
Python高頻使用代碼集錦!
本文記錄的是個(gè)人高頻使用的數(shù)據(jù)分析和機(jī)器學(xué)習(xí)代碼片段,包含的主要內(nèi)容:
pandas設(shè)置 可視化 jieba分詞 缺失值處理 特征分布 數(shù)據(jù)歸一化 上下采樣 回歸與分類模型 模型評(píng)價(jià)等

常用庫
import?numpy?as?np
import?pandas?as?pd
pd.set_option(?'display.precision',6)???#?小數(shù)精度6位
pd.set_option("display.max_rows",999)??#?最多顯示行數(shù)
pd.reset_option("display.max_rows")??#?重置
pd.set_option('display.max_columns',100)??#?最多顯示列100
pd.set_option('display.max_columns',None)??#?顯示全部列
pd.set_option?('display.max_colwidth',?100)??#?列寬
pd.reset_option('display.max_columns')?#?重置
pd.set_option("expand_frame_repr",?True)??#?折疊
pd.set_option('display.float_format',??'{:,.2f}'.format)??#?千分位
pd.set_option('display.float_format',?'{:.2f}%'.format)??#?百分比形式
pd.set_option('display.float_format',?'{:.2f}¥'.format)??#?特殊符號(hào)
pd.options.plotting.backend?=?"plotly"??#?修改繪圖
pd.set_option("colheader_justify","left")??#?列字段對(duì)齊方式
pd.reset_option('all')??#?全部功能重置
#?忽略notebook中的警告
import?warnings
warnings.filterwarnings("ignore")
可視化
#?1、基于plotly
import?plotly?as?py
import?plotly.express?as?px
import?plotly.graph_objects?as?go
py.offline.init_notebook_mode(connected?=?True)
from?plotly.subplots?import?make_subplots??#?多子圖
#?2、基于matplotlib
import?matplotlib.pyplot?as?plt
import?matplotlib.patches?as?mpatches
%matplotlib?inline
#?中文顯示問題
plt.rcParams["font.sans-serif"]=["SimHei"]?#設(shè)置字體
plt.rcParams["axes.unicode_minus"]=False?#正常顯示負(fù)號(hào)
#?3、基于seaborn
import?seaborn?as?sns
#?plt.style.use("fivethirtyeight")
plt.style.use('ggplot')
#?4、基于Pyecharts
from?pyecharts.globals?import?CurrentConfig,?OnlineHostType
from?pyecharts?import?options?as?opts??#?配置項(xiàng)
from?pyecharts.charts?import?Bar,?Pie,?Line,?HeatMap,?Funnel,?WordCloud,?Grid,?Page??#?各個(gè)圖形的類
from?pyecharts.commons.utils?import?JsCode
from?pyecharts.globals?import?ThemeType,SymbolType
1、柱狀圖帶顯示數(shù)值:
fig?=?px.bar(df4,?x="name",y="成績",text="成績")
fig.update_traces(textposition="outside")
fig.update_layout(xaxis_tickangle=45)???#?傾斜角度設(shè)置
fig.show()
2、餅圖帶顯示類型名稱:
fig?=?px.pie(df,??#?以城市和數(shù)量為字段
?????????????names="城市",
?????????????values="數(shù)量"
????????????)
fig.update_traces(
????textposition='inside',
????textinfo='percent+label'
)
fig.update_layout(
????title={
????????"text":"城市占比",
????????"y":0.96,??#?y軸數(shù)值
????????"x":0.5,??#?x軸數(shù)值
????????"xanchor":"center",??#?x、y軸相對(duì)位置
????????"yanchor":"top"
????}
)
fig.show()
3、seaborn箱型圖
#?方式1
ax?=?sns.boxplot(y=df["total_bill"])
#?方式2:傳入y和data參數(shù)
ax?=?sns.boxplot(y="total_bill",?data=df)
4、plotly子圖繪制,假設(shè)是28個(gè)圖,生成7*4的子圖:
jieba分詞與詞云圖
import?jieba
title_list?=?df["title"].tolist()
#?分詞過程
title_jieba_list?=?[]
for?i?in?range(len(title_list)):
????#?jieba分詞
????seg_list?=?jieba.cut(str(title_list[i]).strip(),?cut_all=False)
????for?each?in?list(seg_list):
????????title_jieba_list.append(each)
????????
