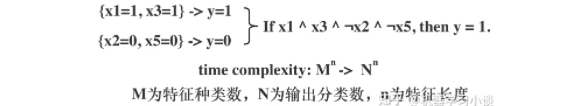一個專注于目標(biāo)檢測與深度學(xué)習(xí)知識分享的公眾號 編者薦語文章以 A Survey on Neural Network Interpretability 讀后感為主,加上作者自身的補充,淺談神經(jīng)網(wǎng)絡(luò)的可解釋性,希望可以給大家?guī)硪恍椭?/span>
轉(zhuǎn)載自 | 圖靈人工智能
鏈接|https://zhuanlan.zhihu.com/p/368755357
論文|https://arxiv.org/abs/2012.14261
本文按照以下的章節(jié)進(jìn)行組織:
人工智能可解釋性的背景意義
神經(jīng)網(wǎng)絡(luò)可解釋性的分類
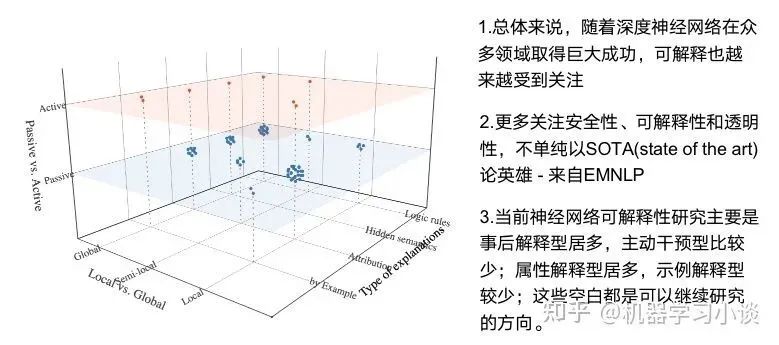
總結(jié)
01 人工智能可解釋性的背景意義1.1 什么是可解釋性Interpretability (of a DNN) is the ability to