在說分布式事務(wù)之前,我們先從數(shù)據(jù)庫(kù)事務(wù)說起。數(shù)據(jù)庫(kù)事務(wù)可能大家都很熟悉,在開發(fā)過程中也會(huì)經(jīng)常使用到。但是即使如此,可能對(duì)于一些細(xì)節(jié)問題,很多人仍然不清楚。比如很多人都知道數(shù)據(jù)庫(kù)事務(wù)的幾個(gè)特性:原子性(Atomicity )、一致性( Consistency )、隔離性或獨(dú)立性( Isolation)和持久性(Durabilily),簡(jiǎn)稱就是ACID。但是再往下比如問到隔離性指的是什么的時(shí)候可能就不知道了,或者是知道隔離性是什么但是再問到數(shù)據(jù)庫(kù)實(shí)現(xiàn)隔離的都有哪些級(jí)別,或者是每個(gè)級(jí)別他們有什么區(qū)別的時(shí)候可能就不知道了。本文并不打算介紹這些數(shù)據(jù)庫(kù)事務(wù)的這些東西,有興趣可以搜索一下相關(guān)資料。不過有一個(gè)知識(shí)點(diǎn)我們需要了解,就是假如數(shù)據(jù)庫(kù)在提交事務(wù)的時(shí)候突然斷電,那么它是怎么樣恢復(fù)的呢?為什么要提到這個(gè)知識(shí)點(diǎn)呢?因?yàn)榉植际较到y(tǒng)的核心就是處理各種異常情況,這也是分布式系統(tǒng)復(fù)雜的地方,因?yàn)榉植际降木W(wǎng)絡(luò)環(huán)境很復(fù)雜,這種“斷電”故障要比單機(jī)多很多,所以我們?cè)谧龇植际较到y(tǒng)的時(shí)候,最先考慮的就是這種情況。這些異常可能有 機(jī)器宕機(jī)、網(wǎng)絡(luò)異常、消息丟失、消息亂序、數(shù)據(jù)錯(cuò)誤、不可靠的TCP、存儲(chǔ)數(shù)據(jù)丟失、其他異常等等...我們接著說本地事務(wù)數(shù)據(jù)庫(kù)斷電的這種情況,它是怎么保證數(shù)據(jù)一致性的呢?我們使用SQL Server來舉例,我們知道我們?cè)谑褂?SQL Server 數(shù)據(jù)庫(kù)是由兩個(gè)文件組成的,一個(gè)數(shù)據(jù)庫(kù)文件和一個(gè)日志文件,通常情況下,日志文件都要比數(shù)據(jù)庫(kù)文件大很多。數(shù)據(jù)庫(kù)進(jìn)行任何寫入操作的時(shí)候都是要先寫日志的,同樣的道理,我們?cè)趫?zhí)行事務(wù)的時(shí)候數(shù)據(jù)庫(kù)首先會(huì)記錄下這個(gè)事務(wù)的redo操作日志,然后才開始真正操作數(shù)據(jù)庫(kù),在操作之前首先會(huì)把日志文件寫入磁盤,那么當(dāng)突然斷電的時(shí)候,即使操作沒有完成,在重新啟動(dòng)數(shù)據(jù)庫(kù)時(shí)候,數(shù)據(jù)庫(kù)會(huì)根據(jù)當(dāng)前數(shù)據(jù)的情況進(jìn)行undo回滾或者是redo前滾,這樣就保證了數(shù)據(jù)的強(qiáng)一致性。接著,我們就說一下分布式事務(wù)。
分布式理論
當(dāng)我們的單個(gè)數(shù)據(jù)庫(kù)的性能產(chǎn)生瓶頸的時(shí)候,我們可能會(huì)對(duì)數(shù)據(jù)庫(kù)進(jìn)行分區(qū),這里所說的分區(qū)指的是物理分區(qū),分區(qū)之后可能不同的庫(kù)就處于不同的服務(wù)器上了,這個(gè)時(shí)候單個(gè)數(shù)據(jù)庫(kù)的ACID已經(jīng)不能適應(yīng)這種情況了,而在這種ACID的集群環(huán)境下,再想保證集群的ACID幾乎是很難達(dá)到,或者即使能達(dá)到那么效率和性能會(huì)大幅下降,最為關(guān)鍵的是再很難擴(kuò)展新的分區(qū)了,這個(gè)時(shí)候如果再追求集群的ACID會(huì)導(dǎo)致我們的系統(tǒng)變得很差,這時(shí)我們就需要引入一個(gè)新的理論原則來適應(yīng)這種集群的情況,就是 CAP 原則或者叫CAP定理,那么CAP定理指的是什么呢?
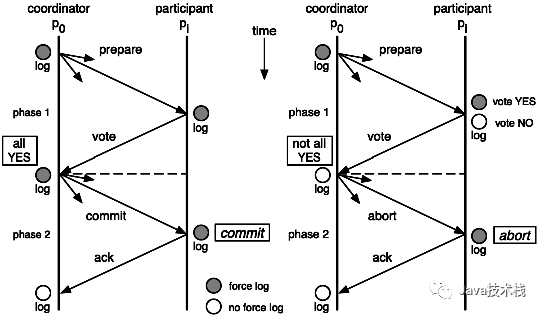
具體地講在分布式系統(tǒng)中,在任何數(shù)據(jù)庫(kù)設(shè)計(jì)中,一個(gè)Web應(yīng)用至多只能同時(shí)支持上面的兩個(gè)屬性。顯然,任何橫向擴(kuò)展策略都要依賴于數(shù)據(jù)分區(qū)。因此,設(shè)計(jì)人員必須在一致性與可用性之間做出選擇。這個(gè)定理在迄今為止的分布式系統(tǒng)中都是適用的! 為什么這么說呢?這個(gè)時(shí)候有同學(xué)可能會(huì)把數(shù)據(jù)庫(kù)的2PC(兩階段提交)搬出來說話了。OK,我們就來看一下數(shù)據(jù)庫(kù)的兩階段提交。對(duì)數(shù)據(jù)庫(kù)分布式事務(wù)有了解的同學(xué)一定知道數(shù)據(jù)庫(kù)支持的2PC,又叫做 XA Transactions。
MySQL從5.5版本開始支持,SQL Server 2005 開始支持,Oracle 7 開始支持。
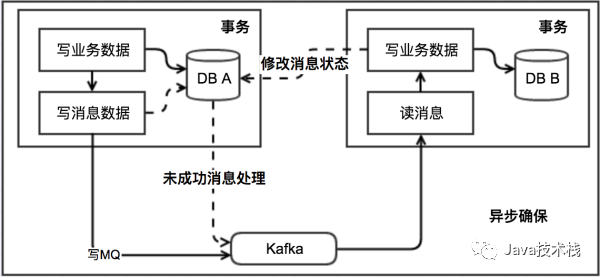
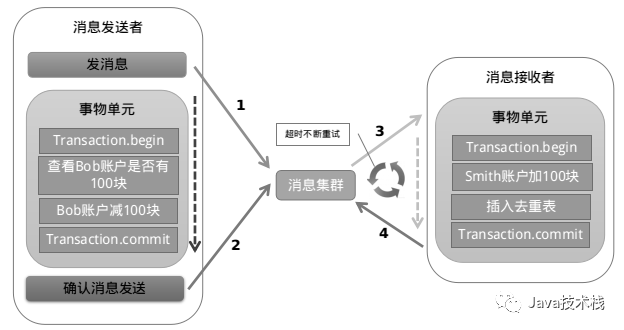
上面介紹的那些分布式事務(wù)的處理方案你在其他地方或許也可以看到,但是并沒有相關(guān)的實(shí)際代碼或者是開源代碼,所以算不上什么干貨,下面就放干貨了。在 .NET 領(lǐng)域,似乎沒有什么現(xiàn)成的關(guān)于分布式事務(wù)的解決方案,或者說是有但未開源。據(jù)筆者了解,有一些公司內(nèi)部其實(shí)是有這種解決方案的,但是也是作為公司的一個(gè)核心產(chǎn)品之一,并未開源...鑒于以上原因,所以博主就打算自己寫一個(gè)并且開源出來,所以從17年初就開始做這個(gè)事情,然后花了大半年的時(shí)間在一直不斷完善,就是下面這個(gè) CAP。Github CAP:這里的 CAP 就不是 CAP 理論了,而是一個(gè) .NET 分布式事務(wù)解決方案的名字。詳細(xì)介紹:http://www.cnblogs.com/savorboard/p/cap.html相關(guān)文檔:http://www.cnblogs.com/savorboard/p/cap-document.html夸張的是,這個(gè)解決方案是具有可視化界面(Dashboard)的,你可以很方面的看到哪些消息執(zhí)行成功,哪些消息執(zhí)行失敗,到底是發(fā)送失敗還是處理失敗,一眼便知。最夸張的是,這個(gè)解決方案的可視化界面還提供了實(shí)時(shí)動(dòng)態(tài)圖表,這樣不但可以看到實(shí)時(shí)的消息發(fā)送及處理情況,連當(dāng)前的系統(tǒng)處理消息的速度都可以看到,還可以看到過去24小時(shí)內(nèi)的歷史消息吞吐量。最最夸張的是,這個(gè)解決方案的還幫你集成了 Consul 做分布式節(jié)點(diǎn)發(fā)現(xiàn)和注冊(cè)還有心跳檢查,你隨時(shí)可以看到其他的節(jié)點(diǎn)的狀況。

 來源:http://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html
來源:http://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html