
OpenAI:基于對比學(xué)習(xí)的無監(jiān)督預(yù)訓(xùn)練

如何無監(jiān)督地訓(xùn)練一個神經(jīng)檢索模型是當(dāng)前IR社區(qū)的研究熱點之一,在今天我們分享的論文中,OpenAI團(tuán)隊嘗試在大規(guī)模無監(jiān)督數(shù)據(jù)上對GPT系列模型做對比預(yù)訓(xùn)練(Contrastive Pre-Training),得到的 CPT-text模型 在文本匹配、語義搜索等任務(wù)上取得了優(yōu)異的zero-shot性能。
OpenAI: Text and Code Embeddings by Contrastive Pre-Training http://arxiv.org/abs/2201.10005 Blog:Introducing Text and Code Embeddings in the OpenAI API[1]
在語義搜索、文本相似度計算等應(yīng)用場景中,如何得到優(yōu)質(zhì)的文本嵌入(Text Embedding)一直是一個核心研究問題,以往的研究工作通常會從訓(xùn)練數(shù)據(jù)、訓(xùn)練目標(biāo)和模型結(jié)構(gòu)三個角度來優(yōu)化文本嵌入,而OpenAI的這篇工作表明在無監(jiān)督數(shù)據(jù)上做大規(guī)模的對比學(xué)習(xí)預(yù)訓(xùn)練就可以得到高質(zhì)量的文本嵌入。
Approach
無監(jiān)督對比學(xué)習(xí)的關(guān)鍵問題就是如何構(gòu)造要對比的樣本,而本文提出可以對文本中相鄰的片段做對比,即將相鄰片段作正樣本,而負(fù)樣本則通過批內(nèi)負(fù)采樣得到,這一思路與BERT中的NSP任務(wù)有些類似。
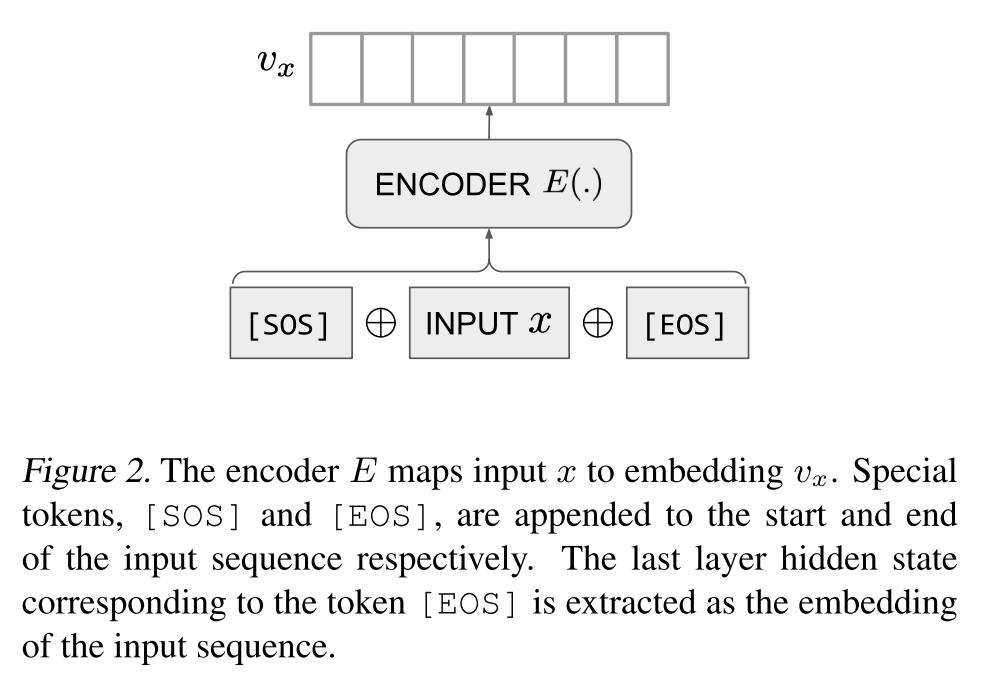
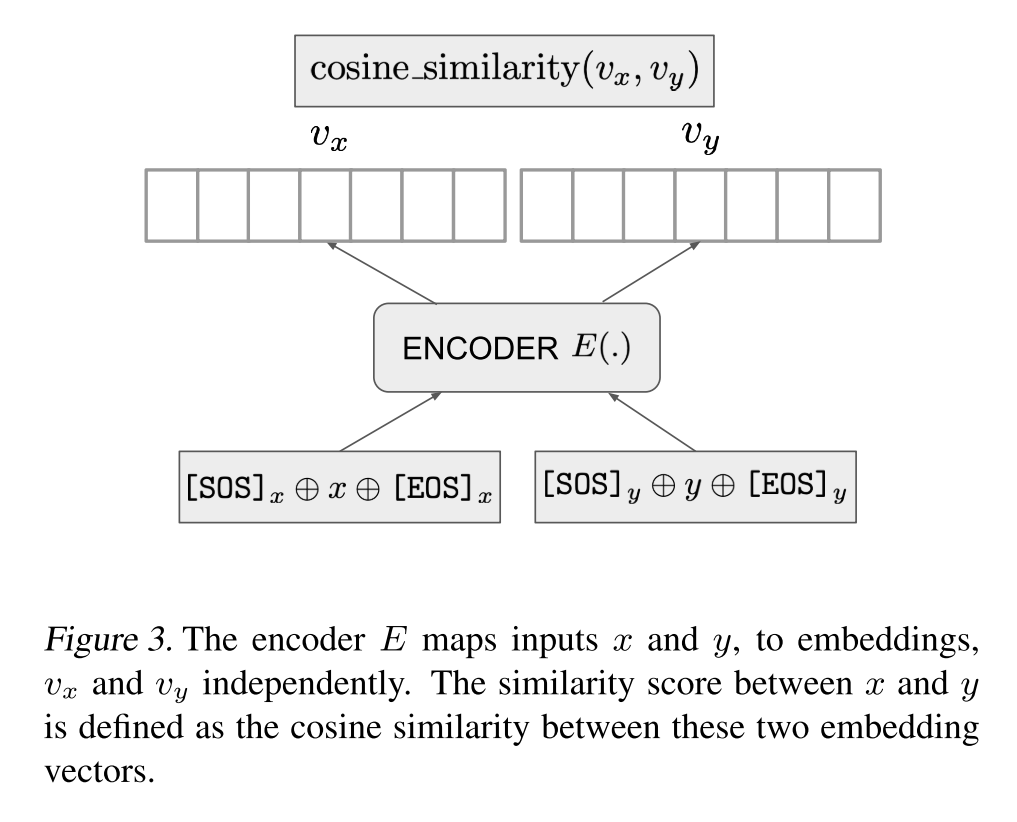
在模型訓(xùn)練過程中,給定一個訓(xùn)練樣本 ,編碼器首先獨(dú)立地編碼 和 ,并將 對應(yīng)的低維稠密向量作為文本的表示,將 和 的余弦相似度作為相關(guān)性打分:
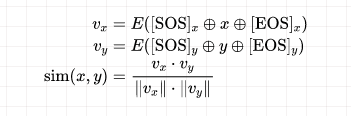
得到相關(guān)性打分后,使用批內(nèi)負(fù)樣本策略構(gòu)建對比損失,即針對大小為 的batch中的每個樣本,將其他的 個樣本當(dāng)作當(dāng)前樣本的負(fù)樣本,而每個batch的logits是一個 的矩陣:
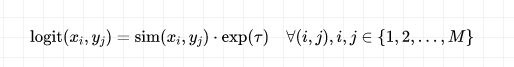
其中 是一個可訓(xùn)練的溫度參數(shù)。在該 的矩陣中,只有對角線上的項被當(dāng)作正樣本,最終的loss為行方向和列方向的交叉熵?fù)p失之和,用偽代碼可表示為:
labels = np.arange(M)
l_r = cross_entropy(logits, labels, axis=0)
l_c = cross_entropy(logits, labels, axis=1)
loss = (l_r + l_c) / 2
最終就得到了完全無監(jiān)督的文本嵌入模型,作者將其稱之為cpt-text。
Setup
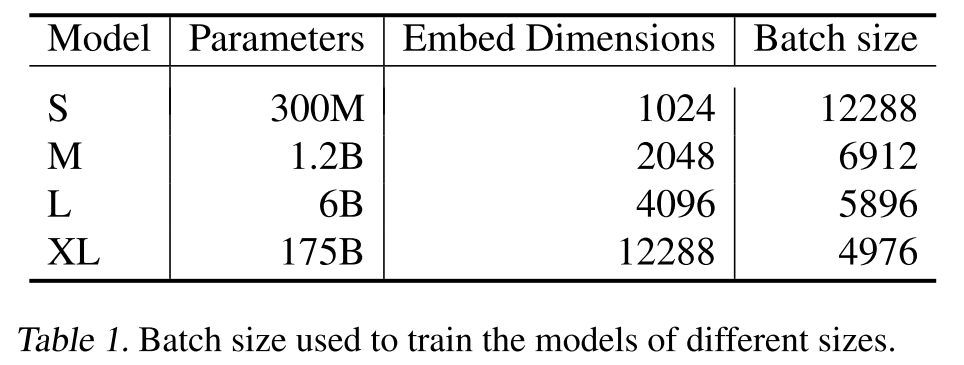
作者用不同大小的GPT系列模型做模型初始化,如下表所示,針對不同大小的模型,作者分別設(shè)置了不同的隱層維數(shù)和批量大小。
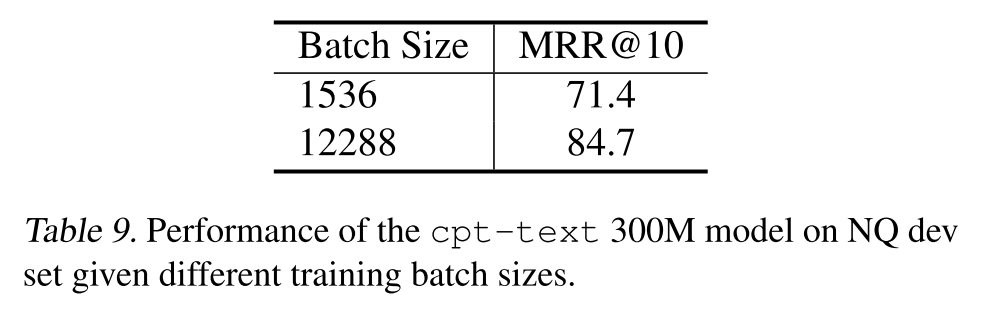
另外,本文也再次驗證了做對比學(xué)習(xí)顯卡越多越好:
Results
雖然文本相似度(Sentence Similarity)任務(wù)和語義搜索(Semantic Search)任務(wù)的目標(biāo)都是獲取高質(zhì)量的文本表示,但面向這兩個任務(wù)的相關(guān)研究長期以來都是割裂的,也就是說,做文本相似度任務(wù)的論文不會評估模型在語義搜索任務(wù)上的效果,反之亦然。而下述實驗結(jié)果表明本文作者的cpt-text可以在兩個任務(wù)上都取得不錯的表現(xiàn)。
線性探測分類任務(wù)
線性探測分類(linear-probe classification)是指將embedding作為下游任務(wù)的特征訓(xùn)練一個線性分類器,用于評估embedding在某個任務(wù)上的區(qū)分能力,實驗結(jié)果如下表所示:
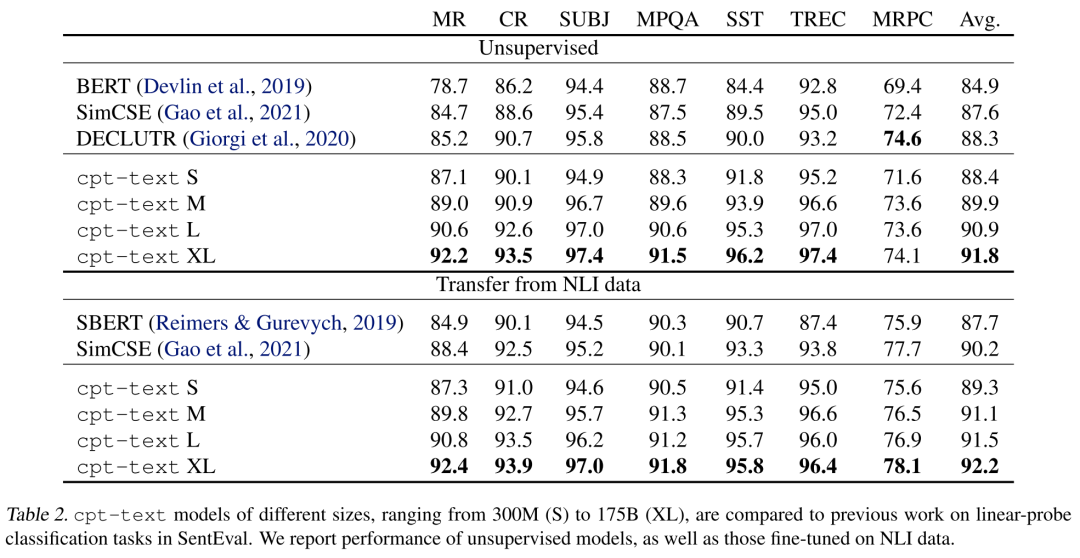
可以看到,直接評估cpt-text(unsupervised)和先在NLI數(shù)據(jù)集上微調(diào)后再評估(Transfer from NLI data)的整體區(qū)別并不是很大,cpt-text整體上也超越了SimCSE這種強(qiáng)基線模型,且最大的模型(175B)取得了SOTA結(jié)果。