#?創(chuàng)建停用詞list
def?StopWords(filepath):
????stopwords?=?[line.strip()?for?line?in?open(filepath,?'r',?encoding='utf-8').readlines()]
????return?stopwords
#?傳入停用詞表的路徑:路徑需要修改
stopwords?=?StopWords("/Users/Desktop/spider/nlp_stopwords.txt")
#?收集有用詞語
useful_result?=?[]
for?col?in?title_jieba_list:
????if?col?not?in?stopwords:
????????useful_result.append(col)
????????
information?=?pd.value_counts(useful_result).reset_index()
information.columns=["word","number"]
#?詞云圖
information_zip?=?[tuple(z)?for?z?in?zip(information_new["word"].tolist(),?information_new["number"].tolist())]
#?繪圖
c?=?(
????WordCloud()
????.add("",?information_zip?word_size_range=[20,?80],?shape=SymbolType.DIAMOND)
????.set_global_opts(title_opts=opts.TitleOpts(title="詞云圖"))
)
c.render_notebook()
數(shù)據(jù)探索
import?pandas?as?pd
df?=?pd.read_csv("data.csv")
df.shape?#?數(shù)據(jù)形狀
df.isnull().sum()??#?缺失值
df.dtypes??#?字段類型
df.describe??#?描述統(tǒng)計(jì)信息
缺失字段可視化
import?missingno?as?mso
mso.bar(df,color="blue")
plt.show()
刪除字段
#?刪除某個(gè)非必須屬性
df.drop('Name',?axis=1,?inplace=True)
缺失值填充
以字段的現(xiàn)有數(shù)據(jù)中位數(shù)進(jìn)行填充為例:
#?transform之前要指定操作的列(Age),它只能對(duì)某個(gè)列進(jìn)行操作
df['Age'].fillna(train.groupby('Title')['Age'].transform("median"),?inplace=True)
字段位置重置
#?1、單獨(dú)提出來
scaled_amount?=?df['amount']
#?2、刪除原字段信息
df.drop(['amount'],?axis=1,?inplace=True)
#?3、插入
df.insert(0,?'amount',?scaled_amount)
數(shù)據(jù)集劃分
from?sklearn.model_selection?import?train_test_split
from?sklearn.model_selection?import?StratifiedShuffleSplit
X?=?df.drop("Class",?axis=1)??#?特征
y?=?df["Class"]??#?標(biāo)簽
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,y,test_size=0.2,random_state=44)
#?3、將數(shù)據(jù)轉(zhuǎn)成數(shù)組,然后傳給模型
X_train?=?X_train.values
X_test?=?X_test.values
y_train?=?y_train.values
y_test?=?y_test.values
數(shù)據(jù)標(biāo)準(zhǔn)化/歸一化
基于numpy來實(shí)現(xiàn)
#?基于numpy實(shí)現(xiàn)
mean?=?X_train.mean(axis=0)
X_train?-=?mean??
std?=?X_train.std(axis=0)
X_train?/=?std
#?測(cè)試集:使用訓(xùn)練集的均值和標(biāo)準(zhǔn)差來歸一化
X_test?-=?mean?
