
Kafka中改進(jìn)的二分查找算法
最近有學(xué)習(xí)些Kafak的源碼,想給大家分享下Kafak中改進(jìn)的二分查找算法。二分查找,是每個(gè)程序員都應(yīng)掌握的基礎(chǔ)算法,而Kafka是如何改進(jìn)二分查找來(lái)應(yīng)用于自己的場(chǎng)景中,這很值得我們了解學(xué)習(xí)。
由于Kafak把二分查找應(yīng)用于索引查找的場(chǎng)景中,所以本文會(huì)先對(duì)Kafka的日志結(jié)構(gòu)和索引進(jìn)行簡(jiǎn)單的介紹。在Kafak中,消息以日志的形式保存,每個(gè)日志其實(shí)就是一個(gè)文件夾,且存有多個(gè)日志段,一個(gè)日志段指的是文件名(起始偏移)相同的消息日志文件和4個(gè)索引文件,如下圖所示。
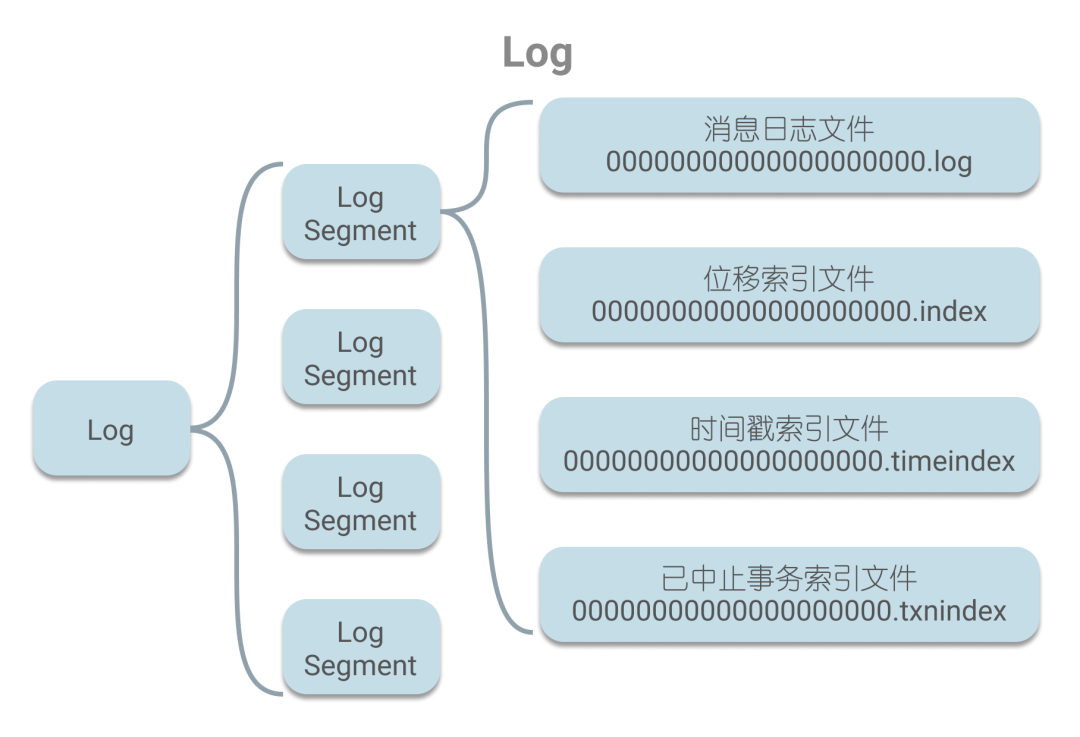
在消息日志文件中以追加的方式存儲(chǔ)著消息,每條消息都有著唯一的偏移量。在查找消息時(shí),會(huì)借助索引文件進(jìn)行查找。如果根據(jù)偏移量來(lái)查詢,則會(huì)借助位移索引文件來(lái)定位消息的位置。為了便于討論索引查詢,下文都將基于位移索引這一背景。位移索引的本質(zhì)是一個(gè)字節(jié)數(shù)組,其中存儲(chǔ)著偏移量和相應(yīng)的磁盤物理位置,這里偏移量和磁盤物理位置都固定用4個(gè)字節(jié),可以看做是每8個(gè)字節(jié)一個(gè)key-value對(duì),如下圖:

索引的結(jié)構(gòu)已經(jīng)清楚了,下面就能正式進(jìn)入本文的主題“二分查找”。給定索引項(xiàng)的數(shù)組和target偏移量,可寫(xiě)出如下代碼:
private?def?indexSlotRangeFor(idx:?ByteBuffer,?target:?Long,?searchEntity:?IndexSearchEntity):?(Int,?Int)?=?{
??//?_entries表示索引項(xiàng)的數(shù)量
??//?1.?如果當(dāng)前索引為空,直接返回(-1,-1)表示沒(méi)找到
??if?(_entries?==?0)
????return?(-1,?-1)
??//?2.?確保查找的偏移量不小于當(dāng)前最小偏移量
??if?(compareIndexEntry(parseEntry(idx,?0),?target,?searchEntity)?>?0)
????return?(-1,?0)
??
??//?3.?執(zhí)行二分查找算法,找出target
??var?lo?=?0
??var?hi?=?_entries?-?1
??while?(lo?????val?mid?=?ceil(hi?/?2.0?+?lo?/?2.0).toInt
????val?found?=?parseEntry(idx,?mid)
