
詳細(xì)解讀TPH-YOLOv5 | 讓目標(biāo)檢測(cè)任務(wù)中的小目標(biāo)無處遁形
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)


本文在YOLOv5的基礎(chǔ)上加入了一些新的技術(shù),比如ViT、CBAM和一些Tricks(數(shù)據(jù)增廣、多尺度測(cè)試等),最終命名為TPH-YOLOv5的目標(biāo)檢測(cè)器,比較適合無人機(jī)小目標(biāo)的檢測(cè)和應(yīng)用。
工作單位: 北京航空航天大學(xué)
1簡(jiǎn)介
針對(duì)無人機(jī)捕獲場(chǎng)景的目標(biāo)檢測(cè)是最近比較流行的一項(xiàng)任務(wù)。由于無人機(jī)在不同高度飛行,目標(biāo)尺度變化較大,這樣給模型的優(yōu)化也帶來了很大的負(fù)擔(dān)。此外,在無人機(jī)進(jìn)行高速低空飛行時(shí),也會(huì)帶來密集目標(biāo)的運(yùn)動(dòng)模糊問題。

為了解決上述2個(gè)問題,本文提出了TPH-YOLOv5。TPH-YOLOv5在YOLOv5的基礎(chǔ)上增加了一個(gè)prediction heads 來檢測(cè)不同尺度的目標(biāo)。然后通過探索Self-Attention的預(yù)測(cè)潛力使用了Transformer Prediction Heads(TPH)代替原來的prediction heads。同時(shí)作者還集成了卷積塊Attention模型(CBAM)來尋找密集場(chǎng)景下的注意力區(qū)域。
為了進(jìn)一步改進(jìn)TPH-YOLOv5,作者還提供了大量有用的策略,如數(shù)據(jù)增強(qiáng)、多尺度測(cè)試、多模型集成和使用額外的分類器。
在VisDrone2021數(shù)據(jù)集上的大量實(shí)驗(yàn)表明,TPH-YOLOv5在無人機(jī)捕獲場(chǎng)景上具有良好的性能和可解釋性。在DET-test-challenge數(shù)據(jù)集上,TPH-YOLOv5的AP結(jié)果為39.18%,比之前的SOTA方法(DPNetV3)提高了1.81%。在VisDrone Challenge 2021中,TPH-YOLOv5與YOLOv5相比提高了約7%。
本文的貢獻(xiàn)如下:
