
怎么用Python畫出好看的詞云圖?

? ? ?作者:易執(zhí)
? ? ?來源:Python讀數(shù)
相信很多人在第一眼看到下面這些圖時,都會被其牛逼的視覺效果所吸引,這篇文章就教大家怎么用Python畫出這種圖。

前期準備
上面的這種圖叫做詞云圖,主要用途是將文本數(shù)據(jù)中出現(xiàn)頻率較高的關(guān)鍵詞以可視化的形式展現(xiàn)出來,使人一眼就可以領(lǐng)略文本數(shù)據(jù)的主要表達意思。詞云圖中,詞的大小代表了其詞頻,越大的字代表其出現(xiàn)頻率更高。
那生成一張詞云圖的主要步驟有哪些?過程中又需要用到哪些Python庫呢?
首先需要一份待分析的文本數(shù)據(jù),由于文本數(shù)據(jù)都是一段一段的,所以第一步要將這些句子或者段落劃分成詞,這個過程稱之為分詞,需要用到Python中的分詞庫
jieba。分詞之后,就需要根據(jù)分詞結(jié)果生成詞云,這個過程需要用到
wordcloud庫最后需要將生成的詞云展現(xiàn)出來,用到大家比較熟悉的
matplotlib
理清了詞云圖繪制的主要脈絡(luò)之后,下面就用代碼操作起來。
小試牛刀明天就過年了,所以我也特地去找了幾首新年歌,將它們的歌詞匯總起來作為本次展示用的文本數(shù)據(jù),大家可以看看新年歌中哪些詞的出現(xiàn)頻率比較高。我們先繪制一個比較簡單的詞云圖:
# 導(dǎo)入相應(yīng)的庫import jiebafrom wordcloud import WordCloudimport matplotlib.pyplot as plt# 導(dǎo)入文本數(shù)據(jù)并進行簡單的文本處理# 去掉換行符和空格text = open("./data/新年歌.txt",encoding='utf8').read()text = text.replace('\n',"").replace("\u3000","")
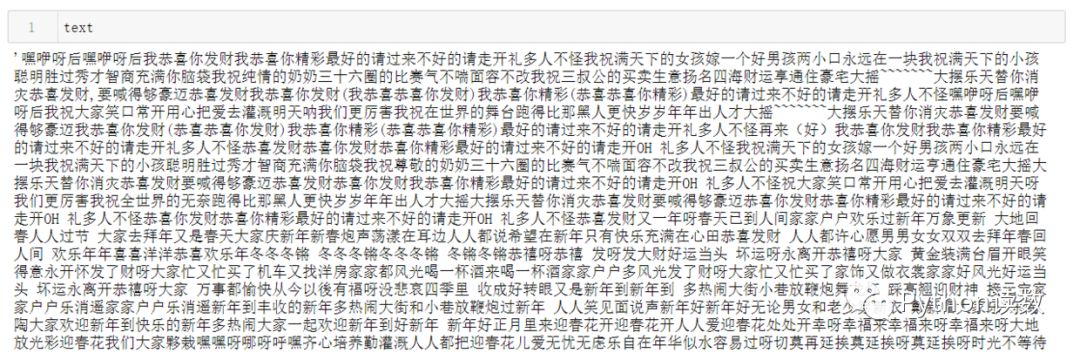
# 分詞,返回結(jié)果為詞的列表text_cut = jieba.lcut(text)# 將分好的詞用某個符號分割開連成字符串text_cut = ' '.join(text_cut)
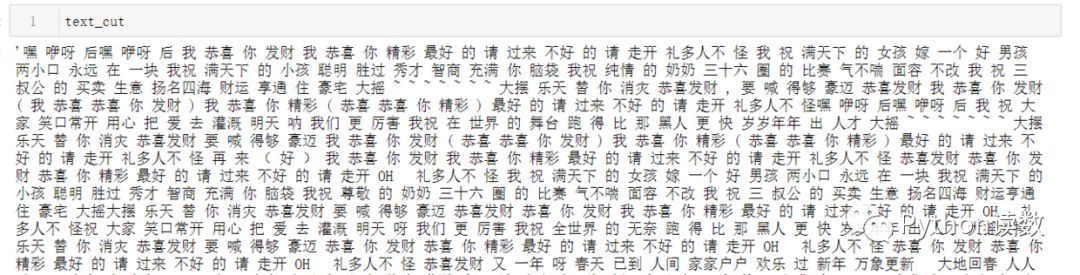
# 導(dǎo)入停詞# 用于去掉文本中類似于'啊'、'你','我'之類的詞stop_words = open("F:/NLP/chinese corpus/stopwords/stop_words_zh.txt",encoding="utf8").read().split("\n")# 使用WordCloud生成詞云word_cloud = WordCloud(font_path="simsun.ttc", # 設(shè)置詞云字體background_color="white", # 詞云圖的背景顏色stopwords=stop_words) # 去掉的停詞word_cloud.generate(text_cut)# 運用matplotlib展現(xiàn)結(jié)果plt.subplots(figsize=(12,8))plt.imshow(word_cloud)plt.axis("off")

一張簡單的詞云圖就成功生成啦,但看起來好像并沒有特別好看,怎么生成帶特定形狀的詞云呢?
登堂入室想生成帶特定形狀的詞云,首先得準備一張該形狀的圖片,且除了目標形狀外,其他地方都是空白的,如下面這張用于演示的圖。

上圖中除了福字之外都是白色的,準備好之后就上代碼
import jiebafrom wordcloud import WordCloudimport matplotlib.pyplot as pltfrom PIL import Imagetext = open("./data/新年歌.txt",encoding='utf8').read()text = text.replace('\n',"").replace("\u3000","")text_cut = jieba.lcut(text)text_cut = ' '.join(text_cut)stop_words = open("F:/NLP/chinese corpus/stopwords/stop_words_zh.txt",encoding="utf8").read().split("\n")# 主要區(qū)別background = Image.open("./data/background.png")graph = np.array(background)word_cloud = WordCloud(font_path="simsun.ttc",background_color="white",mask=graph, # 指定詞云的形狀stopwords=stop_words)word_cloud.generate(text_cut)plt.subplots(figsize=(12,8))plt.imshow(word_cloud)plt.axis("off")
代碼部分和普通的圖基本一致,區(qū)別在于要導(dǎo)入相應(yīng)形狀的圖片,并在wordcloud設(shè)置了mask參數(shù)。
生成的詞云圖如下:

是不是還挺簡單的,借這張圖也祝福大家2020年都福氣滿滿!
◆?◆?◆ ?◆?◆
長按二維碼關(guān)注我們
數(shù)據(jù)森麟公眾號的交流群已經(jīng)建立,許多小伙伴已經(jīng)加入其中,感謝大家的支持。大家可以在群里交流關(guān)于數(shù)據(jù)分析&數(shù)據(jù)挖掘的相關(guān)內(nèi)容,還沒有加入的小伙伴可以掃描下方管理員二維碼,進群前一定要關(guān)注公眾號奧,關(guān)注后讓管理員幫忙拉進群,期待大家的加入。
管理員二維碼: