
【建議收藏】GraphQL及元數(shù)據(jù)驅(qū)動(dòng)架構(gòu)在后端BFF中的實(shí)踐

總第448篇
2021年 第018篇

GraphQL是Facebook提出的一種數(shù)據(jù)查詢語言,核心特性是數(shù)據(jù)聚合和按需索取,目前被廣泛應(yīng)用于前后端之間,解決客戶端靈活使用數(shù)據(jù)問題。本文介紹的是GraphQL的另一種實(shí)踐,我們將GraphQL下沉至后端BFF(Backend For Frontend)層之下,結(jié)合元數(shù)據(jù)技術(shù),實(shí)現(xiàn)數(shù)據(jù)和加工邏輯的按需查詢和執(zhí)行。這樣不僅解決了后端BFF層靈活使用數(shù)據(jù)的問題,這些字段加工邏輯還可以直接復(fù)用,大幅度提升了研發(fā)的效率。
1 BFF的由來
2 BFF背景下的核心矛盾
3 BFF應(yīng)用模式分析
3.1 后端BFF模式
3.2 前端BFF模式
4 基于GraphQL及元數(shù)據(jù)的信息聚合架構(gòu)設(shè)計(jì)
4.1 整體思路
4.2 核心設(shè)計(jì)
5 針對(duì)GraphQL的優(yōu)化實(shí)踐
5.1 使用簡化
5.2 性能優(yōu)化
6 新架構(gòu)對(duì)研發(fā)模式的影響
6.1 聚焦業(yè)務(wù)的開發(fā)模式
6.2 研發(fā)流程升級(jí)
7 總結(jié)
8 參考文獻(xiàn)
9 招聘信息
1 BFF的由來
BFF一詞來自Sam Newman的一篇博文《Pattern:Backends For Frontends》,指的是服務(wù)于前端的后端。BFF是解決什么問題的呢?據(jù)原文描述,隨著移動(dòng)互聯(lián)網(wǎng)的興起,原適應(yīng)于桌面Web的服務(wù)端功能希望同時(shí)提供給移動(dòng)App使用,而在這個(gè)過程中存在這樣的問題:
移動(dòng)App和桌面Web在UI部分存在差異。 移動(dòng)App涉及不同的端,不僅有iOS、還有Android,這些不同端的UI之間存在差異。 原有后端功能和桌面Web UI之間已經(jīng)存在了較大的耦合。
因?yàn)槎说牟町愋源嬖冢?wù)端的功能要針對(duì)端的差異進(jìn)行適配和裁剪,而服務(wù)端的業(yè)務(wù)功能本身是相對(duì)單一的,這就產(chǎn)生了一個(gè)矛盾——服務(wù)端的單一業(yè)務(wù)功能和端的差異性訴求之間的矛盾。那么這個(gè)問題怎么解決呢?這也是文章的副標(biāo)題所描述的"Single-purpose Edge Services for UIs and external parties",引入BFF,由BFF來針對(duì)多端差異做適配,這也是目前業(yè)界廣泛使用的一種模式。
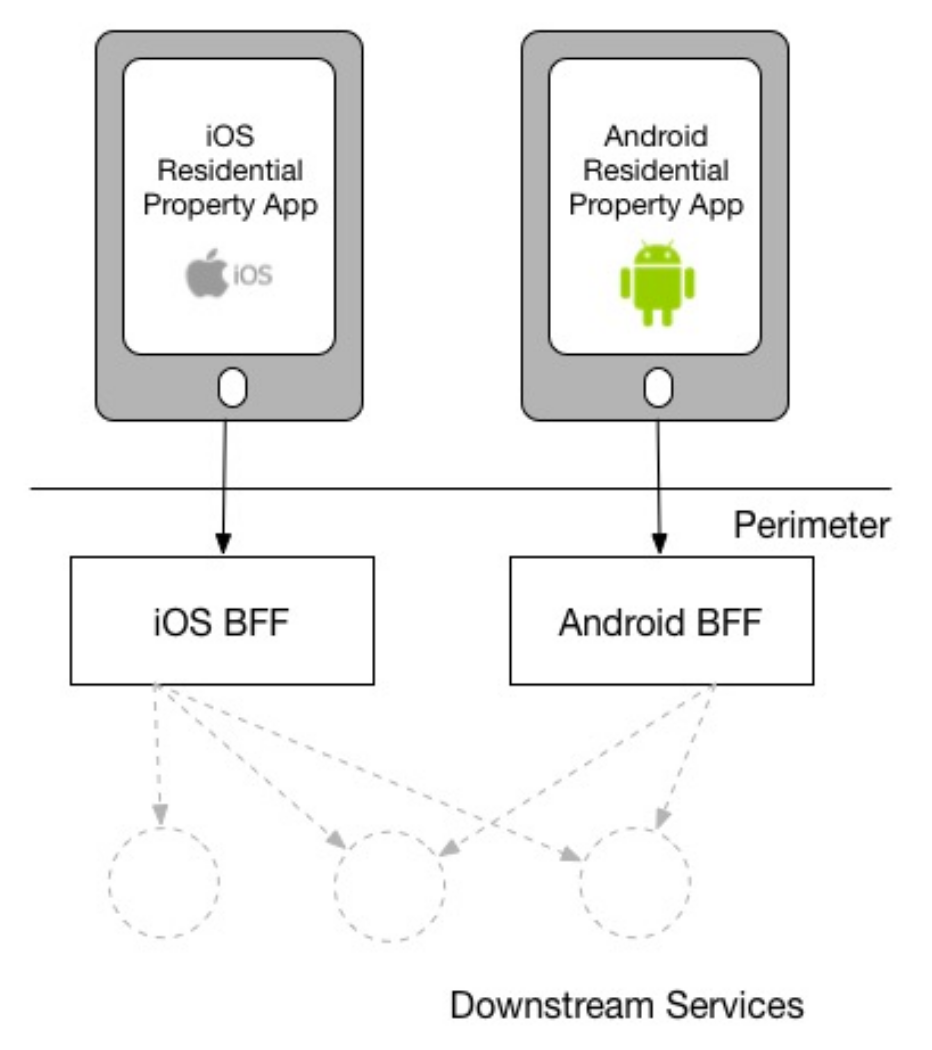
在實(shí)際業(yè)務(wù)的實(shí)踐中,導(dǎo)致這種端差異性的原因有很多,有技術(shù)的原因,也有業(yè)務(wù)的原因。比如,用戶的客戶端是Android還是iOS,是大屏還是小屏,是什么版本。再比如,業(yè)務(wù)屬于哪個(gè)行業(yè),產(chǎn)品形態(tài)是什么,功能投放在什么場景,面向的用戶群體是誰等等。這些因素都會(huì)帶來面向端的功能邏輯的差異性。
在這個(gè)問題上,筆者所在團(tuán)隊(duì)負(fù)責(zé)的商品展示業(yè)務(wù)有一定的發(fā)言權(quán),同樣的商品業(yè)務(wù),在C端的展示功能邏輯,深刻受到商品類型、所在行業(yè)、交易形態(tài)、投放場所、面向群體等因素的影響。同時(shí),面向消費(fèi)者端的功能頻繁迭代的屬性,更是加劇并深化了這種矛盾,使其演化成了一種服務(wù)端單一穩(wěn)定與端的差異靈活之間的矛盾,這也是商品展示(商品展示BFF)業(yè)務(wù)系統(tǒng)存在的必然性原因。本文主要在美團(tuán)到店商品展示場景的背景下,介紹面臨的一些問題及解決思路。
2 BFF背景下的核心矛盾
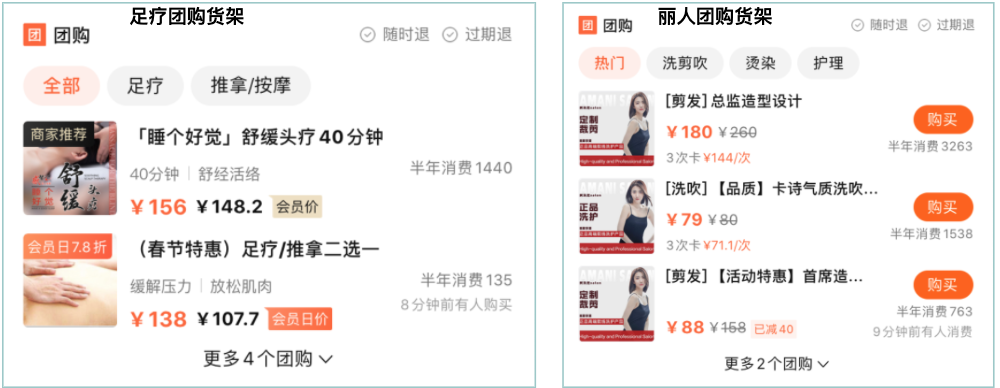
BFF這層的引入是解決服務(wù)端單一穩(wěn)定與端的差異靈活訴求之間的矛盾,這個(gè)矛盾并不是不存在,而是轉(zhuǎn)移了。由原來后端和前端之間的矛盾轉(zhuǎn)移成了BFF和前端之間的矛盾。筆者所在團(tuán)隊(duì)的主要工作,就是和這種矛盾作斗爭。下面以具體的業(yè)務(wù)場景為例,結(jié)合當(dāng)前的業(yè)務(wù)特點(diǎn),說明在BFF的生產(chǎn)模式下,我們所面臨的具體問題。下圖是兩個(gè)不同行業(yè)的團(tuán)購貨架展示模塊,這兩個(gè)模塊我們認(rèn)為是兩個(gè)商品的展示場景,它們是兩套獨(dú)立定義的產(chǎn)品邏輯,并且會(huì)各自迭代。
在業(yè)務(wù)發(fā)展初期,這樣的場景不多。BFF層系統(tǒng)“煙囪式”建設(shè),功能快速開發(fā)上線滿足業(yè)務(wù)的訴求,在這樣的情況下,這種矛盾表現(xiàn)的不明顯。而隨著業(yè)務(wù)發(fā)展,行業(yè)的開拓,形成了許許多多這樣的商品展示功能,矛盾逐漸加劇,主要表現(xiàn)在以下兩個(gè)方面:
業(yè)務(wù)支撐效率:隨著商品展示場景變得越來越多,API呈爆炸趨勢(shì),業(yè)務(wù)支撐效率和人力成線性關(guān)系,系統(tǒng)能力難以支撐業(yè)務(wù)場景的規(guī)模化拓展。 系統(tǒng)復(fù)雜度高:核心功能持續(xù)迭代,內(nèi)部邏輯充斥著 if…else…,代碼過程式編寫,系統(tǒng)復(fù)雜度較高,難以修改和維護(hù)。
那么這些問題是怎么產(chǎn)生的呢?這要結(jié)合“煙囪式”系統(tǒng)建設(shè)的背景和商品展示場景所面臨的業(yè)務(wù),以及系統(tǒng)特點(diǎn)來進(jìn)行理解。
特點(diǎn)一:外部依賴多、場景間取數(shù)存在差異、用戶體驗(yàn)要求高
圖例展示了兩個(gè)不同行業(yè)的團(tuán)購貨架模塊,這樣一個(gè)看似不大的模塊,后端在BFF層要調(diào)用20個(gè)以上的下游服務(wù)才能把數(shù)據(jù)拿全,這是其一。在上面兩個(gè)不同的場景中,需要的數(shù)據(jù)源集合存在差異,而且這種差異普遍存在,這是其二,比如足療團(tuán)購貨架需要的某個(gè)數(shù)據(jù)源,在麗人團(tuán)購貨架上不需要,麗人團(tuán)購貨架需要的某個(gè)數(shù)據(jù)源,足療團(tuán)購貨架不需要。盡管依賴下游服務(wù)多,同時(shí)還要保證C端的用戶體驗(yàn),這是其三。