zero-shot classification
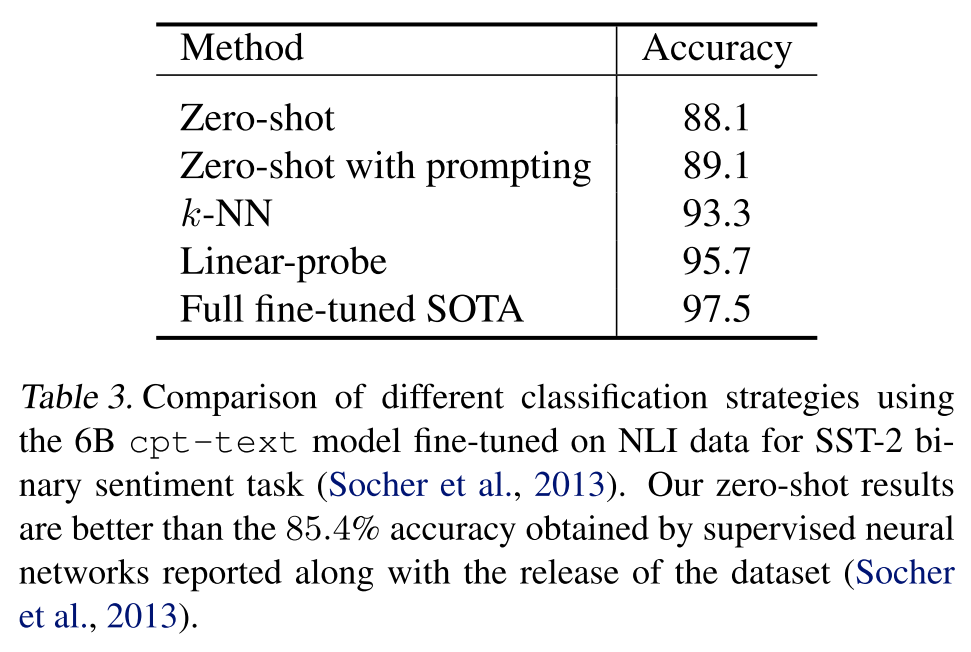
作者在二元情感分類數(shù)據(jù)集SST-2上進(jìn)一步評估了embedding的質(zhì)量,如下表所示,其中zero-shot表示計算輸入樣本分別和positive和negative這兩個詞的embedding的距離,并將更近的那個詞作為預(yù)測標(biāo)簽;zero-shot with prompting表示將上述的單個詞positive和negative替換為了一個更完整的句子,比如this is an example of a positive/negative movie review。但zero-shot方法比后續(xù)的 -NN()和線性分類都要差不少。
Sentence Similarity
奇怪的是,cpt-text在SentEval基準(zhǔn)上要比之前的無監(jiān)督SOTA差很多,如下表所示,作者認(rèn)為可能的原因是句子相似度任務(wù)的定義本身就不明確,即相同的句子對在不同的人看來相似度可能是不一樣的,最典型的一類case就是情感極性不同的樣本是否是相似的。
