
淺談 MySQL 索引優(yōu)化分析
一、索引的概念
1.1 是什么
MySQL 官方對(duì)索引的定義為:索引(Index)是幫助 MySQL 高效獲取數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu)。可以得到索引的本質(zhì):索引是數(shù)據(jù)結(jié)構(gòu)。可以簡(jiǎn)單理解為 「排好序的快速查找數(shù)據(jù)結(jié)構(gòu)」。
在數(shù)據(jù)之外,數(shù)據(jù)庫(kù)系統(tǒng)還維護(hù)著滿足特定查找算法的數(shù)據(jù)結(jié)構(gòu),這些數(shù)據(jù)結(jié)構(gòu)以某種方式引用(指向)數(shù)據(jù), 這樣就可以在這些數(shù)據(jù)結(jié)構(gòu)上實(shí)現(xiàn)高級(jí)查找算法。這種數(shù)據(jù)結(jié)構(gòu),就是索引。下圖就是一種可能的索引方式示例:
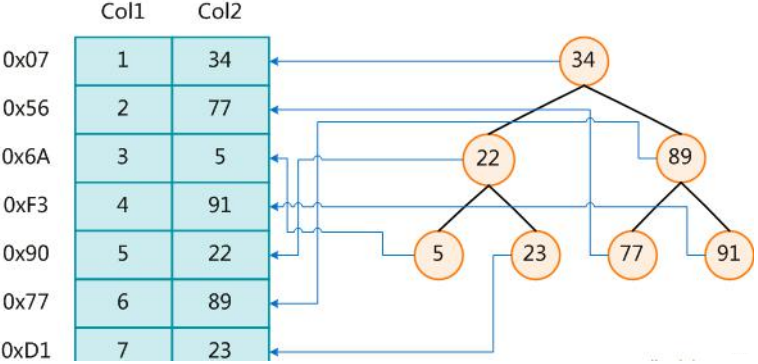 左邊是數(shù)據(jù)表,一共有兩列七條記錄,最左邊的是數(shù)據(jù)記錄的物理地址。為了加快 Col2 的查找,可以維護(hù)一個(gè) 右邊所示的二叉查找樹,每個(gè)節(jié)點(diǎn)分別包含索引鍵值和一個(gè)指向?qū)?yīng)數(shù)據(jù)記錄物理地址的指 針,這樣就可以運(yùn)用 二叉查找在一定的復(fù)雜度內(nèi)獲取到相應(yīng)數(shù)據(jù),從而快速的檢索出符合條件的記錄。
左邊是數(shù)據(jù)表,一共有兩列七條記錄,最左邊的是數(shù)據(jù)記錄的物理地址。為了加快 Col2 的查找,可以維護(hù)一個(gè) 右邊所示的二叉查找樹,每個(gè)節(jié)點(diǎn)分別包含索引鍵值和一個(gè)指向?qū)?yīng)數(shù)據(jù)記錄物理地址的指 針,這樣就可以運(yùn)用 二叉查找在一定的復(fù)雜度內(nèi)獲取到相應(yīng)數(shù)據(jù),從而快速的檢索出符合條件的記錄。
一般來(lái)說(shuō)索引本身也很大,不可能全部存儲(chǔ)在內(nèi)存中,因此索引往往以索引文件的形式存儲(chǔ)的磁盤上。
1.2 優(yōu)缺點(diǎn)
「優(yōu)勢(shì):」
提高數(shù)據(jù)檢索的效率,降低數(shù)據(jù)庫(kù)的IO成本。 通過(guò)索引列對(duì)數(shù)據(jù)進(jìn)行排序,降低數(shù)據(jù)排序的成本,降低了CPU的消耗。
「劣勢(shì):」
雖然索引大大提高了查詢速度,同時(shí)卻會(huì)降低更新表的速度,如對(duì)表進(jìn)行INSERT、UPDATE和DELETE。因?yàn)楦卤頃r(shí),MySQL不僅要保存數(shù)據(jù),還要保存一下索引文件每次更新添加了索引列的字段,都會(huì)調(diào)整因?yàn)?更新所帶來(lái)的鍵值變化后的索引信息。 實(shí)際上索引也是一張表,該表保存了主鍵與索引字段,并指向?qū)嶓w表的記錄,所以索引列也是要占用空間的。
二、MySQL 的索引
2.1 Btree 索引
MySQL 使用的是 Btree 索引。

「【初始化介紹】」
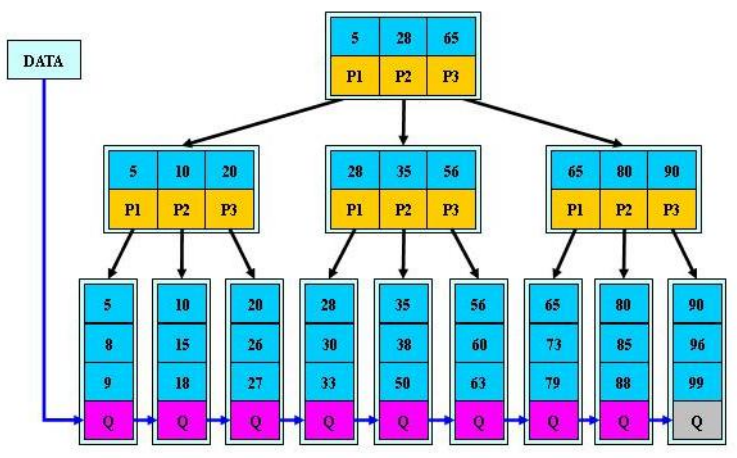
一顆 B 樹,淺藍(lán)色的塊我們稱之為一個(gè)磁盤塊,可以看到每個(gè)磁盤塊包含幾個(gè)數(shù)據(jù)項(xiàng)(深藍(lán)色所示)和指針(黃色所示),
如磁盤塊 1 包含數(shù)據(jù)項(xiàng) 17 和 35,包含指針 P1、P2、P3,
