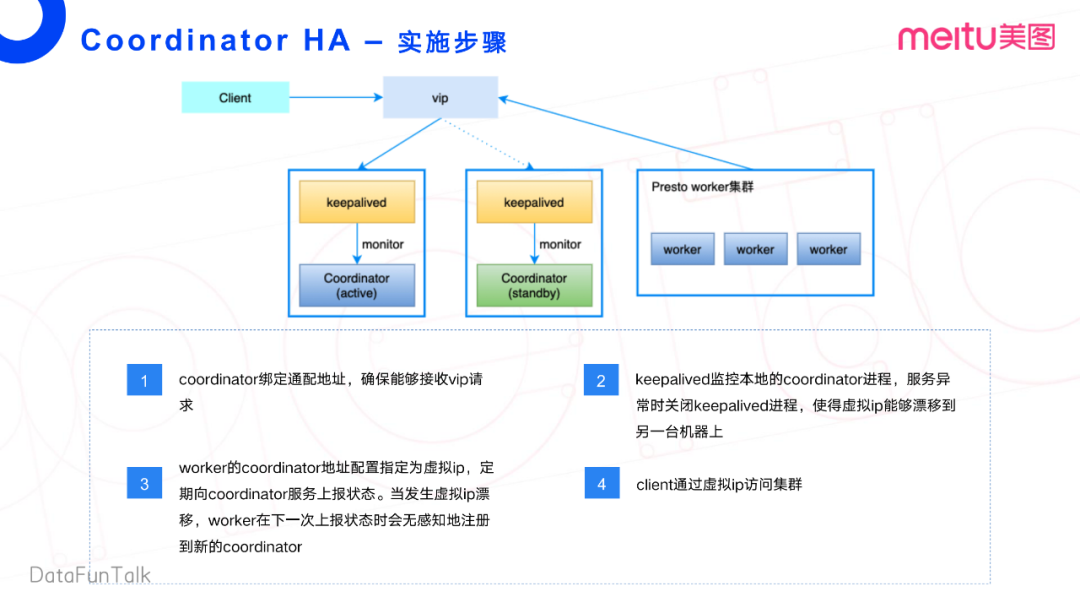
接下來我們再細(xì)細(xì)的看一下方案二的一個(gè)大致的實(shí)施步驟。第一,需要綁定一個(gè)通配地址,也就是類似0.0.0.0這么一個(gè)通配地址,確保能接受VIP的請(qǐng)求。如果是同網(wǎng)段,這樣的IP也可以, 只要他的這個(gè)網(wǎng)絡(luò)環(huán)境是互通的就可以了。
第二點(diǎn)就是使用KeepAlived去監(jiān)控本地的Coordinator進(jìn)程。當(dāng)服務(wù)發(fā)生異常時(shí),去關(guān)閉這個(gè)KeepAlived進(jìn)程,使得這個(gè)VIP可以漂移到另外一臺(tái)機(jī)器上。將Worker的Coordinator地址配置成對(duì)應(yīng)的VIP,然后定期上報(bào)狀態(tài)。其實(shí)再展開一點(diǎn),Worker并不是向真正的Coordinator服務(wù)上報(bào)狀態(tài),而是向Discovery這個(gè)服務(wù)去上報(bào)狀態(tài)。Discovery相當(dāng)于是Coordinator的一個(gè)進(jìn)程。當(dāng)發(fā)生虛擬IP漂移的時(shí)候,Worker會(huì)在下一次上報(bào)狀態(tài)的時(shí)候,無感知的去注冊到新的Coordinator。Client可以繼續(xù)通過VIP去訪問集群。
可能會(huì)有點(diǎn)繞,大家只要記住,Coordinator和Worker都是通過這個(gè)VIP去進(jìn)行關(guān)聯(lián)與信息交互。在網(wǎng)上,這個(gè)方案也相對(duì)比較成熟,具體的代碼和配置都可以找到。
03
跨集群調(diào)度
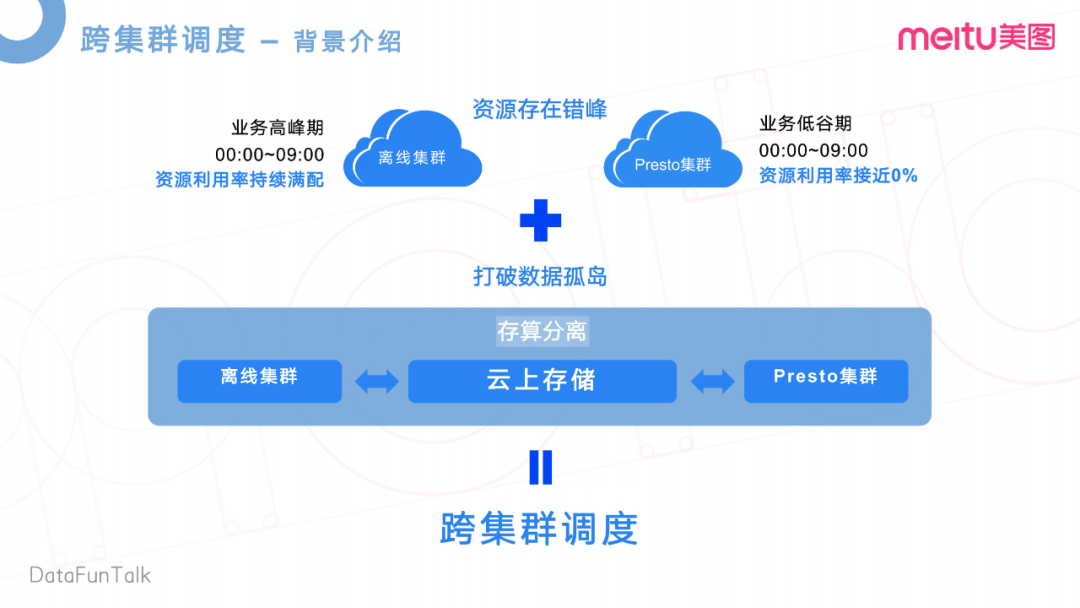
