
醫(yī)學(xué)圖像數(shù)據(jù)讀取及預(yù)處理方法總結(jié)

極市導(dǎo)讀
?個人認為,比如說醫(yī)學(xué)圖像分割這個方向,再具體一點比如腹部器官分割或者肝臟腫瘤分割,需要掌握兩方面的知識:(1)醫(yī)學(xué)圖像預(yù)處理方法;(2)深度學(xué)習(xí)知識。?而第一點是進行第二點的必要條件,因為你需要了解輸入到DL網(wǎng)絡(luò)中的到底是長啥樣的數(shù)據(jù)。這篇文章主要介紹常見的醫(yī)學(xué)圖像讀取方式和預(yù)處理方法。>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
這兩天又重新回顧了一下醫(yī)學(xué)圖像數(shù)據(jù)的讀取和預(yù)處理方法,在這里總結(jié)一下。
基于深度學(xué)習(xí)做醫(yī)學(xué)圖像數(shù)據(jù)分析,例如病灶檢測、腫瘤或者器官分割等任務(wù),第一步就是要對數(shù)據(jù)有一個大概的認識。但是我剛剛?cè)腴T醫(yī)學(xué)圖像分割的時候,很迷茫不知道自己該干啥,不知道需要準(zhǔn)備哪些知識,慢慢到現(xiàn)在才建立了一個簡陋的知識體系。個人認為,比如說醫(yī)學(xué)圖像分割這個方向,再具體一點比如腹部器官分割或者肝臟腫瘤分割,需要掌握兩方面的知識:(1)醫(yī)學(xué)圖像預(yù)處理方法;(2)深度學(xué)習(xí)知識。 而第一點是進行第二點的必要條件,因為你需要了解輸入到DL網(wǎng)絡(luò)中的到底是長啥樣的數(shù)據(jù)。
這篇文章主要介紹常見的醫(yī)學(xué)圖像讀取方式和預(yù)處理方法。
1. 醫(yī)學(xué)圖像數(shù)據(jù)讀取
1.1 ITK-SNAP軟件
首先介紹一下醫(yī)學(xué)圖像可視化軟件ITK-SNAP, 可以作為直觀感受醫(yī)學(xué)圖像3D結(jié)構(gòu)的工具,也可以用來做為分割和檢測框標(biāo)注工具,免費,很好用,安利一下:ITK-SNAP官方下載地址:http://www.itksnap.org/pmwiki/pmwiki.php。此外,mango(http://ric.uthscsa.edu/mango/)是另一個非常輕量的可視化軟件,也可以試試。我一般用ITK-SNAP。
ITK-SNAP的使用方法可以參考大佬的這篇博文,講的很簡潔:
JunMa:ITK-SANP使用入門:
https://zhuanlan.zhihu.com/p/104381149

首先要明確一下和人體對應(yīng)的方向,其中三個窗口對應(yīng)三個切面,對應(yīng)關(guān)系如下圖所示,按照字母索引即可。例如,左上圖對應(yīng)R-A-L-P這個面,是從腳底往頭部方向看的切面(即z方向),另外兩張類似。