增加了一個(gè)預(yù)測(cè)頭來處理目標(biāo)的大尺度方差; 將Transformer Prediction Heads (TPH)集成到Y(jié)OLOv5中,可以在高密度場(chǎng)景中準(zhǔn)確定位目標(biāo); 將CBAM集成到Y(jié)OLOv5中,幫助網(wǎng)絡(luò)在區(qū)域覆蓋范圍大的圖像中找到感興趣的區(qū)域; 提供有用的Tricks,并過濾一些無用的Trick,用于無人機(jī)捕獲場(chǎng)景的目標(biāo)檢測(cè)任務(wù); 使用self-trained classifier來提高對(duì)一些容易混淆的類別的分類能力。
2前人工作總結(jié)
2.1 Data Augmentation
數(shù)據(jù)增強(qiáng)的意義主要是擴(kuò)展數(shù)據(jù)集,使模型對(duì)不同環(huán)境下獲得的圖像具有較高的魯棒性。
Photometric和geometric被研究人員廣泛使用。對(duì)于Photometric主要是對(duì)圖像的色相、飽和度和值進(jìn)行了調(diào)整。在處理geometric時(shí)主要是添加隨機(jī)縮放、裁剪、平移、剪切和旋轉(zhuǎn)。
除了上述的全局像素增強(qiáng)方法外,還有一些比較獨(dú)特的數(shù)據(jù)增強(qiáng)方法。一些研究者提出了將多幅圖像結(jié)合在一起進(jìn)行數(shù)據(jù)增強(qiáng)的方法,如MixUp、CutMix和Mosaic。
MixUp從訓(xùn)練圖像中隨機(jī)選取2個(gè)樣本進(jìn)行隨機(jī)加權(quán)求和,樣本的標(biāo)簽也對(duì)應(yīng)于加權(quán)求和。不同于通常使用零像素mask遮擋圖像的遮擋工作,CutMix使用另一個(gè)圖像的區(qū)域覆蓋被遮擋的區(qū)域。Mosaic是CutMix的改進(jìn)版。拼接4幅圖像,極大地豐富了被檢測(cè)物體的背景。此外,batch normalization計(jì)算每層上4張不同圖像的激活統(tǒng)計(jì)量。
在TPH-YOLOv5的工作中主要是結(jié)合了MixUp、Mosaic以及傳統(tǒng)方法進(jìn)行的數(shù)據(jù)增強(qiáng)。
2.2 Multi-Model Ensemble Method
