
淺談混合精度訓(xùn)練imagenet
淺談混合精度訓(xùn)練imagenet
零、序
本文沒有任何的原理和解讀,只有一些實(shí)驗(yàn)的結(jié)論,對(duì)于想使用混合精度訓(xùn)練的同學(xué)可以直接參考結(jié)論白嫖,或者直接拿github上的代碼(文末放送)。
一、引言
以前做項(xiàng)目的時(shí)候出現(xiàn)過一個(gè)問題,使用FP16訓(xùn)練的時(shí)候,只要BatchSize增加(LR也對(duì)應(yīng)增加)的時(shí)候訓(xùn)練,一段時(shí)間后就會(huì)出現(xiàn)loss異常,同時(shí)val對(duì)應(yīng)的明顯降低,甚至直接NAN的情況出現(xiàn),圖示如下:
這種是比較正常的損失和acc的情況,因?yàn)轫?xiàng)目的數(shù)據(jù)非常長尾。
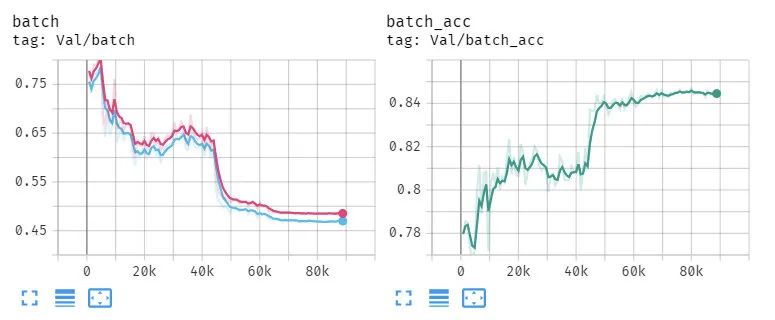
這種就是不正常的訓(xùn)練情況, val的損失不下降反而上升,acc不升反而降。
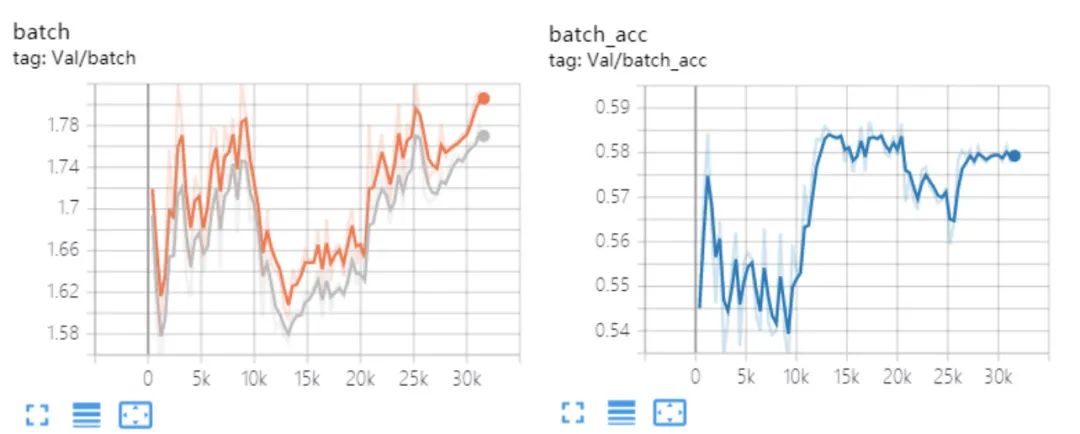
還有一種情況,就是訓(xùn)練十幾個(gè)epoch以后,loss上升到非常大,acc為nan,后續(xù)訓(xùn)練都是nan,tensorboard顯示有點(diǎn)問題,只好看ckpt的結(jié)果了。

由于以前每周都沒跑很多模型,問題也不是經(jīng)常出現(xiàn),所以以為是偶然時(shí)間,不過最近恰好最近要做一些transformer的實(shí)驗(yàn),在跑imagenet baseline(R50)的時(shí)候,出現(xiàn)了類似的問題,由于FP16訓(xùn)練的時(shí)候,出現(xiàn)了溢出的情況所導(dǎo)致的。簡單的做了一些實(shí)驗(yàn),整理如下。
二、混合精度訓(xùn)練
混合精度訓(xùn)練,以pytorch 1.6版本為基礎(chǔ)的話,大致是有3種方案,依次介紹如下:
模型和輸入輸出直接half,如果有BN,那么BN計(jì)算需要轉(zhuǎn)為FP32精度,我上面的問題就是基于此來訓(xùn)練的,代碼如下:
if args.FP16:
model = model.half()
for bn in get_bn_modules(model):
bn.float()
...
