
NLP場(chǎng)景中的對(duì)比學(xué)習(xí)模型SimCSE
導(dǎo)讀:本文是“數(shù)據(jù)拾光者”專欄的第三十五篇文章,這個(gè)系列將介紹在廣告行業(yè)中自然語(yǔ)言處理和推薦系統(tǒng)實(shí)踐。本篇從理論到實(shí)踐介紹了NLP場(chǎng)景下常用的對(duì)比學(xué)習(xí)模型SimCSE,對(duì)于希望將對(duì)比學(xué)習(xí)模型SimCSE應(yīng)用到NLP場(chǎng)景的小伙伴可能有所幫助。歡迎轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)注明出處以及鏈接,更多關(guān)于自然語(yǔ)言處理、推薦系統(tǒng)優(yōu)質(zhì)內(nèi)容請(qǐng)關(guān)注如下頻道。知乎專欄:數(shù)據(jù)拾光者 公眾號(hào):數(shù)據(jù)拾光者
摘要:本篇從理論到實(shí)踐介紹了NLP場(chǎng)景下常用的對(duì)比學(xué)習(xí)模型SimCSE。首先介紹了業(yè)務(wù)背景,經(jīng)過(guò)一系列調(diào)研NLP場(chǎng)景中簡(jiǎn)單有效的對(duì)比學(xué)習(xí)模型是SimCSE;然后重點(diǎn)介紹了SimCSE模型,包括評(píng)估對(duì)比學(xué)習(xí)模型的兩個(gè)指標(biāo)alignment和uniformity、NLP場(chǎng)景中使用對(duì)比學(xué)習(xí)模型的難點(diǎn)、SimCSE提出了一種基于dropout mask的方法來(lái)構(gòu)造正負(fù)例、dropout mask方式有效性原因分析、有監(jiān)督和無(wú)監(jiān)督的SimCSE模型以及BERT系列模型和SimCSE模型效果對(duì)比;最后項(xiàng)目實(shí)踐了SimCSE模型。對(duì)于希望將對(duì)比學(xué)習(xí)模型SimCSE應(yīng)用到NLP場(chǎng)景的小伙伴可能有所幫助。
下面主要按照如下思維導(dǎo)圖進(jìn)行學(xué)習(xí)分享:
01
背景介紹及模型調(diào)研
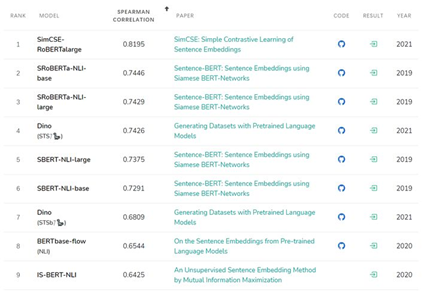
圖1 STS基準(zhǔn)任務(wù)各模型效果圖
同時(shí),蘇劍林也在文獻(xiàn)3中的中文數(shù)據(jù)集上進(jìn)行了完整的實(shí)驗(yàn),證明SimCSE模型的確優(yōu)于其他語(yǔ)義相似度模型。所以調(diào)研SimCSE希望能作為SimBERT的升級(jí)版本用于線上業(yè)務(wù)。
02
詳解NLP中的對(duì)比學(xué)習(xí)模型SimCSE
2.1 對(duì)比學(xué)習(xí)知識(shí)回顧
