
Redis緩存使用技巧和設(shè)計(jì)方案
點(diǎn)擊關(guān)注公眾號(hào),Java干貨及時(shí)送達(dá)??

來源:blog.csdn.net/ym123456677/article/details/80063491
1)緩存的收益和成本分析 2)緩存更新策略 3)緩存粒度控制 4)穿透優(yōu)化 5)無底洞優(yōu)化 6)雪崩優(yōu)化 7)熱點(diǎn)key重建優(yōu)化
緩存能夠有效地加速應(yīng)用的讀寫速度,同時(shí)也可以降低后端負(fù)載,對(duì)日常應(yīng)用的開發(fā)至關(guān)重要。下面會(huì)介紹緩存使用技巧和設(shè)計(jì)方案,包含如下內(nèi)容:緩存的收益和成本分析、緩存更新策略的選擇和使用場景、緩存粒度控制方法、穿透問題優(yōu)化、無底洞問題優(yōu)化、雪崩問題優(yōu)化、熱點(diǎn)key重建優(yōu)化。
1)緩存的收益和成本分析
下圖左側(cè)為客戶端直接調(diào)用存儲(chǔ)層的架構(gòu),右側(cè)為比較典型的緩存層+存儲(chǔ)層架構(gòu)。
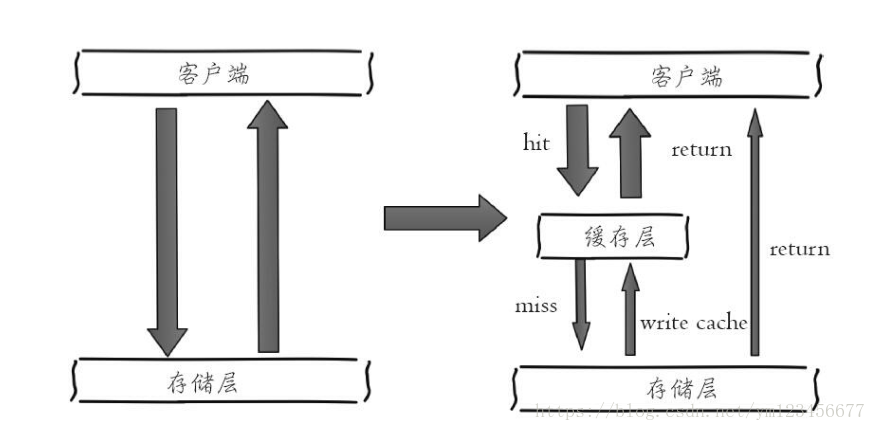
下面分析一下緩存加入后帶來的收益和成本。
收益:
①加速讀寫:因?yàn)榫彺嫱ǔ6际侨珒?nèi)存的,而存儲(chǔ)層通常讀寫性能不夠強(qiáng)悍(例如MySQL),通過緩存的使用可以有效地加速讀寫,優(yōu)化用戶體驗(yàn)。
②降低后端負(fù)載:幫助后端減少訪問量和復(fù)雜計(jì)算(例如很復(fù)雜的SQL語句),在很大程度降低了后端的負(fù)載。
成本:
①數(shù)據(jù)不一致性:緩存層和存儲(chǔ)層的數(shù)據(jù)存在著一定時(shí)間窗口的不一致性,時(shí)間窗口跟更新策略有關(guān)。
②代碼維護(hù)成本:加入緩存后,需要同時(shí)處理緩存層和存儲(chǔ)層的邏輯,增大了開發(fā)者維護(hù)代碼的成本。
③運(yùn)維成本:以Redis Cluster為例,加入后無形中增加了運(yùn)維成本。
緩存的使用場景基本包含如下兩種:
①開銷大的復(fù)雜計(jì)算:以MySQL為例子,一些復(fù)雜的操作或者計(jì)算(例如大量聯(lián)表操作、一些分組計(jì)算),如果不加緩存,不但無法滿足高并發(fā)量,同時(shí)也會(huì)給MySQL帶來巨大的負(fù)擔(dān)。