第三部分,我們來介紹一下美圖內(nèi)部跨集群調(diào)度的實(shí)現(xiàn)。這是基于我們的業(yè)務(wù)特性去做的一個(gè)優(yōu)化。我們內(nèi)部有兩套集群,其中一個(gè)為離線集群,主要就是跑一些統(tǒng)計(jì)報(bào)表,離線查詢之類的任務(wù),另一個(gè)是Presto集群。他們存在一個(gè)資源錯(cuò)峰狀態(tài),離線集群業(yè)務(wù)高峰是在凌晨的0點(diǎn)到9點(diǎn),會(huì)將資源利用率持續(xù)打滿。Presto本身是一個(gè)在線查詢的集群,基本上凌晨沒人使用,0點(diǎn)到9點(diǎn)是它的一個(gè)業(yè)務(wù)低谷,資源利用率接近0%。這樣存在一個(gè)資源錯(cuò)峰。我們想把Presto在業(yè)務(wù)低谷的這部分資源利用上。
可能大家會(huì)有個(gè)疑問,傳統(tǒng)的集群部署基本上都是從自己的HDFS去拉取數(shù)據(jù)。如果資源要互通的話,就需要去訪問各個(gè)集群上的文件,才能做下一步的計(jì)算。
2. 架構(gòu)演進(jìn)
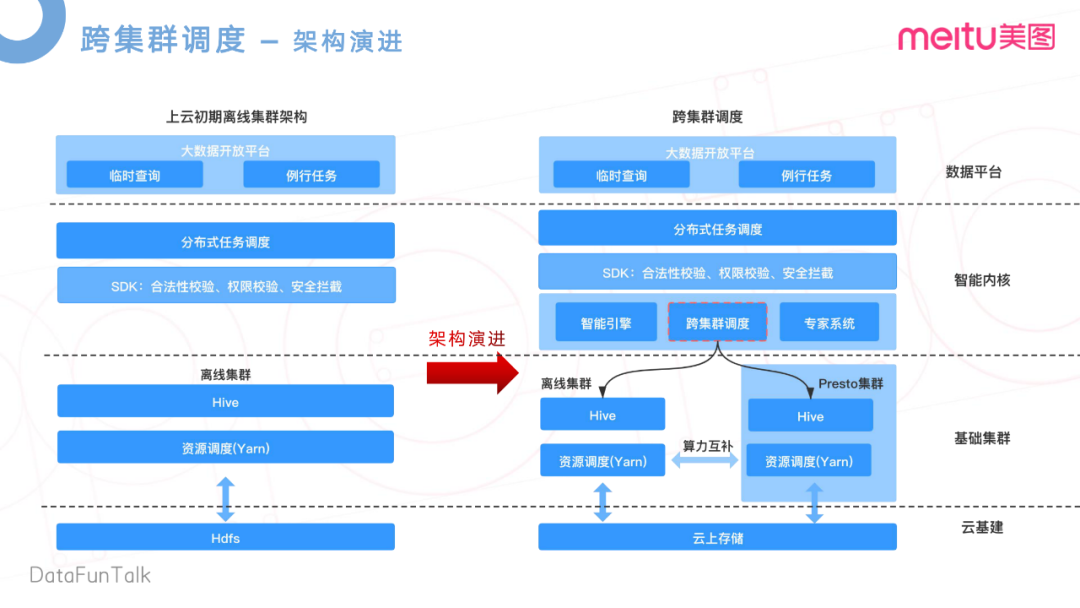
美圖在去年完成了一個(gè)上云的操作,在云上使用了存算分離的架構(gòu),實(shí)現(xiàn)了數(shù)據(jù)的統(tǒng)一存儲(chǔ)。這樣的好處是打破了傳統(tǒng)架構(gòu)的數(shù)據(jù)孤島的問題,離線集群和Presto集群可以無差別的訪問云上的存儲(chǔ),即離線集群可以訪問到Presto集群上的數(shù)據(jù),Presto上的數(shù)據(jù)也可以訪問到離線集群的數(shù)據(jù)。基于這兩點(diǎn),我們就提出了一個(gè)跨集群調(diào)度的概念,去減輕離線集群的高峰負(fù)載,提升Presto集群凌晨業(yè)務(wù)低谷資源使用率。