for data in dataloader:
if args.FP16:
image, label = data[0].half()
output = model(image)
losses = criterion(output, label)
optimizer.zero_grad()
losses.backward()
optimizer.step()
使用NVIDIA的Apex庫,這里有O1,O2,O3三種訓(xùn)練模式,代碼如下:
try:
from apex import amp
from apex.parallel import convert_syncbn_model
from apex.parallel import DistributedDataParallel as DDP
except Exception as e:
print("amp have not been import !!!")
if args.apex:
model = convert_syncbn_model(model)
if args.apex:
model, optimizer = amp.initialize(model, optimizer, opt_level=args.mode)
model = DDP(model, delay_allreduce=True)
...
for data in dataloader:
image, label = data[0], data[1]
batch_output = model(image)
losses = criterion(batch_output, label)
optimizer.zero_grad()
if args.apex:
with amp.scale_loss(losses, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
pytorch1.6版本以后把a(bǔ)pex并入到了自身的庫里面,代碼如下:
from torch.cuda.amp import autocast as autocast
from torch.nn.parallel import DistributedDataParallel as DataParallel
model = DataParallel(model,
device_ids=[args.local_rank],
find_unused_parameters=True)
if args.amp:
scaler = torch.cuda.amp.GradScaler()
for data in dataloader:
image, label = data[0], data[1]
if args.amp:
with autocast():
batch_output = model(image)
losses = criterion(batch_output, label)
if args.amp:
scaler.scale(losses).backward()
scaler.step(optimizer)
scaler.update()
三、pytorch不同的分布式訓(xùn)練速度對(duì)比
環(huán)境配置如下:
CPU Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
GPU 8XV100 32G
cuda 10.2
pytorch 1.7.
pytorch分布式有兩種不同的啟動(dòng)方法,一種是單機(jī)多卡啟動(dòng),一種是多機(jī)多卡啟動(dòng), ps: DataParallel不是分布式訓(xùn)練。