也可以同時將分割結(jié)果導(dǎo)入,對比觀察。

對于標(biāo)注不太嚴(yán)謹(jǐn)?shù)牡胤揭部梢跃毣薷摹.?dāng)然公開集的話,絕大多數(shù)都挺好的。自己標(biāo)注也是類似。(如果顯示不太清晰,對比度太低,需要在軟件中調(diào)節(jié)窗寬和窗位)
1.2 SimpleITK
我們知道,最常見的醫(yī)學(xué)圖像有CT和MRI,這都是三維數(shù)據(jù),相比于二維數(shù)據(jù)要難一些。而且保存下來的數(shù)據(jù)也有很多格式,常見的有.dcm .nii(.gz) .mha .mhd(+raw)。這些類型的數(shù)據(jù)都可以用Python的SimpleITK來處理,此外pydicom可以對.dcm文件進行讀取和修改。
讀取操作的目的是從每一個病人數(shù)據(jù)中抽取tensor數(shù)據(jù),用Simpleitk讀取上面的.nii數(shù)據(jù)為例:
import numpy as np
import os
import glob
import SimpleITK as sitk
from scipy import ndimage
import matplotlib.pyplot as plt # 載入需要的庫
# 指定數(shù)據(jù)root路徑,其中data目錄下是volume數(shù)據(jù),label下是segmentation數(shù)據(jù),都是.nii格式
data_path = r'F:\LiTS_dataset\data'
label_path = r'F:\LiTS_dataset\label'
dataname_list = os.listdir(data_path)
dataname_list.sort()
ori_data = sitk.ReadImage(os.path.join(data_path,dataname_list[3])) # 讀取其中一個volume數(shù)據(jù)
data1 = sitk.GetArrayFromImage(ori_data) # 提取數(shù)據(jù)中心的array
print(dataname_list[3],data1.shape,data1[100,255,255]) #打印數(shù)據(jù)name、shape和某一個元素的值
plt.imshow(data1[100,:,:]) # 對第100張slice可視化
plt.show()
輸出結(jié)果:
['volume-0.nii', 'volume-1.nii', 'volume-10.nii', 'volume-11.nii',...
volume-11.nii (466, 512, 512) 232.0
表明該數(shù)據(jù)shape為(466,512,512),注意對應(yīng)的順序是z,x,y。z其實是slice的索引。x和y是某一個slice的寬和高。
z索引為100的plot結(jié)果:
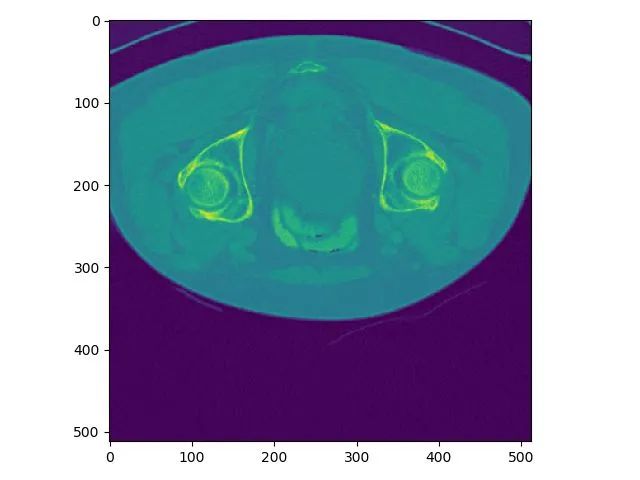