先簡(jiǎn)單回顧下對(duì)比學(xué)習(xí),對(duì)比學(xué)習(xí)最早出現(xiàn)在CV領(lǐng)域,因?yàn)镃V領(lǐng)域的研究者們想獲得一個(gè)類似NLP領(lǐng)域中BERT那樣的模型,可以通過(guò)無(wú)監(jiān)督學(xué)習(xí)的方法利用海量的數(shù)據(jù)集構(gòu)建預(yù)訓(xùn)練模型,從而獲取圖像的先驗(yàn)知識(shí),然后通過(guò)遷移學(xué)習(xí)將獲取的圖像知識(shí)應(yīng)用到下游任務(wù)中。對(duì)比學(xué)習(xí)的核心原則是:通過(guò)構(gòu)造相似實(shí)例和不相似實(shí)例獲得一個(gè)表示學(xué)習(xí)模型,通過(guò)這個(gè)模型可以讓相似的實(shí)例在投影的向量空間中盡可能的接近,而不相似的實(shí)例盡可能的遠(yuǎn)離。為了達(dá)到這個(gè)目的,對(duì)比學(xué)習(xí)模型需要完成三件事:第一件事是如何構(gòu)造相似實(shí)例和不相似實(shí)例;第二件事是如何構(gòu)造滿足上面對(duì)比學(xué)習(xí)核心原則的表示學(xué)習(xí)模型,也就是在向量空間中相似的實(shí)例距離盡可能接近,不相似的盡可能遠(yuǎn)離;第三件是如何防止模型坍塌。關(guān)于對(duì)比學(xué)習(xí)詳細(xì)的知識(shí)小伙伴可以看下我寫的上一篇文章:《廣告行業(yè)中那些趣事系列34:風(fēng)頭正勁的對(duì)比學(xué)習(xí)和項(xiàng)目實(shí)踐》。
本篇主要介紹的NLP場(chǎng)景中的對(duì)比學(xué)習(xí)模型SimCSE和經(jīng)典模型SimCLR模型類似,都屬于基于負(fù)例的對(duì)比學(xué)習(xí)方法。下面是SimCLR模型的整體結(jié)構(gòu)圖:
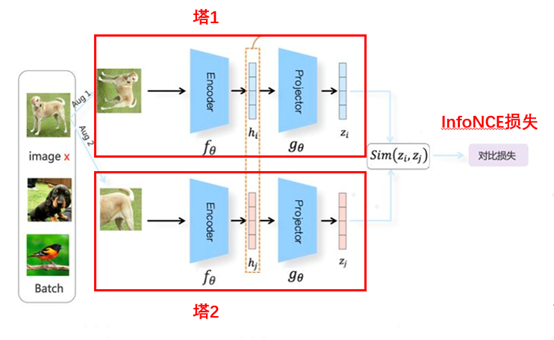
圖2 SimCLR模型整體結(jié)構(gòu)圖
SimCLR模型最早是應(yīng)用在圖像領(lǐng)域中的基于負(fù)例的對(duì)比學(xué)習(xí)模型,通過(guò)圖像樣本增強(qiáng)技術(shù)來(lái)構(gòu)造正負(fù)例,然后基于雙塔模型的思想構(gòu)造標(biāo)準(zhǔn)對(duì)稱模型,將圖像樣本經(jīng)過(guò)encode之后再經(jīng)過(guò)projector拿到最終的特征向量zi。最后通過(guò)InfoNCE損失函數(shù)來(lái)使模型讓相似的樣本距離盡可能接近,不相似的樣本盡可能遠(yuǎn)離。
2.2 如何評(píng)估對(duì)比學(xué)習(xí)模型的好壞
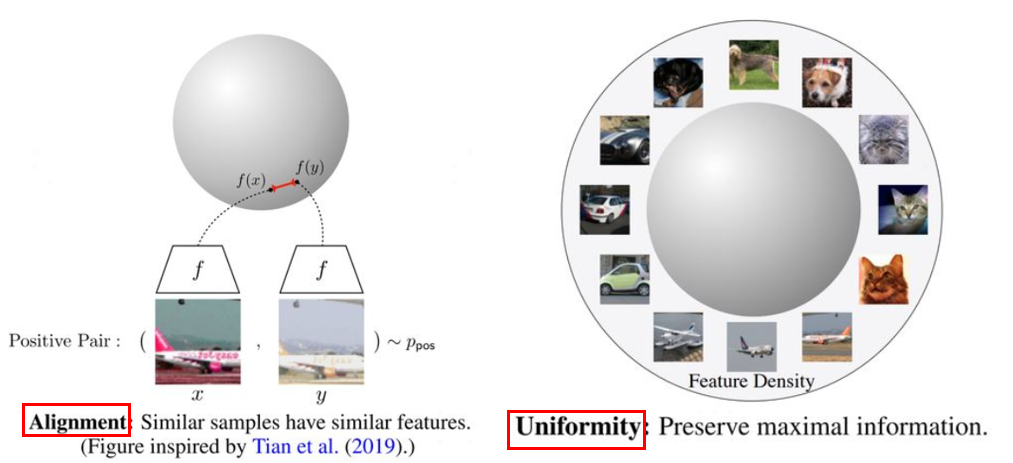
因?yàn)?span data-offset-key="2i9hj-0-1" style="font-weight: bold;">對(duì)比學(xué)習(xí)的目標(biāo)是獲得一個(gè)優(yōu)質(zhì)的語(yǔ)義表示學(xué)習(xí)空間,在這個(gè)空間中相似的樣本盡量拉近,不相似樣本盡量拉遠(yuǎn),那么如何評(píng)估這個(gè)空間是否優(yōu)質(zhì)?文獻(xiàn)2中提出了兩個(gè)評(píng)估對(duì)比學(xué)習(xí)模型優(yōu)劣的指標(biāo):alignment和uniformity。下面是兩個(gè)指標(biāo)的可視化視圖:
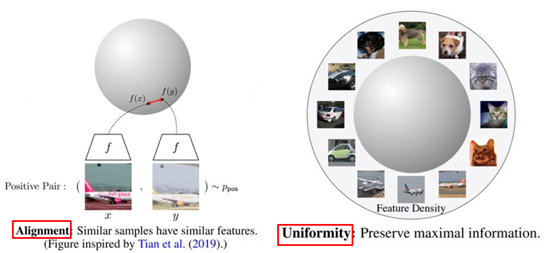
