
少數(shù)派報告:談推薦場景下的對比學(xué)習(xí)
前言
最近對比學(xué)習(xí)(Contrastive Learning, CL)火得一塌糊涂,被Bengio 和 LeCun 這二位巨頭在 ICLR 2020 上點名是 AI 的未來。作為普通打工人,對比學(xué)習(xí)能否帶來AI質(zhì)的飛越,從而導(dǎo)致未來出現(xiàn)終結(jié)者,不是我們考慮的問題。本文只聚焦于推薦領(lǐng)域,討論對比學(xué)習(xí)能否提升推薦性能,幫我們早點完成OKR。
本文并非Contrastive Learning Tutorial之類的科普文章,不會講述對比學(xué)習(xí)的發(fā)展沿革,也不會面面俱到每個技術(shù)細節(jié)。對這部分內(nèi)部感興趣的同學(xué),可以參考張俊林大佬的《對比學(xué)習(xí)(Contrastive Learning):研究進展精要》一文,快速入門。
接下來,本文將從以下三個方面展開:
討論一下對比學(xué)習(xí)到底是什么。這一節(jié)的目的,并非為了吊書袋,我也不是什么考據(jù)狂。實在是對比學(xué)習(xí)和我們推薦常用的向量化召回,在很多底層技術(shù)上是通用的。而有一批水文,利用了這二者之間的相似性,將向量化召回算法用“對比學(xué)習(xí)”的概念重新包裝,掛羊頭賣狗肉,使很多同學(xué)覺得CL不過是新一波的概念炒作。

談?wù)剬Ρ葘W(xué)習(xí)到底能給推薦系統(tǒng)帶來哪些幫助。同學(xué)們不要對新技術(shù)盲目跟風(fēng),看完這一節(jié),再來決定CL是否是解決你問題的那根稻草。 分析“對比學(xué)習(xí)在推薦系統(tǒng)中應(yīng)用”的兩篇典型論文。正如前面提到的,這方面的好文章并不多。很多跟風(fēng)灌水之作,看標題上寫著“對比學(xué)習(xí)”和“推薦”,下載下來一看,才發(fā)現(xiàn)不過是講向量化召回的老生常談。
到底什么是對比學(xué)習(xí)?怎么和向量化召回這么像?
初識對比學(xué)習(xí),我也是不以為然的,覺得這不就是向量化召回嗎?我們推薦工程師玩爛的東西,怎么CV同行們還拿來當個寶。
要說對比學(xué)習(xí)和向量化召回之間的相似性,看看我的另一篇文章《萬變不離其宗:用統(tǒng)一框架理解向量化召回》就能有所感受。我在文章中提出了NEFP框架來構(gòu)建向量化召回算法
N, Near, 正對應(yīng)CL中“要讓正樣本embedding在向量空間足夠近”的概念 F. Far, 正對應(yīng)CL中“要讓負樣本embedding在向量空間足夠遠”的概念。 至于“引入負樣本是為了讓模型uniformity, 防止模型坍塌”的論調(diào),其實對于搞推薦的同學(xué)都已經(jīng)不陌生了。負樣本對于召回算法的重要性已經(jīng)深入人心(我的《負樣本為王》一文也有小小貢獻)。近年來,各大廠在如何構(gòu)建easy negative, hard negative紛紛創(chuàng)新。相比之下,對比學(xué)習(xí)中的負樣本策略還略顯小兒科。 E, Embedding,對應(yīng)CL中的encoder部分。CV/NLP/Reco各領(lǐng)域有各自常用的encoder方案。 P, Pairwise Loss,就是對“足夠近,足夠遠”用數(shù)學(xué)形式進行量化。對比學(xué)習(xí)中常用的NCE Loss, Triplet Loss,對于搞推薦的同學(xué),也都算是老熟人了。
