
時間序列+Transformer!

本文約3500字,建議閱讀10分鐘
本文帶你了解iTransformer,更好地利用注意力機(jī)制進(jìn)行多變量關(guān)聯(lián)。
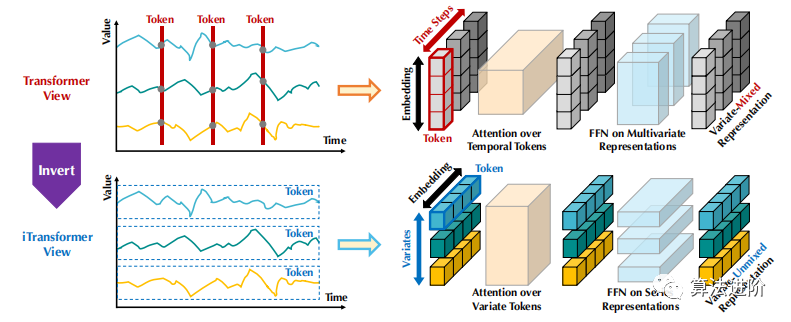
圖1 普通Transformer(上)和提出的iTransformer(下)之間的比較。Transformer嵌入了時間標(biāo)記,其中包含每個時間步的多變量表示。iTransformer將每個序列獨(dú)立地嵌入到變量標(biāo)記中,這樣注意力模塊就可以描述多變量相關(guān)性,前饋網(wǎng)絡(luò)可以對序列表示進(jìn)行編碼。
Transformer變體被提出用于時間序列預(yù)測,超越了同期TCN和基于RNN的預(yù)測。
現(xiàn)有的變體可分為四類:是否修改組件和架構(gòu),如圖2所示。
第一類主要涉及組件調(diào)整,如注意力模塊和長序列的復(fù)雜性優(yōu)化。
第二類充分利用Transformer,關(guān)注時間序列的內(nèi)在處理。
第三類在組件和架構(gòu)兩方面翻新Transformer,以捕捉跨時間和跨變量的依賴性。
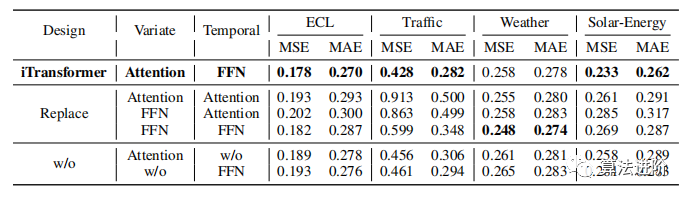
與之前的工作不同,iTransformer沒有修改Transformer的任何原生組件,而是采用反向維度上的組件,并改變其架構(gòu)。

多元時間序列預(yù)測涉及歷史觀測值X和預(yù)測未來值Y。給定T個時間步長和N個變量,預(yù)測未來S個時間步長。數(shù)據(jù)集中變量可能存在系統(tǒng)時間滯后,且變量在物理測量和統(tǒng)計(jì)分布上可能不同。
2.1 結(jié)構(gòu)概述
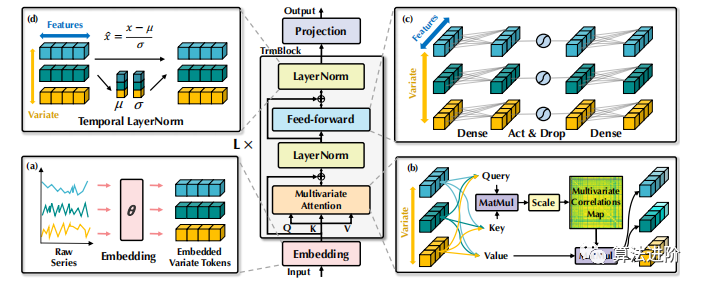
我們提出的iTransformer采用了Transformer的編碼器架構(gòu),包括嵌入、投影和Transformer塊,如圖3所示。
將整個序列作為標(biāo)記。在iTransformer中,基于回望序列X:,n預(yù)測每個特定變量?Y:,n的未來序列的過程簡單地表示如下:
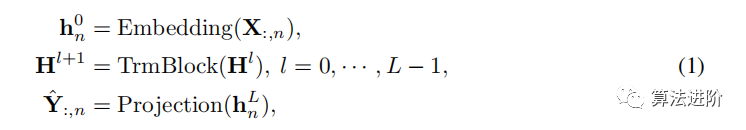
其中H={h1, · · · , hN }∈RN×D包含N個維度為D的嵌入表征,上標(biāo)表示層索引。嵌入:RT7→ RD 和投影:RD7→ RS 均由多層感知器(MLP)實(shí)現(xiàn)。變量表征通過自注意力交互,并在每個TrmBlock中由共享的前饋網(wǎng)絡(luò)獨(dú)立處理,不再需要位置嵌入。
iTransformers。該架構(gòu)靈活地使用注意力機(jī)制,允許多元相關(guān)性,并可降低復(fù)雜性。一系列高效的注意力機(jī)制可以作為插件,令牌數(shù)量可在訓(xùn)練和推理之間變化,模型可在任意數(shù)量的變量上進(jìn)行訓(xùn)練。反向Transformer,命名為iTransformers,在時間序列預(yù)測方面具有優(yōu)勢。
