
機(jī)器學(xué)習(xí)神器Scikit-Learn保姆級(jí)入門(mén)教程
Scikit-learn是一個(gè)非常知名的Python機(jī)器學(xué)習(xí)庫(kù),它廣泛地用于統(tǒng)計(jì)分析和機(jī)器學(xué)習(xí)建模等數(shù)據(jù)科學(xué)領(lǐng)域。
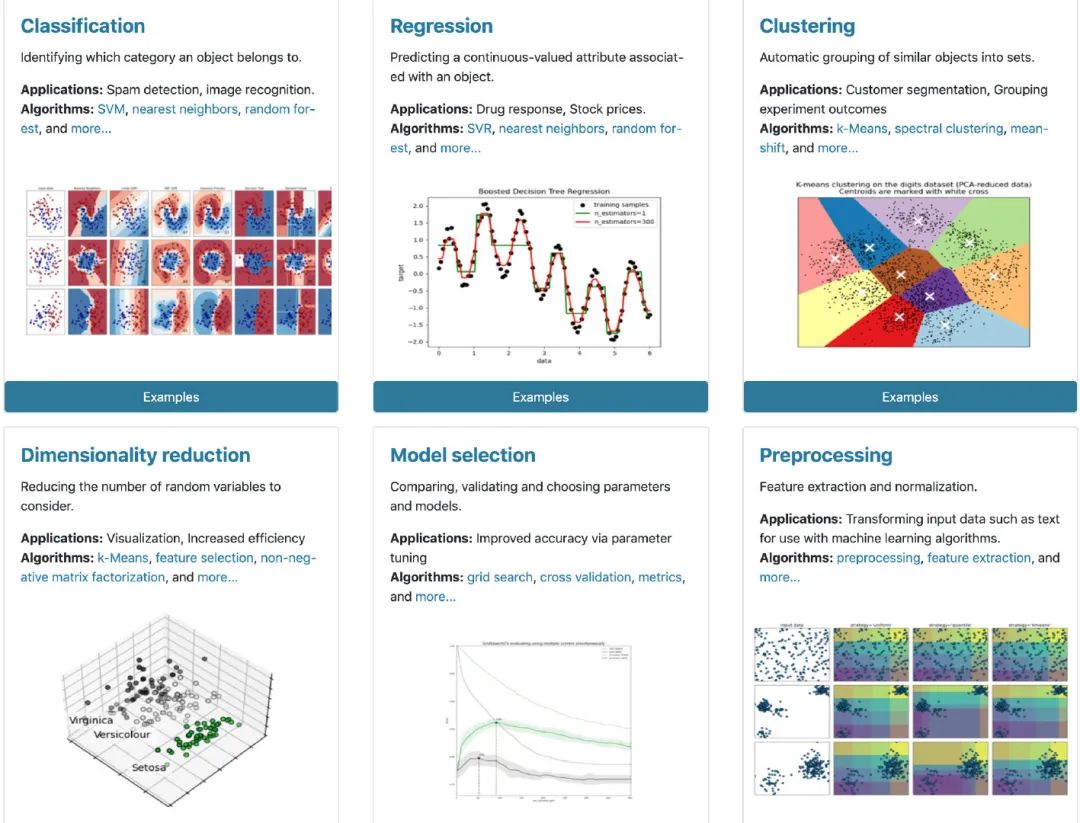
建模無(wú)敵:用戶通過(guò)scikit-learn能夠?qū)崿F(xiàn)各種監(jiān)督和非監(jiān)督學(xué)習(xí)的模型 功能多樣:同時(shí)使用sklearn還能夠進(jìn)行數(shù)據(jù)的預(yù)處理、特征工程、數(shù)據(jù)集切分、模型評(píng)估等工作 數(shù)據(jù)豐富:內(nèi)置豐富的數(shù)據(jù)集,比如:泰坦尼克、鳶尾花等,數(shù)據(jù)不再愁啦
本篇文章通過(guò)簡(jiǎn)明快要的方式來(lái)介紹scikit-learn的使用,更多詳細(xì)內(nèi)容請(qǐng)參考官網(wǎng):
內(nèi)置數(shù)據(jù)集使用 數(shù)據(jù)集切分 數(shù)據(jù)歸一化和標(biāo)準(zhǔn)化 類型編碼 建模6步曲

Scikit-learn使用神圖
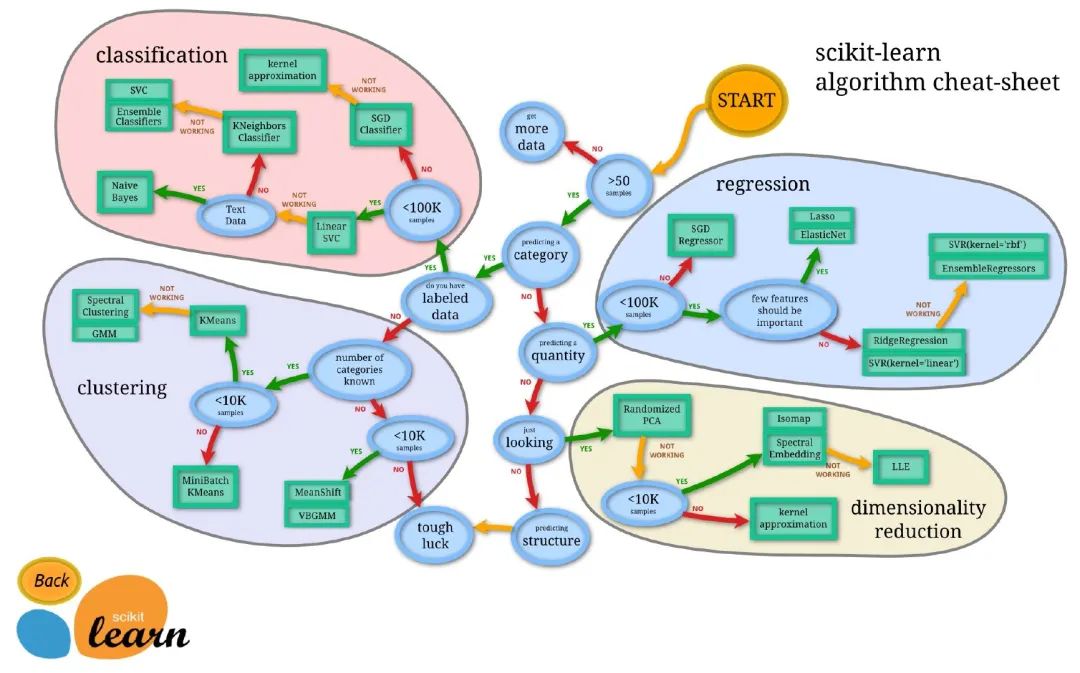
下面這張圖是官網(wǎng)提供的,從樣本量的大小開(kāi)始,分為回歸、分類、聚類、數(shù)據(jù)降維共4個(gè)方面總結(jié)了scikit-learn的使用:
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
安裝
關(guān)于安裝scikit-learn,建議通過(guò)使用anaconda來(lái)進(jìn)行安裝,不用擔(dān)心各種配置和環(huán)境問(wèn)題。當(dāng)然也可以直接pip來(lái)安裝:
pip?install?scikit-learn
數(shù)據(jù)集生成
sklearn內(nèi)置了一些優(yōu)秀的數(shù)據(jù)集,比如:Iris數(shù)據(jù)、房?jī)r(jià)數(shù)據(jù)、泰坦尼克數(shù)據(jù)等。
import?pandas?as?pd
import?numpy?as?np
import?sklearn?