看看我提出的NEFP與對比學(xué)習(xí)的關(guān)鍵概念是多么契合。當初對比學(xué)習(xí)還沒現(xiàn)在這么火,否則肯定要好好蹭一波熱度,拿對比學(xué)習(xí)把我的文章好好包裝一下子。
但是,隨著對CL的深入理解,我感覺是我淺薄了。對比學(xué)習(xí)與向量召回算法,只能算形似,也就是雙塔結(jié)構(gòu)、負采樣策略、Loss這些底層技術(shù)被二者所共享。但是對比學(xué)習(xí)與我們推薦常用的向量化召回有著完全不同的精神內(nèi)核。
向量化召回,屬于Supervised Learning,無論是U2I, U2U, I2I, 哪兩個向量應(yīng)該是相似的(正例)是根據(jù)用戶反饋(標注)得到的。 因此,在召回算法中,正樣本從來就不是問題。大家從來不為找不到正樣本而發(fā)愁,反而要考慮如何嚴格正樣本的定義,將一些用戶意愿較弱的信號(i.e., 噪聲)從正樣本中刪除出去,順便降低一下樣本量,節(jié)省訓(xùn)練時間。 召回的主要研究目標是負樣本,如何構(gòu)建easy/hard negative,降低Sample Selection Bias。 對比學(xué)習(xí),屬于Self-Supervised Learning (SSL)的一種實現(xiàn)方式,產(chǎn)生的背景是為了解決"標注少或無標注"的問題。 我之前說“召回是負樣本的藝術(shù)”,那么CL更注重的應(yīng)該是如何構(gòu)建正樣本。 Data Augmentation是CL的核心,研究如何將一條樣本經(jīng)過變化,構(gòu)建出與其相似的變體。 Data Augmentation在CV領(lǐng)域比較成熟了(翻轉(zhuǎn)、旋轉(zhuǎn)、縮放、裁剪、移位等)。而推薦場景下,數(shù)據(jù)由大量高維稀疏ID組成,特征之間又相互關(guān)聯(lián),如何變化才能構(gòu)建出合情合理的相似正樣本,仍然是一個值得研究的課題。
正因如此,是否涉及Data Augmentation,在Data Augmentation上的創(chuàng)新如何,是我判斷一篇CL論文的價值的重要標準。沒有Data Augmentation,基于“user embedding與其點擊過的item的embedding具備相似性”,或者“被同一個user點擊過的item的embedding具備相似性”,構(gòu)建出來的所謂“對比學(xué)習(xí)”,在我眼里,都是耍流氓。因為這些相似性是由用戶反饋標注的,根本就不符合CL解決“少標準或無標注”的設(shè)計初衷。(當然,要是有人要和我杠,偏說U2I, I2I召回也算是Contrastive Learning,那我也沒辦法。就好比說算盤是計算機的鼻祖一樣,你說了,那就是你對。)
除了Data Augmentation,至于如何構(gòu)建負樣本(沒準CV研究得還沒Reco深)、如何構(gòu)建Encoder(CV/NLP里的結(jié)構(gòu),Reco也未必用得上)、如何建立Loss等方面,對于熟悉向量化召回的推薦打工人來說了,都老生常談了,未必能看出什么新意思。
另外一點,CL在推薦場景下,一定是作為輔助訓(xùn)練任務(wù)出現(xiàn)的。道理很簡單,User/Item之間的相似性(i.e.匹配性)才是推薦算法的重點關(guān)注。而CL關(guān)注的是"User與其變體"、"Item與其變體"之間的相似性,只在訓(xùn)練階段發(fā)揮輔助作用,是不會參與線上預(yù)測的。
那么問題來了,引入CL輔助任務(wù),能夠給我們的推薦主任務(wù)帶來怎么樣的提升?
對比學(xué)習(xí)對于推薦系統(tǒng)有什么用?怎么用?
