
Presto在B站的實踐
1
架構(gòu)
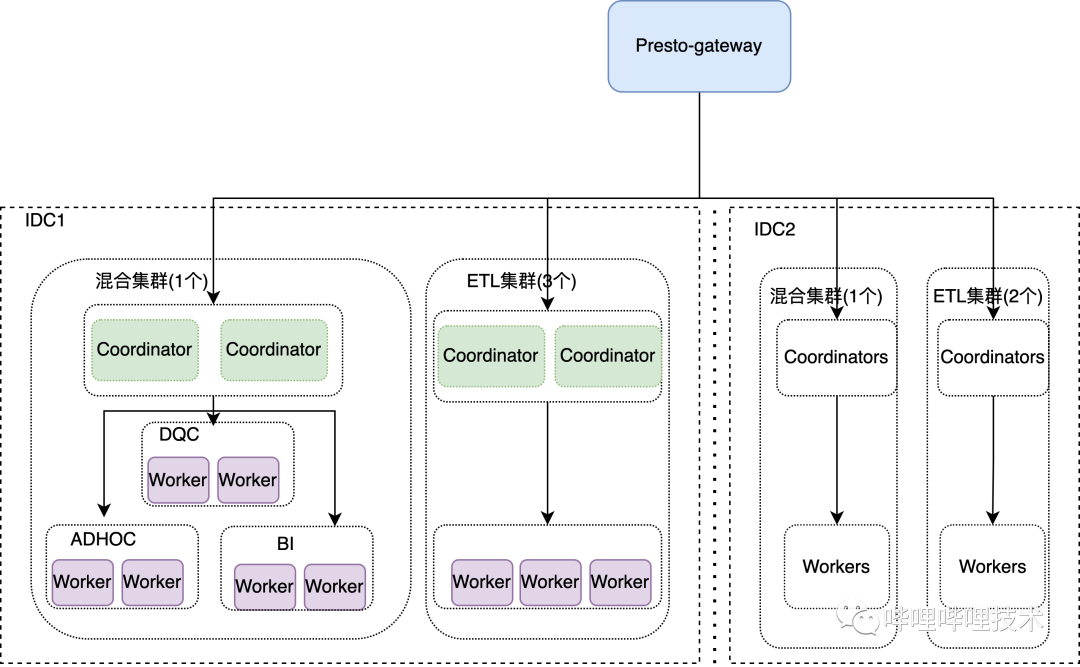
1.1 B站SQL On Hadoop 整體架構(gòu)
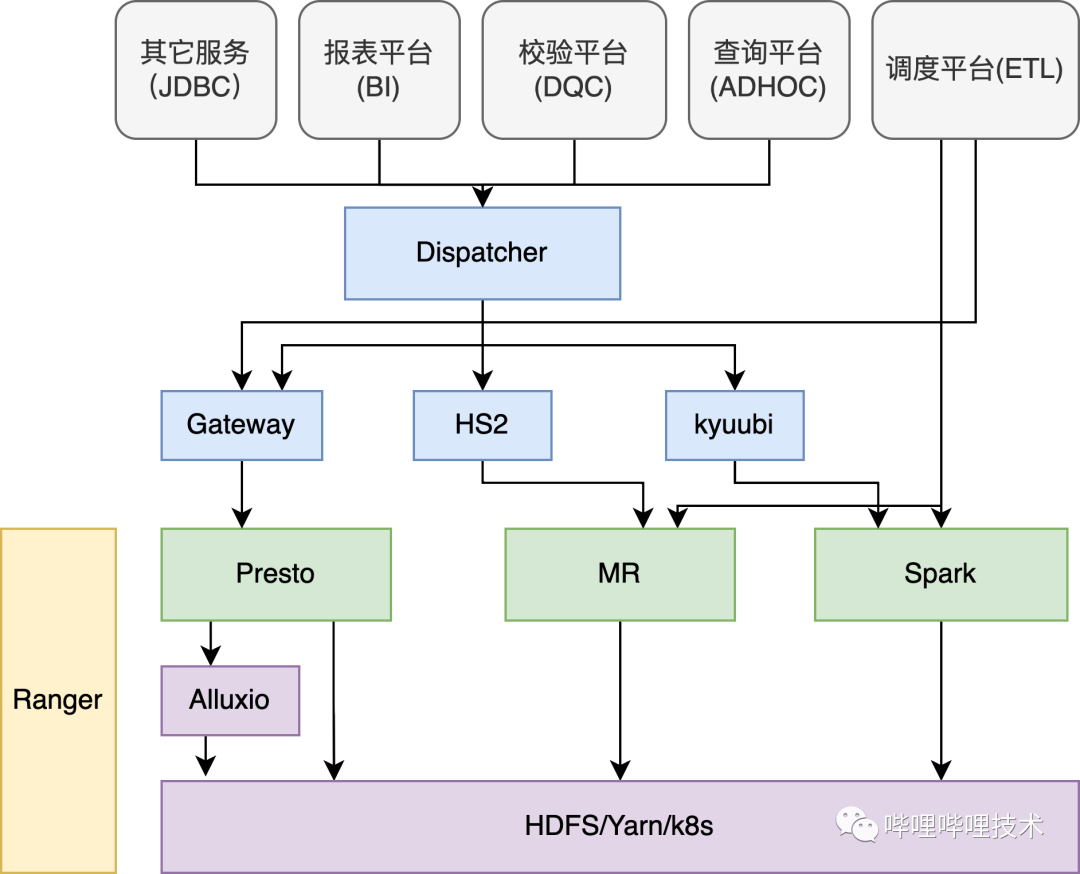
在介紹Presto在B站的實踐之前,先從整體來看看SQL在B站的使用情況,在B站的離線平臺,核心由三大計算引擎Presto、Spark、Hive以及分布式存儲系統(tǒng)HDFS和調(diào)度系統(tǒng)Yarn組成。
如下架構(gòu)圖所示,我們的ADHOC、BI、DQC以及數(shù)據(jù)探查等服務(wù)都是通過自研的Dispatcher路由服務(wù)來進行統(tǒng)一SQL調(diào)度,Dispatcher會結(jié)合查詢語句的語法特征,庫表讀HDFS的數(shù)據(jù)量以及引擎的負載情況等因素動態(tài)決定選擇最合適的計算引擎執(zhí)行,如果是Hive的語法需要用Presto執(zhí)行的,目前利用Linkedin開源的coral對語句進行轉(zhuǎn)化,如果執(zhí)行的SQL失敗了會做引擎自動降級,降低用戶使用門檻;調(diào)度平臺支持Spark、Hive、Presto cli的方式提交ETL作業(yè)到Y(jié)arn進行調(diào)度;Presto gateway服務(wù)負責對Presto進行多集群管理和路由;我們通過Kyuubi來提供多租戶能力,對不同部門管理各自的Spark Engine,提供adhoc查詢;目前各大引擎Hive、Spark、Presto以及HDFS都接入了Ranger來進行權(quán)限認證,HDFS通過路徑來控制權(quán)限,計算引擎通過庫/表來控制權(quán)限,并且我們通過一套Policy來實現(xiàn)表, column masking和row filter的權(quán)限控制;部分組件比如Presto、Alluxio、Kyuubi、Presto Gateway、Dispatcher, 包括混部Yarn集群都已經(jīng)通過公司k8s平臺統(tǒng)一部署調(diào)度。
1.2 Query查詢情況
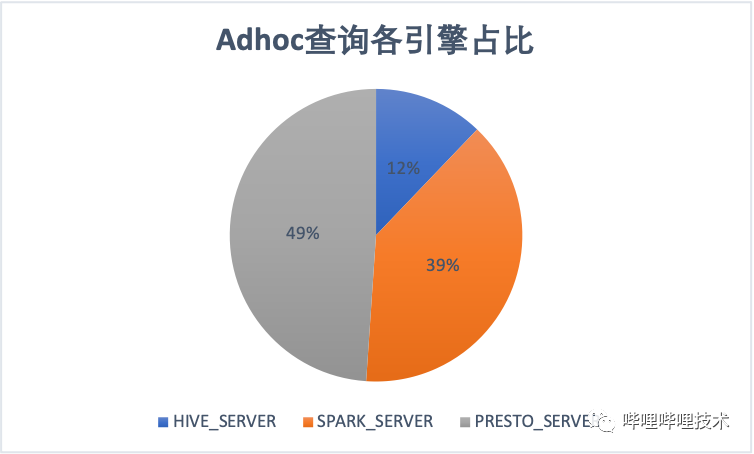
目前在Adhoc查詢場景,Presto引擎占比接近一半。ETL常見主要還是Spark和Hive,隨著我們不斷的對Hive作業(yè)遷移到spark,ETL作業(yè)spark占比達到64%。
2
Presto應用
Presto是由facebook 開源的分布式的MPP(Massive Parallel Processing)架構(gòu)的SQL查詢引擎。基于全內(nèi)存計算(部分算子數(shù)據(jù)也可通過session 配置spill到本地磁盤),并且采用流式pipeline的方式處理數(shù)據(jù)使其能夠節(jié)省內(nèi)存的同時,更快的響應查詢。
相對Hive、Spark引擎,Presto存在不少優(yōu)勢:
1. shuffle數(shù)據(jù)不落地
2.流式任務(wù)執(zhí)行而不是按stage級別執(zhí)行
3.split為線程級別的調(diào)度
4.數(shù)據(jù)源插件化
這使Presto 特別適合交互式跨源數(shù)據(jù)查詢,Presto也并不是完美的,比如因為其流式pipeline執(zhí)行方式的設(shè)計,使其喪失了task級別的recovery機制,所以Presto目前不是特別適合用來做大規(guī)模的ETL查詢,當然目前社區(qū)也在通過對presto進行各種優(yōu)化來使其適應更大規(guī)模的查詢,比如Presto Ulimited和Presto on Spark項目。
2.1 使用場景
在B站,Presto主要承擔了ADHOC查詢、BI查詢、DQC(數(shù)據(jù)校驗,包括跨數(shù)據(jù)源校驗)、AI ETL作業(yè)、數(shù)據(jù)探查等場景.