2.2 倒置Transformer模塊分析
我們組織了由層歸一化、前饋網(wǎng)絡(luò)和自注意力模塊組成的 L 塊的堆棧。
層歸一化(Layer normalization)
層歸一化最初用于提高深度網(wǎng)絡(luò)收斂性和穩(wěn)定性,在Transformer預(yù)測器中,對同一時間戳的多變量表示進(jìn)行歸一化。反向版本中,歸一化應(yīng)用于單個變量的序列表示(如公式2),有效處理非平穩(wěn)問題。所有序列標(biāo)記歸一化為高斯分布,減少不一致測量導(dǎo)致的差異。之前的架構(gòu)中,時間步的不同標(biāo)記將被歸一化,導(dǎo)致時間序列過度平滑。
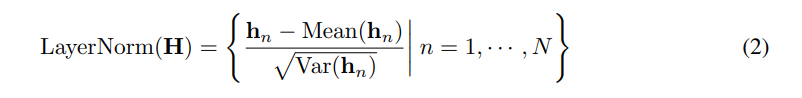
前饋網(wǎng)絡(luò)(Feed-forward network)
Transformer 使用前饋網(wǎng)絡(luò) (FFN) 作為編碼標(biāo)記表示的基本構(gòu)建塊,對每個標(biāo)記應(yīng)用相同的前饋網(wǎng)絡(luò)。在反向版本中,F(xiàn)FN 用于每個變量標(biāo)記的序列表示,通過堆疊反向塊,它們致力于編碼觀測到的時序,并使用密集的非線性連接解碼未來序列的表示。堆疊反向塊可以提取復(fù)雜的表示來描述時間序列,并使用密集的非線性連接解碼未來序列的表示。實(shí)驗(yàn)表明,分工有助于享受線性層在性能和泛化能力方面的好處。
自注意力(Self-attention)
逆模型將時間序列視為獨(dú)立過程,通過自注意力模塊全面提取時間序列表示,采用線性投影獲取查詢、鍵和值,計(jì)算前Softmax分?jǐn)?shù),揭示變量之間的相關(guān)性,為多元序列預(yù)測提供更自然和可解釋的機(jī)制。
3 實(shí)驗(yàn)
我們?nèi)嬖u估了iTransformer在時間序列預(yù)測應(yīng)用中的性能,驗(yàn)證了其通用性,并探討了Transformer組件在時間序列反向維度的應(yīng)用效果。
在實(shí)驗(yàn)中,我們使用了7個真實(shí)數(shù)據(jù)集,包括ECL、ETT、Exchange、Traffic、Weather、太陽能和PEMS,以及Market數(shù)據(jù)集。我們始終優(yōu)于其他基線。附錄A.1提供了詳細(xì)的數(shù)據(jù)集描述。
3.1 預(yù)測結(jié)果
本文進(jìn)行了廣泛的實(shí)驗(yàn),評估提出的模型與先進(jìn)深度預(yù)測器的預(yù)測性能。選擇10個廣為人知的預(yù)測模型作為基準(zhǔn),包括基于Transformer、線性和TCN的方法。
表1 預(yù)測長度S ∈ {12, 24, 36, 48}的PEMS和S ∈ {96, 192, 336, 720}的其他預(yù)測的多元預(yù)測結(jié)果,固定回溯長度T = 96。結(jié)果來自所有預(yù)測長度的平均值。Avg表示進(jìn)一步按子集平均。完整結(jié)果列于附錄F.4

