
【Python】改進(jìn)探索性數(shù)據(jù)分析的實(shí)用技巧!
譯者:張峰,Datawhale成員
讓 EDA 更簡單(更美觀)的實(shí)用指南!
原文鏈接:https://towardsdatascience.com/practical-tips-for-improving-exploratory-data-analysis-1c43b3484577
介紹
探索性數(shù)據(jù)分析(EDA)是使用任何機(jī)器學(xué)習(xí)模型前的必經(jīng)步驟。EDA 過程需要數(shù)據(jù)分析師和數(shù)據(jù)科學(xué)家的專注和耐心:在從分析數(shù)據(jù)中獲得有意義的見解之前,通常需要花費(fèi)大量時(shí)間主動使用一個(gè)或多個(gè)可視化庫。
在本篇文章中,我將根據(jù)個(gè)人經(jīng)驗(yàn)與大家分享一些如何簡化 EDA 程序并使其更便捷的技巧。特別是,我將向大家介紹在與 EDA 作“死磕”的過程中學(xué)到的三條重要技巧:
1.使用最適合你的任務(wù)的非平凡圖表;
2.充分利用可視化庫的功能;
3.尋找制作相同內(nèi)容的更快方法。
注:在本篇文章中,我們將使用 Kaggle [2] 提供的風(fēng)能數(shù)據(jù)制作信息圖表。讓我們開始吧!
技巧1:不要害怕使用非平凡圖表
我在撰寫與風(fēng)能分析和預(yù)測相關(guān)的研究論文[1]時(shí),學(xué)會了如何應(yīng)用這一技巧。在為這個(gè)項(xiàng)目做 EDA 時(shí),我需要?jiǎng)?chuàng)建一個(gè)匯總矩陣來反映風(fēng)能參數(shù)之間的所有關(guān)系,以便找出哪些參數(shù)對彼此的影響最大。我腦海中浮現(xiàn)的第一個(gè)想法是建立一個(gè) “老式” 相關(guān)矩陣,我曾在許多數(shù)據(jù)科學(xué)/數(shù)據(jù)分析項(xiàng)目中看到過這種矩陣。
眾所周知,相關(guān)矩陣用于量化和總結(jié)變量之間的線性關(guān)系。在下面的代碼片段中,對風(fēng)能數(shù)據(jù)的特征列使用了 corrcoef 函數(shù)。在這里,我還應(yīng)用了 Seaborn 的熱圖函數(shù),將相關(guān)矩陣陣列繪制成熱力圖:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 讀取數(shù)據(jù)
data = pd.read_csv('T1.csv')
print(data)
# 為列重命名,使其標(biāo)題更簡短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
cols = ['P', 'Ws', 'Power_curve', 'Wa']