圖3 對(duì)比學(xué)習(xí)模型的兩個(gè)評(píng)估指標(biāo)
上圖中左邊部分是alignment指標(biāo),這個(gè)指標(biāo)希望在向量空間中兩個(gè)相似的向量距離應(yīng)該盡可能拉近,很好理解,基本就是對(duì)比學(xué)習(xí)的指導(dǎo)原則。右邊部分是uniformity指標(biāo),這個(gè)指標(biāo)希望樣本應(yīng)該均勻的分布在向量空間中,主要原因是樣本分布越均勻信息熵越高。舉一個(gè)通俗的例子,現(xiàn)在有個(gè)動(dòng)物園,我們希望動(dòng)物園里面各類動(dòng)物能盡量聚集在一起,同時(shí)我們還希望能更好的利用動(dòng)物園,也就是讓動(dòng)物們均勻的分布在動(dòng)物園里,讓空間更好的被利用。
2.3 NLP場(chǎng)景中應(yīng)用對(duì)比學(xué)習(xí)的難點(diǎn)
上面已經(jīng)講了在CV領(lǐng)域應(yīng)用對(duì)比學(xué)習(xí),其實(shí)將對(duì)比學(xué)習(xí)應(yīng)用到NLP場(chǎng)景中也非常簡(jiǎn)單,套路是通過(guò)樣本增強(qiáng)技術(shù)來(lái)構(gòu)造正負(fù)例,然后構(gòu)造標(biāo)準(zhǔn)對(duì)稱結(jié)構(gòu),可以直接用BERT模型來(lái)進(jìn)行encoder流程,至于是否需要再用BERT模型來(lái)進(jìn)行projector流程可以根據(jù)實(shí)驗(yàn)結(jié)果來(lái)決定是否需要添加。這樣的模型結(jié)構(gòu)已經(jīng)應(yīng)用在微博的CD-TOM模型中了。這里其他還好說(shuō),最麻煩的是如何構(gòu)造正負(fù)例,因?yàn)镃V領(lǐng)域中可以很輕松的進(jìn)行圖像增強(qiáng),比如對(duì)圖片進(jìn)行旋轉(zhuǎn)、縮放、灰度變換等操作,這些圖像增強(qiáng)技術(shù)不僅簡(jiǎn)單而且并不會(huì)帶來(lái)太大的噪聲。但是NLP領(lǐng)域中的樣本增強(qiáng)技術(shù)則復(fù)雜的多,效果也降低嚴(yán)重。這時(shí)候就期待一種簡(jiǎn)單有效的獲取相似文本的技術(shù)了。
2.4 基于dropout mask構(gòu)造正負(fù)例的SimCSE模型
關(guān)于文本增強(qiáng)技術(shù)其實(shí)之前也分享過(guò)一篇文章《廣告行業(yè)中那些趣事系列13:NLP中超實(shí)用的樣本增強(qiáng)技術(shù)》,里面講了包括樣本回譯、隨機(jī)替換等等操作。通過(guò)這些方法也可以進(jìn)行文本增強(qiáng)構(gòu)造正負(fù)例,但是整體來(lái)看這些方法效果并不是很理想,而SimCSE模型作者提出了一種通過(guò)隨機(jī)采樣dropout mask的操作來(lái)構(gòu)造相似樣本。具體操作是在標(biāo)準(zhǔn)的Transformer中會(huì)在全連接層和注意力求和操作上進(jìn)行dropout mask操作,模型訓(xùn)練的時(shí)候會(huì)將一條樣本x復(fù)制兩份,然后將這兩條樣本放到同一個(gè)編碼器中就可以得到兩個(gè)不同的表示向量z和zi。