這幾個(gè)特點(diǎn)給技術(shù)帶來了不小的難題:1)聚合大小難控制,聚合功能是分場景建設(shè)?還是統(tǒng)一建設(shè)?如果分場景建設(shè),必然存在不同場景重復(fù)編寫類似聚合邏輯的問題。如果統(tǒng)一建設(shè),那么一個(gè)大而全的數(shù)據(jù)聚合中必然會(huì)存在無效的調(diào)用。2)聚合邏輯的復(fù)雜性控制問題,在這么多的數(shù)據(jù)源的情況下,不僅要考慮業(yè)務(wù)邏輯怎么寫,還要考慮異步調(diào)用的編排,在代碼復(fù)雜度未能良好控制的情況下,后續(xù)聚合的變更修改將會(huì)是一個(gè)難題。
特點(diǎn)二:展示邏輯多、場景之間存在差異,共性個(gè)性邏輯耦合
我們可以明顯地識(shí)別某一類場景的邏輯是存在共性的,比如團(tuán)單相關(guān)的展示場景。直觀可以看出基本上都是展示團(tuán)單維度的信息,但這只是表象。實(shí)際上在模塊的生成過程中存在諸多的差異,比如以下兩種差異:
字段拼接邏輯差異:比如以上圖中兩個(gè)團(tuán)購貨架的團(tuán)購標(biāo)題為例,同樣是標(biāo)題,在麗人團(tuán)購貨架中的展示規(guī)則是:[類型] + 團(tuán)購標(biāo)題,而在足療團(tuán)購貨架的展示規(guī)則是:團(tuán)購標(biāo)題。 排序過濾邏輯差異:比如同樣是團(tuán)單列表,A場景按照銷量倒排序,B場景按照價(jià)格排序,不同場景的排序邏輯不同。
諸如此類的展示邏輯的差異性還有很多。類似的場景實(shí)際上在內(nèi)部存在很多差異的邏輯,后端如何應(yīng)對(duì)這種差異性是一個(gè)難題,下面是最常見的一種寫法,通過讀取具體的條件字段來做判斷實(shí)現(xiàn)邏輯路由,如下所示:
if(category == "麗人") {
title = "[" + category + "]" + productTitle;
} else if (category == "足療") {
title = productTitle;
}這種方案在功能實(shí)現(xiàn)方面沒有問題,也能夠復(fù)用共同的邏輯。但是實(shí)際上在場景非常多的情況下,將會(huì)有非常多的差異性判斷邏輯疊加在一起,功能一直會(huì)被持續(xù)迭代的情況下,可以想象,系統(tǒng)將會(huì)變得越來越復(fù)雜,越來越難以修改和維護(hù)。
總結(jié):在BFF這層,不同商品展示場景存在差異。在業(yè)務(wù)發(fā)展初期,系統(tǒng)通過獨(dú)立建設(shè)的方式支持業(yè)務(wù)快速試錯(cuò),在這種情況下,業(yè)務(wù)差異性帶來的問題不明顯。而隨著業(yè)務(wù)的不斷發(fā)展,需要搭建及運(yùn)營的場景越來越多,呈規(guī)模化趨勢(shì)。此時(shí),業(yè)務(wù)對(duì)技術(shù)效率提出了更高的要求。在這種場景多、場景間存在差異的背景下,如何滿足場景拓展效率同時(shí)能夠控制系統(tǒng)的復(fù)雜性,就是我們業(yè)務(wù)場景中面臨的核心問題。
3 BFF應(yīng)用模式分析
目前,業(yè)界針對(duì)此類的解決方案主要有兩種模式,一種是后端BFF模式;另一種是前端BFF模式。
3.1 后端BFF模式
后端BFF模式指的是BFF由后端同學(xué)負(fù)責(zé),這種模式目前最廣泛的實(shí)踐是基于GraphQL搭建的后端BFF方案,具體是:后端將展示字段封裝成展示服務(wù),通過GraphQL編排之后暴露給前端使用。如下圖所示:
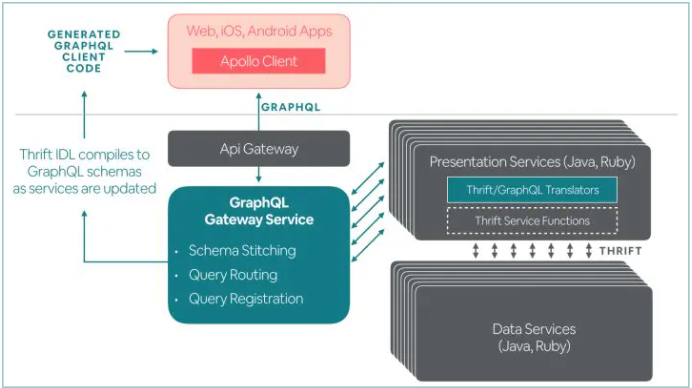
這種模式最大的特性和優(yōu)勢(shì)是,當(dāng)展示字段已經(jīng)存在的情況下,后端不需要關(guān)心前端差異性需求,按需查詢的能力由GraphQL支持。這個(gè)特性可以很好地應(yīng)對(duì)不同場景存在展示字段差異性這個(gè)問題,前端直接基于GraphQL按需查詢數(shù)據(jù)即可,后端不需要變更。同時(shí),借助GraphQL的編排和聚合查詢能力,后端可以將邏輯分解在不同的展示服務(wù)中,因此在一定程度上能夠化解BFF這層的復(fù)雜性。
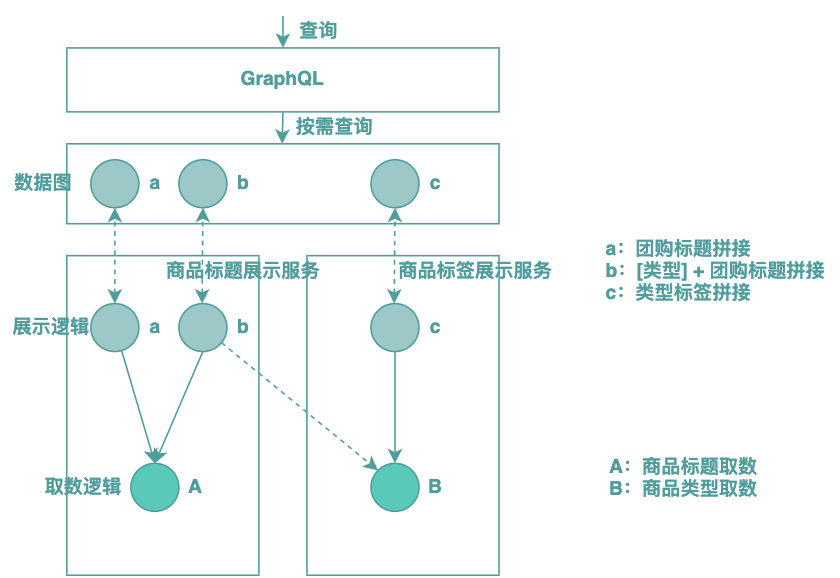
但是基于這種模式,仍然存在幾個(gè)問題:展示服務(wù)顆粒度問題、數(shù)據(jù)圖劃分問題以及字段擴(kuò)散問題,下圖是基于當(dāng)前模式的具體案例:
1)展示服務(wù)顆粒度設(shè)計(jì)問題
這種方案要求展示邏輯和取數(shù)邏輯封裝在一個(gè)模塊中,形成一個(gè)展示服務(wù)(Presentation Service),如上圖所示。而實(shí)際上展示邏輯和取數(shù)邏輯是多對(duì)多的關(guān)系,還是以前文提到的例子說明:
背景:有兩個(gè)展示服務(wù),分別封裝了商品標(biāo)題和商品標(biāo)簽的查詢能力。
情景:此時(shí)PM提了一個(gè)需求,希望商品在某個(gè)場景的標(biāo)題以“[類型]+商品標(biāo)題”的形式展示,此時(shí)商品標(biāo)題的拼接依賴類型數(shù)據(jù),而此時(shí)類型數(shù)據(jù)商品標(biāo)簽展示服務(wù)中已經(jīng)調(diào)用了。
問題:商品標(biāo)題展示服務(wù)自己調(diào)用類型數(shù)據(jù)還是將兩個(gè)展示服務(wù)合并到一起?
以上描述的問題的是展示服務(wù)顆粒度把控的問題,我們可以懷疑上述的示例是不是因?yàn)檎故痉?wù)的顆粒度過小?那么反過來看一看,如果將兩個(gè)服務(wù)合并到一起,那么勢(shì)必又會(huì)存在冗余。這是展示服務(wù)設(shè)計(jì)的難點(diǎn),核心原因在于,展示邏輯和取數(shù)邏輯本身是多對(duì)多的關(guān)系,結(jié)果卻被設(shè)計(jì)放在了一起。
2)數(shù)據(jù)圖劃分問題
通過GraphQL將多個(gè)展示服務(wù)的數(shù)據(jù)聚合到一張圖(GraphQL Schema)中,形成一個(gè)數(shù)據(jù)視圖,需要數(shù)據(jù)的時(shí)候只要數(shù)據(jù)在圖中,就可以基于Query按需查詢。那么問題來了,這個(gè)圖應(yīng)該怎么組織?是一張圖還是多張圖?圖過大的話,勢(shì)必帶來復(fù)雜的數(shù)據(jù)關(guān)系維護(hù)問題,圖過小則將會(huì)降低方案本身的價(jià)值。
3)展示服務(wù)內(nèi)部復(fù)雜性 + 模型擴(kuò)散問題
上文提到過一個(gè)商品標(biāo)題的展示存在不同拼接邏輯的情況,在商品展示場景,這種邏輯特別普遍。比如同樣是價(jià)格,A行業(yè)展示優(yōu)惠后價(jià)格,B行業(yè)展示優(yōu)惠前價(jià)格;同樣是標(biāo)簽位置,C行業(yè)展示服務(wù)時(shí)長,而D行業(yè)展示商品特性等。
