
PyTorch混合精度訓(xùn)練:每個(gè)人必須要知道的事情
 點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
設(shè)為星標(biāo),干貨直達(dá)!
現(xiàn)代神經(jīng)網(wǎng)絡(luò)的有效訓(xùn)練通常依賴于使用較低精度的數(shù)據(jù)類型。在A100 GPU 上,采用float16的矩陣乘法和卷積的峰值性能要比float32快 16 倍。由于 float16 和 bfloat16 數(shù)據(jù)類型的大小只有 float32 的一半,因此它們可以將帶寬受限內(nèi)核的性能提高一倍,并減少訓(xùn)練網(wǎng)絡(luò)所需的內(nèi)存,從而允許更大的模型、更大的批次或更大的輸入。使用像 torch.amp(Automated Mixed Precision)這樣的模塊可以輕松獲得較低精度數(shù)據(jù)類型的速度和內(nèi)存使用優(yōu)勢(shì),同時(shí)保持網(wǎng)絡(luò)的收斂行為。
更快和使用更少的內(nèi)存總是有利的——深度學(xué)習(xí)從業(yè)者可以測(cè)試更多的模型架構(gòu)和超參數(shù),并且可以訓(xùn)練更大、更強(qiáng)大的模型。訓(xùn)練非常大的模型,例如 Narayanan 等人描述的模型(https://arxiv.org/pdf/2104.04473.pdf)和布朗等人提出的模型(GPT-3,https://arxiv.org/pdf/2005.14165.pdf,即使使用專家手寫優(yōu)化也需要數(shù)以千計(jì)的 GPU 進(jìn)行訓(xùn)練),在不使用混合精度的情況下是不可行的。
我們之前的文章(https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/,https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html,https://developer.nvidia.com/automatic-mixed-precision)討論過混合精度技術(shù),如果您不熟悉混合精度,這篇博文是對(duì)這些技術(shù)的總結(jié)和介紹。
混合精度訓(xùn)練實(shí)踐
混合精度訓(xùn)練技術(shù)——使用較低精度的 float16 或 bfloat16 數(shù)據(jù)類型以及 float32 數(shù)據(jù)類型——具有廣泛的適用性和有效性。請(qǐng)參閱圖 1 以了解以混合精度成功訓(xùn)練的模型結(jié)構(gòu)(包括圖像,語音以及文本等各個(gè)領(lǐng)域),圖 2 和圖 3 是使用 torch.amp 的示例加速對(duì)比。
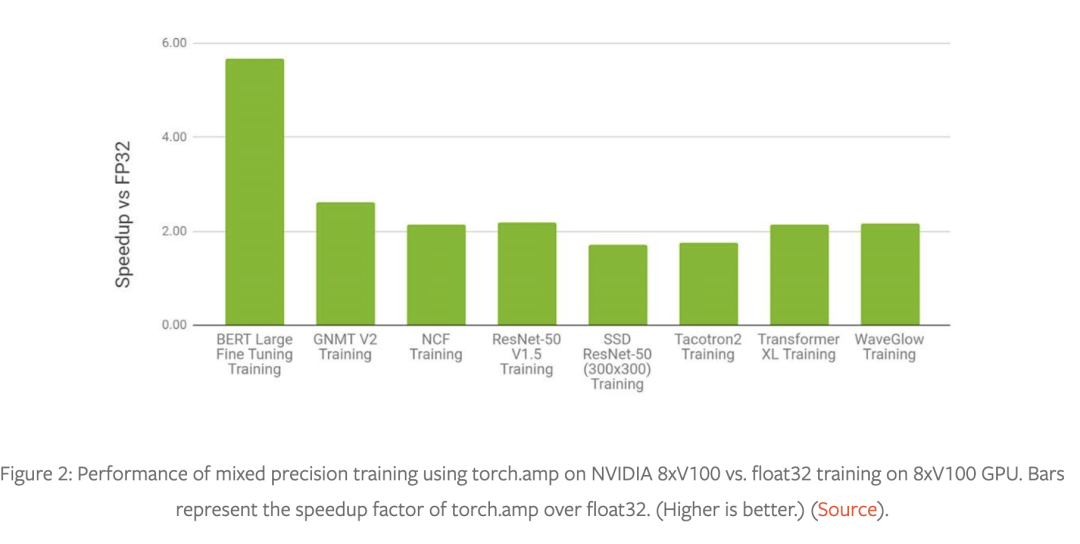
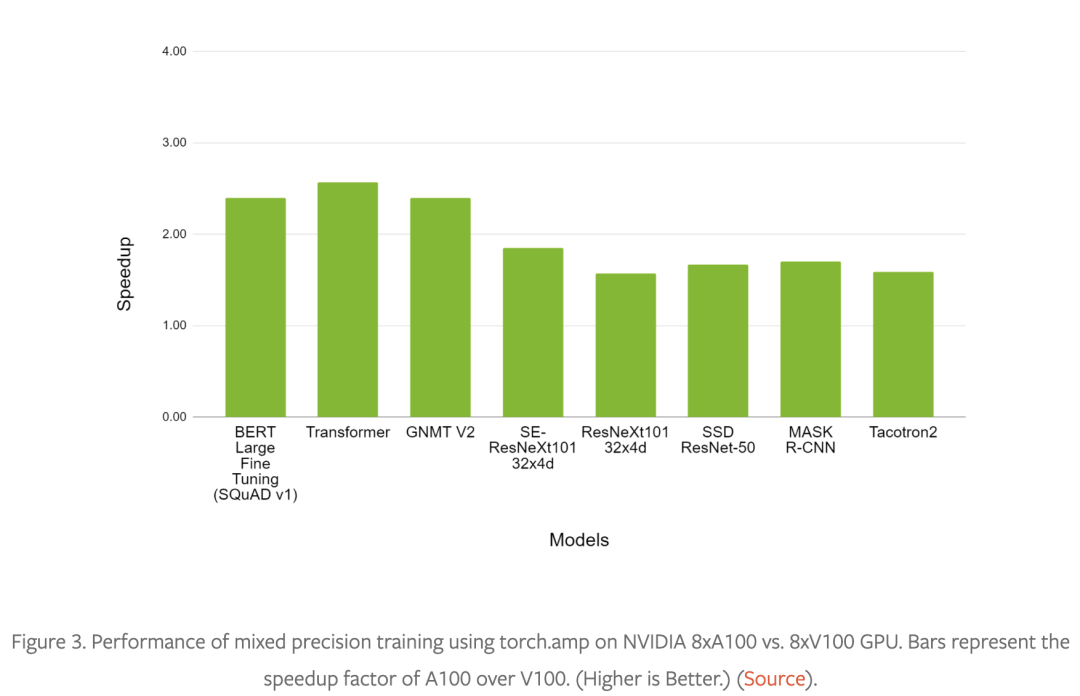
有關(guān)更多示例混合精度工作負(fù)載,請(qǐng)參閱 NVIDIA 深度學(xué)習(xí)示例存儲(chǔ)庫(https://github.com/NVIDIA/DeepLearningExamples)。
在 3D 醫(yī)學(xué)圖像分析、凝視估計(jì)、視頻合成、條件 GAN 和卷積 LSTM 中可以看到類似的性能圖表。黃等人的對(duì)比實(shí)驗(yàn)(https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/)表明混合精度訓(xùn)練在 V100 GPU 上比 float32 快 1.5 到 5.5 倍,在 A100 GPU 上可以再快 1.3 到 2.5 倍。在非常大的網(wǎng)絡(luò)上,對(duì)混合精度的需求更加明顯。https://arxiv.org/pdf/2104.04473.pdf這個(gè)報(bào)告稱在 1024 個(gè) A100 GPU(批量大小為 1536)上訓(xùn)練 GPT-3 175B 需要 34 天,但使用 float32 估計(jì)需要一年多的時(shí)間!
使用torch.amp進(jìn)行混合精度訓(xùn)練
Torch.amp 在 PyTorch 1.6 中引入,使用 float16 或 bfloat16 類型可以輕松利用混合精度訓(xùn)練。有關(guān)更多詳細(xì)信息,請(qǐng)參閱此博客文章(https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/)、教程(https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html)和文檔(https://pytorch.org/docs/master/amp.html)。下面顯示了將具有漸變縮放功能的 AMP 應(yīng)用到網(wǎng)絡(luò)的示例。
import torch
# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()
for data, label in data_iter:
optimizer.zero_grad()
# Casts operations to mixed precision
with torch.amp.autocast(device_type=“cuda”, dtype=torch.float16):
loss = model(data)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration
scaler.update()
選擇正確的方法
使用 float16 或 bfloat16 的開箱即用混合精度訓(xùn)練可有效加速許多深度學(xué)習(xí)模型的收斂,但某些模型可能需要更仔細(xì)的數(shù)值精度管理。以下是一些選項(xiàng):
完整的 float32 精度。默認(rèn)情況下,浮點(diǎn)張量和模塊在 PyTorch 中以 float32 精度創(chuàng)建,但這是一個(gè)歷史性的產(chǎn)物,不能代表訓(xùn)練大多數(shù)現(xiàn)代深度學(xué)習(xí)網(wǎng)絡(luò),網(wǎng)絡(luò)很少需要這么高的數(shù)值精度。
啟用 TensorFloat32 (TF32) 模式。在 Ampere 和更高版本的 CUDA 設(shè)備上,矩陣乘法和卷積可以使用 TensorFloat32 (TF32) 模式進(jìn)行更快但精度稍低的計(jì)算。有關(guān)更多詳細(xì)信息,請(qǐng)參閱使用 NVIDIA TF32 Tensor Cores 博客文章(https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/)加速 AI 訓(xùn)練。默認(rèn)情況下,PyTorch 為卷積啟用 TF32 模式,但不為矩陣乘法啟用,除非網(wǎng)絡(luò)需要完整的 float32 精度,否則我們建議也為矩陣乘法啟用此設(shè)置(有關(guān)如何執(zhí)行此操作,請(qǐng)參閱此處的文檔:https://pytorch.org/docs/master/generated/torch.set_float32_matmul_precision)。它可以顯著加快計(jì)算速度,而數(shù)值精度的損失通常可以忽略不計(jì)。
將 torch.amp 與 bfloat16 或 float16 一起使用。這兩種低精度浮點(diǎn)數(shù)據(jù)類型通常都比較快,但有些網(wǎng)絡(luò)可能只收斂于其中一個(gè)。如果網(wǎng)絡(luò)需要更高的精度,則可能需要使用 float16,如果網(wǎng)絡(luò)需要更大的動(dòng)態(tài)范圍,則可能需要使用 bfloat16,其動(dòng)態(tài)范圍等于 float32。例如,如果觀察到溢出,那么我們建議嘗試 bfloat16。
還有比這里介紹的更高級(jí)的選項(xiàng),例如僅對(duì)模型的一部分使用 torch.amp 的自動(dòng)鑄造,或直接管理混合精度。這些主題在很大程度上超出了本博文的范圍,但請(qǐng)參閱下面的“最佳實(shí)踐”部分。
最佳實(shí)踐
我們強(qiáng)烈建議在訓(xùn)練網(wǎng)絡(luò)時(shí)盡可能將混合精度與 torch.amp 或 TF32 模式(在 Ampere 和更高版本的 CUDA 設(shè)備上)結(jié)合使用。但是,如果其中一種方法不起作用,我們建議以下方法:
高性能計(jì)算 (HPC) 應(yīng)用程序、回歸任務(wù)和生成網(wǎng)絡(luò)可能只需要完整的 float32 IEEE 精度即可按預(yù)期收斂。
嘗試有選擇地應(yīng)用 torch.amp。特別是,我們建議首先在從 torch.linalg 模塊執(zhí)行操作的區(qū)域或在進(jìn)行預(yù)處理或后處理時(shí)禁用它。這些操作通常特別敏感。請(qǐng)注意,TF32 模式是一個(gè)全局開關(guān),不能在網(wǎng)絡(luò)區(qū)域有選擇地使用。首先啟用 TF32 以檢查網(wǎng)絡(luò)運(yùn)營商是否對(duì)該模式敏感,否則禁用它。
如果您在使用 torch.amp 時(shí)遇到類型不匹配,我們不建議您在開始時(shí)插入手動(dòng)轉(zhuǎn)換。此錯(cuò)誤表明網(wǎng)絡(luò)出現(xiàn)問題,通常值得首先調(diào)查。
通過實(shí)驗(yàn)確定您的網(wǎng)絡(luò)是否對(duì)格式的范圍和/或精度敏感。例如,在 float16 中微調(diào) bfloat16 預(yù)訓(xùn)練模型很容易在 float16 中遇到范圍問題,因?yàn)樵?bfloat16 中訓(xùn)練的范圍可能很大,因此如果模型是在 bfloat16 中訓(xùn)練的,用戶應(yīng)該堅(jiān)持使用 bfloat16 微調(diào)。
有關(guān)更多詳細(xì)信息,請(qǐng)參閱 AMP 教程(https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html),使用 Tensor Cores 訓(xùn)練神經(jīng)網(wǎng)絡(luò)(https://nvlabs.github.io/eccv2020-mixed-precision-tutorial/),并參閱 PyTorch 開發(fā)討論中的“浮點(diǎn)精度的更多深入細(xì)節(jié)”一文(https://dev-discuss.pytorch.org/t/more-in-depth-details-of-floating-point-precision/654)。
總結(jié)
混合精度訓(xùn)練是在現(xiàn)代硬件上訓(xùn)練深度學(xué)習(xí)模型的重要工具,隨著較低精度操作和 float32 之間的性能差距在新硬件上不斷擴(kuò)大,它在未來將變得更加重要,如圖 5 所示。
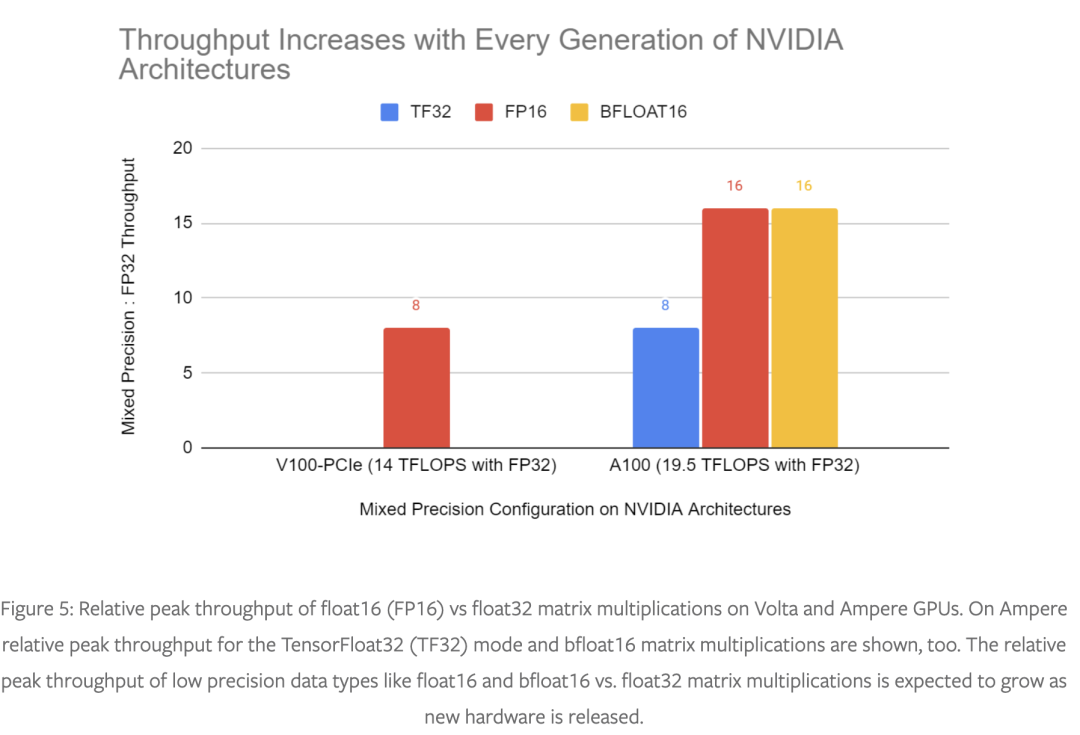
PyTorch 的 torch.amp 模塊可以輕松開始使用混合精度,我們強(qiáng)烈建議使用它來加快訓(xùn)練速度并減少內(nèi)存使用量。torch.amp 支持 float16 和 bfloat16 混合精度。仍然有一些網(wǎng)絡(luò)很難以混合精度進(jìn)行訓(xùn)練,對(duì)于這些網(wǎng)絡(luò),我們建議在 Ampere 和更高版本的 CUDA 硬件上嘗試 TF32 加速矩陣乘法。網(wǎng)絡(luò)很少對(duì)精度如此敏感,以至于每次操作都需要完整的 float32 精度。
本文翻譯自:https://pytorch.org/blog/what-every-user-should-know-about-mixed-precision-training-in-pytorch/
推薦閱讀
輔助模塊加速收斂,精度大幅提升!移動(dòng)端實(shí)時(shí)的NanoDet-Plus來了!
SSD的torchvision版本實(shí)現(xiàn)詳解
機(jī)器學(xué)習(xí)算法工程師
一個(gè)用心的公眾號(hào)