②加速請(qǐng)求響應(yīng):即使查詢單條后端數(shù)據(jù)足夠快(例如select*from table where id=),那么依然可以使用緩存,以Redis為例子,每秒可以完成數(shù)萬次讀寫,并且提供的批量操作可以優(yōu)化整個(gè)IO鏈的響應(yīng)時(shí)間。
2)緩存更新策略
緩存中的數(shù)據(jù)會(huì)和數(shù)據(jù)源中的真實(shí)數(shù)據(jù)有一段時(shí)間窗口的不一致,需要利用某些策略進(jìn)行更新,下面會(huì)介紹幾種主要的緩存更新策略。
①LRU/LFU/FIFO算法剔除 :剔除算法通常用于緩存使用量超過了預(yù)設(shè)的最大值時(shí)候,如何對(duì)現(xiàn)有的數(shù)據(jù)進(jìn)行剔除。例如Redis使用maxmemory-policy這個(gè)配置作為內(nèi)存最大值后對(duì)于數(shù)據(jù)的剔除策略。
②超時(shí)剔除 :通過給緩存數(shù)據(jù)設(shè)置過期時(shí)間,讓其在過期時(shí)間后自動(dòng)刪除,例如Redis提供的expire命令。如果業(yè)務(wù)可以容忍一段時(shí)間內(nèi),緩存層數(shù)據(jù)和存儲(chǔ)層數(shù)據(jù)不一致,那么可以為其設(shè)置過期時(shí)間。在數(shù)據(jù)過期后,再從真實(shí)數(shù)據(jù)源獲取數(shù)據(jù),重新放到緩存并設(shè)置過期時(shí)間。例如一個(gè)視頻的描述信息,可以容忍幾分鐘內(nèi)數(shù)據(jù)不一致,但是涉及交易方面的業(yè)務(wù),后果可想而知。
③主動(dòng)更新 :應(yīng)用方對(duì)于數(shù)據(jù)的一致性要求高,需要在真實(shí)數(shù)據(jù)更新后,立即更新緩存數(shù)據(jù)。例如可以利用消息系統(tǒng)或者其他方式通知緩存更新。
三種常見更新策略的對(duì)比:

有兩個(gè)建議:
①低一致性業(yè)務(wù)建議配置最大內(nèi)存和淘汰策略的方式使用。