在上云初期,因?yàn)橛袛?shù)據(jù)孤島,各自集群有各自的HDFS,數(shù)據(jù)沒法互通。如圖所示,這是上云初期架構(gòu)示意圖。在上層,是對(duì)應(yīng)的大數(shù)據(jù)開放平臺(tái),做一些臨時(shí)查詢,和一些例行任務(wù)。在下一層,是自研的一個(gè)分布式調(diào)度系統(tǒng),主要是做任務(wù)的一些日常調(diào)度。再下來,我們開發(fā)了一個(gè)檢驗(yàn)層,做一些合法性的校驗(yàn)。任務(wù)合法性,是指這個(gè)任務(wù)所攜帶的參數(shù)和語法,是否合法等。在這里還做了統(tǒng)一的權(quán)限校驗(yàn)等數(shù)據(jù)安全的攔截。這些校驗(yàn)完成之后,才會(huì)轉(zhuǎn)發(fā)給離線集群,通過Yarn去做資源調(diào)度,以及跟HDFS的交互。
3. 轉(zhuǎn)發(fā)策略
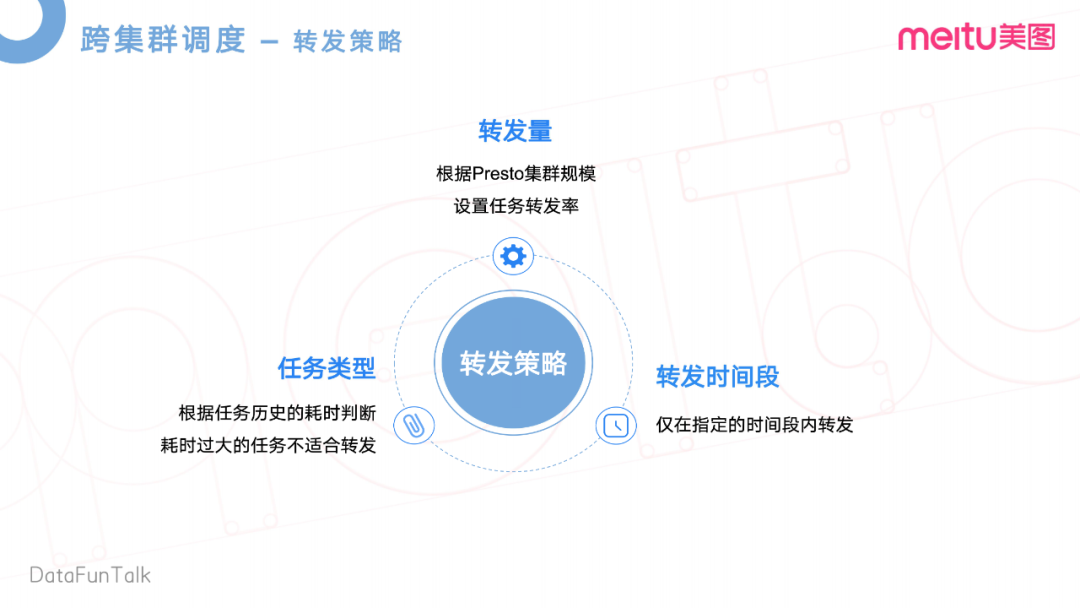
在實(shí)現(xiàn)跨區(qū)域調(diào)度之后,團(tuán)隊(duì)內(nèi)部研發(fā)了一個(gè)智能內(nèi)核。智能內(nèi)核其實(shí)里面有三個(gè)比較核心的東西,一個(gè)是智能引擎,也就是和團(tuán)隊(duì)現(xiàn)在一起在做的事情。跨集群調(diào)度就是通過這個(gè)任務(wù)根據(jù)評(píng)估離線集群和Presto集群的一個(gè)業(yè)務(wù)集群負(fù)載,去轉(zhuǎn)發(fā)到各自的集群,去分擔(dān)各自的集群壓力,或者說提升一個(gè)資源的利用率。這邊也實(shí)現(xiàn)了一個(gè)算力互補(bǔ)的這么一個(gè)東西,當(dāng)然最底層是通過我們的云基建,云上存儲(chǔ)進(jìn)行實(shí)現(xiàn)的。當(dāng)然我們在評(píng)估這個(gè)轉(zhuǎn)發(fā),就是什么樣的任務(wù)可以去轉(zhuǎn)發(fā)到Presto上呢,我們也做了一些簡單的轉(zhuǎn)發(fā)策略,比如說轉(zhuǎn)發(fā)量上,我們會(huì)根據(jù)Presto集群規(guī)模,去設(shè)置一些離線任務(wù)的轉(zhuǎn)發(fā)率。