from?sklearn?import?datasets??#?導(dǎo)入數(shù)據(jù)集
分類數(shù)據(jù)-iris數(shù)據(jù)
#?iris數(shù)據(jù)
iris?=?datasets.load_iris()
type(iris)
sklearn.utils.Bunch
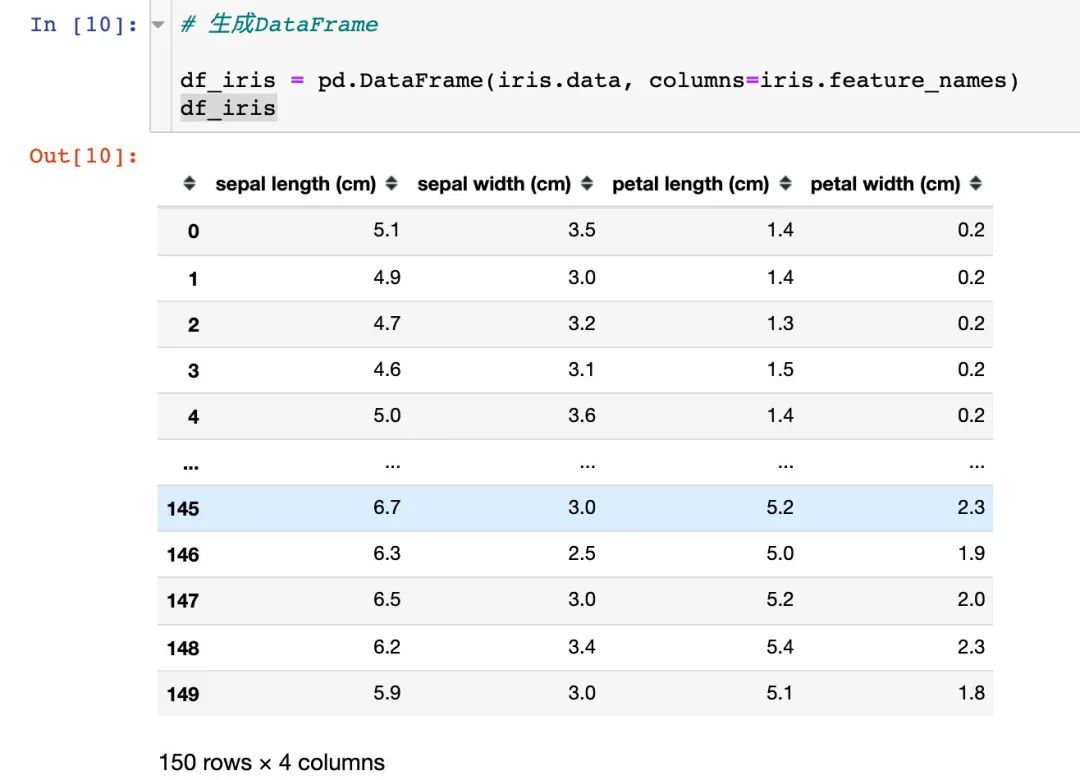
iris數(shù)據(jù)到底是什么樣子?每個(gè)內(nèi)置的數(shù)據(jù)都存在很多的信息
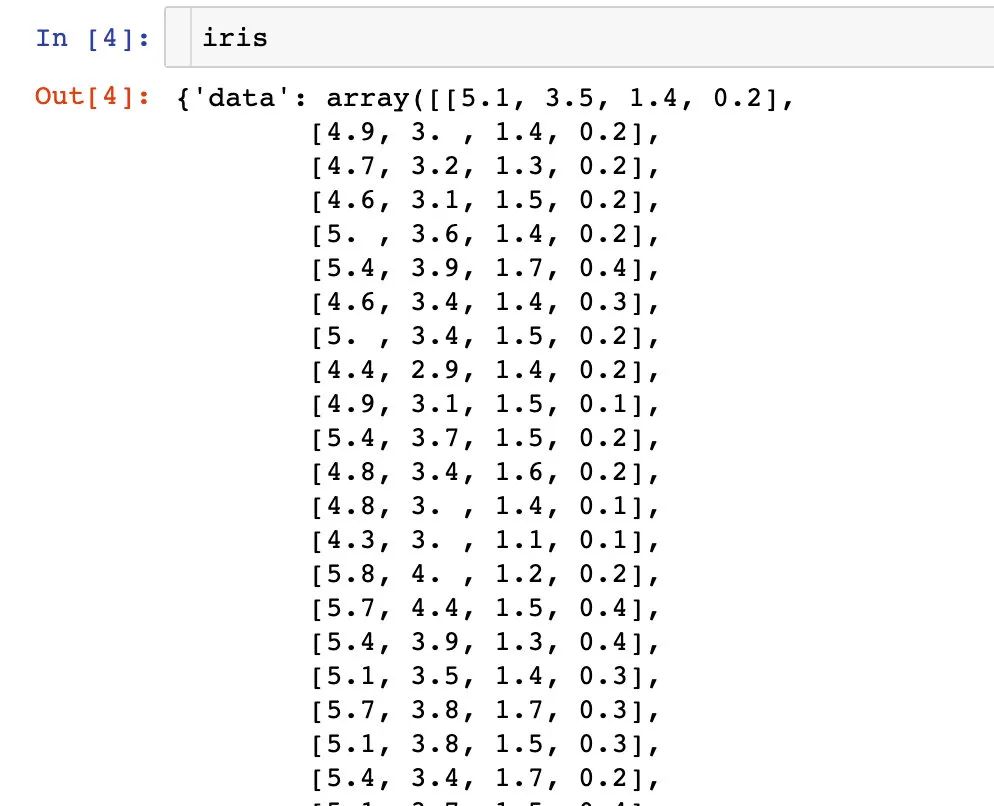


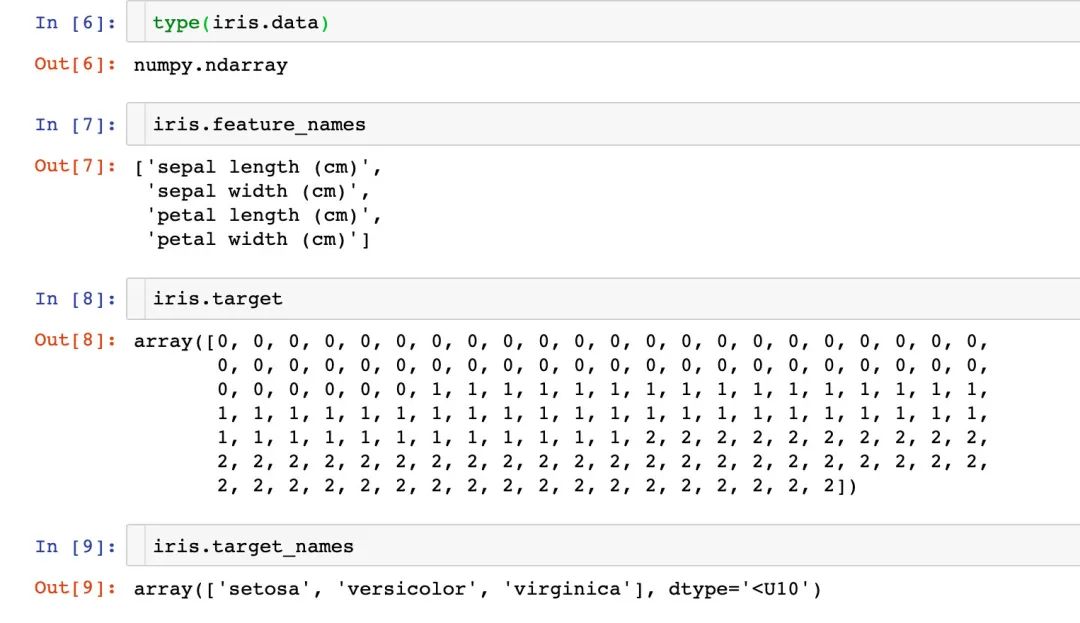
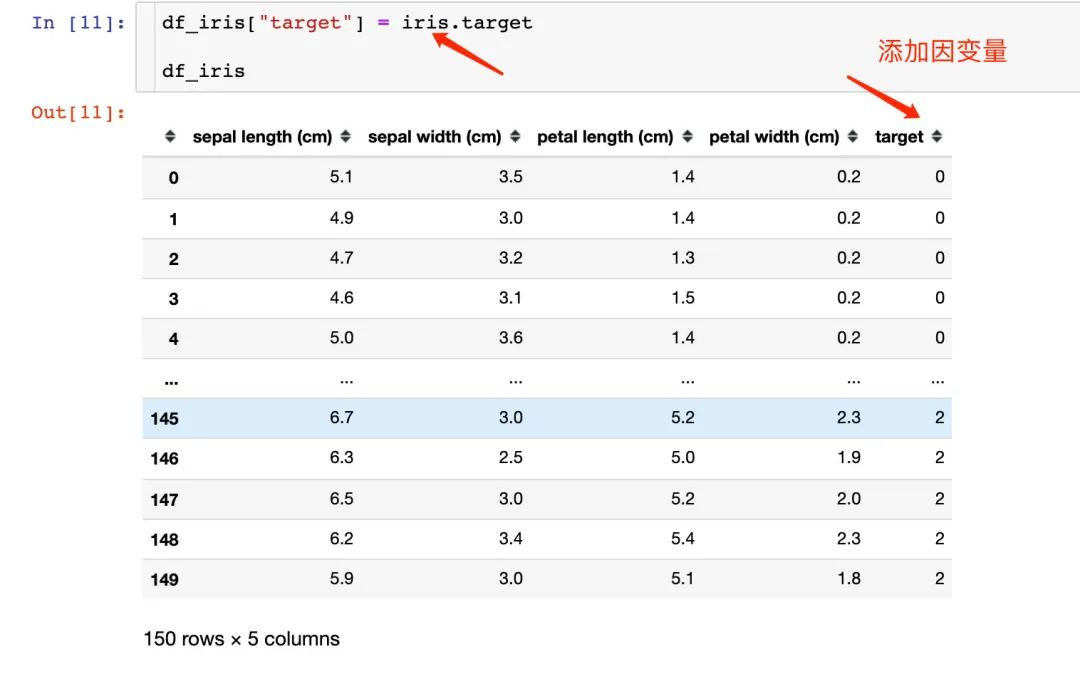
可以將上面的數(shù)據(jù)生成我們想看到的DataFrame,還可以添加因變量:
回歸數(shù)據(jù)-波士頓房?jī)r(jià)
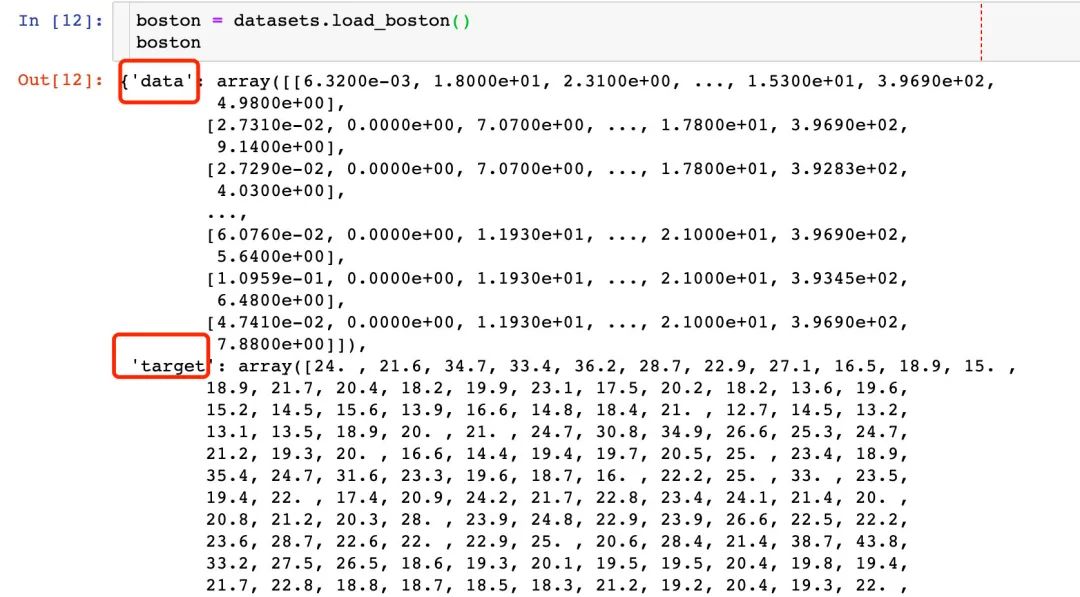

我們重點(diǎn)關(guān)注的屬性:
data target、target_names feature_names filename
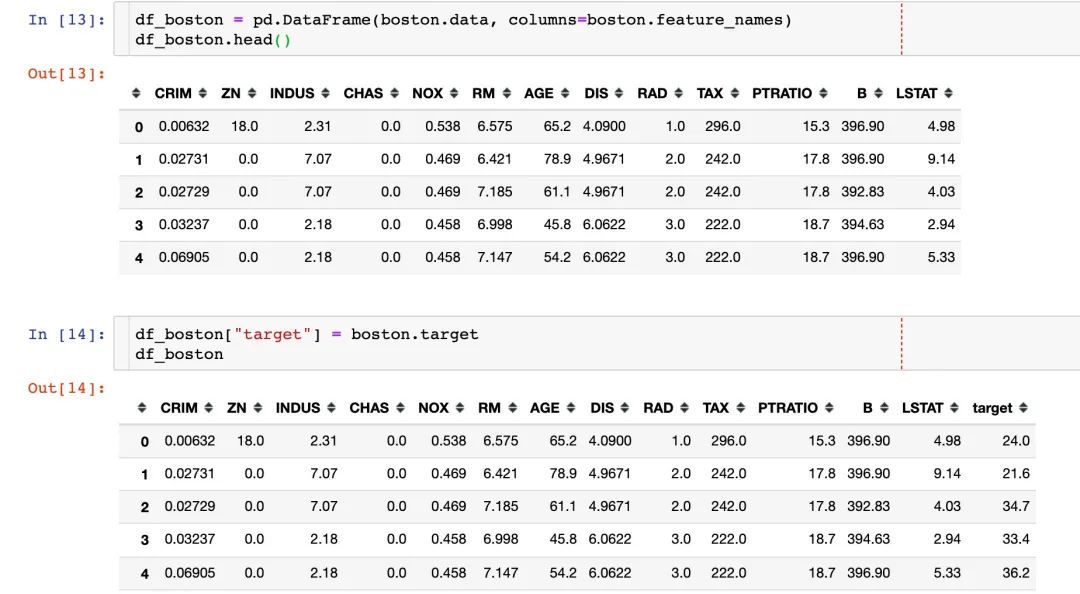
同樣可以生成DataFrame:
三種方式生成數(shù)據(jù)
方式1
#調(diào)用模塊
from?sklearn.datasets?import?load_iris
data?=?load_iris()
#導(dǎo)入數(shù)據(jù)和標(biāo)簽
data_X?=?data.data
data_y?=?data.target?
方式2
from?sklearn?import?datasets
