
一文讓你掌握22個神經(jīng)網(wǎng)絡(luò)訓練技巧

極市導(dǎo)讀
在神經(jīng)網(wǎng)絡(luò)訓練過程中,本文給出眾多tips可以更加簡單方便的加速訓練網(wǎng)絡(luò)。這些tips作為一些啟發(fā)式建議,讓大家更好理解工作任務(wù),并選擇合適的技術(shù)。 >>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
神經(jīng)網(wǎng)絡(luò)訓練是一個非常復(fù)雜的過程,在這過程中,許多變量之間相互影響,因此我們研究者在這過程中,很難搞清楚這些變量是如何影響神經(jīng)網(wǎng)絡(luò)的。而本文給出的眾多tips就是讓大家,在神經(jīng)網(wǎng)絡(luò)訓練過程中,更加簡單方便的加速訓練網(wǎng)絡(luò)。當然,這些tips并不是訓練網(wǎng)絡(luò)的必要過程,而是作為一些啟發(fā)式建議,讓大家更好的理解自己手上的工作任務(wù),并且有針對性的選擇合適的技術(shù)。
首先,選擇一個很好的初始訓練狀態(tài),是一個很廣泛的話題,包括:從圖像增強到選擇超參數(shù)等等,下面我們具體列出了具體的操作:·
-
Overfit a single batch(單批次過擬合)· -
Run with a high number of epochs(運行大量epoch)· -
Set seeds(設(shè)置種子參數(shù)) -
Rebalance the dataset(重平衡數(shù)據(jù)集) -
Use a neutral class(使用中性類) -
Set the bias of the output layer(設(shè)置輸出層偏差) -
Tune the learning rate(調(diào)整學習率) -
Use fast data pipelines(使用快速數(shù)據(jù)流程) -
Use data augmentation(使用數(shù)據(jù)增強) -
Train an AutoEncoder on unlabeled data, use latent space representation as embedding(在未標記的數(shù)據(jù)上訓練AutoEncoder,使用潛在空間表示作為嵌入信息) -
Utilize embeddings from other models(利用來自其他模型的嵌入信息) -
Use embeddings to shrink data(使用嵌入來縮小數(shù)據(jù)) -
Use checkpointing(使用檢查點) -
Write custom training loops(編寫自定義訓練循環(huán)) -
Set hyperparameters appropriately(設(shè)置合適的超參數(shù)) -
Use EarlyStopping(使用EarlyStopping) -
Use transfer-learning(使用遷移學習) -
Employ data-parallel training(采用數(shù)據(jù)并行訓練) -
Use sigmoid activation for multi-label tasks(將sigmoid激活用于多標簽任務(wù)) -
One-hot encode categorical data(One-hot編碼分類數(shù)據(jù) -
Rescale numerical inputs(重調(diào)整數(shù)值輸入) -
Use knowledge distillation(使用知識蒸餾)