再就是轉(zhuǎn)發(fā)的時(shí)間段,需要在指定的時(shí)間段內(nèi)轉(zhuǎn)發(fā)。因?yàn)闃I(yè)務(wù)低峰是0點(diǎn)到9點(diǎn),那么在9點(diǎn)之后,分析師同學(xué)已經(jīng)上班了,可以開始去做一些在線查詢的一些操作。那不能影響他們的業(yè)務(wù),所以我們需要規(guī)定一個(gè)轉(zhuǎn)發(fā)時(shí)間段。還有一些任務(wù)的類型,需要判斷歷史任務(wù)的一些耗時(shí),若耗時(shí)比較大的任務(wù),就不適合做這個(gè)轉(zhuǎn)發(fā)。
4. 實(shí)施步驟
具體的實(shí)施步驟跟大家簡單的看一下。
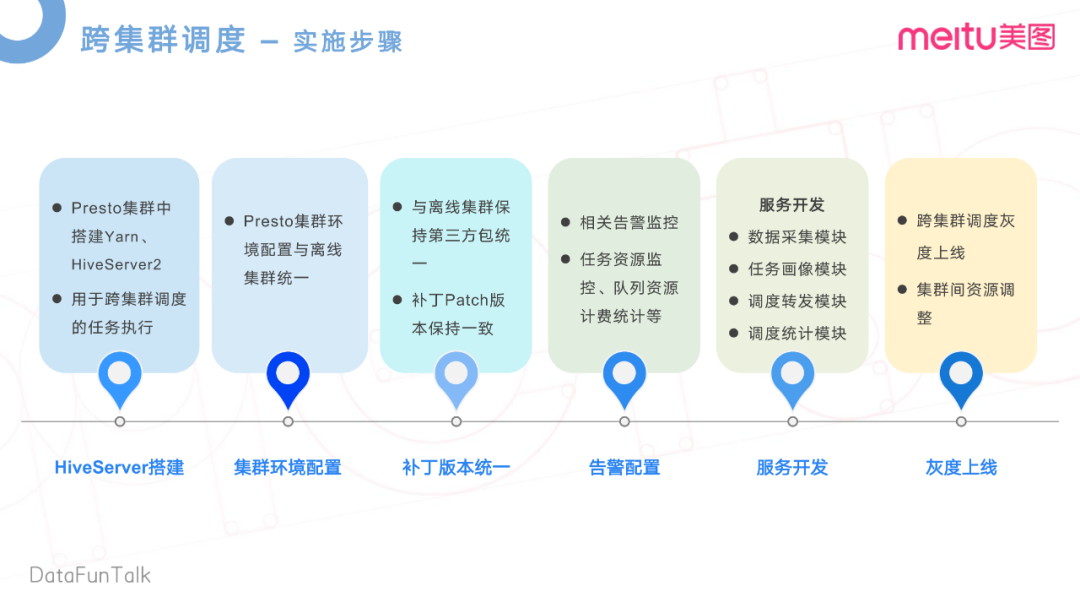
首先是Hive Server服務(wù)的搭建。在離線集群上,我們用了Hive on Spark。了解過Hive on Spark的同學(xué)呢,就知道他們其實(shí)是通過Hive Server進(jìn)行任務(wù)接收的。我們在Presto集群內(nèi)去搭建和部署自己的Yarn和Hive Server環(huán)境,主要是用于跨區(qū)域調(diào)度的任務(wù)、接受和執(zhí)行等。再就是,因?yàn)镠ive集群的這個(gè)任務(wù)要轉(zhuǎn)發(fā)至Presto集群上運(yùn)行,所以離線集群的配置也要和Presto集群做一些統(tǒng)一。
其次是用到的一些第三方包,還有一些補(bǔ)丁。在內(nèi)部團(tuán)隊(duì)也做了比較多的代碼重構(gòu)。需要去將這些代碼去Merge到Presto的集群上,做好補(bǔ)丁的統(tǒng)一,還有相關(guān)告警配置,隊(duì)列資源計(jì)費(fèi)統(tǒng)計(jì)。再就是一些服務(wù)開發(fā),這個(gè)服務(wù)開發(fā)主要就是用于我們的專家系統(tǒng),還有智能引擎的一些服務(wù)模塊,最后就是灰度上線。
