
詳細解讀 | 如何讓你的DETR目標檢測模型快速收斂


本文作者提出了一種conditional cross-attention mechanism用于快速訓(xùn)練DETR,從decoder embedding中學(xué)習(xí)了一個conditional spatial query用于decoder multi-head cross-attention;實驗結(jié)果表明,對于Backbone R50和R101,條件DETR收斂速度快6.7倍;對于backboone DC5-R50和DC5-R101,條件DETR收斂速度快10倍。
1簡介
最近發(fā)展起來的DETR方法將transformer編解碼器體系結(jié)構(gòu)應(yīng)用于目標檢測并取得了很好的性能。在本文中,作者解決了訓(xùn)練收斂速度慢這一關(guān)鍵問題,并提出了一種conditional cross-attention mechanism用于快速訓(xùn)練DETR。作者動機是cross-attention在DETR中高度依賴content embeddings定位的4端和預(yù)測框,這增加了對高質(zhì)量content embedding的需求進而增加了訓(xùn)練的難度。
本文方法被命名為條件DETR,從decoder embedding中學(xué)習(xí)了一個conditional spatial query用于decoder multi-head cross-attention。其好處是,通過conditional spatial query每個cross-attention head能夠關(guān)注包含不同區(qū)域的band(例如,一個目標端點或目標box內(nèi)的一個區(qū)域)。這縮小了目標分類和box回歸的不同區(qū)域定位的空間范圍,從而減輕了對content embedding的依賴,減輕了訓(xùn)練。
實驗結(jié)果表明,對于Backbone R50和R101,條件DETR收斂速度快6.7倍;對于backboone DC5-R50和DC5-R101,條件DETR收斂速度快10倍。
2背景
DETR方法將transformer應(yīng)用于目標檢測取得了良好的性能。它有效地消除了許多手工制作組件的需要,包括NMS和Anchor生成。
DETR方法在訓(xùn)練上收斂緩慢,需要500個epoch才能取得良好的效果。Deformable DETR通過使用高分辨率和多尺度編碼器將global dense attention(self-attention和cross-attention)替換為deformable attention來解決這個問題。相反,本文仍然使用global dense attention并提出了一個改進的 decoder cross-attention mechanism以加速訓(xùn)練收斂的過程。
本文方法的動機是高度依賴content embeddings和spatial embeddings in cross-attention。實驗結(jié)果表明,如果從第2解碼器層去除key和query中的位置嵌入,只使用key和query中的content embeddings,檢測AP略有下降(1%)。

圖1(第2行)顯示了50個epoch訓(xùn)練的DETR cross-attention的spatial attention weight maps。可以看到,4個映射中有2個沒有正確地突出對應(yīng)端點的波段,因此在縮小內(nèi)容查詢的空間范圍以精確定位端點方面很弱。其原因是:
spatial query:即目標query,只給出general attention weight map,而沒有利用具體的圖像信息; 由于訓(xùn)練時間短content embeddings不夠強,不能很好地匹配spatial key,因為它們也用于匹配content key。這增加了對高質(zhì)量content embeddings的依賴性,從而增加了訓(xùn)練難度。
本文提出了一種有條件的DETR方法,該方法從之前對應(yīng)的解碼器輸出嵌入中學(xué)習(xí)每個query的條件spatial embedding,形成decoder multi-head cross-attention的條件spatial query。通過將用于回歸目標框的信息映射到嵌入空間來預(yù)測條件spatial query。
3條件DETR
3.1 方法概覽
該方法采用端到端目標檢測器(detection transformer, DETR),無需生成NMS或Anchor即可一次性預(yù)測所有目標。該體系結(jié)構(gòu)由CNN Backbone、transformer encoder、transformer decoder、目標分類器和邊界框位置預(yù)測器組成。transformer encoder的目的是改進CNN Backbone的content embeddings輸出。它是由多個編碼器層組成的堆棧,其中每一層主要由self-attention層和feed-forward層組成。

transformer decoder是一堆decoder layer。每個decoder layer如圖3所示,由3個主要層組成:
self-attention layer:用于去除重復(fù)預(yù)測,執(zhí)行前一解碼器層輸出的嵌入之間的交互,用于類和box的預(yù)測; cross-attention layer:該層聚合編碼器輸出的embedding以細化解碼器embedding改進類和box預(yù)測; feed-forward layer
Box回歸
從每個decoder embedding中預(yù)測一個候選框,如下所示:

