
特征工程|不容錯(cuò)過的 5 種特征選擇的方法!
特征選擇是從原始特征中選擇出一些最有效特征以降低數(shù)據(jù)集維度、提高法性能的方法。
我們知道模型的性能會隨著使用特征數(shù)量的增加而增加。但是,當(dāng)超過峰值時(shí),模型性能將會下降。這就是為什么我們只需要選擇能夠有效預(yù)測的特征的原因。
特征選擇類似于降維技術(shù),其目的是減少特征的數(shù)量,但是從根本上說,它們是不同的。區(qū)別在于要素選擇會選擇要保留或從數(shù)據(jù)集中刪除的要素,而降維會創(chuàng)建數(shù)據(jù)的投影,從而產(chǎn)生全新的輸入要素。
特征選擇有很多方法,在本文中我將介紹 Scikit-Learn 中 5 個(gè)方法,因?yàn)樗鼈兪亲詈唵蔚珔s非常有用的,讓我們開始吧。
1、方差閾值特征選擇
具有較高方差的特征表示該特征內(nèi)的值變化大,較低的方差意味著要素內(nèi)的值相似,而零方差意味著您具有相同值的要素。
方差選擇法,先要計(jì)算各個(gè)特征的方差,然后根據(jù)閾值,選擇方差大于閾值的特征,使用方法我們舉例說明:
import pandas as pd
import seaborn as sns
mpg = sns.load_dataset('mpg').select_dtypes('number')
mpg.head()
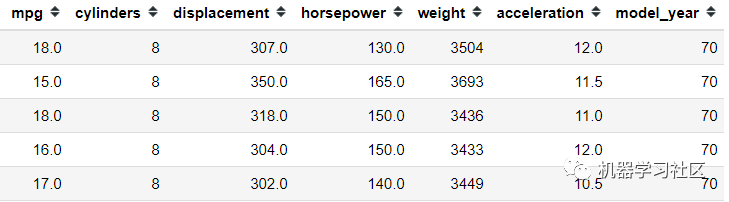 對于此示例,我僅出于簡化目的使用數(shù)字特征。在使用方差閾值特征選擇之前,我們需要對所有這些數(shù)字特征進(jìn)行轉(zhuǎn)換,因?yàn)榉讲钍軘?shù)字刻度的影響。
對于此示例,我僅出于簡化目的使用數(shù)字特征。在使用方差閾值特征選擇之前,我們需要對所有這些數(shù)字特征進(jìn)行轉(zhuǎn)換,因?yàn)榉讲钍軘?shù)字刻度的影響。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
mpg = pd.DataFrame(scaler.fit_transform(mpg), columns = mpg.columns)
mpg.head()
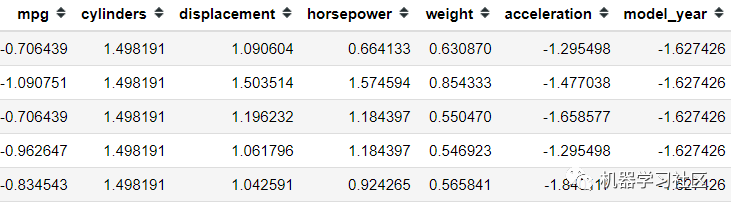
所有特征都在同一比例上,讓我們嘗試僅使用方差閾值方法選擇我們想要的特征。假設(shè)我的方差限制為一個(gè)方差。
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(1)
selector.fit(mpg)
mpg.columns[selector.get_support()]
方差閾值是一種無監(jiān)督學(xué)習(xí)的特征選擇方法。如果我們希望出于監(jiān)督學(xué)習(xí)的目的而選擇功能怎么辦?那就是我們接下來要討論的。
2、SelectKBest特征特征
單變量特征選擇是一種基于單變量統(tǒng)計(jì)檢驗(yàn)的方法,例如:chi2,Pearson等等。
SelectKBest 的前提是將未經(jīng)驗(yàn)證的統(tǒng)計(jì)測試與基于 X 和 y 之間的統(tǒng)計(jì)結(jié)果選擇 K 數(shù)的特征相結(jié)合。
mpg = sns.load_dataset('mpg')
mpg = mpg.select_dtypes('number').dropna()
#Divide the features into Independent and Dependent Variable
X = mpg.drop('mpg' , axis =1)
y = mpg['mpg']
由于單變量特征選擇方法旨在進(jìn)行監(jiān)督學(xué)習(xí),因此我們將特征分為獨(dú)立變量和因變量。接下來,我們將使用SelectKBest,假設(shè)我只想要最重要的兩個(gè)特征。
from sklearn.feature_selection import SelectKBest, mutual_info_regression
#Select top 2 features based on mutual info regression
selector = SelectKBest(mutual_info_regression, k =2)
selector.fit(X, y)
X.columns[selector.get_support()]
3、遞歸特征消除(RFE)
遞歸特征消除或RFE是一種特征選擇方法,利用機(jī)器學(xué)習(xí)模型通過在遞歸訓(xùn)練后消除最不重要的特征來選擇特征。
根據(jù)Scikit-Learn,RFE是一種通過遞歸考慮越來越少的特征集來選擇特征的方法。
首先對估計(jì)器進(jìn)行初始特征集訓(xùn)練,然后通過coef_attribute或feature_importances_attribute獲得每個(gè)特征的重要性。 然后從當(dāng)前特征中刪除最不重要的特征。在修剪后的數(shù)據(jù)集上遞歸地重復(fù)該過程,直到最終達(dá)到所需的要選擇的特征數(shù)量。
在此示例中,我想使用泰坦尼克號數(shù)據(jù)集進(jìn)行分類問題,在那里我想預(yù)測誰將生存下來。