這么做的原因是BERT內(nèi)部每次dropout時(shí)都會(huì)隨機(jī)生成一個(gè)不同的dropout mask,所以不需要改變?cè)嫉腂ERT模型,只需要把樣本喂給模型兩次,就可以得到兩個(gè)不同dropout mask的結(jié)果,這樣就得到了相似樣本對(duì)。這種方式的好處是相似樣本的語(yǔ)義完全一致,只是生成的embedding不同而已,可以認(rèn)為是數(shù)據(jù)增強(qiáng)的最小形式。
2.5 為什么隨機(jī)dropout mask方式有效
小伙伴可能有疑問(wèn)了,為什么SimCSE這種隨機(jī)dropout mask方式會(huì)有效?為了證明隨機(jī)dropout mask方式的有效性,SimCSE模型的作者通過(guò)實(shí)驗(yàn)進(jìn)行論證。下圖是在STS-B數(shù)據(jù)集上幾種不同的樣本增強(qiáng)方法對(duì)比圖:
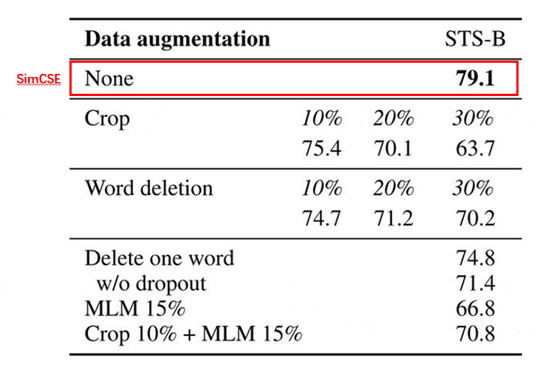
圖4 幾種不同的樣本增強(qiáng)方法效果對(duì)比
上圖中None是SimCSE模型的效果指標(biāo),Crop k%表示隨機(jī)減掉百分比k長(zhǎng)度的span,Word deletion表示隨機(jī)減掉百分比的詞,Delete one word表示隨機(jī)減掉一個(gè)詞,MLM 15%表示BERT模型隨機(jī)替換掉15%的詞等等。通過(guò)對(duì)比這些眼花繚亂的樣本增強(qiáng)技術(shù),最后證明SimCSE這種隨機(jī)采樣dropout mask的效果是最好的。
接著作者證明了采樣比例對(duì)模型效果的影響,下圖是對(duì)比不同的采樣比例模型效果圖:
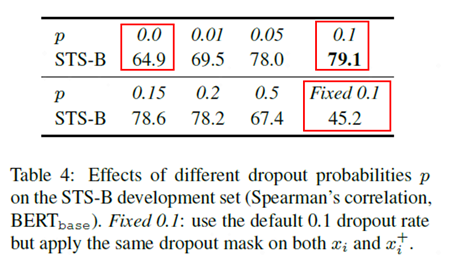
圖5 對(duì)比不同的采樣比例模型效果
從上圖可以看出,作者對(duì)比了從0到0.5不同隨機(jī)采樣比例下模型效果,其中效果最好的是使用0.1的隨機(jī)采樣比例。除此之外圖中還有兩種特殊指標(biāo):p=0和固定0.1時(shí)模型效果指標(biāo)較差。p=0時(shí)相當(dāng)于取消了隨機(jī)dropout mask,固定0.1相當(dāng)于對(duì)樣本進(jìn)行一樣的隨機(jī)dropout mask,這兩種操作都會(huì)讓得到的模型效果變差,主要原因是兩者得到的相似樣本對(duì)一模一樣,模型很難學(xué)到知識(shí)。
SimCSE模型作者通過(guò)可視化的方式從alignment和uniformity兩個(gè)指標(biāo)對(duì)比了幾種不同樣本增強(qiáng)的方法:
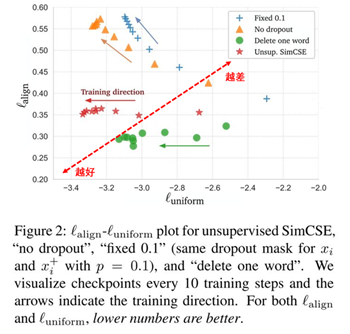
圖6 從alignment和uniformity對(duì)比模型效果
上圖中橫軸代表uniformity,縱軸代表alignment,模型效果越接近左下角越好,相反越接近右上角越差。整體來(lái)看通過(guò)SimCSE的隨機(jī)dropout mask操作模型的效果是最好的。Fixed 0.1和No dropout隨著uniformity效果提升alignment急速下降,而SimCSE因?yàn)閐ropout噪聲使得uniformity效果提升同時(shí)alignment穩(wěn)定在一個(gè)較好的范圍內(nèi)。雖然Delete one word的alignment相比于SimCSE有較小提升,但是uniformity卻差于SimCSE模型。