????val?compareResult?=?compareIndexEntry(found,?target,?searchEntity)
????if?(compareResult?>?0)
??????hi?=?mid?-?1
????else?if?(compareResult?0)
??????lo?=?mid
????else
??????return?(mid,?mid)
??}
??
??(lo,?if?(lo?==?_entries?-?1)?-1?else?lo?+?1)
}
上述代碼使用了普通的二分查找,下面我們看下這樣會(huì)存在什么問(wèn)題。雖然每個(gè)索引項(xiàng)的大小是4B,但操作系統(tǒng)訪問(wèn)內(nèi)存時(shí)的最小單元是頁(yè),一般是4KB,即4096B,會(huì)包含了512個(gè)索引項(xiàng)。而找出在索引中的指定偏移量,對(duì)于操作系統(tǒng)訪問(wèn)內(nèi)存時(shí)則變成了找出指定偏移量所在的頁(yè)。假設(shè)索引的大小有13個(gè)頁(yè),如下圖所示:

由于Kafka讀取消息,一般都是讀取最新的偏移量,所以要查詢的頁(yè)就集中在尾部,即第12號(hào)頁(yè)上。下面我們結(jié)合上述的代碼,看下查詢最新偏移量,會(huì)訪問(wèn)哪些頁(yè)。根據(jù)二分查找,將依次訪問(wèn)6、9、11、12號(hào)頁(yè)。

當(dāng)隨著Kafka接收消息的增加,索引文件也會(huì)增加至第13號(hào)頁(yè),這時(shí)根據(jù)二分查找,將依次訪問(wèn)7、10、12、13號(hào)頁(yè)。

可以看出訪問(wèn)的頁(yè)和上一次的頁(yè)完全不同。之前在只有12號(hào)頁(yè)的時(shí)候,Kafak讀取索引時(shí)會(huì)頻繁訪問(wèn)6、9、11、12號(hào)頁(yè),而由于Kafka使用了mmap來(lái)提高速度,即讀寫(xiě)操作都將通過(guò)操作系統(tǒng)的page cache,所以6、9、11、12號(hào)頁(yè)會(huì)被緩存到page cache中,避免磁盤加載。但是當(dāng)增至13號(hào)頁(yè)時(shí),則需要訪問(wèn)7、10、12、13號(hào)頁(yè),而由于7、10號(hào)頁(yè)長(zhǎng)時(shí)間沒(méi)有被訪問(wèn)(現(xiàn)代操作系統(tǒng)都是使用LRU或其變體來(lái)管理page cache),很可能已經(jīng)不在page cache中了,那么就會(huì)造成缺頁(yè)中斷(線程被阻塞等待從磁盤加載沒(méi)有被緩存到page cache的數(shù)據(jù))。在Kafka的官方測(cè)試中,這種情況會(huì)造成幾毫秒至1秒的延遲。
鑒于以上情況,Kafka對(duì)二分查找進(jìn)行了改進(jìn)。既然一般讀取數(shù)據(jù)集中在索引的尾部。那么將索引中最后的8192B(8KB)劃分為“熱區(qū)”,其余部分劃分為“冷區(qū)”,分別進(jìn)行二分查找。代碼實(shí)現(xiàn)如下:
private?def?indexSlotRangeFor(idx:?ByteBuffer,?target:?Long,?searchEntity:?IndexSearchType):?(Int,?Int)?=?{
??//?1.?如果當(dāng)前索引為空,直接返回(-1,-1)表示沒(méi)找到
??if(_entries?==?0)
????return?(-1,?-1)
?//?二分查找封裝成方法
??def?binarySearch(begin:?Int,?end:?Int)?:?(Int,?Int)?=?{
????var?lo?=?begin
????var?hi?=?end
????while(lo???????val?mid?=?(lo?+?hi?+?1)?>>>?1
??????val?found?=?parseEntry(idx,?mid)
??????val?compareResult?=?compareIndexEntry(found,?target,?searchEntity)
??????if(compareResult?>?0)
????????hi?=?mid?-?1
??????else?if(compareResult?0)
????????lo?=?mid
??????else
????????return?(mid,?mid)
????}
????(lo,?if?(lo?==?_entries?-?1)?-1?else?lo?+?1)
??}
??/**
???* 2. 確認(rèn)熱區(qū)首個(gè)索引項(xiàng)位。_warmEntries就是所謂的分割線,目前固定為8192字節(jié)處
???*?對(duì)于OffsetIndex,_warmEntries?=?8192?/?8?=?1024,即第1024個(gè)索引項(xiàng)
???*?大部分查詢集中在索引項(xiàng)的尾部,所以把尾部的8192字節(jié)設(shè)置為熱區(qū)
???*?如果查詢target在熱區(qū)索引項(xiàng)范圍,直接查熱區(qū),避免頁(yè)中斷
???*/
??val?firstHotEntry?=?Math.max(0,?_entries?-?1?-?_warmEntries)
??//?3.?判斷target偏移值在熱區(qū)還是冷區(qū)
??if(compareIndexEntry(parseEntry(idx,?firstHotEntry),?target,?searchEntity)?0)?{
????//?如果在熱區(qū),搜索熱區(qū)
????return?binarySearch(firstHotEntry,?_entries?-?1)
??}