②高一致性業(yè)務(wù)可以結(jié)合使用超時(shí)剔除和主動(dòng)更新,這樣即使主動(dòng)更新出了問題,也能保證數(shù)據(jù)過期時(shí)間后刪除臟數(shù)據(jù)。
3)緩存粒度控制
緩存粒度問題是一個(gè)容易被忽視的問題,如果使用不當(dāng),可能會(huì)造成很多無用空間的浪費(fèi),網(wǎng)絡(luò)帶寬的浪費(fèi),代碼通用性較差等情況,需要綜合數(shù)據(jù)通用性、空間占用比、代碼維護(hù)性三點(diǎn)進(jìn)行取舍。
緩存比較常用的選型,緩存層選用Redis,存儲(chǔ)層選用MySQL。
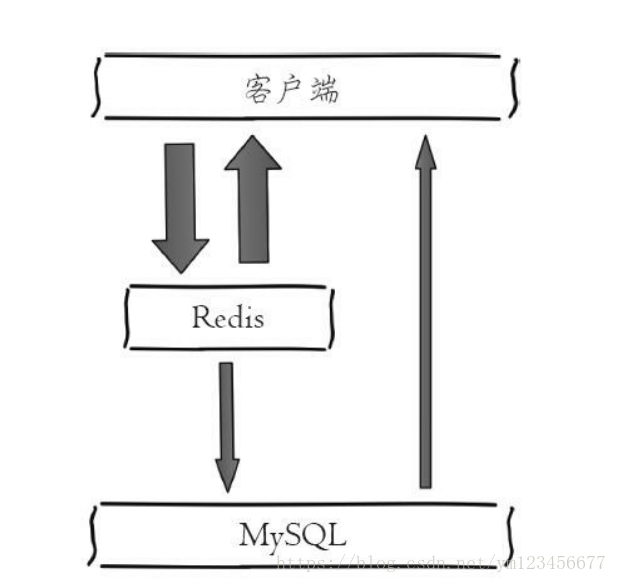
4)穿透優(yōu)化
緩存穿透是指查詢一個(gè)根本不存在的數(shù)據(jù),緩存層和存儲(chǔ)層都不會(huì)命中,通常出于容錯(cuò)的考慮,如果從存儲(chǔ)層查不到數(shù)據(jù)則不寫入緩存層。
通常可以在程序中分別統(tǒng)計(jì)總調(diào)用數(shù)、緩存層命中數(shù)、存儲(chǔ)層命中數(shù),如果發(fā)現(xiàn)大量存儲(chǔ)層空命中,可能就是出現(xiàn)了緩存穿透問題。造成緩存穿透的基本原因有兩個(gè)。第一,自身業(yè)務(wù)代碼或者數(shù)據(jù)出現(xiàn)問題,第二,一些惡意攻擊、爬蟲等造成大量空命中。下面我們來看一下如何解決緩存穿透問題。
①緩存空對(duì)象 :如圖下所示,當(dāng)?shù)?步存儲(chǔ)層不命中后,仍然將空對(duì)象保留到緩存層中,之后再訪問這個(gè)數(shù)據(jù)將會(huì)從緩存中獲取,這樣就保護(hù)了后端數(shù)據(jù)源。
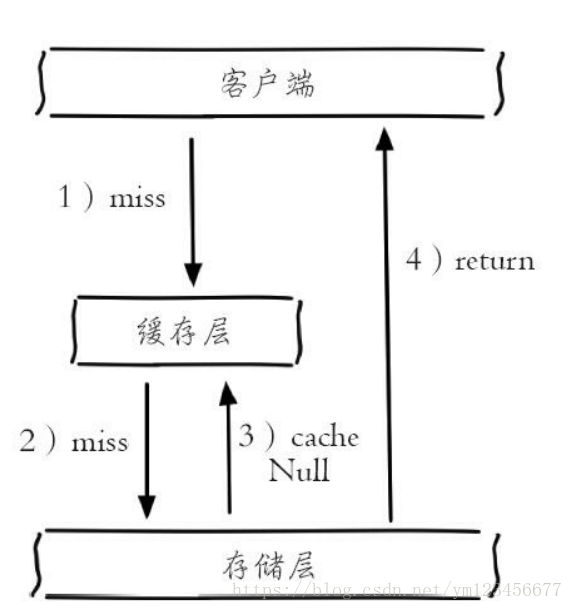
緩存空對(duì)象會(huì)有兩個(gè)問題:第一,空值做了緩存,意味著緩存層中存了更多的鍵,需要更多的內(nèi)存空間(如果是攻擊,問題更嚴(yán)重),比較有效的方法是針對(duì)這類數(shù)據(jù)設(shè)置一個(gè)較短的過期時(shí)間,讓其自動(dòng)剔除。第二,緩存層和存儲(chǔ)層的數(shù)據(jù)會(huì)有一段時(shí)間窗口的不一致,可能會(huì)對(duì)業(yè)務(wù)有一定影響。例如過期時(shí)間設(shè)置為5分鐘,如果此時(shí)存儲(chǔ)層添加了這個(gè)數(shù)據(jù),那此段時(shí)間就會(huì)出現(xiàn)緩存層和存儲(chǔ)層數(shù)據(jù)的不一致,此時(shí)可以利用消息系統(tǒng)或者其他方式清除掉緩存層中的空對(duì)象。