2.6 有監(jiān)督和無(wú)監(jiān)督兩種SimCSE模型結(jié)構(gòu)
SimCSE模型提供了有監(jiān)督和無(wú)監(jiān)督兩種語(yǔ)義相似度模型,下面是模型結(jié)構(gòu)圖:
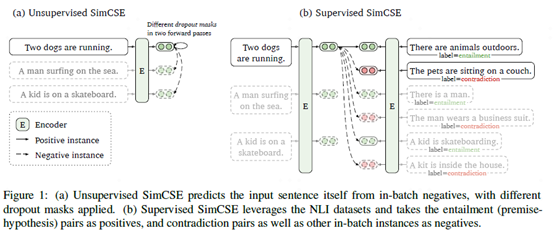
圖7 有監(jiān)督和無(wú)監(jiān)督SimCSE模型結(jié)構(gòu)
上圖中左邊部分是無(wú)監(jiān)督SimCSE模型,通過(guò)給定輸入x用BERT預(yù)訓(xùn)練模型隨機(jī)dropout mask編碼兩次得到相似樣本作為正例,batch內(nèi)其他樣本作為負(fù)例。訓(xùn)練目標(biāo)函數(shù)為:
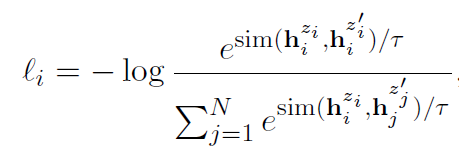
圖8 無(wú)監(jiān)督SimCSE模型訓(xùn)練目標(biāo)函數(shù)
右邊部分是有監(jiān)督SimCSE模型,使用NLI數(shù)據(jù)集中entailment關(guān)系樣例對(duì)作為正例。負(fù)例包括兩部分,第一部分是batch內(nèi)其他樣本作為負(fù)例,第二部分是NLI數(shù)據(jù)集中關(guān)系為contradiction的樣例對(duì)。訓(xùn)練目標(biāo)函數(shù)為:
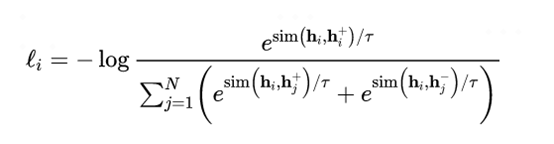
圖9 有監(jiān)督SimCSE模型訓(xùn)練目標(biāo)函數(shù)
2.7 BERT系列模型和SimCSE模型效果對(duì)比
學(xué)習(xí)SimCSE模型的一個(gè)重要原因是用于替代業(yè)務(wù)上常用的基于語(yǔ)義相似度匹配任務(wù)的SimBERT模型。SimBERT模型是追一科技蘇劍林開源的有監(jiān)督語(yǔ)義相似匹配模型,文獻(xiàn)3蘇神也在各種公共數(shù)據(jù)集上證明了SimCSE的確是目前SOTA。SimCSE模型作者從alignment和uniformity兩個(gè)指標(biāo)對(duì)比了各種BERT系列模型,下面是模型效果對(duì)比圖:
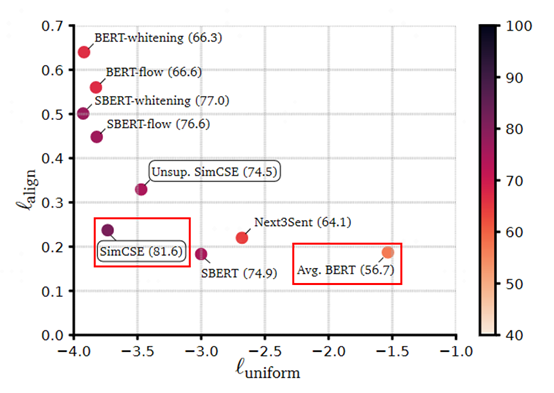
圖10 從alignment和uniformity對(duì)比BERT系列模型
從上圖中可以看出直接通過(guò)BERT模型來(lái)做無(wú)監(jiān)督語(yǔ)義相似度效果會(huì)比較差,主要原因是任意兩個(gè)句子的BERT句向量相似度比較高,向量分布的非線性和奇異性,使得BERT句向量并沒(méi)有均勻的分布在向量空間中,對(duì)應(yīng)的信息熵也比較低。針對(duì)這個(gè)問(wèn)題,BERT-flow通過(guò)normalizing flow把向量分布映射到規(guī)整的高斯分布中,有效的提升了uniformity。后來(lái)蘇神提出了BERT-whitening對(duì)向量分布進(jìn)行了PCA降維消除了冗余信息,進(jìn)一步提升了uniformity,但是alignment有一定降低。而SimCSE則提出了一種更高效的方案,使得alignment保持在較好效果上還能大幅度提升uniformity,達(dá)到了當(dāng)前的SOTA效果。