這里,是decoder embedding。是一個4維矢量,由框的中心、框的寬度和框的高度組成。Sigmoid()用于將預(yù)測b歸一化到范圍[0,1]。FFN()的目的是預(yù)測非規(guī)范化框。在原始DETR中為(0,0),s為參考點的非歸一化二維坐標。在本方法中,作者考慮2個選擇:將參考點s作為每個候選框預(yù)測的參數(shù)學(xué)習(xí),或者從相應(yīng)的目標query中生成它。
類別預(yù)測
每個候選框的分類score也通過FNN預(yù)測:
Main work
cross-attention mechanism的目的是定位不同的區(qū)域(用于box檢測的4個端點和box內(nèi)用于目標分類的區(qū)域)并聚合相應(yīng)的嵌入。本文提出了一種條件cross-attention mechanism,通過引入conditional spatial query來提高定位能力和加速訓(xùn)練的收斂過程。
3.2 DETR Decoder Cross-Attention
DETR解碼器cross-attention mechanism有3個輸入:query、key和value。每個key都是通過添加一個content key (編碼器的content embedding輸出)和一個spatial key (對應(yīng)的標準化2D坐標的positional embedding)形成的。該value是由編碼器輸出的content embedding(與content key相同)形成的。
在原始的DETR方法中,每個query是通過添加content query (decoder self-attention embedding)和spatial query (即object query )形成的。在實現(xiàn)中,有N=300個object queries,相應(yīng)地有N個query,每個query在一個解碼器層輸出一個候選檢測結(jié)果。
attention weight是基于query與key的點積:
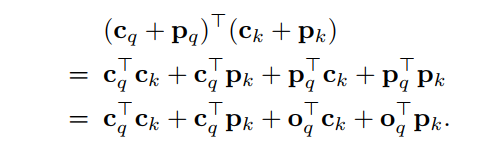
3.3 Conditional Cross-Attention
提出的Conditional Cross-Attention將解碼器self-attention輸出的content query 和spatial query 串聯(lián)起來形成query。因此,同理,key由content key 和spatial key 拼接而成。
cross-attention weight由content attention weight和spatial attention weight兩部分組成。這兩個權(quán)重來自兩個點積,content和spatial點積:
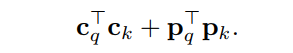
與原來的DETR Cross-Attention不同,本文所提的機制分離了content query和spatial query的角色,使spatial query和content query分別關(guān)注spatial和content的attention weight。
另外一個重要的任務(wù)是從前一個解碼器層的embedding 計算spatial query 。首先識別出不同區(qū)域的空間信息是由解碼器 embedding 和參考點這兩個因素共同決定的。然后展示了如何將它們映射到embedding space形成query ,使spatial位于key的2D坐標映射到的同一空間。
解碼器embedding包含不同區(qū)域相對于參考點的位移。式1中的box預(yù)測過程包括2個步驟:
對非歸一化空間中的參考點進行預(yù)測;
將預(yù)測框歸一化到范圍[0,1];
步驟(1)表示decoder embedding f包含了構(gòu)成方框的4個端點相對于非歸一化空間中的參考點s的位移。這意味著,無論是embedding f還是參考點s,都需要確定不同區(qū)域、4個極值以及預(yù)測分類評分的區(qū)域的空間信息。
Conditional spatial query prediction
通過embedding f和參考點s預(yù)測條件空間查詢,
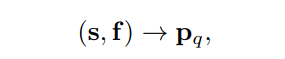
以便與key的標準化2D坐標映射到的位置空間對齊。這個過程如圖3的灰色框區(qū)所示。
這里將參考點歸一化,然后將其映射到256維正弦位置嵌入,方法與key的位置嵌入相同:
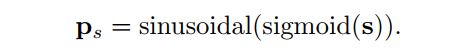
然后通過可學(xué)習(xí)線性投影+ReLU+可學(xué)習(xí)線性投影組成的FFN將解碼器embedding f中包含的位移信息映射到同一空間中的線性投影:
conditional spatial query通過轉(zhuǎn)換embedding空間中的參考點來計算:
作者選擇簡單和計算效率高的對角矩陣。256個對角線元素被表示為一個向量。conditional spatial query通過逐元素乘法計算:
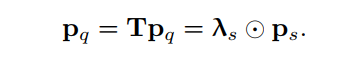
Multi-head cross-attention
與DETR一樣作者采用標準的Multi-head cross-attention機制。目標檢測通常需要隱式或顯式定位目標的4個端點以實現(xiàn)精確的box回歸,并定位目標區(qū)域以實現(xiàn)精確的目標分類。multi-head mechanism有利于解決定位任務(wù)的糾纏問題。
作者通過將query、key和value M=8次投影到低維的線性投影來執(zhí)行multi-head parallel attentions。spatial和content query(key)分別以不同的線性投影投影到每個head。value投影與原始的DETR相同,僅用于content。
3.4 可視化分析
圖4可視化了每個attention weight maps:
spatial attention weight maps content attention weight maps combined attention weight maps
對spatial dot-products 、 content dot-products 和combined dot-products 進行softmax normalized。圖中顯示了8個map中的5個其他3個是重復(fù)的,對應(yīng)于底部和頂部的端點,以及目標框內(nèi)的一個小區(qū)域。