我們都知道深度學(xué)習(xí)模型是一種非線性方法。它們提供了更大的靈活性,并可以根據(jù)訓(xùn)練數(shù)據(jù)量的比例進(jìn)行擴(kuò)展。這種靈活性的一個(gè)缺點(diǎn)是,它們通過隨機(jī)訓(xùn)練算法進(jìn)行學(xué)習(xí),這意味著它們對(duì)訓(xùn)練數(shù)據(jù)的細(xì)節(jié)非常敏感,每次訓(xùn)練時(shí)可能會(huì)得到一組不同的權(quán)重,從而導(dǎo)致不同的預(yù)測(cè)。這給模型帶來了一個(gè)高方差。
減少模型方差的一個(gè)成功方法是訓(xùn)練多個(gè)模型而不是單一模型,并結(jié)合這些模型的預(yù)測(cè)。
針對(duì)不同的目標(biāo)檢測(cè)模型,有3種不同的ensemble boxes方法:非最大抑制(NMS)、Soft-NMS、Weighted Boxes Fusion(WBF)。
在NMS方法中,如果boxes的overlap, Intersection Over Union(IoU)大于某個(gè)閾值,則認(rèn)為它們屬于同一個(gè)對(duì)象。對(duì)于每個(gè)目標(biāo)NMS只留下一個(gè)置信度最高的box刪除其他box。因此,box過濾過程依賴于這個(gè)單一IoU閾值的選擇,這對(duì)模型性能有很大的影響。
Soft-NMS是對(duì)NMS進(jìn)行輕微的修改,使得Soft-NMS在標(biāo)準(zhǔn)基準(zhǔn)數(shù)據(jù)集(如PASCAL VOC和MS COCO)上比傳統(tǒng)NMS有了明顯的改進(jìn)。它根據(jù)IoU值對(duì)相鄰邊界box的置信度設(shè)置衰減函數(shù),而不是完全將其置信度評(píng)分設(shè)為0并將其刪除。
WBF的工作原理與NMS不同。NMS和Soft-NMS都排除了一些框,而WBF將所有框合并形成最終結(jié)果。因此,它可以解決模型中所有不準(zhǔn)確的預(yù)測(cè)。本文使用WBF對(duì)最終模型進(jìn)行集成,其性能明顯優(yōu)于NMS。
2.3 Object Detection
基于CNN的物體檢測(cè)器可分為多種類型:
One-Stage: YOLOX、FCOS、DETR、Scaled-YOLOv4、EfficientDet。 Two-Stage: VFNet、 CenterNet2。 Anchor-Based: ScaledYOLOv4、 YOLOv5。 Anchor-Free: CenterNet、 YOLOX、RepPoints。