結(jié)果顯示,iTransformer模型在預(yù)測高維時間序列方面表現(xiàn)最佳,優(yōu)于其他預(yù)測器。PatchTST在某些情況下失敗,可能是因?yàn)槠湫扪a(bǔ)機(jī)制無法處理快速波動。相比之下,iTransformer將整個序列變化聚合為序列表示,可以更好地應(yīng)對這種情況。Crossformer的性能仍然低于iTransformer,表明來自不同多元的時間不一致的補(bǔ)丁的相互作用會給預(yù)測帶來不必要的噪聲。因此,原生的Transformer組件能夠勝任時間建模和多元相關(guān),而提出的反向架構(gòu)可以有效地處理現(xiàn)實(shí)世界的時間序列預(yù)測場景。
3.2 iTransformer框架通用性
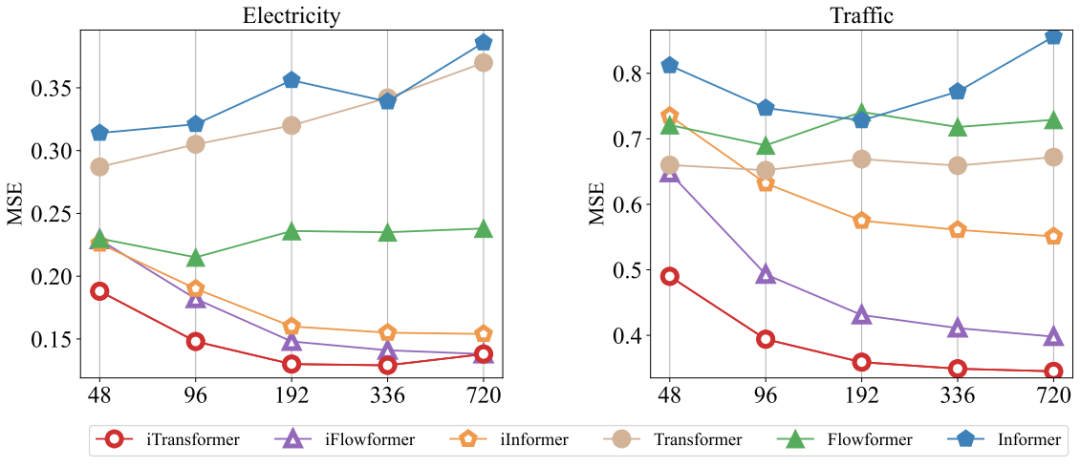
本節(jié)應(yīng)用框架評估了Transformer變體,如Reformer、Informer、Flowformer和FlashAttention,以提高預(yù)測器性能,提高效率,泛化未知變量,更好地利用歷史觀測。
可以提升預(yù)測效果!
該框架在Transformer上實(shí)現(xiàn)了平均38.9%的提升,在Reformer上實(shí)現(xiàn)了36.1%的提升,在Informer上實(shí)現(xiàn)了28.5%的提升,在Flowformer上實(shí)現(xiàn)了16.8%的提升,在Flashformer上實(shí)現(xiàn)了32.2%的提升。由于引入了高效的線性復(fù)雜度注意力,iTransformer解決了大量變量導(dǎo)致的計(jì)算問題。因此,iTransformer的思想可以在基于Transformer的預(yù)測器上廣泛實(shí)踐。


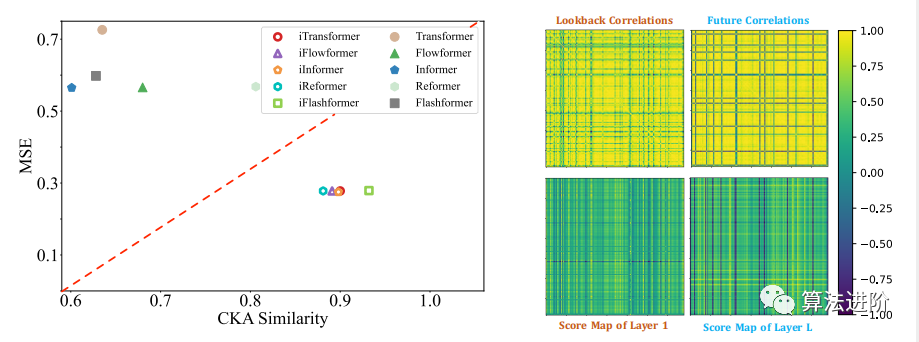
多元相關(guān)性分析。通過分配多元相關(guān)性責(zé)任給注意力機(jī)制,學(xué)習(xí)到的映射具有增強(qiáng)的可解釋性。如圖6太陽能案例中,淺層注意力層與原始輸入序列相關(guān)性相似,深層則與未來序列相關(guān)性相似,驗(yàn)證了反向操作可提供可解釋的注意力。
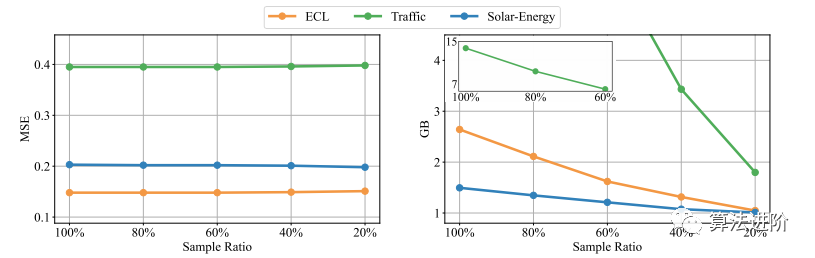
高效的訓(xùn)練策略。本文提出了一種新的訓(xùn)練策略,通過利用先前證明的變量生成能力來訓(xùn)練高維多元序列。具體來說,在每個批中隨機(jī)選擇部分變量,只使用選定的變量訓(xùn)練模型。由于我們的反演,變量通道的數(shù)量是靈活的,因此模型可以預(yù)測所有變量進(jìn)行預(yù)測。如圖7所示,我們提出的策略的性能仍然與全變量訓(xùn)練相當(dāng),同時內(nèi)存占用可以顯著減少。
編輯:黃繼彥