X_test?/=?std
基于sklearn實(shí)現(xiàn)

相關(guān)性熱力圖
f,?ax1?=?plt.subplots(1,1,figsize=(24,?20))
corr?=?df.corr()
sns.heatmap(corr,?cmap="coolwarm_r",annot_kws={"size":20})
ax.set_title("Correlation?Matrix",?fontsize=14)
屬性間相關(guān)性
cols?=?["col1",?"col2",?"col3"]
plt.figure(1,figsize=(15,6))
n?=?0
for?x?in?cols:
????for?y?in?cols:
????????n?+=?1??#?每循環(huán)一次n增加,子圖移動(dòng)一次
????????plt.subplot(3,3,n)??#?3*3的矩陣,第n個(gè)圖形
????????plt.subplots_adjust(hspace=0.5,?wspace=0.5)??#?子圖間的寬、高參數(shù)
????????sns.regplot(x=x,y=y,data=df,color="#AE213D")??#?繪圖的數(shù)據(jù)和顏色
????????plt.ylabel(y.split()[0]?+?"?"?+?y.split()[1]?if?len(y.split())?>?1?else?y)
plt.show()
刪除離群點(diǎn)
刪除基于上下四分位的離群點(diǎn):
#?數(shù)組
v12?=?df["V12"].loc[df["Class"]?==?1]
#?25%和75%分位數(shù)
q1,?q3?=?v12.quantile(0.25),?v12.quantile(0.75)
iqr?=?q3?-?q1
#?確定上下限
v12_cut_off?=?iqr?*?1.5
v12_lower?=?q1?-?v12_cut_off
v12_upper?=?q3?+?v12_cut_off
#?確定離群點(diǎn)
outliers?=?[x?for?x?in?v12?if?x?or?x?>?v12_upper]
#?技巧:如何刪除異常值
new_df?=?df.drop(df[(df["V12"]?>?v12_upper)?|?(df["V12"]?離群點(diǎn)填充均值
df['Price']=np.where(df['Price']>=40000,??#?大于等于40000看成異常值
?????????????????????df['Price'].median(),?#?替換均值
?????????????????????df['Price'])?#?替換字段
特征分布
1、特征取值數(shù)量統(tǒng)計(jì)
df["Class"].value_counts(normalize=True)
plt.figure(1,?figsize=(12,5))
sns.countplot(y="sex",?data=df)
plt.show()
2、基于seaborn繪圖
#?繪圖
colors?=?["red",?"blue"]?
sns.countplot("Class",?data=df,?palette=colors)
plt.title("0-No?Fraud?&?1-Fraud)")
plt.show()
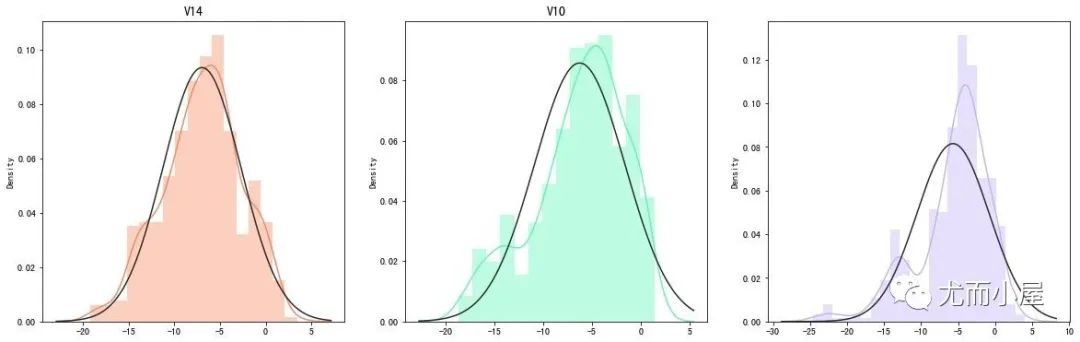
3、特征直方圖分布
效果:
另一種方法:
#?繪圖
plt.figure(1,figsize=(15,6))??
n?=?0
for?col?in?cols:
????n?+=?1?#?子圖位置
????plt.subplot(1,3,n)??
????plt.subplots_adjust(hspace=0.5,wspace=0.5)??#?調(diào)整寬高
????sns.distplot(df[col],bins=20)??#?繪制直方圖
????plt.title(f'Distplot?of?{col}')??