03
項(xiàng)目實(shí)踐SimCSE
上一節(jié)詳解了NLP場(chǎng)景中的對(duì)比學(xué)習(xí)模型SimCSE,這節(jié)從項(xiàng)目實(shí)踐的角度分享下SimCSE。SimCSE的作者進(jìn)行了項(xiàng)目開源,github地址如下:
https://github.com/princeton-nlp/SimCSE
使用起來(lái)非常簡(jiǎn)單,先安裝對(duì)應(yīng)的包:pip install simcse
下面是SimCSE模型應(yīng)用代碼:
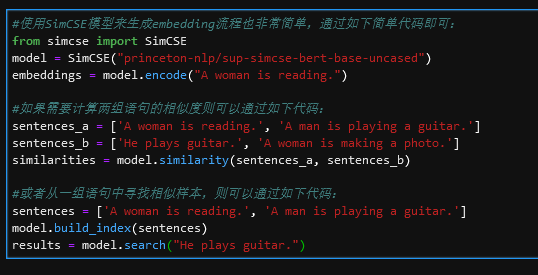
圖11 SimCSE模型應(yīng)用代碼
除了SimCSE作者開源的代碼,蘇神也開源了基于bert4keras框架的SimCSE模型代碼,并在公共數(shù)據(jù)集上補(bǔ)充了實(shí)驗(yàn)結(jié)果,感興趣的小伙伴可以看下文獻(xiàn)3。開源github地址如下:https://github.com/bojone/SimCSE
04
總結(jié)及反思
本篇從理論到實(shí)踐介紹了NLP場(chǎng)景下常用的對(duì)比學(xué)習(xí)模型SimCSE。首先介紹了業(yè)務(wù)背景,經(jīng)過(guò)一系列調(diào)研NLP場(chǎng)景中簡(jiǎn)單有效的對(duì)比學(xué)習(xí)模型是SimCSE;然后重點(diǎn)介紹了SimCSE模型,包括評(píng)估對(duì)比學(xué)習(xí)模型的兩個(gè)指標(biāo)alignment和uniformity、NLP場(chǎng)景中使用對(duì)比學(xué)習(xí)模型的難點(diǎn)、SimCSE提出了一種基于dropout mask的方法來(lái)構(gòu)造正負(fù)例、dropout mask方式有效性原因分析、有監(jiān)督和無(wú)監(jiān)督的SimCSE模型以及BERT系列模型和SimCSE模型效果對(duì)比;最后項(xiàng)目實(shí)踐了SimCSE模型。對(duì)于希望將對(duì)比學(xué)習(xí)模型SimCSE應(yīng)用到NLP場(chǎng)景的小伙伴可能有所幫助。
05
參考資料
[1] SimCSE: Simple Contrastive Learning of Sentence Embeddings
[2] Understanding Contrastive Representation Learning throughAlignment and Uniformity on the Hypersphere
[3] 蘇劍林. (Apr. 26, 2021). 《中文任務(wù)還是SOTA嗎?我們給SimCSE補(bǔ)充了一些實(shí)驗(yàn) 》[Blog post]. Retrieved from https://www.kexue.fm/archives/8348