從預(yù)訓(xùn)練任務(wù)的角度來看,cpt-text的預(yù)訓(xùn)練任務(wù)是拉近相鄰片段的距離,但相鄰片段在語義上是相關(guān)但不相似的,也就是說該預(yù)訓(xùn)練任務(wù)實際上更接近于語義搜索的相關(guān)性建模,所以作者的模型在句子相似度任務(wù)上的表現(xiàn)就不如SimCSE了,因為SimCSE對比損失的構(gòu)造更接近于句子相似度任務(wù)的定義。
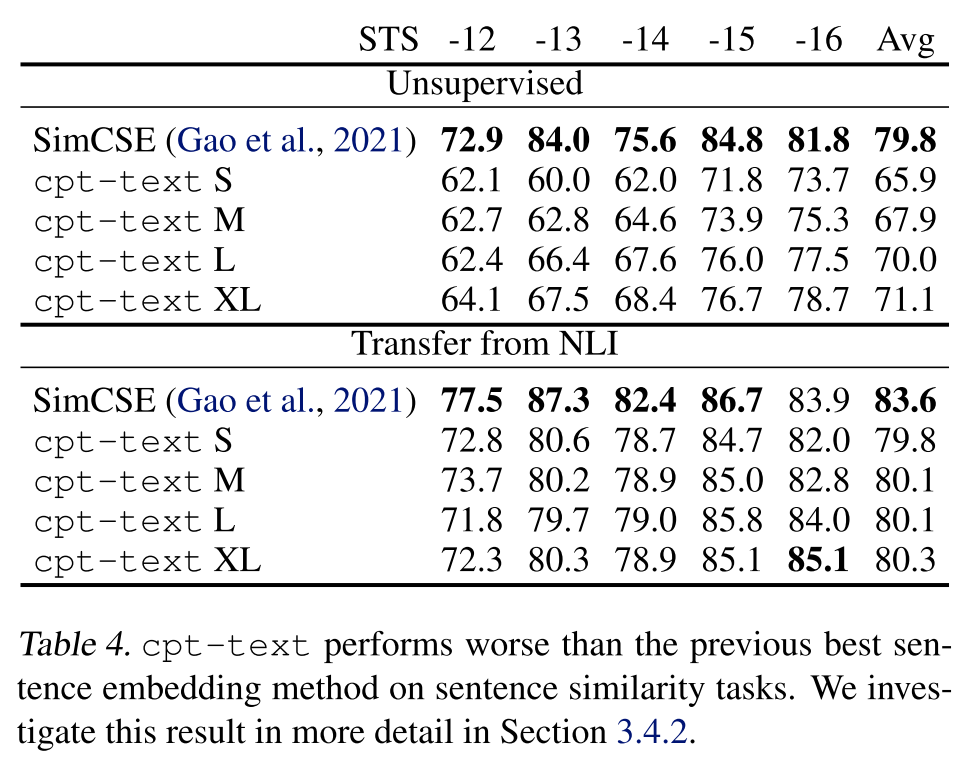
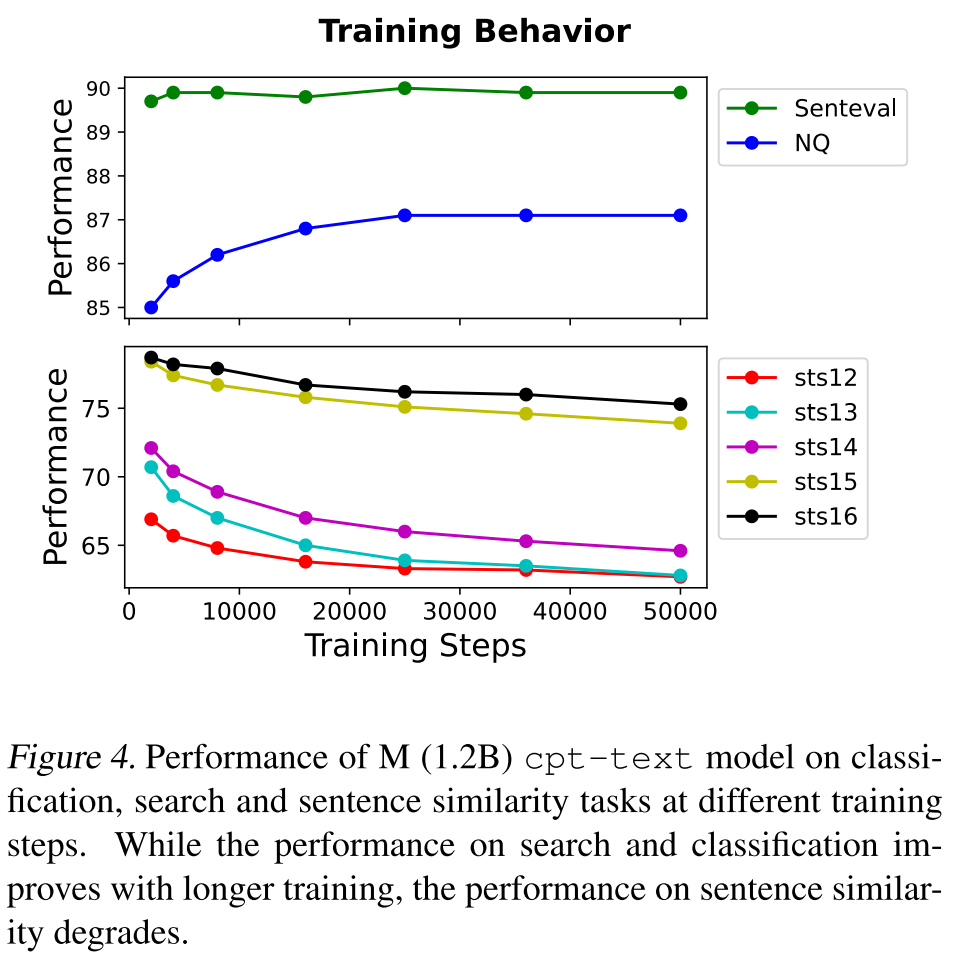
另外,作者發(fā)現(xiàn)隨著訓(xùn)練的進(jìn)行,模型在線性探測和語義搜索任務(wù)上的表現(xiàn)越來越好,但是在句子相似度任務(wù)上的表現(xiàn)卻越來越差,這進(jìn)一步說明句子相似度和語義搜索的確是兩個不同的任務(wù),甚至他們的訓(xùn)練目標(biāo)可能存在一定的沖突,比如針對同一個事物表達(dá)肯定的句子和一個表達(dá)否定的句子,在語義搜索中可能會被當(dāng)作正樣本,而在句子相似度任務(wù)上則會被當(dāng)作負(fù)樣本。
Semantic Search
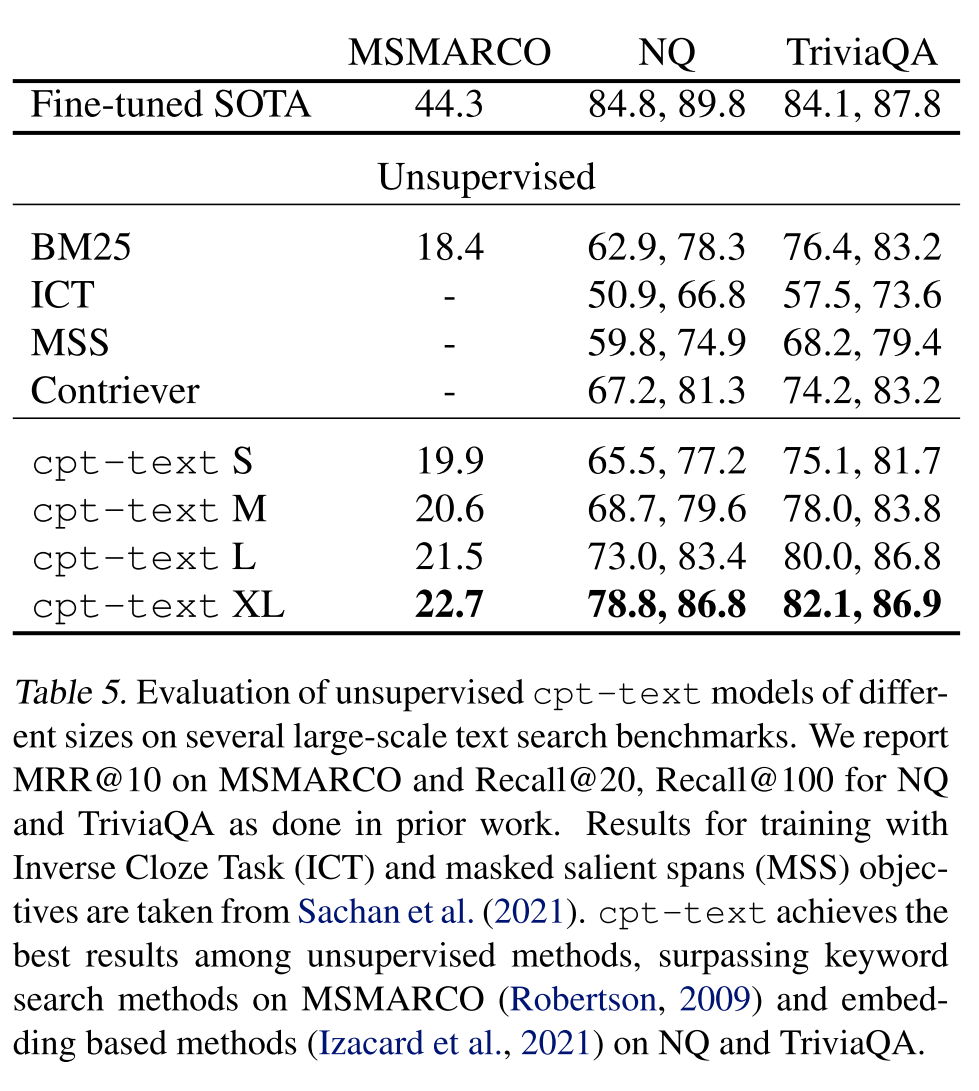
下表展示了cpt-text在語義搜索基準(zhǔn)MSMARCO、NQ和TriviaQA上的表現(xiàn),cpt-text超越了一些經(jīng)典的無監(jiān)督方法。
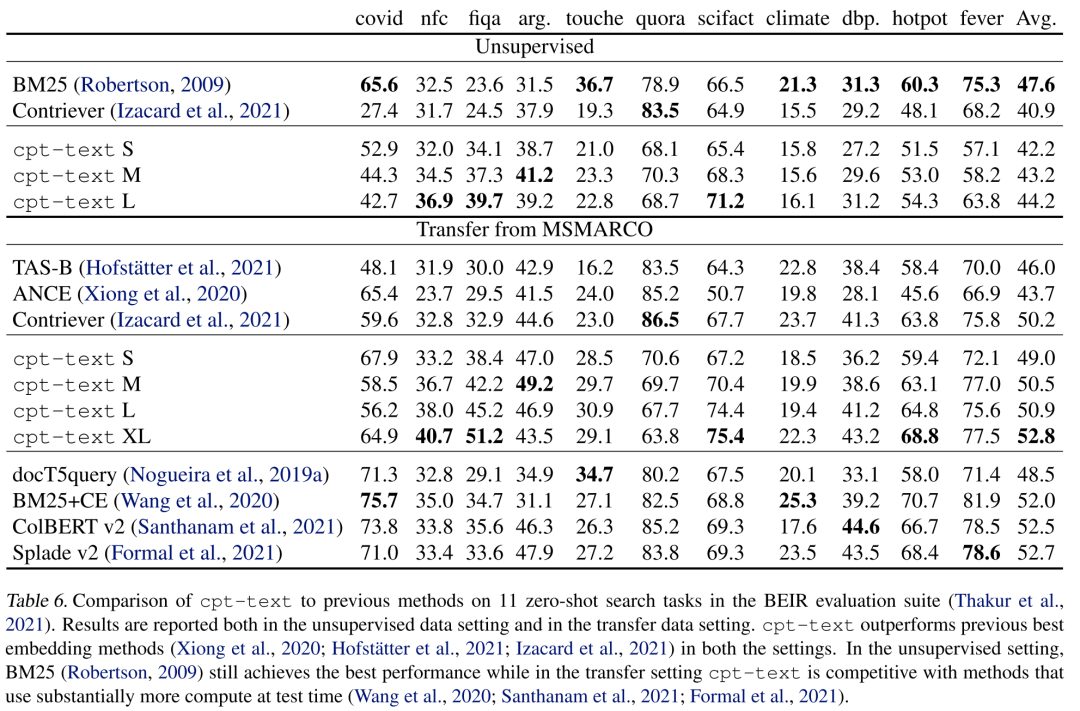
另外作者也評估了cpt-text的zero-shot性能,下表展示了cpt-text在BEIR基準(zhǔn)上的表現(xiàn),在無監(jiān)督的條件下,cpt-text與BM25還是有一定距離,但在經(jīng)過MSMARCO微調(diào)后,cpt-text超越了BM25,其中175B模型取得了SOTA結(jié)果。
Discussion
雖然是OpenAI發(fā)表的論文,但讀下來感覺更像是一篇面向GPT-3的PR論文。比較有啟發(fā)的點主要是大規(guī)模對比預(yù)訓(xùn)練的效果確實很好,之前已經(jīng)有很多論文證明了這一點,但一味的scaling可能也并沒有從本質(zhì)上解決語義檢索模型的泛化問題,提升的那部分指標(biāo)可能僅僅是模型見得更多,記得更多了而已。
- 點擊下方閱讀原文加入社區(qū)會員 -