那么問題來了,展示模型如何設(shè)計(jì)?以標(biāo)題字段為例,是在展示模型上放個(gè)title字段就可以,還是分別放個(gè)title和titleWithCategory?如果是前者那么服務(wù)內(nèi)部必然會(huì)存在if…else…這種邏輯,用于區(qū)分title的拼接方式,這同樣會(huì)導(dǎo)致展示服務(wù)內(nèi)部的復(fù)雜性。如果是多個(gè)字段,那么可以想象,展示服務(wù)的模型字段也將會(huì)不斷擴(kuò)散。
總結(jié):后端BFF模式能夠在一定程度上化解后端邏輯的復(fù)雜性,同時(shí)提供一個(gè)展示字段的復(fù)用機(jī)制。但是仍然存在未決問題,如展示服務(wù)的顆粒度設(shè)計(jì)問題,數(shù)據(jù)圖的劃分問題,以及展示服務(wù)內(nèi)部的復(fù)雜性和字段擴(kuò)散問題。目前這種模式實(shí)踐的代表有Facebook、愛彼迎、eBay、愛奇藝、攜程、去哪兒等等。
3.2 前端BFF模式
前端BFF模式在Sam Newman的文章中的"And Autonomy"部分有特別的介紹,指的是BFF本身由前端團(tuán)隊(duì)自己負(fù)責(zé),如下示意圖所示:
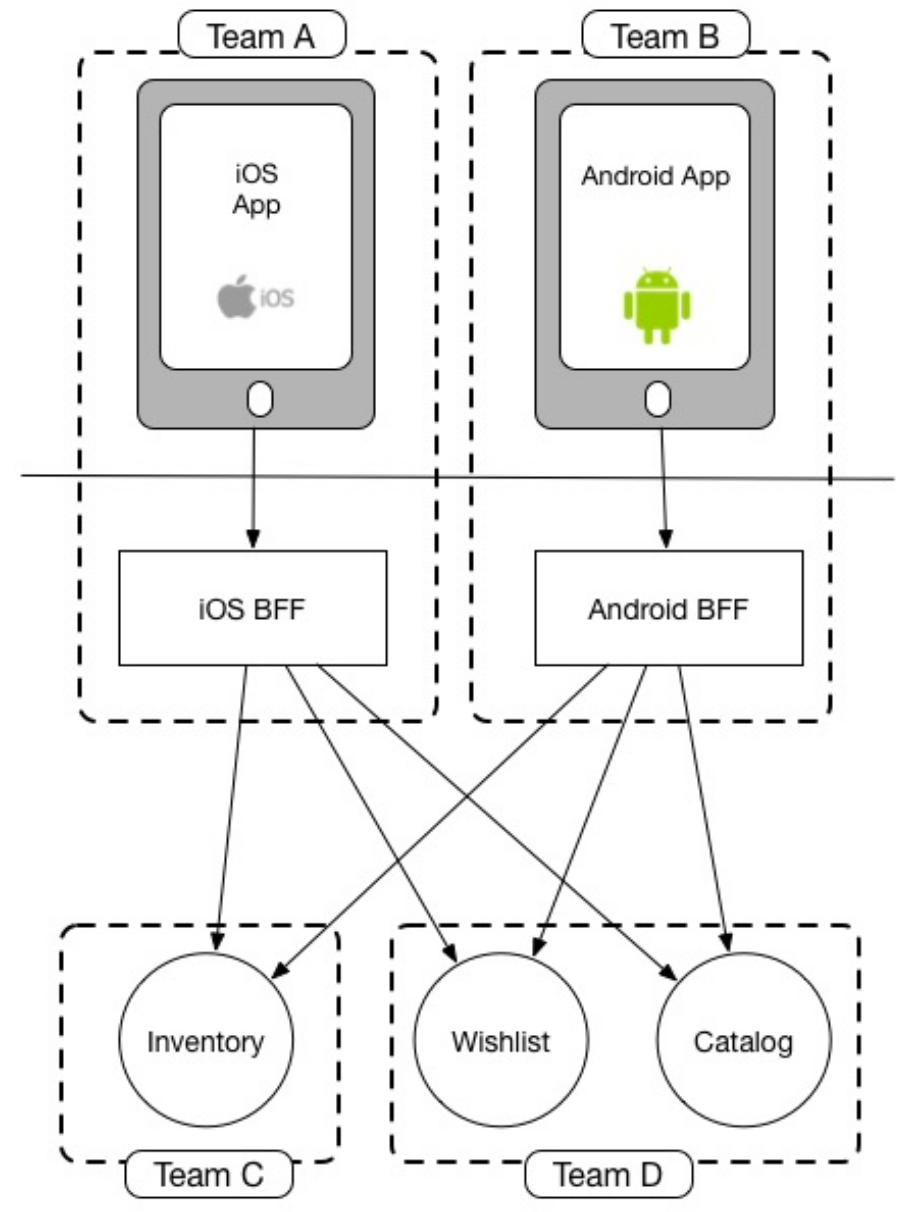
這種模式的理念是,本來能一個(gè)團(tuán)隊(duì)交付的需求,沒必要拆成兩個(gè)團(tuán)隊(duì),兩個(gè)團(tuán)隊(duì)本身帶來較大的溝通協(xié)作成本。本質(zhì)上,也是一種將“敵我矛盾”轉(zhuǎn)化為“人民內(nèi)部矛盾”的思路。前端完全接手BFF的開發(fā)工作,實(shí)現(xiàn)數(shù)據(jù)查詢的自給自足,大大減少了前后端的協(xié)作成本。但是這種模式?jīng)]有提到我們關(guān)心的一些核心問題,如:復(fù)雜性如何應(yīng)對(duì)、差異性如何應(yīng)對(duì)、展示模型如何設(shè)計(jì)等等問題。除此之外,這種模式也存在一些前提條件及弊端,比如較為完備的前端基礎(chǔ)設(shè)施;前端不僅僅需要關(guān)心渲染、還需要了解業(yè)務(wù)邏輯等。
總結(jié):前端BFF模式通過前端自主查詢和使用數(shù)據(jù),從而達(dá)到降低跨團(tuán)隊(duì)協(xié)作的成本,提升BFF研發(fā)效率的效果。目前這種模式的實(shí)踐代表是阿里巴巴。
4 基于GraphQL及元數(shù)據(jù)的信息聚合架構(gòu)設(shè)計(jì)
4.1 整體思路
通過對(duì)后端BFF和前端BFF兩種模式的分析,我們最終選擇后端BFF模式,前端BFF這個(gè)方案對(duì)目前的研發(fā)模式影響較大,不僅需要大量的前端資源,而且需要建設(shè)完善的前端基礎(chǔ)設(shè)施,方案實(shí)施成本比較高昂。
前文提到的后端GraphQL BFF模式代入我們的具體場景雖然存在一些問題,但是總體有非常大的參考價(jià)值,比如展示字段的復(fù)用思路、數(shù)據(jù)的按需查詢思路等等。在商品展示場景中,有80%的工作集中在數(shù)據(jù)的聚合和集成部分,并且這部分具有很強(qiáng)的復(fù)用價(jià)值,因此信息的查詢和聚合是我們面臨的主要矛盾。因此,我們的思路是:基于GraphQL+后端BFF方案改進(jìn),實(shí)現(xiàn)取數(shù)邏輯和展示邏輯的可沉淀、可組合、可復(fù)用,整體架構(gòu)如下示意圖所示:
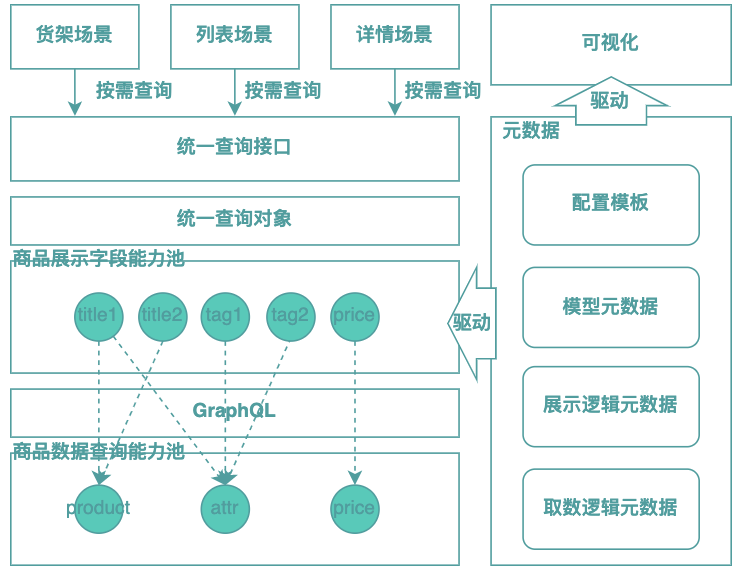
從上圖可看出,與傳統(tǒng)GraphQL BFF方案最大的差別在于我們將GraphQL下放至數(shù)據(jù)聚合部分,由于數(shù)據(jù)來源于商品領(lǐng)域,領(lǐng)域是相對(duì)穩(wěn)定的,因此數(shù)據(jù)圖規(guī)模可控且相對(duì)穩(wěn)定。除此之外,整體架構(gòu)的核心設(shè)計(jì)還包括以下三個(gè)方面:1)取數(shù)展示分離;2)查詢模型歸一;3)元數(shù)據(jù)驅(qū)動(dòng)架構(gòu)。
我們通過取數(shù)展示分離解決展示服務(wù)顆粒度問題,同時(shí)使得展示邏輯和取數(shù)邏輯可沉淀、可復(fù)用;通過查詢模型歸一化設(shè)計(jì)解決展示字段擴(kuò)散的問題;通過元數(shù)據(jù)驅(qū)動(dòng)架構(gòu)實(shí)現(xiàn)能力的可視化,業(yè)務(wù)組件編排執(zhí)行的自動(dòng)化,這能夠讓業(yè)務(wù)開發(fā)同學(xué)聚焦于業(yè)務(wù)邏輯的本身。下面將針對(duì)這三個(gè)部分逐一展開介紹。
4.2 核心設(shè)計(jì)
4.2.1 取數(shù)展示分離
上文提到,在商品展示場景中,展示邏輯和取數(shù)邏輯是多對(duì)多的關(guān)系,而傳統(tǒng)的基于GraphQL的后端BFF實(shí)踐方案把它們封裝在一起,這是導(dǎo)致展示服務(wù)顆粒度難以設(shè)計(jì)的根本原因。思考一下取數(shù)邏輯和展示邏輯的關(guān)注點(diǎn)是什么?取數(shù)邏輯關(guān)注怎么查詢和聚合數(shù)據(jù),而展示邏輯關(guān)注怎么加工生成需要的展示字段,它們的關(guān)注點(diǎn)不一樣,放在一起也會(huì)增加展示服務(wù)的復(fù)雜性。因此,我們的思路是將取數(shù)邏輯和展示邏輯分離開來,單獨(dú)封裝成邏輯單元,分別叫取數(shù)單元和展示單元。在取數(shù)展示分離之后,GraphQL也隨之下沉,用于實(shí)現(xiàn)數(shù)據(jù)的按需聚合,如下圖所示:
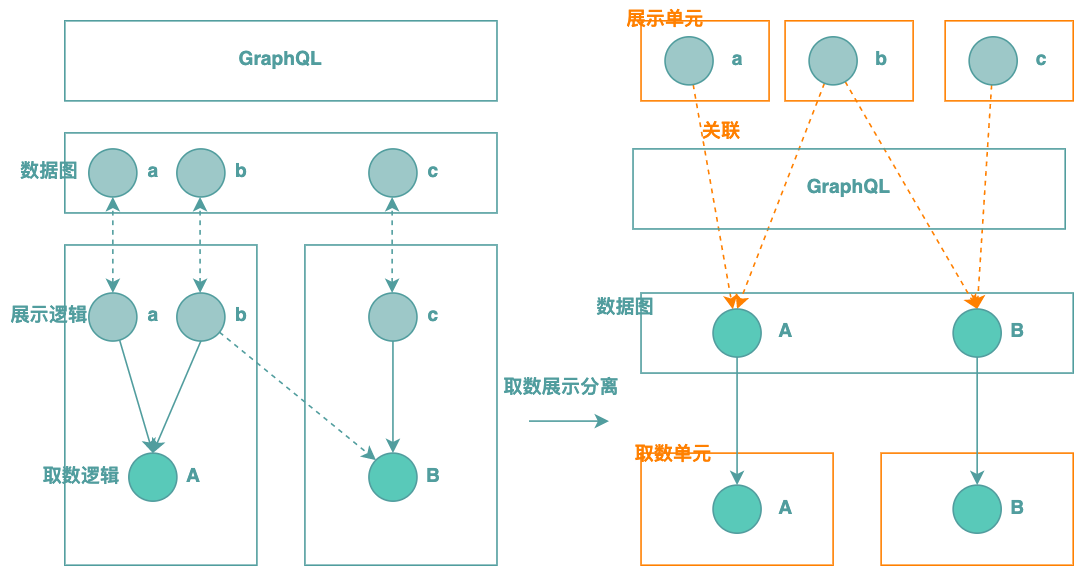
那么取數(shù)和展示邏輯的封裝顆粒度是怎么樣的呢?不能太小也不能太大,在顆粒度的設(shè)計(jì)上,我們有兩個(gè)核心考量:1)復(fù)用,展示邏輯和取數(shù)邏輯在商品展示場景中,都是可以被復(fù)用的資產(chǎn),我們希望它們能沉淀下來,被單獨(dú)按需使用;2)簡單,保持簡單,這樣容易修改和維護(hù)。基于這兩點(diǎn)考慮,顆粒度的定義如下:
取數(shù)單元:盡量只封裝1個(gè)外部數(shù)據(jù)源,同時(shí)負(fù)責(zé)對(duì)外部數(shù)據(jù)源返回的模型進(jìn)行簡化,這部分生成的模型我們稱之為取數(shù)模型。 展示單元:盡量只封裝1個(gè)展示字段的加工邏輯。
分開的好處是簡單且可被組合使用,那么具體如何實(shí)現(xiàn)組合使用呢?我們的思路是通過元數(shù)據(jù)來描述它們之間的關(guān)系,基于元數(shù)據(jù)由統(tǒng)一的執(zhí)行框架來關(guān)聯(lián)運(yùn)行,具體設(shè)計(jì)下文會(huì)展開介紹。通過取數(shù)和展示的分離,元數(shù)據(jù)的關(guān)聯(lián)和運(yùn)行時(shí)的組合調(diào)用,可以保持邏輯單元的簡單,同時(shí)又滿足復(fù)用訴求,這也很好地解決了傳統(tǒng)方案中存在的展示服務(wù)的顆粒度問題。
4.2.2 查詢模型歸一