同一個slice在ITK-SNAP可視化結(jié)果(注意這里(x,y,z=(256,256,101)),因為itk-snap默認從1開始索引):
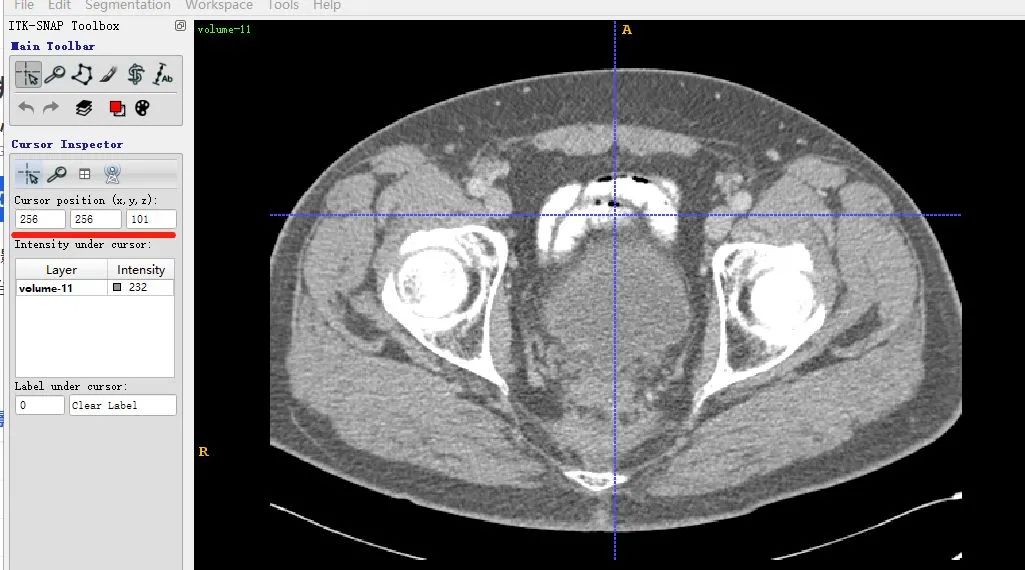
可以發(fā)現(xiàn),上下兩張x軸一樣但y軸方向上下翻轉(zhuǎn)了,這是由于matplotlib顯示方式不同,但是不會出現(xiàn)讀取數(shù)據(jù)對不齊的問題。
對于dicom和mhd的處理方式,可以參考這篇博文:
譚慶波:常見醫(yī)療掃描圖像處理步驟:
https://zhuanlan.zhihu.com/p/52054982
2.醫(yī)學(xué)圖像預(yù)處理
這部分內(nèi)容比較雜亂。因為不同的任務(wù)、不同的數(shù)據(jù)集,通常數(shù)據(jù)預(yù)處理的方法有很大不同。但基本思路是要讓處理后的數(shù)據(jù)更有利于網(wǎng)絡(luò)訓(xùn)練。那么二維圖像預(yù)處理的一些方法都是可以借鑒的,如對比度增強、去噪、裁剪等等。此外還有醫(yī)學(xué)圖像本身的一些先驗知識也可以利用,比如CT圖像中不同仿射劑量(單位:HU) 會對應(yīng)人體不同的組織器官。
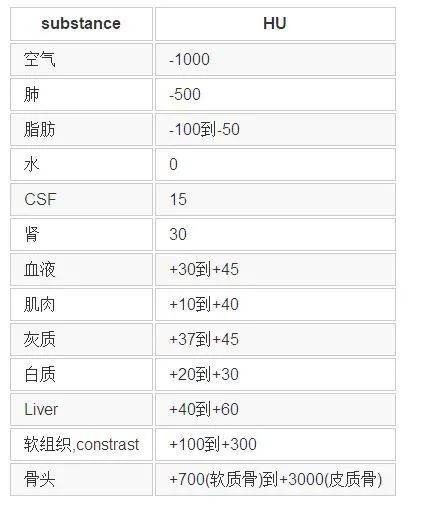
基于上表,可以對原始數(shù)據(jù)進行歸一化處理:
MIN_BOUND = -1000.0
MAX_BOUND = 400.0
def norm_img(image): # 歸一化像素值到(0,1)之間,且將溢出值取邊界值
image = (image - MIN_BOUND) / (MAX_BOUND - MIN_BOUND)
image[image > 1] = 1.
image[image < 0] = 0.
return image
也可以將其標(biāo)準(zhǔn)化/0均值化,將數(shù)據(jù)中心轉(zhuǎn)移到原點處:
image = image-meam
上述歸一化處理適用于絕大多數(shù)數(shù)據(jù)集,其他一些都是可有可無的針對于具體數(shù)據(jù)的操作,這些操作包括上面的MIN_BOUND 和MAX_BOUND 都最好參考優(yōu)秀論文的開源代碼的處理方式。
預(yù)處理后的數(shù)據(jù)集建議保存在本地,這樣可以減少訓(xùn)練時的部分資源消耗。此外,如隨機裁剪、線性變換等數(shù)據(jù)增強處理步驟,還是需要在訓(xùn)練時進行。
參考:
https://zhuanlan.zhihu.com/p/77791840
https://zhuanlan.zhihu.com/p/104381149
譚慶波:常見醫(yī)療掃描圖像處理步驟
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“transformer”獲取最新Transformer綜述論文下載~

#?CV技術(shù)社群邀請函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