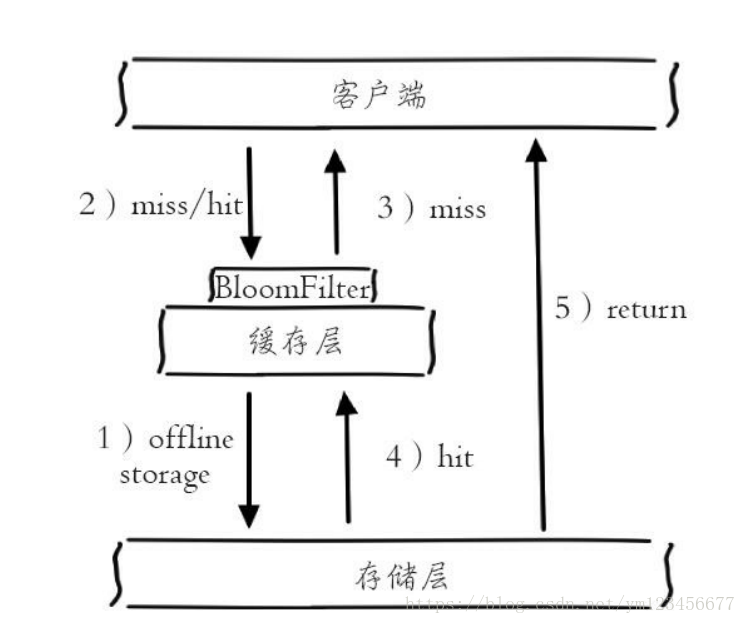
②布隆過濾器攔截
如下圖所示,在訪問緩存層和存儲(chǔ)層之前,將存在的key用布隆過濾器提前保存起來,做第一層攔截。例如:一個(gè)推薦系統(tǒng)有4億個(gè)用戶id,每個(gè)小時(shí)算法工程師會(huì)根據(jù)每個(gè)用戶之前歷史行為計(jì)算出推薦數(shù)據(jù)放到存儲(chǔ)層中,但是最新的用戶由于沒有歷史行為,就會(huì)發(fā)生緩存穿透的行為,為此可以將所有推薦數(shù)據(jù)的用戶做成布隆過濾器。如果布隆過濾器認(rèn)為該用戶id不存在,那么就不會(huì)訪問存儲(chǔ)層,在一定程度保護(hù)了存儲(chǔ)層。
 圖片
圖片緩存空對(duì)象和布隆過濾器方案對(duì)比

另:布隆過濾器簡單說明:
如果想判斷一個(gè)元素是不是在一個(gè)集合里,一般想到的是將集合中所有元素保存起來,然后通過比較確定。鏈表、樹、散列表(又叫哈希表,Hash table)等等數(shù)據(jù)結(jié)構(gòu)都是這種思路。但是隨著集合中元素的增加,我們需要的存儲(chǔ)空間越來越大。同時(shí)檢索速度也越來越慢。
Bloom Filter 是一種空間效率很高的隨機(jī)數(shù)據(jù)結(jié)構(gòu),Bloom filter 可以看做是對(duì) bit-map 的擴(kuò)展, 它的原理是:
當(dāng)一個(gè)元素被加入集合時(shí),通過 K 個(gè) Hash 函數(shù)將這個(gè)元素映射成一個(gè)位陣列(Bit array)中的 K 個(gè)點(diǎn),把它們置為 1。檢索時(shí),我們只要看看這些點(diǎn)是不是都是 1 就(大約)知道集合中有沒有它了:
如果這些點(diǎn)有任何一個(gè) 0,則被檢索元素一定不在;如果都是 1,則被檢索元素很可能在。
5)無底洞優(yōu)化