可以看到,每個head的spatial attention weight maps能夠定位一個不同的區(qū)域(包含一個極點的區(qū)域或物體box內(nèi)的區(qū)域)。有趣的是,每個spatial attention weight maps對應(yīng)的一個極點突出了一個空間帶,該空間帶與目標框的相應(yīng)邊緣重疊。目標框內(nèi)區(qū)域的另一個spatial attention weight maps僅僅突出顯示了一個小區(qū)域,該區(qū)域的表示可能已經(jīng)編碼了足夠的目標分類信息。
content attention weight maps還突出了分散的區(qū)域。空間和內(nèi)容映射的組合過濾掉了其他高亮部分,并保留了極端高亮部分以實現(xiàn)精確的box回歸。
Comparison to DETR
圖1顯示了條件式DETR(第1行)和經(jīng)過50個epoch訓(xùn)練的原始DETR(第2行)的spatial attention weight maps。本文方法的映射是通過spatial key和query之間的dot的softmax normalized來計算的:
可以看出spatial attention weight maps準確定位了不同的區(qū)域。相比之下,原始的DETR中包含50個epoch的map不能準確定位2個極點,而500個訓(xùn)練epoch(第3行)使得content query更強,從而實現(xiàn)了精確定位。這意味著學(xué)習(xí)content query 作為2個角色(同時匹配content key和spatial key)是非常困難的,因此需要更多的訓(xùn)練epoch。
分析
圖4所示的spatial attention weight maps暗示用于形成spatial query的conditional spatial query至少有2種效果:
將突出顯示的位置轉(zhuǎn)換為4個端點和目標框內(nèi)的位置:有趣的是,突出顯示的位置在目標框內(nèi)的空間分布相似; 縮放頂端亮點的空間擴展:大目標的空間擴展大,小目標的空間擴展小。
這2種效果是在spatial embedding space中通過T/ps變換實現(xiàn)的(通過cross-attention中包含的獨立于圖像的線性投影進一步分離,并分布到每個head)。這說明變換T不僅包含前面討論的位移,還包含目標尺度。
4實驗
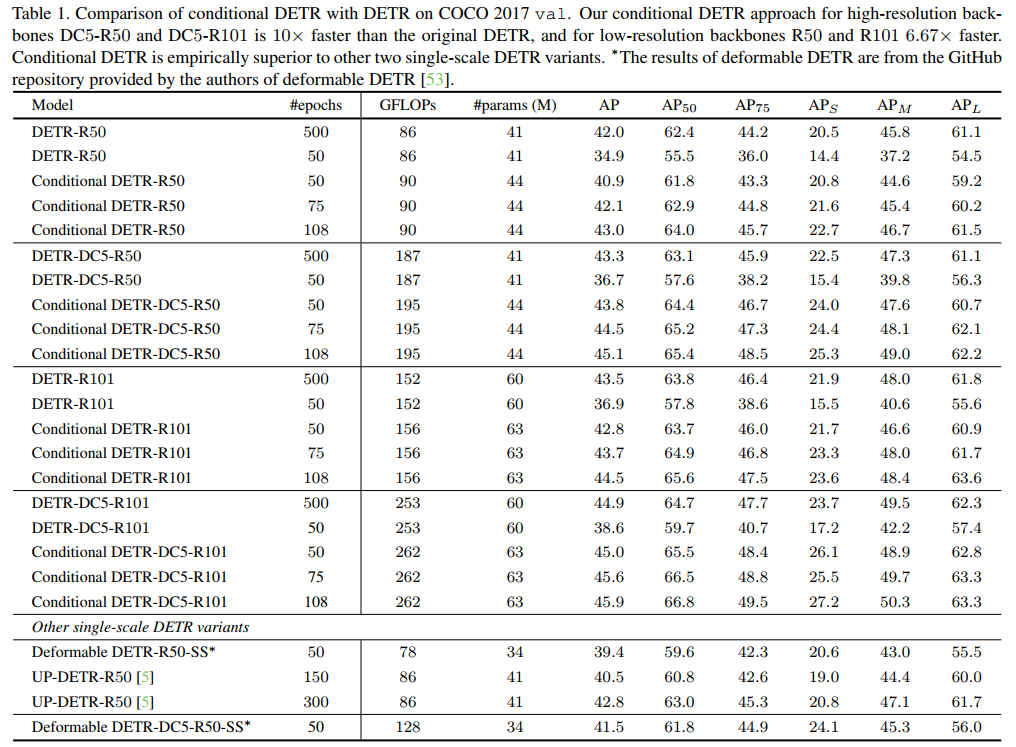
表1給出了DETR和條件DETR的結(jié)果。具有50個訓(xùn)練期的DETR比500個訓(xùn)練期的表現(xiàn)差得多。