一些檢測(cè)器是專門為無人機(jī)捕獲的圖像設(shè)計(jì)的,如RRNet、PENet、CenterNet等。但從組件的角度來看,它們通常由2部分組成,一是基于CNN的主干,用于圖像特征提取,另一部分是檢測(cè)頭,用于預(yù)測(cè)目標(biāo)的類和Box。
此外,近年來發(fā)展起來的目標(biāo)檢測(cè)器往往在backbone和head之間插入一些層,人們通常稱這部分為檢測(cè)器的Neck。接下來分別對(duì)這3種結(jié)構(gòu)進(jìn)行詳細(xì)介紹:
Backbone
常用的Backbone包括VGG、ResNet、DenseNet、MobileNet、EfficientNet、CSPDarknet53、Swin-Transformer等,均不是自己設(shè)計(jì)的網(wǎng)絡(luò)。因?yàn)檫@些網(wǎng)絡(luò)已經(jīng)證明它們?cè)诜诸惡推渌麊栴}上有很強(qiáng)的特征提取能力。但研究人員也將微調(diào)Backbone,使其更適合特定的垂直任務(wù)。
Neck
Neck的設(shè)計(jì)是為了更好地利用Backbone提取的特征。對(duì)Backbone提取的特征圖進(jìn)行不同階段的再處理和合理使用。通常,一個(gè)Neck由幾個(gè)自底向上的路徑和幾個(gè)自頂向下的路徑組成。Neck是目標(biāo)檢測(cè)框架中的關(guān)鍵環(huán)節(jié)。最早的Neck是使用上下取樣塊。該方法的特點(diǎn)是沒有特征層聚合操作,如SSD,直接跟隨頭部后的多層次特征圖。
常用的Neck聚合塊有:FPN、PANet、NAS-FPN、BiFPN、ASFF、SAM。這些方法的共性是反復(fù)使用各種上下采樣、拼接、點(diǎn)和或點(diǎn)積來設(shè)計(jì)聚合策略。Neck也有一些額外的塊,如SPP, ASPP, RFB, CBAM。
Head
作為一個(gè)分類網(wǎng)絡(luò),Backbone無法完成定位任務(wù),Head負(fù)責(zé)通過Backbone提取的特征圖檢測(cè)目標(biāo)的位置和類別。
Head一般分為2種:One-Stage檢測(cè)器和Two-Stage檢測(cè)器。