展示單元的加工結(jié)果通過什么樣的接口透出呢?接下來,我們介紹一下查詢接口設(shè)計(jì)的問題。
1)查詢接口設(shè)計(jì)的難點(diǎn)
常見查詢接口的設(shè)計(jì)模式有以下兩種:
強(qiáng)類型模式:強(qiáng)類型模式指的是查詢接口返回的是POJO對(duì)象,每一個(gè)查詢結(jié)果對(duì)應(yīng)POJO中的一個(gè)明確的具有特定業(yè)務(wù)含義的字段。 弱類型模式:弱類型模式指的是查詢結(jié)果以K-V或JSON模式返回,沒有明確的靜態(tài)字段。
以上兩種模式在業(yè)界都有廣泛應(yīng)用,且它們都有明確的優(yōu)缺點(diǎn)。強(qiáng)類型模式對(duì)開發(fā)者友好,但是業(yè)務(wù)是不斷迭代的,與此同時(shí),系統(tǒng)沉淀的展示單元會(huì)不斷豐富,在這樣的情況下,接口返回的DTO中的字段將會(huì)愈來愈多,每次新功能的支持,都要伴隨著接口查詢模型的修改,JAR版本的升級(jí)。而JAR的升級(jí)涉及數(shù)據(jù)提供方和數(shù)據(jù)消費(fèi)兩方,存在明顯效率問題。另外,可以想象,查詢模型的不斷迭代,最終將會(huì)包括成百上千個(gè)字段,難以維護(hù)。
而弱類型模式恰好可以彌補(bǔ)這一缺點(diǎn),但是弱類型模式對(duì)于開發(fā)者來說非常不友好,接口查詢模型中有哪些查詢結(jié)果對(duì)于開發(fā)者來說在開發(fā)的過程中完全沒有感覺,但是程序員的天性就是喜歡通過代碼去理解邏輯,而非配置和文檔。其實(shí),這兩種接口設(shè)計(jì)模式都存在著一個(gè)共性問題——缺少抽象,下面兩節(jié),我們將介紹在接口返回的查詢模型設(shè)計(jì)方面的抽象思路及框架能力支持。
2)查詢模型歸一化設(shè)計(jì)
回到商品展示場景中,一個(gè)展示字段有多種不同的實(shí)現(xiàn),如商品標(biāo)題的兩種不同實(shí)現(xiàn)方式:1)商品標(biāo)題;2)[類目]+商品標(biāo)題。商品標(biāo)題和這兩種展示邏輯的關(guān)系本質(zhì)上是一種抽象-具體的關(guān)系。識(shí)別這個(gè)關(guān)鍵點(diǎn),思路就明了了,我們的思路是對(duì)查詢模型做抽象。查詢模型上都是抽象的展示字段,一個(gè)展示字段對(duì)應(yīng)多個(gè)展示單元,如下圖所示:
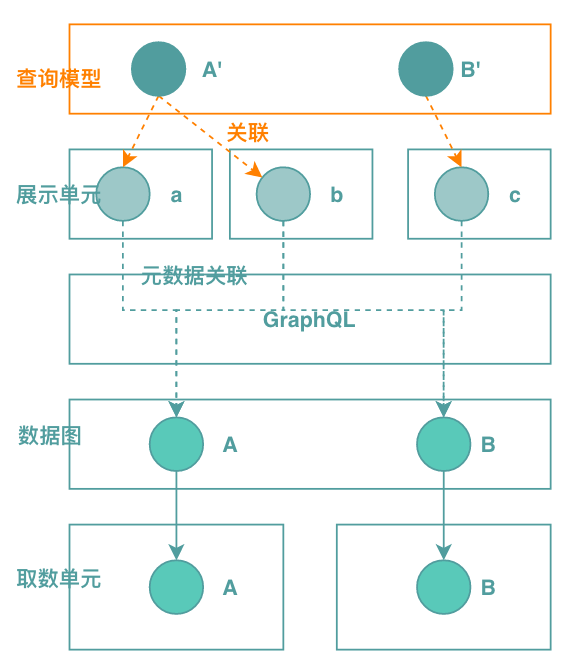
在實(shí)現(xiàn)層面,同樣基于元數(shù)據(jù)描述展示字段和展示單元之間的關(guān)系,基于以上的設(shè)計(jì)思路,可以在一定程度上減緩模型的擴(kuò)散,但是還不能避免擴(kuò)展。比如除了價(jià)格、庫存、銷量等每個(gè)商品都有的標(biāo)準(zhǔn)屬性之外,不同的商品類型一般還會(huì)有這個(gè)商品特有的屬性。比如密室主題拼場商品才有“幾人拼”這樣的描述屬性,這種字段本身抽象的意義不大,且放在商品查詢模型中作為一個(gè)單獨(dú)的字段會(huì)導(dǎo)致模型擴(kuò)張,針對(duì)這類問題,我們的解決思路是引入擴(kuò)展屬性,擴(kuò)展屬性專門承載這類非標(biāo)準(zhǔn)的字段。通過標(biāo)準(zhǔn)字段 + 擴(kuò)展屬性的方式建立查詢模型,能夠較好地解決字段擴(kuò)散的問題。
4.2.3 元數(shù)據(jù)驅(qū)動(dòng)架構(gòu)
到目前為止,我們定義了如何分解業(yè)務(wù)邏輯單元以及如何設(shè)計(jì)查詢模型,并提到用元數(shù)據(jù)描述它們之間的關(guān)系。基于以上定義實(shí)現(xiàn)的業(yè)務(wù)邏輯及模型,都具備很強(qiáng)的復(fù)用價(jià)值,可以作為業(yè)務(wù)資產(chǎn)沉淀下來。那么,為什么用元數(shù)據(jù)描述業(yè)務(wù)功能及模型之間的關(guān)系呢?
我們引入元數(shù)據(jù)描述主要有兩個(gè)目的:1)代碼邏輯的自動(dòng)編排,通過元數(shù)據(jù)描述業(yè)務(wù)邏輯之間的關(guān)聯(lián)關(guān)系,運(yùn)行時(shí)可以自動(dòng)基于元數(shù)據(jù)實(shí)現(xiàn)邏輯之間的關(guān)聯(lián)執(zhí)行,從而可以消除大量的人工邏輯編排代碼;2)業(yè)務(wù)功能的可視化,元數(shù)據(jù)本身描述了業(yè)務(wù)邏輯所提供的功能,如下面兩個(gè)示例:
團(tuán)單基礎(chǔ)售價(jià)字符串展示,例:30元。
團(tuán)單市場價(jià)展示字段,例:100元。
這些元數(shù)據(jù)上報(bào)到系統(tǒng)中,可以用于展示當(dāng)前系統(tǒng)所提供的功能。通過元數(shù)據(jù)描述組件及組件之間關(guān)聯(lián)關(guān)系,通過框架解析元數(shù)據(jù)自動(dòng)進(jìn)行業(yè)務(wù)組件的調(diào)用執(zhí)行,形成了如下的元數(shù)據(jù)架構(gòu):
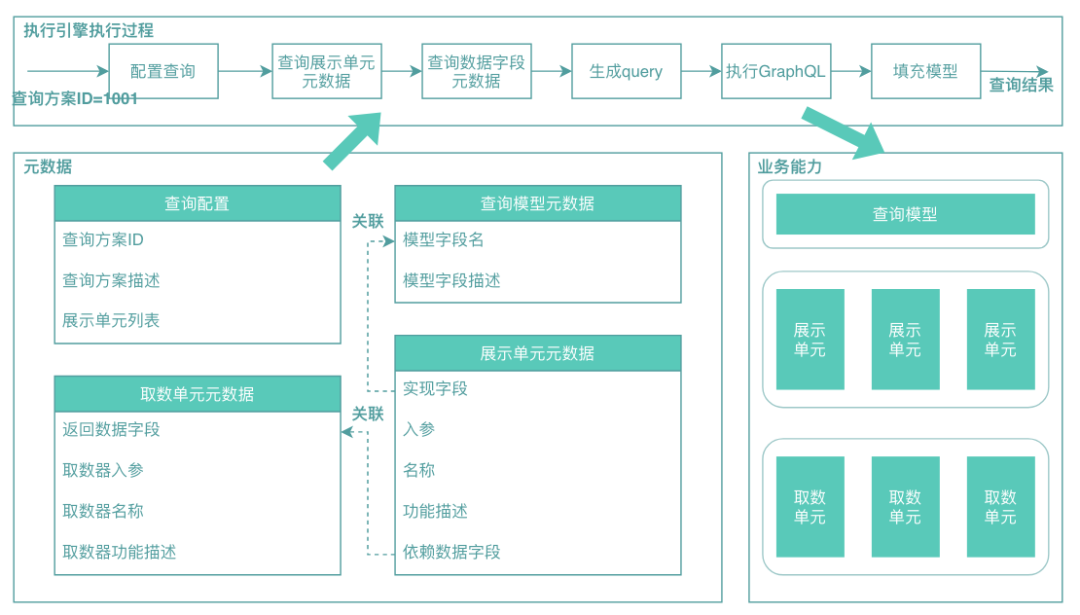
整體架構(gòu)由三個(gè)核心部分組成:
業(yè)務(wù)能力:標(biāo)準(zhǔn)的業(yè)務(wù)邏輯單元,包括取數(shù)單元、展示單元和查詢模型,這些都是關(guān)鍵的可復(fù)用資產(chǎn)。 元數(shù)據(jù):描述業(yè)務(wù)功能(如:展示單元、取數(shù)單元)以及業(yè)務(wù)功能之間的關(guān)聯(lián)關(guān)系,比如展示單元依賴的數(shù)據(jù),展示單元映射的展示字段等。 執(zhí)行引擎:負(fù)責(zé)消費(fèi)元數(shù)據(jù),并基于元數(shù)據(jù)對(duì)業(yè)務(wù)邏輯進(jìn)行調(diào)度和執(zhí)行。
通過以上三個(gè)部分有機(jī)的組合在一起,形成了一個(gè)元數(shù)據(jù)驅(qū)動(dòng)風(fēng)格的架構(gòu)。
5 針對(duì)GraphQL的優(yōu)化實(shí)踐
5.1 使用簡化
1)GraphQL直接使用問題
引入GraphQL,會(huì)引入一些額外的復(fù)雜性,比如會(huì)涉及到GraphQL帶來的一些概念如:Schema、RuntimeWiring,下面是基于GraphQL原生Java框架的開發(fā)過程:

這些概念對(duì)于未接觸過GraphQL的同學(xué)來說,增加了學(xué)習(xí)和理解的成本,而這些概念和業(yè)務(wù)領(lǐng)域通常沒有什么關(guān)系。而我們僅僅希望使用GraphQL的按需查詢特性,卻被GraphQL本身拖累了,業(yè)務(wù)開發(fā)同學(xué)的關(guān)注點(diǎn)應(yīng)該聚焦在業(yè)務(wù)邏輯本身才對(duì),這個(gè)問題如何解決呢?
