
我用Transformer修復(fù)代碼bug

來(lái)源:機(jī)器之心 本文約3900字,建議閱讀7分鐘
本文介紹了一種預(yù)訓(xùn)練模型transformer進(jìn)行自動(dòng)debug的方法。

論文標(biāo)題:
DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons
論文鏈接:
https://arxiv.org/pdf/2105.09352.pdf
引言
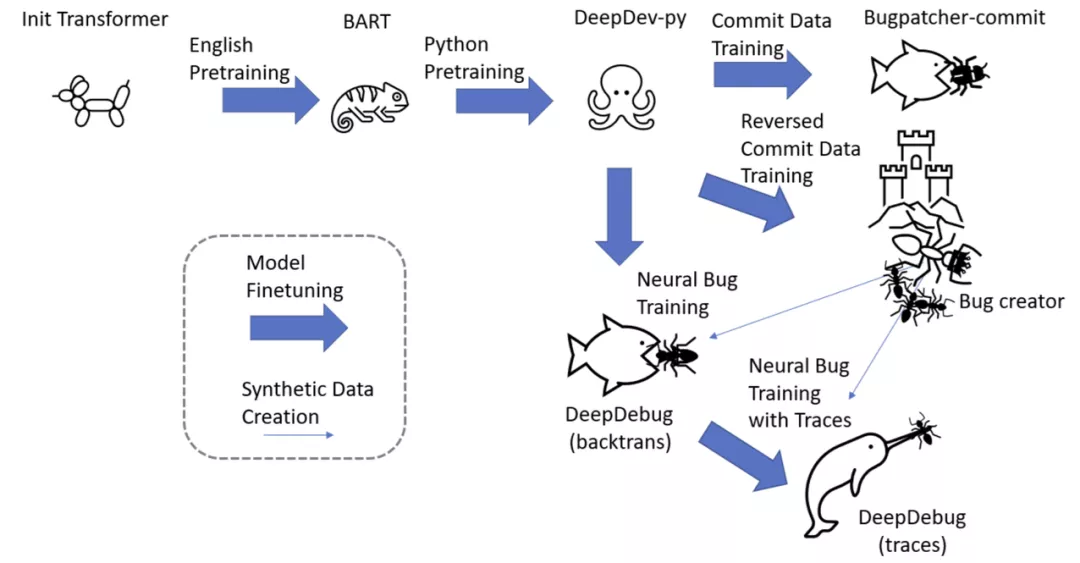
▲訓(xùn)練 pipeline
模型
數(shù)據(jù)
用于預(yù)訓(xùn)練的原始 python 代碼; 用于訓(xùn)練神經(jīng) bug 創(chuàng)建和 bug 修補(bǔ)程序的 commit 數(shù)據(jù); 從原始代碼中提取的方法,其中插入了神經(jīng) bug 以訓(xùn)練更強(qiáng)大的 bug 修補(bǔ)程序; 通過(guò)可執(zhí)行測(cè)試的方法。
預(yù)訓(xùn)練
commit 的數(shù)據(jù)
合成 bug
將點(diǎn)訪(fǎng)問(wèn)器替換為方括號(hào)訪(fǎng)問(wèn)器; 將截?cái)噫溄拥暮瘮?shù)調(diào)用; 刪除返回行; 將返回值封裝在元組和字典等對(duì)象中然后忘記封裝對(duì)象; 將 IndexError 等精確錯(cuò)誤替換為 ValueError 等不同的錯(cuò)誤; 誤命名變量諸如 self.result 而不是 self._result; 錯(cuò)誤地按引用復(fù)制而不是按值復(fù)制。研究者幾乎應(yīng)用了以前文獻(xiàn)中已報(bào)道的所有啟發(fā)式 bug。

可執(zhí)行測(cè)試的方法
追蹤法:除了使用測(cè)試對(duì)不正確的編輯進(jìn)行分類(lèi)之外,還以三種不同的方式將來(lái)自測(cè)試的信息整合到訓(xùn)練中:將錯(cuò)誤消息附加到 buggy 方法中,另外附加了棧追蹤,并進(jìn)一步使用測(cè)試框架 Pytest 提供了故障處的所有局部變量值; 收集通過(guò)測(cè)試法:為了以訓(xùn)練規(guī)模收集可執(zhí)行的測(cè)試,從用于預(yù)訓(xùn)練的 20 萬(wàn)個(gè)庫(kù)開(kāi)始,過(guò)濾到包含測(cè)試和 setup.py 或 requirements.txt 文件的 3.5 萬(wàn)個(gè)庫(kù)。對(duì)于這些庫(kù)中的每一個(gè),都在唯一的容器中執(zhí)行 Pytest,最終從 1 萬(wàn)個(gè)庫(kù)中收集通過(guò)的測(cè)試; 合成 bug 測(cè)試法:在過(guò)濾通過(guò)可執(zhí)行測(cè)試的函數(shù)并插入神經(jīng) bug 之后,重新運(yùn)行測(cè)試以收集 Pytest 追蹤,并濾除仍通過(guò)測(cè)試并因此實(shí)際上不是 buggy 的已編輯函數(shù)。
實(shí)驗(yàn)及結(jié)果
反向翻譯數(shù)據(jù)


添加框架

Pytest 棧追蹤

編輯:于騰凱
校對(duì):龔力
評(píng)論
圖片
表情