loaded_data?=?datasets.load_iris()??#?導(dǎo)入數(shù)據(jù)集的屬性
#導(dǎo)入樣本數(shù)據(jù)
data_X?=?loaded_data.data
#?導(dǎo)入標(biāo)簽
data_y?=?loaded_data.target
方式3
#?直接返回
data_X,?data_y?=?load_iris(return_X_y=True)
數(shù)據(jù)集使用匯總
from?sklearn?import?datasets??#?導(dǎo)入庫(kù)
boston?=?datasets.load_boston()??#?導(dǎo)入波士頓房?jī)r(jià)數(shù)據(jù)
print(boston.keys())??#?查看鍵(屬性)?????['data','target','feature_names','DESCR',?'filename']?
print(boston.data.shape,boston.target.shape)??#?查看數(shù)據(jù)的形狀?
print(boston.feature_names)??#?查看有哪些特征?
print(boston.DESCR)??#?described?數(shù)據(jù)集描述信息?
print(boston.filename)??#?文件路徑?
數(shù)據(jù)切分
#?導(dǎo)入模塊
from?sklearn.model_selection?import?train_test_split
#?劃分為訓(xùn)練集和測(cè)試集數(shù)據(jù)
X_train,?X_test,?y_train,?y_test?=?train_test_split(
??data_X,?
??data_y,?
??test_size=0.2,
??random_state=111
)
#?150*0.8=120
len(X_train)
數(shù)據(jù)標(biāo)準(zhǔn)化和歸一化
from?sklearn.preprocessing?import?StandardScaler??#?標(biāo)準(zhǔn)化
from?sklearn.preprocessing?import?MinMaxScaler??#?歸一化
#?標(biāo)準(zhǔn)化
ss?=?StandardScaler()
X_scaled?=?ss.fit_transform(X_train)??#?傳入待標(biāo)準(zhǔn)化的數(shù)據(jù)
#?歸一化
mm?=?MinMaxScaler()
X_scaled?=?mm.fit_transform(X_train)
類型編碼
來(lái)自官網(wǎng)案例:https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
對(duì)數(shù)字編碼

對(duì)字符串編碼

建模案例
導(dǎo)入模塊
from?sklearn.neighbors?import?KNeighborsClassifier,?NeighborhoodComponentsAnalysis??#?模型
from?sklearn.datasets?import?load_iris??#?導(dǎo)入數(shù)據(jù)
from?sklearn.model_selection?import?train_test_split??#?切分?jǐn)?shù)據(jù)
from?sklearn.model_selection?import?GridSearchCV??#?網(wǎng)格搜索
from?sklearn.pipeline?import?Pipeline??#?流水線管道操作
from?sklearn.metrics?import?accuracy_score??#?得分驗(yàn)證
模型實(shí)例化
#?模型實(shí)例化
knn?=?KNeighborsClassifier(n_neighbors=5)
訓(xùn)練模型
knn.fit(X_train,?y_train)
KNeighborsClassifier()
測(cè)試集預(yù)測(cè)
y_pred?=?knn.predict(X_test)
y_pred??#?基于模型的預(yù)測(cè)值
array([0,?0,?2,?2,?1,?0,?0,?2,?2,?1,?2,?0,?1,?2,?2,?0,?2,?1,?0,?2,?1,?2,
???????1,?1,?2,?0,?0,?2,?0,?2])
得分驗(yàn)證
模型得分驗(yàn)證的兩種方式:
knn.score(X_test,y_test)
0.9333333333333333
accuracy_score(y_pred,y_test)
0.9333333333333333
網(wǎng)格搜索
如何搜索參數(shù)
from?sklearn.model_selection?import?GridSearchCV
#?搜索的參數(shù)
knn_paras?=?{"n_neighbors":[1,3,5,7]}
#?默認(rèn)的模型
knn_grid?=?KNeighborsClassifier()
#?網(wǎng)格搜索的實(shí)例化對(duì)象
grid_search?=?GridSearchCV(
?knn_grid,?
?knn_paras,?
?cv=10??#?10折交叉驗(yàn)證
)
grid_search.fit(X_train,?y_train)
GridSearchCV(cv=10,?estimator=KNeighborsClassifier(),
?????????????param_grid={'n_neighbors':?[1,?3,?5,?7]})
#?通過(guò)搜索找到的最好參數(shù)值
grid_search.best_estimator_?
KNeighborsClassifier(n_neighbors=7)
grid_search.best_params_
Out[42]:
{'n_neighbors':?7}
grid_search.best_score_
0.975
基于搜索結(jié)果建模
knn1?=?KNeighborsClassifier(n_neighbors=7)
knn1.fit(X_train,?y_train)
KNeighborsClassifier(n_neighbors=7)
通過(guò)下面的結(jié)果可以看到:網(wǎng)格搜索之后的建模效果是優(yōu)于未使用網(wǎng)格搜索的模型:
y_pred_1?=?knn1.predict(X_test)
knn1.score(X_test,y_test)
1.0
accuracy_score(y_pred_1,y_test)
1.0本文為轉(zhuǎn)載分享&推薦閱讀,若侵權(quán)請(qǐng)聯(lián)系后臺(tái)刪除
對(duì)比Excel系列圖書(shū)累積銷(xiāo)量達(dá)15w冊(cè),讓你輕松掌握數(shù)據(jù)分析技能,可以在全網(wǎng)搜索書(shū)名進(jìn)行了解:
