有哪些你看了之后大呼過癮的數(shù)據(jù)分析方法論(萬字長文)?
01
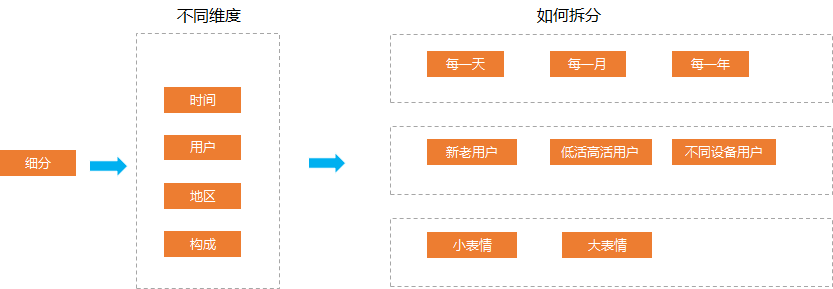
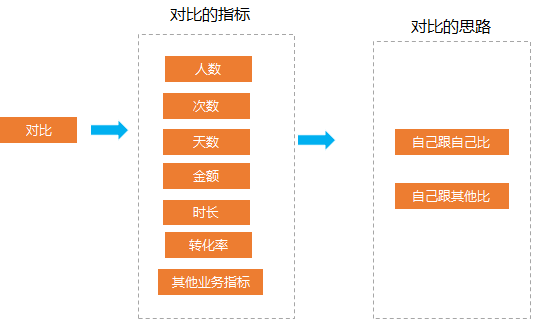
02
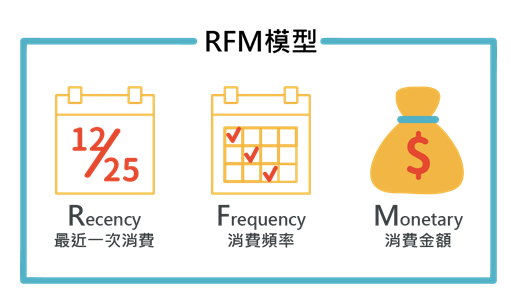
RFM 模型是利用 R, F, M 三個(gè)特征去對(duì)用戶進(jìn)行劃分的。
其中R是表示最后一次付費(fèi)的日期距離現(xiàn)在的時(shí)間, 比如你在 12月20號(hào)給一個(gè)主播打賞過, 那么到現(xiàn)在的距離的天數(shù)是5 那么R就是5, R是用來刻畫用戶的忠誠度, 一般來說R越小, 代表用戶上一次剛剛才付費(fèi)的, 這種用戶的忠誠度比較高。
F是表示一段時(shí)間的付費(fèi)頻次, 也就是比如一個(gè)月付費(fèi)了多少次, 這個(gè)是用來刻畫用戶付費(fèi)行為的活躍度, 我們認(rèn)為用戶的付費(fèi)行為頻次越高, 一定程度上代表他的價(jià)值度
M是表示一段時(shí)間的付費(fèi)金額, 比如一個(gè)月付費(fèi)了10000元, M=10000, M主要是用來刻畫用戶的土豪程度。
以上我們就從用戶的忠誠度, 活躍度, 土豪度三個(gè)方面去刻畫一個(gè)用戶的價(jià)值度。
根據(jù)RFM的值, 我們就可以把用戶劃分為以下不同的類別:
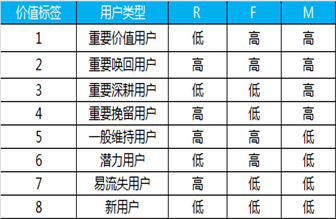
重要價(jià)值用戶: R 低, F 高, M 高, 這種用戶價(jià)值度非常高, 因?yàn)橹艺\度高, 付費(fèi)頻次高, 又很土豪
重要召回用戶: R 低, F 低 M 高, 因?yàn)楦顿M(fèi)頻次低, 但金額高, 所以是重點(diǎn)召回用戶
重要發(fā)展用戶: R 高, F 低, M 高 因?yàn)橹艺\度不夠, 所以需要大力發(fā)展
重要挽留用戶: R 高 F 低 M高 因?yàn)?nbsp;忠誠度和活躍度都不夠 很容易流失 所以需要重點(diǎn)挽留
還有四種其他用戶就不一一列舉
RFM如何分群:
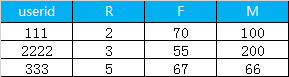
1.首先是利用sql 計(jì)算 每一個(gè)用戶的 R, F, M, 最終得到的數(shù)據(jù)格式如下
2. 讀取數(shù)據(jù)和查看數(shù)據(jù)
pay_data= pd.read_csv('d:/My Documents/Desktop/train_pay.csv')# 路徑名 'd:/My Documents/Desktop/train_pay.csv' 填寫你自己的即可pay_data.head() # 查看數(shù)據(jù)前面幾行
3. 選取我們要聚類的特征
pay_RFM = pay_data[['r_c','f_c','m_c']]4. 開始聚類, 因?yàn)槲覀冇脩舴秩悍值氖前藗€(gè)類別, 所以k =8
# 創(chuàng)建模型model_k = KMeans(n_clusters=8,random_state=1)# 模型訓(xùn)練model_k.fit(pay_RFM)# 聚類出來的類別賦值給新的變量 cluster_labelscluster_labels = model_k.labels_
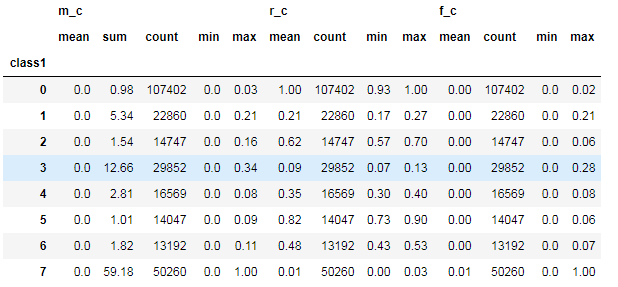
5. 對(duì)聚類的結(jié)果中每一個(gè)類別計(jì)算 每個(gè)類別的數(shù)量 最小值 最大值 平均值等指標(biāo)
rfm_kmeans = pay_RFM.assign(class1=cluster_labels)num_agg = {'r_c':['mean', 'count','min','max'], 'f_c':['mean', 'count','min','max'],'m_c':['mean','sum','count','min','max']}rfm_kmeans.groupby('class1').agg(num_agg).round(2)
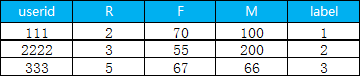
6. 把聚類出來的類別和用戶id 拼接在一起
pay_data.assign(class1=cluster_labels).to_csv('d:/My Documents/Desktop/result.csv',header=True, sep=',')下面就是最終結(jié)果, label 表示用戶是屬于哪一個(gè)細(xì)分的類別
03
生命周期模型
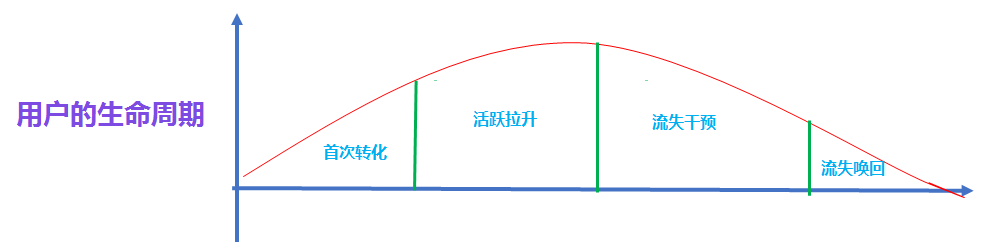
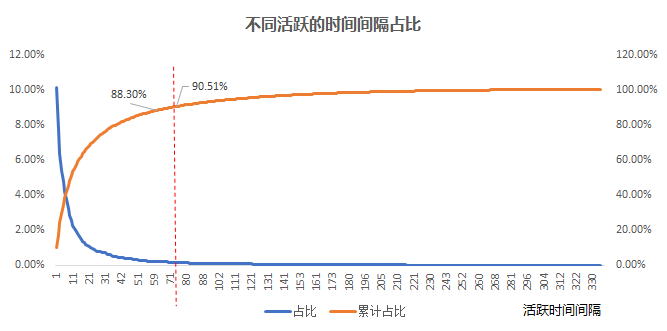
分位數(shù)法:
首先先計(jì)算用戶活躍的時(shí)間間隔, 比如用戶a 活躍的時(shí)間日期分別是 2020-12-01 和 2020-12-14 那么間隔就是13天, 我們把所有用戶的活躍的時(shí)間間隔都計(jì)算好, 然后找出間隔的 90% 分位數(shù).
為什么是90% 分位數(shù)呢?這是因?yàn)槿绻?0% 的活躍時(shí)間間隔都在某個(gè)周期以內(nèi)的話, 那么這個(gè)周期內(nèi)不活躍的話, 之后活躍的可能性也不高。
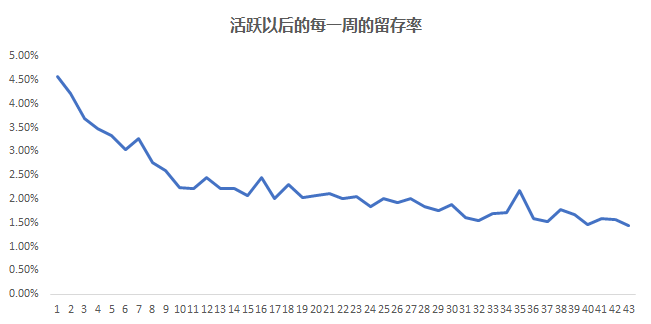
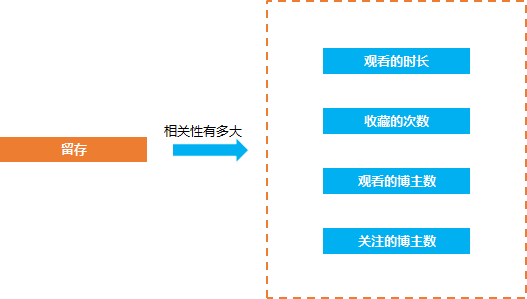
在數(shù)據(jù)分析的問題中, 經(jīng)常會(huì)遇見的一種問題就是相關(guān)的問題, 比如抖音短視頻的產(chǎn)品經(jīng)理經(jīng)常要來問留存(是否留下來)和觀看時(shí)長, 收藏的次數(shù), 轉(zhuǎn)發(fā)的次數(shù), 關(guān)注的抖音博主數(shù)等等是否有相關(guān)性, 相關(guān)性有多大。
因?yàn)橹挥兄懒四男┮蛩睾土舸姹容^相關(guān), 才知道怎么去優(yōu)化從產(chǎn)品的方向去提升留存率, 比如 如果留存和收藏的相關(guān)性比較大 那么我們就要引導(dǎo)用戶去收藏視頻, 從而提升相關(guān)的指標(biāo),
除了留存的相關(guān)性計(jì)算的問題, 還有類似的需要去計(jì)算相關(guān)性的問題, 比如淘寶的用戶 他們的付費(fèi)行為和哪些行為相關(guān), 相關(guān)性有多大, 這樣我們就可以挖掘出用戶付費(fèi)的關(guān)鍵行為
這種問題就是相關(guān)性量化, 我們要找到一種科學(xué)的方法去計(jì)算這些因素和留存的相關(guān)性的大小,
這種方法就是相關(guān)性分析
04
相關(guān)性分析是指對(duì)兩個(gè)或多個(gè)具備相關(guān)性的變量元素進(jìn)行分析,從而衡量兩個(gè)變量因素的相關(guān)密切程度。相關(guān)性的元素之間需要存在一定的聯(lián)系或者概率才可以進(jìn)行相關(guān)性分析(官方定義)
簡單來說, 相關(guān)性的方法主要用來分析兩個(gè)東西他們之間的相關(guān)性大小
相關(guān)性大小用相關(guān)系數(shù)r來描述,關(guān)于r的解讀:(從知乎摘錄的)
(1)正相關(guān):如果x,y變化的方向一致,如身高與體重的關(guān)系,r>0;一般地,
·|r|>0.95 存在顯著性相關(guān);
·|r|≥0.8 高度相關(guān);
·0.5≤|r|<0.8 中度相關(guān);
·0.3≤|r|<0.5 低度相關(guān);
·|r|<0.3 關(guān)系極弱,認(rèn)為不相關(guān)
(2)負(fù)相關(guān):如果x,y變化的方向相反,如吸煙與肺功能的關(guān)系,r<0;
(3)無線性相關(guān):r=0, 這里注意, r=0 不代表他們之間沒有關(guān)系, 可能只是不存在線性關(guān)系。
下面用幾個(gè)圖來描述一下 不同的相關(guān)性的情況
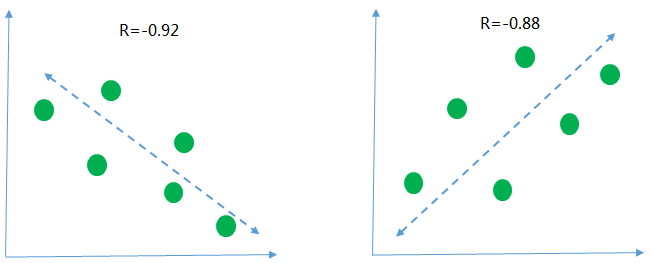
第一張圖r=-0.92 <0 是說明橫軸和縱軸的數(shù)據(jù)呈現(xiàn)負(fù)相關(guān), 意思就是隨著橫軸的數(shù)據(jù)值越來越大縱軸的數(shù)據(jù)的值呈現(xiàn)下降的趨勢, 從r的絕對(duì)值為0.92>0.8 來看, 說明兩組數(shù)據(jù)的相關(guān)性高度相關(guān)
同樣的, 第二張圖 r=0.88 >0 說明縱軸和橫軸的數(shù)據(jù)呈現(xiàn)正向的關(guān)系, 隨著橫軸數(shù)據(jù)的值越來越大, 縱軸的值也隨之變大, 并且兩組數(shù)據(jù)也是呈現(xiàn)高度相關(guān)
如何實(shí)現(xiàn)相關(guān)性分析:
前面已經(jīng)講了什么是相關(guān)性分析方法, 那么我們?cè)趺慈?shí)現(xiàn)這種分析方法呢, 以下先用python 實(shí)現(xiàn)
1. 首先是導(dǎo)入數(shù)據(jù)集, 這里以tips 為例
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline## 定義主題風(fēng)格sns.set(style="darkgrid")## 加載tipstips = sns.load_dataset("tips")
2. 查看導(dǎo)入的數(shù)據(jù)集情況,
字段分別代表
total_bill: 總賬單數(shù)
tip: 消費(fèi)數(shù)目
sex: 性別
smoker: 是否是吸煙的群眾
day: 天氣
time: 晚餐 dinner, 午餐lunch
size: 顧客數(shù)
tips.head() # 查看數(shù)據(jù)的前幾行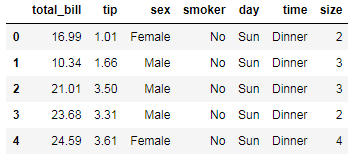
3. 最簡單的相關(guān)性計(jì)算
tips.corr()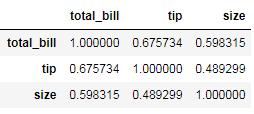
4. 任意看兩個(gè)數(shù)據(jù)之間相關(guān)性可視化,比如看 total_bill 和 tip 之間的相關(guān)性,就可以如下操作進(jìn)行可視化
## 繪制圖形,根據(jù)不同種類的三點(diǎn)設(shè)定圖注sns.relplot(x="total_bill", y="tip", data=tips);plt.show()
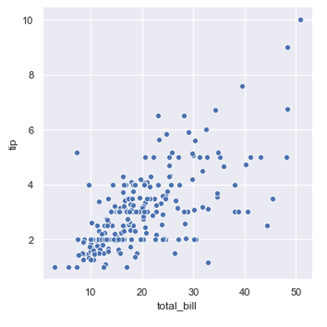
從散點(diǎn)圖可以看出賬單的數(shù)目和消費(fèi)的數(shù)目基本是呈正相關(guān), 賬單的總的數(shù)目越高, 給得消費(fèi)也會(huì)越多
5. 如果要看全部任意兩兩數(shù)據(jù)的相關(guān)性的可視化
sns.pairplot(tips)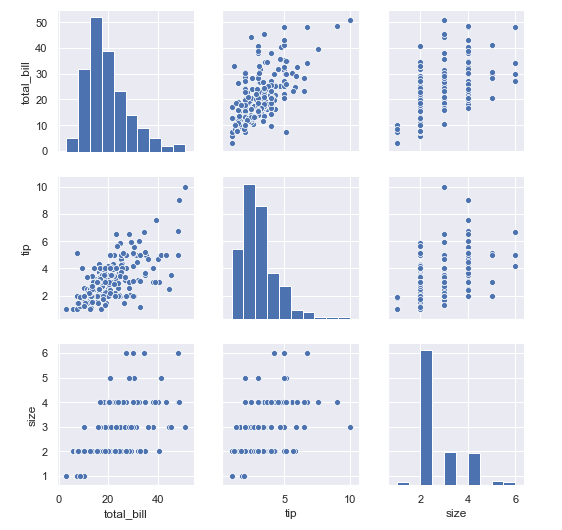
6. 如果要分不同的人群, 吸煙和非吸煙看總的賬單數(shù)目total_bill和小費(fèi)tip 的關(guān)系。
sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips)# 利用hue 進(jìn)行區(qū)分plt.show()
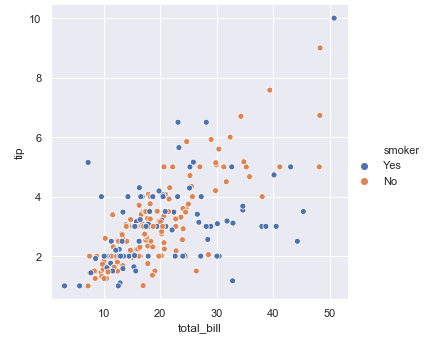
7. 同樣的 區(qū)分抽煙和非抽煙群體看所有數(shù)據(jù)之間的相關(guān)性,我們可以看到
對(duì)于男性和女性群體, 在小費(fèi)和總賬單金額的關(guān)系上, 可以同樣都是賬單金額越高的時(shí)候, 小費(fèi)越高的例子上, 男性要比女性給得小費(fèi)更大方
在顧客數(shù)量和小費(fèi)的數(shù)目關(guān)系上, 我們可以發(fā)現(xiàn), 同樣的顧客數(shù)量, 男性要比女性給得小費(fèi)更多
在顧客數(shù)量和總賬單數(shù)目關(guān)系上, 也是同樣的顧客數(shù)量, 男性要比女性消費(fèi)更多
sns.pairplot(tips ,hue ='sex')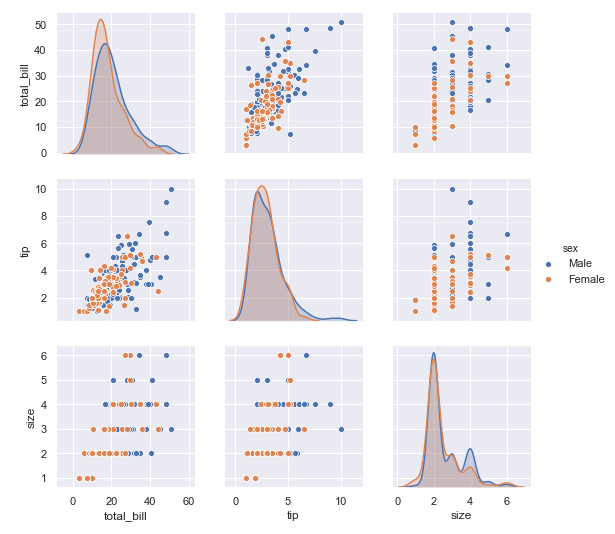
實(shí)戰(zhàn)案例:
問題:
影響B(tài) 站留存的相關(guān)的關(guān)鍵行為有哪些?
這些行為和留存哪一個(gè)相關(guān)性是最大的?
分析思路:
找全與留存相關(guān)的行為
計(jì)算這些行為和留存的相關(guān)性大小
首先規(guī)劃好完整的思路, 哪些行為和留存相關(guān), 然后利用這些行為+時(shí)間維度 組成指標(biāo), 因?yàn)椴煌臅r(shí)間跨度組合出來的指標(biāo), 意義是不一樣的, 比如登錄行為就有 7天登錄天數(shù), 30天登錄天數(shù)
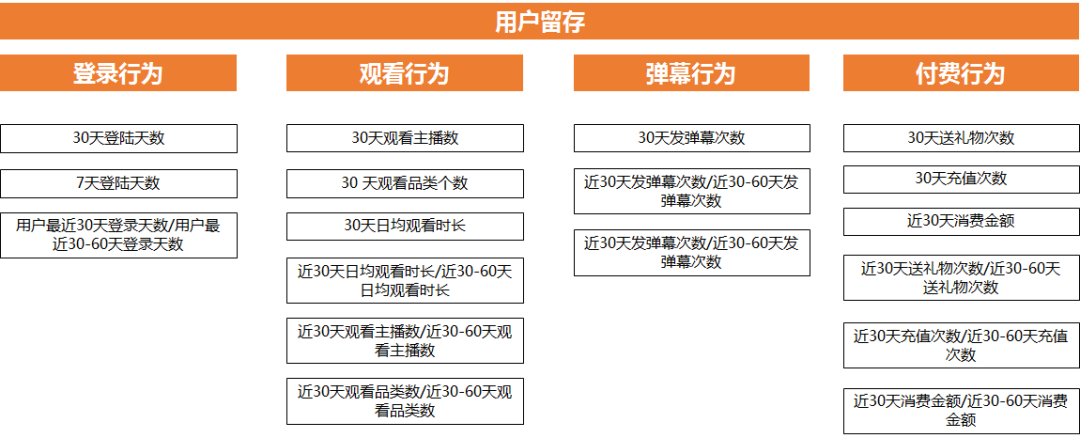
第二步計(jì)算這些行為和留存的相關(guān)性, 我們用1 表示會(huì)留存 0 表示不會(huì)留存
那么就得到 用戶id + 行為數(shù)據(jù)+ 是否留存 這幾個(gè)指標(biāo)組成的數(shù)據(jù)
然后就是相關(guān)性大小的計(jì)算
import matplotlib.pyplot as pltimport seaborn as snsretain2 = pd.read_csv("d:/My Documents/Desktop/train2.csv") # 讀取數(shù)據(jù)retain2 = retain2.drop(columns=['click_share_ayyuid_ucnt_days7']) # 去掉不參與計(jì)算相關(guān)性的列plt.figure(figsize=(16,10), dpi= 80)# 相關(guān)性大小計(jì)算sns.heatmap(retain2.corr(), xticklabels=retain2.corr().columns, yticklabels=retain2.corr().columns, cmap='RdYlGn', center=0, annot=True)# 可視化plt.title('Correlogram of retain', fontsize=22)plt.xticks(fontsize=12)plt.yticks(fontsize=12)plt.show()
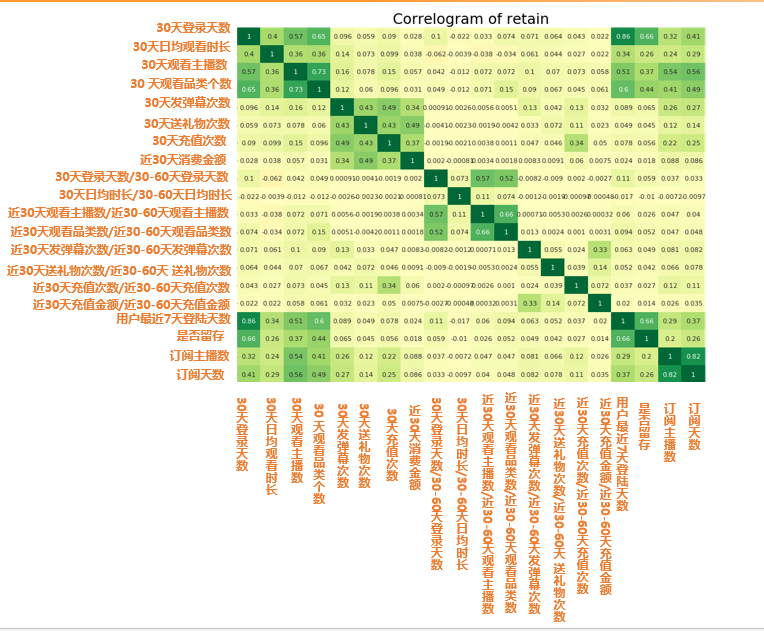
圖中的數(shù)字值就是代表相關(guān)性大小 r 值 所以從圖中我們可以發(fā)現(xiàn)
留存相關(guān)最大的四大因素:
?30天或者7天登錄天數(shù)(cor: 0.66)
?30天觀看品類個(gè)數(shù)(cor: 0.44)
?30天觀看主播數(shù) (cor: 0.37)
?30天日均觀看時(shí)長(cor: 0.26)
05

我們經(jīng)常在淘寶上購物, 作為淘寶方, 他們肯定想知道他的使用用戶是什么樣的, 是什么樣的年齡性別, 城市, 收入, 他的購物品牌偏好, 購物類型, 平時(shí)的活躍程度是什么樣的, 這樣的一個(gè)用戶描述就是用戶畫像分析
無論是產(chǎn)品策劃還是產(chǎn)品運(yùn)營, 前者是如何去策劃一個(gè)好的功能, 去獲得用戶最大的可見的價(jià)值以及隱形的價(jià)值, 必須的價(jià)值以及增值的價(jià)值, 那么了解用戶, 去做用戶畫像分析, 會(huì)成為數(shù)據(jù)分析去幫助產(chǎn)品做做更好的產(chǎn)品設(shè)計(jì)重要的一個(gè)環(huán)節(jié)。
那么作為產(chǎn)品運(yùn)營, 比如要針用戶的拉新, 挽留, 付費(fèi), 裂變等等的運(yùn)營, 用戶畫像分析可以幫助產(chǎn)品運(yùn)營去找到他們的潛在的用戶, 從而用各種運(yùn)營的手段去觸達(dá)。
因?yàn)楫?dāng)我們知道我們的群體的是什么樣的一群人的時(shí)候, 潛在的用戶也是這樣的類似的一群人, 這樣才可以做最精準(zhǔn)的拉新, 提高我們的ROI
在真正的工作中, 用戶畫像分析是一個(gè)重要的數(shù)據(jù)分析手段去幫助產(chǎn)品功能迭代, 幫助產(chǎn)品運(yùn)營做用戶增長。
總的來說, 用戶畫像分析就是基于大量的數(shù)據(jù), 建立用戶的屬性標(biāo)簽體系, 同時(shí)利用這種屬性標(biāo)簽體系去描述用戶
用戶畫像的作用:
像上面描述的那樣, 用戶畫像的作用主要有以下幾個(gè)方面
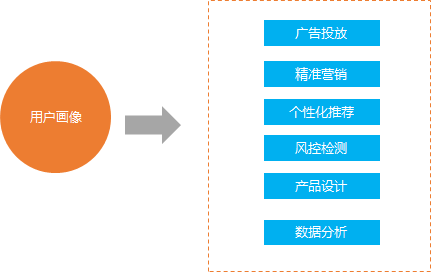
1.廣告投放
在做用戶增長的例子中, 我們需要在外部的一些渠道上進(jìn)行廣告投放, 對(duì)可能的潛在用戶進(jìn)行拉新, 比如B站在抖音上投廣告
我們?cè)谶x擇平臺(tái)進(jìn)行投放的時(shí)候, 有了用戶畫像分析, 我們就可以精準(zhǔn)的進(jìn)行廣告投放, 比如抖音的用戶群體是18-24歲的群體, 那么廣告投放的時(shí)候就可以針對(duì)這部分用戶群體進(jìn)行投放, 提高投放的ROI
假如我們沒有畫像分析, 那么可能會(huì)出現(xiàn)投了很多次廣告, 結(jié)果沒有人點(diǎn)擊

2.精準(zhǔn)營銷
假如某個(gè)電商平臺(tái)需要做個(gè)活動(dòng)給不同的層次的用戶發(fā)放不同的券, 那么我們就要利用用戶畫像對(duì)用戶進(jìn)行劃分, 比如劃分成不同的付費(fèi)的活躍度的用戶, 然后根據(jù)不同的活躍度的用戶發(fā)放不用的優(yōu)惠券。
比如針對(duì)付費(fèi)次數(shù)在 [1-10] 的情況下發(fā) 10 元優(yōu)惠券刺激, 依次類推
3. 個(gè)性化推薦
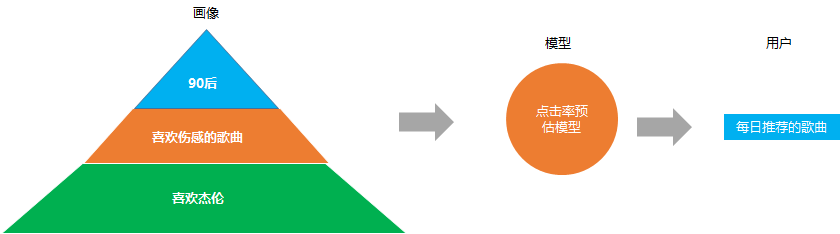
精確的內(nèi)容分發(fā), 比如我們?cè)谝魳穉pp 上看到的每日推薦, 網(wǎng)易云之所以推薦這么準(zhǔn), 就是他們?cè)谧鳇c(diǎn)擊率預(yù)估模型(預(yù)測給你推薦的歌曲你會(huì)不會(huì)點(diǎn)擊)的時(shí)候, 考慮了你的用戶畫像屬性。
比如根據(jù)你是90后, 喜歡傷感的, 又喜歡杰倫, 就會(huì)推薦類似的歌曲給你, 這些就是基于用戶畫像推薦
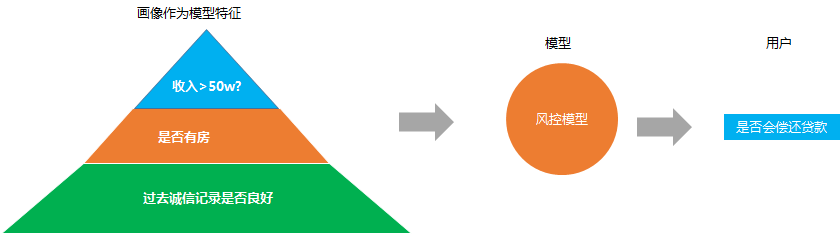
4. 風(fēng)控檢測
這個(gè)主要是金融或者銀行業(yè)設(shè)計(jì)的比較多, 因?yàn)榻?jīng)常遇到的一個(gè)問題就是銀行怎么決定要不要給一個(gè)申請(qǐng)貸款的人給他去放貸
經(jīng)常的解決方法就是搭建一個(gè)風(fēng)控預(yù)測模型, 去預(yù)約這個(gè)人是否會(huì)不還貸款,同樣的, 模型的背后很依賴用戶畫像。
用戶的收入水平, 教育水平, 職業(yè), 是否有家庭, 是否有房子, 以及過去的誠信記錄, 這些的畫像數(shù)據(jù)都是模型預(yù)測是否準(zhǔn)確的重要數(shù)據(jù)
5. 產(chǎn)品設(shè)計(jì)
互聯(lián)網(wǎng)的產(chǎn)品價(jià)值 離不開 用戶 需求 場景 這三大元素, 所以我們?cè)谧霎a(chǎn)品設(shè)計(jì)的時(shí)候, 我們得知道我們的用戶到底是怎么樣的一群人, 他們的具體情況是什么, 他們有什么特別的需求, 這樣我們才可以設(shè)計(jì)出對(duì)應(yīng)解決他們需求痛點(diǎn)的產(chǎn)品功能
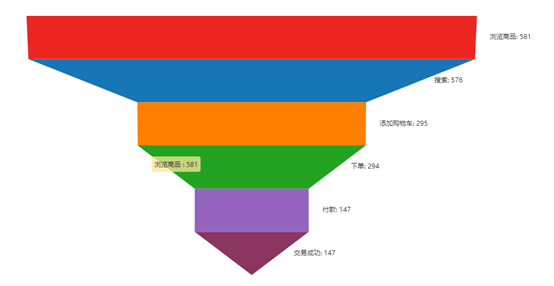
在產(chǎn)品功能迭代的時(shí)候, 我們需要分析用戶畫像行為數(shù)據(jù), 去發(fā)現(xiàn)用戶的操作流失情況, 最典型的一種場景就是漏斗轉(zhuǎn)化情況, 就是基于用戶的行為數(shù)據(jù)去發(fā)現(xiàn)流失嚴(yán)重的頁面, 從而相對(duì)應(yīng)的去優(yōu)化對(duì)應(yīng)的頁面,
比如我們發(fā)現(xiàn)從下載到點(diǎn)擊付款轉(zhuǎn)化率特別低,那么有可能就是我們付款的按鈕的做的有問題, 就可以針對(duì)性的優(yōu)化按鈕的位置等等
同時(shí)也可以分析這部分轉(zhuǎn)化率主要是在那部分用戶群體中低, 假如發(fā)現(xiàn)高齡的用戶的轉(zhuǎn)化率要比中青年的轉(zhuǎn)化率低很多, 那有可能是因?yàn)槲覀冏煮w的設(shè)置以及按鈕本身位置不顯眼等等, 還有操作起來不方便等等因素
6. 數(shù)據(jù)分析
在做描述性的數(shù)據(jù)分析的時(shí)候, 經(jīng)常需要畫像的數(shù)據(jù), 比如描述抖音的美食博主是怎么樣的一群人, 他們的觀看的情況, 他們的關(guān)注其他博主的情況等等
簡單來說就是去做用戶刻畫的時(shí)候, 用戶畫像可以幫助數(shù)據(jù)分析刻畫用戶更加清晰。
如何構(gòu)建用戶畫像:
用戶畫像搭建的架構(gòu)如下:
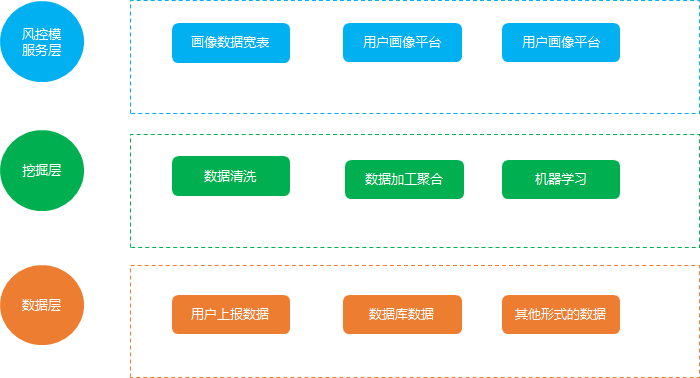
數(shù)據(jù)層:
首先 是數(shù)據(jù)層, 用戶畫像的基礎(chǔ)是首先要去獲取完整的數(shù)據(jù), 互聯(lián)網(wǎng)的數(shù)據(jù)主要是 利用打點(diǎn), 也就是大家說的數(shù)據(jù)埋點(diǎn)上報(bào)上來的, 整個(gè)過程就是 數(shù)據(jù)分析師會(huì)根據(jù)業(yè)務(wù)需要提數(shù)據(jù)上報(bào)的需求,然后由開發(fā)完成, 這樣就有了上報(bào)的數(shù)據(jù)。

除了上報(bào)的數(shù)據(jù), 還有其他數(shù)據(jù)庫同步的數(shù)據(jù), 一般會(huì)把數(shù)據(jù)庫的數(shù)據(jù)同步到hive表中, 按照數(shù)據(jù)倉庫的規(guī)范, 按照一個(gè)個(gè)主題來放置
還有一些其他的數(shù)據(jù)比如外部的一些調(diào)研的數(shù)據(jù), 以excel 格式存在, 就需要把excel 數(shù)據(jù)導(dǎo)入到hive 表中
挖掘?qū)?
有了基礎(chǔ)的數(shù)據(jù)以后, 就進(jìn)入到挖掘?qū)? 這個(gè)層次主要是兩件事情, 一個(gè)是數(shù)據(jù)倉庫的構(gòu)建, 一個(gè)是標(biāo)簽的預(yù)測, 前者是后者的基礎(chǔ)。
一般來說我們會(huì)根據(jù)數(shù)據(jù)層的數(shù)據(jù)表, 對(duì)這些數(shù)據(jù)表的數(shù)據(jù)進(jìn)行數(shù)據(jù)清洗,數(shù)據(jù)計(jì)算匯總, 然后按照數(shù)據(jù)倉庫的分層思想, 比如按照 數(shù)據(jù)原始層, 數(shù)據(jù)清洗層, 數(shù)據(jù)匯總層, 數(shù)據(jù)應(yīng)用層等等進(jìn)行表的設(shè)計(jì)

數(shù)據(jù)原始層的表的數(shù)據(jù)就是上報(bào)上來的數(shù)據(jù)入庫的數(shù)據(jù), 這一層的數(shù)據(jù)沒有經(jīng)過數(shù)據(jù)清洗處理, 是最外層的用戶明細(xì)數(shù)據(jù)
數(shù)據(jù)清洗層主要是數(shù)據(jù)原始層的數(shù)據(jù)經(jīng)過簡單數(shù)據(jù)清洗之后的數(shù)據(jù)層, 主要是去除明顯是臟數(shù)據(jù), 比如年齡大于200歲, 地域來自 FFFF的 等明顯異常數(shù)據(jù)
數(shù)據(jù)匯總層的數(shù)據(jù)主要是根據(jù)數(shù)據(jù)分析的需求, 針對(duì)想要的業(yè)務(wù)指標(biāo), 比如用戶一天的聽歌時(shí)長, 聽歌歌曲數(shù), 聽的歌手?jǐn)?shù)目等等, 就可以按照用戶的維度, 把他的行為進(jìn)行聚合, 得到用戶的輕量指標(biāo)的聚合的表。
這個(gè)層的用處主要是可以快速求出比如一天的聽歌總數(shù), 聽歌總時(shí)長, 聽歌時(shí)長高于1小時(shí)的用戶數(shù), 收藏歌曲數(shù)高于100 的用戶數(shù)是多少等等的計(jì)算就可以從這個(gè)層的表出來
數(shù)據(jù)應(yīng)用層主要是面向業(yè)務(wù)方的需求進(jìn)行加工, 可能是在數(shù)據(jù)匯總的基礎(chǔ)上加工成對(duì)應(yīng)的報(bào)表的指標(biāo)需求, 比如每天聽歌的人數(shù), 次數(shù), 時(shí)長, 搜索的人數(shù), 次數(shù), 歌曲數(shù)等等
按照規(guī)范的數(shù)據(jù)倉庫把表都設(shè)計(jì)完成后, 我們就得到一部分的用戶的年齡性別地域的基礎(chǔ)屬性的數(shù)據(jù)以及用戶觀看 付費(fèi) 活躍等等行為的數(shù)據(jù)
但是有一些用戶的數(shù)據(jù)是拿不到的比如音樂app 為例, 我們一般是拿不到用戶的聽歌偏好這個(gè)屬性的數(shù)據(jù), 我們就要通過機(jī)器學(xué)習(xí)的模型對(duì)用戶的偏好進(jìn)行預(yù)測

機(jī)器學(xué)習(xí)的模型預(yù)測都是基于前面我們構(gòu)建的數(shù)據(jù)倉庫的數(shù)據(jù)的, 因?yàn)橹挥型暾臄?shù)據(jù)倉庫的數(shù)據(jù), 是模型特征構(gòu)建的基礎(chǔ)
服務(wù)層:
有了數(shù)據(jù)層和挖掘?qū)右院? 我們基本對(duì)用戶畫像體系構(gòu)建的差不多, 那么就到了用戶畫像賦能的階段。
最基礎(chǔ)的應(yīng)用就是利用用戶畫像寬表的數(shù)據(jù), 對(duì)用戶的行為進(jìn)行洞察歸因 挖掘行為和屬性特征上的規(guī)律
另外比較大型的應(yīng)用就是搭建用戶畫像的平臺(tái), 背后就是用戶畫像表的集成。
用戶提取: 我們可以利用用戶畫像平臺(tái), 進(jìn)行快速的用戶選取, 比如抽取18-24歲的女性群體 聽過杰倫歌曲的用戶, 我們就可以快速的抽取。
分群對(duì)比: 我們可以利用畫像平臺(tái)進(jìn)行分群對(duì)比。比如我們想要比較音樂vip 的用戶和非vip 的用戶他們?cè)谛袨榛钴S和年齡性別地域 注冊(cè)時(shí)間, 聽歌偏好上的差異, 我們就可以利用這個(gè)平臺(tái)來完成
功能畫像分析: 我們還可以利用用戶畫像平臺(tái)進(jìn)行快速進(jìn)行某個(gè)功能的用戶畫像描述分析, 比如音樂app 的每日推薦功能, 我們想要知道使用每日推薦的用戶是怎么樣的用戶群體, 以及使用每日推薦不同時(shí)長的用戶他們的用戶特征分別都是怎么樣的,就可以快速的進(jìn)行分析
06
在數(shù)據(jù)分析的面試中, 你是否不止一次遇到以下的問題:
DAU降低了, 怎么分析,
用戶留存率下降了怎么分析
訂單數(shù)量下降了怎么分析
像這樣的問題, 如果沒有科學(xué)的思維框架去梳理你的思路的話, 去回答這個(gè)問題我們就會(huì)有一種想要說很多個(gè)點(diǎn), 但不知道先說哪一個(gè)點(diǎn), 只會(huì)造成回答很亂, 沒有條理性, 同時(shí)有可能會(huì)漏斗很多點(diǎn)
回答這種分析的類似的問題的時(shí)候, 大多數(shù)情況下都可以利用5w2h 的方法幫助我們?nèi)ソM織思路, 這樣可以在回答這種類似的問題的時(shí)候, 可以做到邏輯清晰, 答得點(diǎn)縝密完善
比如DAU下降了, 5w2h 分析法會(huì)教你如何拆解DAU下降以及歸因以及給出建議
比如用戶留存率下降了, 5w2h方法會(huì)教你去拆解用戶, 歸納不同群體的留存率下跌原因
比如訂單數(shù)量下跌了, 5w2h 方法助力漏斗分析, 快速挖掘流失的關(guān)鍵步驟, 關(guān)鍵節(jié)點(diǎn)
什么是5w2h:
5w2h 分析法主要是 以五個(gè)W開頭的英語單詞和兩個(gè)以H開頭的英語單詞組成的, 這五個(gè)單詞為我們提供了問題的分析框架
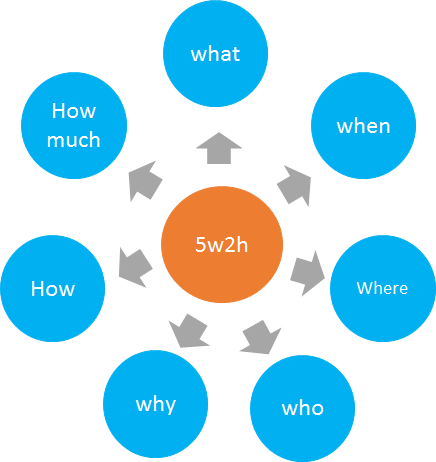
5W的內(nèi)容
1.What-發(fā)生了什么?一般用來值得是問題是什么, what 的精髓在于告訴我們第一步要認(rèn)清問題的本質(zhì)是什么
2.When-何時(shí)?在什么時(shí)候發(fā)生的? 問題發(fā)生的時(shí)間, 比如dau 下降了就是下降的具體時(shí)間分析, 這個(gè)時(shí)間是不是節(jié)假日等等
3.Where-何地?在哪里發(fā)生的? 問題發(fā)生的拆解其中一個(gè)環(huán)節(jié), 還是dau 下降了, 是哪一個(gè)的地區(qū)的下降了, 是哪一個(gè)功能的使用的人下降了等等
4.Who-是誰? 比如dau 下降了, 就是是哪一部分的用戶群體在降, 是哪一個(gè)的年齡, 性別, 使用app 時(shí)長等等
5.Why-為什么會(huì)這樣?dau 可能降低的原因猜想, 比如某個(gè)地區(qū)的dau 降低了, 其他地方的沒有降低, 那可能是這個(gè)地區(qū)的app 在使用的過程中有什么問題
2H的內(nèi)容
1.How-怎樣做?知道了問題是什么以后, 就到了策略層了, 就是我們要采取什么樣的方法和策略去解決這個(gè)dau 下降的問題
2.How Much-多少?做到什么程度?這個(gè)主要是比如dau下降了以后, 我們采取對(duì)應(yīng)的策略是可能花費(fèi)的成本是多少, 以及我們要解決這個(gè)降低的問題解決到什么程度才可以
案例實(shí)戰(zhàn):
1.背景:
某APP的付費(fèi)人數(shù)一直在流失, 如何通過數(shù)據(jù)分析去幫助產(chǎn)品和業(yè)務(wù)去挖掘?qū)?yīng)的付費(fèi)的流失原因并給出對(duì)應(yīng)的解決策略
2.分析思路:
嘗試用5w2h 分析法去拆解這個(gè)問題

what: 我們的問題是付費(fèi)人數(shù)開始流失了, 這種流失應(yīng)該就是表現(xiàn)出來同比和環(huán)比可能都是下降的
when: 整體的流失很難看出問題, 所以我們需要去分析不同的流失周期的用戶的占比大概都是多大, 從而分析出現(xiàn)在付費(fèi)用戶的流失周期主要集中在哪里。
where: 付費(fèi)的入口和不同付費(fèi)點(diǎn)的分析, 主要是分析哪一個(gè)入口的付費(fèi)人數(shù)流失嚴(yán)重或者哪個(gè)功能的付費(fèi)人數(shù)流失嚴(yán)重, 挖掘關(guān)鍵位置
who: 對(duì)用戶的屬性和行為進(jìn)行分析, 分析流失的這部分用戶群體是否具有典型的特征, 比如集中在老年群體, 集中在某個(gè)地區(qū)等等, 行為的特征分析表現(xiàn)在流失的用戶的行為活躍表現(xiàn)是怎么樣的, 比如是否還在app 上活躍, 活躍的時(shí)長和天數(shù)等等的分析
why: 通過上面的分析, 就可能大致得出用戶的流失的原因, 需要把數(shù)據(jù)結(jié)論和猜想對(duì)應(yīng)起來去看, 并做好歸納總結(jié)
how: 當(dāng)我們挖掘和分析出付費(fèi)用戶流失的原因了以后, 需要采取對(duì)應(yīng)的策略去減少流失的速度, 同時(shí)針對(duì)流失的用戶進(jìn)行挽留和召回
how much: 在通過數(shù)據(jù)分析給出對(duì)應(yīng)的策略的時(shí)候, 也需要幫助業(yè)務(wù)方去評(píng)估我們的策略大概需要的成本, 讓業(yè)務(wù)方知道這個(gè)策略的可行性以及價(jià)值
3.分析過程:
(1) 不同用戶的流失周期比例分析, 大部分的群體的流失周期還不是很長, 說明整體來說用戶的流失是最近剛發(fā)生的, 同時(shí)流失的周期不長, 說明我們有能力可以針對(duì)這部分的流失用戶利用策略進(jìn)行挽留
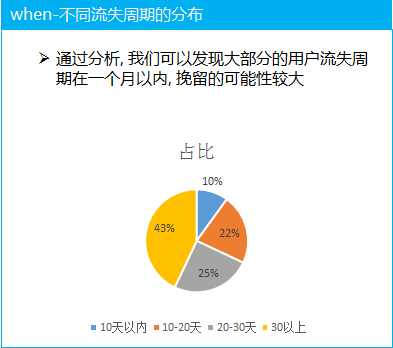
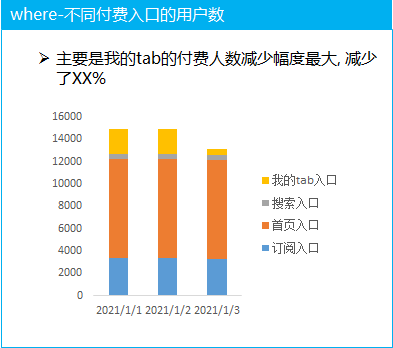
(2)不同付費(fèi)入口的拆解分析
對(duì)比付費(fèi)的四個(gè)主要的入口, 分析每天的付費(fèi)人數(shù)的走勢, 發(fā)現(xiàn)付費(fèi)人數(shù)的減少主要集中在我的tab 入口, 我的tab 入口的付費(fèi)降低的可能原因是什么呢
這就需要拉上業(yè)務(wù)方一起去分析對(duì)應(yīng)的原因, 比如是可能是這個(gè)位置的付費(fèi)功能的具體流失的每一個(gè)環(huán)節(jié)的流失情況(結(jié)合漏斗分析一起去看)
分析出我的tab 頁面中 付費(fèi)功能具體的流失環(huán)節(jié), 然后再針對(duì)性的進(jìn)行調(diào)整迭代
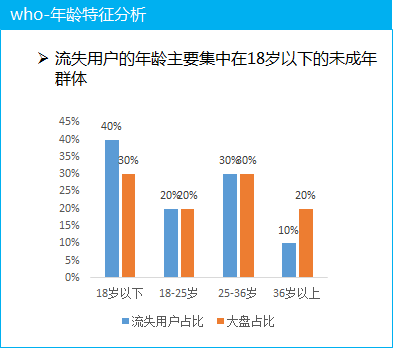
(3) 用戶特征分析
這里以年齡為例, 分析流失的付費(fèi)用戶的年齡特征, 發(fā)現(xiàn)主要集中在18歲以下的未成年群體, 這部分的用戶群體為什么流失呢? 就需要結(jié)合用戶反饋等一起去看
除了年齡的角度, 我們還可以分析流失的用戶的性別特征, 城市級(jí)別特征, 活躍時(shí)長和活躍天數(shù), 經(jīng)常使用的功能等特征
(4) 原因總結(jié)歸納
通過分析, 付費(fèi)的用戶群體主要原因是我的tab 的付費(fèi)功能引起的, 可能是具體的某個(gè)付費(fèi)轉(zhuǎn)化環(huán)節(jié)出現(xiàn)問題
流失的用戶群體主要是18歲以下, 男性, 三線城市為主(假設(shè))
流失的用戶群體活躍時(shí)長, 活躍次數(shù), 活躍天數(shù)等沒有明顯下降
(5) 策略落地
這個(gè)環(huán)節(jié)需要和業(yè)務(wù)方反饋我們的數(shù)據(jù)分析結(jié)論, 然后結(jié)合產(chǎn)品的經(jīng)驗(yàn)以及用戶反饋以及調(diào)查問卷等方法進(jìn)一步確定原因
如果確定好是我的tab 中付費(fèi)功能的某個(gè)環(huán)節(jié)出現(xiàn)問題, 就需要針對(duì)的進(jìn)行改進(jìn), 同時(shí)上線小流量的ab test 去驗(yàn)證我們的策略是否有效
07
麥肯錫邏輯樹
邏輯樹又稱為問題數(shù),演繹樹或者分解樹,是麥肯錫公司提出的分析問題,解決問題的重要方法
首先它的形態(tài)像一顆樹,把已知的問題比作樹干,然后考慮哪些問題或者任務(wù)與已知問題有關(guān),將這些問題或子任務(wù)比作邏輯樹的樹枝,一個(gè)大的樹枝還可以繼續(xù)延續(xù)伸出更小的樹枝,逐步列出所有與已知問題相關(guān)聯(lián)的問題
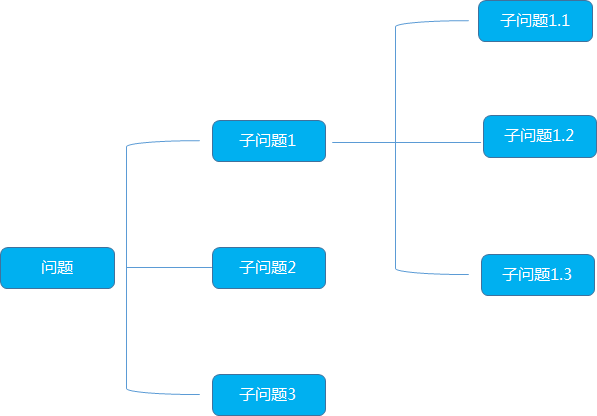
總的來說, 邏輯樹滿足三個(gè)要素
要素化:把相同問題總結(jié)歸納成要素
框架化:將各個(gè)要素組織成框架,遵守不重不漏的原則
關(guān)聯(lián)化:框架內(nèi)的各要素保持必要的相互關(guān)系,簡單而不孤立
邏輯樹的作用:
數(shù)據(jù)體系的搭建
數(shù)據(jù)體系的搭建中, 需要借助邏輯樹的思路將業(yè)務(wù)的整體的目標(biāo)結(jié)構(gòu)化的進(jìn)行拆解, 然后轉(zhuǎn)化成可以量化的數(shù)據(jù)指標(biāo), 再轉(zhuǎn)變?yōu)橹笜?biāo)體系。
舉個(gè)例子, 比如下面的OSM模型搭建數(shù)據(jù)體系的思路就是借助了邏輯樹的思路
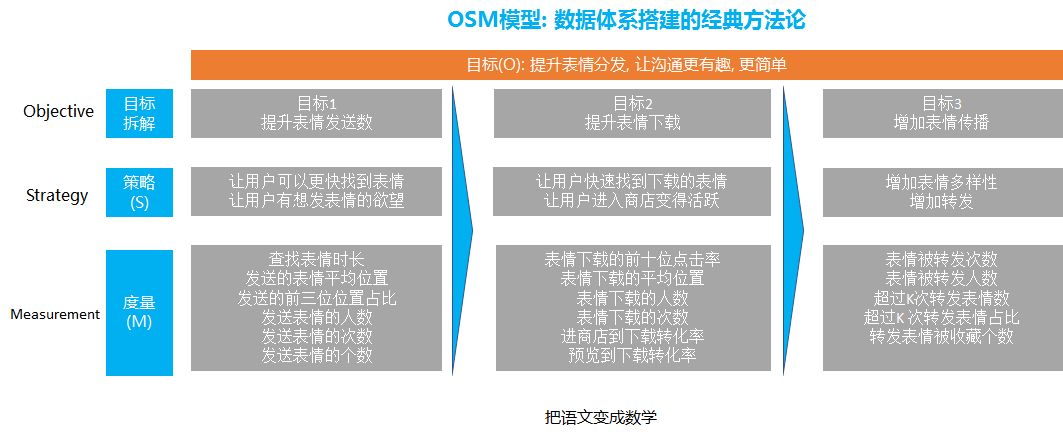
首先業(yè)務(wù)的整體目標(biāo)是 提升表情的分發(fā), 讓表情的溝通更有趣更簡單
通過邏輯樹分析法, 我們可以進(jìn)行第一步的拆解, 就是把整體表情進(jìn)行拆解為提升表情發(fā)送數(shù), 提升表情下載, 增加表情傳播
提高表情發(fā)送數(shù)主要是提升用戶的發(fā)送, 那么就變成去提升用戶的發(fā)送, 那么怎么提升用戶的發(fā)送呢, 我們可以通過內(nèi)容和功能維度去解答
在內(nèi)容方面, 我們要做到我們的表情豐富度和有趣度和新穎度和表達(dá)度等等, 要讓用戶有發(fā)這個(gè)表情的欲望
除了表情本身, 在發(fā)表情功能上我們也要針對(duì)性的進(jìn)行優(yōu)化, 比如提高用戶查找表情的效率, 我們要去縮短查找表情的時(shí)間。
提升表情的下載, 也是同樣的內(nèi)容和功能本身, 在功能方面, 我們涉及到怎么把每個(gè)用戶喜歡的表情排在最前面, 因?yàn)檫@樣用戶可以快速找到他們想要下載的表情.
另外, 也要通過功能的優(yōu)化, 提升用戶進(jìn)入到表情商店的比例, 從源頭上保證有足夠的用戶數(shù)都能夠進(jìn)入到表情商店
在內(nèi)容方面, 我們要保證表情商店的表情在豐富度和吸引用戶方面進(jìn)行優(yōu)化等等
提升表情的傳播, 也是需要在內(nèi)容和功能上優(yōu)化, 這就涉及到社交關(guān)系的傳播和表情的關(guān)系, 涉及除了要去引導(dǎo)用戶下載自己喜歡的, 還要去下載他和朋友共同喜歡的表情
這樣當(dāng)a 用戶發(fā)送了a 和a 的朋友b 共同喜歡的表情 就可以得到更多的轉(zhuǎn)發(fā)
2. 數(shù)據(jù)問題的分析
針對(duì)用戶訂單減少的問題的分析, 可以利用邏輯樹分析法, 定位到可能的流失原因, 再用數(shù)據(jù)驗(yàn)證
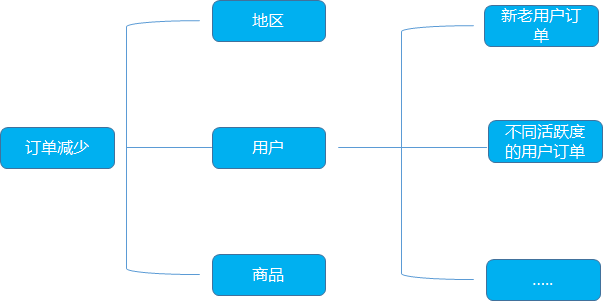
比如某個(gè)電商平臺(tái)的訂單降低, 我們利用邏輯樹的拆解從地區(qū), 用戶, 商品類型等多個(gè)維度去思考。
從地區(qū)的角度, 整體的訂單減少, 可以看一下是否是某個(gè)地區(qū)降低了, 可以細(xì)分到省, 市
從用戶的角度, 是否是哪一類的用戶的訂單在減少, 同時(shí)還可以區(qū)分不同活躍度的用戶在訂單上的表現(xiàn), 看具體的原因猜想
從商品的角度, 可以區(qū)分一下不同品類的商品看是否是特定品類的商品訂單量跌了
邏輯樹分析法在dau 中的應(yīng)用:
背景:
某電商app DAU 跌了, 需要分析為什么dau 會(huì)跌, 這也是數(shù)據(jù)分析面試經(jīng)典的問題, 在回答這個(gè)問題的時(shí)候, 為了使得我們的答案具有結(jié)構(gòu)化和條理化, 需要應(yīng)用邏輯樹分析法
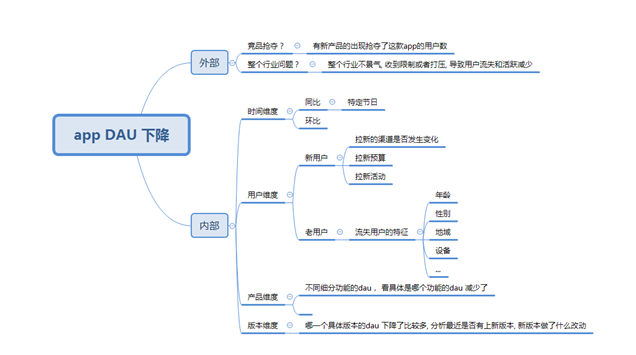
分析思路:
整體的分析思路如上,首先是拆分成外部和內(nèi)部因素, 從最大的兩個(gè)思路去切入, 一般去分析這個(gè)問題的時(shí)候, 很容易就會(huì)忽略外部因素, 外部因素也是很重要的一部分
外部的思考主要是競品分析, 分析是否是競品的崛起導(dǎo)致一部分用戶轉(zhuǎn)移到他們那邊去了
外部的另外一個(gè)就是行業(yè)分析, 可以借助pest 等分析方法,分析這個(gè)行業(yè)的外部環(huán)境是否變得惡劣, 比如國家限制, 生活, 經(jīng)濟(jì), 政策, 政治等外部原因
假如外部沒有明顯的問題, 這才進(jìn)入到內(nèi)部因素的排查
內(nèi)部的分析首先應(yīng)該是時(shí)間因素, 因?yàn)檎嬲诠ぷ鲗?shí)際中, 我們發(fā)現(xiàn)大多數(shù)的dau 等數(shù)據(jù)指標(biāo)有大幅度波動(dòng)都是因?yàn)楣?jié)日引起的
所以有兩個(gè)判斷的方法, 假如這個(gè)dau 只是環(huán)比跌的很厲害, 然而同比沒有明顯變化, 甚至可能比去年這個(gè)指標(biāo)還是漲的, 那么很大的概率可能就是節(jié)假日的影響
然后是用戶維度, 整體的DAU= 新用戶+老用戶, 所以應(yīng)該看這兩個(gè)部分的是哪一部分的用戶數(shù)減少
如果是新用戶減少, 因?yàn)樾掠脩羰菑那劳ㄟ^廣告買量買過來的, 與這個(gè)數(shù)量相關(guān)的涉及到 渠道的質(zhì)量, 買量的錢, 買完的一些承接運(yùn)營活動(dòng)
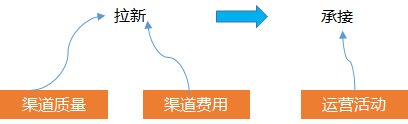
所以, 可以分開拆解看, 是否是渠道本身的質(zhì)量問題, 比如騰訊廣點(diǎn)通, 頭條巨量, 看渠道本身在投放上起量是否是有問題的
同時(shí)也要看我們投放廣告的錢是否有減少這會(huì)直接影響到我們能拉多少的人,預(yù)算直接決定了你的拉新絕對(duì)量的上限
拉取過來的用戶要保證活躍, 我們通常會(huì)有運(yùn)營活動(dòng)或其他策略的承接, 也就是業(yè)界說的拉承一體化, 所以我們要去分析是否是運(yùn)營活動(dòng)的效果或者其他策略的效果影響我們的承接, 導(dǎo)致這部分用戶的活躍度下降
除了新用戶的分析, 老用戶的分析也是非常重要的, 主要有常用的用戶畫像分析, 這部分可以參照 數(shù)據(jù)分析思維和方法—用戶畫像分析
主要是分析老用戶是否下降, 如果下降了分析這部分下降的用戶群體具有什么樣的畫像特征, 這樣可以輸出一個(gè)下跌用戶的完整行為和基礎(chǔ)屬性的洞察, 比如下降的用戶群主要是18歲以下的未成年人等等
第三個(gè)是產(chǎn)品本身維度, 如果分析出是所有類型的用戶, 所有渠道的用戶都在跌, 那就可能是產(chǎn)品本身的功能引起的
我們需要去排查一下dau 主要的功能模塊的組成的用戶, 去看一下這些功能的dau 是否跌的, 一般如果沒有版本上線, 舊的功能的用戶波動(dòng)是由于功能bug 引起的
產(chǎn)品本身的排查比較麻煩, 因?yàn)橛锌赡芏ㄎ荒硞€(gè)功能的人數(shù)變少了但是不知道原因, 這時(shí)候可以借助用戶反饋, 一般可以從用戶反饋上發(fā)現(xiàn)一些問題
08
漏斗分析法
漏斗分析是一種可以直觀地呈現(xiàn)用戶行為步驟以及各步驟之間的轉(zhuǎn)化率,分析各個(gè)步驟之間的轉(zhuǎn)化率的分析方法
比如對(duì)應(yīng)我們每一次在淘寶上的購物, 從打開淘寶app, 到搜索產(chǎn)品, 到查看產(chǎn)品詳情, 到添加購物車, 到下單, 到成功交易, 漏斗分析就是幫助我們?nèi)ビ?jì)算每一個(gè)環(huán)節(jié)的轉(zhuǎn)化率
從打開淘寶app 到搜索的轉(zhuǎn)化率, 從搜索產(chǎn)品到查看產(chǎn)品的詳情的轉(zhuǎn)化率,從查看產(chǎn)品到添加購物車的轉(zhuǎn)化率, 從添加購物車到下單的轉(zhuǎn)化率等等
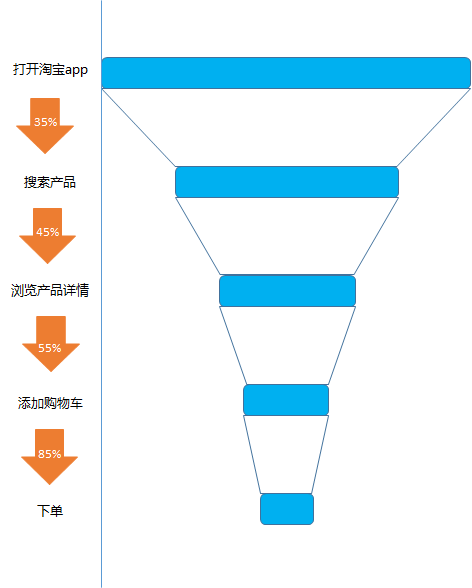
漏斗分析的價(jià)值:
漏斗分析的價(jià)值主要有: 功能優(yōu)化, 運(yùn)營投放, 用戶流失等

功能優(yōu)化:
以視頻制作工具為例, 從下面我們可以明顯看出, 進(jìn)入到上傳視頻的轉(zhuǎn)化率只有80%, 可能是上傳入口不明顯, 上傳的引導(dǎo)不夠, 上傳功能的吸引程度不夠等原因引起的, 我們就可以去優(yōu)化上傳功能

運(yùn)營投放:
以運(yùn)營投放類為例, 在實(shí)際業(yè)務(wù)中經(jīng)常會(huì)對(duì)一些定向的用戶投放一些活動(dòng), 讓他們參加活動(dòng), 比如針對(duì)游戲的業(yè)務(wù), 會(huì)定期針對(duì)潛在的付費(fèi)用戶投放一批充值優(yōu)惠大禮包活動(dòng)
從下圖的觸達(dá)到參與的轉(zhuǎn)化率只有 62.5%, 說明我們選的定向的用戶可能對(duì)于我們的活動(dòng)不是非常感興趣, 可能是這批用戶本身不是特別喜歡參與活動(dòng), 所以我們就可以重新選取其他可能更加可能響應(yīng)的用戶來做定向推送
那么怎么選取最有可能參與活動(dòng)的用戶呢, 這里最簡單的就可以用用戶特征分析的方法來, 我們可以分析出參與活動(dòng)和不參與活動(dòng)的特征差異, 進(jìn)行對(duì)比,
也就是采取對(duì)比的分析方法, 具體可以見數(shù)據(jù)分析方法和思維—對(duì)比細(xì)分
分析的結(jié)果就可以得到比如參與活動(dòng)的用戶可能本身在過去的付費(fèi)頻次上更好, 付費(fèi)的金額更大, 并且在游戲的平均時(shí)長, 平均的游戲局?jǐn)?shù)上更多, 年齡集中在18歲以下的群體中
那么我們就可以用這些特征去圈定更多的用戶去做投放
另外一種去優(yōu)化定向用戶提高參與率的方法就是去利用模型去提前預(yù)測好哪些用戶可能會(huì)參與活動(dòng), 可能使用的模型比如決策樹, 邏輯回歸等分類模型

用戶流失:
以電商app 淘寶為例, 假如我們的訂單人數(shù)下降了, 這時(shí)候就需要梳理用戶購買鏈路, 把用戶從打開app 到下單的所有的鏈路都梳理一遍, 然后利用漏斗分析, 計(jì)算每個(gè)環(huán)節(jié)的轉(zhuǎn)化率
假如我們梳理鏈路中發(fā)現(xiàn), 從搜索商品到查看商品的轉(zhuǎn)化率很低, 那么我們就需要看是否是很多搜索無結(jié)果, 或者是搜索中的結(jié)果很多用戶不太滿意, 導(dǎo)致用戶不買單
那就可以把電商的付費(fèi)問題轉(zhuǎn)化為搜索的問題, 從而又可以對(duì)搜索的整個(gè)轉(zhuǎn)化鏈路再做一次漏斗分析, 一步步的去定位問題

漏斗分析的作用:
在用戶增長的最出名的漏斗模型叫做AARRR, 即從用戶獲取, 用戶激活, 用戶留存, 用戶付費(fèi)到用戶傳播
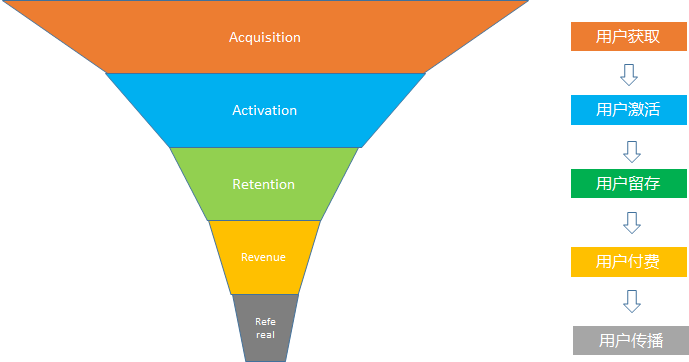
以拼多多為例, 以AARRR漏斗模型解析拼多多的用戶增長之路
1.用戶獲取
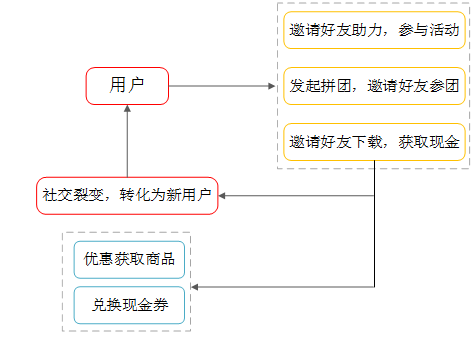
拼多多主要的目標(biāo)群體是三四線城市,這也屬于現(xiàn)有電商品臺(tái)比較空白的區(qū)域,對(duì)于三四線用戶來說,最好的吸引方案就是優(yōu)惠。
而且三四線用戶時(shí)間充足,時(shí)間成本于他們而言是非常低的,而砍價(jià)也是一種慣常的方法,在他們的群體中很少存在對(duì)貪小便宜歧視的問題,也沒有太多的社交壓力,甚至砍價(jià)可以變成一種聯(lián)系的手段,砍價(jià)群又何嘗不是一種交流。
他們也很樂意用時(shí)間和社交成本來換取更大的優(yōu)惠。所以砍價(jià)這種優(yōu)惠活動(dòng)紅極一時(shí),也幫助拼多多拉取了很多流量
砍價(jià)活動(dòng)借助微信朋友圈和微信群的關(guān)系鏈, 成為爆發(fā)式的轉(zhuǎn)發(fā)和增長, 一般親朋友不會(huì)拒絕你的要請(qǐng)砍一刀
2.用戶激活
當(dāng)拉到新用戶的時(shí)候, 就要保證最大程度的去激活他, 拼多多采取的做法也是跟拉新類似, 就是不斷用用戶的傳播去觸達(dá)好友
當(dāng)一個(gè)用戶被其他朋友反復(fù)觸達(dá)的時(shí)候, 自然而然就會(huì)去打開曾經(jīng)下載過的app,在其他朋友感受到拼多多百億補(bǔ)貼各種補(bǔ)貼各種優(yōu)惠的真香的時(shí)候, 自己也會(huì)去嘗試
3.留存
為了提高用戶的留存, 拼多多提供了一個(gè)簽到領(lǐng)取獎(jiǎng)品的活動(dòng)鼓勵(lì)用戶每天都打開app 來簽到打卡, 簽到滿XX天就可以送你對(duì)應(yīng)的商品禮物, 大大促進(jìn)拼多多用戶群體的薅羊毛的心理, 同時(shí)也提升了留存
除了這個(gè)活動(dòng)拼多多里面還設(shè)置了不同的各種小活動(dòng), 滿足不同的用戶群體的需要, 在玩小任務(wù)的過程中領(lǐng)取對(duì)應(yīng)的獎(jiǎng)勵(lì)
4. 用戶付費(fèi)
拼多多以優(yōu)惠券等的形式刺激用戶下單, 比如下面的下首單并賺XX元, 而且還不給你叉掉這個(gè)頁面的按鈕
還有就是非常出名的百億補(bǔ)貼, 直接用大額現(xiàn)金給用戶補(bǔ)貼, 這一個(gè)打法把一二線的用戶也被轉(zhuǎn)化了
還有就是0元下單的活動(dòng), 0元免費(fèi)下三單全額返還金額的活動(dòng)
以及限時(shí)優(yōu)惠限時(shí)秒殺, 9快手特賣等都是促使用戶去下單等活動(dòng)
頁面上也是各種“”XX已經(jīng)拼單“”等文字的提醒引導(dǎo)也是促進(jìn)用戶下單
5. 用戶傳播
傳播主要依賴微信這個(gè)流量大平臺(tái)以及微信關(guān)系鏈, 朋友之間的傳播分為, 有些東西是要轉(zhuǎn)發(fā)朋友才可以領(lǐng)取現(xiàn)金以及拼單以及優(yōu)惠, 在這些優(yōu)惠面前, 轉(zhuǎn)發(fā)的成本變得很小
另外拼多多上是有一些真的實(shí)惠又好用的高性價(jià)比的商品, 這種的商品會(huì)引發(fā)朋友之間互相推薦
以上的一些原因, 拼多多的商品和玩法在朋友之前瘋狂流轉(zhuǎn), 在傳播的過程中, 每個(gè)用戶都熟知了拼多多可以做到這么實(shí)惠的玩法, 被觸達(dá)的用戶又會(huì)開始新的轉(zhuǎn)發(fā), 從而引爆增長
社交網(wǎng)絡(luò)的增長是沒有盡頭的, 也是阻止不了的, 一代帝國的誕生
數(shù)據(jù)是風(fēng), 你們是風(fēng)上閃爍的星群
風(fēng)中細(xì)數(shù)星群, 一如那余味纏繞的甘醇
-----------------------------------------------------------------
公布前期送書活動(dòng)中獎(jiǎng)讀者,請(qǐng)于24小時(shí)內(nèi)通過公眾號(hào)菜單-“關(guān)于”添加小編微信,聯(lián)系送書事宜。