2.2 集群規(guī)模
目前Presto總共7個集群,分布在2個機房,最大單集群節(jié)點400+,總節(jié)點數(shù)在1000+。
2.3 業(yè)務(wù)增長
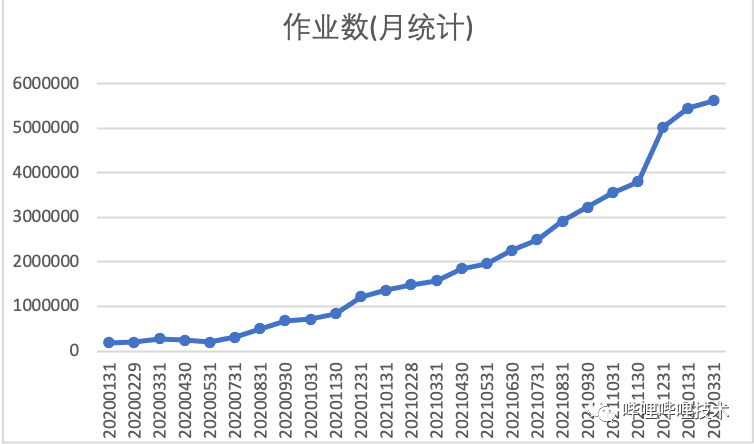
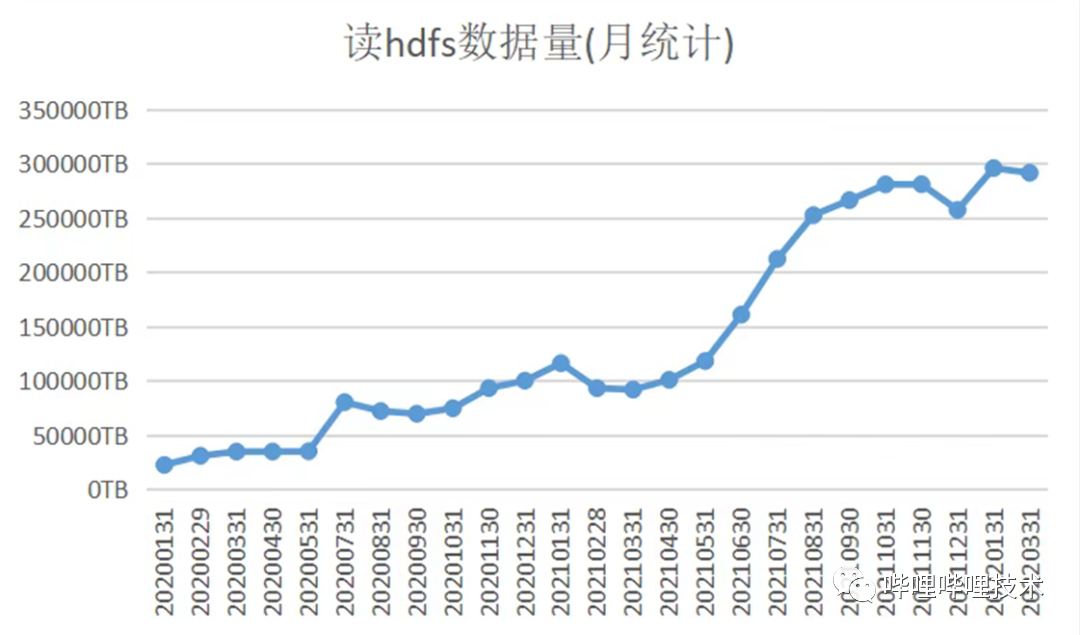
目前我們集群每日查詢數(shù)16w左右,每日查詢HDFS數(shù)據(jù)量10PB左右,目前相比2020年初日查詢數(shù)增長10倍。
2.4 Presto架構(gòu)
目前我們是基于PrestoSQL-330(現(xiàn)在改名叫Trino)版本進行二次開發(fā)和優(yōu)化的,我們所有集群接入到公司Caster發(fā)布系統(tǒng),由k8s進行調(diào)度管理,包括jmx的采集、監(jiān)控dashboard、告警,極大的簡化了我們運維的成本。整體架構(gòu)如下圖:
目前我們所有的presto查詢,包括Cli、JDBC、PyHive都是直接提交到Presto-gateway,由gateway來負責路由。
gateway改造:
1. 支持多coordinator調(diào)度,相同query只能調(diào)度到一個集群的一個coordinator。
2. 探測coordinator的狀態(tài),如果不Active,則踢出調(diào)度列表,給無損發(fā)布提供可能。
3. 支持按用戶/作業(yè)ID來選擇機房調(diào)度,同時我們還會對Query通過Parser解析依賴的表和分區(qū),根據(jù)哪個機房流量讀取大,將Query調(diào)度到哪個集群。
4. 探測coordinator的負載,主要包括內(nèi)存、作業(yè)是否堵住,支持跨集群負載均衡調(diào)度。
5. 提取了Query特征,相同特征Query提交我們會有一系列攔截措施。
presto改造:
1. coordinator支持多活,解決了coordinator的單點問題。
2. coordinator支持按業(yè)務(wù)來進行調(diào)度,不同業(yè)務(wù)調(diào)度到不同的Worker節(jié)點,同時為了增加集群利用率,我們支持按時間跨Label調(diào)度, 比如凌晨為adhoc和bi查詢的低峰,但卻為dqc的高峰,這個時候dqc能夠跨Label使用其他Label的計算資源。
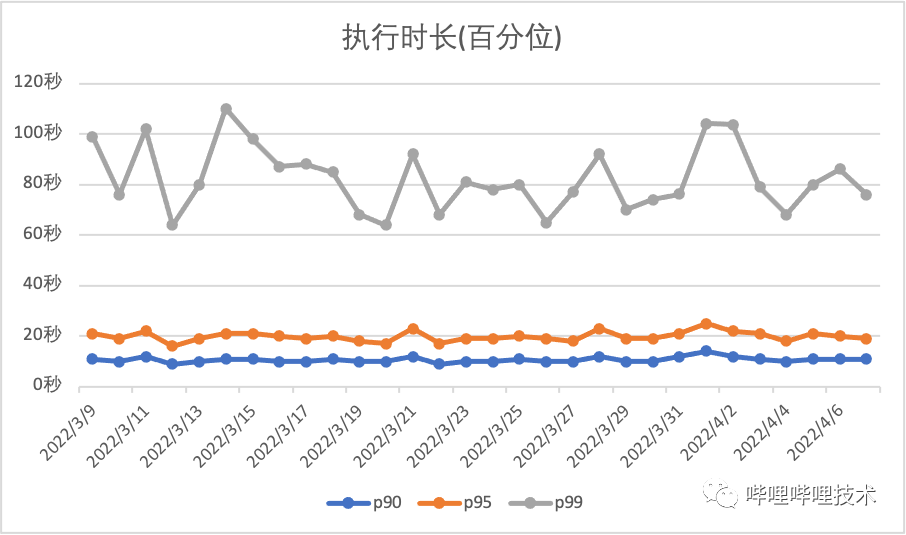
2.5 集群執(zhí)行情況
目前adhoc集群執(zhí)行百分位如下圖所示:
3
穩(wěn)定性改進
3.1 Coordinator多活改造
Presto 是典型的主從架構(gòu),Coordinator作為主節(jié)點,其存在單點問題,當主節(jié)點掛了之后,整個集群不能對外提供服務(wù),為了增加集群的穩(wěn)定性和可靠性,我們對Presto服務(wù)發(fā)現(xiàn)以及資源全局化做了改造,使coordinator可以支持橫向擴展。架構(gòu)圖如下:
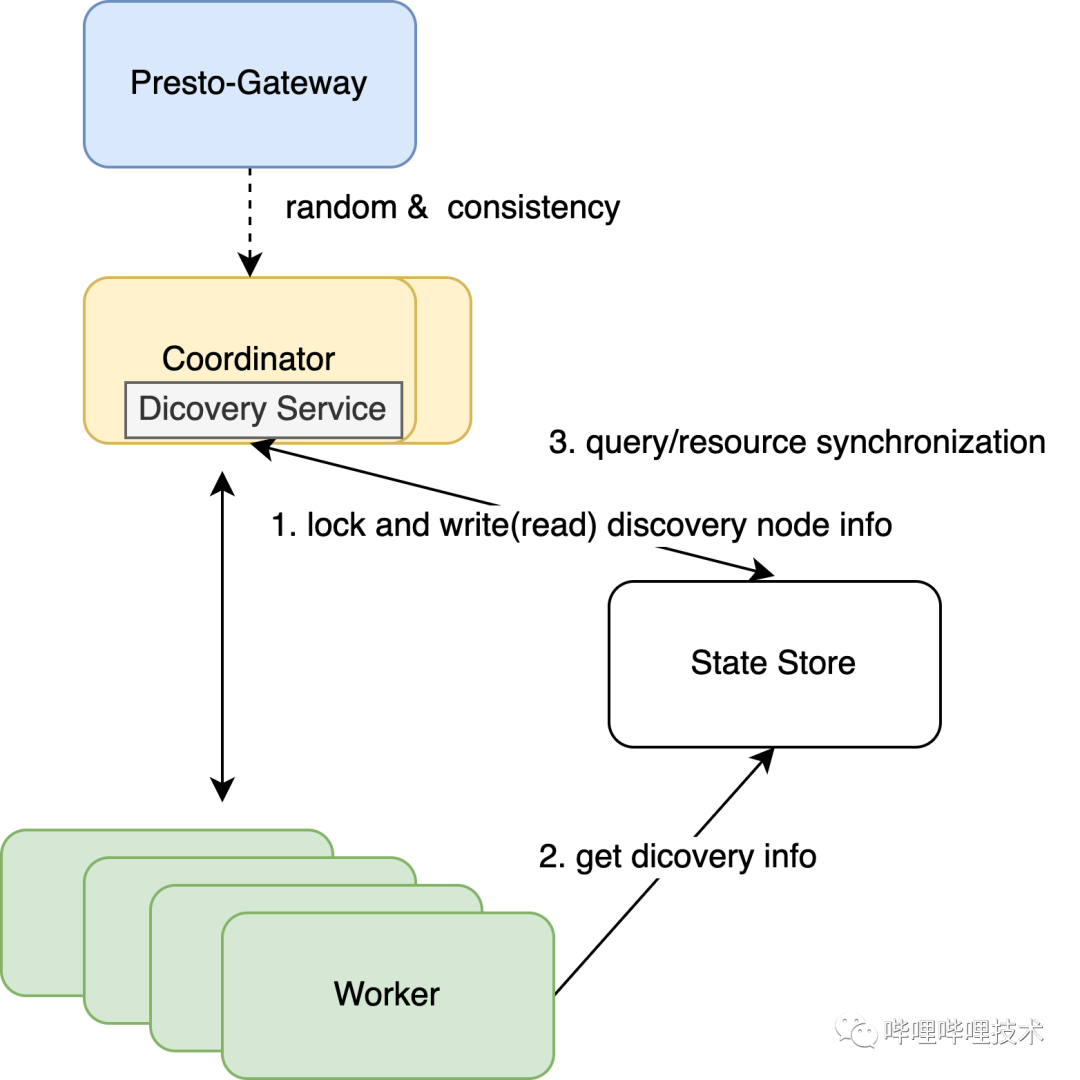
1. 因為Coordinator雖然能夠支持橫向擴展,但是它并不是無狀態(tài)化的,所以我們對gateway進行了改造,一條query提交過來之后,針對這個集群,如果是多活,則隨機選擇一個coordinator,并且將該query和coordinator的mapping保持到redis,之后該query的所有請求都會保持一致。
2.coordinator啟動的時候會通過加全局鎖的方式,嘗試將自己節(jié)點ip和端口寫入State Store服務(wù),然后啟動DiscoveryServer服務(wù)。
3.各節(jié)點的ServiceInventory獲取上述寫入到State Store中的節(jié)點信息來作為Discovery Service,所有節(jié)點都會向該地址發(fā)送announce,DiscoveryServer會進行保存,然后DiscoveryNodeManager通過GET請求到‘/v1/service‘便能拿到所有節(jié)點信息。
4.為了保持多Coordinator具有整個集群的全局資源信息,每個Coordinator會將自己的query和resource group的信息寫入State Store,同時會從State Store中不斷的讀取并更新自己節(jié)點上的資源信息,這能保證各個Coordinator都有全局的資源使用情況,避免了過度調(diào)度導致集群負載過高而不穩(wěn)定。
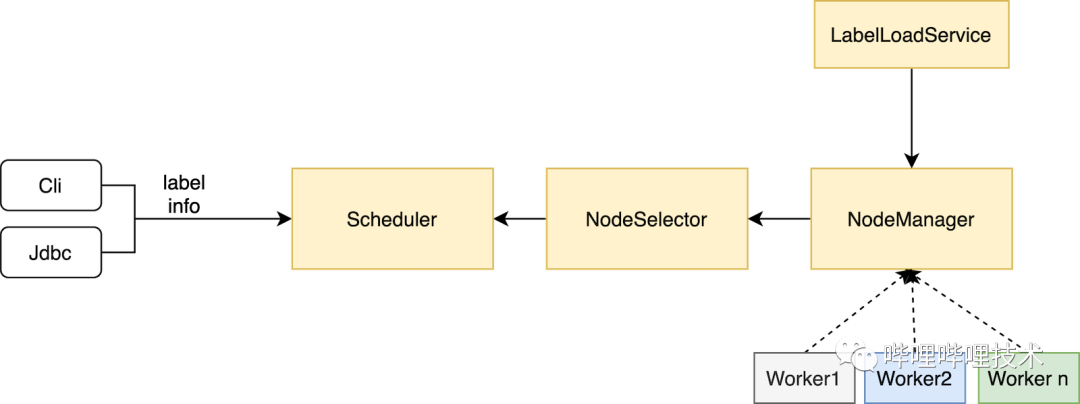
3.2 Label改造
大家都知道,Presto 在資源隔離方面做的并不好,coordinator的resource group 只能在用戶提交查詢的時候進行限制,比如超過query數(shù),內(nèi)存使用超過比例,cpu使用超過quota則新提交的查詢會進到queued隊列中,worker端雖然有MultilevelSplitQueue 來對運行時間長的task進行調(diào)度限制,但是并不能做到很好的資源隔離。
在經(jīng)過多次因adhoc大查詢影響報表查詢之后,同時又不想拆分集群(運維成本增加),所以我們對presto進行了改造,改造思路比較簡單:
1.開發(fā)一個服務(wù),負責將已經(jīng)劃好label的配置文件load進內(nèi)存,并實時檢測文件是否更新,如有更新重新load。
2.DiscoveryNodeManager 通過服務(wù)發(fā)現(xiàn)拿到所有Node之后,將label信息寫進InternalNode中。