1 Overfit a single batch
(單批次過擬合)
單批次過擬合——主要是用來測試我們網(wǎng)絡(luò)的性能。首先,輸入單個數(shù)據(jù)批次,并且保證這個batch數(shù)據(jù)對應(yīng)的標簽是正確的(如果需要標簽的話)。然后,重復(fù)在這個batch數(shù)據(jù)上進行訓練,直到損失函數(shù)數(shù)值達到穩(wěn)定。如果你的網(wǎng)絡(luò)不能到達一個完美的準確率(利用不同指標),那么首先檢查一下數(shù)據(jù),在我們提出的這個方法,就是在確保數(shù)據(jù)沒有問題的情況下,檢測我們模型的性能。這樣,就避免了我們使用過于龐大或復(fù)雜的模型來解決簡單的問題,畢竟找到最合適的方法才是最有效的(殺雞用不著牛刀)。
2 Run with a high number of epochs
(運行大數(shù)值epochs)
很多情況下,我們通過大量epochs訓練模型之后,可以獲得一個很好的結(jié)果。如果,我們可以承受長時間的模型訓練,那么我們可以采用一種策略來選擇epochs數(shù)值(例如:從100逐漸增長到500)。這樣,當我們有過大量訓練模型的經(jīng)驗之后,大家就可以總結(jié)出自己的一組數(shù)據(jù)(稱為epoch factors),使用這些參數(shù),我們訓練新的模型時,可以快速設(shè)置初始訓練epochs,并且按照一定的比例來增加epochs。
3 Set seeds
(設(shè)置種子參數(shù))
為了保證模型的可重現(xiàn)性(reproducibility),我們可以采用一種方法,就是設(shè)置任何隨機數(shù)生成操作的種子。例如,如果我們使用TensorFlow框架,我們可以采用下面的代碼片段:
import os, random
import numpy as np
import tensorflow as tf
def set_seeds(seed: int):
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
使用操作種子的原因是,計算機并不能真實輸出隨機數(shù),也就是計算機輸出的是偽隨機數(shù),它是按照一定的規(guī)則來輸出隨機數(shù)。這樣的話,我們可以采用一系列規(guī)則來模擬隨機數(shù)的生成,也就是我們采用set_seed這個函數(shù)來模擬隨機數(shù)生成,具體的細節(jié),大家可以查閱TensorFlow的文檔。
4 Rebalance the dataset
(重平衡數(shù)據(jù)集)
不平衡數(shù)據(jù)集----也就是有一個類別或多個類別,占據(jù)了整個數(shù)據(jù)集的大部分;反之亦同,一個類別或多個類別占據(jù)數(shù)據(jù)集的很小一部分。如果我們使用的數(shù)據(jù)的不同類別都有基本相同的特性,那么我們考慮采用一些策略來解決這樣的問題,例如:上采樣最小類別數(shù)據(jù),下采樣最大類別數(shù)據(jù),采集額外的數(shù)據(jù)樣本(如果可能的話)和使用數(shù)據(jù)增強來產(chǎn)生偽數(shù)據(jù)樣本等等。
5 Use a neutral class
(使用中性類)