為了滿足業(yè)務(wù)需要可能會(huì)添加大量新的緩存節(jié)點(diǎn),但是發(fā)現(xiàn)性能不但沒有好轉(zhuǎn)反而下降了。用一句通俗的話解釋就是,更多的節(jié)點(diǎn)不代表更高的性能,所謂“無底洞”就是說投入越多不一定產(chǎn)出越多。但是分布式又是不可以避免的,因?yàn)樵L問量和數(shù)據(jù)量越來越大,一個(gè)節(jié)點(diǎn)根本抗不住,所以如何高效地在分布式緩存中批量操作是一個(gè)難點(diǎn)。
無底洞問題分析:
①客戶端一次批量操作會(huì)涉及多次網(wǎng)絡(luò)操作,也就意味著批量操作會(huì)隨著節(jié)點(diǎn)的增多,耗時(shí)會(huì)不斷增大。
②網(wǎng)絡(luò)連接數(shù)變多,對(duì)節(jié)點(diǎn)的性能也有一定影響。
如何在分布式條件下優(yōu)化批量操作?我們來看一下常見的IO優(yōu)化思路:
命令本身的優(yōu)化,例如優(yōu)化SQL語句等。 減少網(wǎng)絡(luò)通信次數(shù)。 降低接入成本,例如客戶端使用長連/連接池、NIO等。
這里我們假設(shè)命令、客戶端連接已經(jīng)為最優(yōu),重點(diǎn)討論減少網(wǎng)絡(luò)操作次數(shù)。下面我們將結(jié)合Redis Cluster的一些特性對(duì)四種分布式的批量操作方式進(jìn)行說明。
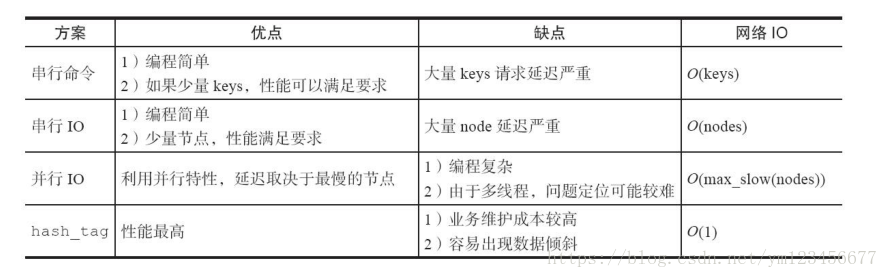
①串行命令 :由于n個(gè)key是比較均勻地分布在Redis Cluster的各個(gè)節(jié)點(diǎn)上,因此無法使用mget命令一次性獲取,所以通常來講要獲取n個(gè)key的值,最簡單的方法就是逐次執(zhí)行n個(gè)get命令,這種操作時(shí)間復(fù)雜度較高,它的操作時(shí)間=n次網(wǎng)絡(luò)時(shí)間+n次命令時(shí)間,網(wǎng)絡(luò)次數(shù)是n。很顯然這種方案不是最優(yōu)的,但是實(shí)現(xiàn)起來比較簡單。
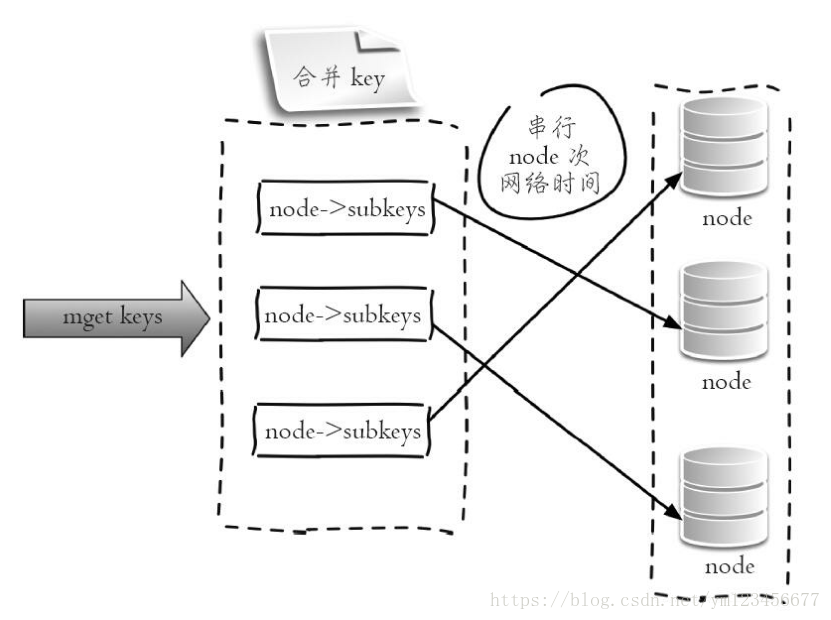