plt.show()??#?顯示圖形
特征重要性
from?sklearn.feature_selection?import?mutual_info_classif
imp?=?pd.DataFrame(mutual_info_classif(X,y),
??????????????????index=X.columns)
imp.columns=['importance']
imp.sort_values(by='importance',ascending=False)
2種編碼
Nominal?data?--?Data?that?are?not?in?any?order?-->one?hot?encoding
ordinal?data?--?Data?are?in?order?-->?labelEncoder
標(biāo)稱數(shù)據(jù):沒有任何順序,使用獨(dú)熱編碼oneot encoding 有序數(shù)據(jù):存在一定的順序,使用類型編碼labelEncoder
獨(dú)熱碼的實(shí)現(xiàn):
df["sex"]?=?pd.get_dummies(df["sex"])
基于有序數(shù)據(jù)的類型編碼自定義:
dic?=?{"v1":1,?"v2":2,?"v3":3,?"v4":4}
df["class"]?=?df["class"].map(dic)
sklearn實(shí)現(xiàn)類型編碼:
from?sklearn.preprocessing?import?LabelEncoder
le?=?LabelEncoder()
for?i?in?['Route1',?'Route2',?'Route3',?'Route4',?'Route5']:
????categorical[i]=le.fit_transform(categorical[i])
上、下采樣
上采樣
#?使用imlbearn庫中上采樣方法中的SMOTE接口
from?imblearn.over_sampling?import?SMOTE
#?設(shè)置隨機(jī)數(shù)種子
smo?=?SMOTE(random_state=42)
X_smo,?y_smo?=?smo.fit_resample(X,?y)
下采樣
#?欺詐的數(shù)據(jù)
fraud_df?=?df[df["Class"]?==?1]??#?少量數(shù)據(jù)
#?從非欺詐的數(shù)據(jù)中取出相同的長度len(fraud_df)
no_fraud_df?=?df[df["Class"]?==?0][:len(fraud_df)]
#?組合
normal_distributed_df?=?pd.concat([fraud_df,?no_fraud_df])
#?隨機(jī)打亂數(shù)據(jù)
new_df?=?normal_distributed_df.sample(frac=1,?random_state=123)
PCA降維
from?sklearn.manifold?import?TSNE
from?sklearn.decomposition?import?PCA,?TruncatedSVD
#?PCA降維
X_reduced_pca?=?PCA(n_components=2,
????????????????????random_state=42).fit_transform(X.values)
sklearn使用k折交叉驗(yàn)證
隨機(jī)打亂數(shù)據(jù)并生成索引:
Keras使用交叉驗(yàn)證
Keras中的k折交叉驗(yàn)證:

回歸模型
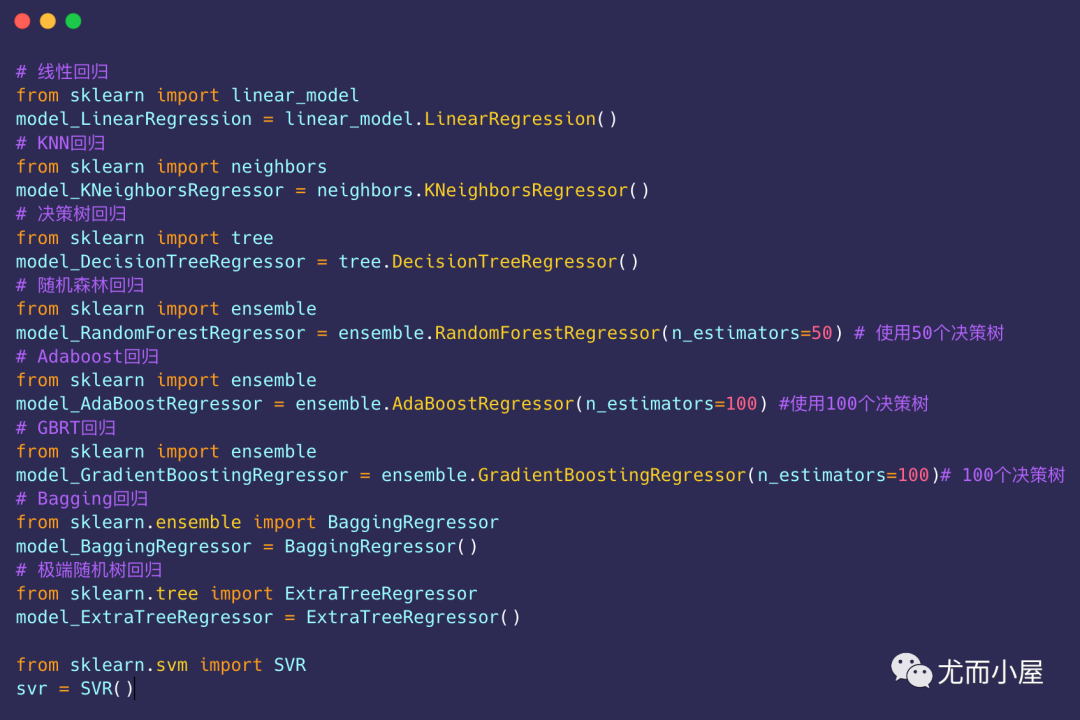
回歸模型評(píng)分
from?sklearn.metrics?import?r2_score,mean_absolute_error,mean_squared_error
def?predict(ml_model):
????print("Model?is:?",?ml_model)
????model?=?ml_model.fit(X_train,?y_train)
????print("Training?score:?",?model.score(X_train,y_train))
????predictions?=?model.predict(X_test)
????print("Predictions:?",?predictions)
????print('-----------------')