當(dāng)前面的這些環(huán)境全部都做好之后,開始灰度,灰度覆蓋率由小到大做任務(wù)的轉(zhuǎn)發(fā)。可以看一下這個(gè)收益分析。離線集群的資源在夜間它的消耗降低了10%,因?yàn)榧洪g已經(jīng)實(shí)現(xiàn)了算力互補(bǔ),可以將離線集群的一部分機(jī)器去遷移至Presto集群上,那也相當(dāng)于對(duì)Presto做一個(gè)擴(kuò)容。這樣Presto的集群性能也提高了19%。
04
展望未來
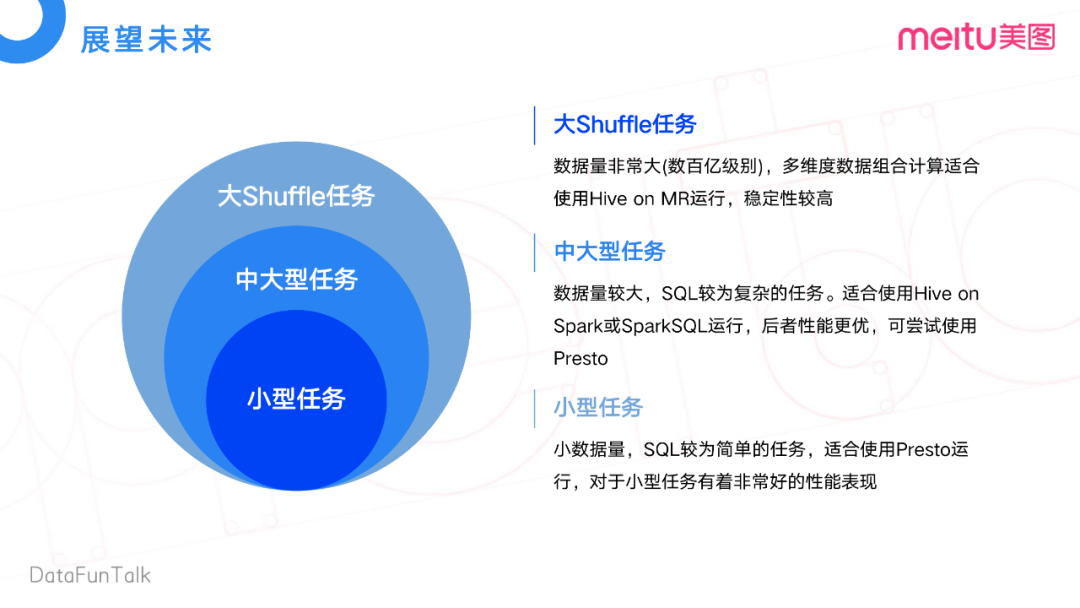
最后,我們對(duì)未來進(jìn)行一個(gè)展望。在大數(shù)據(jù)場景下,根據(jù)任務(wù)屬性的不同可以分為三類任務(wù):大shuffle任務(wù),中大型任務(wù)和小型任務(wù)。
大shuffle任務(wù)數(shù)據(jù)量非常大,查詢級(jí)別在數(shù)百億,還有比如說做多維度的cube構(gòu)建,或者grouping set類似這樣的操作,比較適合Hive on Spark運(yùn)行。因?yàn)镠ive on Spark是基于磁盤進(jìn)行計(jì)算,穩(wěn)定性相對(duì)高。
中大型任務(wù)的數(shù)據(jù)量相對(duì)比較大,SQL語句也比較復(fù)雜,比較適合Hive on Spark或者Spark SQL。在日常使用中,我們發(fā)現(xiàn)Spark on SQL的性能明顯優(yōu)于Hive on Spark。但是,對(duì)于在這部分中大型任務(wù),團(tuán)隊(duì)內(nèi)正在嘗試使用Presto來解決時(shí)效性或者運(yùn)行時(shí)間問題。
小型任務(wù)的數(shù)據(jù)量比較小,SQL也比較簡單,非常適合Presto去做。Presto對(duì)小型任務(wù)也有比較好的性能表現(xiàn)。
用一句話來總結(jié):對(duì)于中大型任務(wù)和小型任務(wù),會(huì)將原來的Hive on Spark或者Spark SQL的運(yùn)行方式,逐步切換到Presto上,來達(dá)到性能提升的目的。