??//?4.?確保要查找的位移值不能小于當(dāng)前最小位移值
??if(compareIndexEntry(parseEntry(idx,?0),?target,?searchEntity)?>?0)
????return?(-1,?0)
??//?5.?如果在冷區(qū),搜索冷區(qū)
??binarySearch(0,?firstHotEntry)
}
這樣做的好處是,在頻繁查詢尾部的情況下,尾部的頁(yè)基本都能在page cahce中,從而避免缺頁(yè)中斷。
下面我們還是用之前的例子來(lái)看下。由于每個(gè)頁(yè)最多包含512個(gè)索引項(xiàng),而最后的1024個(gè)索引項(xiàng)所在頁(yè)會(huì)被認(rèn)為是熱區(qū)。那么當(dāng)12號(hào)頁(yè)未滿時(shí),則10、11、12會(huì)被判定是熱區(qū);而當(dāng)12號(hào)頁(yè)剛好滿了的時(shí)候,則11、12被判定為熱區(qū);當(dāng)增至13號(hào)頁(yè)且未滿時(shí),11、12、13被判定為熱區(qū)。假設(shè)我們讀取的是最新的消息,則在熱區(qū)中進(jìn)行二分查找的情況如下:
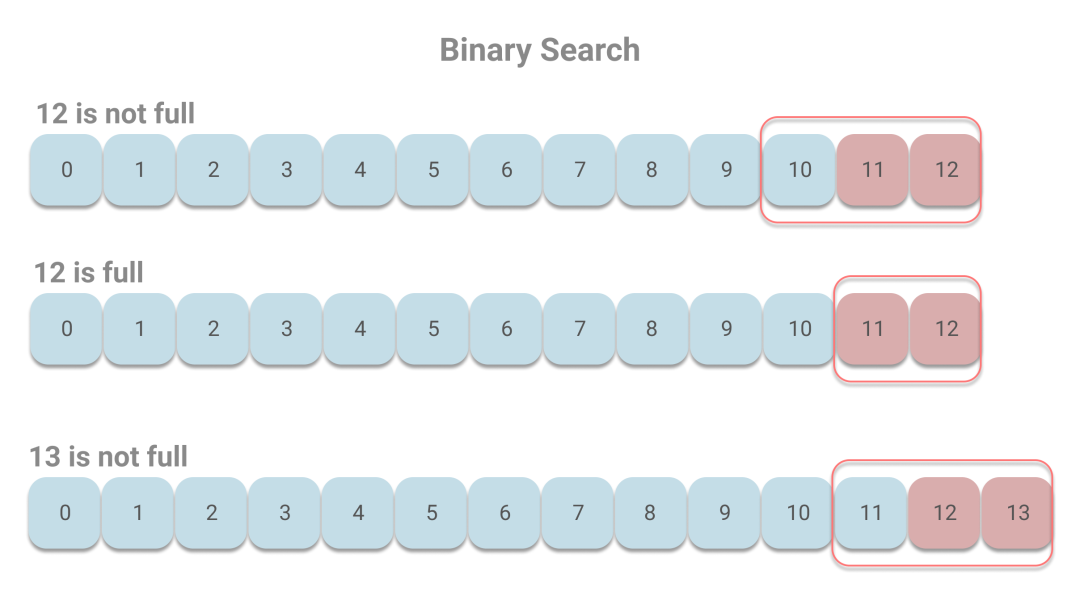
當(dāng)12號(hào)頁(yè)未滿時(shí),依次訪問(wèn)11、12號(hào)頁(yè),當(dāng)12號(hào)頁(yè)滿時(shí),訪問(wèn)頁(yè)的情況相同。當(dāng)13號(hào)頁(yè)出現(xiàn)的時(shí)候,依次訪問(wèn)12、13號(hào)頁(yè),不會(huì)出現(xiàn)訪問(wèn)長(zhǎng)時(shí)間未訪問(wèn)的頁(yè),則能有效避免缺頁(yè)中斷。
關(guān)于為什么設(shè)置熱區(qū)大小為8192字節(jié),官方給出的解釋,這是一個(gè)合適的值:
足夠小,能保證熱區(qū)的頁(yè)數(shù)小于等于3,那么當(dāng)二分查找時(shí)的頁(yè)面都很大可能在page cache中。也就是說(shuō)如果設(shè)置的太大了,那么可能出現(xiàn)熱區(qū)中的頁(yè)不在page cache中的情況。 足夠大,8192個(gè)字節(jié),對(duì)于位移索引,則為1024個(gè)索引項(xiàng),可以覆蓋4MB的消息數(shù)據(jù),足夠讓大部分在in-sync內(nèi)的節(jié)點(diǎn)在熱區(qū)查詢。
最后一句話總結(jié)下:在Kafka索引中使用普通二分搜索會(huì)出現(xiàn)缺頁(yè)中斷的現(xiàn)象,造成延遲,且結(jié)合查詢大多集中在尾部的情況,通過(guò)將索引區(qū)域劃分為熱區(qū)和冷區(qū),分別搜索,將盡可能保證熱區(qū)中的頁(yè)在page cache中,從而避免缺頁(yè)中斷。