著名計(jì)算機(jī)科學(xué)家David Wheeler說了一句名言,"All problems in computer science can be solved by another level of indirection"。沒有加一層解決不了的問題,本質(zhì)上是需要有人來對(duì)這事負(fù)責(zé),因此我們?cè)谠鶪raphQL之上增加了一層執(zhí)行引擎層來解決這些問題,目標(biāo)是屏蔽GraphQL的復(fù)雜性,讓開發(fā)人員只需要關(guān)注業(yè)務(wù)邏輯。
2)取數(shù)接口標(biāo)準(zhǔn)化
首先要簡化數(shù)據(jù)的接入,原生的DataFetcher和DataLoader都是處在一個(gè)比較高的抽象層次,缺少業(yè)務(wù)語義,而在查詢場景,我們能夠歸納出,所有的查詢都屬于以下三種模式:
1查1:根據(jù)一個(gè)條件查詢一個(gè)結(jié)果。 1查N:根據(jù)一個(gè)條件查詢多個(gè)結(jié)果。 N查N:一查一或一查多的批量版本。
由此,我們對(duì)查詢接口進(jìn)行了標(biāo)準(zhǔn)化,業(yè)務(wù)開發(fā)同學(xué)基于場景判斷是那種,按需選擇使用即可,取數(shù)接口標(biāo)準(zhǔn)化設(shè)計(jì)如下:
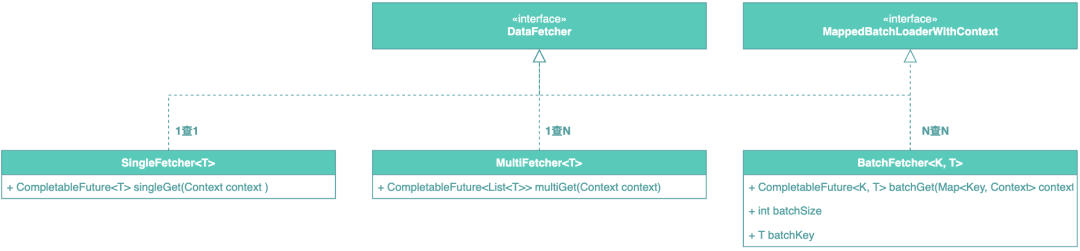
業(yè)務(wù)開發(fā)同學(xué)按需選擇所需要使用的取數(shù)器,通過泛型指定結(jié)果類型,1查1和1查N比較簡單,N查N我們對(duì)其定義為批量查詢接口,用于滿足"N+1"的場景,其中batchSize字段用于指定分片大小,batchKey用于指定查詢Key,業(yè)務(wù)開發(fā)只需要指定參數(shù),其他的框架會(huì)自動(dòng)處理。除此之外,我們還約束了返回結(jié)果必須是CompleteFuture,用于滿足聚合查詢的全鏈路異步化。
3)聚合編排自動(dòng)化
取數(shù)接口標(biāo)準(zhǔn)化使得數(shù)據(jù)源的語義更清晰,開發(fā)過程按需選擇即可,簡化了業(yè)務(wù)的開發(fā)。但是此時(shí)業(yè)務(wù)開發(fā)同學(xué)寫好Fetcher之后,還需要去另一個(gè)地方去寫Schema,而且寫完Schema還要再寫Schema和Fetcher的映射關(guān)系,業(yè)務(wù)開發(fā)更享受寫代碼的過程,不太愿意寫完代碼還要去另外一個(gè)地方取配置,并且同時(shí)維護(hù)代碼和對(duì)應(yīng)配置也提高了出錯(cuò)的可能性,能否將這些冗雜的步驟移除掉?
Schema和RuntimeWiring本質(zhì)上是想描述某些信息,如果這些信息換一種方式描述是不是也可以。我們的優(yōu)化思路是,在業(yè)務(wù)開發(fā)過程中標(biāo)記注解,通過注解標(biāo)注的元數(shù)據(jù)描述這些信息,其他的事情交給框架來做。解決思路示意圖如下:

5.2 性能優(yōu)化
5.2.1 GraphQL性能問題
雖然GraphQL已經(jīng)開源了,但是Facebook只開源了相關(guān)標(biāo)準(zhǔn),并沒有給出解決方案。GraphQL-Java框架是由社區(qū)貢獻(xiàn)的,基于開源的GraphQL-Java作為按需查詢引擎的方案,我們發(fā)現(xiàn)了GraphQL應(yīng)用方面的一些問題,這些問題有部分是由于使用姿勢(shì)不當(dāng)所導(dǎo)致的,也有部分是GraphQL本身實(shí)現(xiàn)的問題,比如我們遇到的幾個(gè)典型的問題:
耗CPU的查詢解析,包括 Schema的解析和Query的解析。當(dāng)查詢模型比較復(fù)雜特別是存在大列表時(shí)候的延時(shí)問題。 基于反射的模型轉(zhuǎn)換CPU消耗問題。 DataLoader的層級(jí)調(diào)度問題。
于是,我們對(duì)使用方式和框架做了一些優(yōu)化與改造,以解決上面列舉的問題。本章著重介紹我們?cè)贕raphQL-Java方面的優(yōu)化和改造思路。
5.2.2 GraphQL編譯優(yōu)化
1)GraphQL語言原理概述
GraphQL是一種查詢語言,目的是基于直觀和靈活的語法構(gòu)建客戶端應(yīng)用程序,用于描述其數(shù)據(jù)需求和交互。GraphQL屬于一種領(lǐng)域特定語言(DSL),而我們所使用的GraphQL-Java客戶端在語言編譯層面是基于ANTLR 4實(shí)現(xiàn)的,ANTLR 4是一種基于Java編寫的語言定義和識(shí)別工具,Antlr是一種元語言(Meta-Language),它們的關(guān)系如下:
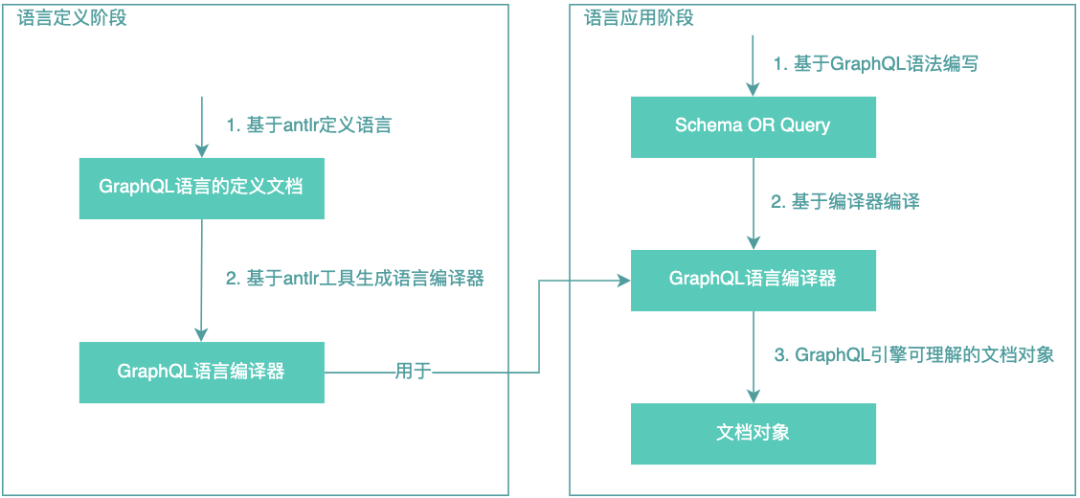
GraphQL執(zhí)行引擎所接受的Schema及Query都是基于GraphQL定義的語言所表達(dá)的內(nèi)容,GraphQL執(zhí)行引擎不能直接理解GraphQL,在執(zhí)行之前必須由GraphQL編譯器翻譯成GraphQL執(zhí)行引擎可理解的文檔對(duì)象。而GraphQL編譯器是基于Java的,經(jīng)驗(yàn)表明在大流量場景實(shí)時(shí)解釋的情況下,這部分代碼將會(huì)成為CPU熱點(diǎn),而且還占用響應(yīng)延遲,Schema或Query越復(fù)雜,性能損耗越明顯。
2)Schema及Query編譯緩存
Schema表達(dá)的是數(shù)據(jù)視圖和取數(shù)模型同構(gòu),相對(duì)穩(wěn)定,個(gè)數(shù)也不多,在我們的業(yè)務(wù)場景一個(gè)服務(wù)也就一個(gè)。因此,我們的做法是在啟動(dòng)的時(shí)候就將基于Schema構(gòu)造的GraphQL執(zhí)行引擎構(gòu)造好,作為單例緩存下來。對(duì)于Query來說,每個(gè)場景的Query有些差異,因此Query的解析結(jié)果不能作為單例,我們的做法是實(shí)現(xiàn)PreparsedDocumentProvider接口,基于Query作為Key將Query編譯結(jié)果緩存下來。如下圖所示:

5.2.3 GraphQL執(zhí)行引擎優(yōu)化
1)GraphQL執(zhí)行機(jī)制及問題