對于R50和R101具有50個訓(xùn)練周期的條件DETR作為backbone,其表現(xiàn)略低于具有500個訓(xùn)練周期的DETR。
對于DC5-R50和DC5-R101,帶有50個訓(xùn)練周期的條件DETR的性能與帶有500個訓(xùn)練周期的DETR相似。
4個backbone 75/108個訓(xùn)練周期的條件DETR優(yōu)于500個訓(xùn)練周期的DETR。
總之,高分辨率backbone DC5-R50和DC5-R101的有條件DETR比原始的DETR快10倍,低分辨率backbone R50和R101快6.67倍。換句話說,有條件的DETR對于更強大的backbone和更好的性能表現(xiàn)得更好。
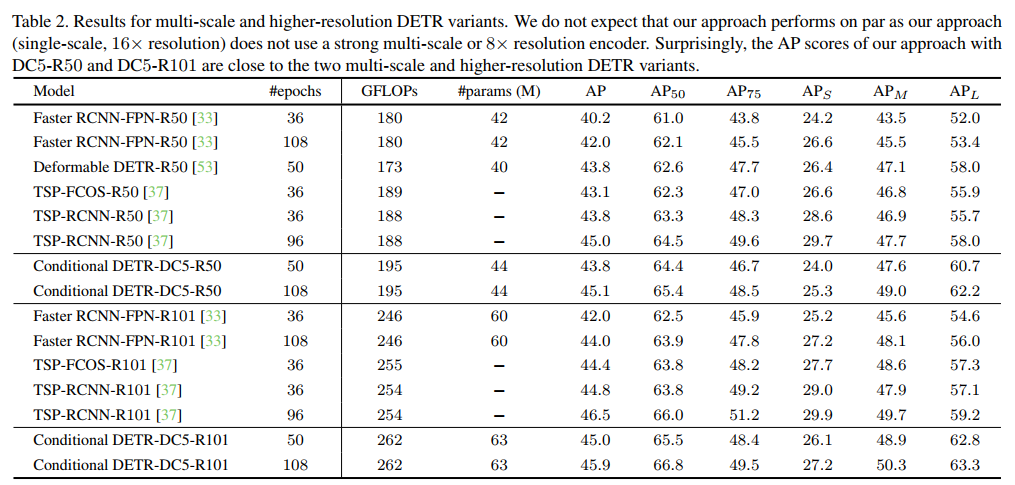
表2中顯示,在DC5-R50(16×)上的方法與可變形的方法表現(xiàn)相同DETR-R50(多尺度、8×)。考慮到單尺度可變形DETR-DC5-R50-SS的AP為41.5(低于43.8)(表1),可以看到,可變形的DETR受益于多尺度和高分辨率編碼器。
本文方法的性能也與TSP-FCOS TSP-RCNN。這2種方法包含一個在少量選定位置/區(qū)域上的transformer編碼器(在TSP-FCOS和TSP-RCNN區(qū)域提議中感興趣的特性),而不使用transformer解碼器是FCOS和Faster RCNN的擴展。
5參考
[1].Conditional DETR for Fast Training Convergence
6集智書童知識星球
各位小伙伴們,【集智書童】也上線啦!!!主要涉獵的內(nèi)容包括:
算法改進 優(yōu)秀論文推薦 算法復(fù)現(xiàn) AI算法部署(TensorRT、OpenCV、ONNX、OpenVINO等內(nèi)容) 部分內(nèi)容如下截圖:



下面是送出了40張新人優(yōu)惠券,掃描下方二維碼即可加入星球:
7推薦閱讀
Mobile-Former | MobileNet+Transformer輕量化模型(精度速度秒殺MobileNet)

牛津大學(xué)提出PSViT | Token池化+Attention Sharing讓Transformer模型不在冗余!!!

YOffleNet | YOLO V4 基于嵌入式設(shè)備的輕量化改進設(shè)計
長按掃描下方二維碼添加小助手。
可以一起討論遇到的問題
聲明:轉(zhuǎn)載請說明出處
掃描下方二維碼關(guān)注【集智書童】公眾號,獲取更多實踐項目源碼和論文解讀,非常期待你我的相遇,讓我們以夢為馬,砥礪前行!