②串行IO :Redis Cluster使用CRC16算法計(jì)算出散列值,再取對(duì)16383的余數(shù)就可以算出slot值,同時(shí)Smart客戶端會(huì)保存slot和節(jié)點(diǎn)的對(duì)應(yīng)關(guān)系,有了這兩個(gè)數(shù)據(jù)就可以將屬于同一個(gè)節(jié)點(diǎn)的key進(jìn)行歸檔,得到每個(gè)節(jié)點(diǎn)的key子列表,之后對(duì)每個(gè)節(jié)點(diǎn)執(zhí)行mget或者Pipeline操作,它的操作時(shí)間=node次網(wǎng)絡(luò)時(shí)間+n次命令時(shí)間,網(wǎng)絡(luò)次數(shù)是node的個(gè)數(shù),整個(gè)過程如下圖所示,很明顯這種方案比第一種要好很多,但是如果節(jié)點(diǎn)數(shù)太多,還是有一定的性能問題。
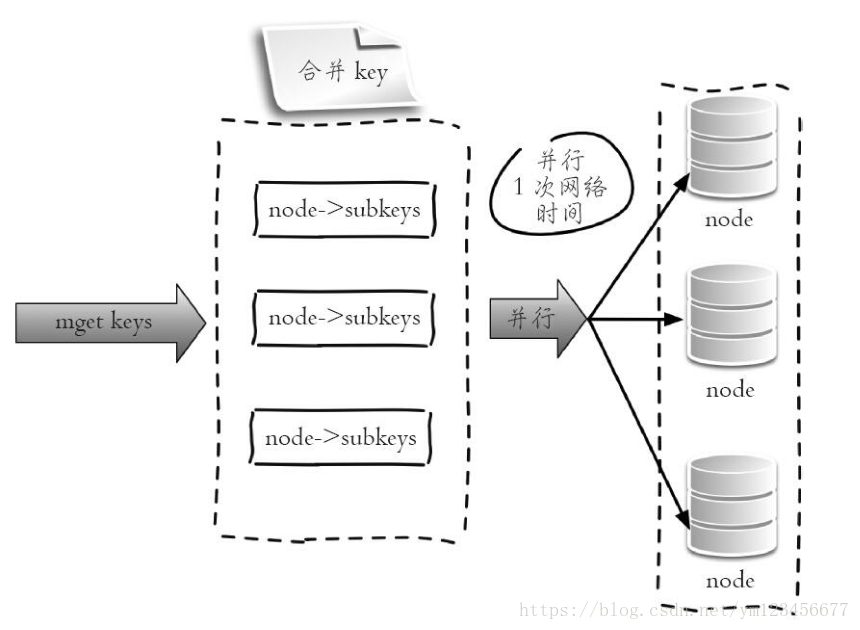
③并行IO :此方案是將方案2中的最后一步改為多線程執(zhí)行,網(wǎng)絡(luò)次數(shù)雖然還是節(jié)點(diǎn)個(gè)數(shù),但由于使用多線程網(wǎng)絡(luò)時(shí)間變?yōu)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(0, 150, 136);">O(1),這種方案會(huì)增加編程的復(fù)雜度。
④hash_tag實(shí)現(xiàn) :Redis Cluster的hash_tag功能,它可以將多個(gè)key強(qiáng)制分配到一個(gè)節(jié)點(diǎn)上,它的操作時(shí)間=1次網(wǎng)絡(luò)時(shí)間+n次命令時(shí)間。
四種批量操作解決方案對(duì)比
6)雪崩優(yōu)化
緩存雪崩:由于緩存層承載著大量請(qǐng)求,有效地保護(hù)了存儲(chǔ)層,但是如果緩存層由于某些原因不能提供服務(wù),于是所有的請(qǐng)求都會(huì)達(dá)到存儲(chǔ)層,存儲(chǔ)層的調(diào)用量會(huì)暴增,造成存儲(chǔ)層也會(huì)級(jí)聯(lián)宕機(jī)的情況。
預(yù)防和解決緩存雪崩問題,可以從以下三個(gè)方面進(jìn)行著手:
①保證緩存層服務(wù)高可用性 。如果緩存層設(shè)計(jì)成高可用的,即使個(gè)別節(jié)點(diǎn)、個(gè)別機(jī)器、甚至是機(jī)房宕掉,依然可以提供服務(wù),例如前面介紹過的Redis Sentinel和Redis Cluster都實(shí)現(xiàn)了高可用。
