
pandas 篩選數(shù)據(jù)的 8 個(gè)騷操作
↑?關(guān)注 + 星標(biāo)?,每天學(xué)Python新技能
后臺回復(fù)【大禮包】送你Python自學(xué)大禮包
日常用Python做數(shù)據(jù)分析最常用到的就是查詢篩選了,按各種條件、各種維度以及組合挑出我們想要的數(shù)據(jù),以方便我們分析挖掘。
東哥總結(jié)了日常查詢和篩選常用的種騷操作,供各位學(xué)習(xí)參考。本文采用sklearn的boston數(shù)據(jù)舉例介紹。
from?sklearn?import?datasets
import?pandas?as?pd
boston?=?datasets.load_boston()
df?=?pd.DataFrame(boston.data,?columns=boston.feature_names)
1. []
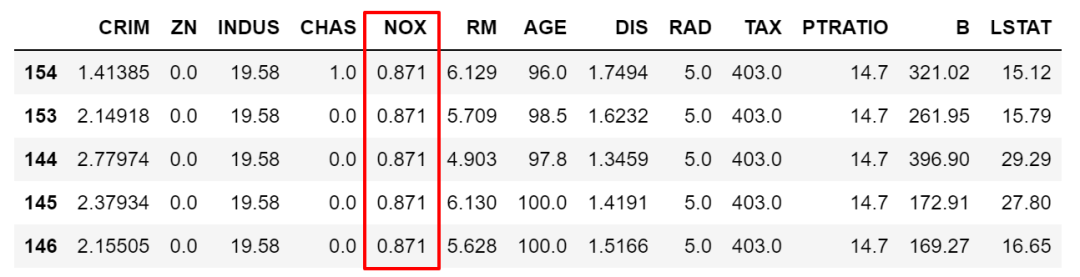
第一種是最快捷方便的,直接在dataframe的[]中寫篩選的條件或者組合條件。比如下面,想要篩選出大于NOX這變量平均值的所有數(shù)據(jù),然后按NOX降序排序。
df[df['NOX']>df['NOX'].mean()].sort_values(by='NOX',ascending=False).head()
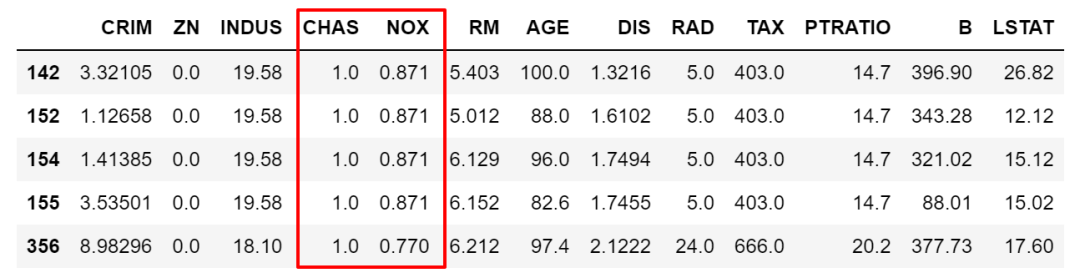
當(dāng)然,也可以使用組合條件,條件之間使用邏輯符號& |等。比如下面這個(gè)例子除了上面條件外再加上且條件CHAS為1,注意邏輯符號分開的條件要用()隔開。
df[(df['NOX']>df['NOX'].mean())&?(df['CHAS']?==1)].sort_values(by='NOX',ascending=False).head()
2. loc/iloc
除[]之外,loc/iloc應(yīng)該是最常用的兩種查詢方法了。loc按標(biāo)簽值(列名和行索引取值)訪問,iloc按數(shù)字索引訪問,均支持單值訪問或切片查詢。除了可以像[]按條件篩選數(shù)據(jù)以外,loc還可以指定返回的列變量,從行和列兩個(gè)維度篩選。
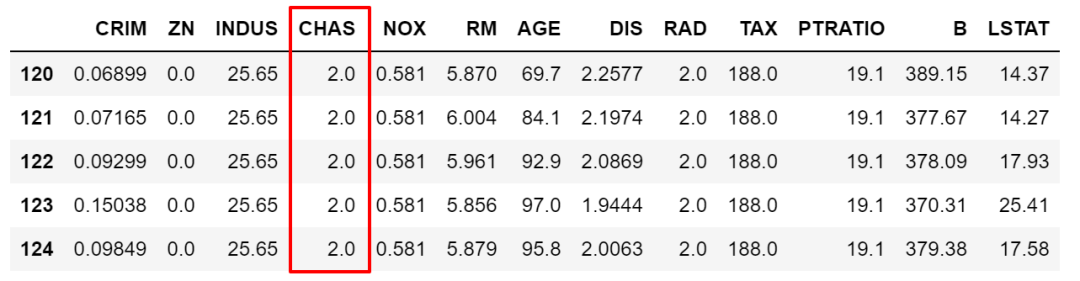
比如下面這個(gè)例子,按條件篩選出數(shù)據(jù),并篩選出指定變量,然后賦值。
df.loc[(df['NOX']>df['NOX'].mean()),['CHAS']]?=?2
3. isin
上面我們篩選條件< > == !=都是個(gè)范圍,但很多時(shí)候是需要鎖定某些具體的值的,這時(shí)候就需要isin了。比如我們要限定NOX取值只能為0.538,0.713,0.437中時(shí)。
df.loc[df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)