初看CL,作為Self-Supervised Learning的一種,是為了應(yīng)對“少標注或無標注”的問題而提出的,感覺在推薦場景下沒啥用武之地。因為大廠的推薦系統(tǒng),啥都缺,就是不缺標注數(shù)據(jù)(用戶反饋)。每天我們都為如何在海量數(shù)據(jù)上快點跑模型而發(fā)愁,甚至不得不抽樣數(shù)據(jù)以降低輸入數(shù)據(jù)的規(guī)模。“標注樣本少”?不存在。
但是后來再細想一下,推薦系統(tǒng)中的樣本豐富,也是個假象。就如何人間一樣,推薦系統(tǒng)有海量樣本不假,但是貧富差距也懸殊:
82定律才是推薦系統(tǒng)逃不脫的真香定律,20%的熱門item占據(jù)了80%的曝光量,剩下80%的小眾、長尾item撈不著多少曝光機會,自然在訓(xùn)練樣本中也是少數(shù)、弱勢群體 樣本中的用戶分布也有天壤之別。任何一個app都有其多數(shù)、優(yōu)勢人群,比如社交app中的年輕人,或者跨國app中某個先發(fā)地區(qū)的用戶。相比之下,也就有少數(shù)、劣勢人群在樣本中“人微言輕”。
樣本分布中的貧富懸殊,會帶來什么危害?和人間一樣,帶來的是“不公平”,我們稱之為bias
模型迎合多數(shù)人群,忽視少數(shù)人群,不利于用戶增長。 模型很少給小眾、長尾的item曝光機會,不利于建立良好的內(nèi)容生態(tài)。
因此,在推薦系統(tǒng)中引入對比學(xué)習(xí),解決“少數(shù)人群+冷門物料,標注樣本少”的問題,其用武之地,就是推薦系統(tǒng)的debias
在主任務(wù)之前預(yù)訓(xùn)練,或者,與主任務(wù)共同訓(xùn)練。 讓Embedding/Encoder層,多多見識一些平常在log里面不常見的少數(shù)人群和小眾物料。讓平常聽慣了“陽春白雪”的模型,也多多感受一下“下里巴人”。 因為在訓(xùn)練階段與少數(shù)人群與小眾物料都“親密接觸”過了,這樣的模型線上預(yù)測時,會少一份勢利,對少數(shù)人群與小眾物料友好一些。 其實也算是一種對少數(shù)樣本的regularization。
如果明確了對比學(xué)習(xí)的目標是為了debias,那么有兩點是值得我們注意的
參與對比學(xué)習(xí)的樣本,和參與主任務(wù)的樣本,必然來自不同的樣本空間 主任務(wù),需要擬合U~I之間的真實互動,還是以log中的已經(jīng)曝光過的user/item為主。 而對比學(xué)習(xí),既然是為了debias,必然要包含,而且是多多包含鮮有曝光機會的少數(shù)人群和小眾物料。 主任務(wù)與對比學(xué)習(xí)任務(wù)之間,一定存在Embedding或Encoder(某種程度)共享 近年來,給我的感覺,參數(shù)共享、結(jié)構(gòu)共享在推薦算法中,越來越不受待見。比如,多任務(wù)的場景下,同一個特征(e.g. userId, itemId)對不同目標,需要有不同embedding;再比如,阿里的Co-Action Net通篇都在講參數(shù)獨立性,同一個特征與不同特征交叉時,都要使用不同的embedding。 但是,對于對比學(xué)習(xí),(某種程度)參數(shù)共享、結(jié)構(gòu)共享,是必須的。否則,主模型與CL輔助模型,各學(xué)各的,主模型中的bias依舊存在,CL學(xué)了個寂寞。