# 建立矩陣
correlation_matrix = np.corrcoef(data[cols].values.T)
hm = sns.heatmap(correlation_matrix,
cbar=True, annot=True, square=True, fmt='.3f',
annot_kws={'size': 15},
cmap='Blues',
yticklabels=['P', 'Ws', 'Power_curve', 'Wa'],
xticklabels=['P', 'Ws', 'Power_curve', 'Wa'])
# 保存圖表
plt.savefig('image.png', dpi=600, bbox_inches='tight')
plt.show()
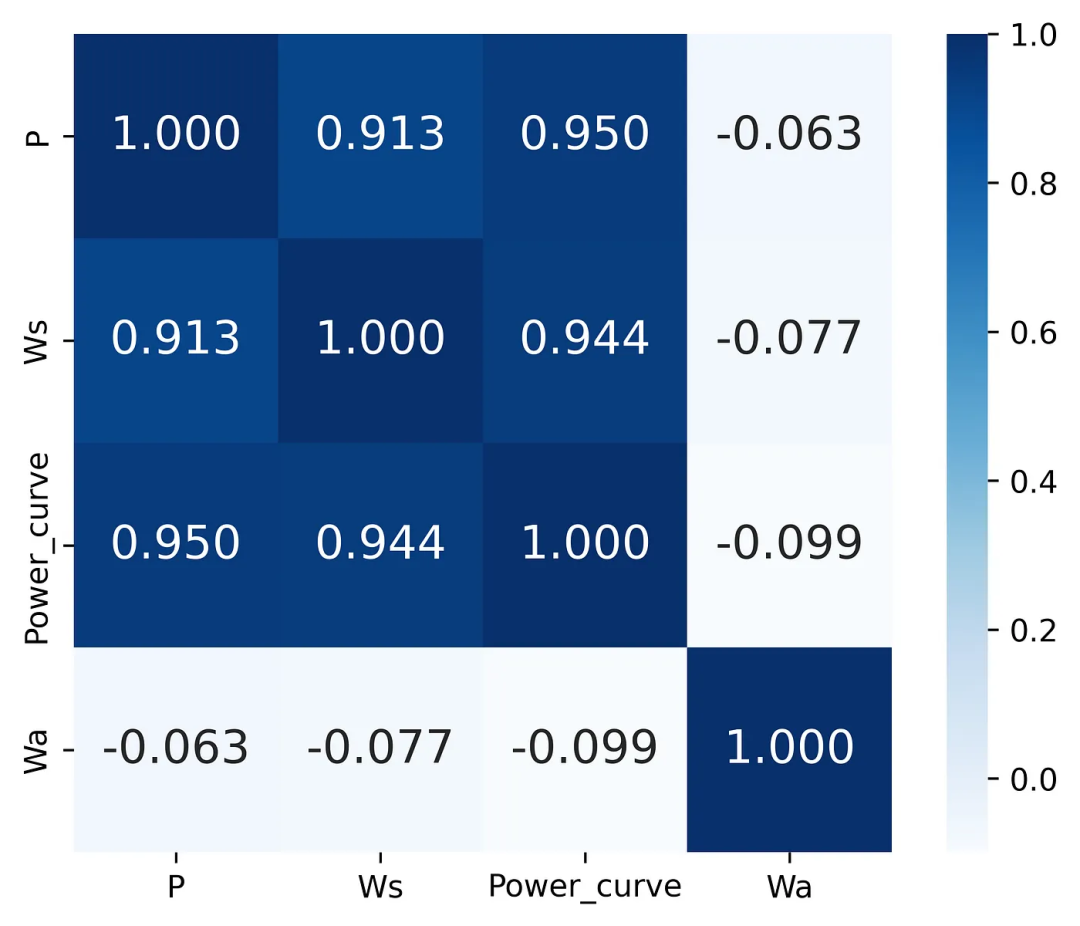
圖1 建立的相關(guān)矩陣示例
通過對圖表結(jié)果的分析,我們可以得出結(jié)論:風(fēng)速和有效功率具有很強(qiáng)的相關(guān)性,但我想很多人都會同意我的觀點(diǎn),即在使用這種可視化方法時(shí),這并不是一種解釋結(jié)果的簡單方法,因?yàn)檫@里我們只有數(shù)字。
散點(diǎn)圖矩陣是相關(guān)矩陣的一個(gè)很好的替代品,它可以讓你在一個(gè)地方直觀地看到數(shù)據(jù)集不同特征之間的成對相關(guān)性。在這種情況下,應(yīng)使用 sns.pairplot:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 讀取數(shù)據(jù)
data = pd.read_csv('T1.csv')
print(data)
# 為列重命名,使其標(biāo)題更簡短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
cols = ['P', 'Ws', 'Power_curve', 'Wa']
# 建立矩陣
sns.pairplot(data[cols], height=2.5)
plt.tight_layout()
# 保存圖表
plt.savefig('image2.png', dpi=600, bbox_inches='tight')
plt.show()
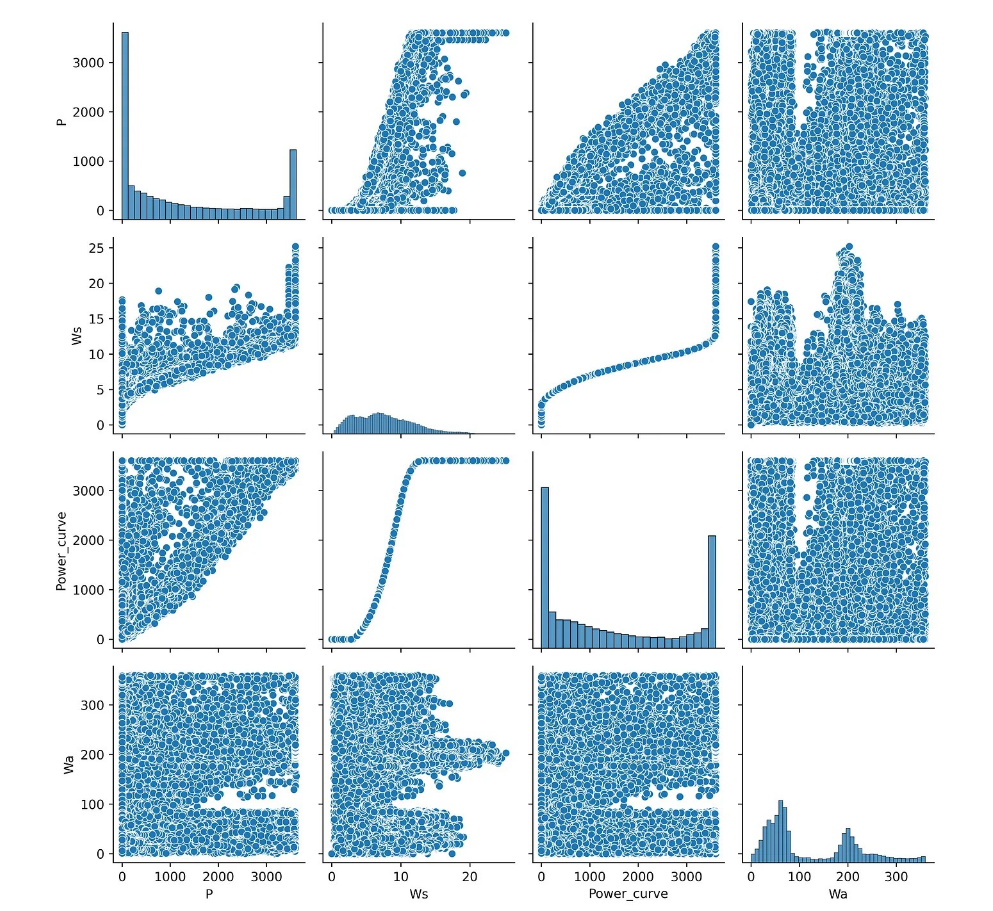
圖2 散點(diǎn)圖矩陣示例
通過觀察散點(diǎn)圖矩陣,我們可以快速目測數(shù)據(jù)的分布情況以及是否包含異常值。不過,這種圖表的主要缺點(diǎn)是,由于采用成對方式繪制數(shù)據(jù),會出現(xiàn)重復(fù)數(shù)據(jù)。
最后,我決定將上述圖表合二為一,其中左下部分將包含所選參數(shù)的散點(diǎn)圖,右上部分將包含不同大小和顏色的氣泡:圓圈越大,表示所研究參數(shù)的線性相關(guān)性越強(qiáng)。矩陣的對角線將顯示每個(gè)特征的分布情況:這里的窄峰值表示該特定參數(shù)變化不大,而其他特征會發(fā)生變化。
構(gòu)建匯總表的代碼如下。這里的地圖由三個(gè)部分組成:fig.map_lower、fig.map_diag 和 fig.map_upper:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 讀取數(shù)據(jù)
data = pd.read_csv('T1.csv')
print(data)
# 為列重命名,使其標(biāo)題更簡短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
cols = ['P', 'Ws', 'Power_curve', 'Wa']
# 建立矩陣
def correlation_dots(*args, **kwargs):
corr_r = args[0].corr(args[1], 'pearson')
ax = plt.gca()
ax.set_axis_off()
marker_size = abs(corr_r) * 3000
ax.scatter([.5], [.5], marker_size,
[corr_r], alpha=0.5,
cmap = 'Blues',
vmin = -1, vmax = 1,
transform = ax.transAxes)
font_size = abs(corr_r) * 40 + 5
sns.set(style = 'white', font_scale = 1.6)
fig = sns.PairGrid(data, aspect = 1.4, diag_sharey = False)
fig.map_lower(sns.regplot)
fig.map_diag(sns.histplot)
fig.map_upper(correlation_dots)
# 保存圖表
plt.savefig('image3.jpg', dpi = 600, bbox_inches = 'tight')
plt.show()
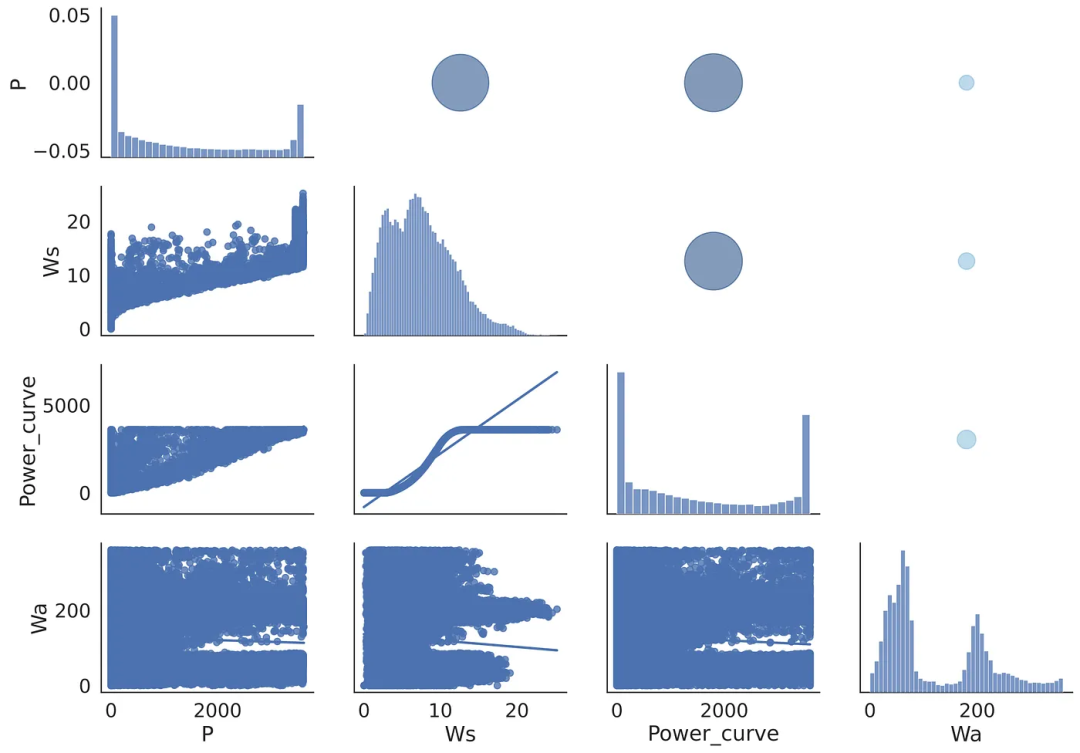
圖3 匯總表示例
匯總表結(jié)合了之前研究過的兩種圖表的優(yōu)點(diǎn)——其下部(左側(cè))模仿散點(diǎn)圖矩陣,其上部(右側(cè))片段以圖形方式反映了相關(guān)矩陣的數(shù)值結(jié)果。
技巧 2:充分利用可視化庫的功能
我時(shí)常需要向同事和客戶介紹 EDA 的成果,因此可視化是我完成這項(xiàng)任務(wù)的重要助手。我總是嘗試在圖表中添加各種元素,如箭頭和注釋,使圖表更具吸引力和可讀性。