多機(jī)啟動(dòng)
#!/bin/bash
cd $FOLDER;
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -W ignore -m torch.distributed.launch --nproc_per_node 8 train_lanuch.py \
...單機(jī)啟動(dòng)
cd $FOLDER;
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -W ignore test.py \
--dist-url 'tcp://127.0.0.1:9966' \
--dist-backend 'nccl' \
--multiprocessing-distributed=1 \
--world-size=1 \
--rank=0 \
...詳細(xì)代碼看文末的github鏈接。
實(shí)驗(yàn)一、num workers對(duì)于速度的影響
我的服務(wù)器是48個(gè)物理核心,96個(gè)邏輯核心,所以48的情況下,效果最好,不過增加和減少對(duì)于模型的影響不大,基本上按照CPU的物理核心個(gè)數(shù)來設(shè)置就可以。
num workers BatchSize FP16 epoch time 32 256 No 7:48 48 256 No 7:46 64 256 No 7:47 實(shí)驗(yàn)二、OMP和MKL對(duì)于速度的影響
OMP和MKL對(duì)于多機(jī)模式下的速度有輕微的影響,如果不想每個(gè)都去試,直接經(jīng)驗(yàn)設(shè)置為1最合理。FP16大幅度提升模型的訓(xùn)練速度,可以節(jié)省2/5的時(shí)間。
OMP & MKL num workers BatchSize FP16 epoch time 1 48 256 No 7:47 2 48 256 No 7:51 4 48 256 No 7:50 1 48 256 Yes 4:46 實(shí)驗(yàn)三、單機(jī)和多機(jī)啟動(dòng)速度差異
單機(jī)和多機(jī)啟動(dòng),對(duì)于模型的前向基本是沒有影響的, 主要的差異是在loader開始執(zhí)行的速度,多機(jī)比起單機(jī)啟動(dòng)要快2倍-5倍左右的時(shí)間。
四、不同混合精度訓(xùn)練方法對(duì)比
實(shí)驗(yàn)均在ResNet50和imagenet下面進(jìn)行的,LR隨著BS變換和線性增長,公式如下
實(shí)驗(yàn)結(jié)果
模型FP16+BNFP32實(shí)驗(yàn)記錄
模型 數(shù)據(jù)集 batchsize(所有卡的總數(shù)) 優(yōu)化器 LearningRate top1@acc ResNet50 ImageNet1k 256 SGD optimizer 0.1 75.40% ResNet50 ImageNet1k 512 SGD optimizer 0.2 75.70% ResNet50 ImageNet1k 1024 SGD optimizer 0.4 75.57% ResNe50 ImageNet1k 2048 SGD optimizer 0.8 NaN ResNet50 ImageNet1k 4096 SGD optimizer 1.6 NaN 很明顯可以發(fā)現(xiàn),單存使用FP16進(jìn)行訓(xùn)練,但是沒有l(wèi)oss縮放的情況下,當(dāng)BS和LR都增大的時(shí)候,訓(xùn)練是無法進(jìn)行的,直接原因就是因?yàn)長R過大,導(dǎo)致模型更新的時(shí)候數(shù)值范圍溢出了,同理loss也就直接為NAN了,我嘗試把LR調(diào)小后發(fā)現(xiàn),模型是可以正常訓(xùn)練的,只是精度略有所下降。