兩級(jí)檢測(cè)器一直是目標(biāo)檢測(cè)領(lǐng)域的主導(dǎo)方法,其中最具代表性的是RCNN系列。與Two-Stage檢測(cè)器相比One-Stage檢測(cè)器同時(shí)預(yù)測(cè)box和目標(biāo)的類別。One-Stage檢測(cè)器的速度優(yōu)勢(shì)明顯,但精度較低。對(duì)于One-Stage檢測(cè)器,最具代表性的型號(hào)是YOLO系列、SSD和RetaNet。
3TPH-YOLOv5
3.1 Overview of YOLOv5
YOLOv5有4種不同的配置,包括YOLOv5s,YOLOv5m, YOLOv5l和YOLOv5x。一般情況下,YOLOv5分別使用CSPDarknet53+SPP為Backbone,PANet為Neck, YOLO檢測(cè)Head。為了進(jìn)一步優(yōu)化整個(gè)架構(gòu)。由于它是最顯著和最方便的One-Stage檢測(cè)器,作者選擇它作為Baseline。
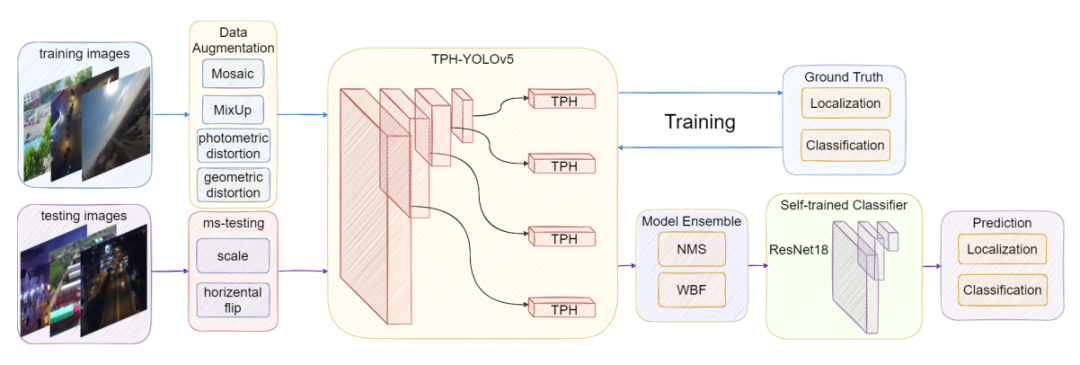
當(dāng)使用VisDrone2021數(shù)據(jù)集訓(xùn)練模型時(shí),使用數(shù)據(jù)增強(qiáng)策略(Mosaic和MixUp)發(fā)現(xiàn)YOLOv5x的結(jié)果遠(yuǎn)遠(yuǎn)好于YOLOv5s、YOLOv5m和YOLOv5l, AP值的差距大于1.5%。雖然YOLOv5x模型的訓(xùn)練計(jì)算成本比其他3種模型都要高,但仍然選擇使用YOLOv5x來追求最好的檢測(cè)性能。此外,根據(jù)無人機(jī)捕獲圖像的特點(diǎn),對(duì)常用的photometric和geometric參數(shù)進(jìn)行了調(diào)整。
3.2 TPH-YOLOv5
TPH-YOLOv5的框架如圖3所示。修改了原來的YOLOv5,使其專一于VisDrone2021數(shù)據(jù)集:
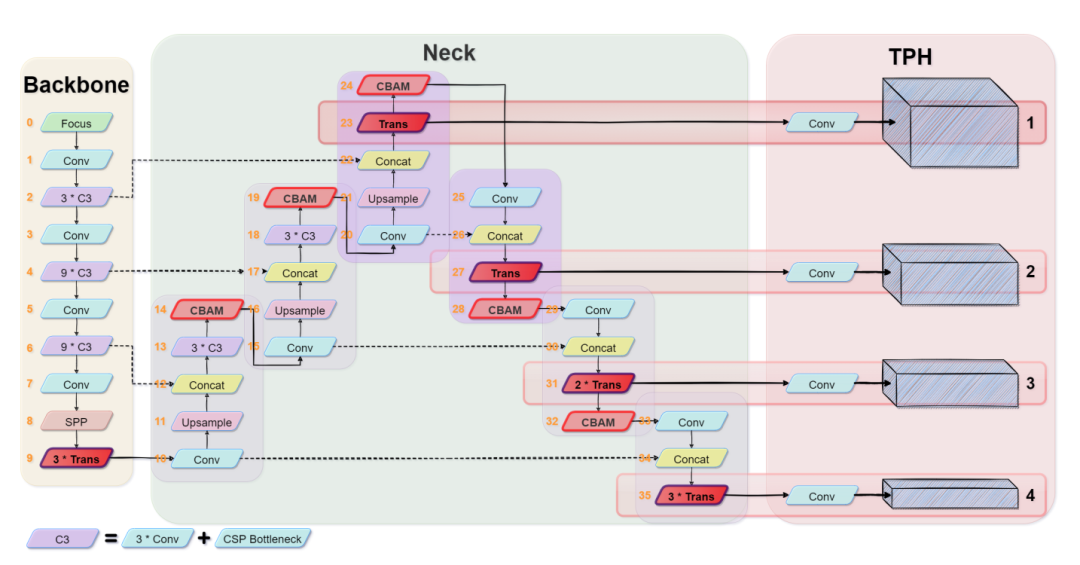
微小物體的預(yù)測(cè)頭
作者統(tǒng)計(jì)了VisDrone2021數(shù)據(jù)集,發(fā)現(xiàn)它包含了很多非常小的目標(biāo),所以增加了一個(gè)用于微小物體檢測(cè)的預(yù)測(cè)頭。結(jié)合其他3個(gè)預(yù)測(cè)頭,4頭結(jié)構(gòu)可以緩解劇烈的目標(biāo)尺度變化帶來的負(fù)面影響。如圖3所示,添加的預(yù)測(cè)頭(Head 1)是由low-level、高分辨率的feature map生成的,對(duì)微小物體更加敏感。增加檢測(cè)頭后,雖然增加了計(jì)算和存儲(chǔ)成本,但對(duì)微小物體的檢測(cè)性能得到了很大的提高。