3.NodeSelector 構(gòu)建NodeMap的時候也就有了節(jié)點label信息了。
4.客戶端根據(jù)不同業(yè)務(wù)將label信息傳遞到coordinator,調(diào)度的時候根據(jù)label去get到相應的節(jié)點即可。
3.3 實時懲罰
Label的改造能隔離業(yè)務(wù)之間互相影響,但是并不能解決相同業(yè)務(wù)Label下受大查詢的影響,另外社區(qū)版本的cpu/內(nèi)存限制只能限制新提交的語句,已經(jīng)在執(zhí)行的語句會不受cpu/內(nèi)存限制,所以我們開發(fā)了一套實時懲罰的機制。
架構(gòu)圖如下,通過實時收集到各個query的cpu使用情況,基于resource group配置的cpu quota信息,對超過quota的resource group,直接向所有worker節(jié)點下發(fā)懲罰消息,worker收到消息后,會停止對該resource group的task進行調(diào)度,等到該resource group使用資源低于quota后,再通知worker重新對task進行調(diào)度執(zhí)行。
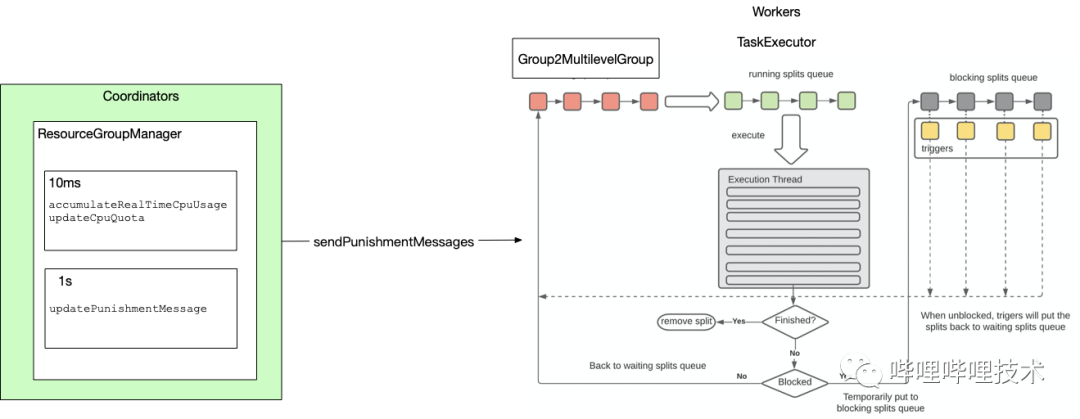
目前的使用場景是,ETL集群如果有大量大查詢同時提交,就會出現(xiàn)集群不穩(wěn)定,比如某個worker被打掛,針對大查詢,presto gateway會在第二次提交到集群后,自動路由到slow resource group,針對該resource group我們開啟了懲罰機制,避免過多大查詢影響整個集群的穩(wěn)定性。同時我們的懲罰機制是否開啟,以及懲罰quota大小都支持動態(tài)更新,隨時可以調(diào)整配置不需要重啟集群。
懲罰算法偽代碼如下:
成員變量:(以GroupA舉例)
punishCpuLimit :GroupA所配置的cpu算力上限
usagePerSecond:GroupA實時統(tǒng)計到的每秒所使用的cpu消耗
cSum:GroupA累計消耗的cpu總和
long cSum = lastCSum + usagePerSecond;if (cSum <= punishCpuLimit) {cSum = 0;} else if (cSum >= 2 * punishCpuLimit) {// 這邊記錄當前resource group 需要懲罰cSum = cSum - punishCpuLimit;} else if (punishCpuLimit < cSum && cSum < 2 * punishCpuLimit) {cSum = cSum - punishCpuLimit;}
代碼做了如下改造:
1. ResourceGroup中除了通過running query收集原有cpu time信息,我們還收集了schedule time和running driver指標供懲罰選擇。
2. 如下圖所示,worker端我們實現(xiàn)Grouped2MultilevelSplitQueue對象,該對象維護了一個resource group和MultilevelQueue的mapping,并且會接受處理coordinator的懲罰信息。
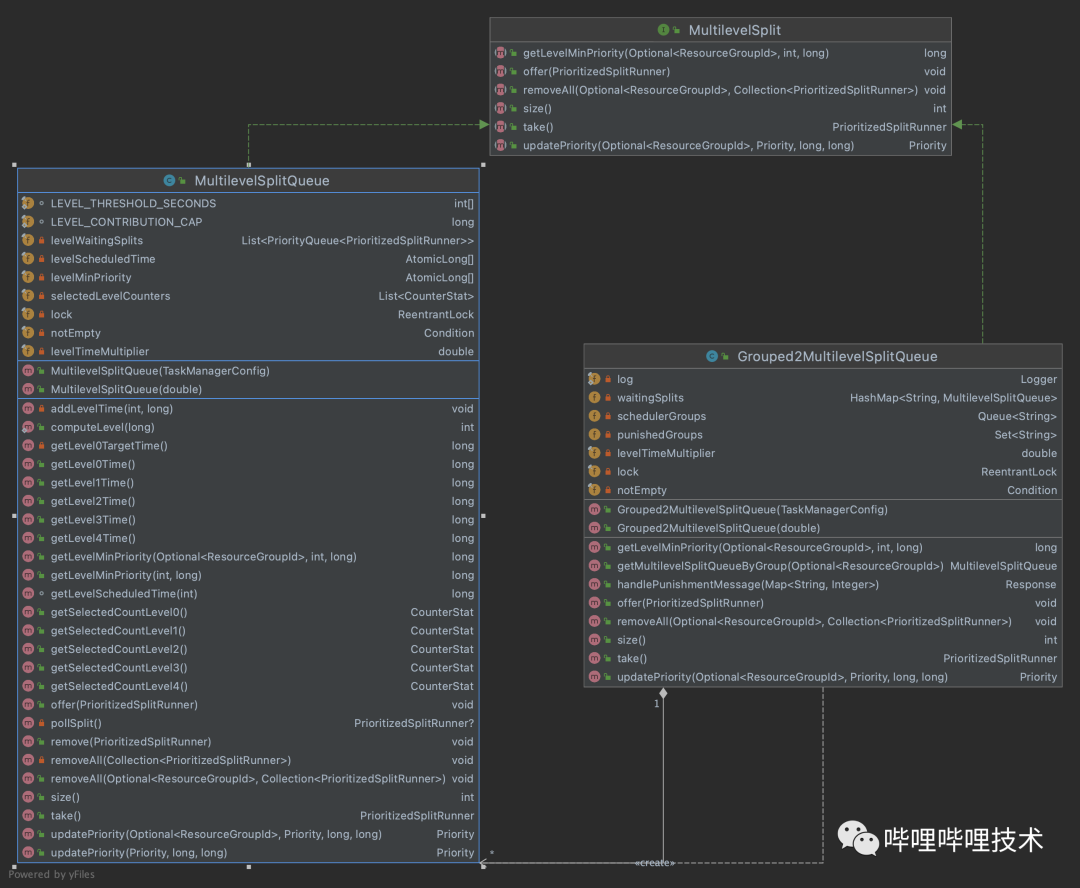
3. coordinator端實現(xiàn)了一個Punish Service,用來實時計算各resource group是否超過了quota設(shè)置,如果超過,則下發(fā)懲罰信息給所有worker節(jié)點
3.4 查詢限制
我們在presto gateway中開發(fā)了一系列規(guī)則來對用戶查詢行為以及bad sql進行限制,策略包括:
1. 對查詢語句進行了特征提取,包括去除注釋,替換表達式的具體值為通配符,取md5為該查詢的特征值,方便進行相同特征查詢限制。
2. 針對INSUFFICIENT_RESOURCES類型超內(nèi)存的查詢,第二次查詢直接攔截不讓提交,因為再次提交依然會失敗,浪費集群資源。
3. 讀HDFS超過30TB的查詢第一次會在運行時被kill掉,第二次提交會被gateway檢測到后直接攔截。
4. 短時間大量提交的查詢會進行攔截限流,比如1分鐘提交超過30條相同特征的query。
5. 回刷數(shù)據(jù)任務(wù)統(tǒng)一調(diào)度到一個獨立的resource group,避免影響正常ETL/ADHOC任務(wù)。
6. 針對worker oom killer的kill掉的查詢,如果其占用內(nèi)存超過一定閾值,那么之后該特征query都會調(diào)度到slow resource group進行限制。
3.5 其他改造
1. worker端開發(fā)了oom killer服務(wù)
不斷的從MemoryMXBean拿內(nèi)存使用情況,當worker堆使用超過一定百分比,并且持續(xù)超過一定時間,就開始選擇占用最大內(nèi)存的task kill掉。
2.監(jiān)控告警
通過presto暴露的jmx,然后將信息采集吐到grafana,可以很方便的監(jiān)控到集群的一些關(guān)鍵信息,并且基于這些信息做了一些告警。
4
可用性改進
4.1 支持隱式轉(zhuǎn)換
Hive和Spark默認就支持隱式數(shù)據(jù)類型的轉(zhuǎn)換,比如query select 1 = '1' hive能正確返回true,而presto直接報語法錯誤,我們通過在ExpressionAnalyzer中對邏輯表達式和算術(shù)表達式進行了判斷,如果左右表達式不一致,同時能夠兼容的話,直接通過加cast進行類型強轉(zhuǎn)。