#Load the dataset and only selecting the numerical features for example purposes
titanic = sns.load_dataset('titanic')[['survived', 'pclass', 'age', 'parch', 'sibsp', 'fare']].dropna()
X = titanic.drop('survived', axis = 1)
y = titanic['survived']
我想看看哪些特征最能幫助我預(yù)測誰可以幸免于泰坦尼克號事件。讓我們使用LogisticRegression模型獲得最佳特征。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# #Selecting the Best important features according to Logistic Regression
rfe_selector = RFE(estimator=LogisticRegression(),n_features_to_select = 2, step = 1)
rfe_selector.fit(X, y)
X.columns[rfe_selector.get_support()]
默認(rèn)情況下,為RFE選擇的特征數(shù)是全部特征的中位數(shù),步長是1.當(dāng)然,你可以根據(jù)自己的經(jīng)驗(yàn)進(jìn)行更改。
4、SelectFromModel 特征選擇
Scikit-Learn 的 SelectFromModel 用于選擇特征的機(jī)器學(xué)習(xí)模型估計(jì),它基于重要性屬性閾值。默認(rèn)情況下,閾值是平均值。
讓我們使用一個(gè)數(shù)據(jù)集示例來更好地理解這一概念。我將使用之前的數(shù)據(jù)。
from sklearn.feature_selection import SelectFromModel
sfm_selector = SelectFromModel(estimator=LogisticRegression())
sfm_selector.fit(X, y)
X.columns[sfm_selector.get_support()]
與RFE一樣,你可以使用任何機(jī)器學(xué)習(xí)模型來選擇功能,只要可以調(diào)用它來估計(jì)特征重要性即可。你可以使用隨機(jī)森林模或XGBoost進(jìn)行嘗試。
5、順序特征選擇(SFS)
順序特征選擇是一種貪婪算法,用于根據(jù)交叉驗(yàn)證得分和估計(jì)量來向前或向后查找最佳特征,它是 Scikit-Learn 版本0.24中的新增功能。方法如下:
SFS-Forward 通過從零個(gè)特征開始進(jìn)行功能選擇,并找到了一個(gè)針對單個(gè)特征訓(xùn)練機(jī)器學(xué)習(xí)模型時(shí)可以最大化交叉驗(yàn)證得分的特征。 一旦選擇了第一個(gè)功能,便會通過向所選功能添加新功能來重復(fù)該過程。當(dāng)我們發(fā)現(xiàn)達(dá)到所需數(shù)量的功能時(shí),該過程將停止。
讓我們舉一個(gè)例子說明。
from sklearn.feature_selection import SequentialFeatureSelector
sfs_selector = SequentialFeatureSelector(estimator=LogisticRegression(), n_features_to_select = 3, cv =10, direction ='backward')
sfs_selector.fit(X, y)
X.columns[sfs_selector.get_support()]
結(jié)論
特征選擇是機(jī)器學(xué)習(xí)模型中的一個(gè)重要方面,對于模型無用的特征,不僅影響模型的訓(xùn)練速度,同時(shí)也會影響模型的效果。如果你對機(jī)器學(xué)習(xí)感興趣,可以后臺回復(fù)關(guān)鍵字:「加群」,加入技術(shù)交流群。

推薦一本由美國科學(xué)作家 Michael Nielsen編寫的非常好的深度學(xué)習(xí)入門書籍-《Neural Network and Deep Learning》,中文譯為《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》。
個(gè)人認(rèn)為是目前最好的神經(jīng)網(wǎng)絡(luò)與機(jī)器學(xué)習(xí)入門資料。內(nèi)容非常淺顯易懂,很多數(shù)學(xué)密集的區(qū)域作者都有提示。全書貫穿的是 MNIST 手寫數(shù)字的識別問題,每個(gè)模型和改進(jìn)都有詳細(xì)注釋的代碼。非常適合用來入門神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)!

領(lǐng)取方式:
長按掃碼,發(fā)消息 [神經(jīng)網(wǎng)絡(luò)]
感謝你的分享,點(diǎn)贊,在看三連 