②依賴隔離組件為后端限流并降級(jí) 。在實(shí)際項(xiàng)目中,我們需要對(duì)重要的資源(例如Redis、MySQL、HBase、外部接口)都進(jìn)行隔離,讓每種資源都單獨(dú)運(yùn)行在自己的線程池中,即使個(gè)別資源出現(xiàn)了問題,對(duì)其他服務(wù)沒有影響。但是線程池如何管理,比如如何關(guān)閉資源池、開啟資源池、資源池閥值管理,這些做起來還是相當(dāng)復(fù)雜的。
③提前演練 。在項(xiàng)目上線前,演練緩存層宕掉后,應(yīng)用以及后端的負(fù)載情況以及可能出現(xiàn)的問題,在此基礎(chǔ)上做一些預(yù)案設(shè)定。
7)熱點(diǎn)key重建優(yōu)化
開發(fā)人員使用“緩存+過期時(shí)間”的策略既可以加速數(shù)據(jù)讀寫,又保證數(shù)據(jù)的定期更新,這種模式基本能夠滿足絕大部分需求。但是有兩個(gè)問題如果同時(shí)出現(xiàn),可能就會(huì)對(duì)應(yīng)用造成致命的危害:
當(dāng)前key是一個(gè)熱點(diǎn)key(例如一個(gè)熱門的娛樂新聞),并發(fā)量非常大。 重建緩存不能在短時(shí)間完成,可能是一個(gè)復(fù)雜計(jì)算,例如復(fù)雜的SQL、多次IO、多個(gè)依賴等。在緩存失效的瞬間,有大量線程來重建緩存,造成后端負(fù)載加大,甚至可能會(huì)讓應(yīng)用崩潰。
要解決這個(gè)問題也不是很復(fù)雜,但是不能為了解決這個(gè)問題給系統(tǒng)帶來更多的麻煩,所以需要制定如下目標(biāo):
減少重建緩存的次數(shù) 數(shù)據(jù)盡可能一致。 較少的潛在危險(xiǎn)
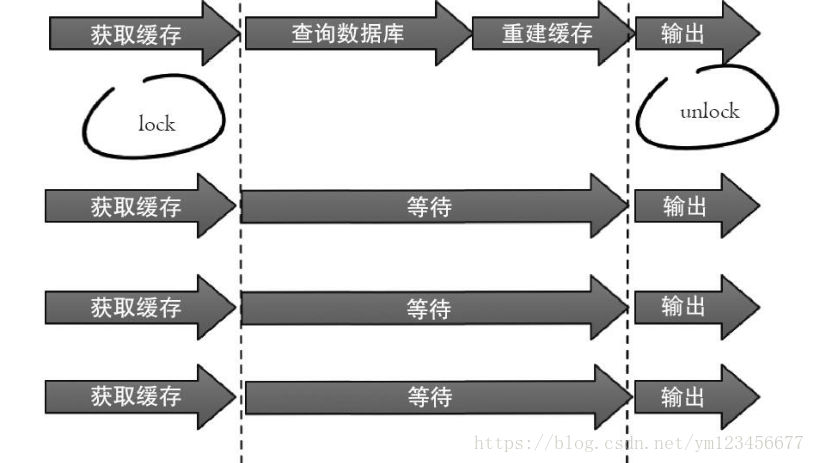
①互斥鎖 :此方法只允許一個(gè)線程重建緩存,其他線程等待重建緩存的線程執(zhí)行完,重新從緩存獲取數(shù)據(jù)即可,整個(gè)過程如圖所示。
下面代碼使用Redis的setnx命令實(shí)現(xiàn)上述功能:
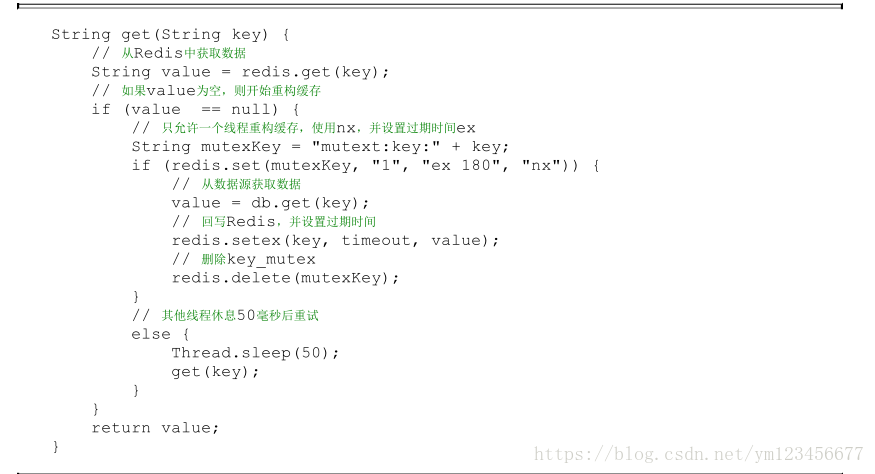