hive> select 1 = '1';trueTime taken: 3.1 seconds, Fetched: 1 row(s)presto> select 1 = '1';Query 20220301_114217_08911_b5gjq failed: line 1:10: '=' cannot be applied to integer, varchar(1)select 1 = '1'presto> set session implicit_conversion=true;SET SESSIONpresto> select 1 = '1';_col0-------true(1 row)
4.2 兼容HIVE UDF
我們兼容了Hive自帶的UDF和GenericUDF, 并且如果在Presto自帶以及hive-apache中沒有的UDF,會嘗試從hive metastore去獲取一下是否存在該Function,如果存在,則將UDF所在的jar包download到本地,然后通過classloader進行l(wèi)oad。
1. UDF入?yún)⒑统鰠⑥D(zhuǎn)換,Hive GenericUDF入?yún)镈eferredObject,需要根據(jù)Presto參數(shù)類型進行相應的轉(zhuǎn)換,比如Presto的VARCHAR則需要通過Slice的toString轉(zhuǎn)換成String類型,返回結(jié)果為ObjectInspector,不同的返回類型需要轉(zhuǎn)換成Presto相應的數(shù)據(jù)類型,比如是StringObjectInspector則需要封裝到Slice中。
2. 通過codegen方式將HiveUDF調(diào)用方法生成到MethodHandle中。
3. 因Hive UDF未考慮并發(fā)問題,所以存在線程安全問題,構(gòu)建的GenericUDF需要通過ThreadLocal來隔離。
4.為了防止各個UDF依賴不同版本的jar導致沖突,通過對每個UDF的jar new一個新classLoader進行隔離,該classLoader的parent為Hive plugin ClassLoader(已經(jīng)加載了Hive-exec相關(guān)類)。
presto> select b_security_mask_email('[email protected]',0);_col0------------------1*3@bilibili.com(1 row)
4.3 支持insert overwrite table/ directory語法
Presto原生要支持Overwrite語義需要在insert into語句中設(shè)置'insert_existing_partitions_behavior' session參數(shù)來控制,為了保持和hive語法的一致性,我們通過修改Presto的語法文件, 使其先支持接受Insert overwrite table語法,然后在遍歷AST樹時,遇到InsertOverwrite節(jié)點則生成Insert節(jié)點,同時將overwrite含義一路透傳到worker,修改其Insert語義為overwrite, 同時也支持hive的動態(tài)和靜態(tài)分區(qū)寫法。
因為adhoc系統(tǒng)針對大查詢的結(jié)果下載功能,通過將用戶sql修改為insert overwrite directory ‘location’ select語法,將結(jié)果保存到hdfs,然后通過下載中心提供給用戶導出,hive和spark是支持的,我們也對presto進行了改造支持。
presto> insert overwrite table tmp_db.tmp_table select '1' as a, '2' as b;INSERT OVERWRITE: 1 rowpresto> insert overwrite directory "/tmp/xxx/insert1" select value.features from ai.xxxTable limit 10;rows------10(1 row)
4.4 兼容Hive Ranger Plugin
Ranger在2.0版本開始支持Presto plugin,我們基于Ranger1.2版本做了不少優(yōu)化,升級的需求不大,所以我們在1.2版本的Ranger中加入了Presto的plugin,同時2.0版本的Ranger是基于3段式來進行賦權(quán),而我們大部分的權(quán)限需求還都在hive,所以我們對plugin進行了一些改造,使其兼容了Ranger Hive賦權(quán)policy,也就是說通過對Hive plugin賦權(quán)一次,presto和hive、spark引擎共用policy,目前庫,表,row-level filtering和column masking都支持。
4.5 支持Hint語法
我們在語法定義層面做了hint的實現(xiàn),支持常見session參數(shù)通過寫在sql hint上進行配置,比如join類型的選擇,query執(zhí)行時間,是否關(guān)閉cache讀,是否開啟spill to disk等。
/*+ query_max_execution_time= '1h', scale_writers=true*/SELECT clo_1, col_2 FROM xxxx WHERE log_data='20211019'
4.6 支持having alias、group by alias語法
