
【NLP】NLP文本風(fēng)格遷移,秒變金庸風(fēng)
NewBeeNLP公眾號(hào)原創(chuàng)出品??
公眾號(hào)專欄作者@山竹小果
風(fēng)格遷移是自然語言生成領(lǐng)域一個(gè)非常火的主題,對于文本風(fēng)格遷移,先舉個(gè)例子:
Input:謝謝
Output(金庸):多謝之至Input:再見
Output(金庸):別過!Input:請問您貴性?
Output(金庸):請教閣下尊姓大名?
再潑個(gè)冷水:
目前自然語言生成(NLG)領(lǐng)域的研究還不太實(shí)用,所以希望像人一樣先理解句子,再改寫句子是不太現(xiàn)實(shí)的。
那么能否用機(jī)器翻譯的方法,不理解句子也能實(shí)現(xiàn)句子的轉(zhuǎn)換?這也是挺有局限的。機(jī)器翻譯需要使用使用大量的對齊語料進(jìn)行監(jiān)督學(xué)習(xí),應(yīng)該是不會(huì)有人專門標(biāo)注這樣的語料的。
不過在某些特定領(lǐng)域,可以通過一些巧妙的數(shù)據(jù)挖掘方式來獲取語料。例如根據(jù)新聞報(bào)道自動(dòng)生成評論或摘要等,這樣的題目現(xiàn)在很多人在做。假如把新聞?wù)Z料和新聞評論的關(guān)系也當(dāng)做“風(fēng)格轉(zhuǎn)換”的話,那么答案還是存在的。
相關(guān)工作 接下來我們看一些文本風(fēng)格遷移的工作,我們關(guān)心的:
文本風(fēng)格轉(zhuǎn)換是否可行? 用的什么方法?生成 or 翻譯? 評價(jià)標(biāo)準(zhǔn)?
論文 LIST
Unpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer Generating Sentences by Editing Prototypes Style Transfer from Non-Parallel Text by Cross-Alignment Style Transfer Through Back-Translation A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer A Hierarchical Reinforced Sequence Operation Method for Unsupervised Text Style Transfer
下面簡單看下前三篇:
Unpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach
第一篇工作,從題目來看就很吸引人,unpaired 對應(yīng) cycle,很自然聯(lián)想到 reconstruction。而 reinforcement learning 主要是為了解決訓(xùn)練過程中離散文本不可求導(dǎo)的問題。
雖然過去也有一些 text style transfer 的問題,但是因?yàn)槿鄙賹τ诜?stylish 或者說“普通文本”的語義信息的顯式保留,導(dǎo)致很容易出現(xiàn)下面這種情況:當(dāng)把“The food is delicious”這句話從正向情感遷移到負(fù)向情感時(shí),會(huì)得到“What a bad movie”——雖然情感被正確轉(zhuǎn)化了,但是內(nèi)容的主體也跟著變了。這顯然是不好的。
為了解決這個(gè)問題,這篇工作使用了兩個(gè) module,一個(gè) neutralization module 用于提取 non-emotional content,另一個(gè) emotionalization module 用于生成或者說融入 sentiment words。
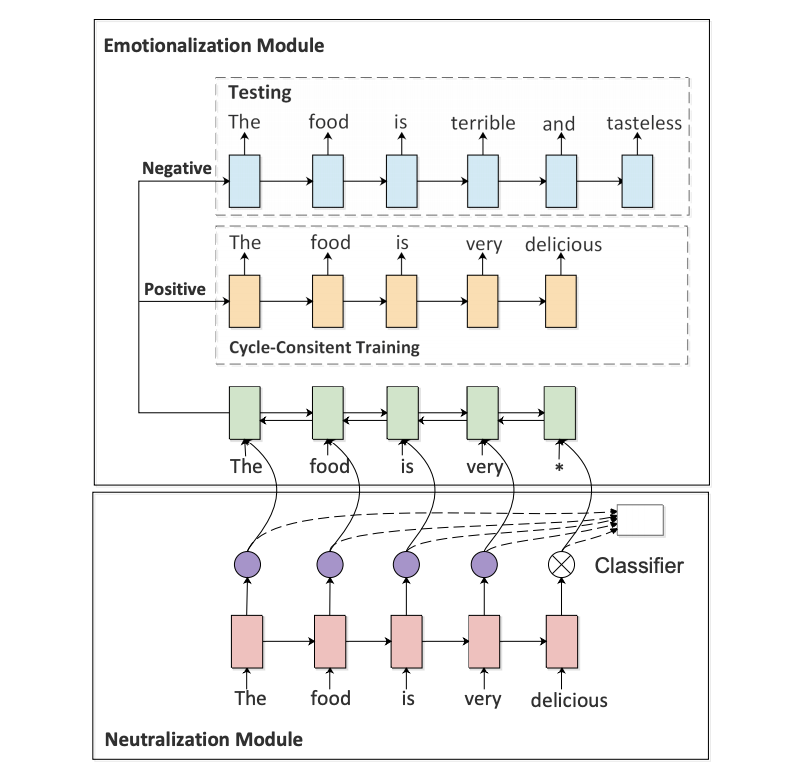
如上圖所示,下面的 neutralization module 其實(shí)是通過直接刪除emotional words 來實(shí)現(xiàn) non-emotional content 的保留。這一步中,作者通過使用 self-attention 得到的注意力權(quán)重作為分類器特征,從而自動(dòng)找出 emotional words。
從實(shí)驗(yàn)結(jié)果來看,這個(gè)方法的分類準(zhǔn)確率也可以達(dá)到 90% 左右(不過 sentiment classification 本身也不是很難,稍微復(fù)雜一點(diǎn)的模型都可以達(dá)到95%甚至更高)。
接下來就是 emotionalization module,可以看到,一個(gè) encoder 和兩個(gè) decoder。兩個(gè) decoder 對應(yīng) sentiment classification 的兩個(gè)類別(positive or negative),并且分別用于訓(xùn)練時(shí)的 reconstruction 和測試時(shí)的 generation(emotionalization)。
由于文本的離散性,作者采用了 RL 的方法來訓(xùn)練這兩個(gè) module。RL 成功與否嚴(yán)重依賴于獎(jiǎng)勵(lì)函數(shù)的設(shè)計(jì)。在這篇論文中,作者提出了兩個(gè) reward:sentiment confidence 和 BLEU。尤其是 BLEU,主要是針對作者想解決的問題——non-emotional content perserving。最終的獎(jiǎng)勵(lì)函數(shù)如下:
插播:BLEU(Bilingual Evaluation Understudy)
其中,
這里的BLEU值是針對一條翻譯(一個(gè)樣本)來說的。例子:
候選譯文(Predicted):It is a guide to action which ensures that the military always obeys the commands of the party
參考譯文(Gold Standard) 1:It is a guide to action that ensures that the military will forever heed Party commands
2:It is the guiding principle which guarantees the military forces always being under the command of the Party
3:It is the practical guide for the army always to heed the directions of the partyModified n-gram Precision計(jì)算也即Pn):
這里n取值為4,也就是從1-gram計(jì)算到4-gram。
首先統(tǒng)計(jì)候選譯文里每個(gè)詞出現(xiàn)的次數(shù),然后統(tǒng)計(jì)每個(gè)詞在參考譯文中出現(xiàn)的次數(shù),Max表示3個(gè)參考譯文中的最大值,Min表示候選譯文和參考譯文中的最大值的最小值。例如,詞"the":
然后將每個(gè)詞的Min值相加,將候選譯文每個(gè)詞出現(xiàn)的次數(shù)相加,然后兩值相除即得
類似得到2-gram 3-gram 4-gram的Pn,例如"ensures that":
然后我們?nèi)?1=?2=?3=?4=0.25,也就是Uniform Weights。得到:
下面計(jì)算BP(Brevity Penalty),翻譯過來就是“過短懲罰”。由BP的公式可知取值范圍是(0,1],候選句子越短,越接近0。
候選翻譯句子長度為18,參考翻譯分別為:16,18,16。所以?=18(候選翻譯句子長度),?=18(參考翻譯中選取長度最接近候選翻譯的作為r)
所以
整合:
????=1????(?0.684055269517)=0.504566684006