P1 表示小于 17 的磁盤塊,P2 表示在 17 和 35 之間的磁盤塊,P3 表示大于 35 的磁盤塊。
真實(shí)的數(shù)據(jù)存在于葉子節(jié)點(diǎn)即 3、5、9、10、13、15、28、29、36、60、75、79、90、99。
非葉子節(jié)點(diǎn)只不存儲(chǔ)真實(shí)的數(shù)據(jù),只存儲(chǔ)指引搜索方向的數(shù)據(jù)項(xiàng),如 17、35 并不真實(shí)存在于數(shù)據(jù)表中。
「【查找過(guò)程】」
如果要查找數(shù)據(jù)項(xiàng) 29,那么首先會(huì)把磁盤塊 1 由磁盤加載到內(nèi)存,此時(shí)發(fā)生一次 IO,在內(nèi)存中用二分查找確定 29 在 17 和 35 之間,鎖定磁盤塊 1 的 P2 指針,內(nèi)存時(shí)間因?yàn)榉浅6蹋ㄏ啾却疟P的 IO)可以忽略不計(jì),通過(guò)磁盤塊 1 的 P2 指針的磁盤地址把磁盤塊 3 由磁盤加載到內(nèi)存,發(fā)生第二次 IO,29 在 26 和 30 之間,鎖定磁盤塊 3 的 P2 指 針,通過(guò)指針加載磁盤塊 8 到內(nèi)存,發(fā)生第三次 IO,同時(shí)內(nèi)存中做二分查找找到 29,結(jié)束查詢,總計(jì)三次 IO。
真實(shí)的情況是,3 層的 B+樹可以表示上百萬(wàn)的數(shù)據(jù),如果上百萬(wàn)的數(shù)據(jù)查找只需要三次 IO,性能提高將是巨大的, 如果沒有索引,每個(gè)數(shù)據(jù)項(xiàng)都要發(fā)生一次 IO,那么總共需要百萬(wàn)次的 IO,顯然成本非常非常高。
2.2 B+tree 索引
「B+Tree 與 B-Tree 的區(qū)別」
1)B-樹的關(guān)鍵字和記錄是放在一起的,葉子節(jié)點(diǎn)可以看作外部節(jié)點(diǎn),不包含任何信息;B+樹的非葉子節(jié)點(diǎn)中只有關(guān)鍵字和指向下一個(gè)節(jié)點(diǎn)的索引,記錄只放在葉子節(jié)點(diǎn)中。
2)在 B-樹中,越靠近根節(jié)點(diǎn)的記錄查找時(shí)間越快,只要找到關(guān)鍵字即可確定記錄的存在;而 B+樹中每個(gè)記錄的查找時(shí)間基本是一樣的,都需要從根節(jié)點(diǎn)走到葉子節(jié)點(diǎn),而且在葉子節(jié)點(diǎn)中還要再比較關(guān)鍵字。
從這個(gè)角度看 B- 樹的性能好像要比 B+樹好,而在實(shí)際應(yīng)用中卻是 B+樹的性能要好些。因?yàn)?B+樹的非葉子節(jié)點(diǎn)不存放實(shí)際的數(shù)據(jù), 這樣每個(gè)節(jié)點(diǎn)可容納的元素個(gè)數(shù)比 B-樹多,樹高比 B-樹小,這樣帶來(lái)的好處是減少磁盤訪問(wèn)次數(shù)。
盡管 B+樹找到 一個(gè)記錄所需的比較次數(shù)要比 B-樹多,但是一次磁盤訪問(wèn)的時(shí)間相當(dāng)于成百上千次內(nèi)存比較的時(shí)間,因此實(shí)際中 B+樹的性能可能還會(huì)好些,而且 B+樹的葉子節(jié)點(diǎn)使用指針連接在一起,方便順序遍歷(例如查看一個(gè)目錄下的所有 文件,一個(gè)表中的所有記錄等),這也是很多數(shù)據(jù)庫(kù)和文件系統(tǒng)使用 B+樹的緣故。
「思考:為什么說(shuō) B+樹比 B-樹更適合實(shí)際應(yīng)用中操作系統(tǒng)的文件索引和數(shù)據(jù)庫(kù)索引?」
「1)B+樹的磁盤讀寫代價(jià)更低」
B+樹的內(nèi)部結(jié)點(diǎn)并沒有指向關(guān)鍵字具體信息的指針。因此其內(nèi)部結(jié)點(diǎn)相對(duì) B 樹更小。如果把所有同一內(nèi)部結(jié)點(diǎn) 的關(guān)鍵字存放在同一盤塊中,那么盤塊所能容納的關(guān)鍵字?jǐn)?shù)量也越多。一次性讀入內(nèi)存中的需要查找的關(guān)鍵字也就 越多。相對(duì)來(lái)說(shuō) IO 讀寫次數(shù)也就降低了。
「2) B+樹的查詢效率更加穩(wěn)定」
由于非終結(jié)點(diǎn)并不是最終指向文件內(nèi)容的結(jié)點(diǎn),而只是葉子結(jié)點(diǎn)中關(guān)鍵字的索引。所以任何關(guān)鍵字的查找必須 走一條從根結(jié)點(diǎn)到葉子結(jié)點(diǎn)的路。所有關(guān)鍵字查詢的路徑長(zhǎng)度相同,導(dǎo)致每一個(gè)數(shù)據(jù)的查詢效率相當(dāng)。
2.3 聚簇索引和非聚簇索引
聚簇索引并不是一種單獨(dú)的索引類型,而是一種數(shù)據(jù)存儲(chǔ)方式。術(shù)語(yǔ)‘聚簇’表示:數(shù)據(jù)行和相鄰的鍵值聚簇的存儲(chǔ)在一起。如下圖,左側(cè)的索引就是聚簇索引,因?yàn)閿?shù)據(jù)行在磁盤的排列和索引排序保持一致。
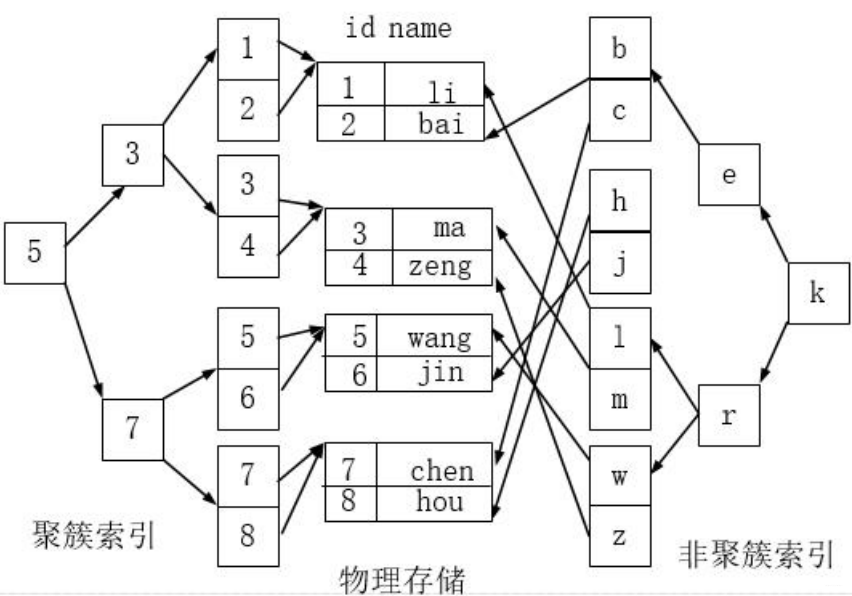
聚簇索引的好處:按照聚簇索引排列順序,查詢顯示一定范圍數(shù)據(jù)的時(shí)候,由于數(shù)據(jù)都是緊密相連,數(shù)據(jù)庫(kù)不不用從多 個(gè)數(shù)據(jù)塊中提取數(shù)據(jù),所以節(jié)省了大量的 io 操作。
聚簇索引的限制:對(duì)于 mysql 數(shù)據(jù)庫(kù)目前只有 innodb 數(shù)據(jù)引擎支持聚簇索引,而 Myisam 并不支持聚簇索引。由于數(shù)據(jù)物理存儲(chǔ)排序方式只能有一種,所以每個(gè) Mysql 的表只能有一個(gè)聚簇索引。一般情況下就是 該表的主鍵。
為了充分利用聚簇索引的聚簇的特性,所以 innodb 表的主鍵列盡量選用有序的順序 id,而不建議用 無(wú)序的 id,比如 uuid 這種。
2.4 時(shí)間復(fù)雜度(擴(kuò)展)
同一問(wèn)題可用不同算法解決,而一個(gè)算法的質(zhì)量?jī)?yōu)劣將影響到算法乃至程序的效率。算法分析的 目的在于選擇合適算法和改進(jìn)算法。時(shí)間復(fù)雜度是指執(zhí)行算法所需要的計(jì)算工作量,用大 O 表示記為:O(…)
三、MySQL 索引分類
3.1 單值索引
概念:即一個(gè)索引只包含單個(gè)列,一個(gè)表可以有多個(gè)單列索引 語(yǔ)法:
//所表一起創(chuàng)建:
CREATE TABLE customer (
id INT(10) UNSIGNED AUTO_INCREMENT ,
customer_no VARCHAR(200),
customer_name VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name) // Σ(っ °Д °;)っ
);
//單獨(dú)建單值索引:
CREATE INDEX idx_customer_name ON
3.2 唯一索引
概念:索引列的值必須唯一,但允許有空值
//隨表一起創(chuàng)建:
CREATE TABLE customer (
id INT(10) UNSIGNED AUTO_INCREMENT ,
customer_no VARCHAR(200),
customer_name VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name),
UNIQUE (customer_no) // Σ(っ °Д °;)っ