針對如下查詢,因為percent是一個alias字段,presto查詢會報錯,而hive和spark是支持該語法的,我們通過拿到node的SelectItems進行對比,并替換alias字段信息。
presto> select log_date, sum(job_percent) as percent from test.test_report group by log_date having percent > 0;log_date | percent----------+-----------------------20211231 | 0.03625346663870051
4.7 其他改造
基于Linkedin開源的Coral支持讀Hive視圖。
支持動態(tài)加載和更新Resource group。
支持多數(shù)據(jù)源聯(lián)合查詢,數(shù)據(jù)源包括Kafka, JDBC, Tidb,Clickhouse,Iceberg,Hudi, ES,其中JDBC connector支持按splitField自動切分成多個Split并行讀表。
基于HDFS的共享JAR包和配置,做到動態(tài)添加Catalog,無需重啟集群。
在Web ui中展示了Query queued具體原因。
語句結(jié)束后將QueryInfo序列化寫入HDFS,實現(xiàn)了Job History服務(wù),更長時間保留語句信息,方便對出問題語句進行問題定位。
集群實現(xiàn)無損發(fā)布,Presto worker進程通過監(jiān)聽發(fā)布系統(tǒng)kill -15信號,然后將自身狀態(tài)置為非ACTIVE,不接受新任務(wù),等所有任務(wù)結(jié)束再退出進程。
實現(xiàn)了和Hive一樣的點邊式的字段級血緣和算子影響關(guān)系,細化了血緣模型。
5
性能提升
5.1 Presto on alluxio
通過收集presto的血緣信息,我們發(fā)現(xiàn)少數(shù)表會被反復讀取,根據(jù)表最近7天訪問的平均值作為熱度,從下圖可以發(fā)現(xiàn),很多表一天被訪問好幾百次。

基于這樣一個事實,因為本身Presto和HDFS是存算分離的架構(gòu),加上HDFS經(jīng)常會存在slow rpc,或者熱點Datanode情況。所以我們決定使用Alluxio來緩存這部分熱數(shù)據(jù),使Presto提升查詢效率的同時,也減少了HDFS的壓力,減少了受HDFS的影響。
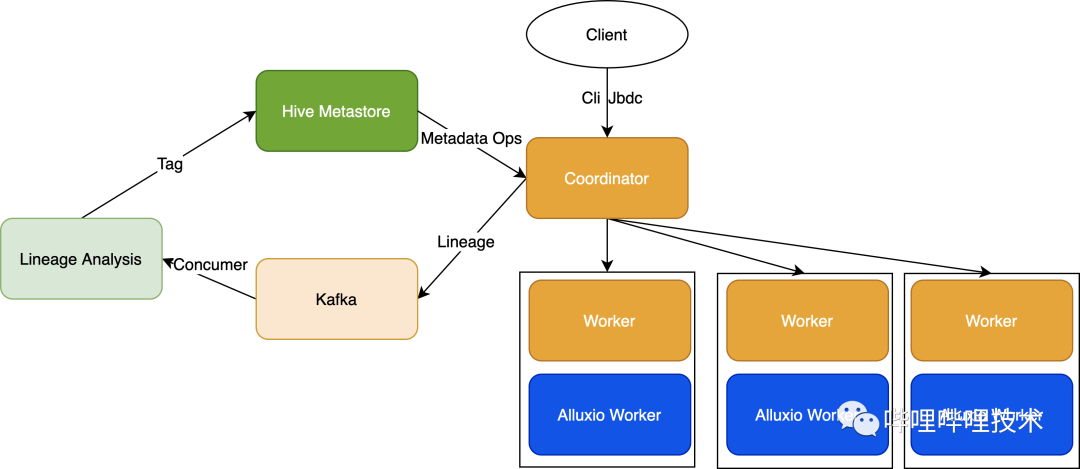
架構(gòu)圖如上,通過將Presto的血緣吐出到kafka,然后對血緣進行分析,比如如下血緣信息,只需要對json進行解析就能拿到查詢的表,以及讀了哪些分區(qū)。

我們也做了以下事情來確保熱表數(shù)據(jù)被Presto識別,并且自動轉(zhuǎn)換到Alluxio中讀取:
1. 消費血緣數(shù)據(jù),按集群解析到分區(qū)級別訪問信息并落地到Tidb。
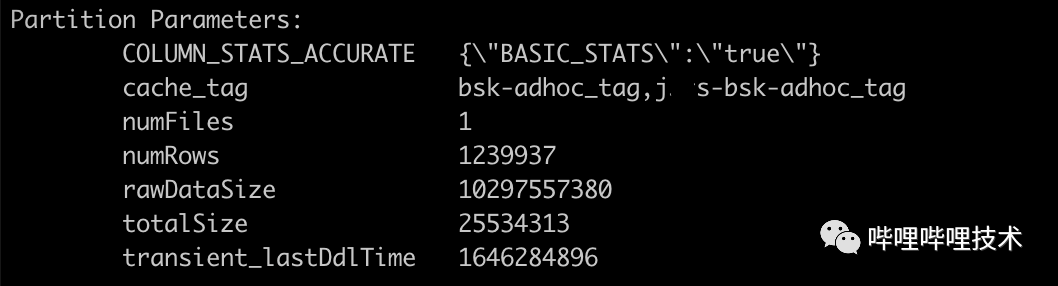
2. 開發(fā)cache tag管理服務(wù),主要用來對分區(qū)進行打tag(tag存儲在hms中的Partition Parameters),并且通過分區(qū)訪問情況,計算其TTL,對于超過TTL的分區(qū)會進行untag,并且從alluxio中刪除路徑。
如下圖所示,如果這個分區(qū)對哪個集群是熱表,那么只需通過cache_tag來控制哪個集群應該從Alluxio讀數(shù)據(jù)。
3. 開發(fā)cache invalidate服務(wù)主要為了保證hdfs和alluxio的數(shù)據(jù)一致性,該服務(wù)會監(jiān)聽Hive meta event,分區(qū)更新則刪除alluxio中的分區(qū)路徑,同時對于已經(jīng)打tag的表,該服務(wù)還監(jiān)聽add partition事件,然后給新增分區(qū)打tag,并且通過alluxio的distributed load 向Alluxio JobMaster發(fā)送請求,load文件到alluxio worker。
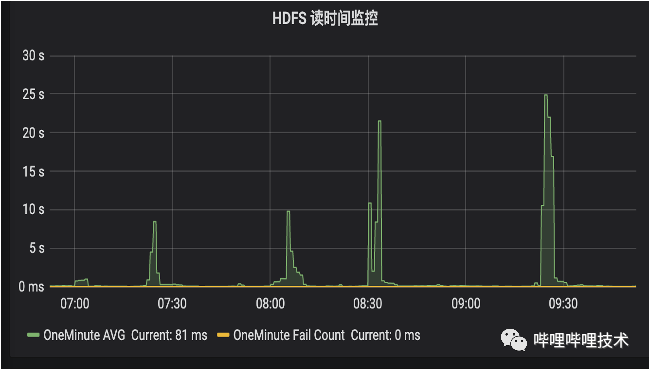
alluxio自身可以通過下面參數(shù)來控制是否每次和底層HDFS元數(shù)據(jù)是否一致,但是為了不受偶爾NN慢rpc影響,我們通過上述服務(wù)來保證數(shù)據(jù)的一致性,目前Presto adhoc集群已經(jīng)接入了HDFS的Observer NN,在RPC讀請求延遲方面得到了很大的改善,可以考慮直接通過alluxio來保證數(shù)據(jù)的一致性。
alluxio.user.file.metadata.sync.interval=0alluxio.user.file.metadata.load.type=ALWAYS
4. Presto這邊做的改造就比較簡單,在load split的地方拿到分區(qū)的Parameters,如果含有cache_tag的信息,并且如果和當前集群是吻合的,那么將HDFS的路徑改成Alluxio的地址,真正建立連接時候還會檢測一次Alluxio是否連通,如果有問題,會繼續(xù)降級讀HDFS。
效果如下:
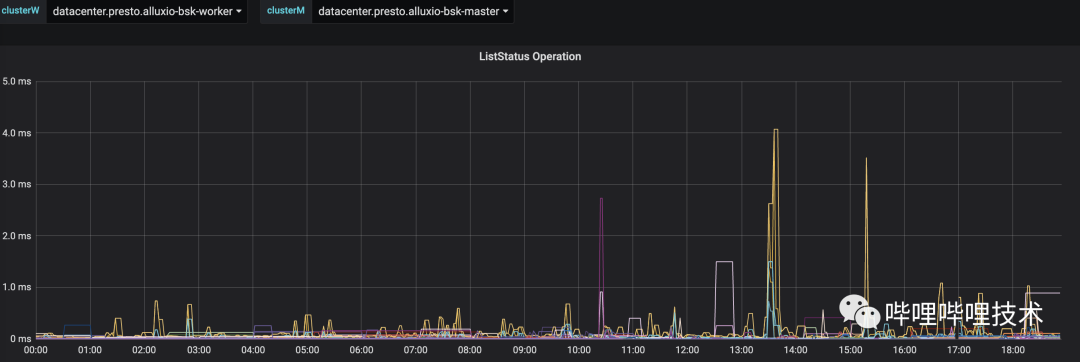
通過Presto的TPC-DS benchmark,基本上平均能夠達到20-30%左右的性能提升,同時被打了tag的分區(qū)查詢更加穩(wěn)定,如下圖所示,HDFS經(jīng)常會有幾十秒的讀RPC延遲,從Alluxio的liststatus rpc時間來看(耗時低于10ms),訪問到熱分區(qū)的rpc請求更穩(wěn)定,也更快。目前我們BI報表有30%的分區(qū)已經(jīng)被打上了tag,未來計劃打上更多的熱分區(qū)tag。
5.2 多機房架構(gòu)
隨著B站業(yè)務(wù)高速發(fā)展,數(shù)據(jù)量和作業(yè)數(shù)增長也變得越來越快,機房機位快速消耗,容量達到上限后會阻塞業(yè)務(wù)的發(fā)展。
一個機房資源既然有限,那我們擴展為多個機房,引入異地第二機房部署Hadoop和Presto集群, 但多機房面臨的問題一個是跨機房數(shù)據(jù)交互帶寬資源有限,存在瓶頸,一個是網(wǎng)絡(luò)抖動造成的服務(wù)SLA會有影響。在此背景下我們設(shè)計了Presto的多機房架構(gòu),對原有的架構(gòu)進行改造,保證從用戶視角仍然是一個機房。
用戶側(cè)統(tǒng)一接入Presto gateway,每個機房我們都獨立部署一套Presto集群,這樣Presto內(nèi)部shuffle數(shù)據(jù)就不會跨機房產(chǎn)生流量。
對于Hive外部數(shù)據(jù)源讀取,分兩種場景,ETL場景下由于我們做了基于單元化思路的數(shù)據(jù)和業(yè)務(wù)遷移,將高內(nèi)聚的業(yè)務(wù)和數(shù)據(jù)遷移到第二機房,所以作業(yè)通過Presto gateway時會自動按照用戶或者作業(yè)ID的mapping關(guān)系路由到對應機房的集群。
adhoc場景下,臨時產(chǎn)生的需求,一般無法預測流量,我們做法是在Presto gateway中解析出語句需要訪問的表和分區(qū)路徑,并從Namenode proxy中獲取到路徑所在的機房位置和數(shù)據(jù)大小信息進行計算,預估出作業(yè)放到各機房后所產(chǎn)生的跨機房流量,以節(jié)省跨機房帶寬為目標,再綜合每個集群的實際負載情況來決定將作業(yè)調(diào)度到哪個機房。比如:
訪問單張表:調(diào)度到數(shù)據(jù)所在機房
訪問多張表:
a. 多表在同一機房,作業(yè)路由到數(shù)據(jù)所在機房
b. 多表在不同機房,路由到數(shù)據(jù)量較大的表所在機房,較小的表限流讀
此外我們也做了兩個優(yōu)化,一個是計算下推優(yōu)化,利用Presto的Connector多源查詢能力,實現(xiàn)了跨IDC connector,將第二機房集群視為一個connector,在訪問多表不同機房的場景下將SQL做改寫,子查詢計算邏輯盡可能下推到第二機房集群進行部分計算處理,再和主機房計算結(jié)果進行合并,以減少跨機房流量帶寬。
另一個我們也通過血緣分析出跨機房讀熱分區(qū),提前加載到本地alluxio進行緩存,盡量避免下次跨機房訪問。

5.3 Query result cache
我們之前根據(jù)query的md5統(tǒng)計了一下,每天有超過萬條查詢是重復的查詢,如果這部分查詢的結(jié)果能夠緩存起來,那么直接將結(jié)果返回給客戶端,不僅可以減少集群壓力也可以提升查詢速度。
對Query的結(jié)果做緩存,最大的挑戰(zhàn)就是保證用戶查詢的是最新的數(shù)據(jù),否則就出現(xiàn)數(shù)據(jù)質(zhì)量問題了。

架構(gòu)如上圖:
1.為了能夠獲取query查詢的表以及分區(qū)信息(這部分信息將用來作為緩存的key),我們將邏輯寫在Coordinator,在Coordinator 做完LogicalPlan之后,拿到查詢的表信息(包括分區(qū)信息),然后再加上query本身計算md5作為key,然后從根據(jù)key值從redis中查詢看看是否存在緩存,如果存在,則將QueryStateMachine置為Cached狀態(tài)。這里再解釋一下為什么需要獲取查詢的表和分區(qū)信息,比如這條sql:select * from db.table where log_date > '20220101', 那么這條query今天和明天分別執(zhí)行,讀到的分區(qū)數(shù)是不一樣的。當然我們最近也在準備將這部分邏輯前置到gateway,在gateway中對query進行部分元數(shù)據(jù)分析,拿到分區(qū)級別信息。
2.在獲取結(jié)果的邏輯中,加入了緩存結(jié)果保存和讀取的邏輯,在保存緩存結(jié)果的同時,也會將上述分析拿到的分區(qū)、列類型信息和query的mapping關(guān)系也保存起來。
3.同時還開發(fā)了緩存失效服務(wù),監(jiān)聽查詢依賴的表分區(qū)是否有更新,如果有則直接刪除緩存。
如下圖所示,兩條一樣的query,第一次執(zhí)行需要7s,第二次執(zhí)行只需要300ms,并且從split來看沒有觸發(fā)調(diào)度。目前每天有5k條Query能夠得到緩存加速。

5.4 Raptorx
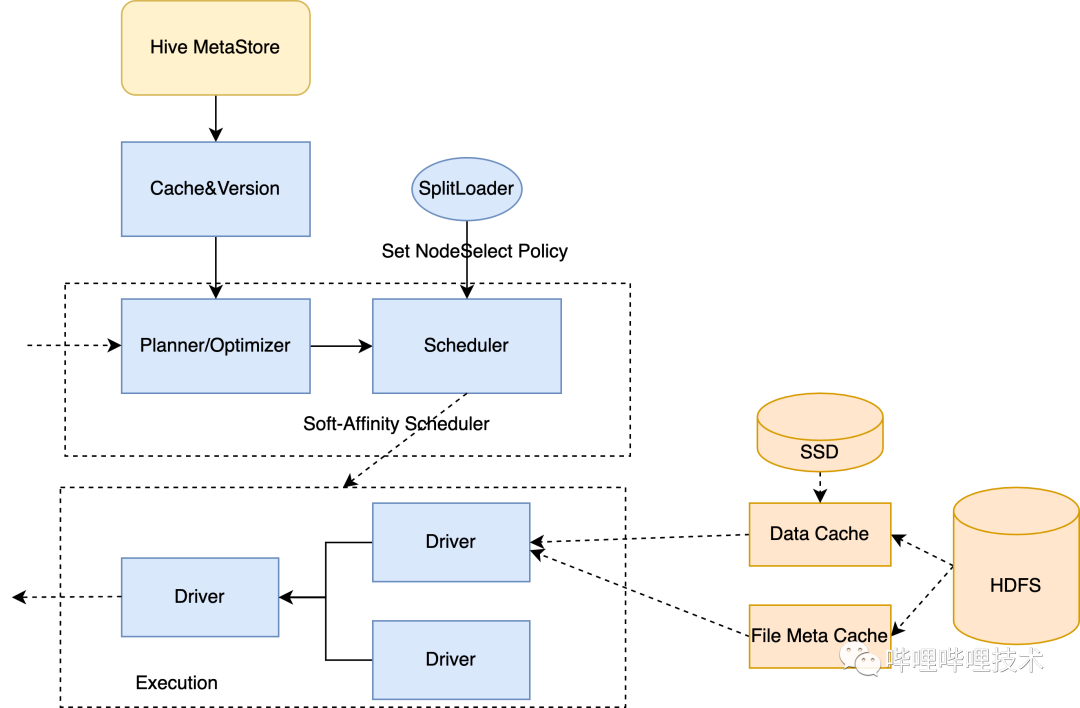
Raptorx是Prestodb通過數(shù)據(jù)緩存進行查詢加速的項目(https://github.com/prestodb/presto/issues/13205),得益于軟親和性的調(diào)度策略,一個Split或者文件會通過一致性Hash算法調(diào)度到相同的Worker節(jié)點,第一次訪問的時候按照文件需要讀的offset和length,以細粒度Page(通常1MB)為單位從HDFS緩存在本地磁盤,第二次訪問的時候,直接從本地節(jié)點的緩存訪問,而不需要再遠程讀取數(shù)據(jù),因為采用了一致性Hash算法所以盡可能降低了節(jié)點擴縮容時候?qū)ΜF(xiàn)有節(jié)點緩存命中率的影響,如果分片Hash完選擇的第一臺節(jié)點由于負載過高不宜分配,會自動順延降級到后一臺節(jié)點調(diào)度,如果后一臺節(jié)點負載也很高,則繼續(xù)降級調(diào)度策略進行隨機調(diào)度,同時關(guān)閉本次查詢從緩存讀的開關(guān),這樣文件最多物理緩存在兩臺節(jié)點。同時得益于Split或者文件能調(diào)度到相同機器,那么針對ORC或者Parquet的一些文件meta信息,比如orc文件的file footer,stripe statistics, row group index信息等都可以緩存到worker進程JVM內(nèi)存中,無需再從HDFS讀取,也有不錯的緩存命中率。
上面也提到,我們其實上線了Alluxio集群來緩存數(shù)據(jù),那為什么還需要引入raptorx呢,raptorx相對于Alluxio集群模式有幾大好處:
Raptorx基于Alluxio local cache,是Page級別(默認1MB)的緩存,而集群模式必須緩存整個文件,通常用戶經(jīng)常訪問的數(shù)據(jù)集中在某張表的幾個列,而列存格式中同一列數(shù)據(jù)是緊湊存放一起的,細粒度緩存只需要緩存某些常用列的數(shù)據(jù),不需要整個文件緩存,減少緩存管理開銷。
上面提到,可以針對orc和parquet緩存文件和stripe、row group等的meta信息,近一步提升查詢性能。
本地數(shù)據(jù)管理以Library方式嵌入到Presto worker進程中,不受Alluxio集群穩(wěn)定性影響。
我們backport了Prestodb Raptorx相關(guān)的patch,并且做了一些其他改造:
1. 社區(qū)通過session來控制一個query級別的local cache,如果該query 開啟local cache,那么query依賴的所有表的所有分區(qū)數(shù)據(jù)都會進SSD,粒度不夠精細,我們是根據(jù)分區(qū)是否被標記成熱分區(qū),然后只會將熱分區(qū)進行軟親和性調(diào)度。
2. Raptorx中的hive metastore versioned cache是基于FB的內(nèi)部版本,要使用這塊功能需要對hive metastore改造thrift api暴露出分區(qū)和表的版本信息,我們利用Table和Partition的lastDDLTime來作為version,解決meta版本不一致問題,及時失效meta緩存并重新加載。
3. 對orc和parquet都支持了文件元數(shù)據(jù)的緩存,并根據(jù)hive文件的lastModifiedTime及時失效過期緩存。
4. 基于alluxio local cache進行了改造,支持基于文件的lastModifiedTime來判斷數(shù)據(jù)是否失效,并及時清理過期page。
5. 因為alluxio local cache目前只支持掛載一塊磁盤,實現(xiàn)了基于剩余空間的VolumeChoosingPolicy來對多塊磁盤進行存儲管理。
6. 每次Presto worker啟動后必須恢復完所有page后才開始對外提供服務(wù),這樣盡可能保證Page的緩存命中率。
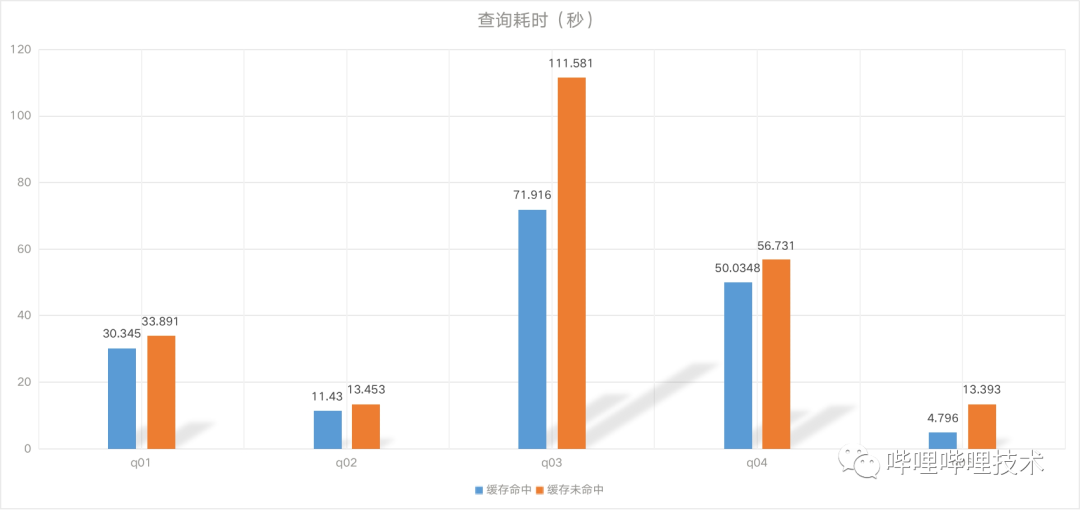
我們拿了一些query進行測試,如下圖所示,部分query能夠得到數(shù)倍性能提升。
PS:如果有用到viewfs來做hdfs的federation,那么應該會遇到一些問題,大家可以參考:
https://github.com/prestodb/presto/pull/17390
https://github.com/prestodb/presto/pull/17365
https://github.com/prestodb/presto/pull/17367
5.5 支持struct 字段類型下推
trino在高版本(334,https://github.com/trinodb/trino/pull/2672) 支持struct字段類型的下推優(yōu)化,包括project和filter的下推,我們AI團隊經(jīng)常會用到嵌套數(shù)據(jù)類型,這個優(yōu)化能夠給查詢帶來不小的提升,我們將整個功能backport到我們自己的版本,如下圖所示,有和沒有deference下推,執(zhí)行計劃的project和filter有巨大的差別,實際測試下來有的sql shuffle數(shù)據(jù)量能夠達到幾十上百倍的減少,查詢性能也能夠提升數(shù)倍。
測試語句:
SELECTA.ip,B.info.midFROMtmp_bdp.tmp_struct_test AJOIN tmp_bdp.tmp_struct_test B on A.ip = B.ip
其中info是struct類型,包含9個String類型字段,執(zhí)行效果見下圖,Scan input size和shuffle size大幅度減少

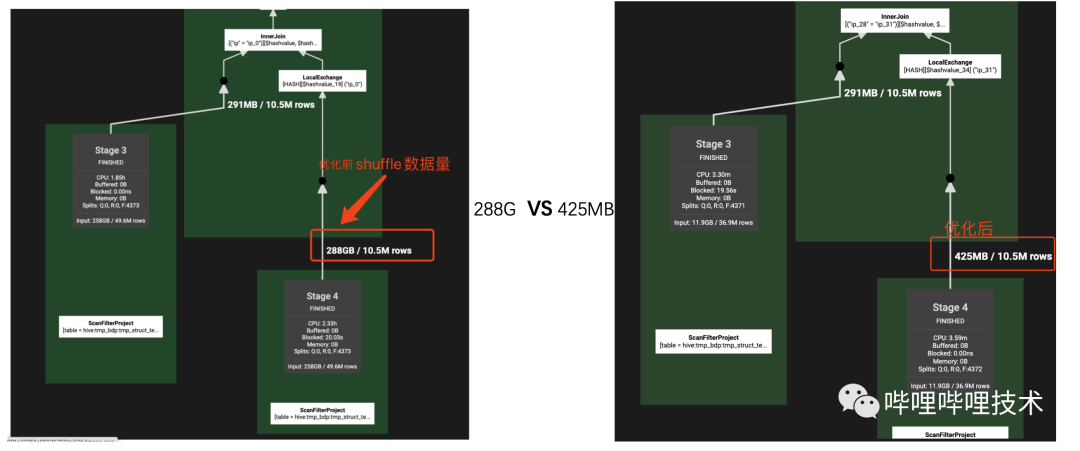
目前我們只支持struct字段類型下推,還無法做到map和array類型的下推,而我們線上存在不少array中嵌套struct的數(shù)據(jù)類型,大部分sql通過unnest來對array進行展開,之后目標是繼續(xù)深入研究針對array和map的下推支持。
5.6 JDK版本從8升級到zulu JDK 11
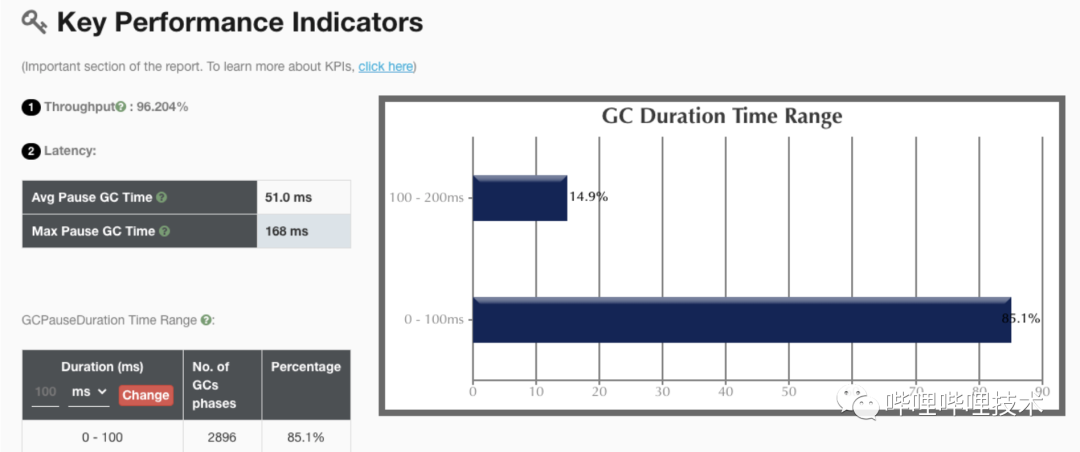
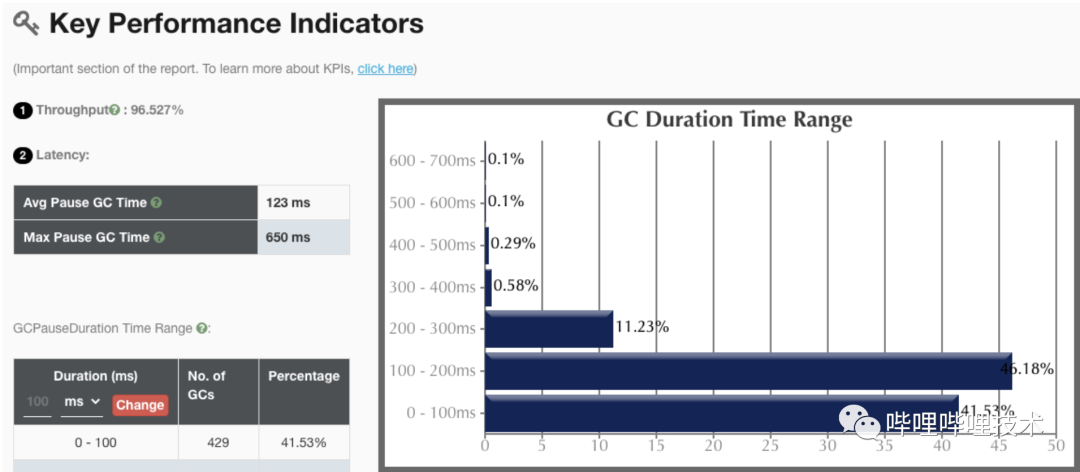
我們一開始想在升級JDK同時將垃圾收集器切換到ZGC來降低單次 GC的時間,提升集群整體性能。benchmark測下來也確實ZGC效果最好,但是因為JDK11的zgc沒有class unloading功能,導致presto codegen出來的大量class無法回收導致metaspace泄漏,所以升級了JDK11依然使用G1收集器。
升級后,JDK11 g1收集器gc吞吐量是98%,相比JDK8有2個點的提升。同時JDK11提供了一些新的監(jiān)控和診斷工具,比如JFR能幫助我們后續(xù)進一步分析JVM運行性能和定位問題。
JDK11 ZGC收集器性能指標:
JDK8 G1收集器關(guān)鍵性能指標:
JDK11 G1收集器關(guān)鍵性能指標:

5.7 支持動態(tài)過濾
動態(tài)過濾是指作業(yè)在運行時動態(tài)生成過濾器的功能(簡稱Dynamic Filter),適用于高選擇性Join場景,以此減少IO以及后續(xù)的計算量。目前,trino高版本已支持動態(tài)過濾,我們借鑒了trino高版本的動態(tài)過濾,實現(xiàn)了BroadcastJoin,Dynamic Partition Pruning以及Partitioned Join。
整體架構(gòu):
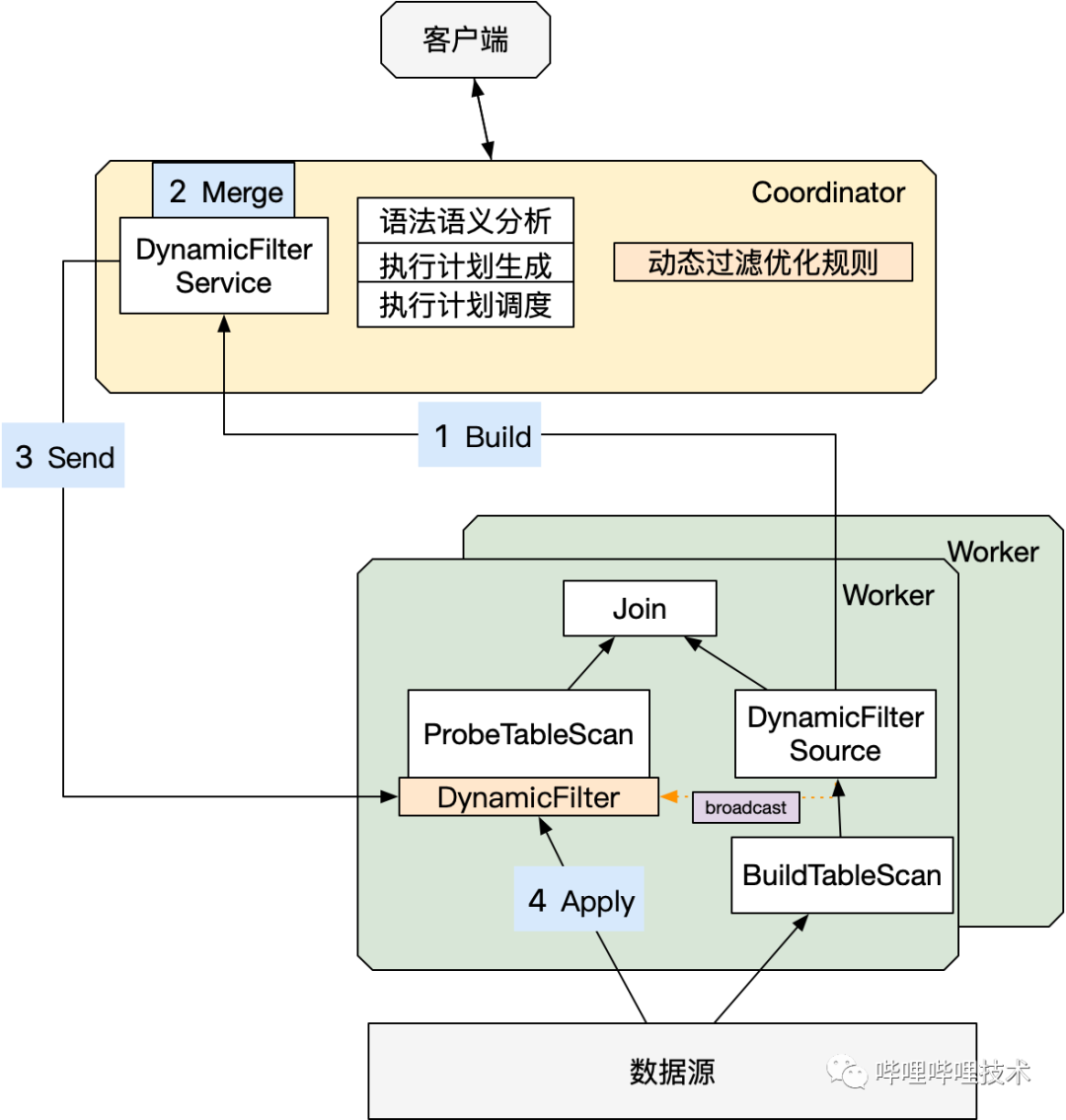
具體改造如下:
Coordinator端新增PredicatePushDown優(yōu)化器下推DynamicFilter信息。
Worker新增“Collect”算子,通過PageSourceProvider下推DynamicFilter到源文件讀取。
Worker新增上報DynamicFilter信息。
Coordinator新增DynamicFilterService,對Worker匯報上來的DynamicFilter信息做整合,再將整合后的DF信息下發(fā)到各個worker做過濾。
改造效果:
對特定Dynamic Partition Pruning的SQL,效果明顯:
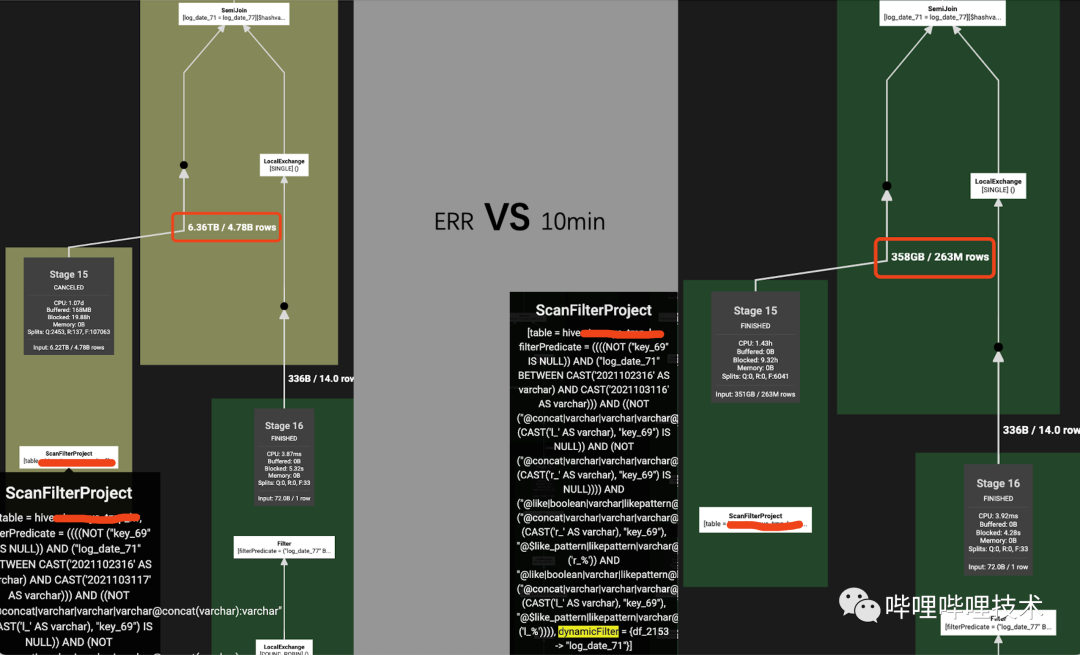
左表讀數(shù)據(jù)量從6.36T減少到358GB
2. benchmark效果:
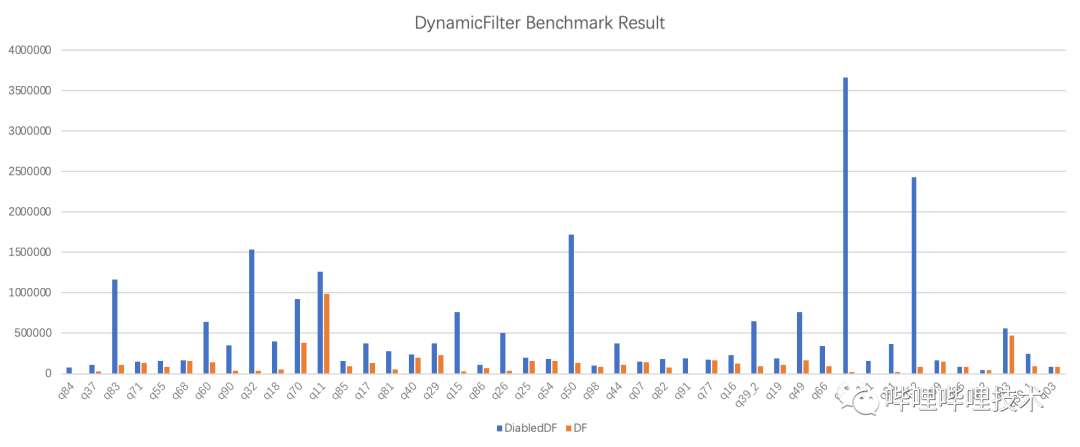
其中,benchmark中效果好的Query主要由以下兩個因素決定:
Query類型為高選擇性join場景。
底層文件的過濾性能,例如orc文件寫入的時候如果有sort by字段,stripe過濾時會更高效;或者底層orc文件如果開啟了bloomFilter,也會提高過濾效果。
總結(jié):
動態(tài)過濾適用于Hive Connector,支持OrcFile/Parquet,下推到數(shù)據(jù)源。
支持分區(qū)表的分區(qū)裁剪,非分區(qū)表的行過濾。
支持Join策略包括Broadcast Join/Dynamic Partition Pruning/Partitioned Join。
支持Join語法包括InnerJoin/SemiJoin。
5.8 其他改進
針對小文件產(chǎn)生split數(shù)過多的問題,將它們合并成一個大split進行調(diào)度,減少split數(shù)和調(diào)度壓力。
HDFS讀請求接入Observer Namenode,減少因Active Namenode slow rpc造成的影響。
開啟FileStatus cache, 減少對NN的RPC訪問壓力。
針對大查詢,開啟spill功能,將page寫入本地磁盤,緩解內(nèi)存壓力。
Coordinator側(cè)查詢執(zhí)行計劃緩存,減少生成和優(yōu)化plan的時間。
多個stage的語句自動轉(zhuǎn)換成phased調(diào)度執(zhí)行方式,降低集群壓力。
當Hive分區(qū)或者表的Stats信息不準的情況下,比如row_count為0,但size不為0,Presto在做Join選擇的時候會優(yōu)先選擇Broadcast join,如果是一張大表,那么整個查詢效率非常低,我們在CBO計算模塊中,如果row_count為0,那么我們通過拿分區(qū)的datasize信息乘以一個默認的膨脹比來作為該表或分區(qū)的scan數(shù)據(jù)量,然后通過該值來進行CBO的計算,確保更準確的選擇更合適的Join類型。
6
未來規(guī)劃
Presto集群支持HPA, 低峰時自動對Presto Worker節(jié)點進行優(yōu)雅縮容給到Y(jié)arn混部集群,從而提升機器利用率,達到降本增效目的。
啟發(fā)式索引,在讀數(shù)據(jù)前提前過濾Split,orc的文件和stripe,減少讀數(shù)據(jù)量。
支持自動物化視圖,根據(jù)用戶常見的語句,自動創(chuàng)建和刷新物化視圖,無需用戶操作和管理開銷,查詢時改寫語句復用先前物化的數(shù)據(jù)。
復雜數(shù)據(jù)類型Array/Map讀優(yōu)化。
基于HBO,ETL大查詢自動路由到Presto on spark,緩解Presto集群壓力,提升作業(yè)成功率。
我們會和業(yè)界同行和開源社區(qū)保持密切技術(shù)交流,在服務(wù)好內(nèi)部用戶作業(yè)的同時,也會積極反饋社區(qū),共建社區(qū)生態(tài)。