對比學(xué)習(xí)在推薦場景下的正確姿勢
正如前文所述,盡管對比學(xué)習(xí)當下很火,但是在推薦系統(tǒng)中的應(yīng)用本來就不多,再刨除一些將向量化召回也包裝成對比學(xué)習(xí)的跟風(fēng)灌水文,有價值的好文章就更少了。今天我挑選兩篇對我?guī)椭浅4蟮膬善恼拢唵闻c大家分享。
Google的《Self-supervised Learning for Large-scale Item Recommendations》
講推薦場景下的對比學(xué)習(xí),我首推2021看Google的《Self-supervised Learning for Large-scale Item Recommendations》這一篇,正是此篇幫我樹立了對CL的正確認識。這篇文章利用對比學(xué)習(xí)輔助訓(xùn)練雙塔召回模型,目的是讓item tower對冷門、小眾item也能夠?qū)W習(xí)出高質(zhì)量的embedding,從而改善內(nèi)容生態(tài)。
正如前文所述,讀CL論文,重點是看其中的Data Augmentation部分。傳統(tǒng)上,針對item的data augmentation,是采用Random Feature Masking (RFM)的方法,如下圖所示。
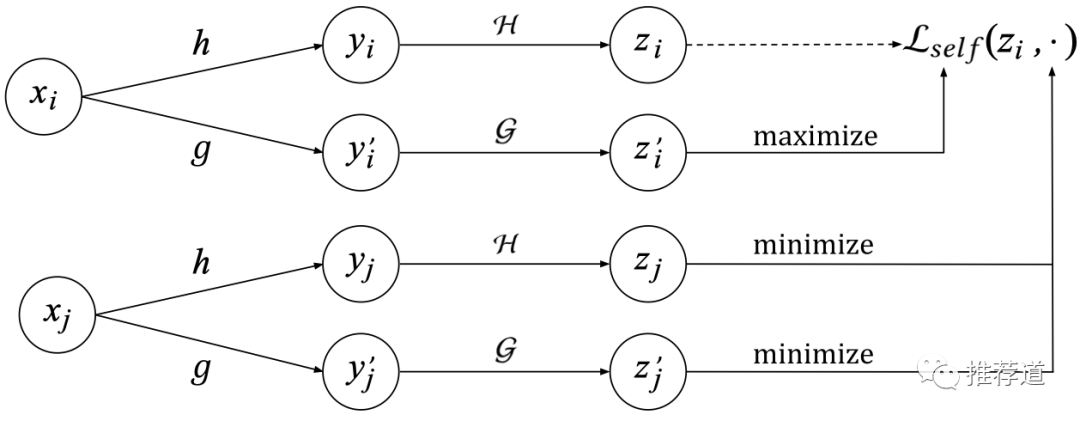
某個item , 隨機抽取一半的特征h,得到變體,再經(jīng)過Encoder H,得到向量;保留剩下的另一半特征g,得到變體,再經(jīng)過Encoder G,得到向量。 來自同一個item的兩種變體對應(yīng)的embedding 和,兩者之間的相似度應(yīng)該越大越好。 按照同樣的作法,另一個item ,用一半特征h得到變體,再經(jīng)過Encoder H得到;用另一半特征g,得到變體,再經(jīng)過Encoder G得到。 來自不同item的變體對應(yīng)的embedding 和(或),兩者之間的相似度應(yīng)該越低越好。
基于以上正負樣本,整個對比學(xué)習(xí)輔助loss采用了Batch Softmax的形式,其實對于搞召回算法的同學(xué)來說,就非常常規(guī)了。(是溫度系數(shù),N是batch size)
后續(xù)會提到,實際上H和G就是同一套結(jié)構(gòu)與參數(shù),同時也與主任務(wù)“雙塔召回”中的item tower共享結(jié)構(gòu)與參數(shù)。
但是,隨機mask特征的data augmentation方法,存在問題。
這樣容易制造出一些“脫離現(xiàn)實”的樣本,比如一個變體中,我們保留了item作者的國籍是巴西,但是卻缺失作品的語言?盡管這樣的樣本不能算離譜,但是畢竟對于模型來說,營養(yǎng)有限。 相互關(guān)聯(lián)的兩個特征,分別被拆分進兩個變體中,比如“作者國籍”在h,“作品語言”在g。盡管看上去兩個變體都是殘缺的,但實際上所包含的信息(e.g., 作品受眾)依舊是完整的。這兩個變體的embedding太容易相似了,達不到鍛煉模型的目的。
