
transformer面試題的簡(jiǎn)單回答
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


來自 | 知乎
作者 | Greene
地址 | https://zhuanlan.zhihu.com/p/363466672
編輯 | 機(jī)器學(xué)習(xí)算法與自然語言處理公眾號(hào)
本文僅作學(xué)術(shù)分享,若侵權(quán),請(qǐng)聯(lián)系后臺(tái)刪文處理
此文章為我在實(shí)驗(yàn)室?guī)У膶?shí)習(xí)生李潛所寫,個(gè)人看了寫得不錯(cuò),要吐槽的請(qǐng)留下正確解答和建設(shè)性意見。
1.Transformer為何使用多頭注意力機(jī)制?(為什么不使用一個(gè)頭)
答:多頭可以使參數(shù)矩陣形成多個(gè)子空間,矩陣整體的size不變,只是改變了每個(gè)head對(duì)應(yīng)的維度大小,這樣做使矩陣對(duì)多方面信息進(jìn)行學(xué)習(xí),但是計(jì)算量和單個(gè)head差不多。
2.Transformer為什么Q和K使用不同的權(quán)重矩陣生成,為何不能使用同一個(gè)值進(jìn)行自身的點(diǎn)乘?
答:請(qǐng)求和鍵值初始為不同的權(quán)重是為了解決可能輸入句長(zhǎng)與輸出句長(zhǎng)不一致的問題。并且假如QK維度一致,如果不用Q,直接拿K和K點(diǎn)乘的話,你會(huì)發(fā)現(xiàn)attention score 矩陣是一個(gè)對(duì)稱矩陣。因?yàn)槭峭瑯右粋€(gè)矩陣,都投影到了同樣一個(gè)空間,所以泛化能力很差。
3.Transformer計(jì)算attention的時(shí)候?yàn)楹芜x擇點(diǎn)乘而不是加法??jī)烧哂?jì)算復(fù)雜度和效果上有什么區(qū)別?
答:K和Q的點(diǎn)乘是為了得到一個(gè)attention score 矩陣,用來對(duì)V進(jìn)行提純。K和Q使用了不同的W_k, W_Q來計(jì)算,可以理解為是在不同空間上的投影。正因?yàn)?有了這種不同空間的投影,增加了表達(dá)能力,這樣計(jì)算得到的attention score矩陣的泛化能力更高。
4.為什么在進(jìn)行softmax之前需要對(duì)attention進(jìn)行scaled(為什么除以dk的平方根),并使用公式推導(dǎo)進(jìn)行講解
答:假設(shè) Q 和 K 的均值為0,方差為1。它們的矩陣乘積將有均值為0,方差為dk,因此使用dk的平方根被用于縮放,因?yàn)椋琎 和 K 的矩陣乘積的均值本應(yīng)該為 0,方差本應(yīng)該為1,這樣可以獲得更平緩的softmax。當(dāng)維度很大時(shí),點(diǎn)積結(jié)果會(huì)很大,會(huì)導(dǎo)致softmax的梯度很小。為了減輕這個(gè)影響,對(duì)點(diǎn)積進(jìn)行縮放。
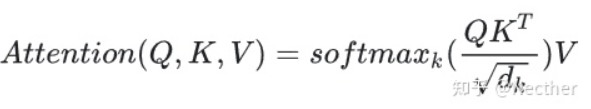
5.在計(jì)算attention score的時(shí)候如何對(duì)padding做mask操作?
答:對(duì)需要mask的位置設(shè)為負(fù)無窮,再對(duì)attention score進(jìn)行相加
6.為什么在進(jìn)行多頭注意力的時(shí)候需要對(duì)每個(gè)head進(jìn)行降維?
答:將原有的高維空間轉(zhuǎn)化為多個(gè)低維空間并再最后進(jìn)行拼接,形成同樣維度的輸出,借此豐富特性信息,降低了計(jì)算量
7.大概講一下Transformer的Encoder模塊?
答:輸入嵌入-加上位置編碼-多個(gè)編碼器層(每個(gè)編碼器層包含全連接層,多頭注意力層和點(diǎn)式前饋網(wǎng)絡(luò)層(包含激活函數(shù)層))
8.為何在獲取輸入詞向量之后需要對(duì)矩陣乘以embedding size的開方?
embedding matrix的初始化方式是xavier init,這種方式的方差是1/embedding size,因此乘以embedding size的開方使得embedding matrix的方差是1,在這個(gè)scale下可能更有利于embedding matrix的收斂。
9.簡(jiǎn)單介紹一下Transformer的位置編碼?有什么意義和優(yōu)缺點(diǎn)?
答:因?yàn)閟elf-attention是位置無關(guān)的,無論句子的順序是什么樣的,通過self-attention計(jì)算的token的hidden embedding都是一樣的,這顯然不符合人類的思維。因此要有一個(gè)辦法能夠在模型中表達(dá)出一個(gè)token的位置信息,transformer使用了固定的positional encoding來表示token在句子中的絕對(duì)位置信息。
10.你還了解哪些關(guān)于位置編碼的技術(shù),各自的優(yōu)缺點(diǎn)是什么?
答:相對(duì)位置編碼(RPE)1.在計(jì)算attention score和weighted value時(shí)各加入一個(gè)可訓(xùn)練的表示相對(duì)位置的參數(shù)。2.在生成多頭注意力時(shí),把對(duì)key來說將絕對(duì)位置轉(zhuǎn)換為相對(duì)query的位置3.復(fù)數(shù)域函數(shù),已知一個(gè)詞在某個(gè)位置的詞向量表示,可以計(jì)算出它在任何位置的詞向量表示。前兩個(gè)方法是詞向量+位置編碼,屬于亡羊補(bǔ)牢,復(fù)數(shù)域是生成詞向量的時(shí)候即生成對(duì)應(yīng)的位置信息。
11.簡(jiǎn)單講一下Transformer中的殘差結(jié)構(gòu)以及意義。
答:encoder和decoder的self-attention層和ffn層都有殘差連接。反向傳播的時(shí)候不會(huì)造成梯度消失。
12.為什么transformer塊使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
答:多頭注意力層和激活函數(shù)層之間。CV使用BN是認(rèn)為channel維度的信息對(duì)cv方面有重要意義,如果對(duì)channel維度也歸一化會(huì)造成不同通道信息一定的損失。而同理nlp領(lǐng)域認(rèn)為句子長(zhǎng)度不一致,并且各個(gè)batch的信息沒什么關(guān)系,因此只考慮句子內(nèi)信息的歸一化,也就是LN。
13.簡(jiǎn)答講一下BatchNorm技術(shù),以及它的優(yōu)缺點(diǎn)。
答:批歸一化是對(duì)每一批的數(shù)據(jù)在進(jìn)入激活函數(shù)前進(jìn)行歸一化,可以提高收斂速度,防止過擬合,防止梯度消失,增加網(wǎng)絡(luò)對(duì)數(shù)據(jù)的敏感度。
14.簡(jiǎn)單描述一下Transformer中的前饋神經(jīng)網(wǎng)絡(luò)?使用了什么激活函數(shù)?相關(guān)優(yōu)缺點(diǎn)?
答:輸入嵌入-加上位置編碼-多個(gè)編碼器層(每個(gè)編碼器層包含全連接層,多頭注意力層和點(diǎn)式前饋網(wǎng)絡(luò)層(包含激活函數(shù)層))-多個(gè)解碼器層(每個(gè)編碼器層包含全連接層,多頭注意力層和點(diǎn)式前饋網(wǎng)絡(luò)層)-全連接層,使用了relu激活函數(shù)
15.Encoder端和Decoder端是如何進(jìn)行交互的?
答:通過轉(zhuǎn)置encoder_ouput的seq_len維與depth維,進(jìn)行矩陣兩次乘法,即q*kT*v輸出即可得到target_len維度的輸出
16.Decoder階段的多頭自注意力和encoder的多頭自注意力有什么區(qū)別?
答:Decoder有兩層mha,encoder有一層mha,Decoder的第二層mha是為了轉(zhuǎn)化輸入與輸出句長(zhǎng),Decoder的請(qǐng)求q與鍵k和數(shù)值v的倒數(shù)第二個(gè)維度可以不一樣,但是encoder的qkv維度一樣。
17.Transformer的并行化提現(xiàn)在哪個(gè)地方?
答:Transformer的并行化主要體現(xiàn)在self-attention模塊,在Encoder端Transformer可以并行處理整個(gè)序列,并得到整個(gè)輸入序列經(jīng)過Encoder端的輸出,但是rnn只能從前到后的執(zhí)行
18.Decoder端可以做并行化嗎?
訓(xùn)練的時(shí)候可以,但是交互的時(shí)候不可以
18.簡(jiǎn)單描述一下wordpiece model 和 byte pair encoding,有實(shí)際應(yīng)用過嗎?
答“傳統(tǒng)詞表示方法無法很好的處理未知或罕見的詞匯(OOV問題)
傳統(tǒng)詞tokenization方法不利于模型學(xué)習(xí)詞綴之間的關(guān)系”
BPE(字節(jié)對(duì)編碼)或二元編碼是一種簡(jiǎn)單的數(shù)據(jù)壓縮形式,其中最常見的一對(duì)連續(xù)字節(jié)數(shù)據(jù)被替換為該數(shù)據(jù)中不存在的字節(jié)。后期使用時(shí)需要一個(gè)替換表來重建原始數(shù)據(jù)。
優(yōu)點(diǎn):可以有效地平衡詞匯表大小和步數(shù)(編碼句子所需的token次數(shù))。
缺點(diǎn):基于貪婪和確定的符號(hào)替換,不能提供帶概率的多個(gè)分片結(jié)果。
19.Transformer訓(xùn)練的時(shí)候?qū)W習(xí)率是如何設(shè)定的?Dropout是如何設(shè)定的,位置在哪里?Dropout 在測(cè)試的需要有什么需要注意的嗎?
LN是為了解決梯度消失的問題,dropout是為了解決過擬合的問題。在embedding后面加LN有利于embedding matrix的收斂。
20.bert的mask為何不學(xué)習(xí)transformer在attention處進(jìn)行屏蔽score的技巧?
答:BERT和transformer的目標(biāo)不一致,bert是語言的預(yù)訓(xùn)練模型,需要充分考慮上下文的關(guān)系,而transformer主要考慮句子中第i個(gè)元素與前i-1個(gè)元素的關(guān)系。
推薦閱讀
國(guó)產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營(yíng)維護(hù)的號(hào),大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!