BLEU的取值范圍是[0,1],0最差,1最好。通過計(jì)算過程,我們可以看到,BLEU值其實(shí)也就是“改進(jìn)版的n-gram”加上“過短懲罰因子”。
從實(shí)驗(yàn)結(jié)果來看,過去的工作主要都只考慮了 style transfer 的成功與否(sentiment accuracy),而沒有顯性地考慮 content perserving,所以確實(shí)在 BLEU 指標(biāo)下表現(xiàn)很差。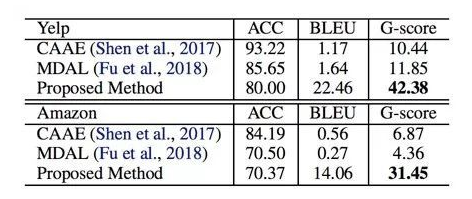
但是也可以看到,這篇工作提出的方法在大幅提高 BLEU 的情況下,ACC 也有一定損失。可以從這個(gè)結(jié)果看到,想要非常自然地融入 sentiment words 并且不破壞語義和語法,是很困難的事情。看一些直觀的轉(zhuǎn)換結(jié)果:
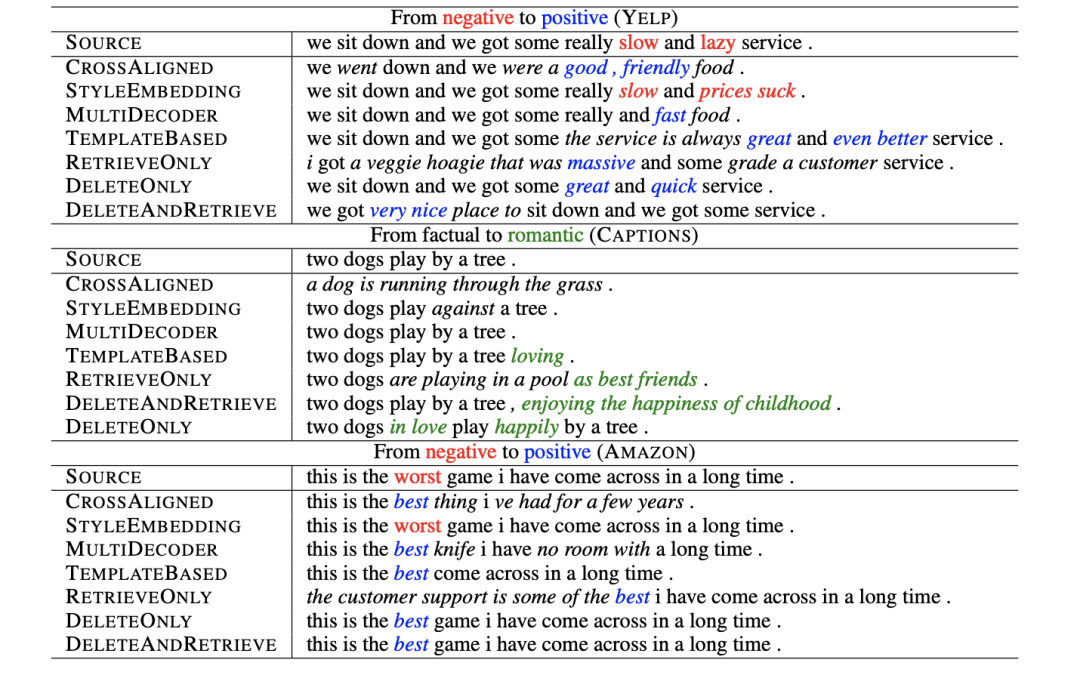
2. Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer
第二篇論文,幾乎也是一樣的思路。但是在具體實(shí)現(xiàn)上要更直接一點(diǎn)。第二篇論文在進(jìn)行 style transfer 的時(shí)候,基于的是這樣的假設(shè):文本的一些屬性(attribute),比如文本傳達(dá)出來的情感信息等,可以體現(xiàn)在文本中的某些特定詞匯上。通過改變這些詞匯,就可能直接改變整句文本的性質(zhì)屬性(value)。
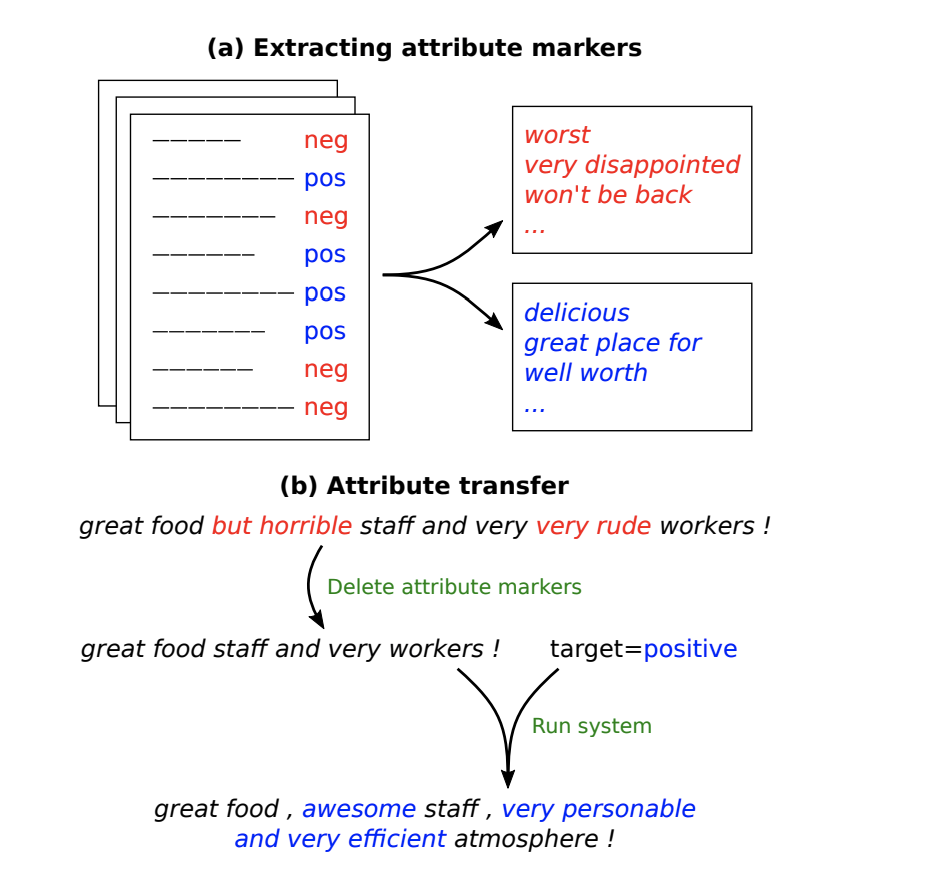
由上面的示意圖可以看出,作者將那些具有指示功能的特定詞稱為 attribute marker,通過(主要)改變這些 marker,進(jìn)行 attribute transfer。文章進(jìn)一步提出了4種具體的方法來改變 marker。
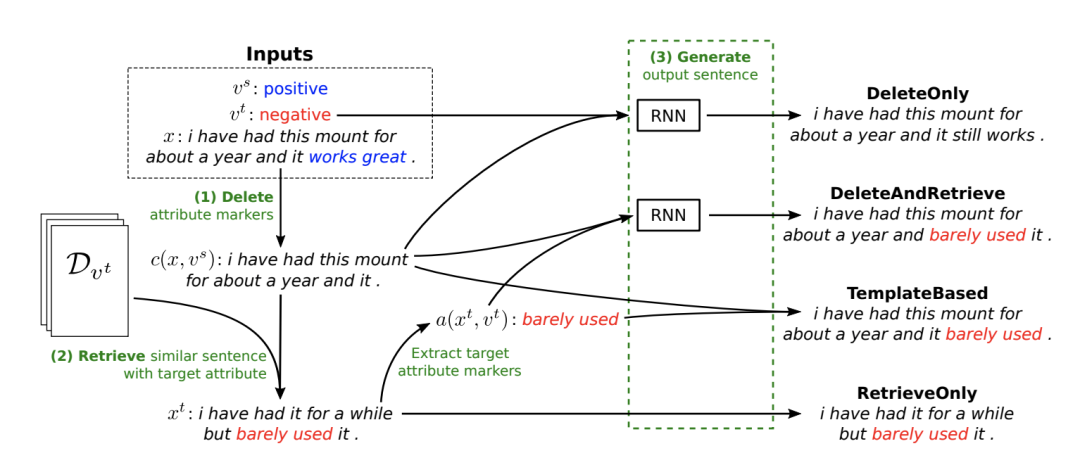
這4種具體的方式也由上圖很清晰地展示了出來。值得一提的是 DeleteOnly 和 DeleteAndRetrieve。在刪除了具體的 marker 后,作者提出再去根據(jù)這個(gè)沒有情感特定性的句子去從數(shù)據(jù)中檢索出一句最相似但是 attribute 的數(shù)值相反(target attribute)的話。檢索出的這句話主要用于提取新的 target attribute marker,作為“重寫” RNN 的輸入之一。
很明顯,這樣的工作可能有一定局限性,但在一些簡化場景中,卻是更可控的。其實(shí)驗(yàn)結(jié)果也印證了這點(diǎn)。