????r2score?=?r2_score(y_test,?predictions)
????print("r2?score?is:?",?r2score)
????print('MAE:{}',?mean_absolute_error(y_test,predictions))
????print('MSE:{}',?mean_squared_error(y_test,predictions))
????print('RMSE:{}',?np.sqrt(mean_squared_error(y_test,predictions)))
????#?真實(shí)值和預(yù)測(cè)值的差值
????sns.distplot(y_test?-?predictions)
分類模型

混淆矩陣
分類任務(wù)的混淆矩陣
from?sklearn?import?metrics??#?模型評(píng)價(jià)
confusion_matrix?=?metrics.confusion_matrix(y_test,?y_pred)
auc值
auc?=?metrics.roc_auc_score(y_test,?y_pred)??#?測(cè)試值和預(yù)測(cè)值
ROC曲線
from?sklearn.metrics?import?roc_curve,?auc
false_positive_rate,?true_positive_rate,?thresholds?=?roc_curve(y_test,?y_prob)??#?y的真實(shí)值和預(yù)測(cè)值
#?roc值
roc?=?auc(false_positive_rate,?true_positive_rate)
import?matplotlib.pyplot?as?plt
plt.figure(figsize=(10,10))
plt.title('ROC')
plt.plot(false_positive_rate,true_positive_rate,?color='red',label?=?'AUC?=?%0.2f'?%?roc_auc)
plt.legend(loc?=?'lower?right')
plt.plot([0,?1],?[0,?1],linestyle='--')
plt.axis('tight')
plt.ylabel('True?Positive?Rate')
plt.xlabel('False?Positive?Rate')
plt.show()
網(wǎng)絡(luò)搜索
以邏輯回歸為例:
from?sklearn.model_selection?import?GridSearchCV
#?邏輯回歸
lr_params?=?{"penalty":["l1",?"l2"],
?????????????"C":?[0.001,?0.01,?0.1,?1,?10,?100,?1000]
????????????}
grid_lr?=?GridSearchCV(LogisticRegression(),?lr_params)
grid_lr.fit(X_train,?y_train)
#?最好的參數(shù)組合
best_para_lr?=?grid_lr.best_estimator_
隨機(jī)搜索
以隨機(jī)森林模型為例為例:
#?采用隨機(jī)搜索調(diào)優(yōu)
from?sklearn.model_selection?import?RandomizedSearchCV
#?待調(diào)優(yōu)的參數(shù)
random_grid?=?{
????'n_estimators'?:?[100,?120,?150,?180,?200,220],
????'max_features':['auto','sqrt'],
????'max_depth':[5,10,15,20],
????}
#?建模擬合
rf=RandomForestRegressor()
rf_random=RandomizedSearchCV(
??estimator=rf,
??param_distributions=random_grid,
??cv=3,
??verbose=2,
??n_jobs=-1)
rf_random.fit(X_train,y_train)對(duì)比Excel系列圖書累積銷量達(dá)15w冊(cè),讓你輕松掌握數(shù)據(jù)分析技能,可以在全網(wǎng)搜索書名進(jìn)行了解選購:

評(píng)論
圖片
表情