Transformer encoder block
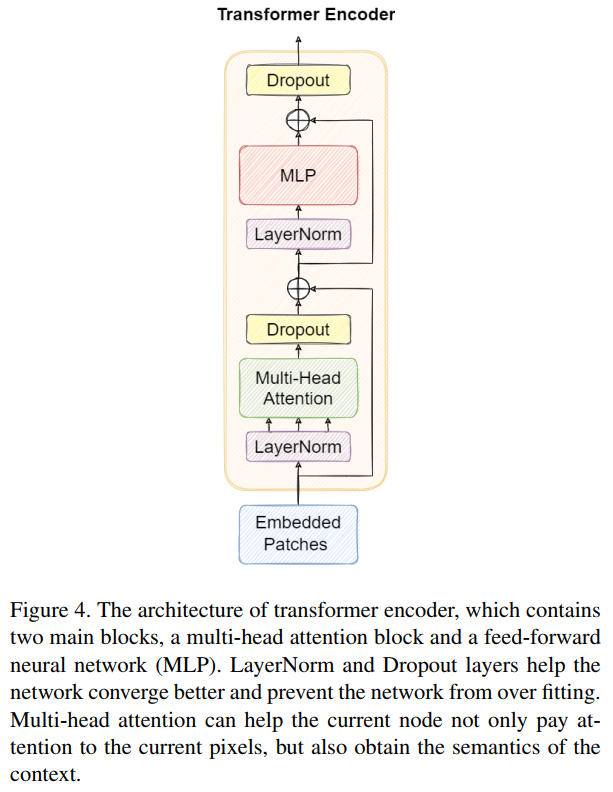
用Transformer encoder塊替換了YOLOv5原版中的一些卷積塊和CSP bottleneck blocks。其結(jié)構(gòu)如圖4所示。與CSPDarknet53中原有的bottleneck blocks相比,作者認(rèn)為Transformer encoder block可以捕獲全局信息和豐富的上下文信息。
每個(gè)Transformer encoder block包含2個(gè)子層。第1子層為multi-head attention layer,第2子層(MLP)為全連接層。每個(gè)子層之間使用殘差連接。Transformer encoder block增加了捕獲不同局部信息的能力。它還可以利用自注意力機(jī)制來挖掘特征表征潛能。在VisDrone2021數(shù)據(jù)集中,Transformer encoder block在高密度閉塞對(duì)象上有更好的性能。
基于YOLOv5,作者只在頭部部分應(yīng)用Transformer encoder block形成transformer Prediction head(TPH)和backbone端。因?yàn)榫W(wǎng)絡(luò)末端的特征圖分辨率較低。將TPH應(yīng)用于低分辨率特征圖可以降低計(jì)算和存儲(chǔ)成本。此外,當(dāng)放大輸入圖像的分辨率時(shí)可選擇去除早期層的一些TPH塊,以使訓(xùn)練過程可用。
Convolutional block attention module (CBAM)
CBAM是一個(gè)簡(jiǎn)單但有效的注意力模塊。它是一個(gè)輕量級(jí)模塊,可以即插即用到CNN架構(gòu)中,并且可以以端到端方式進(jìn)行訓(xùn)練。給定一個(gè)特征映射,CBAM將沿著通道和空間兩個(gè)獨(dú)立維度依次推斷出注意力映射,然后將注意力映射與輸入特征映射相乘,以執(zhí)行自適應(yīng)特征細(xì)化。
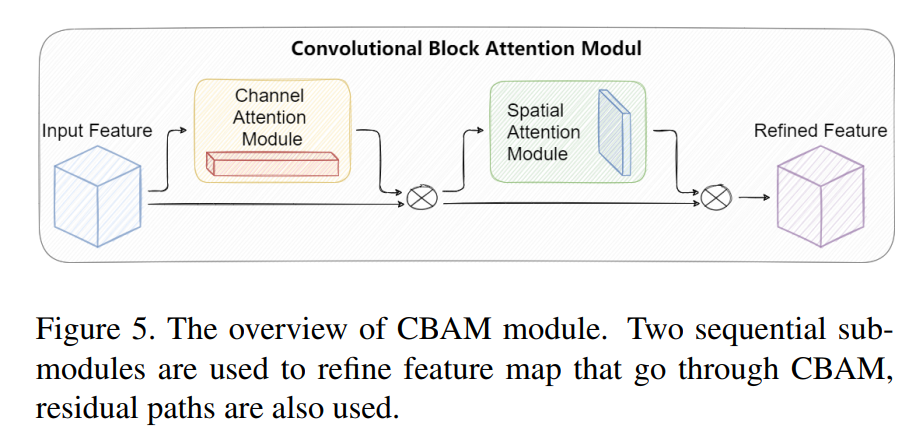
CBAM模塊的結(jié)構(gòu)如圖5所示。通過本文的實(shí)驗(yàn),在不同的分類和檢測(cè)數(shù)據(jù)集上將CBAM集成到不同的模型中,模型的性能得到了很大的提高,證明了該模塊的有效性。
在無人機(jī)捕獲的圖像中,大覆蓋區(qū)域總是包含令人困惑的地理元素。使用CBAM可以提取注意區(qū)域,以幫助TPH-YOLOv5抵制令人困惑的信息,并關(guān)注有用的目標(biāo)對(duì)象。
Self-trained classifier
用TPH-YOLOv5對(duì)VisDrone2021數(shù)據(jù)集進(jìn)行訓(xùn)練后,對(duì)test-dev數(shù)據(jù)集進(jìn)行測(cè)試,然后通過可視化失敗案例分析結(jié)果,得出TPH-YOLOv5定位能力較好,分類能力較差的結(jié)論。作者進(jìn)一步探索如圖6所示的混淆矩陣,觀察到一些硬類別,如三輪車和遮陽三輪車的精度非常低。
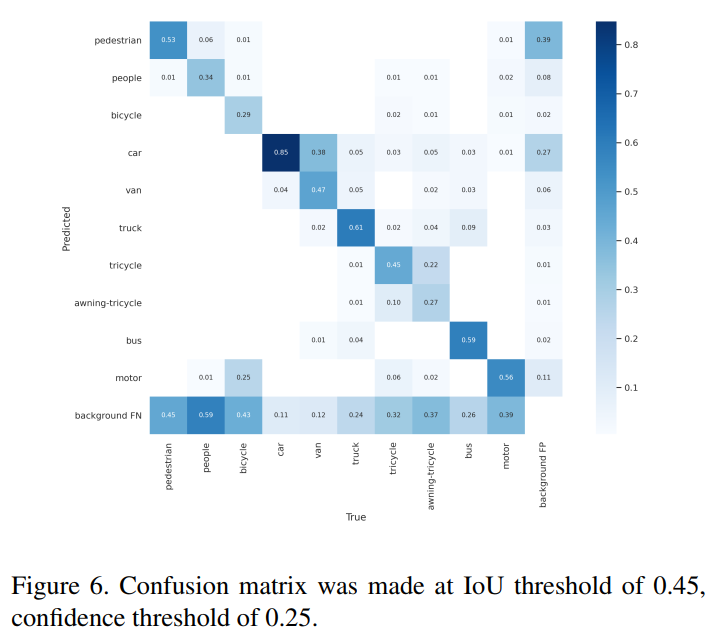
因此,作者提出了一個(gè)Self-trained classifier。首先,通過裁剪ground-truth邊界框并將每個(gè)圖像patch的大小調(diào)整為6464來構(gòu)建訓(xùn)練集。然后選擇ResNet18作為分類器網(wǎng)絡(luò)。實(shí)驗(yàn)結(jié)果表明,在這個(gè)Self-trained classifier的幫助下,所提方法對(duì)AP值提高了約0.8%~1.0%。
4實(shí)驗(yàn)與結(jié)論
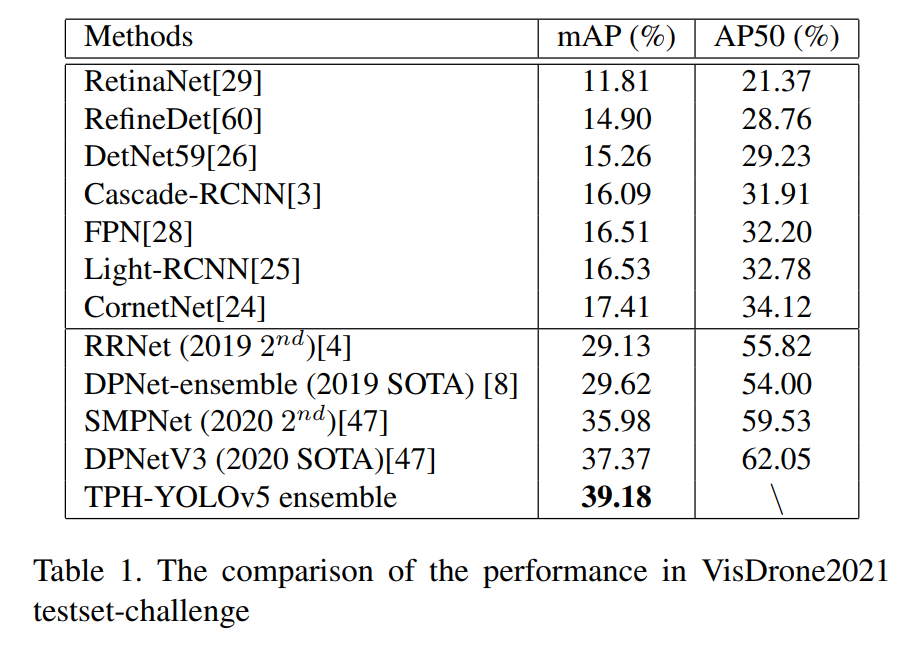
最終在test-set-challenge上取得了39.18的好成績(jī),遠(yuǎn)遠(yuǎn)高于VisDrone2020的最高成績(jī)37.37。
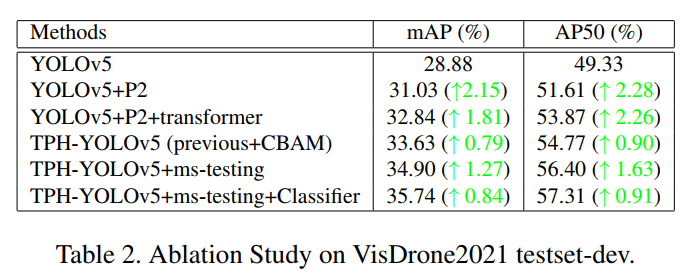
添加一個(gè)微小物體的檢測(cè)頭,使得原來的YOLOv5x的層數(shù)從607變成719,GFLOPs從219.0到259.0。這當(dāng)然增加了計(jì)算量,但mAP的改進(jìn)也非常高。從從圖9中可以看出,TPH-YOLOv5在檢測(cè)小目標(biāo)時(shí)表現(xiàn)良好,所以增加計(jì)算是值得的。