3. Generating Sentences by Editing Prototypes
上面兩篇工作都是進(jìn)行風(fēng)格轉(zhuǎn)換,而在進(jìn)行文本改寫的時(shí)候,還有一類常見的場景就是進(jìn)行非情感類改寫,比如擴(kuò)寫句子,改寫語法錯(cuò)誤等。在進(jìn)行這樣的工作時(shí),其實(shí)也可以采用類似的思路。先找到一個(gè)“中立”的、“簡單”的“模板”,再在這個(gè)基礎(chǔ)上加入希望增加的信息,如情感、一些復(fù)雜修飾詞等等。今天要分享的最后一篇工作就是這樣一個(gè)思路。
從上面的示意圖中可以看到,修改后的句子增加了“modiocre”和“ridiculous”這兩個(gè)形容詞,變得更復(fù)雜了。而重中之重就是在學(xué)習(xí) edit vector 上。
可以看到,此時(shí)的 edit vector 不再是 sentiment words,而是一種 semantic operation。如果讓 edit vector 作為一種隱變量,也遵循某種分布,那么同樣的 edit vector 應(yīng)該符合同一種 edit operation,并且對于句子的改寫是一種微小的可控的操作。
基于這樣的假設(shè)和期望,作者用 VAE 來建模 z,目標(biāo)函數(shù)如下:
關(guān)鍵就是如何保證學(xué)到好的 p 和 q。這篇論文使用的方式和過去很多 VAE 的文本應(yīng)用都不太一樣,有興趣的同學(xué)請一定去查閱原文。值得一提的是,這篇工作中的 edit vector z 是直接拼接在給 decoder 的每一個(gè)時(shí)刻的輸入上的,并沒有額外的 gate 或者 transform。這也是和上面兩篇工作的區(qū)別之一。
最后從結(jié)果來看,作者提出的方法確實(shí)能更自然地改寫句子。這點(diǎn)從 case studies 還有句子的平滑度方面可以看出:
Summary
目前的方法大概就是深度學(xué)習(xí)在外加使用policy gradient的方法,對于文本的生成的損失函數(shù)只論詞的生成概率,可添加語言規(guī)則的損失項(xiàng),類似詞性,情感等之類,可以提升,而后在beam search階段也可添加語言規(guī)則,而不是以只關(guān)注概率。
另則,現(xiàn)在的文本風(fēng)格遷移在人類的角度來看過于easy,離我們想象中的文本風(fēng)格遷移還有很大一段距離。
往期精彩回顧
獲取本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群請掃碼: