
一個(gè)架構(gòu)師的緩存修煉之路

本文作者:張勇,現(xiàn)任科大訊飛高級(jí)架構(gòu)師。11年后端經(jīng)驗(yàn),曾就職于同程藝龍、神州優(yōu)車等公司。樂于分享、熱衷通過自己的實(shí)踐經(jīng)驗(yàn)平鋪對(duì)技術(shù)的理解。
“Nginx+業(yè)務(wù)邏輯層+數(shù)據(jù)庫+緩存層+消息隊(duì)列,這種模型幾乎能適配絕大部分的業(yè)務(wù)場(chǎng)景。
這么多年過去了,這句話或深或淺地影響了我的技術(shù)選擇,以至于后來我花了很多時(shí)間去重點(diǎn)學(xué)習(xí)緩存相關(guān)的技術(shù)。
我在10年前開始使用緩存,從本地緩存、到分布式緩存、再到多級(jí)緩存,踩過很多坑。下面我結(jié)合自己使用緩存的歷程,談?wù)勎覍?duì)緩存的認(rèn)識(shí)。
01?本地緩存
1. 頁面級(jí)緩存
"foobar" ??????some jsp?content?
2. 對(duì)象緩存
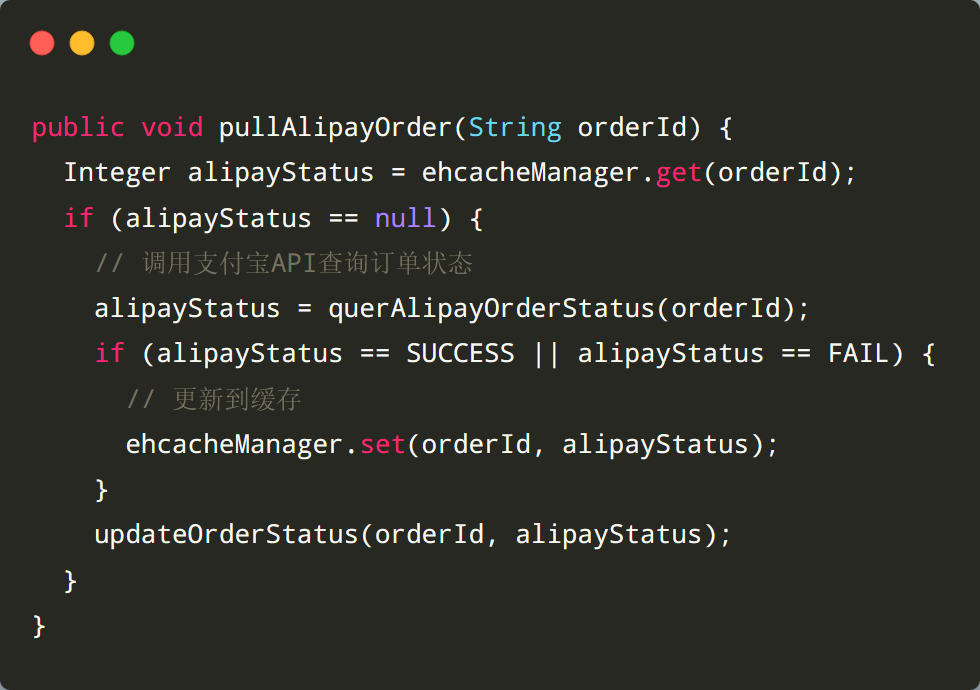
3. 刷新策略
2018年,我和我的小伙伴自研了配置中心,為了讓客戶端以最快的速度讀取配置, 本地緩存使用了 Guava,整體架構(gòu)如下圖所示:
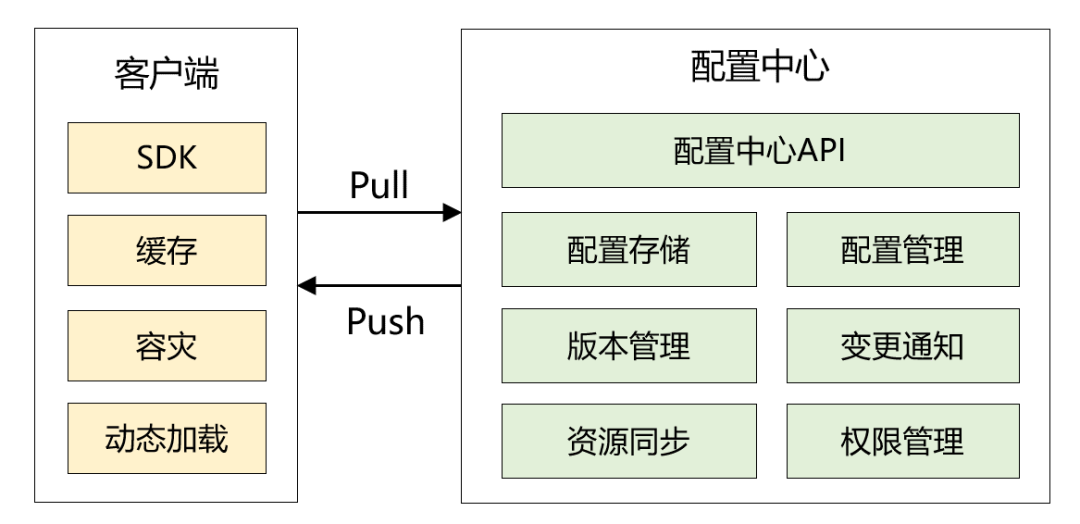
那本地緩存是如何更新的呢?有兩種機(jī)制:
客戶端啟動(dòng)定時(shí)任務(wù),從配置中心拉取數(shù)據(jù)。 當(dāng)配置中心有數(shù)據(jù)變化時(shí),主動(dòng)推送給客戶端。這里我并沒有使用websocket,而是使用了 RocketMQ Remoting 通訊框架。
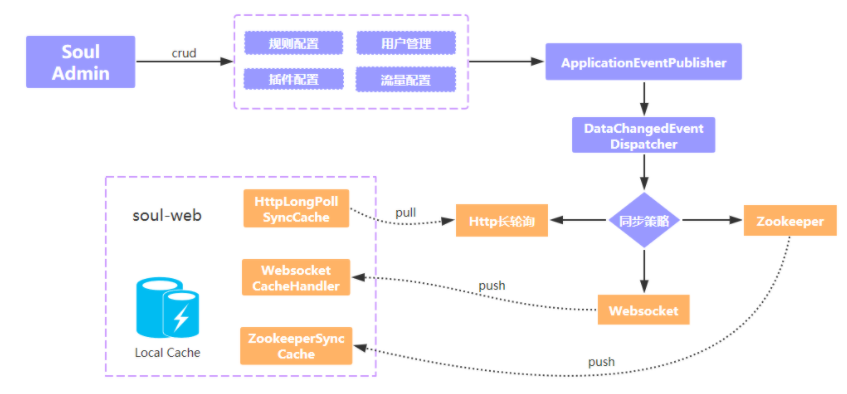
▍zookeeper watch機(jī)制
▍websocket 機(jī)制
websocket 和 zookeeper 機(jī)制有點(diǎn)類似,當(dāng)網(wǎng)關(guān)與 admin 首次建立好 websocket 連接時(shí),admin 會(huì)推送一次全量數(shù)據(jù),后續(xù)如果配置數(shù)據(jù)發(fā)生變更,則將增量數(shù)據(jù)通過 websocket 主動(dòng)推送給 soul-web。
http請(qǐng)求到達(dá)服務(wù)端后,并不是馬上響應(yīng),而是利用 Servlet 3.0 的異步機(jī)制響應(yīng)數(shù)據(jù)。當(dāng)配置發(fā)生變化時(shí),服務(wù)端會(huì)挨個(gè)移除隊(duì)列中的長(zhǎng)輪詢請(qǐng)求,告知是哪個(gè) Group 的數(shù)據(jù)發(fā)生了變更,網(wǎng)關(guān)收到響應(yīng)后,再次請(qǐng)求該 Group 的配置數(shù)據(jù)。
pull 模式必不可少 增量推送大同小異
02 分布式緩存
1.? 合理控制對(duì)象大小及讀取策略
1、數(shù)據(jù)格式非常精簡(jiǎn),只返回給前端必要的數(shù)據(jù),部分?jǐn)?shù)據(jù)通過數(shù)組的方式返回
2、使用 websocket,進(jìn)入頁面后推送全量數(shù)據(jù),數(shù)據(jù)發(fā)生變化推送增量數(shù)據(jù)
再回到我的問題上,最終是用什么方案解決的呢?當(dāng)時(shí),我們的比分直播模塊緩存格式是 JSON 數(shù)組,每個(gè)數(shù)組元素包含 20 多個(gè)鍵值對(duì), 下面的 JSON 示例我僅僅列了其中 4 個(gè)屬性。
[{"playId":"2399","guestTeamName":"小牛","hostTeamName":"湖人","europe":"123"}]
這種數(shù)據(jù)結(jié)構(gòu),一般情況下沒有什么問題。但是當(dāng)字段數(shù)多達(dá) 20 多個(gè),而且每天的比賽場(chǎng)次非常多時(shí),在高并發(fā)的請(qǐng)求下其實(shí)很容易引發(fā)問題。
基于工期以及風(fēng)險(xiǎn)考慮,最終我們采用了比較保守的優(yōu)化方案:
[["2399","小牛","湖人","123"]]修改完成之后, 緩存的大小從平均 300k 左右降為 80k 左右,YGC 頻率下降很明顯,同時(shí)頁面響應(yīng)也變快了很多。
但過了一會(huì),cpu load 會(huì)在瞬間波動(dòng)得比較高。可見,雖然我們減少了緩存大小,但是讀取大對(duì)象依然對(duì)系統(tǒng)資源是極大的損耗,導(dǎo)致 Full GC 的頻率也不低。?
3)為了徹底解決這個(gè)問題,我們使用了更精細(xì)化的緩存讀取策略。
我們把緩存拆成兩個(gè)部分,第一部分是全量數(shù)據(jù),第二部分是增量數(shù)據(jù)(數(shù)據(jù)量很小)。頁面第一次請(qǐng)求拉取全量數(shù)據(jù),當(dāng)比分有變化的時(shí)候,通過 websocket 推送增量數(shù)據(jù)。
第 3 步完成后,頁面的訪問速度極快,服務(wù)器的資源使用也很少,優(yōu)化的效果非常優(yōu)異。
2.? 分頁列表查詢
select?id?from?blogs?limit?0,10?select?id?from?blogs?where?id?in?(noHitId1,?noHitId2)本地緩存:性能極高,for 循環(huán)即可 memcached:使用 mget 命令 Redis:若緩存對(duì)象結(jié)構(gòu)簡(jiǎn)單,使用 mget 、hmget命令;若結(jié)構(gòu)復(fù)雜,可以考慮使用 pipleline,lua腳本模式
03 多級(jí)緩存
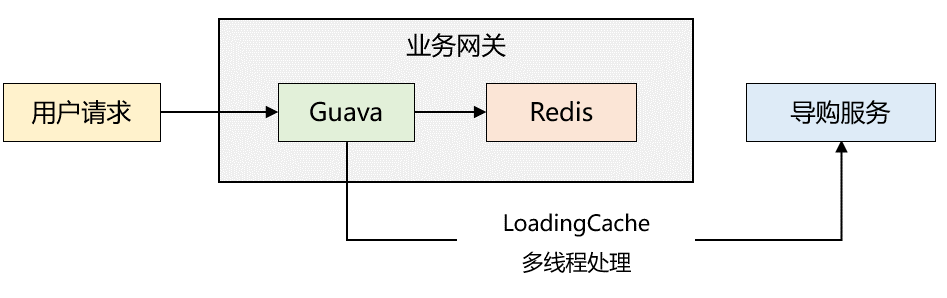
緩存讀取流程如下:
1、業(yè)務(wù)網(wǎng)關(guān)剛啟動(dòng)時(shí),本地緩存沒有數(shù)據(jù),讀取 Redis 緩存,如果 Redis 緩存也沒數(shù)據(jù),則通過 RPC 調(diào)用導(dǎo)購(gòu)服務(wù)讀取數(shù)據(jù),然后再將數(shù)據(jù)寫入本地緩存和 Redis 中;若 Redis 緩存不為空,則將緩存數(shù)據(jù)寫入本地緩存中。
2、由于步驟1已經(jīng)對(duì)本地緩存預(yù)熱,后續(xù)請(qǐng)求直接讀取本地緩存,返回給用戶端。
3、Guava 配置了 refresh 機(jī)制,每隔一段時(shí)間會(huì)調(diào)用自定義 LoadingCache 線程池(5個(gè)最大線程,5個(gè)核心線程)去導(dǎo)購(gòu)服務(wù)同步數(shù)據(jù)到本地緩存和 Redis 中。
優(yōu)化后,性能表現(xiàn)很好,平均耗時(shí)在 5ms 左右。最開始我以為出現(xiàn)問題的幾率很小,可是有一天晚上,突然發(fā)現(xiàn) app 端首頁顯示的數(shù)據(jù)時(shí)而相同,時(shí)而不同。
1、惰性加載仍然可能造成多臺(tái)機(jī)器的數(shù)據(jù)不一致
2、 LoadingCache 線程池?cái)?shù)量配置的不太合理,? 導(dǎo)致了線程堆積
緩存是非常重要的一個(gè)技術(shù)手段。如果能從原理到實(shí)踐,不斷深入地去掌握它,這應(yīng)該是技術(shù)人員最享受的事情。
這篇文章屬于緩存系列的開篇,更多是把我 10 多年工作中遇到的典型問題娓娓道來,并沒有非常深入地去探討原理性的知識(shí)。
我想我更應(yīng)該和朋友交流的是:如何體系化的學(xué)習(xí)一門新技術(shù)。
選擇該技術(shù)的經(jīng)典書籍,理解基礎(chǔ)概念? 建立該技術(shù)的知識(shí)脈絡(luò)? 知行合一,在生產(chǎn)環(huán)境中實(shí)踐或者自己造輪子 不斷復(fù)盤,思考是否有更優(yōu)的方案
后續(xù)我會(huì)連載一些緩存相關(guān)的內(nèi)容:包括緩存的高可用機(jī)制、codis 的原理等,歡迎大家繼續(xù)關(guān)注。
關(guān)于緩存,如果你有自己的心得體會(huì)或者想深入了解的內(nèi)容,歡迎評(píng)論區(qū)留言。
推薦閱讀:
歡迎關(guān)注微信公眾號(hào):互聯(lián)網(wǎng)全棧架構(gòu),收取更多有價(jià)值的信息。