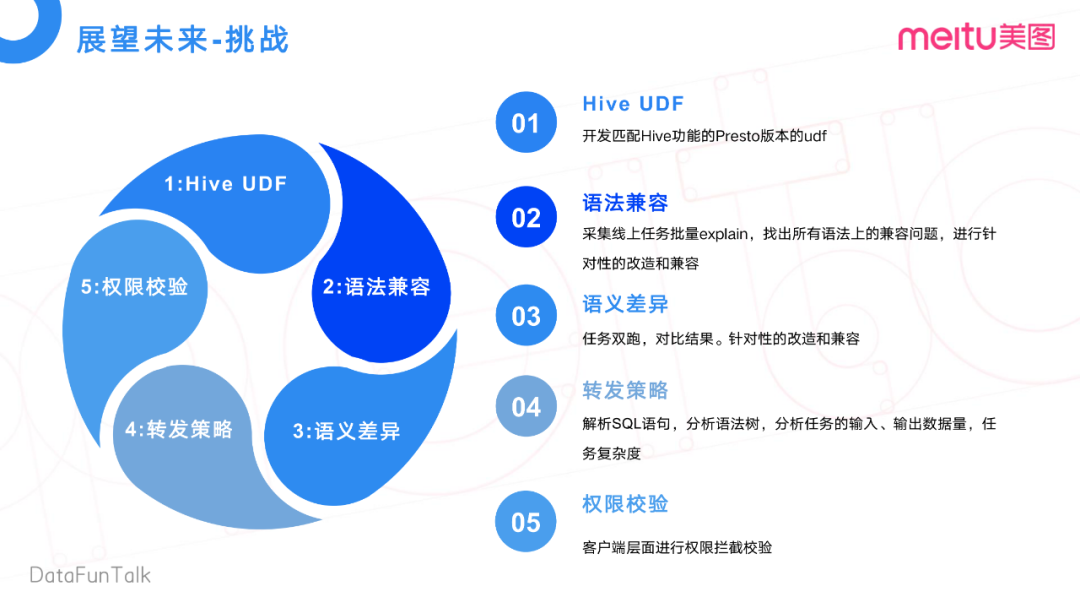
目前的架構(gòu)也遇到了一些挑戰(zhàn):
比如,在離線統(tǒng)計(jì)Hive集群上,有些UDF有一些語法兼容的問題,還有一些語義差異。
比如某個(gè)任務(wù),在離線集群上用了一個(gè)Hive UDF,在Presto上也要實(shí)現(xiàn)對(duì)應(yīng)的UDF。現(xiàn)在這個(gè)完全是靠人力去開發(fā)對(duì)應(yīng)的UDF。當(dāng)然,后面也在想一些更好的方式,如何去快速的適配Hive上已有的UDF。
再就是一些語法上的兼容,比如說Hive語法在Presto上去跑,它不一定能兼容。那么我們會(huì)去采集線上所有的任務(wù),去做一個(gè)提前的預(yù)編譯,去找出語法上的一個(gè)兼容性問題,然后針對(duì)性的有選擇的去做一些改造和兼容。為什么是有選擇性呢?我們不一定會(huì)將線上所有任務(wù)都都扔到Presto上,只是有選擇性把一些中小任務(wù)放Presto上執(zhí)行。
還有就是語義的差異,我們會(huì)用Hive和Presto兩個(gè)引擎執(zhí)行,然后對(duì)比結(jié)果,針對(duì)性的做一些改造的兼容。再就是轉(zhuǎn)發(fā)策略,什么樣的任務(wù)能夠轉(zhuǎn)發(fā)到Presto上呢?我們會(huì)分析它的一個(gè)SQL語句,包括一些語法樹的分析,還有任務(wù)的輸入輸出,任務(wù)復(fù)雜度的一些分析。
最后一點(diǎn),是權(quán)限校驗(yàn)。我們會(huì)在客戶端層做一個(gè)基于多引擎級(jí)別的統(tǒng)一權(quán)限校驗(yàn)。
Q:是否考慮過使用Doris來對(duì)接Hive,性能相比Presto會(huì)快。