provide explanations in understandable terms to a human. F Doshi-Velez & B Kim, 2017
解釋(Explanations),是指需要用某種語言來描述和注解
理想情況下,嚴(yán)謹(jǐn)?shù)臄?shù)學(xué)符號-邏輯規(guī)則是最好的解釋(D Pedreschi et al., 2019)。實際上人們往往不強求“完整的解釋”,只需要關(guān)鍵信息和一些先驗知識
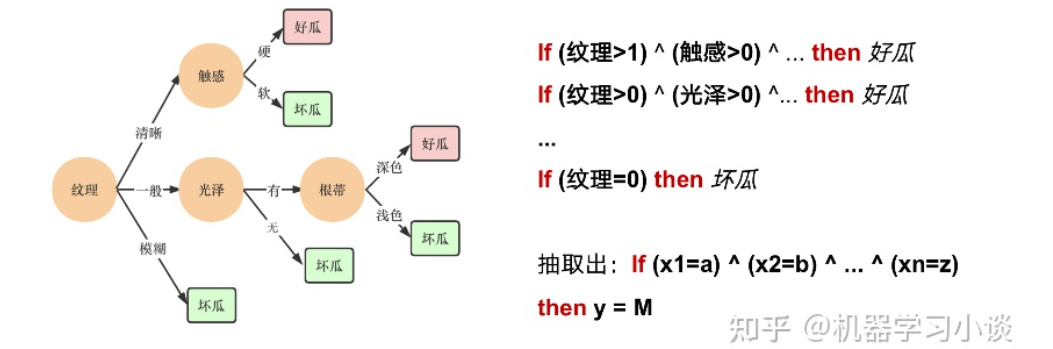
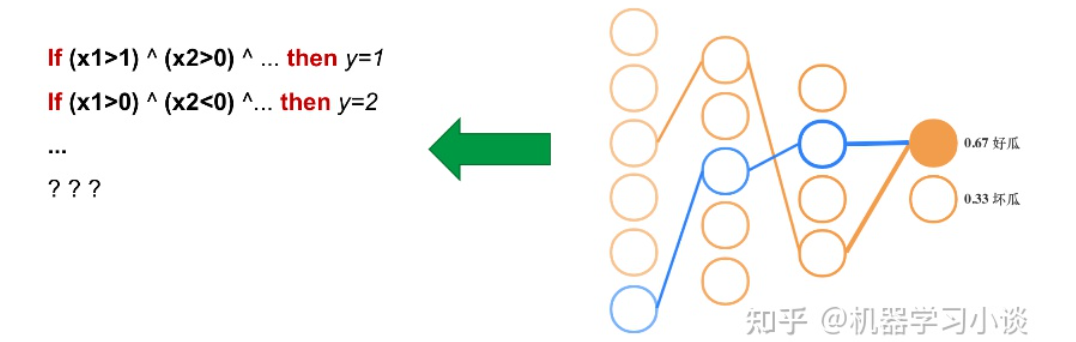
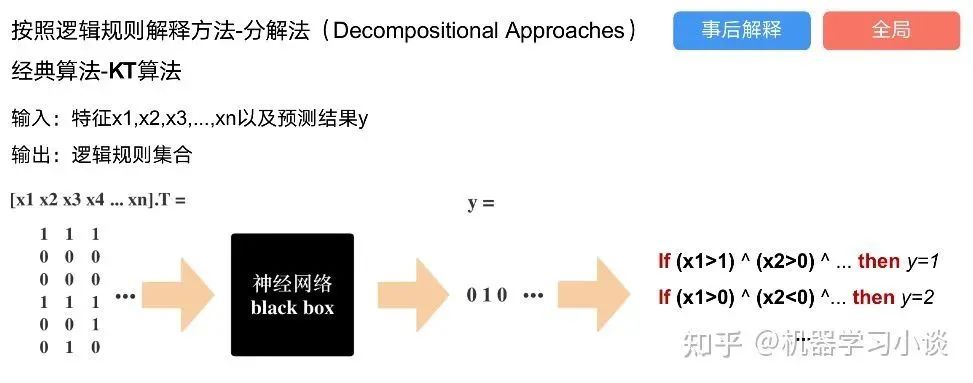
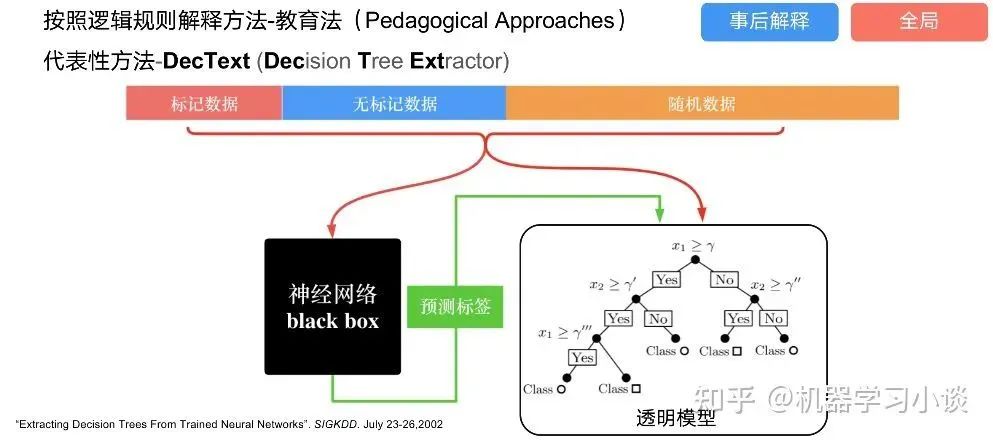
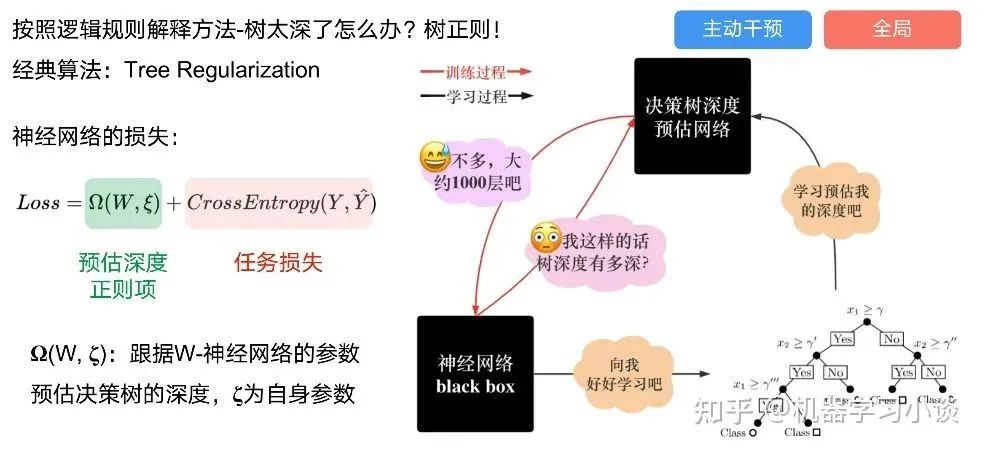
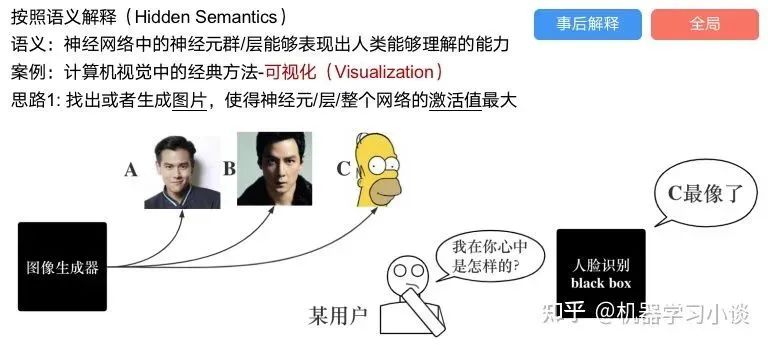