考慮下面一種情況,你的數(shù)據(jù)集有兩個類別:class1和class2(即不是class1),假設(shè)這些數(shù)據(jù)樣本都是由專家標注的(確保數(shù)據(jù)標簽的準確性)。那么,如果這些數(shù)據(jù)中有一個樣例無法確定其類別,那么這個樣本的類別可能被標記為none,或者標記為一個類別(但是其置信度非常低)。這樣的情況下,我們引入第三個類別是一個很好的方法,來解決這樣的問題。當前情況下,這個額外的類別表示為“不確定”類別。在網(wǎng)絡(luò)模型訓練過程中,我們可以將這第三類數(shù)據(jù)排除在外,不參與訓練。之后,我們就可以使用訓練好的模型,對這些模糊標簽數(shù)據(jù)樣例進行重新標注。
6 Set the bias of the output layer
(設(shè)置輸出層偏差)
對于未標注的數(shù)據(jù)集,那么網(wǎng)絡(luò)在初始階段對于數(shù)據(jù)樣例的猜測無法避免。即使網(wǎng)絡(luò)模型可以通過訓練來學習數(shù)據(jù)樣例的正確標簽,但是這樣會大大增加訓練的時間。我們可以通過在模型設(shè)計階段,設(shè)計一個更好的模型偏差公式,來減少模型訓練時間。對于一個sigmoid層來說,偏差可以通過下面公式來計算(假設(shè)只有兩個類別):
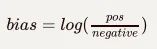
當我們在創(chuàng)建模型之后,可以使用上面計算的數(shù)值來初始化偏差。
7 Tune the learning rate
(調(diào)整學習率)
如果你想要調(diào)整一些超參數(shù),那么首要關(guān)注的重點就是----學習率。下面,我們給出一個學習率設(shè)置過高情況下,模型學習結(jié)果的輸出圖:
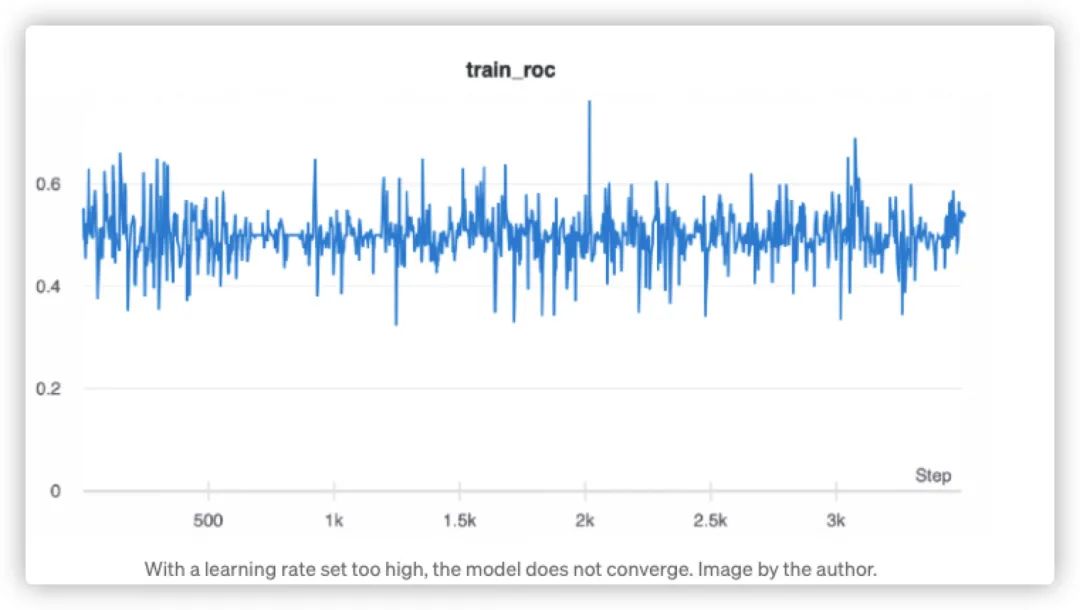
點擊可查看大圖
相比之下,如果使用一個不同的、較小的初始學習率,我們可以得到下面的結(jié)果:
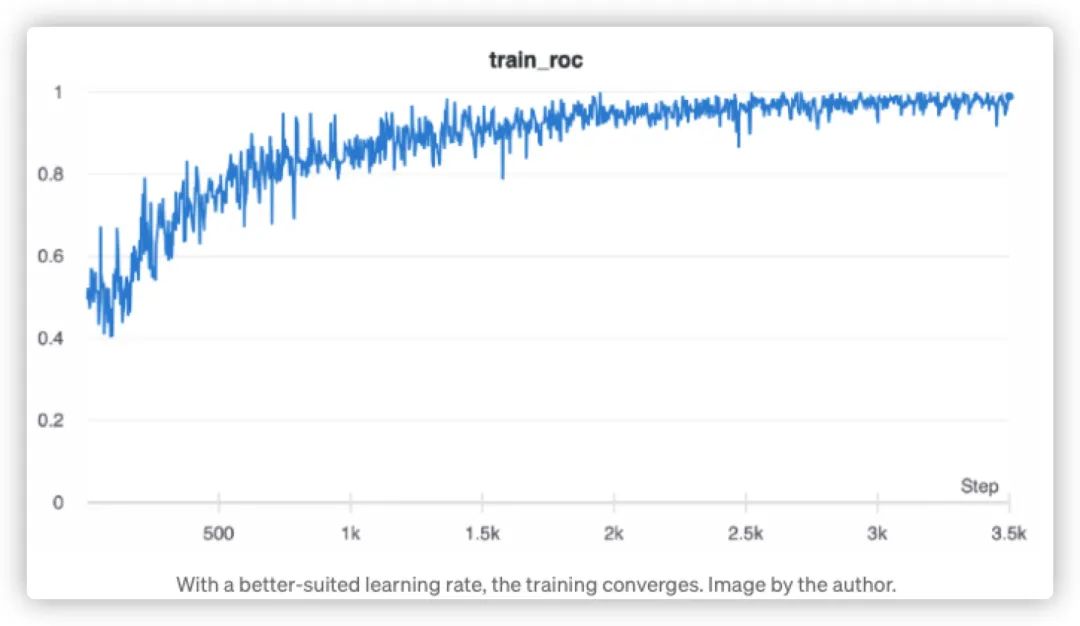 點擊可查看大圖
點擊可查看大圖
顯而易見,學習率選擇對應(yīng)模型的訓練時間消耗和準確度,都尤為重要,這里我們不會展開講解如果設(shè)計策略來通過訓練選取一個最優(yōu)學習率,而是會在后續(xù)文章中詳細給出選取最優(yōu)學習率的方法(歡迎關(guān)注后續(xù)文章)。這里,我們給出經(jīng)驗的學習數(shù)值,也就是給出初始學習率范圍為0.001和0.01之間。
8 Use fast data pipelines
(使用快速數(shù)據(jù)流程)
對于小項目來說,我們可以采用一個定制化生成器。而當我們參與一個大項目時,我們可以使用一個專門的數(shù)據(jù)集機制來替換生成器。在TenorFlow例子中,我們可以采用tf.data這個API,這個API函數(shù)包含大部分需要的方法,例如:shuffling、batching和prefetching等等。這個專業(yè)的數(shù)據(jù)集機制,替代我們定制化的數(shù)據(jù)生成器,可以很好應(yīng)用在我們實際項目中。
9 Use data augmentation
(使用數(shù)據(jù)增強)
數(shù)據(jù)增強可以讓我們訓練一個更加魯棒的網(wǎng)絡(luò)模型,通過增加數(shù)據(jù)集的數(shù)量,或者通過上采樣小類別數(shù)據(jù),但是這些數(shù)據(jù)增強,帶來的消耗就是訓練次數(shù)的增加,下面我們給出一些常用的普通圖像數(shù)據(jù)增強方法:
1.Flip(翻轉(zhuǎn))
我們可以水平翻轉(zhuǎn)或者垂直翻轉(zhuǎn),很多框架提供了翻轉(zhuǎn)的實現(xiàn),話不多說,我們直接給出代碼示例(以TensorFlow為例):
#You can perform flips by using any of the following commands, #from
your favorite packages. Data Augmentation Factor = 2 to #4x
# NumPy.'img' = A single image.
flip_1 = np.fliplr(img)
# TensorFlow. 'x' = A placeholder for an image.
shape = [height, width, channels] x = tf.placeholder(dtype = tf.float32, shape = shape)
flip_2 = tf.image.flip_up_down(x)
flip_3 = tf.image.flip_left_right(x)
flip_4 = tf.image.random_flip_up_down(x)
flip_5 = tf.image.random_flip_left_right(x)

2.Rotation(旋轉(zhuǎn))
注意,在旋轉(zhuǎn)之后,圖像的維度信息就不會得到保存,下面給出代碼示例:
# Placeholders: 'x' = A single image, 'y' = A batch of images
# 'k' denotes the number of 90 degree anticlockwise rotations
shape = [height, width, channels] x = tf.placeholder(dtype = tf.float32, shape = shape)
rot_90 = tf.image.rot90(img, k=1)
rot_180 = tf.image.rot90(img, k=2)
# To rotate in any angle. In the example below, 'angles' is in
radians
shape = [batch, height, width, 3] y = tf.placeholder(dtype = tf.float32, shape = shape)
rot_tf_180 = tf.contrib.image.rotate(y, angles=3.1415)
# Scikit-Image. 'angle' = Degrees. 'img' = Input Image
# For details about 'mode', checkout the interpolation section below.
rot = skimage.transform.rotate(img, angle=45, mode='reflect')

3.Scale(縮放)
圖像可以向內(nèi)縮放或者向外縮放,這里我們給出代碼示例:
# Scikit Image. 'img' = Input Image, 'scale' = Scale factor
# For details about 'mode', checkout the interpolation section below.
scale_out = skimage.transform.rescale(img, scale=2.0,
mode='constant')
scale_in = skimage.transform.rescale(img, scale=0.5, mode='constant')
# Don't forget to crop the images back to the original size (for
# scale_out)

4.Crop(剪切)
注意,剪切不同于縮放,剪切只是隨機采樣原始圖片,代碼示例如下:
# TensorFlow. 'x' = A placeholder for an image.
original_size = [height, width, channels] x = tf.placeholder(dtype = tf.float32, shape = original_size)
# Use the following commands to perform random crops
crop_size = [new_height, new_width, channels]
seed = np.random.randint(1234) x = tf.random_crop(x, size = crop_size, seed = seed)
output = tf.images.resize_images(x, size = original_size)

這里,我們對于數(shù)據(jù)增強也就不在贅述,一些高級的數(shù)據(jù)增強方法,包括使用GAN方法等等,我們也會在后續(xù)文章系列中詳細講述,歡迎關(guān)注。
10 Train an AutoEncoder on unlabeled data, use latent space representation as embedding
(在未標記的數(shù)據(jù)上訓練AutoEncoder,使用潛在空間表示作為嵌入信息)
如果我們用來訓練的標注數(shù)據(jù)集相對較小,那么我們?nèi)匀豢梢岳靡恍┎呗詠硎褂眠@些數(shù)據(jù)集來完成任務(wù)。其中一個方法就是采用AutoEncoder,這其中的背景是,我們可以很方便的采集未標記的數(shù)據(jù)。那么,我們就可以使用AutoEncoder,并且AutoEncoder巨頭一個合適大小的潛在空間(例如:300到600條目),來獲得一個合理且較小的重建損失函數(shù)值。為了獲取實際數(shù)據(jù)的嵌入信息,我們可以丟棄decoder網(wǎng)絡(luò)層,然后我們使用保留的encoder網(wǎng)絡(luò)層來生成嵌入信息。
11 Utilize embeddings from other models
(利用來自其他模型的嵌入信息)
不同于第10條,使用的是我們自己的數(shù)據(jù)來獲得嵌入信息,我們還可以從其他模型學習到嵌入信息。對于文本數(shù)據(jù)任務(wù),下載預(yù)學習的嵌入信息是很普遍的方法。而對對于圖像數(shù)據(jù)任務(wù),我們可以使用在大數(shù)據(jù)集(例如:ImageNet)上訓練好的模型,選擇一個充分訓練的網(wǎng)絡(luò)層,并且對這些輸出進行切割,然后使用這些切割的結(jié)果作為嵌入信息。
12 Use embeddings to shrink data
(使用嵌入來縮小數(shù)據(jù))
首先,假設(shè)我們的數(shù)據(jù)集樣例都有一個類別特征信息,那么在一開始,某個數(shù)據(jù)樣例對應(yīng)的類別特征只可能取兩個值,也就是對應(yīng)的one-hot編碼有兩個下標。但是,一旦這個類別值擴大到1000類或者更大的值,那么一個稀疏的one-hot編碼方法就不再高效,因為我們可以在一個相對較低的維度表示這些數(shù)據(jù),那么采用信息嵌入就是一個有效的方法。我們可以在訓練之前插入一個嵌入層(將大類別數(shù)據(jù)信息,從0到1000,甚至更大類別),將類別信息輸入,或者一個降維的嵌入信息。這樣的表示,可以通過網(wǎng)絡(luò)模型學習來獲得。
13 Use checkpointing
(使用檢查點)
當我們訓練一個網(wǎng)絡(luò)模型數(shù)個小時甚至更久時間之后,但是很不幸,這個模型奔潰了,但是訓練的所有信息都丟失,那么這就是一個很令人沮喪的事情。考慮到硬件和軟件都不是百分之分完善的運行,那么我們做好保存點的存儲是一個很重要的操作。在簡單的檢查點使用中,我們可能只是保存了每k步模型的權(quán)重,到后面復(fù)雜的檢查點使用中,我們可以保存優(yōu)化器的狀態(tài),以及當前和任何其他的關(guān)鍵信息。然后,在訓練運行開始后,我們可以檢查任何失敗的運行快照,并且基于這個運行快照快速恢復(fù)所有必要的設(shè)置。尤其是,在14條自定義訓練訓練結(jié)合使用檢查點非常有效。
14 Write custom training loops
(編寫自定義訓練循環(huán))
在大多數(shù)情況下,使用默認的訓練流程,例如TensorFlow中的model.fit\(\),這就足夠有效了。但是,我們注意到使用默認訓練流程的靈活性具有局限,一些微小的改動可能很容易合并,但是較大的修改就很難實施。這也就是我們建議自行編寫自定義算法。這里,我們也不再贅述,會在后續(xù)系列文章中展開來講,如何通過不同的代碼案例,快速實現(xiàn)修改算法,整合我們自己的最新想法。
15 Set hyperparameters appropriately
(設(shè)置合適的超參數(shù))
現(xiàn)代GPU非常擅長矩陣計算,這也就是它們被廣泛用于訓練大型神經(jīng)網(wǎng)絡(luò)模型的原因。通過選擇合適的超參數(shù),我們可以進一步提高算法的效率,例如對于Nvidia GPU(目前主流的GPU),我們可以參考下列指南:
1. 選擇的batchsize可以被4正常,或者2的倍數(shù)
2. 對于稠密網(wǎng)絡(luò)層,設(shè)定輸入和輸出都可以被64整除
3. 對于卷積層,設(shè)定輸入和輸出通道可以被4正常,或者2的倍數(shù)
4. 將輸入圖像從RGB三通道padding到4通道
5. 使用BHWC的數(shù)據(jù)模式(Batch_height_width_channels)
6. 對于遞歸網(wǎng)絡(luò)層,設(shè)定batch和隱藏層可以被4整除,理想值為64、128、256
這些建議遵循的思想是,讓數(shù)據(jù)的分布更加均衡。這里,我們給出一些參考文檔:
-
Nvidia文檔1:https://docs.nvidia.com/deeplearning/performance/index.html -
Nvidia文檔2:https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html -
Nvidia文檔3https://docs.nvidia.com/deeplearning/performance/dl-performance-convolutional/index.html
16 Use EarlyStopping
(使用EarlyStopping)
什么時候可以停止訓練模型,這個問題很難回答。可能發(fā)生的一種現(xiàn)象就是深度雙層下降:也就是你的模型指標在穩(wěn)步改善之后開始惡化,然后,經(jīng)過一些訓練更新后,模型分數(shù)再次提高,甚至比之前更好。為了避免在這之間來回震蕩,我們可以使用驗證數(shù)據(jù)集。這個單獨分出來的數(shù)據(jù)集用來衡量算法,在新的、看不見數(shù)據(jù)上的性能。如果性能在我們設(shè)定的“耐心步數(shù)”范圍內(nèi)不在更新,那么模型就不再繼續(xù)訓練了。這里,關(guān)鍵就是選擇合適的“耐心步數(shù)參數(shù)”,可以幫助我們的模型客服克服暫時的分數(shù)高原,一個常用的“耐心步數(shù)參數(shù)”可以選取為5到20epochs之間。
17 Use transfer-learning
(使用遷移學習)
遷移學習背后的想法,就是利用從業(yè)中已經(jīng)在大量數(shù)據(jù)集上訓練得到的模型結(jié)果成就,應(yīng)用在我們的任務(wù)上。理想情況下,我們使用的網(wǎng)絡(luò)針對相同的數(shù)據(jù)類型(圖像、文本、音頻)和我們的任務(wù)(分類、翻譯、檢測)類似的任務(wù)進行了訓練。主要有兩種相關(guān)的方法:
1.Fine-tuning(微調(diào))
微調(diào)是采用已經(jīng)訓練好的模型,并更新特點問題的權(quán)重的任務(wù)。通常情況下,我們會凍結(jié)前幾層,應(yīng)為它們經(jīng)過訓練可以識別基本特征,然后在我們的數(shù)據(jù)集上對其余層進行微調(diào)。
2.Feature extraction(特征提取)
與微調(diào)相反,特征提取描述了一種使用經(jīng)過訓練的網(wǎng)絡(luò)來提取特征的方法。在預(yù)選訓練好的模型上,添加自己的分類器,只更新這部分的網(wǎng)絡(luò);而基層被凍結(jié)。我們遵循此方法的原因是,原始頂層網(wǎng)絡(luò)只是針對特點問題進行訓練的,但是我們的任務(wù)是有所不同的。通常從頭開始學習自定義部分網(wǎng)絡(luò)層,我們就可以確保專注于我們的數(shù)據(jù)集----同時保持大型基礎(chǔ)模型的優(yōu)勢。
18 Employ data-parallel training
(采用數(shù)據(jù)并行訓練)
如果我們想要更快的訓練我們的模型,那么可以在多個GPU上運行算法來計算訓練速度。通常情況下,這是按照數(shù)據(jù)并行的方式完成的:網(wǎng)絡(luò)在不同的設(shè)備上復(fù)制,不同批次的數(shù)據(jù)被拆分和分發(fā)。然后,將梯度平均并應(yīng)用在每個網(wǎng)絡(luò)副本上。在TensorFlow上,我們可以采用多種不同的分布式訓練策略。最簡單的選擇就是“MirroredStategy”,但是還有很多其他策略,這里不再贅述。例如,如果我們編寫自定義訓練循環(huán)(如上面14條),則可以遵循這些教程。按照我們的訓練經(jīng)驗來看,將數(shù)據(jù)從一個GPU分布到二到三個訓練,速度是最快的,對于大型數(shù)據(jù)集來說,這是減少訓練次數(shù)的有效途徑。
19 Use sigmoid activation for multi-label tasks
(將sigmoid激活用于多標簽任務(wù))
在樣本可以有多個標簽的情況下,我們可以使用sigmoid激活函數(shù),與softmax不同的是,sigmoid單獨應(yīng)用于每個神經(jīng)元,這意味著多個神經(jīng)元可以被觸發(fā),并且輸出值都介于0和1之間,這樣方便于解釋。這個方法在一些任務(wù)中很重要,例如,將樣本分類為多個類別或者檢測各種不同的對象。
20 One-hot encode categorical data
(One-hot編碼分類數(shù)據(jù))
由于我們使用數(shù)字表示的需要,因此需要將分類數(shù)據(jù)編碼為數(shù)字。例如,我們不能直接反饋得到“金毛”類別,而只能得到表示“金毛”的類別數(shù)字。一個比較吸引人的選擇就是枚舉所有可能的值,也就是說,這種方法意味著在編碼為1的“金毛”和編碼為2的“橘貓”,來進行排序。但是,實際使用中這些排序很少使用,這也就是我們依賴one-hot編碼的原因,這種編碼保證了變量的獨立性。
21 Rescale numerical inputs
(重調(diào)整數(shù)值輸入)
網(wǎng)絡(luò)模型通過更新權(quán)重進行訓練,而優(yōu)化器主要負責這一點。通常情況下,如果輸出值介于[-1,1]之間,它們可以被調(diào)整為最佳值,那么這是為啥呢?讓我們假設(shè)一個丘陵景觀,我們?yōu)榱藢ふ易畹忘c,如果周圍區(qū)域的丘陵越多,那么我們花在尋找局部丘陵最小值上的時間就越多。但是,如果我們可以修改景觀的現(xiàn)狀呢?我們是否可以更快地找到解決方案嗎?這就是我們通過調(diào)整數(shù)值所實現(xiàn)的,當我們將數(shù)值縮放到[-1,1]時,我們使用曲率更加球型(也就是更圓、更均勻)。如果我們使用這個范圍的數(shù)據(jù)訓練我們的模型,我們可以更快地收斂。這是為什么呢?因為特征的大小(即權(quán)重值)影響梯度的大小,較大的特征會產(chǎn)生較大的梯度,從而導(dǎo)致較大的權(quán)重更新,這些更新需要更多的步驟來收斂,導(dǎo)致訓練速度降低。大家還想進一步了解這方面的內(nèi)容,可以查閱TensorFlow的教程。
22 Use knowledge distillation
(使用知識蒸餾)
大家一定聽說過BERT模型吧?這個Transformer模型有幾億個參數(shù),但是我們可能無法在我們的GPU上進行訓練它,這大量的參數(shù)就是知識蒸餾過程變得有效的地方,我們通過訓練第二個模型來產(chǎn)生更大模型的輸出,而作為輸出仍是原始數(shù)據(jù)集,但是標簽確實參考模型的輸出,也被稱為軟輸出。這種技術(shù)的目標是在小模型的幫助下,復(fù)制更大的模型。這里,我們也沒有過度講解知識蒸餾和教師--學生網(wǎng)絡(luò)模型的知識,大家有進一步了解的需要,可以查閱這些相關(guān)教程。
參考文獻
[1].https://towardsdatascience.com/tips-and-tricks-for-neural-networks-63876e3aad1a?gi=2 732cb2a6e99
[2].https://nanonets.com/blog/data-augmentation-how-to-use-deep-learning-when-you-ha ve-limited-data-part2/
[3].https://www.tensorflow.org/tutorials/structured_data/imbalanced_data#optional_set_the_ correct_initial_bias
[4].https://docs.nvidia.com/deeplearning/performance/index.html
[5].https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/inde x.html
[6].https://docs.nvidia.com/deeplearning/performance/dl-performance-convolutional/index. html
[7].https://openai.com/blog/deep-double-descent/
[8].https://www.tensorflow.org/tutorials/distribute/multi_worker_with_ctl
[9].https://www.tensorflow.org/tutorials/images/transfer_learning#rescale_pixel_values
[10].https://medium.com/huggingface/distilbert-8cf3380435b5
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“79”獲取CVPR 2021:TransT 直播鏈接~

# CV技術(shù)社群邀請函 #

備注:姓名-學校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