讓我們回到上文討論的風(fēng)能項(xiàng)目 EDA 實(shí)施案例。說到風(fēng)能,最重要的參數(shù)之一就是功率曲線。風(fēng)力渦輪機(jī)(或整個(gè)風(fēng)電場)的功率曲線是一張顯示不同風(fēng)速下發(fā)電量的圖表。值得注意的是,渦輪機(jī)不會在低風(fēng)速下運(yùn)行。它們的啟動與切入速度有關(guān),切入速度通常在 2.5-5 米/秒之間。當(dāng)風(fēng)速在 12 至 15 米/秒之間時(shí),渦輪機(jī)可達(dá)到額定功率。最后,每臺渦輪機(jī)都有一個(gè)安全運(yùn)行的風(fēng)速上限。一旦達(dá)到這個(gè)極限,風(fēng)力渦輪機(jī)將無法發(fā)電,除非風(fēng)速降回運(yùn)行范圍內(nèi)。
所研究的數(shù)據(jù)集包括理論功率曲線(這是制造商提供的典型曲線,沒有任何異常值)和實(shí)際曲線(如果我們繪制風(fēng)力功率與風(fēng)速的關(guān)系曲線)。后者通常包含許多超出理想理論形狀的點(diǎn),這可能是由于風(fēng)機(jī)故障、SCADA 測量錯(cuò)誤或計(jì)劃外維護(hù)造成的。
現(xiàn)在,我們將創(chuàng)建一張圖片 ,同時(shí)顯示兩種類型的風(fēng)力曲線——首先,除了圖例外,不帶任何附加項(xiàng):
import pandas as pd
import matplotlib.pyplot as plt
# 讀取數(shù)據(jù)
data = pd.read_csv('T1.csv')
print(data)
# 為列重命名,使其標(biāo)題更簡短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
# 建立圖表
plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='actual')
plt.scatter(data['Ws'], data['Power_curve'], color='black', label='theoretical')
plt.xlabel('Wind Speed')
plt.ylabel('Power')
plt.legend(loc='best')
# 保存圖表
plt.savefig('image4.png', dpi=600, bbox_inches='tight')
plt.show()
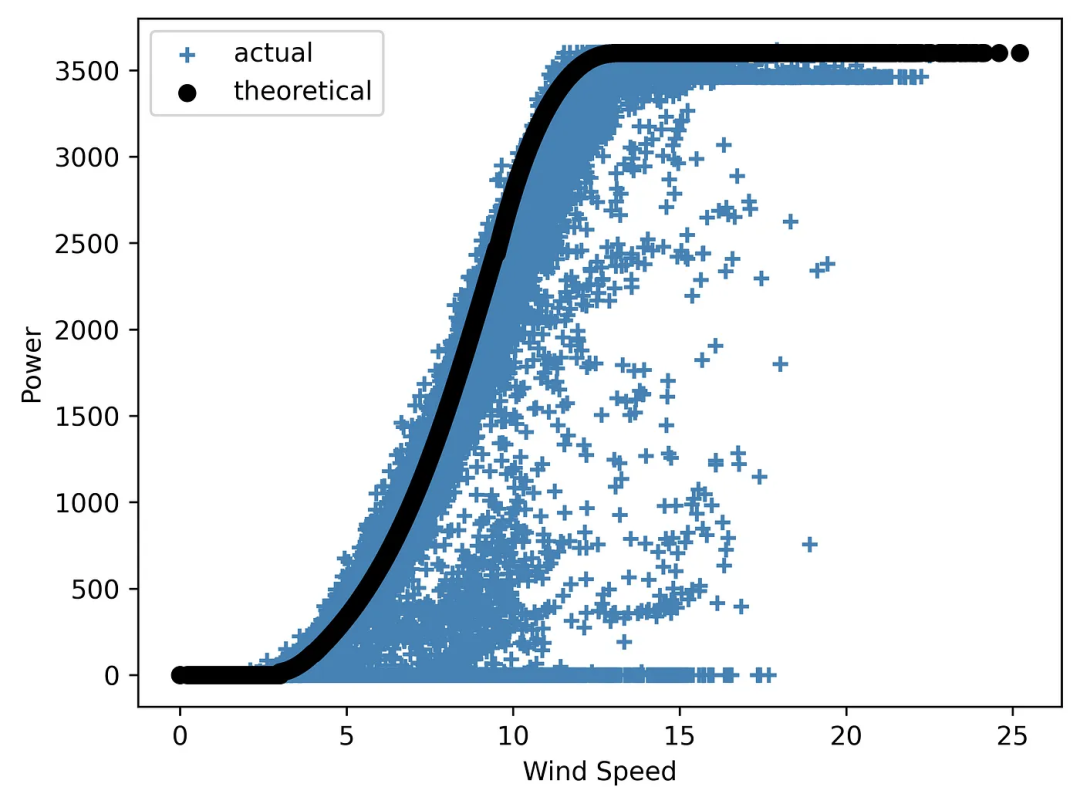
圖4 一張 “沉默無語” 的風(fēng)能曲線圖
如你所見,該圖需要解釋,因?yàn)樗话魏纹渌?xì)節(jié)。
但是,如果我們添加線條來突出顯示圖表中的三個(gè)主要區(qū)域,標(biāo)明切入速度、額定速度和切出速度,并添加帶箭頭的注釋來顯示其中一個(gè)異常值,又會怎樣呢?
讓我們來看看這種情況下的圖表效果如何:
import pandas as pd
import matplotlib.pyplot as plt
# 讀取數(shù)據(jù)
data = pd.read_csv('T1.csv')
print(data)
# 為列重命名,使其標(biāo)題更簡短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
# 建立圖表
plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='actual')
plt.scatter(data['Ws'], data['Power_curve'], color='black', label='theoretical')
# 添加垂直線、文字注釋和箭頭
plt.vlines(x=3.05, ymin=10, ymax=350, lw=3, color='black')
plt.text(1.1, 355, r"cut-in", fontsize=15)
plt.vlines(x=12.5, ymin=3000, ymax=3500, lw=3, color='black')
plt.text(13.5, 2850, r"nominal", fontsize=15)
plt.vlines(x=24.5, ymin=3080, ymax=3550, lw=3, color='black')
plt.text(21.5, 2900, r"cut-out", fontsize=15)
plt.annotate('outlier!', xy=(18.4,1805), xytext=(21.5,2050),
arrowprops={'color':'red'})
plt.xlabel('Wind Speed')
plt.ylabel('Power')
plt.legend(loc='best')
# 保存圖表
plt.savefig('image4_2.png', dpi=600, bbox_inches='tight')
plt.show()
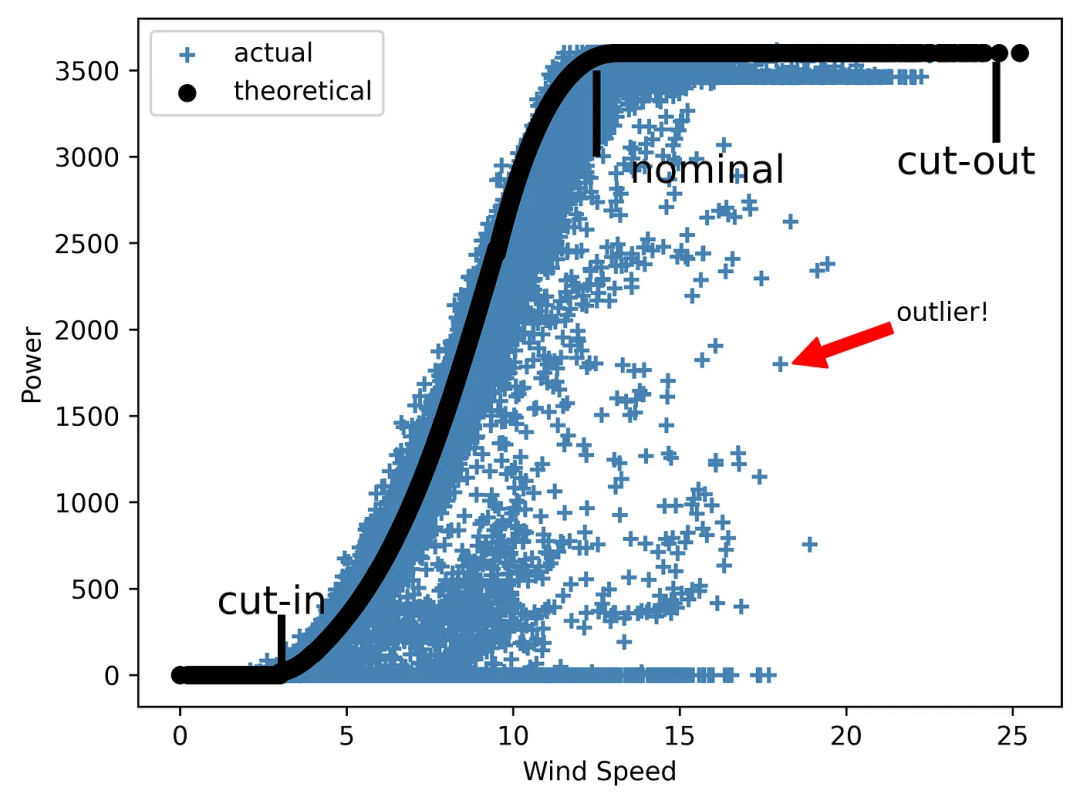
圖5 一張 “能說會道” 的風(fēng)能曲線圖
技巧 3:總是能找到更快的制作方法
在分析風(fēng)能數(shù)據(jù)時(shí),我們通常希望獲得有關(guān)風(fēng)能潛在的全面信息。因此,除了風(fēng)能的動態(tài)變化外,還需要有一個(gè)圖表來顯示風(fēng)速如何隨風(fēng)向變化。
為了說明風(fēng)能的變化,可以使用以下代碼:
import pandas as pd
import matplotlib.pyplot as plt
# 讀取數(shù)據(jù)
data = pd.read_csv('T1.csv')
print(data)
# 為列重命名,使其標(biāo)題更簡短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
# 將 10 分鐘數(shù)據(jù)重采樣為每小時(shí)測量值
data['Date/Time'] = pd.to_datetime(data['Date/Time'])
fig = plt.figure(figsize=(10,8))
group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()
# 繪制風(fēng)能動態(tài)圖
group_data.plot(kind='line')
plt.ylabel('Power')
plt.xlabel('Date/Time')
plt.title('Power generation (resampled to 1 hour)')
# 保存圖表
plt.savefig('wind_power.png', dpi=600, bbox_inches='tight')
plt.show()
下圖是繪制的結(jié)果:
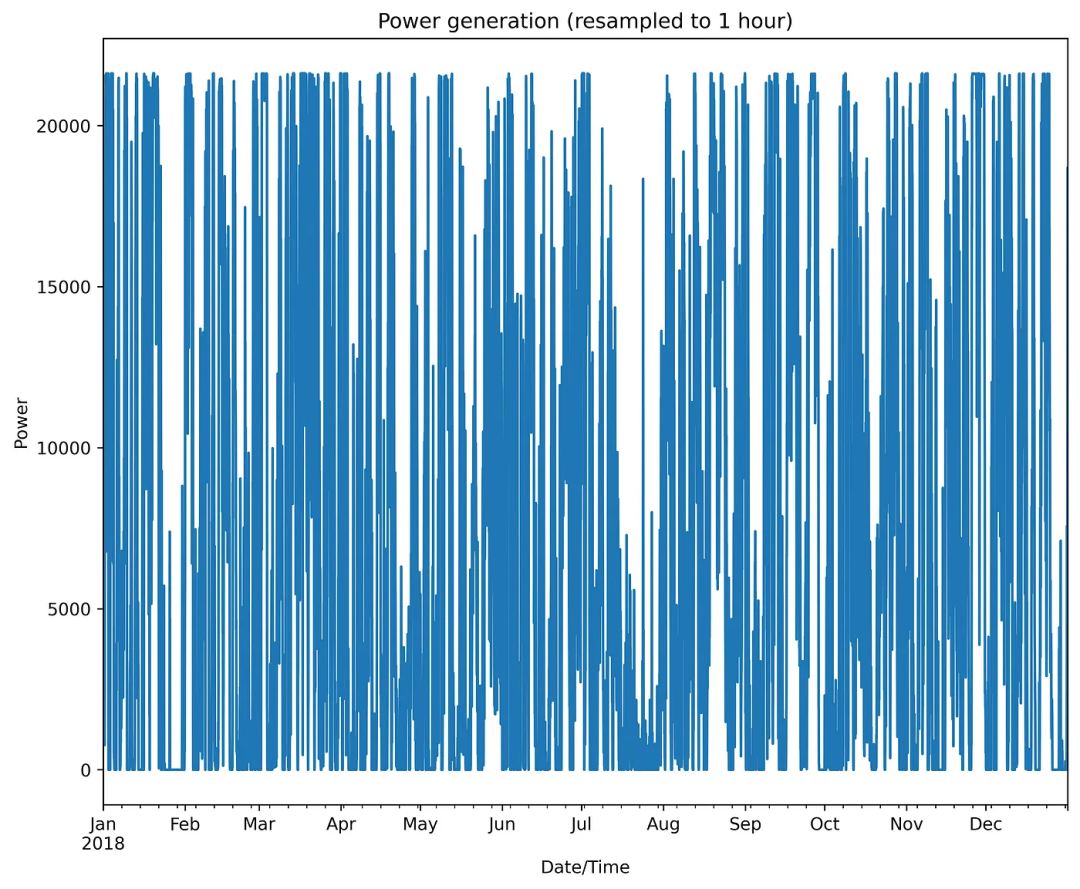
圖6 風(fēng)能的動態(tài)變化
正如人們可能注意到的那樣,風(fēng)能的動態(tài)輪廓具有相當(dāng)復(fù)雜的不規(guī)則形狀。
風(fēng)玫瑰圖(windrose)或極玫瑰圖(polar rose plot)是一種特殊的圖表,用于表示氣象數(shù)據(jù)的分布,通常是風(fēng)速的方向分布[3]。matplotlib 庫中有一個(gè)簡單的模塊 windrose,可以輕松構(gòu)建這類可視化圖,例如:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from windrose import WindroseAxes
# 讀取數(shù)據(jù)
data = pd.read_csv('T1.csv')
print(data)
#為列重命名,使其標(biāo)題更簡短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
wd = data['Wa']
ws = data['Ws']
# 以堆疊直方圖的形式繪制正態(tài)化風(fēng)玫瑰圖
ax = WindroseAxes.from_ax()
ax.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')
ax.set_legend()
# 保存圖表
plt.savefig('windrose.png', dpi = 600, bbox_inches = 'tight')
plt.show()
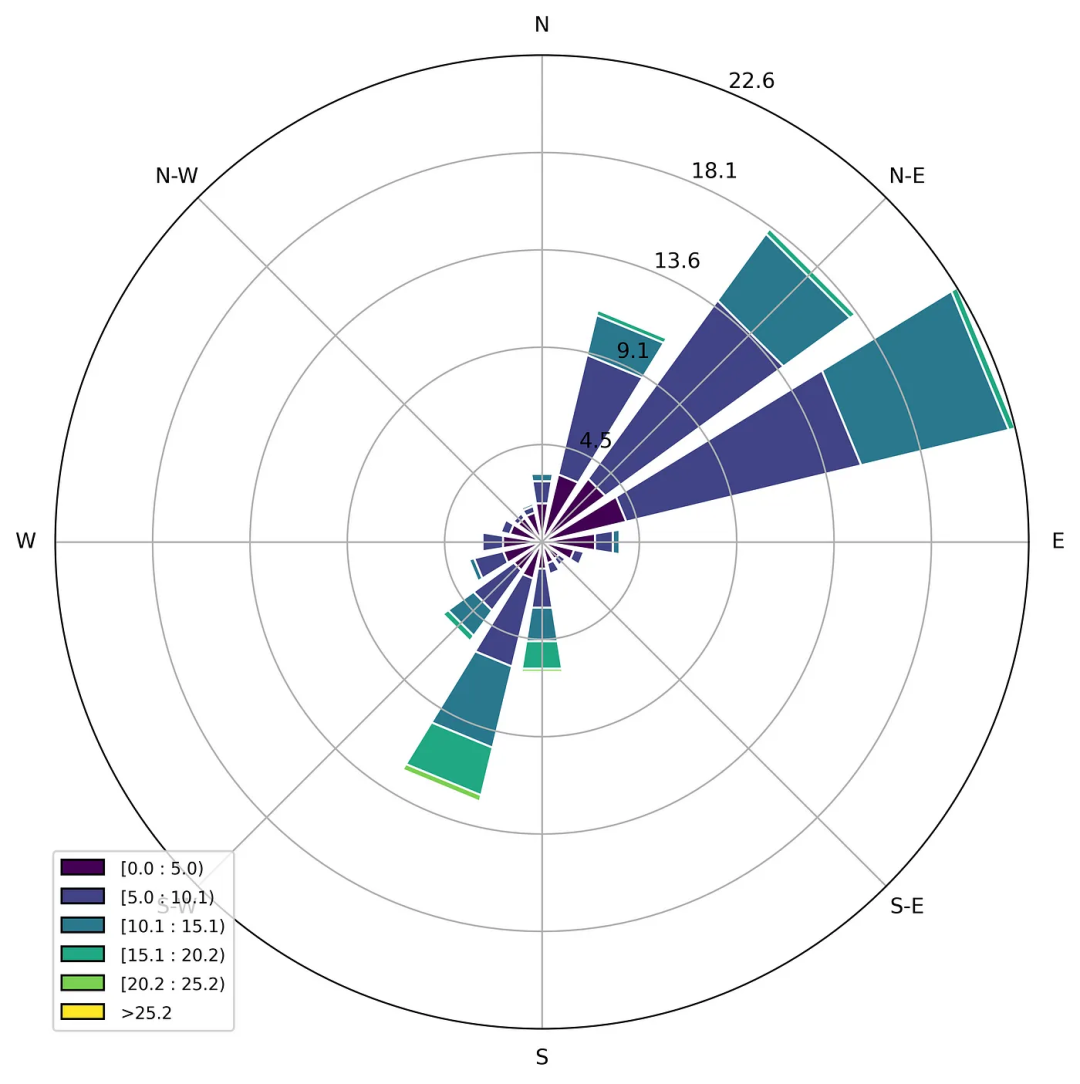
圖7 根據(jù)現(xiàn)有數(shù)據(jù)得出的風(fēng)玫瑰圖
觀察風(fēng)玫瑰圖,可以發(fā)現(xiàn)有兩個(gè)主要風(fēng)向——東北風(fēng)和西南風(fēng)。
但如何將這兩張圖片合并成一張呢?最明顯的辦法是使用 add_subplot。但由于 windrose 庫的特殊性,這并不是一項(xiàng)簡單的任務(wù):
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from windrose import WindroseAxes
# 讀取數(shù)據(jù)
data = pd.read_csv('T1.csv')
print(data)
# 為列重命名,使其標(biāo)題更簡短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
data['Date/Time'] = pd.to_datetime(data['Date/Time'])
fig = plt.figure(figsize=(10,8))
# 將兩個(gè)圖都繪制為子圖
ax1 = fig.add_subplot(211)
group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()
group_data.plot(kind='line')
ax1.set_ylabel('Power')
ax1.set_xlabel('Date/Time')
ax1.set_title('Power generation (resampled to 1 hour)')
ax2 = fig.add_subplot(212, projection='windrose')
wd = data['Wa']
ws = data['Ws']
ax = WindroseAxes.from_ax()
ax2.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')
ax2.set_legend()
# 保存圖表
plt.savefig('image5.png', dpi=600, bbox_inches='tight')
plt.show()
在這種情況下,結(jié)果是這樣的:
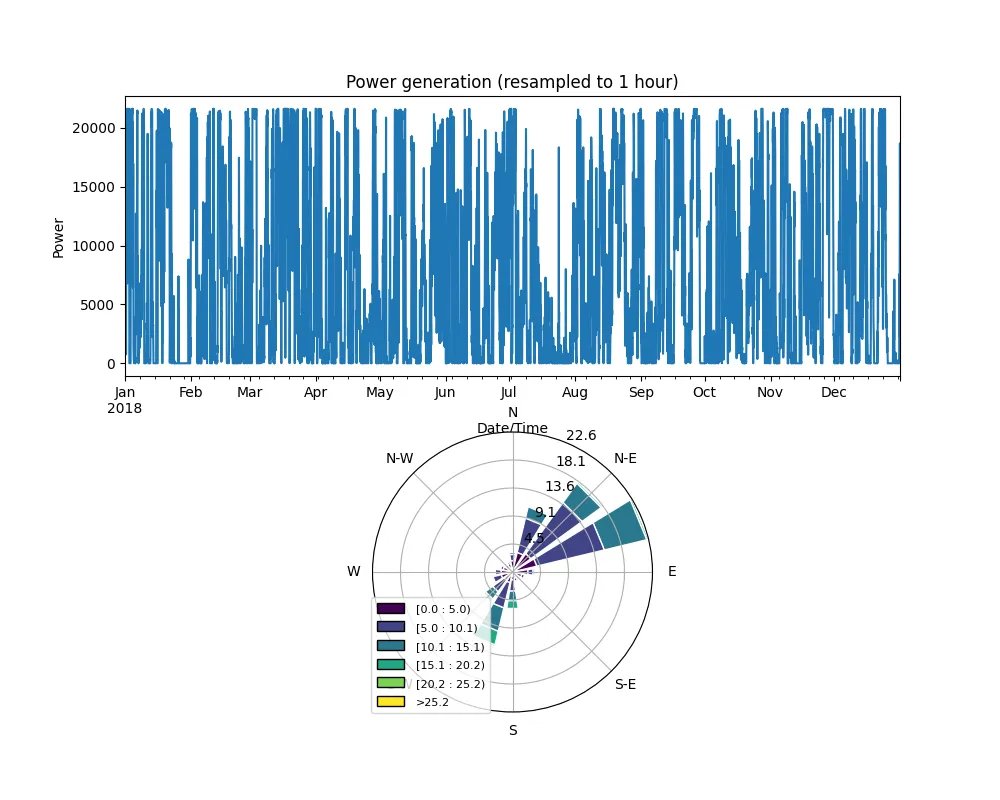
圖8 單張圖片 顯示風(fēng)能動態(tài)和風(fēng)玫瑰圖
這樣做的主要缺點(diǎn)是兩個(gè)子圖的大小不同,因此風(fēng)玫瑰圖周圍有很多空白。
為了方便起見,我建議采用另一種方法,使用 Python Imaging Library (PIL) [4],只需十幾行代碼:
import numpy as np
import PIL
from PIL import Image
# 列出需要合并的圖片
list_im = ['wind_power.png','windrose.png']
imgs = [PIL.Image.open(i) for i in list_im]
# 調(diào)整所有圖片的大小,使其與最小圖片相匹配
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
# 對于垂直堆疊,我們使用 vstack
images_comb = np.vstack((np.asarray(i.resize(min_shape)) for i in imgs))
images_comb = PIL.Image.fromarray(imgs_comb)
# 保存圖表
imgages_comb.save('image5_2.png', dpi=(600,600))
這里的輸出看起來更漂亮一些,兩張圖片的尺寸相同,這是因?yàn)榇a選擇最小的圖片,并重新縮放其他圖片來進(jìn)行匹配:
使用 PIL 獲取的包含風(fēng)能動力和風(fēng)玫瑰圖的單一圖片
順便說一下,在使用 PIL 時(shí),我們還可以使用水平堆疊法,例如,我們可以將 “沉默無語” 和 “能說會道” 的風(fēng)力曲線圖進(jìn)行比較和對比:
import numpy as np
import PIL
from PIL import Image
list_im = ['image4.png','image4_2.png']
imgs = [PIL.Image.open(i) for i in list_im]
# 選取最小的圖片 ,并調(diào)整其他圖片 的大小以與之匹配(此處可任意調(diào)整圖片形狀)
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
imgs_comb = np.hstack((np.asarray(i.resize(min_shape)) for i in imgs))
# 保存圖表
imgs_comb = PIL.Image.fromarray(imgs_comb)
imgs_comb.save('image4_merged.png', dpi=(600,600))
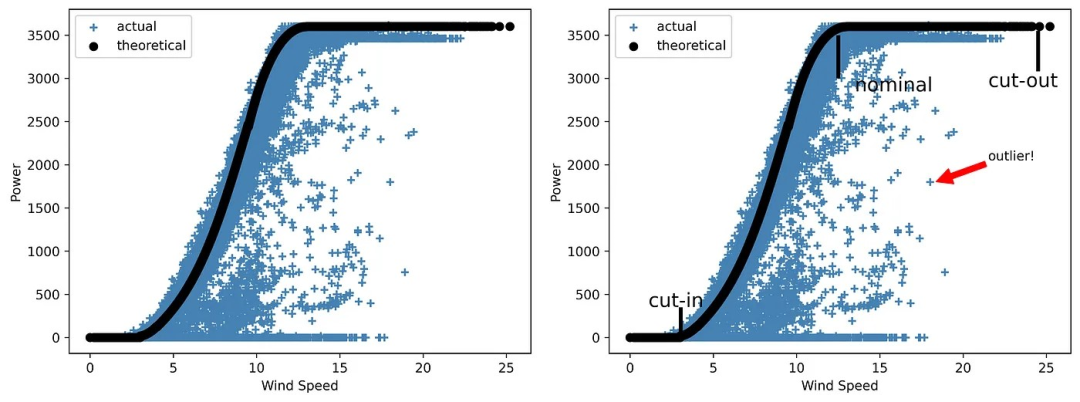
圖9 比較和對比兩張風(fēng)力曲線圖
結(jié)論
在這篇文章中,我與大家分享了如何讓 EDA 流程更輕松的三個(gè)技巧。我希望這些建議對學(xué)習(xí)者有用,并開始將它們應(yīng)用到你的數(shù)據(jù)任務(wù)中。
這些技巧完全符合我在進(jìn)行 EDA 時(shí)一直嘗試應(yīng)用的公式:定制 → 逐項(xiàng) → 優(yōu)化。
你可能會問,這到底有什么關(guān)系呢?我可以說,這其實(shí)很重要,因?yàn)椋?/p>
- 根據(jù)當(dāng)前的特定需求定制圖表非常重要。例如,與其制作大量的信息圖表,不如考慮如何將幾個(gè)圖表合并成一個(gè),就像我們在制作匯總矩陣時(shí)所做的那樣,它結(jié)合了散點(diǎn)圖和相關(guān)圖的優(yōu)點(diǎn)。
- 所有圖表都應(yīng)該為自己代言。因此,你需要知道如何在圖表中逐項(xiàng)列出重要內(nèi)容,使其詳細(xì)易讀。比較 “沉默無語” 和 “能說會道” 的功率曲線之間的差別有多大。
- 最后,每一位數(shù)據(jù)專家都應(yīng)該學(xué)習(xí)如何優(yōu)化 EDA 流程,使工作更便捷(生活更輕松)。如果需要將兩幅圖片合并成一幅,不必總是使用 add_subplot 選項(xiàng)。
還有什么?我可以肯定地說,在處理數(shù)據(jù)的過程中,EDA 是一個(gè)非常有創(chuàng)意和有趣的步驟(更何況它還超級重要)。
讓你的信息圖表像鉆石一樣閃閃發(fā)光,別忘了享受這個(gè)過程!
參考文獻(xiàn)列表
- 風(fēng)能分析和預(yù)測的數(shù)據(jù)驅(qū)動應(yīng)用:The case of “La Haute Borne” wind farm. https://doi.org/10.1016/j.dche.2022.100048
- 風(fēng)能數(shù)據(jù):https://www.kaggle.com/datasets/bhavikjikadara/wind-power-generated-data?resource=download
- 關(guān)于 windrose 庫的教程:https://windrose.readthedocs.io/en/latest/index.html
- PIL 庫:https://pillow.readthedocs.io/en/stable/index.html
往期 精彩 回顧
- 適合初學(xué)者入門人工智能的路線及資料下載
- (圖文+視頻)機(jī)器學(xué)習(xí)入門系列下載
- 機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印
- 《統(tǒng)計(jì)學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯
-
機(jī)器學(xué)習(xí)交流qq群772479961,加入微信群請 掃碼 -