當(dāng)然,也可以做取反操作,在篩選條件前加~符號即可。
df.loc[~df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)

4. str.contains
上面的舉例都是數(shù)值大小比較的篩選條件,除數(shù)值以外當(dāng)然也有字符串的查詢需求。pandas里實(shí)現(xiàn)字符串的模糊篩選,可以用.str.contains()來實(shí)現(xiàn),有點(diǎn)像在SQL語句里用的是like。
下面利用titanic的數(shù)據(jù)舉例,篩選出人名中包含Mrs或者Lily的數(shù)據(jù),|或邏輯符號在引號內(nèi)。
train.loc[train['Name'].str.contains('Mrs|Lily'),:].head()

.str.contains()中還可以設(shè)置正則化篩選邏輯。
case=True:使用case指定區(qū)分大小寫 na=True:就表示把有NAN的轉(zhuǎn)換為布爾值True flags=re.IGNORECASE:標(biāo)志傳遞到re模塊,例如re.IGNORECASE regex=True:regex :如果為True,則假定第一個(gè)字符串是正則表達(dá)式,否則還是字符串
5. where/mask
在SQL里,我們知道where的功能是要把滿足條件的篩選出來。pandas中where也是篩選,但用法稍有不同。
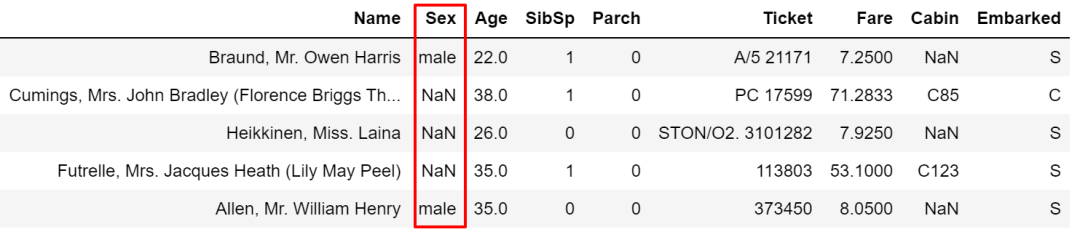
where接受的條件需要是布爾類型的,如果不滿足匹配條件,就被賦值為默認(rèn)的NaN或其他指定值。舉例如下,將Sex為male當(dāng)作篩選條件,cond就是一列布爾型的Series,非male的值就都被賦值為默認(rèn)的NaN空值了。
cond?=?train['Sex']?==?'male'
train['Sex'].where(cond,?inplace=True)
train.head()
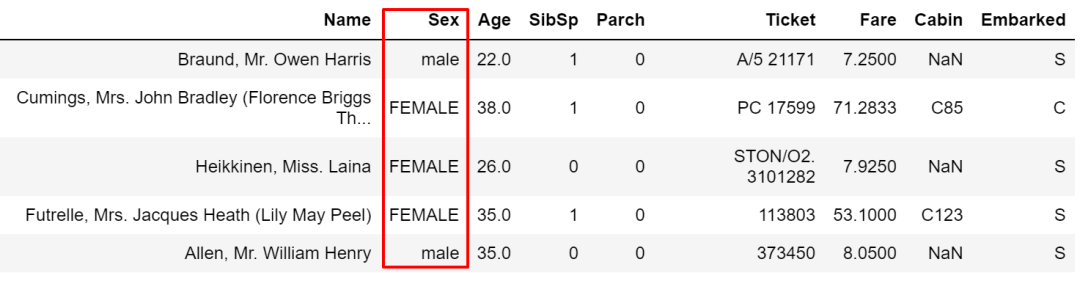
也可以用other賦給指定值。
cond?=?train['Sex']?==?'male'
train['Sex'].where(cond,?other='FEMALE',?inplace=True)
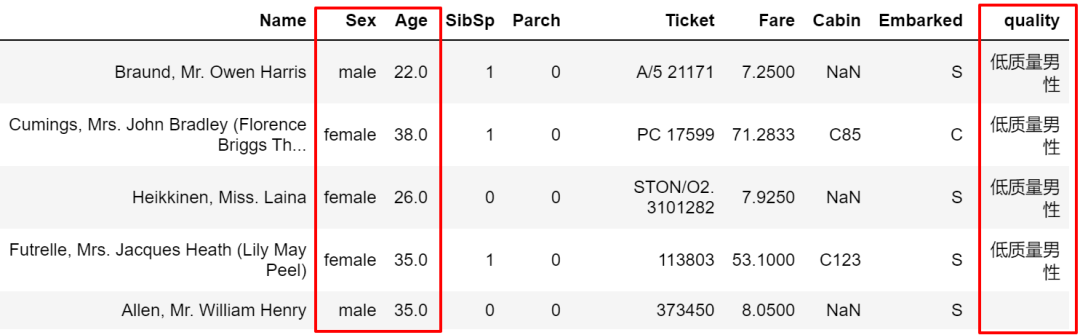
甚至還可以寫組合條件。
train['quality']?=?''
traincond1?=?train['Sex']?==?'male'
cond2?=?train['Age']?>?25
train['quality'].where(cond1?&?cond2,?other='低質(zhì)量男性',?inplace=True)
mask和where是一對操作,與where正好反過來。
train['quality'].mask(cond1?&?cond2,?other='低質(zhì)量男性',?inplace=True)

6. query
這是一種非常優(yōu)雅的篩選數(shù)據(jù)方式。所有的篩選操作都在''之內(nèi)完成。
#?常用方式
train[train.Age?>?25]
#?query方式
train.query('Age?>?25')
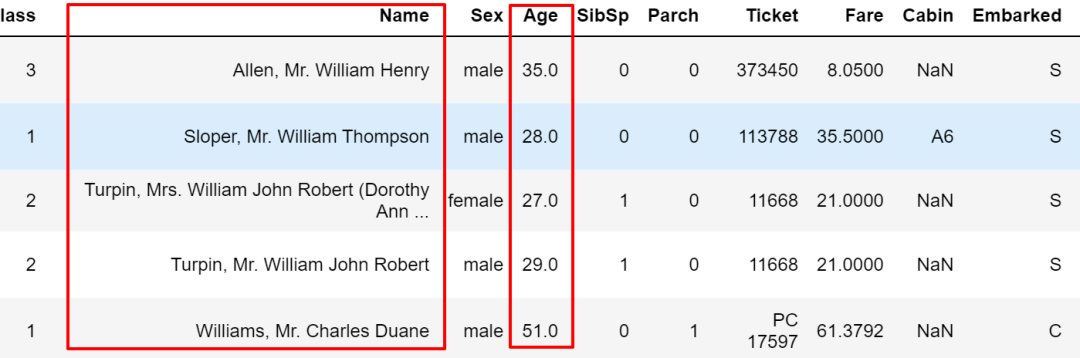
上面的兩種方式效果上是一樣的。再比如復(fù)雜點(diǎn)的,加入上面的str.contains用法的組合條件,注意條件里有''時(shí),兩邊要用""包住。
train.query("Name.str.contains('William')?&?Age?>?25")
在query里還可以通過@來設(shè)定變量。
name?=?'William'
train.query("Name.str.contains(@name)")
7. filter
filter是另外一個(gè)獨(dú)特的篩選功能。filter不篩選具體數(shù)據(jù),而是篩選特定的行或列。它支持三種篩選方式:
items:固定列名 regex:正則表達(dá)式 like:以及模糊查詢 axis:控制是行index或列columns的查詢
下面舉例介紹下。
train.filter(items=['Age',?'Sex'])

train.filter(regex='S',?axis=1)?#?列名包含S的

train.filter(like='2',?axis=0)?#?索引中有2的

train.filter(regex='^2',?axis=0).filter(like='S',?axis=1)
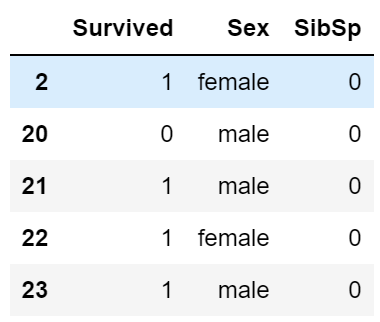
8. any/all
any方法意思是,如果至少有一個(gè)值為True結(jié)果便為True,all需要所有值為True結(jié)果才為True,比如下面這樣。
>>?train['Cabin'].all()
>>?False
>>?train['Cabin'].any()
>>?True
any和all一般是需要和其它操作配合使用的,比如查看每列的空值情況。
train.isnull().any(axis=0)

再比如查看含有空值的行數(shù)。
>>>?train.isnull().any(axis=1).sum()
>>>?708
參考:
[1] https://pandas.pydata.org/
[2]?https://www.gairuo.com/p/pandas-selecting-data
[3]?https://blog.csdn.net/weixin_43484764/article/details/89847241
推薦閱讀
推薦閱讀