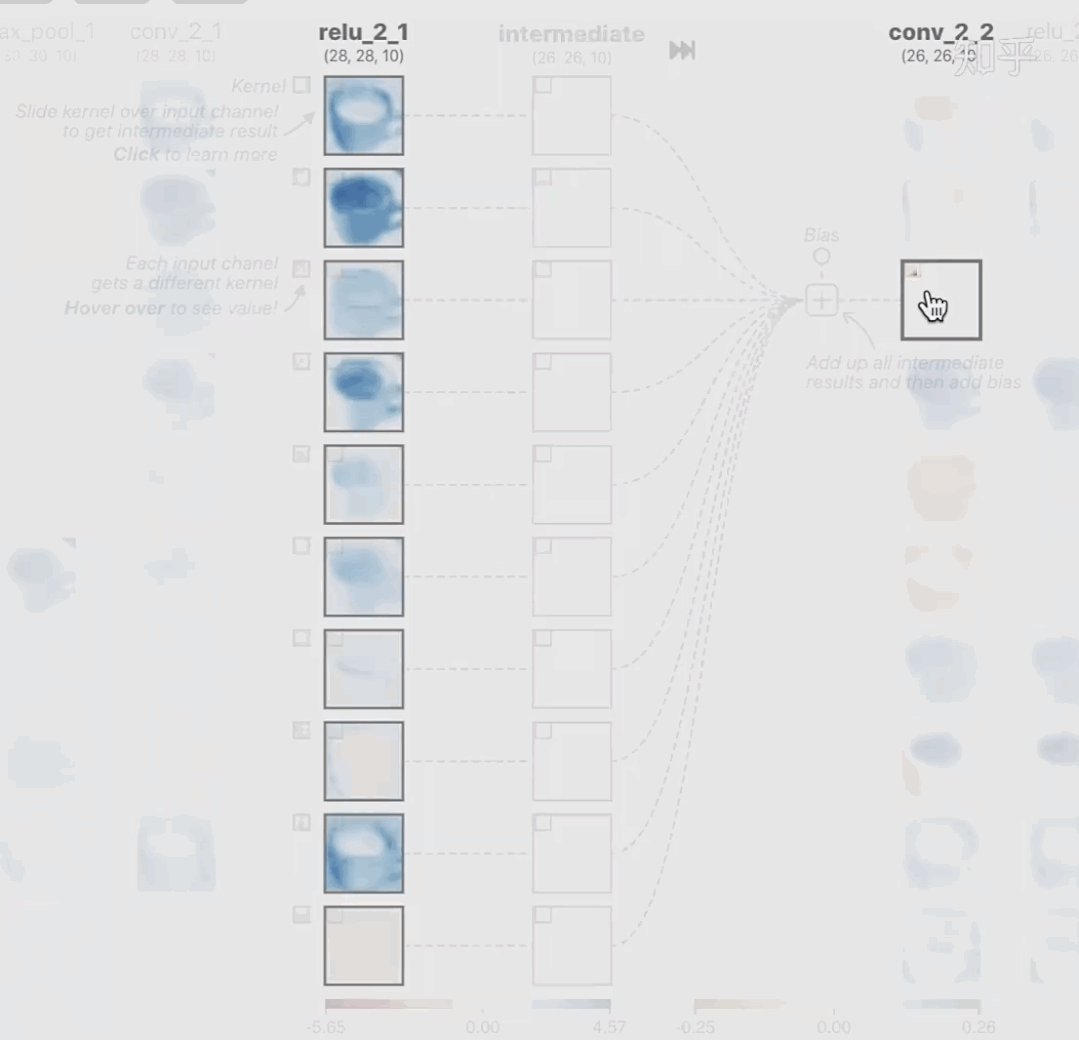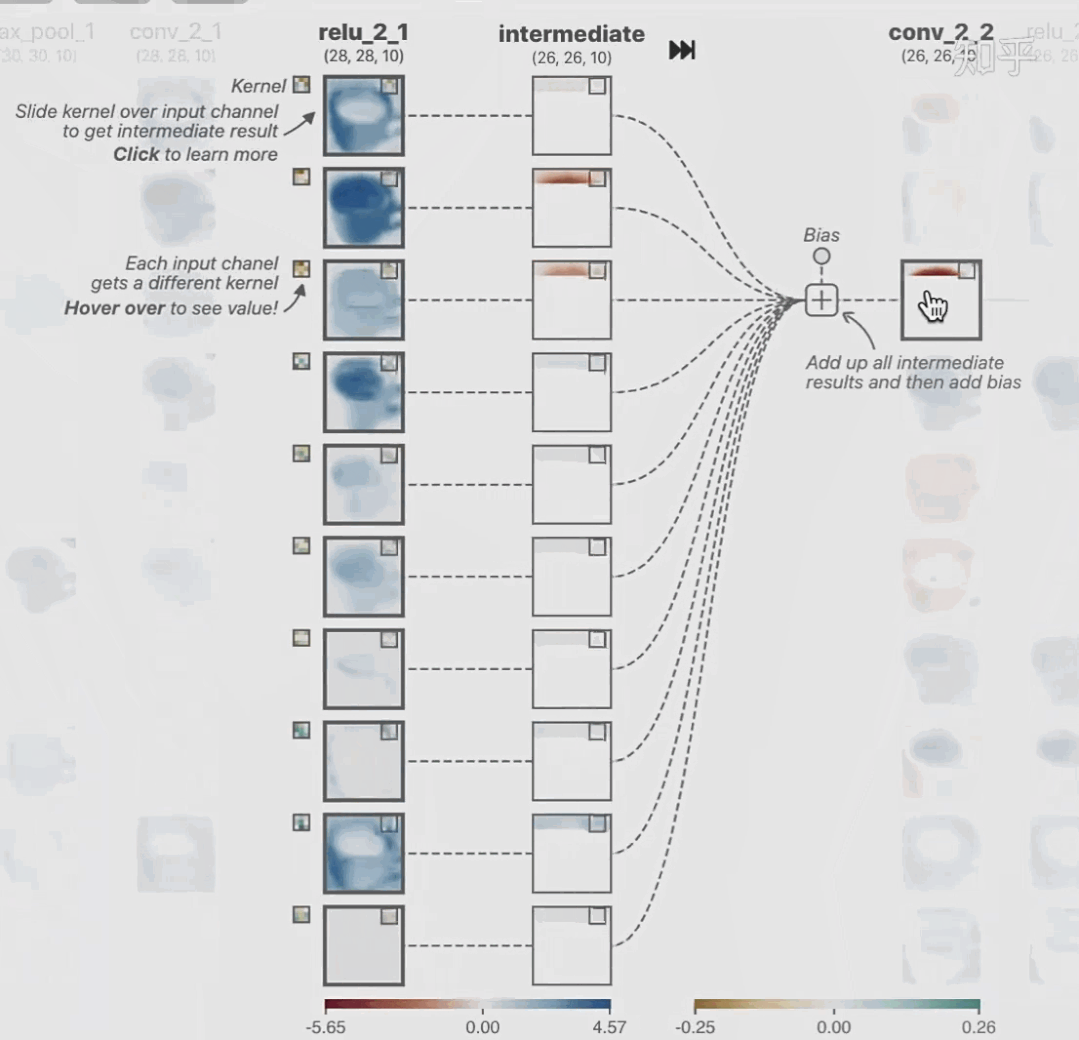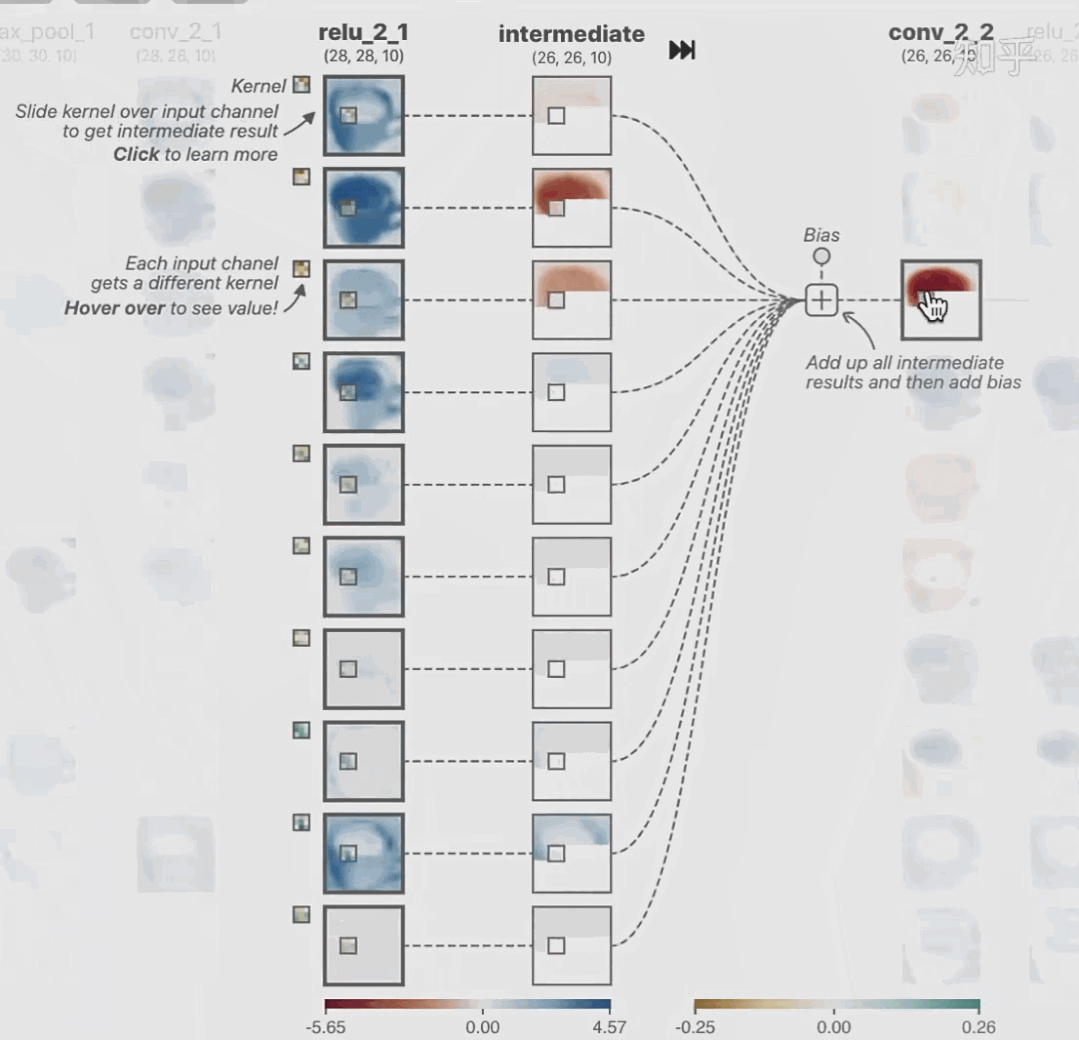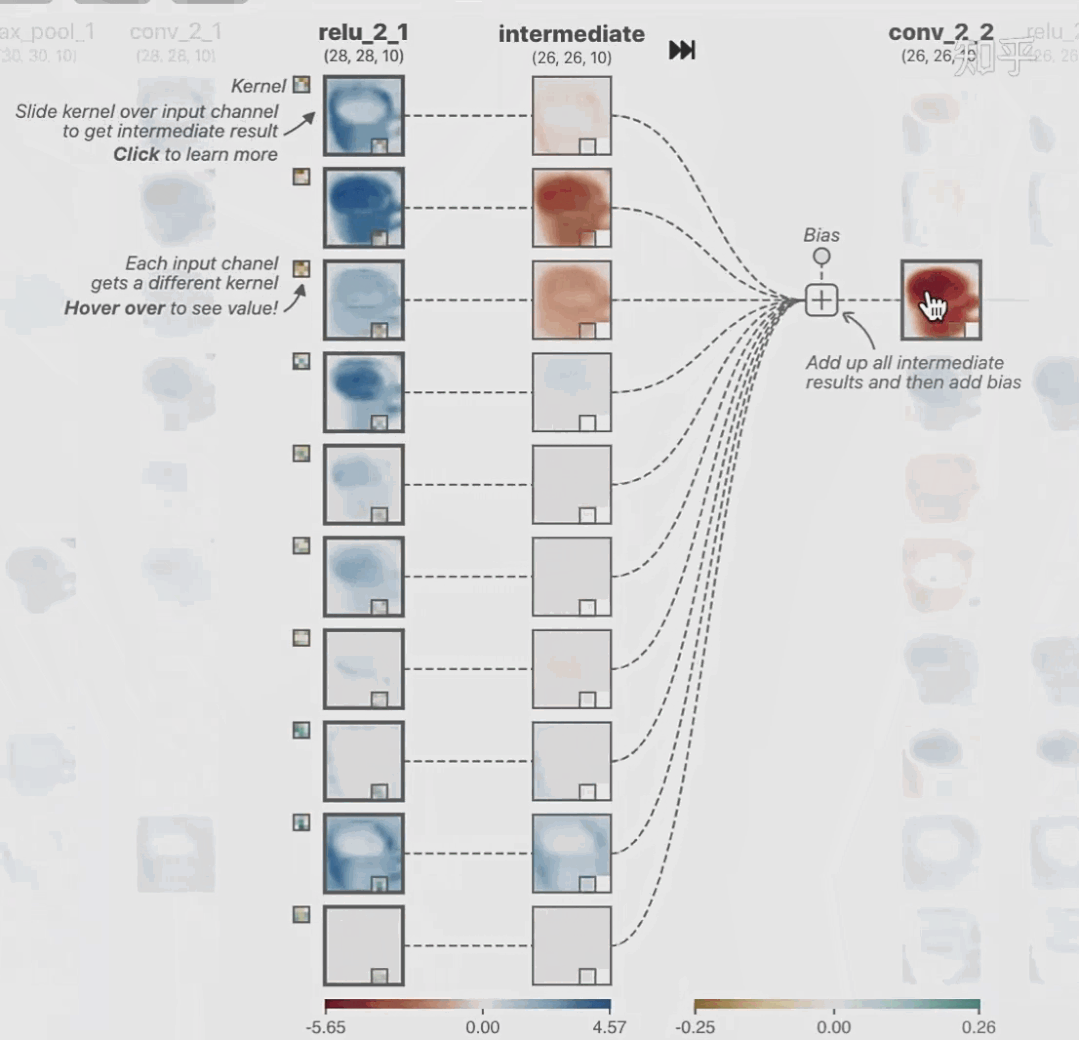
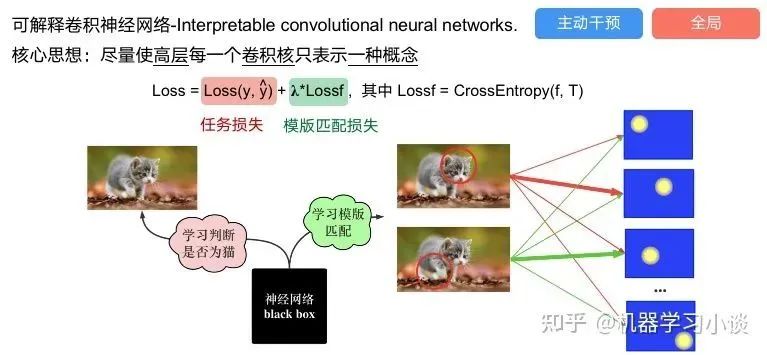
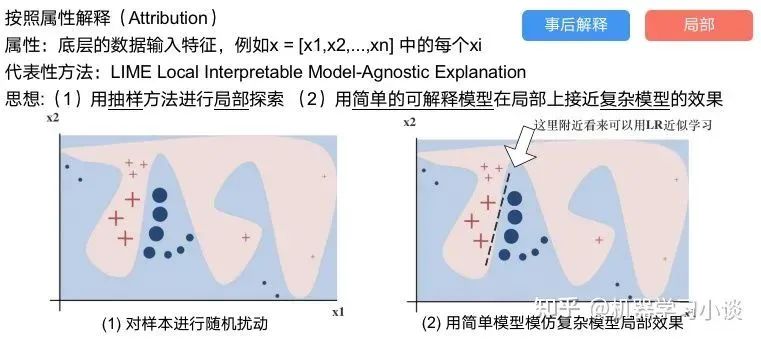
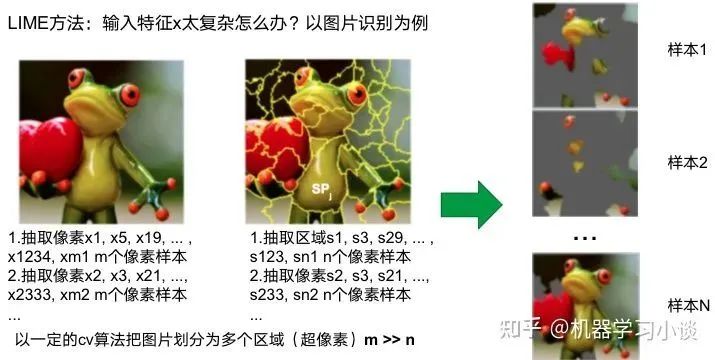
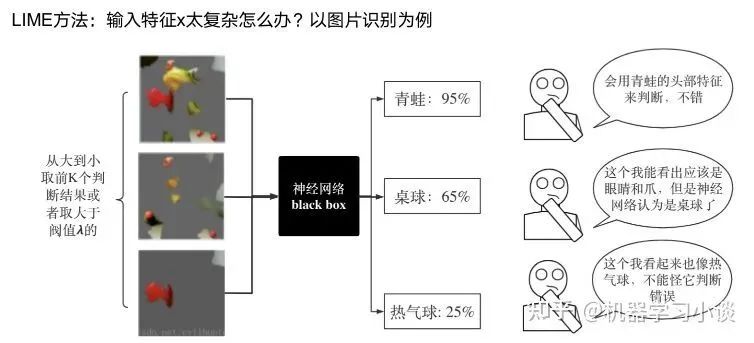
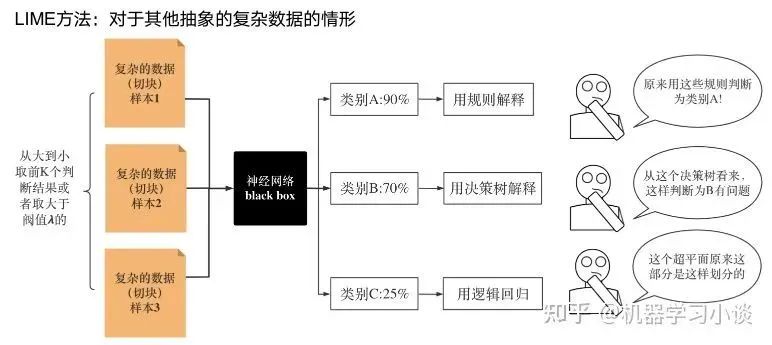
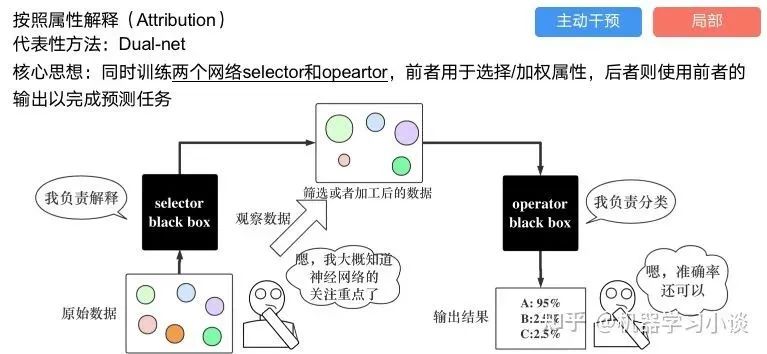
科學(xué)研究可以發(fā)現(xiàn)新知識,可解釋性正是用以揭示背后原理。 02 神經(jīng)網(wǎng)絡(luò)可解釋性的分類2.1 按照邏輯規(guī)則解釋(Rule as Explanation)圖左是一顆關(guān)于判斷西瓜好壞的決策樹,經(jīng)過DFS后,我們可以抽取出右圖的規(guī)則。而對于神經(jīng)網(wǎng)絡(luò),我們是否也可以類似決策樹這樣做呢? 答案是肯定的。 第一種方法是分解法,遍歷所有特征的排列組合分解法最簡單,但是缺點也是顯而易見的,就是時間復(fù)雜度太高,雖然KT算法有所優(yōu)化,但是指數(shù)形式的復(fù)雜度還是難以投入實際使用。于是我們引入第二種方法:教育法[1] DecText-決策樹抽取器,主要采用經(jīng)過黑箱子的數(shù)據(jù)來抽取黑箱子的規(guī)則,并且與其他決策樹不同的是,該方法除了使用標(biāo)記數(shù)據(jù)還可以使用未標(biāo)記數(shù)據(jù)以及隨機(jī)數(shù)據(jù),只要經(jīng)過神經(jīng)網(wǎng)絡(luò)黑箱子都可以獲得標(biāo)簽。對比僅用訓(xùn)練集,由于傳統(tǒng)決策樹進(jìn)行生成葉子比生成其根的可信度還要低(因為能用于劃分界限的數(shù)據(jù)越來越少)。所以DecText有一個優(yōu)勢就是可以利用更多的無標(biāo)記數(shù)據(jù)甚至隨機(jī)數(shù)據(jù)進(jìn)行補充。但是一般論文也不會提及到自身設(shè)計的大多數(shù)缺點。例如,這里我認(rèn)為有兩大缺點。一、無標(biāo)記數(shù)據(jù)或者隨機(jī)數(shù)據(jù)其實有很多是超過解釋的意義,例如人臉識別,如果我們倒入一些不及格的人臉甚至隨機(jī)的圖像,決策樹也會對這些圖像進(jìn)行開枝散葉,降低了真正解釋人臉的枝葉的占比。二、決策樹不能表達(dá)太深的網(wǎng)絡(luò),決策樹越深,性能會急劇下降,可解釋性也越差。Tree Regulartion[2]提出了樹正則的方法,來抑制了樹的深度。樹正則通過引入深度損失正則項,在優(yōu)化時候會抑制樹的深度。而樹的深度則是通過一個簡單的預(yù)估網(wǎng)絡(luò)進(jìn)行預(yù)估,需要的參數(shù)就是主網(wǎng)絡(luò)的參數(shù)。2.2 按照語義進(jìn)行解釋類比人類開始對細(xì)胞解釋的時候,無法一下子直接從細(xì)胞本身理解這個細(xì)胞的類別或者功能,但是可以從細(xì)胞群或者組織(例如表皮細(xì)胞組織)來從宏觀角度了解細(xì)胞的作用。神經(jīng)網(wǎng)絡(luò)亦是如此。例如卷積神經(jīng)網(wǎng)絡(luò),淺層的卷積網(wǎng)絡(luò)往往關(guān)注更基礎(chǔ)的圖像信息例如紋理、顏色等,而越往上層則越能抽象出更豐富的語義,例如人臉識別的眼睛、鼻子等。其中經(jīng)典代表就是計算機(jī)視覺中的經(jīng)典方法-可視化[3]可視化的方法非常多,比如說有一個華人的博士就可視化了CNN,把每一層都展示得非常清楚,只需要在網(wǎng)頁上點擊對于的神經(jīng)元,就可以看到工作流程。右邊是一位維也納的小哥,本來搞unity3D特效開發(fā)的,他把整個CNN網(wǎng)絡(luò)用3d的形式可視化了出來。cnn_visualfeaturemap_layout另外一種主動的按照語義進(jìn)行解釋的代表作:可解釋卷積神經(jīng)網(wǎng)絡(luò)[4](Interpretable convolutional neural networks.)與傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)不同的是,ICNN的每一個卷積核盡量只代表一種概念,例如,傳統(tǒng)的卷積核對貓的頭或者腳都有較大的激活值,而ICNN只能選擇最大的一種。2.3 通過示例解釋這種方法容易理解,是一種直觀方法:尋找和待解釋的樣本最“相似”的一個訓(xùn)練樣本,典型的代表作 Understanding black-box predictions via inflfluence functions,[5]2.4 按照屬性解釋按照屬性解釋目前內(nèi)容上最。如前面提及到,決策樹等透明模型難以模仿復(fù)雜的神經(jīng)網(wǎng)絡(luò),那怎么解決呢?針對此問題研究的代表作有:Why should i trust you?: Explaining the predictions of any classififier[6]由于LIME不介入模型的內(nèi)部,需要不斷的擾動樣本特征,這里所謂的樣本特征就是指圖片中一個一個的像素了。但如果LIME采樣的特征空間太大的話,效率會非常低,而一張普通圖片的像素少說也有上萬個。若直接把每個像素視為一個特征,采樣的空間過于龐大,嚴(yán)重影響效率;如果少采樣一些,最終效果又會比較差。所以針對圖像任務(wù)使用LIME時還需要一些特別的技巧,也就是考慮圖像的空間相關(guān)和連續(xù)的特性。不考慮一些極小特例的情況下,圖片中的物體一般都是由一個或幾個連續(xù)的像素塊構(gòu)成,所謂像素塊是指具有相似紋理、顏色、亮度等特征的相鄰像素構(gòu)成的有一定視覺意義的不規(guī)則像素塊,我們稱之為超像素。下面提供一些主動干預(yù)型的方法,如Dual-net[7]其他的還有:用意想空間的對話系統(tǒng)[8]這種解釋的類型是最有深度而且也是用戶最容易理解的。但是對AI模型和訓(xùn)練難度也更高了。目前這方面的研究屈指可數(shù)。 03 可解釋性總結(jié)