1)從Redis獲取數(shù)據(jù),如果值不為空,則直接返回值;否則執(zhí)行下面的2.1)和2.2)步驟。
2.1)如果set(nx和ex)結(jié)果為true,說明此時(shí)沒有其他線程重建緩存,那么當(dāng)前線程執(zhí)行緩存構(gòu)建邏輯。
2.2)如果set(nx和ex)結(jié)果為false,說明此時(shí)已經(jīng)有其他線程正在執(zhí)行構(gòu)建緩存的工作,那么當(dāng)前線程將休息指定時(shí)間(例如這里是50毫秒,取決于構(gòu)建緩存的速度)后,重新執(zhí)行函數(shù),直到獲取到數(shù)據(jù)。
②永遠(yuǎn)不過期
“永遠(yuǎn)不過期”包含兩層意思:
從緩存層面來看,確實(shí)沒有設(shè)置過期時(shí)間,所以不會(huì)出現(xiàn)熱點(diǎn)key過期后產(chǎn)生的問題,也就是“物理”不過期。 從功能層面來看,為每個(gè)value設(shè)置一個(gè)邏輯過期時(shí)間,當(dāng)發(fā)現(xiàn)超過邏輯過期時(shí)間后,會(huì)使用單獨(dú)的線程去構(gòu)建緩存。
從實(shí)戰(zhàn)看,此方法有效杜絕了熱點(diǎn)key產(chǎn)生的問題,但唯一不足的就是重構(gòu)緩存期間,會(huì)出現(xiàn)數(shù)據(jù)不一致的情況,這取決于應(yīng)用方是否容忍這種不一致。
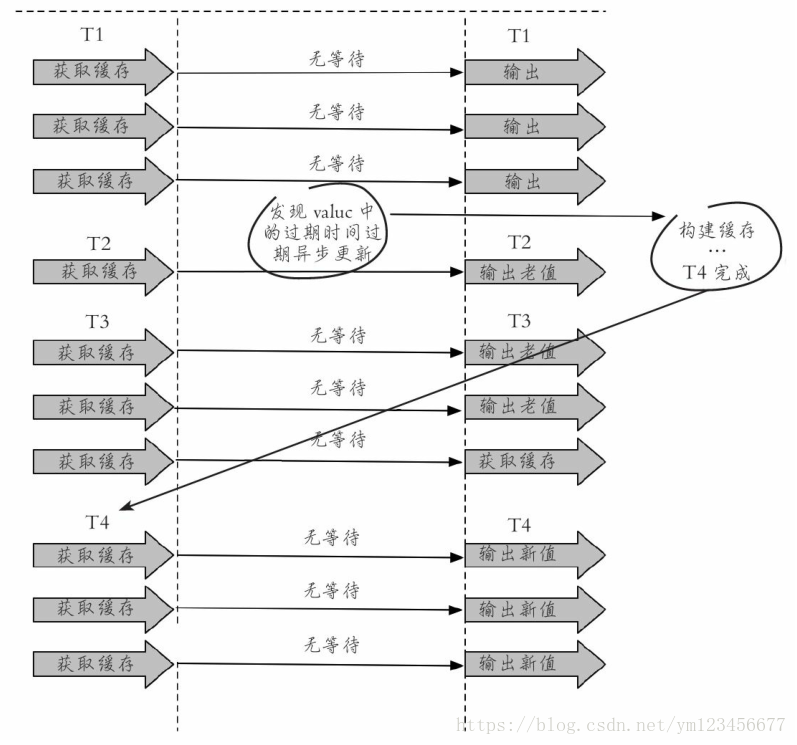
兩種熱點(diǎn)key的解決方法

1.?干掉Random:這個(gè)類已經(jīng)成為獲取隨機(jī)數(shù)的王者
2.?4種方案,幫你解決Maven創(chuàng)建項(xiàng)目過慢問題
最近面試BAT,整理一份面試資料《Java面試BATJ通關(guān)手冊(cè)》,覆蓋了Java核心技術(shù)、JVM、Java并發(fā)、SSM、微服務(wù)、數(shù)據(jù)庫、數(shù)據(jù)結(jié)構(gòu)等等。
獲取方式:點(diǎn)“在看”,關(guān)注公眾號(hào)并回復(fù)?Java?領(lǐng)取,更多內(nèi)容陸續(xù)奉上。
文章有幫助的話,在看,轉(zhuǎn)發(fā)吧。
謝謝支持喲 (*^__^*)