為了解決以上問題,Google的論文里面提出了Correlated Feature Masking (CFM)
首先,將任意兩個特征之間的互信息,離線計算好。(比如,是作者國籍,是語言,是加拿大,是法語)
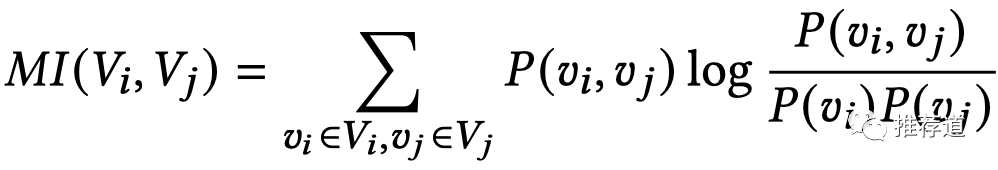
在訓(xùn)練每個batch時,隨機挑選出一個種子特征,再根據(jù)離線計算好的互信息,挑選出與關(guān)聯(lián)度最高的n個特征(n一般取總特征數(shù)的一半),組成要mask的特征集 接下來的步驟就和常規(guī)CL步驟相同了,保留特征h=構(gòu)建一個變體,再拿剩下的一半特征g,構(gòu)建另一個變體,兩變體embedding要足夠近。
除了提出Correlated Feature Masking (CFM)提升了變體的質(zhì)量,Google的這篇論文還提出如下觀點,值得我們注意并加以實踐
Google原文還是拿CL當輔助任務(wù)與主任務(wù)(雙塔召回)共同訓(xùn)練,。但是作者也指出,在未來會嘗試“先用CL pre-train,再用主任務(wù) fine-tune”的訓(xùn)練模式。 整個item tower是被user~item雙塔召回的主任務(wù)、對比學(xué)習(xí)輔助任務(wù)中的encoder H和G,這三者所共享的。這一點的原因前面也解釋過了,CL在推薦系統(tǒng)中的目的,就是為了減輕主模型對long-tail user/item的偏見,如果各學(xué)各的,CL學(xué)了個寂寞,就變得毫無意義。
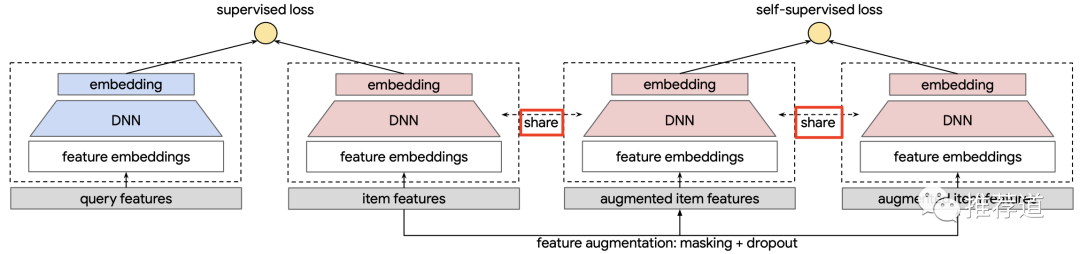
Google的論文里特別指出,召回主任務(wù)中的item主要還是來自曝光日志,因此還是偏頭部item。而為了達到debias的目的,CL輔助任務(wù)中的item必須采用與主任務(wù)完全不同的分布,"we sample items uniformly from the corpus for "。事實上,在我看過的CL in Reco多篇論文中,Google的這篇論文是唯一一篇明確指出了樣本分布對CL的重要性,"In practice, we find using the heterogeneous distributions for main and ssl tasks is critical for SSL to achieve superior performance"。
阿里的《Disentangled Self-Supervision in Sequential Recommenders》
上一篇文章介紹的是針對item的data augmentation,而對于user來說,最重要的特征就是用戶的交互歷史,因此針對用戶歷史的data augmentation,就是影響針對user對比學(xué)習(xí)成敗的重中之重。在我的《萬變不離其宗:用統(tǒng)一框架理解向量化召回》一文中,就提到過一種利用孿生網(wǎng)絡(luò)來構(gòu)建U2U召回的方法:將用戶歷史序列,隨機劃分為兩個子序列,各自喂入雙塔的一邊,訓(xùn)練要求兩塔輸出的embedding越相似越好。現(xiàn)在看來,這種作法實際上就是在做對比學(xué)習(xí)。
阿里的這篇文章針對的是sequentail recommender問題,即輸入用戶歷史序列,預(yù)測下一個用戶可能交互的item,因此seq-2-item是預(yù)測的主任務(wù)。同時,這篇論文里提出了類似“孿生網(wǎng)絡(luò)”的方法訓(xùn)練seq-2-seq輔助任務(wù),只不過有兩點改進:
從用戶完整歷史中提取出兩個子序列,不再是隨機劃分,而是按照時序劃分。而且為了建模時序關(guān)系,后一個子序列,還使用了倒序。 為了顯式建模用戶的多興趣,Encoder不再將用戶序列壓縮成一個向量,而是提取出K個向量。 因此正例變成了,同一個用戶,從他的前一段歷史提取出的第k個興趣向量,與從他后一段歷史提取出的第k個興趣向量,距離相近 負例擴展成,除了不同用戶的興趣向量相互遠離,同一個用戶的不同類別的興趣向量,距離也要足夠遠。
對比學(xué)習(xí)公式如下。代表用戶在t時刻之前的歷史,是t時刻之后用戶歷史;是負責(zé)從用戶歷史中提取第k個興趣向量的encoder。
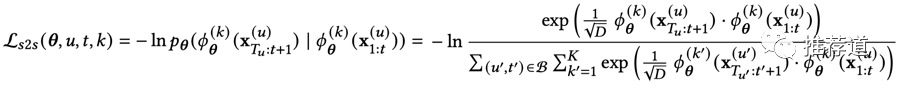
剩下的一些技術(shù)細節(jié),比如顯式地學(xué)出K個不同的興趣向量比壓縮成一個向量能提升多少、時序的分裂點t是隨機的還是固定成一半的位置、......,我覺得都不重要,在阿里場景下取得的收益是否能夠在你的場景下復(fù)現(xiàn),就留待GPU和AB平臺告訴我們答案了。
總結(jié)
本文也算是緊跟“對比學(xué)習(xí)”燎原之勢的跟風(fēng)應(yīng)景之作,但是自認為還是有點干貨的,而并非僅是別人成就的綜述
談了我對對比學(xué)習(xí)的理解,特別是厘清了與向量化召回算法的重要區(qū)別。盡管底層很多技術(shù)是通用的,但是對比學(xué)習(xí)與向量化召回,是形似神不似。對比學(xué)習(xí)作為Self-Supervised Learning的一種,畢竟針對的是“少標注或無標注”問題,Data Augmentation是其核心,在推薦場景下往往作為輔助任務(wù)出現(xiàn)。有鑒于此,同學(xué)們?nèi)蘸笤倏吹侥脤Ρ葘W(xué)習(xí)包裝向量化召回的水文,一定要擦亮眼睛。 指出對比學(xué)習(xí)在推薦系統(tǒng)中的用武之地,就是debias,讓平常聽慣了主流人群&物料的“陽春白雪”的模型,也多多感受一下非主流人群&物料的“下里巴人”。為了達到debias的目的,要求我們在實踐對比學(xué)習(xí)時,從樣本分布、參數(shù)共享、訓(xùn)練模式等方面要多加注意。 CL in Reco領(lǐng)域的好文不多,我分析了Google和阿里的兩篇文章,感受一下正確姿勢。特別是Google那一篇,推薦每個有意在推薦系統(tǒng)實踐對比學(xué)習(xí)的同學(xué),都仔細閱讀一遍。