我們先一起了解一下GraphQL-Java執(zhí)行引擎的運(yùn)行機(jī)制是怎么樣的。假設(shè)在執(zhí)行策略上我們選取的是AsyncExecutionStrategy,來看看GraphQL執(zhí)行引擎的執(zhí)行過程:

以上時(shí)序圖做了些簡化,去除了一些與重點(diǎn)無關(guān)的信息,AsyncExecutionStrategy的execute方法是對(duì)象執(zhí)行策略的異步化模式實(shí)現(xiàn),是查詢執(zhí)行的起點(diǎn),也是根節(jié)點(diǎn)查詢的入口,AsyncExecutionStrategy對(duì)對(duì)象的多個(gè)字段的查詢邏輯,采取的是循環(huán)+異步化的實(shí)現(xiàn)方式,我們從AsyncExecutionStrategy的execute方法觸發(fā),理解GraphQL查詢過程如下:
調(diào)用當(dāng)前字段所綁定的 DataFetcher的get方法,如果字段沒有綁定DataFetcher,則通過默認(rèn)的PropertyDataFetcher查詢字段,PropertyDataFetcher的實(shí)現(xiàn)是基于反射從源對(duì)象中讀取查詢字段。將從 DataFetcher查詢得到結(jié)果包裝成CompletableFuture,如果結(jié)果本身是CompletableFuture,那么不會(huì)包裝。結(jié)果 CompletableFuture完成之后,調(diào)用completeValue,基于結(jié)果類型分別處理。如果查詢結(jié)果是列表類型,那么會(huì)對(duì)列表類型進(jìn)行遍歷,針對(duì)每個(gè)元素在遞歸執(zhí)行 completeValue。如果結(jié)果類型是對(duì)象類型,那么會(huì)對(duì)對(duì)象執(zhí)行 execute,又回到了起點(diǎn),也就是AsyncExecutionStrategy的execute。
以上是GraphQL的執(zhí)行過程,這個(gè)過程有什么問題呢?下面基于圖上的標(biāo)記順序一起看看GraphQL在我們的業(yè)務(wù)場景中應(yīng)用和實(shí)踐所遇到的問題,這些問題不代表在其他場景也是問題,僅供參考:
問題1:PropertyDataFetcherCPU熱點(diǎn)問題,PropertyDataFetcher在整個(gè)查詢過程中屬于熱點(diǎn)代碼,而其本身的實(shí)現(xiàn)也有一些優(yōu)化空間,在運(yùn)行時(shí)PropertyDataFetcher的執(zhí)行會(huì)成為CPU熱點(diǎn)。(具體問題可參考GitHub上的commit和Conversion:https://github.com/graphql-java/graphql-java/pull/1815)
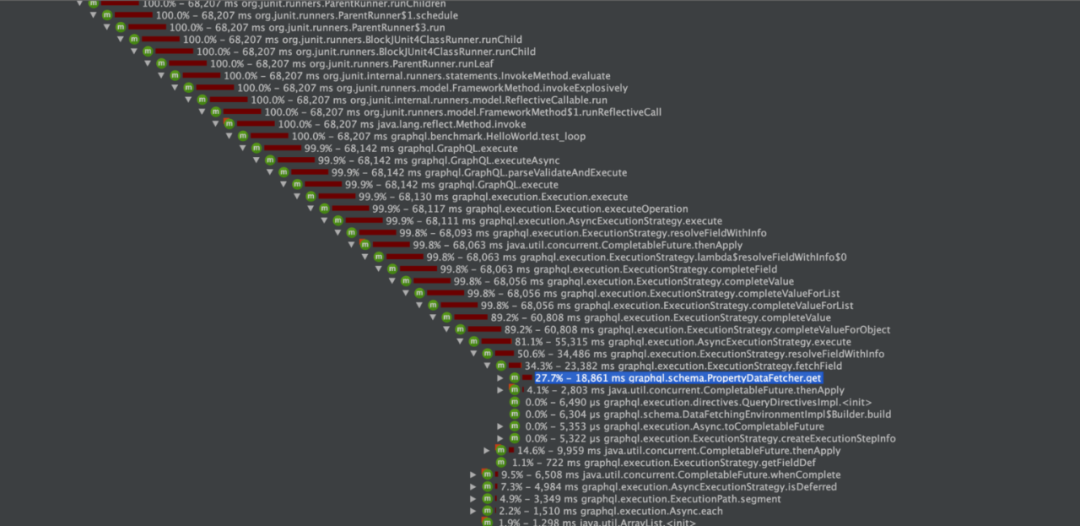 圖16 PropertyDataFetcher成為CPU熱點(diǎn)
圖16 PropertyDataFetcher成為CPU熱點(diǎn)
問題2:列表的計(jì)算耗時(shí)問題,列表計(jì)算是循環(huán)的,對(duì)于查詢結(jié)果中存在大列表的場景,此時(shí)循環(huán)會(huì)造成整體查詢明顯的延遲。我們舉個(gè)具體的例子,假設(shè)查詢結(jié)果中存在一個(gè)列表大小是1000,每個(gè)元素的處理是0.01ms,那么總體耗時(shí)就是10ms,基于GraphQL的查機(jī)制,這個(gè)10ms會(huì)阻塞整個(gè)鏈路。
2)類型轉(zhuǎn)換優(yōu)化
通過GraphQL查詢引擎拿到的GraphQL模型,和業(yè)務(wù)實(shí)現(xiàn)的DataFetcher返回的取數(shù)模型是同構(gòu),但是所有字段的類型都會(huì)被轉(zhuǎn)換成GraphQL內(nèi)部類型。PropertyDataFetcher之所以會(huì)成為CPU熱點(diǎn),問題就在于這個(gè)模型轉(zhuǎn)換過程,業(yè)務(wù)定義的模型到GraphQL類型模型轉(zhuǎn)換過程示意圖如下圖所示:
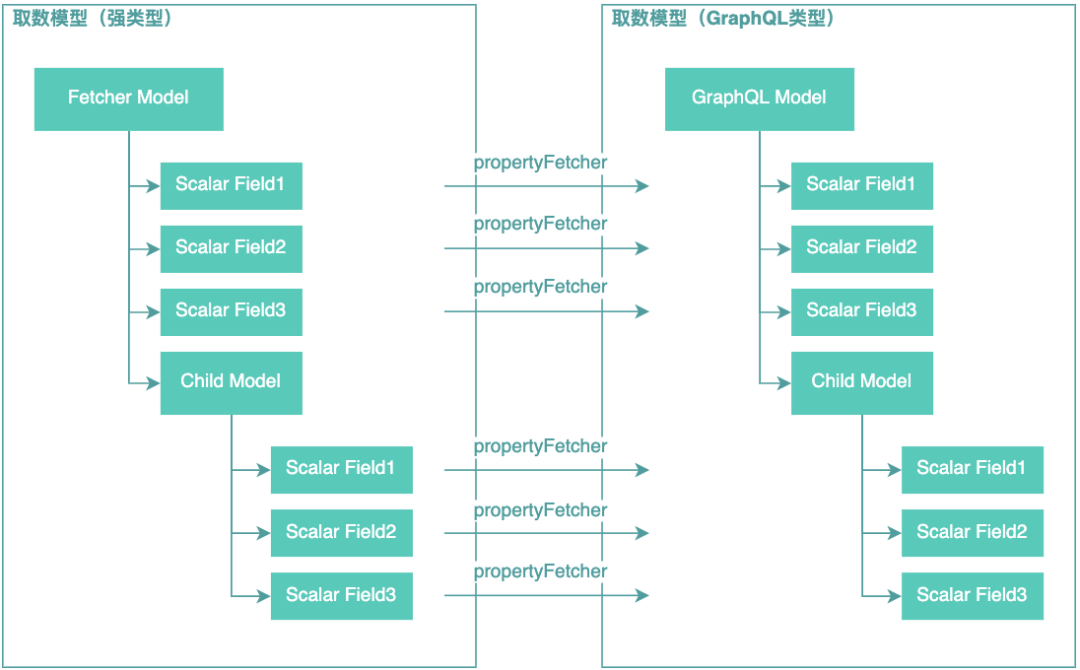
當(dāng)查詢結(jié)果模型中的字段非常多的時(shí)候,比如上萬個(gè),意味著每次查詢有上萬次的PropertyDataFetcher操作,實(shí)際就反映到了CPU熱點(diǎn)問題上,這個(gè)問題我們的解決思路是保持原有業(yè)務(wù)模型不變,將非PropertyDataFetcher查詢的結(jié)果反過來填充到業(yè)務(wù)模型上。如下示意圖所示:
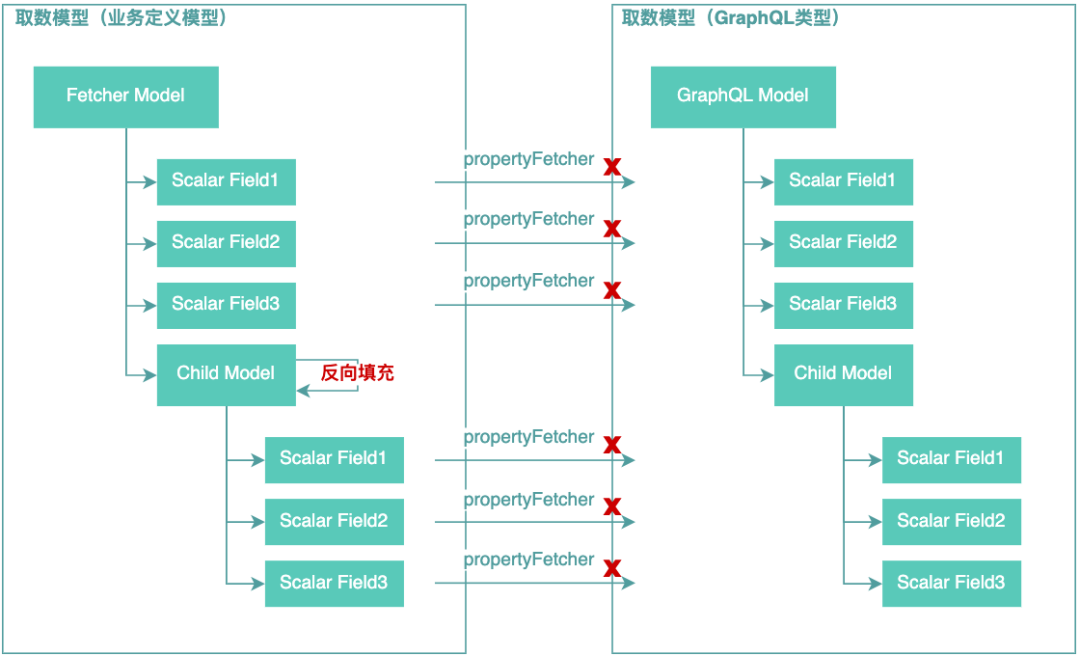
基于這個(gè)思路,我們通過GraphQL執(zhí)行引擎拿到的結(jié)果就是業(yè)務(wù)Fetcher返回的對(duì)象模型,這樣不僅僅解決了因字段反射轉(zhuǎn)換帶來的CPU熱點(diǎn)問題,同時(shí)對(duì)于業(yè)務(wù)開發(fā)來說增加了友好性。因?yàn)镚raphQL模型類似JSON模型,這種模型是缺少業(yè)務(wù)類型的,業(yè)務(wù)開發(fā)直接使用起來非常麻煩。以上優(yōu)化在一個(gè)場景上試點(diǎn)測(cè)試,結(jié)果顯示該場景的平均響應(yīng)時(shí)間縮短1.457ms,平均99線縮短5.82ms,平均CPU利用率降低約12%。
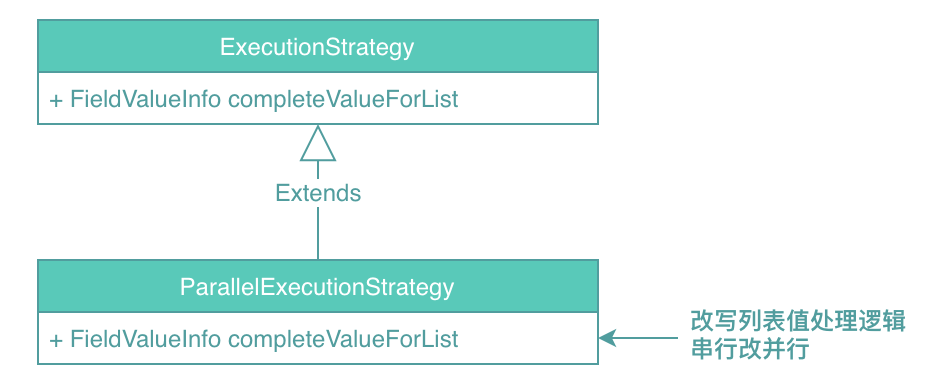
3)列表計(jì)算優(yōu)化
當(dāng)列表元素比較多的時(shí)候,默認(rèn)的單線程遍歷列表元素計(jì)算的方式所帶來的延遲消耗非常明顯,對(duì)于響應(yīng)時(shí)間比較敏感的場景這個(gè)延遲優(yōu)化很有必要。針對(duì)這個(gè)問題我們的解決思路是充分利用CPU多核心計(jì)算的能力,將列表拆分成任務(wù),通過多線程并行執(zhí)行,實(shí)現(xiàn)機(jī)制如下:
5.2.4 GraphQL-DataLoader調(diào)度優(yōu)化
1)DataLoader基本原理
先簡單介紹一下DataLoader的基本原理,DataLoader有兩個(gè)方法,一個(gè)是load,一個(gè)是dispatch,在解決N+1問題的場景中,DataLoader是這么用的:
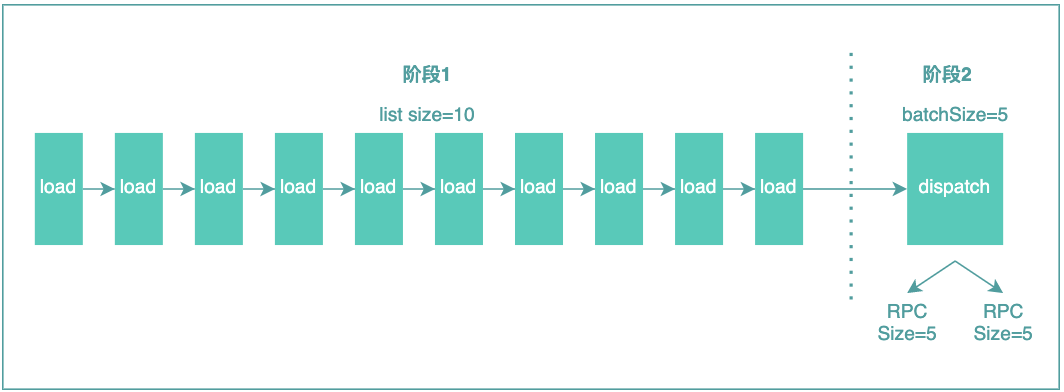
整體分為2個(gè)階段,第一個(gè)階段調(diào)用load,調(diào)用N次,第二個(gè)階段調(diào)用dispatch,調(diào)用dispatch的時(shí)候會(huì)真正的執(zhí)行數(shù)據(jù)查詢,從而達(dá)到批量查詢+分片的效果。
2)DataLoader調(diào)度問題
GraphQL-Java對(duì)DataLoader的集成支持的實(shí)現(xiàn)在FieldLevelTrackingApproach中,FieldLevelTrackingApproach的實(shí)現(xiàn)會(huì)存在怎樣的問題呢?下面基于一張圖表達(dá)原生DataLoader調(diào)度機(jī)制所產(chǎn)生的問題:
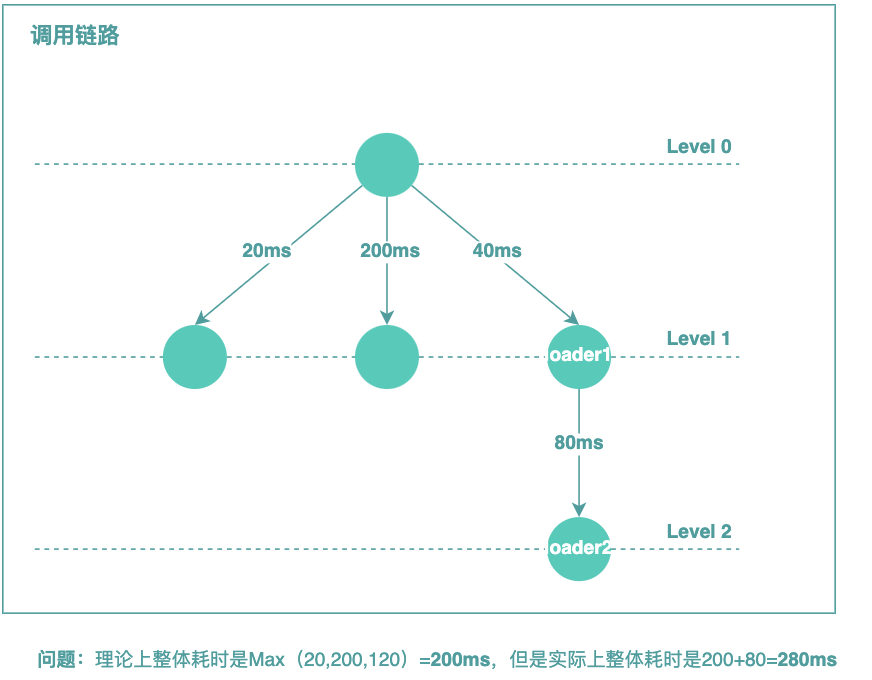
問題很明顯,基于FieldLevelTrackingApproach的實(shí)現(xiàn),下一層級(jí)的DataLoader的dispatch是需要等到本層級(jí)的結(jié)果都回來之后才發(fā)出。基于這樣的實(shí)現(xiàn),查詢總耗時(shí)的計(jì)算公式等于:TOTAL = MAX(Level 1 Latency)+ MAX(Level 2 Latency)+ MAX(Level 3 Latency)+ … ,總查詢耗時(shí)等于每層耗時(shí)最大的值加起來,而實(shí)際上如果鏈路編排由業(yè)務(wù)開發(fā)同學(xué)自己來寫的話,理論上的效果是總耗時(shí)等于所有鏈路最長的那個(gè)鏈路所耗的時(shí)間,這個(gè)才是合理的。而FieldLevelTrackingApproach的實(shí)現(xiàn)所表現(xiàn)出來的結(jié)果是反常識(shí)的,至于為什么這么實(shí)現(xiàn),目前我們理解可能是設(shè)計(jì)者基于簡單和通用方面的考慮。
問題在于以上的實(shí)現(xiàn)在有些業(yè)務(wù)場景下是不能接受的,比如我們的列表場景的響應(yīng)時(shí)間約束一共也就不到100ms,其中幾十ms是因?yàn)檫@個(gè)原因搭進(jìn)去的。針對(duì)這個(gè)問題的解決思路,一種方式是對(duì)于響應(yīng)時(shí)間要求特別高的場景獨(dú)立編排,不采用GraphQL;另一種方式是在GraphQL層面解決這個(gè)問題,保持架構(gòu)的統(tǒng)一性。接下來,介紹一下我們是如何擴(kuò)展GraphQL-Java執(zhí)行引擎來解決這個(gè)問題的。
3)DataLoader調(diào)度優(yōu)化
針對(duì)DataLoader調(diào)度的性能問題,我們的解決思路是在最后一次調(diào)用某個(gè)DataLoader的load之后,立即調(diào)用dispatch方法發(fā)出查詢請(qǐng)求,問題是我們?cè)趺粗滥囊淮蔚膌oad是最后一次load呢?這個(gè)問題也是解決DataLoader調(diào)度問題的難點(diǎn),以下舉個(gè)例子來解釋我們的解決思路:
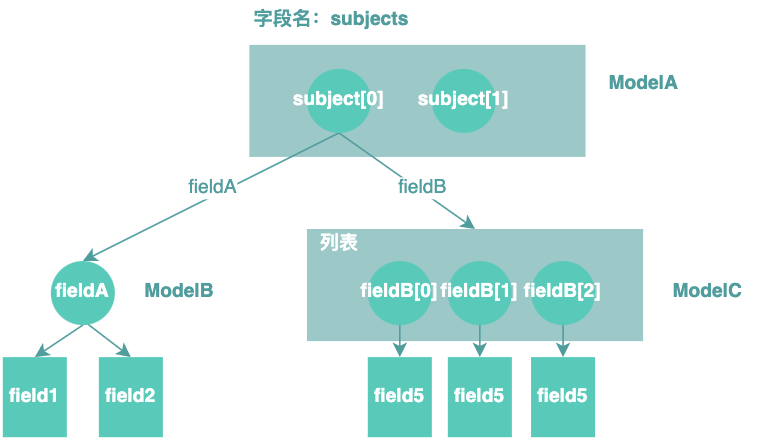
假設(shè)我們查詢到的模型結(jié)構(gòu)如下:根節(jié)點(diǎn)是Query下的字段,字段名叫subjects,subject引用的是個(gè)列表,subject下有兩個(gè)元素,都是ModelA的對(duì)象實(shí)例,ModelA有兩個(gè)字段,fieldA和fieldB,subjects[0]的fieldA關(guān)聯(lián)是ModelB的一個(gè)實(shí)例,subjects[0]的fieldB關(guān)聯(lián)多個(gè)ModelC實(shí)例。
為了方便理解,我們定義一些概念,字段、字段實(shí)例、字段實(shí)例執(zhí)行完、字段實(shí)例值大小等等:
字段:具有唯一路徑,是靜態(tài)的,和運(yùn)行時(shí)對(duì)象大小沒有關(guān)系,如: subjects和subjects/fieldA。字段實(shí)例:字段的實(shí)例,具有唯一路徑,是動(dòng)態(tài)的,跟運(yùn)行時(shí)對(duì)象大小有關(guān)系,如: subjects[0]/fieldA和subjects[1]/fieldA是字段subjects/fieldA的實(shí)例。字段實(shí)例執(zhí)行完:字段實(shí)例關(guān)聯(lián)的對(duì)象實(shí)例都被GraphQL執(zhí)行完了。 字段實(shí)例值大小:字段實(shí)例引用對(duì)象實(shí)例的個(gè)數(shù),如以上示例, subjects[0]/fieldA字段實(shí)例值大小是1,subjects[0]/fieldB字段實(shí)例值大小是3。
除了以上定義之外,我們的業(yè)務(wù)場景還滿足以下條件:
只有1個(gè)根節(jié)點(diǎn),且根節(jié)點(diǎn)是列表。 DataLoader一定屬于某個(gè)字段,某個(gè)字段下的DataLoader應(yīng)該被執(zhí)行次數(shù)等于其下的對(duì)象實(shí)例個(gè)數(shù)。
基于以上信息,我們可以得出以下問題分析:
在執(zhí)行字段實(shí)例的時(shí)候,我們可以知道當(dāng)前字段實(shí)例的大小,字段實(shí)例的大小等于字段關(guān)聯(lián) DataLoader在當(dāng)前實(shí)例下需要執(zhí)行load的次數(shù),因此在執(zhí)行load之后,我們可以知道當(dāng)前對(duì)象實(shí)例是否是其所在字段實(shí)例的最后一個(gè)對(duì)象。一個(gè)對(duì)象的實(shí)例可能會(huì)掛在不同的字段實(shí)例下,所以僅當(dāng)當(dāng)前對(duì)象實(shí)例是其所在字段實(shí)例的最后一個(gè)對(duì)象實(shí)例的時(shí)候,不代表當(dāng)前對(duì)象實(shí)例是所有對(duì)象實(shí)例中的最后一個(gè),當(dāng)且僅當(dāng)對(duì)象實(shí)例所在節(jié)點(diǎn)實(shí)例是節(jié)點(diǎn)的最后一個(gè)實(shí)例的時(shí)候才成立。 我們可從字段實(shí)例大小推算字段實(shí)例的個(gè)數(shù),比如我們知道 subjects的大小是2,那么就知道subjects字段有兩個(gè)字段實(shí)例subjects[0]和subjects[1],也就知道字段subjects/fieldA有兩個(gè)實(shí)例,subjects[0]/fieldA和subjects[1]/fieldA,因此我們從根節(jié)點(diǎn)可以往下推斷出某個(gè)字段實(shí)例是否執(zhí)行完。