A:Doris暫時(shí)沒有考慮,我們有在做ClickHouse。ClickHouse在我們內(nèi)部慢慢做起來了之后,隨著業(yè)務(wù)的接入,框架的相對(duì)比較成熟之后,也會(huì)考慮將ClickHouse接入到多引擎的這個(gè)架構(gòu)里面。所以說Doris我們現(xiàn)在沒有用。
Q:Presto在查詢大數(shù)據(jù)性能和Hive on Mapreduce差的很多嗎?可以對(duì)比一下嗎?
A:Presto在查詢中小型任務(wù)性能遠(yuǎn)遠(yuǎn)好于Hive on Mapreduce,但如果查詢大任務(wù)的話就不一定了,因?yàn)镻resto主要基于內(nèi)存上的計(jì)算。在線上其實(shí)也發(fā)現(xiàn),如果一個(gè)任務(wù)查詢的時(shí)間周期比較長的話,拉取數(shù)據(jù)的量級(jí)也比較大,計(jì)算復(fù)雜度高。任務(wù)很可能會(huì)失敗,甚至?xí)峡逭麄€(gè)集群。所以我們會(huì)在客戶端做一定的攔截去保護(hù),相當(dāng)于一定的熔斷機(jī)制,就不讓這樣的任務(wù)發(fā)到Presto集群內(nèi)部。所以若一個(gè)非常大的查詢的話,我還是比較建議將這樣的任務(wù)去轉(zhuǎn)發(fā)到Hive on MR或者說Hive on Spark這樣的引擎上。中小型任務(wù)可以嘗試在Presto引擎上執(zhí)行。
Q:更進(jìn)一步了解智能引擎是如何工作的?
A:智能引擎一個(gè)核心的概念,就是會(huì)對(duì)歷史的一些做一些分析,得到任務(wù)畫像系統(tǒng)。當(dāng)任務(wù)下一次任務(wù)再運(yùn)行后,會(huì)根據(jù)這個(gè)畫像系統(tǒng)里面的存儲(chǔ)的一些任務(wù)metric信息,去指定給我們下層的最適合的引擎,就是相當(dāng)于最適合的任務(wù)交給最適合的引擎執(zhí)行。例如我們有MapReduce,Hive on Spark, Spark SQL引擎還有包括說后面會(huì)繼續(xù)引入的Presto,那么什么樣的任務(wù)適合什么樣的引擎執(zhí)行,這正是智能引擎做的事。