采用transformer encoder blocks后,模型總層數(shù)由719層減少到705層,GFLOPs由259.0層減少到237.3層。采用transformer encoder blocks不僅可以增加mAP,還可以減小網(wǎng)絡(luò)的尺寸。同時(shí),它也在稠密物體和大物體的檢測(cè)中發(fā)揮作用。
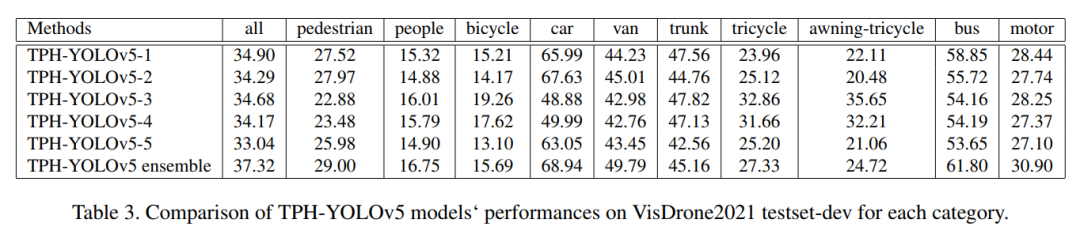
列出了5個(gè)不同模型在每個(gè)類別中的最終結(jié)果mAP,并與表3中的融合模型進(jìn)行了比較。在訓(xùn)練階段使用不同的輸入圖像大小,并改變每個(gè)類別的權(quán)重,使每個(gè)模型唯一。使最終的集成模型得到一個(gè)相對(duì)平衡的結(jié)果:
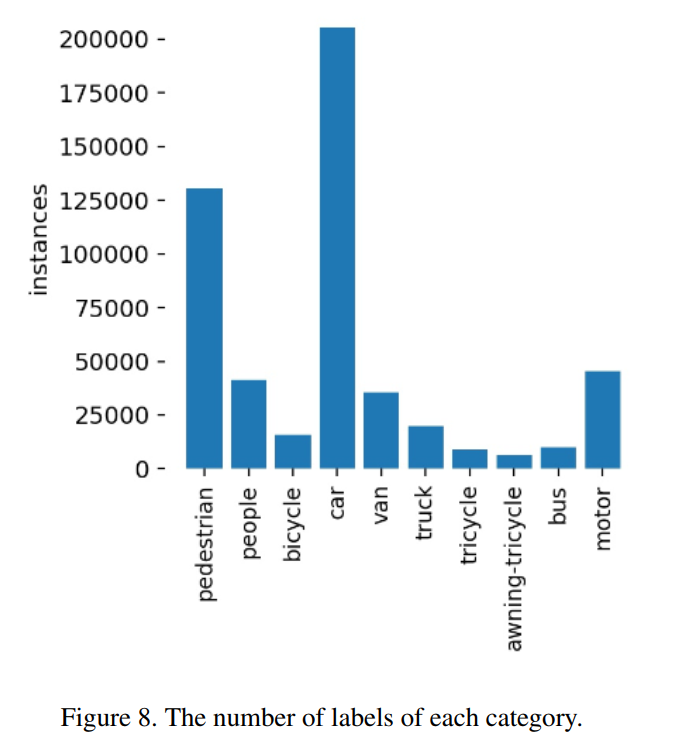
TPH-YOLOv5-1使用輸入圖像大小為1920,所有類別的權(quán)重相等。 TPH-YOLOv5-2使用輸入圖像大小1536,所有類別權(quán)重相等。 TPH-YOLOv5-3使用輸入圖像大小1920,每個(gè)類別的權(quán)重與標(biāo)簽數(shù)量相關(guān),如圖8所示。某一類別的標(biāo)簽越多,其權(quán)重就越低。 TPH-YOLOv5-4使用輸入圖像大小1536,每個(gè)類別的權(quán)重與標(biāo)簽數(shù)量相關(guān)。 TPH-YOLOv5-5采用YOLOv5l的骨干,輸入圖像尺寸為1536。
5參考
[1].TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for
Object Detection on Drone-captured Scenarios
好消息!?
小白學(xué)視覺知識(shí)星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):Python視覺實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車道線檢測(cè)、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請(qǐng)按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~