通過以上分析,我們可以得出,一個(gè)對(duì)象執(zhí)行完的條件是其所在的字段實(shí)例以及其所在的字段所有的父親字段實(shí)例都執(zhí)行完,且當(dāng)前執(zhí)行的對(duì)象實(shí)例是其所在字段實(shí)例的最后一個(gè)對(duì)象實(shí)例的時(shí)候。
基于這個(gè)判斷邏輯,我們的實(shí)現(xiàn)方案是在每次調(diào)用完DataFetcher的時(shí)候,判斷是否需要發(fā)起dispatch,如果是則發(fā)起。另外,以上時(shí)機(jī)和條件存在漏發(fā)dispatch的問題,有個(gè)特殊情況,當(dāng)當(dāng)前對(duì)象實(shí)例不是最后一個(gè),但是剩下的對(duì)象大小都為0的時(shí)候,那么就永遠(yuǎn)不會(huì)觸發(fā)當(dāng)前對(duì)象關(guān)聯(lián)的DataLoader的load了,所以在對(duì)象大小為0的時(shí)候,需要額外再判斷一次。
根據(jù)以上的邏輯分析,我們實(shí)現(xiàn)了DataLoader調(diào)用鏈路的最優(yōu)化,達(dá)到理論最優(yōu)的效果。
6 新架構(gòu)對(duì)研發(fā)模式的影響
生產(chǎn)力決定生產(chǎn)關(guān)系,元數(shù)據(jù)驅(qū)動(dòng)信息聚合架構(gòu)是展示場景搭建的核心生產(chǎn)力,而業(yè)務(wù)開發(fā)模式和過程是生產(chǎn)關(guān)系,因此也會(huì)隨之改變。下面我們將會(huì)從開發(fā)模式和流程兩個(gè)角度來介紹新架構(gòu)對(duì)研發(fā)帶來的影響。
6.1 聚焦業(yè)務(wù)的開發(fā)模式
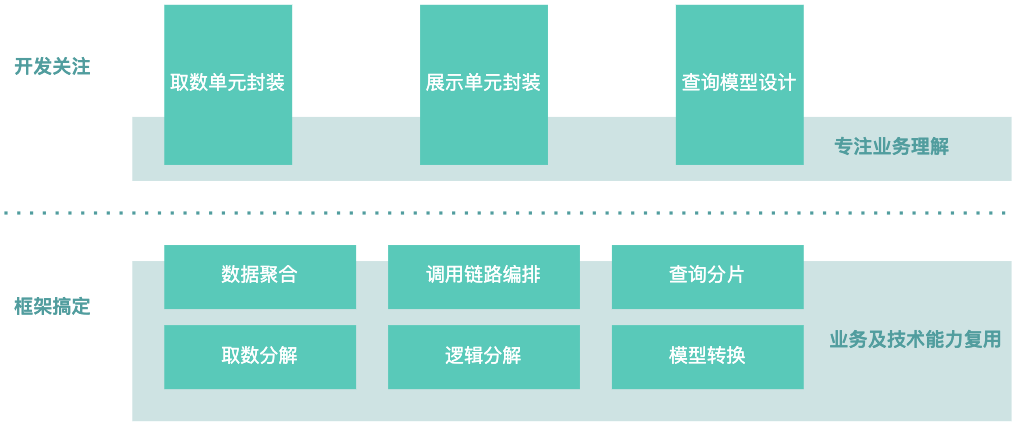
新架構(gòu)提供了一套基于業(yè)務(wù)抽象出的標(biāo)準(zhǔn)化代碼分解約束。以前開發(fā)同學(xué)對(duì)系統(tǒng)的理解很可能就是“查一查服務(wù),把數(shù)據(jù)粘在一起”,而現(xiàn)在,研發(fā)同學(xué)對(duì)于業(yè)務(wù)的理解及代碼分解思路將會(huì)是一致的。比如展示單元代表的是展示邏輯,取數(shù)單元代表的是取數(shù)邏輯。同時(shí),很多冗雜且容易出錯(cuò)的邏輯已經(jīng)被框架屏蔽掉了,研發(fā)同學(xué)能夠有更多的精力聚焦于業(yè)務(wù)邏輯本身,比如:業(yè)務(wù)數(shù)據(jù)的理解和封裝,展示邏輯的理解和編寫,以及查詢模型的抽象和建設(shè)。如下示意圖所示:
6.2 研發(fā)流程升級(jí)
新架構(gòu)不僅僅影響了研發(fā)的代碼編寫,同時(shí)也影響著研發(fā)流程的改進(jìn),基于元數(shù)據(jù)架構(gòu)實(shí)現(xiàn)的可視化及配置化能力,現(xiàn)有研發(fā)流程和之前研發(fā)流程相比有了明顯的區(qū)別,如下圖所示:
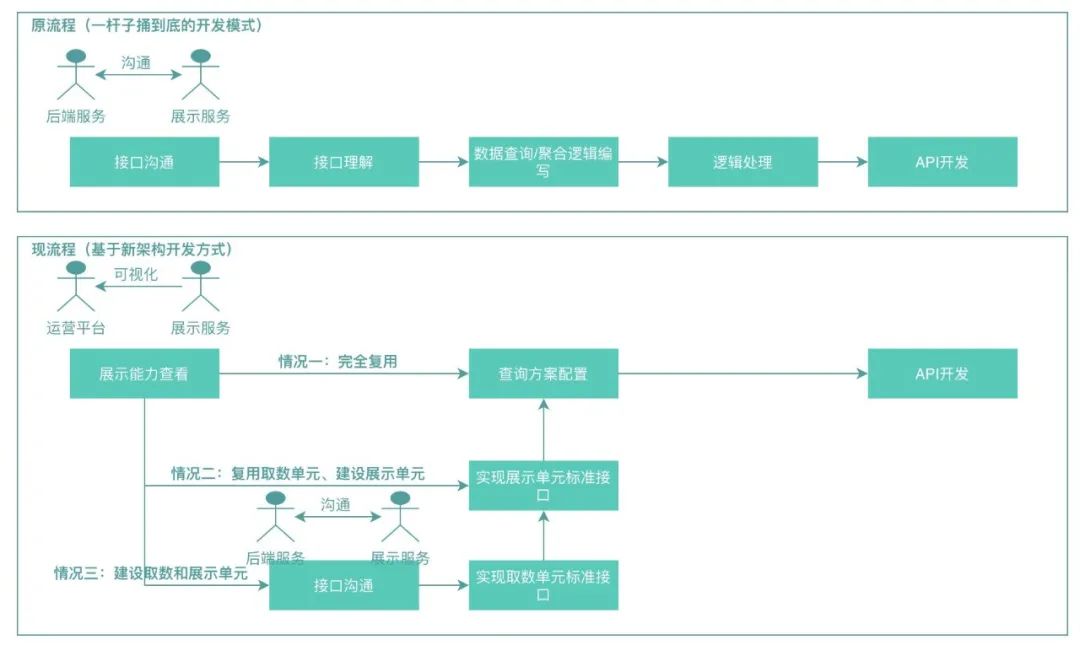
以前是“一桿子捅到底”的開發(fā)模式,每個(gè)展示場景的搭建需要經(jīng)歷過從接口的溝通到API的開發(fā)整個(gè)過程,基于新架構(gòu)之后,系統(tǒng)自動(dòng)具備多層復(fù)用及可視化、配置化能力。
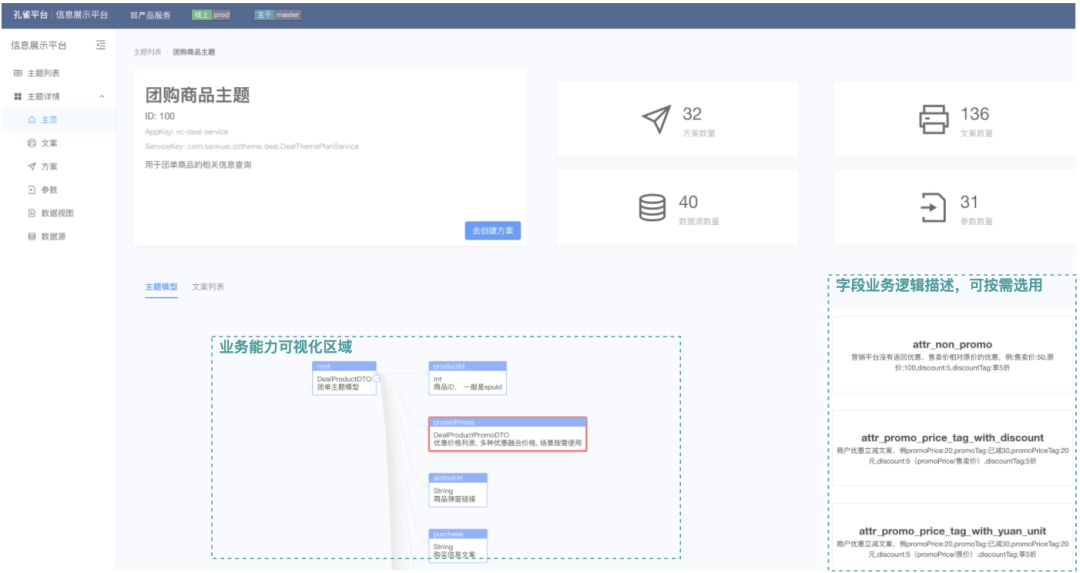
情況一:這是最好的情況,此時(shí)取數(shù)功能和展示功能都已經(jīng)被沉淀下來,研發(fā)同學(xué)需要做的只是創(chuàng)建查詢方案,基于運(yùn)營平臺(tái)按需選擇需要的展示單元,拿著查詢方案ID基于查詢接口就可以查到需要的展示信息了,可視化、配置化界面如下示意圖所示:
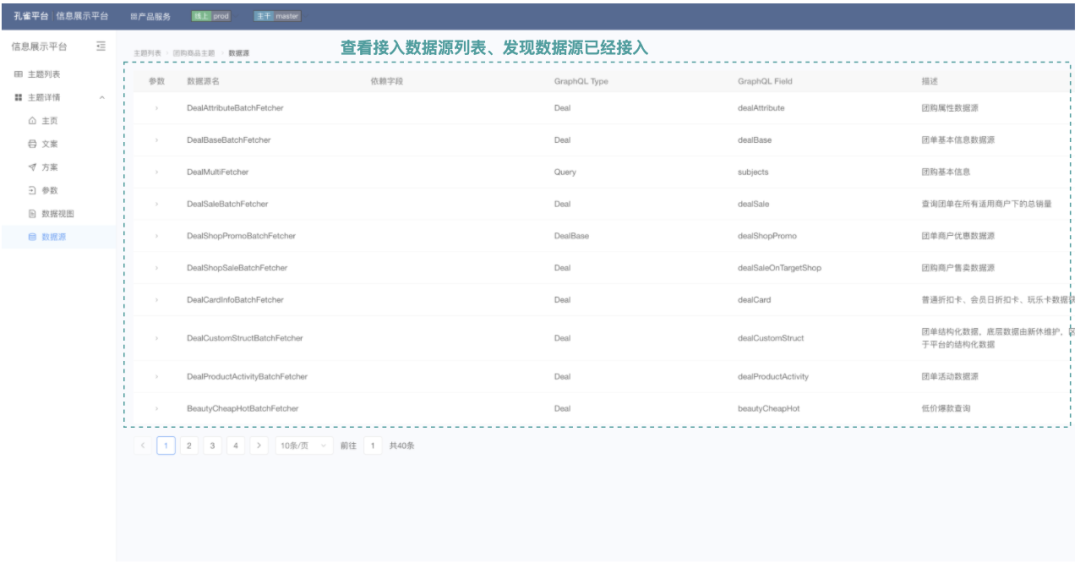
情況二:此時(shí)可能沒有展示功能,但是通過運(yùn)營平臺(tái)查看到,數(shù)據(jù)源已經(jīng)接入過,那么也不難,只需要基于現(xiàn)有的數(shù)據(jù)源編寫一段加工邏輯即可,這段加工邏輯是非常爽的一段純邏輯的編寫,數(shù)據(jù)源列表如下示意圖所示:
情況三:最壞的情況是此時(shí)系統(tǒng)不能滿足當(dāng)前的查詢能力,這種情況比較少見,因?yàn)楹蠖朔?wù)是比較穩(wěn)定的,那么也無需驚慌,只需要按照標(biāo)準(zhǔn)規(guī)范將數(shù)據(jù)源接入進(jìn)來,然后編寫加工邏輯片段即可,之后這些能力是可以被持續(xù)復(fù)用的。
7 總結(jié)
商品展示場景的復(fù)雜性體現(xiàn)在:場景多、依賴多、邏輯多,以及不同場景之間存在差異。在這樣的背景下,如果是業(yè)務(wù)初期,怎么快怎么來,采用“煙囪式”個(gè)性化建設(shè)的方式不必有過多的質(zhì)疑。但是隨著業(yè)務(wù)的不斷發(fā)展,功能的不斷迭代,以及場景的規(guī)模化趨勢(shì),“煙囪式”個(gè)性化建設(shè)的弊端會(huì)慢慢凸顯出來,包括代碼復(fù)雜度高、缺少能力沉淀等問題。
本文以基于對(duì)美團(tuán)到店商品展示場景所面臨的核心矛盾分析,介紹了:
業(yè)界不同的BFF應(yīng)用模式,以及不同模式的優(yōu)勢(shì)和缺點(diǎn)。 基于GraphQL BFF模式改進(jìn)的元數(shù)據(jù)驅(qū)動(dòng)的架構(gòu)方案設(shè)計(jì)。 我們?cè)贕raphQL實(shí)踐過程中遇到的問題及解決思路。 新架構(gòu)對(duì)研發(fā)模式產(chǎn)生的影響呈現(xiàn)。
目前,筆者所在團(tuán)隊(duì)負(fù)責(zé)的核心商品展示場景都已遷入新架構(gòu),基于新的研發(fā)模式,我們實(shí)現(xiàn)了50%以上的展示邏輯復(fù)用以及1倍以上的效率提升。希望本文對(duì)大家能夠有所幫助。
8 參考文獻(xiàn)
[6] 《系統(tǒng)架構(gòu)-復(fù)雜系統(tǒng)的產(chǎn)品設(shè)計(jì)與開發(fā)》