);
//單獨(dú)建唯一索引:
CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no);
3.3 主鍵索引
概念:設(shè)定為主鍵后數(shù)據(jù)庫(kù)會(huì)自動(dòng)建立索引,innodb為聚簇索引
//隨表一起建索引
CREATE TABLE customer (
id INT(10) UNSIGNED AUTO_INCREMENT ,
customer_no VARCHAR(200),
customer_name VARCHAR(200),
PRIMARY KEY(id) // Σ(っ °Д °;)っ
);
//單獨(dú)建主鍵索引:
ALTER TABLE customer add PRIMARY KEY customer(customer_no);
//刪除建主鍵索引:
ALTER TABLE customer drop PRIMARY KEY ;
//修改建主鍵索引:
必須先刪除掉(drop)原索引,再新建(add)索引
3.4 復(fù)合索引
概念:即一個(gè)索引包含多個(gè)列
隨表一起建索引:
CREATE TABLE customer (
id INT(10) UNSIGNED AUTO_INCREMENT ,
customer_no VARCHAR(200),
customer_name VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name),
UNIQUE (customer_name),
KEY (customer_no,customer_name) // Σ(っ °Д °;)っ
);
單獨(dú)建索引:
CREATE INDEX idx_no_name ON customer(customer_no,customer_name);
3.5 基本語(yǔ)法
| 操作 | 命令 |
|---|---|
| 創(chuàng)建 | CREATE [UNIQUE ] INDEX [indexName] ON table_name(column)) |
| 刪除 | DROP INDEX [indexName] ON mytable; |
| 查看 | SHOW INDEX FROM table_name\G |
| 使 用 Alter 命令 | ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) : 該語(yǔ)句添加一個(gè)主鍵,這意味著索引值必須是唯一 的,且不能為 NULL。 |
| ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) | |
| ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出現(xiàn)多次。 | |
| ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):該語(yǔ)句指定了索引為 FULLTEXT ,用于全文索 引。 |
四、索引的創(chuàng)建時(shí)機(jī)
4.1 適合創(chuàng)建索引的情況
主鍵自動(dòng)建立唯一索引 頻繁作為查詢條件的字段應(yīng)該創(chuàng)建索引 查詢中與其它表關(guān)聯(lián)的字段,外鍵關(guān)系建立索引 單鍵/組合索引的選擇問(wèn)題, 組合索引性價(jià)比更高 查詢中排序的字段,排序字段若通過(guò)索引去訪問(wèn)將大大提高排序速度 查詢中統(tǒng)計(jì)或者分組字段
4.2 不適合創(chuàng)建索引的情況
表記錄太少 經(jīng)常增刪改的表或者字段 Where 條件里用不到的字段不創(chuàng)建索引 過(guò)濾性不好的不適合建索引