Apex混合精度實(shí)驗(yàn)記錄
模型 MODE 數(shù)據(jù)集 batchsize(所有卡的總數(shù)) 優(yōu)化器 LearningRate top1@acc ResNet50 O1(FP16訓(xùn)練,部分op,layer用FP32計(jì)算) ImageNet1k 4096 SGD optimizer 1.6 75.79% ResNe50 O2 (FP16訓(xùn)練,BN用FP32計(jì)算) ImageNet1k 4096 SGD optimizer 1.6 75.59% ResNet50 O3(幾乎存FP16訓(xùn)練) ImageNet1k 4096 SGD optimizer 1.6 NaN Apex O3模式下的訓(xùn)練情況和上面FP16的結(jié)論是一致的,存FP16訓(xùn)練,不管是否有l(wèi)oss縮放都會(huì)導(dǎo)致訓(xùn)練NaN,O2和O1是沒有任何問題的,O2的精度略低于O1的精度。
AMP實(shí)驗(yàn)記錄
模型 MODE 數(shù)據(jù)集 batchsize(所有卡的總數(shù)) 優(yōu)化器 LearningRate top1@acc Time ResNet50 APEX O1 ImageNet1k 4096 SGD optimizer 1.6 75.79% 8h42min32s ResNe50 AMP ImageNet1k 4096 SGD optimizer 1.6 75.92% 8h26min45s AMP自動(dòng)把模型需要用FP32計(jì)算的層或者op直接轉(zhuǎn)換,不需要顯著性指定。精度比apex高,同時(shí)訓(xùn)練時(shí)間更少。
2-bit訓(xùn)練,ACTNN
簡單的嘗試了一下2bit訓(xùn)練,1k的bs是可以跑的,不過速度相比FP16跑,慢了太多,基本可以pass掉了。
附上一個(gè)比較合理的收斂情況
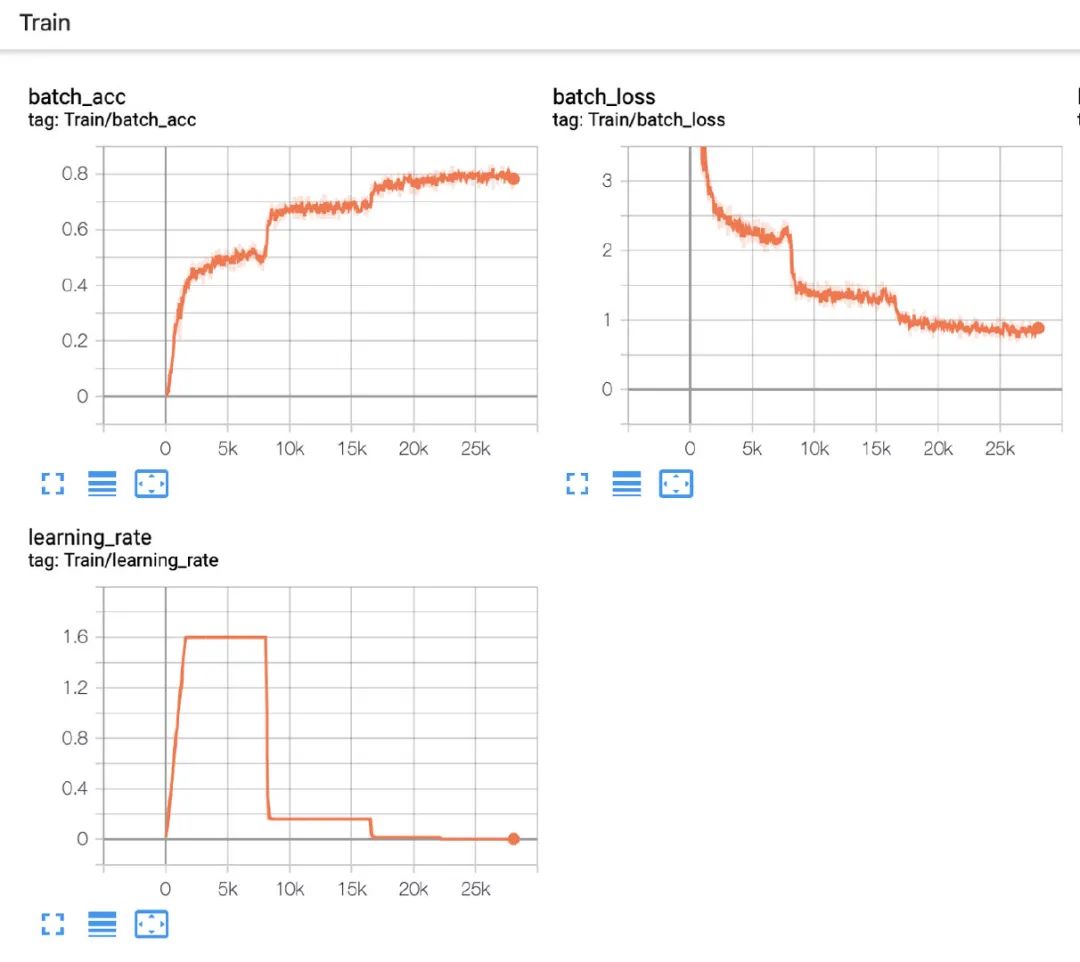
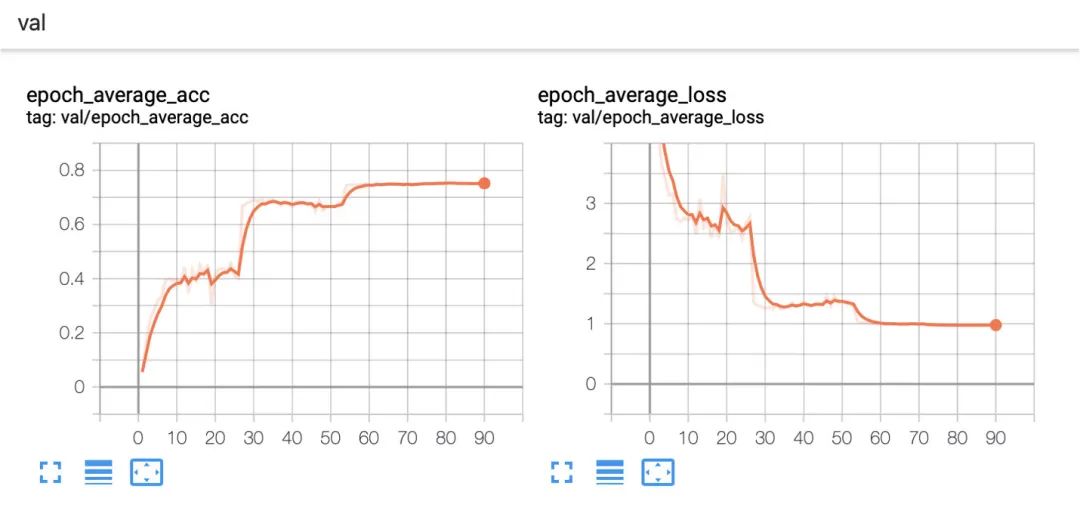
五、結(jié)論
如果使用分布式訓(xùn)練,使用pytorch 多機(jī)模式啟動(dòng),收益比較高,如果你不希望所有卡都用的話,那么建議使用單機(jī)多卡的模式。 如果使用FP16方式計(jì)算的話,那么無腦pytorch amp就可以了,速度和精度都比較有優(yōu)勢(shì),代碼量也不多。 我的增強(qiáng)只用了隨機(jī)裁剪,水平翻轉(zhuǎn),跑了90個(gè)epoch,原版的resnet50是跑了120個(gè)epoch,還有color jitter,imagenet上one crop的結(jié)果0.76012,和我的結(jié)果相差無幾,所以分類任務(wù)(基本上最后是求概率的問題,圖像,視頻都work,已經(jīng)驗(yàn)證過)上FP16很明顯完全可以替代FP32。我跑了一個(gè)120epoch的版本,結(jié)果是0.767,吊打原版本結(jié)果了QAQ。 如果跑小的bs,第一種FP16的方法完全是ok的,對(duì)于大的bs來說,使用AMP會(huì)使得模型的收斂更加穩(wěn)定。 代碼在這里,自行取用。